Dynamic Probabilistic Reliable Broadcast

Abstract
Byzantine reliable broadcast is a fundamental primitive in distributed systems that allows a set of processes to agree on a message broadcast by a dedicated process, even when some of them are malicious (Byzantine). It guarantees that no two correct processes deliver different messages, and if a message is delivered by a correct process, every correct process eventually delivers one. Byzantine reliable broadcast protocols are known to scale poorly, as they require message exchanges, where is the number of system members. The quadratic cost can be explained by the inherent need for every process to relay a message to every other process.
In this paper, we explore ways to overcome this limitation by casting the problem to the probabilistic setting. We propose a solution in which every broadcast message is validated by a small set of witnesses, which allows us to maintain low latency and small communication complexity. In order to tolerate the slow adaptive adversary, we dynamically select the witnesses through a novel stream-local hash function: given a stream of inputs, it generates a stream of output hashed values that adapts to small deviations of the inputs.
Our performance analysis shows that the proposed solution exhibits significant scalability gains over state-of-the-art protocols.
Keywords and phrases:
Reliable broadcast, probabilistic algorithms, witness sets, stream-local hashing, cryptocurrencies, accountabilityCopyright and License:
2012 ACM Subject Classification:
Theory of computation Distributed algorithmsSupplementary Material:
Software (Source Code): https://github.com/testJota/mininet-distributed-system-simulation.gitarchived at
archived at
Acknowledgements:
This project was supported by TrustShare Innovation Chair. Akamai Technologies provided access to the hardware essential to our simulations. We would also like to thank Laurent Decreusefond, Emre Telatar, Nirupam Gupta and Anastasiia Kucherenko for fruitful discussions.Editors:
Silvia Bonomi, Letterio Galletta, Etienne Rivière, and Valerio SchiavoniSeries and Publisher:
1 Introduction
Modern distributed computing systems are expected to run in extremely harsh conditions. Besides communicating over weakly synchronous or even purely asynchronous communication networks, the processes performing distributed computations may be subject to failures: from hardware crashes to security attacks or malicious (Byzantine) behavior. In these environments, ensuring that a system never produces wrong outputs (safety properties) and, at the same time, makes progress by producing some outputs is extremely challenging. The distributed computing literature reveals a plethora of negative results, from theoretical lower bounds and impossibility results to empirical studies, that exhibit fundamental scalability limitations.
Efficient protocols that tolerate Byzantine failures are in high demand. Let us consider cryptocurrencies, by far the most popular decentralized application nowadays. Originally, cryptocurrency systems were designed on top of consensus-based blockchain protocols [37, 43]. However, consensus is a notoriously hard synchronization problem [19, 16, 10, 11]. It came as good news that we do not need consensus to implement a cryptocurrency [23, 24], which gave rise to asynchronous, consensus-free cryptocurrencies [14, 4, 27] that exhibit significant performance gains over the consensus-based protocols. At a high level, these implementations replace consensus with (Byzantine) reliable broadcast [6], where a designated sender broadcasts a message so that no two correct processes deliver different messages (consistency), either all correct processes deliver a message or none does (totality), and if the sender is correct, all correct processes eventually deliver the broadcast message (validity).
Starting from the classical Bracha’s algorithm [7], Byzantine reliable broadcast algorithms [32, 34, 41] are known to scale poorly, as they typically have per-process communication complexity, where is the number of processes. This can be explained by their use of quorums [33, 42], i.e., sets of processes that are large enough (typically more than ) to ensure that any two such sets have at least one correct process in common. By relaxing the quorum-intersection requirement to only hold with high probability, the per-process communication complexity can be reduced to [35]. Guerraoui et al. [22] describe a probabilistic broadcast protocol that replaces quorums with randomly selected samples. This gossip-based broadcast consists of three phases, where each phase involves communication with a small (of the order ) randomly selected set of processes (a sample), which would give per-process communication cost. It can be shown that assuming a static adversary and an underlying uniform random sampling mechanism, the protocol can be tuned to guarantee almost negligible probabilities of failing the properties of reliable broadcast.
In this paper, we take a step forward by introducing a probabilistic reliable-broadcast protocol that tolerates an adaptive adversary, incurs an even lower communication overhead. Our protocol replaces samples with witness sets: every broadcast message is assigned with a dynamically selected small subset of processes that we call the witnesses of this message.
The witnesses are approached by the receivers to check that no other message has been issued by the same source and with the same sequence number. The processes select the witness set by applying a novel stream-local hash function to the current random sample. The random sample is a set of random numbers that the participants periodically generate and propagate throughout the system, and we ensure that “close” random samples induce similar witness sets. To counter a dynamic adversary manipulating the random samples and, thus, the witness sets in its favor, the random numbers are generated and committed in advance using a secret-sharing mechanism [39, 15]. The committed random numbers are revealed only after a certain number of broadcast instances, which is a parameter of the security properties of our protocol. As a result, the protocol is resistant against a slowly adaptive adversary. We model the evolution of the random samples as an ergodic Markov process: the time for the adversary to corrupt a process is assumed to be much longer than the mixing time of a carefully defined random walk in a multi-dimensional space. Intuitively, even if the adversary introduces a biased value instead of a random one, by the time the value is used, the distribution of the random sample is close to uniform and the benefits of the bias are lost.
We argue that the desired safety properties of Byzantine reliable broadcast can be achieved under small, , witness sets. When the communication is close to synchronous, which we take as a common case in our performance analysis, the divergence between the random samples evaluated by different processes and, thus, the witness sets for the given broadcast event, is likely to be very small. Thus, in the common case, our broadcast protocol maintains communication complexity, or per node, similar to sample-based gossiping [22], by additionally exhibiting constant latency.
The current “amount of synchrony” may negatively affect the liveness properties of our algorithm: the less synchronous the network becomes, the less accurate may the witness set evaluation become and, thus, the longer it takes to deliver a broadcast message. Notice that we do not need the processes to perfectly agree on the witnesses for any particular event: thanks to the use of stream-local hashing, a sufficient overlap is enough. To compensate for liveness degradation when the network synchrony weakens, i.e., the variance of effective message delays increases, we propose a recovery mechanism relying on the classical (quorum-based) reliable broadcast [6].
Our comparative performance analysis shows that throughput and latency of our protocol scale better than earlier protocols [6, 22], which makes its use potentially attractive in large-scale decentralized services [14, 4].
The rest of the paper is organized as follows. In Section 2, we describe the system model and in Section 3, we formulate the problem of probabilistic reliable broadcast and present our baseline witness-based protocol. In Section 4, we extend the baseline protocol to implement probabilistic broadcast. In Section 5, we analyze the security properties of our protocol and we present the outcomes of our performance analysis. In Section 6, we sketch a recovery mechanism that can be used to complement our baseline witness-based protocol. We conclude the paper in Section 7 with a discussion of related work. Proofs and technical details of the secret-sharing and recovery schemes are provided in the appendix.
2 System Model
A system is composed of a set of processes. Every process is assigned an algorithm (we also say protocol). Up to processes can be corrupted by the adversary. Corrupted processes might deviate arbitrarily from the assigned algorithm, in particular they might prematurely stop sending messages. A corrupted process is also called faulty (or Byzantine), otherwise we call it correct.
We assume a slow adaptive adversary: it decides which processes to corrupt depending on the execution, but there is a delay before the corruption takes effect. When selecting a process to corrupt at a given moment in the execution, the adversary can have access to ’s private information and control its steps only after every other correct process has terminated protocol instances, where is a predefined parameter.111In this paper we consider broadcast protocols (Section 3), so that an instance terminates for a process when it delivers a message. In addition, we assume that previously sent messages by cannot be altered or suppressed.
Every pair of processes communicate through authenticated reliable channels: messages are signed and the channel does not create, drop or duplicate messages. We assume that the time required to convey a message from one correct process to another is negligible compared to the time required for any individual correct process to terminate in instances.222The time to process instances can be in range of hours or days (see Section 5).
We use hash functions and asymmetric cryptographic tools: a public-key/private-key pair is associated with every process in [9]. The private key is known only to its owner and can be used to produce a signature for a message or statement, while the public key is known by all processes and is used to verify that a signature is valid. We assume that the adversary is computationally bounded: no process can forge the signature for a statement of a benign process. In addition, signatures satisfy the uniqueness property: for each public-key and a message , there is only one valid signature for relative to . The hash functions are modeled as a random oracle.
3 Probabilistic Reliable Broadcast
The Byzantine reliable broadcast abstraction [6, 9] exports operation , where belongs to a message set , and produces callback , . Each instance of reliable broadcast has a dedicated source, i.e., a single process broadcasting a message. In any execution with a set of Byzantine processes, the abstraction guarantees the following properties:
-
If the source is correct and invokes , then every correct process eventually delivers .
-
If and are correct and deliver and respectively, then .
-
If a correct process delivers a message, then eventually every correct process delivers a message.
-
If the source is correct and a correct process delivers , then previously broadcast .
In a long-lived execution of reliable broadcast, each process maintains a history of delivered messages and can invoke an unbounded number of times, but correct processes behave sequentially, i.e., wait for the output of a invocation before starting a new one. The abstraction can easily be implemented using an instance of reliable broadcast for each message, by attaching to it the source’s and a sequence number [6].
Instances of reliable broadcast can also be probabilistic [22], in which case there is a probability for each instance that the protocol does not satisfy some property (e.g. violates ). If one uses instances of probabilistic reliable broadcast for building a long-lived abstraction, the probability of failure converges to 1 in an infinite run (assuming processes broadcast messages an infinite number of times). We therefore consider the expected failure time of a long-lived probabilistic reliable broadcast (L-PRB) as the expected number of broadcast instances by which the protocol fails.
Definition 1 (Long-lived Probabilistic Reliable Broadcast).
An -Secure L-PRB has an expected time of failure (average number of instances until some property is violated) of at least instances.
3.1 Protocol Description
We first present an algorithm that implements Byzantine reliable broadcast using a distributed witness oracle . Intuitively, every process can query its local oracle module to map each event (a pair of a process identifier and a sequence number) to a set of processes that should validate the -th event of process . The oracle module exports two operations: , which returns a set of processes potentially acting as witnesses for the pair , and , that returns a set of witnesses particular to , referred to as ’s witness set.
We now describe an algorithm that uses to implement Byzantine reliable broadcast, a variation of Bracha’s algorithm [6] that instead of making every process gather messages from aquorum, we delegate this task to the witnesses.333A quorum is a subset of processes that can act on behalf of the system. A Byzantine quorum [33] is composed of processes, for a system with processes in which are Byzantine. Each process waits for replies from a threshold of its witnesses in to advance to the next protocol phase. However witness sets can differ, so messages are sent to to guarantee that every process acting as a witness can gather enough messages from the network. The protocol maintains correctness as long as for each correct process , there are at least correct witnesses and at most faulty witnesses in . Moreover, should include the witness set of every other correct process. In Section 4, we describe a method to select and a construction of that satisfies these with very large expected failure time.
The pseudo-code for a single instance of Byzantine reliable broadcast (parameterized with a pair ) is presented in Algorithm 1. Here we assume the set of participants () to be static: the set of processes remains the same throughout the execution. denotes the number of faulty nodes tolerated in (see 3.2).
At the source , a single instance of Witness-Based Broadcast (WBB) parameterized with is initialized when invokes , where is attached to . On the remaining processes, the initialization happens when first receiving a protocol message associated to . Upon initialization, processes sample and from , which are fixed for the rest of the instance.
Each action is tagged with , or , where is an action performed by the source, is performed by a process acting as witness and by every process. A process can take multiple roles in the same instance and always takes actions tagged with , but performs each action only once per instance. Moreover, (correct) acts as witness iff . We assume every broadcast to include the source’s signature so that every process can verify its authenticity.
Algorithm 2 uses WBB as a building block to validate and deliver messages. Clearly, if the validation procedure satisfies the reliable broadcast properties, then Algorithm 2 implements long-lived reliable broadcast.
3.2 Protocol Correctness
Consider an instance of WBB where and for every correct:
-
1.
has at least correct witnesses and at most faulty witnesses;
-
2.
for every correct, .
Then the following theorem holds:
Theorem 2.
Algorithm 1 implements Byzantine reliable broadcast.
Proof.
: Let be a correct process and assume that a correct source is broadcasting . Since for every correct (assumption 2), all correct witnesses in receive echoes and reply with . From assumption 1, has at least correct witnesses that reply to , which in turn sends its own back. The validation phase follows similarly and delivers after receiving messages from witnesses.
: is signed by the source and processes verify its authenticity, so a message broadcast is only delivered if the authentication is successful. By assumption, the adversary cannot crack the private key of a correct process and forge signatures.
: Because has at most faulty processes, is guaranteed to receive a message from at least one correct process in lines 10 and 14 before proceeding to a new phase. A correct witness has to receive in order to send . Since , every pair of subsets of processes intersects in at least one correct process, thus two correct witnesses cannot send for distinct messages (this would require a correct process to send for distinct messages).
If a correct process delivers , then at least processes sent to a correct witness, thus, at least correct processes sent to every witness. Consequently from assumption 2, correct witnesses receive readies for a message and are able to trigger line 9 to send . In order to send without hearing from processes, witnesses gather echoes from processes. Similarly to the part of the proof, two correct witnesses cannot then send for distinct messages. Finally, holds from the fact that every has at least correct witnesses, which send to all processes.
For a single broadcast instance, the message complexity depends on the size of (the set of potential witnesses). Let and the expected size of , the message complexity is . We assume that parameters for the witness-oracle (Section 4) are chosen such that is , resulting in a complexity of . Moreover, WBB takes message delays to terminate with a correct source.
4 Witness Oracle
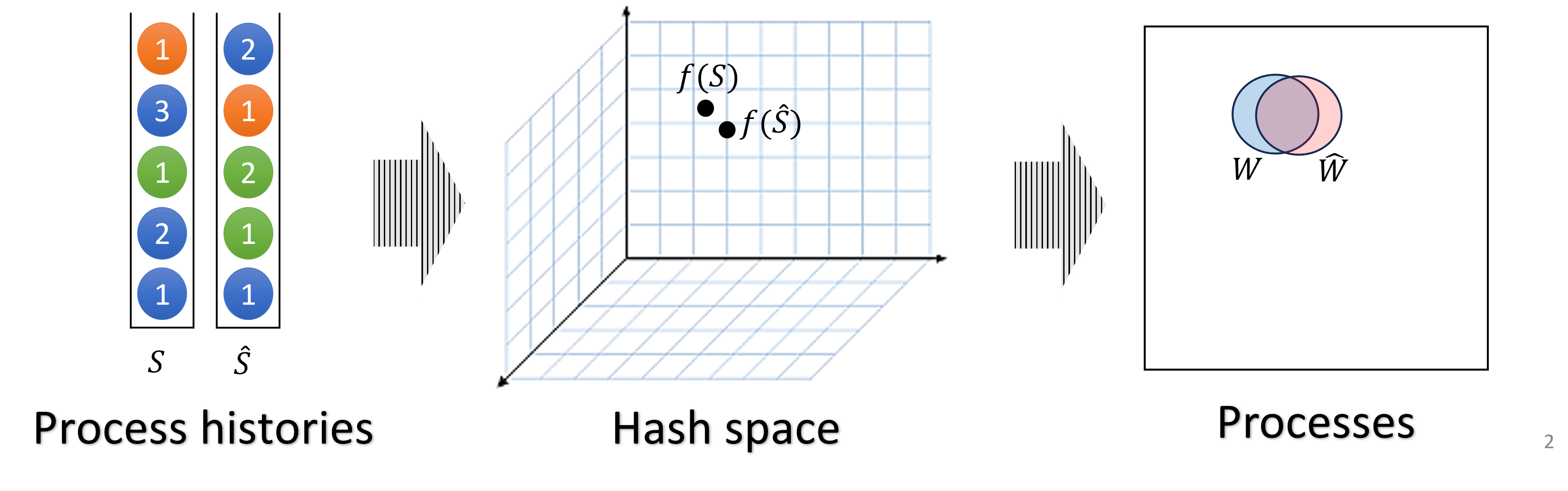
The witness oracle is responsible for selecting a set of witnesses for each broadcast message. This selection should be unpredictable so that it is known only with close proximity to the time of receiving the broadcast message. We implement this service locally on each node and require that for every broadcast message and for any pair of nodes, the locally selected witness sets will be similar.
In order to provide unpredictable outputs, each node uses the hash of a history of random numbers that are jointly delivered with messages. The witness set used in a particular broadcast instance is defined according to the current history, and remains the same (for that instance) after the first oracle call.
Let and be the outputs for and respectively at the moment ’s history has elements. The witness oracle construction satisfies:
-
(Witness Inclusion) For any pair of correct nodes and , and instance :
-
(Unpredictability) Let be the history of correct process and the average witness set size. Then for a given , there exists such that, for any process and :
Witness Inclusion ensures that correct processes use close witness sets in the same instance. Unpredictability hinders processes from accurately predicting witness sets: based on ’s history at any point in the execution, it is impossible to precisely determine whether any process will be selected as a witness after instances.
To support a high rate of broadcast messages, nodes do not wait or try to establish the same histories before hashing. Instead, we use a novel locality sensitive hashing scheme to ensure that small differences in histories will result in small differences in the selected witness set, as illustrated in Figure 1.
The history of random numbers can be regarded as a set. However, existing locality sensitive hashing algorithms for sets (such as those based on MinHash [8]) are less sensitive to small differences with bigger sets, which does not fit well the case of histories that are expected to grow indefinitely. Note that hashing just a sliding window within histories may result with distinct nodes having different hash values even if their histories are the same, due to differences in the order that values can be added.
Another disadvantage of existing locality sensitive hashing algorithms is their vulnerability to messages crafted to manipulate the hash result. For example in MinHash based algorithms, adding an item with extremely small hash value will most likely keep the hash of the entire set constant for a long time regardless of insertions of new items. In our case, when using history hash for witness selection, it could allow the adversary to make the witness selection predictable.
In short, let be a stream local function that can hash a set of binary strings into a vector in -dimensional torus. We require to satisfy:
-
(Locality) Let . There exists and such that:
For some pre-defined distance measure in .
Next, we show a construction of a safe stream local hashing for histories (), a hashing scheme that guarantees high degree of unpredictability and also similar outputs for similar histories. Later we show how can be used for witness selection.
4.1 Constructing a safe stream local hashing of histories
We consider a history as a set of binary strings and we assume the existence of a family of one-way functions . For example, for , we can use where is a predefined random binary string with length at least and “” is the bit concatenation operator.
We define a family of functions , where . Each of these functions can hash a set of arbitrary binary strings into a vector in -dimensional torus and should be locality sensitive in the sense that sets with small differences should be hashed to vectors with small distance, where vector distance is defined as follows:
Our construction of functions can be described as follows: each evaluation of on a set defines a random walk in where each item in accounts for an independent random step based on the hash of . More specifically:
where and .
The distance between any two sets is not affected by shared items while each non-shared item increases or decreases the distance by at most .
Theorem 3 (Locality).
Let , then for any :
Proof.
Each element can be mapped to a single , in which it either increases or decreases by . Suppose that (so either or ). Let , then is identical to in all positions except for , where . So:
Now assume that for , and let . Assume without loss of generality that , and let . Then by assumption, for any position in :
Now let , then the inequalities above are satisfied for and at any position except maybe for , where:
Therefore: .
Theorem 3 implies that satisfies Locality with .
We consider node ids to be binary strings of length . During the execution, each node maintains a view regarding the set of active node ids and the history of delivered random numbers . In addition, a function is maintained for each node in . All nodes are initialized with the same functions as well as the one-way function , so that for each particular the id of node is used as the seed for computing , in order to make each step computed for different independent.
To select witness sets, nodes are also initialized with a distance parameter . To determine the set of witnesses , node computes and then selects all nodes for which is at distance at most from the origin.
| (1) |
Keeping a instance for each node does not add significant storage overhead, since we expect its size to be smaller than in number of bits (see Section 5.1). Moreover, the computational cost of updating should also be significantly smaller than verifying digital signatures.
4.2 Secret Sharing
Unpredictability is achieved with a secret sharing protocol, in which a random number is secretly shared by the source at the start of every instance. In the reveal phase, the number is added to a local history and it is used to compute a random step in .
We capitalize on the steady distribution of a random walk which is the uniform distribution in a torus444To guarantee uniform distribution, the diameter needs to be odd [5], we can trivially achieve this by skipping the last point (so the diameter of each dimension becomes ). (this means that as we increase the number of steps, the distribution of converges to uniform). The number of steps necessary to make the distribution of the random walk close to uniform is called the mixing time. For each new random number that is shared by a node, we delay its addition to the history by steps, where is the fraction of the throughput generated by correct sources.555One can adjust based on the broadcast rate of the nodes with smallest rate. Alternatively one can wait until the total number of additions to the history, committed by the nodes with smallest rate, has reached . This guarantees that the adversary cannot use it’s current state to issue carefully chosen numbers and make the outcome of close to any specific value.
To further prevent the adversary from biasing the outcome of , we require each number to be generated by a verifiable source of randomness. This is achieved using the signature scheme and a hash function. Consider a random string known to all nodes. To generate the random number of instance , signs and assigns to the hash of the resulting signature. The signature for is then used as proof that was correctly generated. The random string used for is the random number generated in the previous instance, and the original seed can be any agreed upon number.
4.3 Witness Oracle – Correctness
The detailed analysis for the oracle correctness can be found in Appendix B. To verify the conditions under which Witness Inclusion and Unpredictability are satisfied, we assume that:
-
The interval between the first time a correct process recovers a secret , and the last time a correct process does so is upper bounded by ;
-
correct processes reveal numbers (adding them to their local history) at the same rate ;
-
at any correct process and within any interval of time, there is a lower bound on the fraction of numbers revealed that come from correct processes.
Let and be the selection radius for and respectively (Equation 1), i.e., a node is selected as witness if is at distance at most from the origin in .
Theorem 4 (Witness Inclusion).
As long as , for any pair of correct nodes and , and instance : .
In Section 6 and Appendix D, we show how to avoid relying on the above condition by introducing a fallback protocol that ensures progress for correct processes, even in the absence of network synchrony. Now let to be the predetermined average witness set size.
Theorem 5 (Unpredictability).
Let be the history of process at a particular moment in the execution. For any process :
According to our model, it takes instances for a node corruption to take effect. In our approach we set since the same witnesses used in WBB are involved in the reveal phase instances later. The parameters , and are chosen based depend on the expected speed of adversarial corruption and the probability that the adversary can accurately predict the processes selected as witnesses. As shown in Section 5.1, this probability is negligible given a realistic adversarial corruption speed.
5 Security and Performance
The witness set selections depend on the positions of the random walks in , and there may happen that not enough good nodes or too many bad nodes arrive in the selection zone. Thus the average number of instances until some property of WBB is violated depends on the random walks properties. Next, we determine the expected failure time of the complete protocol by calculating the time it takes for the random walks to reach a position where a “bad” witness set is chosen. Note that in our approach, the probability of failure for a particular instance is dependent on previous instances, as the random walks depend on their previous state.
5.1 Expected Time of Failure
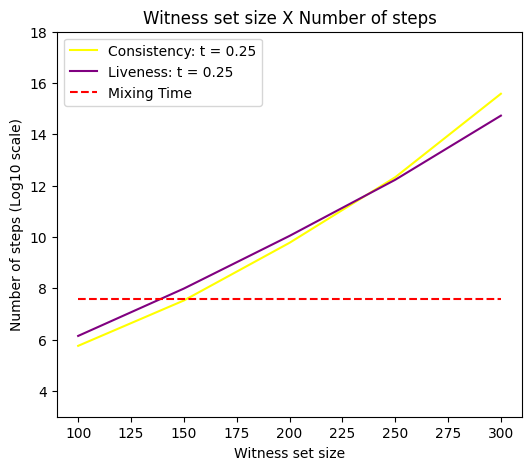
We say that the long-lived protocol fails when, in any WBB instance, a correct process selects a witness set containing at least corrupted parties (consistency failure) or fewer than correct ones (liveness failure). The adversary may attempt to corrupt processes dynamically to cause protocol failure as quickly as possible. However, as shown in Theorem 5, the probability of accurately predicting which processes to corrupt decreases with . We choose (mixing time in Figure 2) to ensure that the total variation distance between the outcome and the uniform distribution is bounded by , giving the adversary a negligible advantage in predicting witnesses.
Given that the probability distribution is close to uniform from the time a value is shared to the moment it is added to the history, we consider every step to be independent from the states. In addition, since we are in the random model for hash functions, the distribution of the values issued by malicious nodes becomes uniform for a large number of values. We therefore assume that every value added to a local history comprises a random step in .
Random walks on may randomly result in the selection of a “bad” witness set. We analyze this scenario bellow. Since the adversary cannot predict witness sets with significant advantage, we assume all adversarial nodes in the execution are corrupted from start, thereby maximizing the probability of selecting a sufficiently corrupted witness set.
We call gathering time the average number of steps until at least nodes out of are selected as witnesses, assuming that the initial distribution for each node is uniform and independent. We give a detailed discussion of the gathering time calculations in Appendix C. Intuitively, we relate the problem to the well known hitting time [18] of Markov chains, in which one calculates the first time the chain reaches a particular set of states. Let be the number of corrupted nodes in the witness selection area after steps, we consider a Markov Chain whose possible states are . The gathering time is then the average number of steps such that . We compare the numbers obtained from our analysis with simulations of random walks666We choose , based on the total number of nodes we consider for each run. in in Appendix C, the results show that our approach gives conservative777In general, our estimations are at least times smaller than the simulated values. gathering times.
The problem is the same when it comes to calculating the time until the witness set is not live. The possible states are and we calculate the average number of steps such that .
The choice of parameters for the witness oracle depends on the characteristics of the application. Selecting a bigger diameter increases the average time of failure, but also increases the mixing time, and thus the system can tolerate adversaries that take longer to corrupt nodes. We consider the example of a system with nodes, and give parameters so that the mixing time is in a practical range.888The mixing time is steps for and . If we consider a throughput of broadcast messages per second, then the system takes around 10 hours to mix. Figure 2 shows the expected time of failure and the mixing time for , and , where is the expected witness set size.
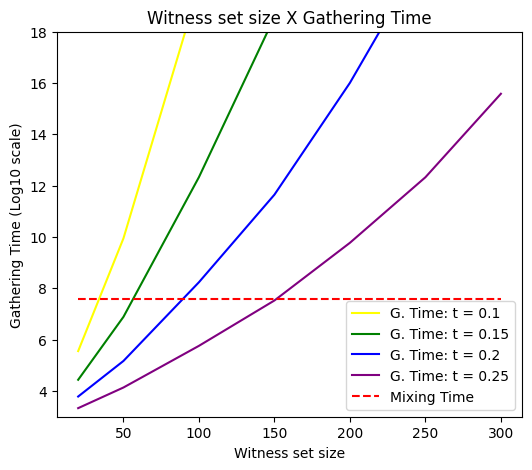
To contextualize Figure 2, we compare our protocol’s expected time of failure with two well-known probabilistic protocols: the gossip based reliable broadcast by Guerraoui et al. [22] and the Algorand protocol [20].
Guerraoui et al. [22] propose a one-shot probabilistic reliable broadcast that can be used in Algorithm 2 to implement L-PRB. In their construction, each instance has an independent probability of failure based on the sample size, with a communication complexity of , similar to WBB’s . For a system with nodes and , they require a sample size of approximately nodes to achieve an expected failure time of broadcast instances. In contrast, our protocol achieves the same expected time of failure with just witnesses.
Algorand [20] employs a randomly selected committee to solve Byzantine Agreement, where the committee size influences the failure probability. In a system with , Algorand requires a committee size of nodes to achieve an average failure time of , whereas our approach needs fewer than witnesses.
Instead of relying on a single, evolving witness set to validate all messages, multiple independent histories can be maintained, each assigned based on the issuer’s ID and sequence number. This creates parallel dynamic witness sets, where each set validates an equal portion of the workload. The hitting time for multiple random walks decreases linearly with the number of walks [1], as does the gathering time. However, since each history receives a fraction of the random numbers proportional to the number of witness sets, the total gathering time remains roughly the same. On the downside, the overall number of delivered messages required to ensure unpredictability increases proportionally with the number of witness sets.
5.2 Scalability – A Comparative Analysis
We use simulations to make a comparative analysis between Bracha’s reliable broadcast, the probabilistic reliable broadcast from [22] (hereby called scalable broadcast) and our witness-based reliable broadcast. We implemented all three protocols in Golang, the protocol and simulation codes are available at [2, 3]. For the simulation software, we used Mininet [30] to run all processes in a single machine.
We used a Linode dedicated CPU virtual machine [31] with cores, GB of RAM, running Linux 5.4.0-148-generic Kernel with Mininet version 2.3.0.dev6 and Open vSwitch [38] version 2.13.8.
We chose witness set and sample sizes so that both WBB and scalable broadcast have longevity of instances when . For the witness set size, we use and , the parameters selected for the construction are the same as in Figure 2 and parallel witness sets are used. For the sample size we use . The small sizes allow us to better compare the performance of both protocols with Bracha’s broadcast for a small number of nodes.
Since in a simulated environment we can change network parameters to modify the system’s performance, we analyze normalized values instead of absolute ones, using Bracha’s protocol as the base line.999Simulating hundreds of nodes on a single server presents significant performance challenges. In throughput tests involving a large number of nodes, we allocate reduced resources, such as limited bandwidth and CPU time, to each node. Processes are evenly distributed in a tree topology structure, with leaves on the base connected by a single parent node. The bandwidth speed is limited to Mbps per link.
In the first simulation, we observe each protocol’s performance with a high volume of transmitted messages and how it relates to the number of processes. Each process initiates broadcast of a new message once the previous one was delivered throughout all the experiment. We then measure the achievable throughput (number of delivered messages per second) and average latency for different system sizes as it’s show in Figures 3(a) and 3(b).
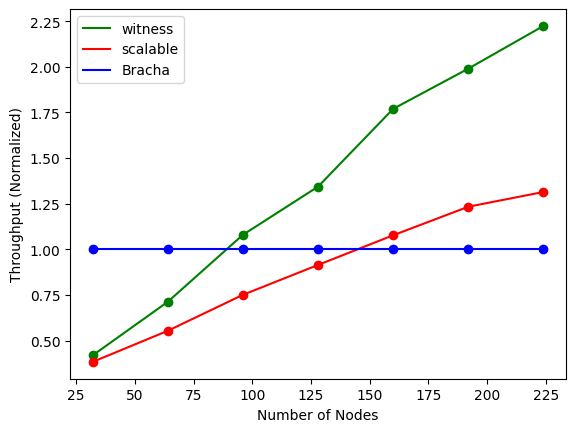
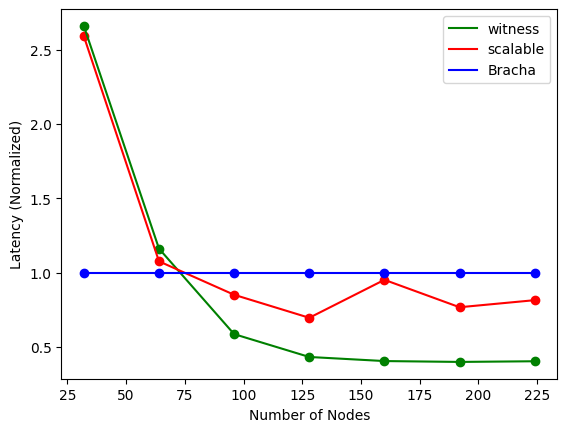
The superior asymptotic complexity of the probabilistic protocols is illustrated in Figures 3(a) and 3(b), where both WBB and scalable broadcast show improved performance relative to Bracha’s broadcast as the number of processes increases. Additionally, WBB scales consistently better than scalable broadcast, as it requires fewer processes for message validation overall.
6 Timeout and Recovery
Based on the assumptions outlined in Section 4.3, the level of synchrony may contribute to discrepancies in local histories among correct processes. A process with a significantly divergent history from the rest of the system may attempt to validate messages using a non-responsive witness set.
In this section, we present an extension of our protocol that includes a liveness fallback: if it takes too long for a process to validate a message, a timeout mechanism and a recovery protocol are triggered to ensure progress.
First, to account for time, we modify the WBB initialization block: after sampling the witnesses we call the method (Algorithm 3). This method guarantees that a is triggered after a predetermined amount of time has passed without a successful validation. Once a process receives a protocol message containing a new broadcast message , it initializes a new instance of message validation and relays to the corresponding witnesses in a NOTIFY message.
When a event is triggered, a process resorts to the recovery protocol outlined in Algorithm 7 (Appendix D). The actions on the recovery protocol should be executed by every process, and are performed only once a process triggers or delivers a message in that instance.101010Messages from the recovery protocol received by a process before satisfying any of these conditions are then stored and treated later.
The idea behind the algorithm is to “recover” any value that could have possibly been delivered in the witness validation procedure, and then execute Bracha’s Byzantine reliable broadcast [6]. We achieve this by making processes echo the last WBB they acknowledged, so that if a message is delivered by any process using WBB, no distinct message can be delivered using the recovery protocol. A detailed description of the protocol, as well as correctness proofs can be found in Appendix D.
The inclusion of the recovery protocol ensures progress if WBB is not live for a correct process, albeit with a higher communication cost as we use Bracha’s Byzantine reliable broadcast which has communication complexity of . Reduced communication using WBB is thus achieved in optimistic runs, when network asynchrony is not too severe.
7 Related Work
Solutions designed for partially synchronous models [17] are inherently optimistic: safety properties of consensus are always preserved, but liveness is only guaranteed in sufficiently long periods of synchrony, when message delays do not exceed a pre-defined bound. This kind of algorithms, also known as indulgent [21], were originally intended to solve the fundamental consensus problem, which gave rise to prominent partially synchronous state-machine replication protocols [29, 10] and, more recently, partially-synchronous blockchains.
Reliable broadcast protocols [6] provide a weaker form synchronization than consensus: instead of reaching agreement on the total order of events, reliable broadcast only establishes common order on the messages issued by any given source. This partial order turns out handy in implementing “consensus-free” asset transfer [23, 24], by far the most popular blockchain application, and resulting implementations are simpler, more efficient and more robust than consensus-based solutions [4, 14, 27].111111These implementations, however, assume that no account can be concurrently debited. i.e., no conflicting transactions must ever be issued by honest account owners [28]. To alleviate communication complexity of classical quorum-based reliable broadcast algorithms [7, 32, 34, 41], one can resort to probabilistic relaxations of its properties [35, 22]. The probabilistic broadcast protocol in [22] achieves, with a very high level of security, expected complexity and latency by replacing quorums with randomly selected samples of size. In this paper, we propose an optimistic probabilistic reliable broadcast algorithm that, in a good run, exhibits even better security (due to the “quasi-deterministic” though unpredictable choice of witnesses) and, while achieving the same communication complexity, constant expected latency. For simplicty, as a fall-back solution in a bad run, we propose the classical broadcast protocol [6]. However, one can also use the protocol of [22] here, which would give lower costs with gracefully improved security.
In the Algorand blockchain [20, 12], scalable performance is achieved by electing a small-size committee for each new block. To protect the committee members from a computationally bound adversary, one can use verifiable random functions (VRF) [36]. The participants use a hash of the last block and their private keys as inputs to the VRF that returns a proof of selection. As the proof is revealed only when a committee member proposes the next block, the protocol is protected against an adaptive adversary. The approach was later applied to asynchronous (randomized) Byzantine consensus [13], assuming trusted setup and public-key infrastructure (PKI). Similar to [20, 13], we use local knowledge for generating unpredictable process subsets of a fixed expected size. In contrast, our protocol does not assume trusted setup. We generate pseudo-randomness based on the local states, without relying on external sources (e.g., the blockchain state). However, we only tolerate a slow adversary (time to corrupt a node considerably exceeds communication delay).
References
- [1] Noga Alon, Chen Avin, Michal Koucky, Gady Kozma, Zvi Lotker, and Mark R Tuttle. Many random walks are faster than one. In Proceedings of the twentieth annual symposium on parallelism in algorithms and architectures, pages 119–128, 2008. doi:10.1145/1378533.1378557.
- [2] Veronika Anikina and João Paulo Bezerra. Mininet distributed system simulation, 2024. URL: https://github.com/testJota/mininet-distributed-system-simulation.
- [3] Veronika Anikina and João Paulo Bezerra. Stochastic checking simulation, 2024. URL: https://github.com/interestIngc/stochastic-checking-simulation.
- [4] Mathieu Baudet, George Danezis, and Alberto Sonnino. Fastpay: High-performance byzantine fault tolerant settlement. In Proceedings of the 2nd ACM Conference on Advances in Financial Technologies, pages 163–177, 2020. doi:10.1145/3419614.3423249.
- [5] Nathanaël Berestycki. Mixing times of markov chains: Techniques and examples. Alea-Latin American Journal of Probability and Mathematical Statistics, 2016.
- [6] Gabriel Bracha. Asynchronous Byzantine agreement protocols. Information and Computation, 75(2):130–143, 1987. doi:10.1016/0890-5401(87)90054-X.
- [7] Gabriel Bracha and Sam Toueg. Asynchronous Consensus and Broadcast Protocols. JACM, 32(4), 1985. doi:10.1145/4221.214134.
- [8] Andrei Z Broder. On the resemblance and containment of documents. In Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171), pages 21–29. IEEE, 1997. doi:10.1109/SEQUEN.1997.666900.
- [9] Christian Cachin, Rachid Guerraoui, and Luís Rodrigues. Introduction to reliable and secure distributed programming. Springer Science & Business Media, 2011.
- [10] Miguel Castro and Barbara Liskov. Practical byzantine fault tolerance and proactive recovery. ACM Transactions on Computer Systems (TOCS), 20(4):398–461, 2002. doi:10.1145/571637.571640.
- [11] Tushar Deepak Chandra, Vassos Hadzilacos, and Sam Toueg. The weakest failure detector for solving consensus. J. ACM, 43(4):685–722, July 1996. doi:10.1145/234533.234549.
- [12] Jing Chen and Silvio Micali. Algorand. arXiv preprint, 2016. arXiv:1607.01341.
- [13] Shir Cohen, Idit Keidar, and Alexander Spiegelman. Not a coincidence: Sub-quadratic asynchronous byzantine agreement whp. arXiv preprint, 2020. arXiv:2002.06545.
- [14] Daniel Collins, Rachid Guerraoui, Jovan Komatovic, Petr Kuznetsov, Matteo Monti, Matej Pavlovic, Yvonne Anne Pignolet, Dragos-Adrian Seredinschi, Andrei Tonkikh, and Athanasios Xygkis. Online payments by merely broadcasting messages. In 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, DSN 2020, Valencia, Spain, June 29 - July 2, 2020, pages 26–38. IEEE, 2020. doi:10.1109/DSN48063.2020.00023.
- [15] Sourav Das, Zhuolun Xiang, and Ling Ren. Asynchronous data dissemination and its applications. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, pages 2705–2721, 2021. doi:10.1145/3460120.3484808.
- [16] Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer. Consensus in the presence of partial synchrony. J. ACM, 35(2):288–323, April 1988. doi:10.1145/42282.42283.
- [17] Cynthia Dwork, Nancy A. Lynch, and Larry Stockmeyer. Consensus in the presence of partial synchrony. Journal of the ACM, 35(2):288–323, April 1988. doi:10.1145/42282.42283.
- [18] Robert Elsässer and Thomas Sauerwald. Tight bounds for the cover time of multiple random walks. In Proceedings of the 36th International Colloquium on Automata, Languages and Programming: Part I, ICALP ’09, pages 415–426, Berlin, Heidelberg, 2009. Springer-Verlag. doi:10.1007/978-3-642-02927-1_35.
- [19] Michael J. Fischer, Nancy A. Lynch, and Michael S. Paterson. Impossibility of distributed consensus with one faulty process. JACM, 32(2):374–382, April 1985. doi:10.1145/3149.214121.
- [20] Yossi Gilad, Rotem Hemo, Silvio Micali, Georgios Vlachos, and Nickolai Zeldovich. Algorand: Scaling byzantine agreements for cryptocurrencies. In Proceedings of the 26th symposium on operating systems principles, pages 51–68, 2017. doi:10.1145/3132747.3132757.
- [21] Rachid Guerraoui. Indulgent algorithms (preliminary version). In PODC, pages 289–297. ACM, 2000. doi:10.1145/343477.343630.
- [22] Rachid Guerraoui, Petr Kuznetsov, Matteo Monti, Matej Pavlovic, and Dragos-Adrian Seredinschi. Scalable byzantine reliable broadcast. In Jukka Suomela, editor, 33rd International Symposium on Distributed Computing, DISC 2019, October 14-18, 2019, Budapest, Hungary, volume 146 of LIPIcs, pages 22:1–22:16. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2019. doi:10.4230/LIPICS.DISC.2019.22.
- [23] Rachid Guerraoui, Petr Kuznetsov, Matteo Monti, Matej Pavlovic, and Dragos-Adrian Seredinschi. The consensus number of a cryptocurrency. In PODC, 2019. arXiv:1906.05574.
- [24] Saurabh Gupta. A Non-Consensus Based Decentralized Financial Transaction Processing Model with Support for Efficient Auditing. Master’s thesis, Arizona State University, USA, 2016.
- [25] Andreas Haeberlen and Petr Kuznetsov. The fault detection problem. In OPODIS, pages 99–114, 2009. doi:10.1007/978-3-642-10877-8_10.
- [26] Andreas Haeberlen, Petr Kuznetsov, and Peter Druschel. PeerReview: Practical accountability for distributed systems. In Proceedings of the 21st ACM Symposium on Operating Systems Principles (SOSP’07), October 2007.
- [27] Petr Kuznetsov, Yvonne-Anne Pignolet, Pavel Ponomarev, and Andrei Tonkikh. Permissionless and asynchronous asset transfer. In DISC 2021, volume 209 of LIPIcs, pages 28:1–28:19, 2021. doi:10.4230/LIPICS.DISC.2021.28.
- [28] Petr Kuznetsov, Yvonne-Anne Pignolet, Pavel Ponomarev, and Andrei Tonkikh. Cryptoconcurrency: (almost) consensusless asset transfer with shared accounts. CoRR, abs/2212.04895, 2022. doi:10.48550/arXiv.2212.04895.
- [29] Leslie Lamport. The Part-Time parliament. ACM Transactions on Computer Systems, 16(2):133–169, May 1998. doi:10.1145/279227.279229.
- [30] Bob Lantz, Brandon Heller, and Nick McKeown. A network in a laptop: rapid prototyping for software-defined networks. In Proceedings of the 9th ACM SIGCOMM Workshop on Hot Topics in Networks, pages 1–6, 2010.
- [31] Linode (Akamai). Plan Types - Dedicated CPU Compute Instances. https://www.linode.com/docs/products/compute/compute-instances/plans/dedicated-cpu/, 2023. [Online; accessed 10-May-2023].
- [32] Dahlia Malkhi, Michael Merritt, and Ohad Rodeh. Secure reliable multicast protocols in a WAN. In ICDCS, pages 87–94. IEEE Computer Society, 1997. doi:10.1109/ICDCS.1997.597857.
- [33] Dahlia Malkhi and Michael Reiter. Byzantine quorum systems. In Proceedings of the twenty-ninth annual ACM symposium on Theory of computing, pages 569–578. ACM, 1997. doi:10.1145/258533.258650.
- [34] Dahlia Malkhi and Michael K. Reiter. A high-throughput secure reliable multicast protocol. Journal of Computer Security, 5(2):113–128, 1997. doi:10.3233/JCS-1997-5203.
- [35] Dahlia Malkhi, Michael K Reiter, Avishai Wool, and Rebecca N Wright. Probabilistic quorum systems. Inf. Comput., 170(2):184–206, November 2001. doi:10.1006/INCO.2001.3054.
- [36] Silvio Micali, Michael Rabin, and Salil Vadhan. Verifiable random functions. In 40th annual symposium on foundations of computer science (cat. No. 99CB37039), pages 120–130. IEEE, 1999. doi:10.1109/SFFCS.1999.814584.
- [37] Satoshi Nakamoto. Bitcoin: A peer-to-peer electronic cash system, 2008.
- [38] Ben Pfaff, Justin Pettit, Teemu Koponen, Ethan J. Jackson, Andy Zhou, Jarno Rajahalme, Jesse Gross, Alex Wang, Jonathan Stringer, Pravin Shelar, Keith Amidon, and Martín Casado. The design and implementation of open vswitch. In Proceedings of the 12th USENIX Conference on Networked Systems Design and Implementation, NSDI’15, pages 117–130, USA, 2015. USENIX Association. URL: https://www.usenix.org/conference/nsdi15/technical-sessions/presentation/pfaff.
- [39] Irving S Reed and Gustave Solomon. Polynomial codes over certain finite fields. Journal of the society for industrial and applied mathematics, 8(2):300–304, 1960.
- [40] Adi Shamir. How to share a secret. Communications of the ACM, 22(11):612–613, 1979. doi:10.1145/359168.359176.
- [41] Sam Toueg. Randomized byzantine agreements. In Proceedings of the Third Annual ACM Symposium on Principles of Distributed Computing, PODC ’84, pages 163–178, New York, NY, USA, 1984. ACM. doi:10.1145/800222.806744.
- [42] Marko Vukolic. The origin of quorum systems. Bulletin of the EATCS, 101:125–147, 2010. URL: http://eatcs.org/beatcs/index.php/beatcs/article/view/183.
- [43] Gavin Wood. Ethereum: A secure decentralised generalised transaction ledger. Ethereum project yellow paper, 151(2014):1–32, 2014.
Appendix A Secret Sharing Scheme
In order to prevent the adversary from biasing the outcome of , we require each number to be generated by a verifiable source of randomness. This is achieved using the signature scheme and a hash function. Consider a random string known to all nodes, to generate the random number of instance , signs and assigns to the hash of the resulting signature. The signature for is then used as proof that was correctly generated. The random string used for is the random number generated in the previous instance, and the original seed can be any agreed upon number.
On top of that, we capitalize on the steady distribution of a random walk which is the uniform distribution in a torus121212To guarantee uniform distribution, the diameter needs to be odd [5], we can trivially achieve this by skipping the last point (so the diameter of each dimension becomes ). (this means that as we increase the number of steps, the distribution of converges to uniform). The number of steps necessary to make the distribution of the random walk close to uniform is called the mixing time. For each new random number that is broadcast by a node, we delay its addition to the history by steps, where is the fraction of the throughput generated by correct sources.131313One can adjust based on the broadcast rate of the nodes with smallest rate. Alternatively one can wait until the total number of additions to the history, committed by the nodes with smallest rate, has reached . This guarantees that the adversary cannot use it’s current state to issue carefully chosen numbers and make the outcome of close to any specific value, in other words, the adversary does not know if the delayed step will bring the value of the hash closer of farther to a desirable value.
The unpredictability is achieved with a secret sharing protocol, in which the source’s signature for is shared and only revealed after messages are delivered. The goal of the protocol is to guarantee that:
-
Correct processes agree on the revealed number.
-
No information about a number issued by a correct process is revealed until at least one correct process starts the reveal phase.
We use Shamir’s secret sharing scheme [40] abstracted as follows: the split method takes a string and generates shares such that any shares are sufficient to recover . The recover method takes a vector with shares as input and outputs a string such that, if was generated using , then . In addition, no information about is revealed with or less shares.
The pseudo-codes in Algorithms 4 and 5 describe the complete protocol. In short, the source first generates the signature for and splits in shares. Next, includes the corresponding share to each NOTIFY message. We assume that the source’s signature for the message with the share is also sent alongside it.
When delivering the message associated with , nodes store the current number of delivered messages in the history. After delivering new messages, each process starts executing the reveal phase using the same witnesses to recover the secret. Each process then sends its share to the witnesses which, after gathering enough shares, either reveal the secret or build a proof that the shares were not correctly distributed by the source. In the former case, each process verifies the revealed signature and adds the hash of to secret, defining a step in the random walk on . In the latter, when receiving such proof, a process marks the faulty source as “convicted”.
The following results assume correctness of the underlying WBB protocol.
Proposition 6.
If and correct add and to respectively, then .
Proof.
Before adding or to secret, they check whether the revealed signature is valid for the string (line 11). From the uniqueness property of the signature scheme, it follows that .
Proposition 7.
If a correct process adds to , then eventually every correct process adds to .
Proof.
After receiving from a witness, relays the message to every witness in (line 14). Because the underlying WBB is correct, for any correct. Thus, there is a common correct witness that receives from and relays it to , which adds to secret (note that since added to secret, is a valid signature).
Proposition 8.
Let be the signature a correct process shares at instance , then any other process can only reveal if at least one correct process delivers new messages after delivering .
Proof.
From Shamir’s construction, no information about is revealed unless a process gathers shares [40]. A correct process does not reveal its share unless it has delivered new messages (line 1), and a correct source does not reveal the secret . It follows that can be revealed only when at least one correct process reveals its share.
Detecting when a source incorrectly distributes shares is important to prevent the adversary from controlling when the secret is revealed. A malicious process can send malformed shares that cannot be recovered by correct processes, and later (in an arbitrary time) send with the correct secret through a corrupted witness. We employ the detection mechanism to discourage malicious sources from distributing bad shares. Processes relay the proof as soon as an incorrect share is detected, leaving little time for malicious nodes to take advantage of the incorrect distribution. Correct processes can subsequently exclude the misbehaving party from the system.
One can also guarantees the recovery of a secret (independently of adversarial action) with a stronger primitive called Verifiable Secret Sharing (VSS [15]). The asynchronous VSS protocol presented in [15] allows nodes to check their shares against a commitment that must be reliably broadcast, thus preventing a malicious source from distributing bad ones. One can replace the reliable broadcast with WBB, attaching the commitment to the broadcast message to reduce communication complexity. Because the size of the commitment can be large and the scheme computationally intensive, we use Algorithms 4 and 5 as a more efficient approach. For the remaining of the paper, we consider optimistic runs of the algorithms in which the detection mechanism successfully deter malicious participants from distributing incorrect shares.
Appendix B Witness Oracle - Correctness
The pseudo-code for the witness oracle implementation is described in Algorithm 6. Parameters and are the distances of the selection area for and respectively, while is node ’s current local history of random numbers.
We now analyse the properties of the resulting protocol composed of Algorithms 2, 6, 4 and 5. To combine Algorithm 6 with 5, we make . First, to verify the conditions under which Witness Inclusion and Unpredictability are satisfied, we assume that:
-
The interval between the first time a correct process adds to secret, and the last time a correct process does so is upper bounded by ;
-
correct processes add new numbers to secret at the same rate ;
-
at any correct process and within any interval of time, there is a lower bound on the fraction of numbers added to secret that come from correct processes.
Recall that and in Algorithm 6 are the selection radius for and respectively, i.e., a node is selected as witness if is at distance at most from the origin in .
Theorem 4 (Witness Inclusion).
As long as , for any pair of correct nodes and , and instance : .
Proof.
Let and be ’s and ’s histories at a particular time respectively. The condition is guaranteed if .
By assumption, all numbers in are already in . The only numbers that might be in are those and have added to their histories in , therefore, because they add numbers at a maximum rate of :
Moreover, from the Locality property of . Thus is satisfied whenever .
We generalize an upper bound on the mixing time of a random walk on the circle [5], by including a multiplicative factor of to calculate the mixing time of a random walk on :
Where is the upper bound on the distance between the random walk distribution and the uniform distribution , using the total variation distance:
Consider to be the predetermined average witness set size, and the corresponding distance selected to achieve .
Theorem 5 (Unpredictability).
Let be the history of process at a particular moment in the execution. For any process :
Proof.
Let , be ’s history after adding new numbers to and . Calculating the probability that is equivalent to calculate the probability that is within distance from the origin.
Any of the next numbers will reveal must be already shared by its source and the corresponding instance finished delivered by , so that can start counting the number of instances that passed before revealing the number. Any number originated from a correct process is shared regardless of the current state and thus comprise a random step in when applying , note that there are at least such numbers. On the other hand, numbers originated from malicious nodes were already shared based on information up to . Thus, we can apply these numbers in any order from , since they do not depend in later states of ’s history.
Consider the resulting hash value after applying all numbers issued by malicious nodes at once from . Now, when we apply the remaining steps coming from correct processes, it is equivalent of performing a random walk starting from , and the upper bound on the mixing time applies to this case as well.
The probability that is within distance from the origin is given by the resulting distribution after applying all remaining steps. If the distribution is uniform, then the probability is . The maximum the probability can variate is given by the TotalVariationDistance, which when replacing becomes:
Where is the number of steps in the random walk. The result follows by replacing with the minimum amount of numbers coming from correct processes: .
Appendix C Security Against Passive Attacks
In the passive attack, the adversary waits until the history hash will be such that the selected witness set for a malicious message will contain many compromised nodes. The selection of each compromised node depends on what can be considered as an independent random walk (the per node history hash) arriving to a small subspace in (within a defined distance from the origin).
The expected ratio of compromised nodes in the witness set is their ratio in the total population. We argue that the number of random walk steps (new numbers revealed and added to the local history) required to obtain a much higher ratio of compromised witnesses can be very high. One key indication that it takes long for multiple random walks to co-exist in the same region in is the linear speedup in parallel coverage time of [18].
C.1 The Gathering Time Problem
We are interested in the average occurrence time of two events: the time until the number of selected compromised nodes exceeds a given ratio of the expected witness set size, and the time until the number of selected correct nodes is smaller than said ratio. The former event is discussed first, which we call Gathering Time since the adversary waits until enough random walks gather in a defined area.
Our problem is related to Hitting Time bounds [18] that were well studied in recent years and consider the time it takes for one (or many) random walks to arrive to a specific destination point. The Gathering Time differs from the Hitting Time in two main aspects: 1) we require that the random walks will be at the destination area at the same time and 2) we do not require all random walks to arrive at the destination but instead we are interested in the first time that a subset of them, of a given size, will arrive at the destination area. Next we provide an approximation for a lower bound which we compare to simulated random walks results.
C.2 A simplified Markov Chain approach
We assume that nodes are initially mapped to points in and are selected to be witnesses if they are at distance at most from the origin in (based on ). The initial mapping of nodes is uniform and independent, also, the movement of nodes in the space can me modeled as independent random walks.
The initial probability that a node is found at distance at most is equal to the probability that in all dimensions its location is at most , i.e. . Therefore, is the initial probability that a node is selected and the expected witness set size is . We consider configurations where the witness set size is logarithmic with , i.e., .
Next, we estimate the expected time until at least out of compromised nodes will be selected, where and are the ratio of compromised nodes in the system and in the witness set respectively, i.e., and . Initially, nodes are uniformly distributed in . In one step, every node moves a single unit ( or ) in one dimension.
Let be the witness selection area in and , that is, is the complement of in . Calculating the hitting time for out of nodes to reach is an analytical and computational challenge. Suppose, for instance, that we use the transition matrix of a random walk in , depending on the size of the space, the number of states makes it implausible to solve the hitting time computationally using (even without considering the simultaneous random walks).
Instead, we represent the number of nodes inside as a Markov Chain , where are the possible states and is the number of nodes in the targeted area after steps. In order to calculate we consider, as a simplification, only the average probability (over all possible positions) that each individual node inside may leave the area in one step, as well as the average probability that each individual node inside may move to . These probabilities are assumed to be the same for every node independently of its position inside (or inside ).
Only nodes located in the “border” of with can move to in one step. Intuitively, the border of is composed of points that are one step away from a point in . To formalize this notion we use the norm- distance, which can be thought as the minimum number of steps needed to go from a point to another point .
We define the distance between a point and an area as the minimum distance from to any point of . The border of an area is comprised of all the points that are at distance from its complement .
Nodes inside that are not located in the border cannot leave the area in a single step. Thus, the average probability that a node leaves after one step (over all points of 141414As shown later, the probability that a node leaves given that it is in is the same for every point in , which is not the case for all points in .) is:
The probability of a node leaving is analogous.
Let denote the number of nodes that leave from step to step , and the number of nodes that leave . We define as the variation of the number of nodes in , thus:
The witness selection region is comprised of all the points at a distance () from the origin. We say that iff (where is the same as ). The size of the space (number of points) is , while the size of is , and thus .
A point inside that is one step away from satisfy the following condition: there is a single such that or , and for all other , . For a specific , there are points in with (same for ). Since there are dimensions, the total number of points in is . Now for any node in , a random step can change the value of a single position by or , so the probability that such node moves to after one step is .
On the other hand, in there are points that are at distance from multiple points in . A point in should satisfy: and or . The probability of moving from to depends on how many values (or ), and there can be at most values equal to . Suppose there are such , then the probability that a node in this point leaves to is .
There are distinct ways of choosing out of values to be either or , and for each choice of elements, there are ways of arranging it in a -sequence of and . Finally, there are points in which have value either or . The total number of points in is the sum over all possible :
We can now calculate the average probability that a node in moves to :
Next, we calculate each component of the transition matrix.
Let and the individual probabilities that a node leave the current area in one step. Suppose that there are nodes in and nodes in . Then,
The variation is calculated as following:
Where can range from to and can range from to . Let be the transition matrix of the Markov Chain , and the component of the row and columns, then:
We use to compute the average number of steps that starting from a particular state , the chain arrives at a state . The average hitting time is the weighted sum of all individual hitting times, where the weight for each initial state is the probability of that state in the initial distribution. To calculate the initial distribution, we assume that all nodes are distributed uniformly at random and have the same probability . Let denote the initial number of nodes inside , then:
We ran simulations for multiple random walks in and compared the hitting time of the simulations with the values obtained from the simplified analysis. For this purpose, we chose parameters so that the number of steps required for witness set corruption is small enough to allow the simulations to finish in a reasonable time.
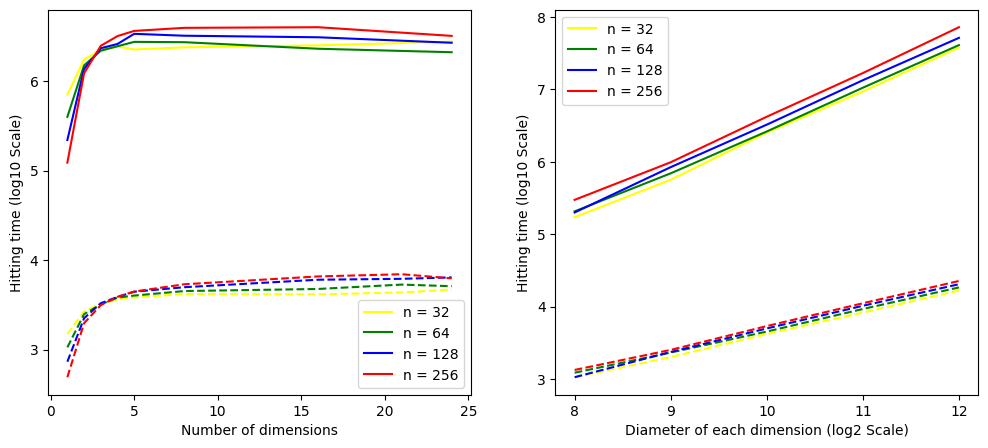
Figure 4 shows results from the simulations and from the simplified analysis. For each point in the graphs, we took the average of runs. From both graphs, we can conclude that the simplified analysis gives a conservative estimate of the hitting time.
In the counterpart problem of the Gathering Time, we want to know the average number of steps after which there are not enough correct nodes in the witness set. It can be calculated with simple modifications in the Markov chain: the possible states are now , and we use the updated to compute the average number of steps until the chain arrive at a state .
Because of history differences, the path of local random walks may slightly diverge among processes. Consider the extreme case where each local history evolves independently from each other (and thus the difference can be arbitrarily large). The speed up property of multiple random random walks guarantees that a linear speed up (on the number of walks ) of the hitting time occurs [1]. In reality, the walks are highly correlated and are apart from each other only by a factor that is much smaller than the hitting time. Thus, the speed up in the cases we consider is negligible in relation to the hitting time.
C.3 Liveness vs Consistency graph
To optimize the overall time of failure, one has to select the threshold so that it takes the same amount of steps to violate liveness and consistency. In Figure 5, we show both curves for and .151515Ideally, should be selected to optimize the failure time for each value of and . However, calculating liveness results takes considerably longer (than consistency) due to the size of matrix . Therefore, we present the values for , where the size of is smaller.
Appendix D Recovery Protocol
A process first sends to every process and includes the latest WBB message it has sent with tag . If a process that has already delivered a message receives , it replies with . When receives replies for , it knows at least one is from a correct process, and can safely deliver it. Moreover, when receiving messages, also sends a to every process (this threshold ensures that at least one correct process should propose to initiate a reliable broadcast instance).
When receives from processes, if a unique message was received so far, it then starts Bracha’s broadcast phase for . Otherwise, waits until it receives from the recovery messages to start echoing. The traditional Byzantine reliable broadcast is then executed.
For a particular instance , we assume that for every correct process , has at most faulty witnesses161616Note that these assumptions are weaker than those of 3.2. This is because the addition of the recovery protocol and a timeout compensate for the non-responsiveness of witness sets.. In addition, we assume the time to be set much smaller than the execution time of broadcast instances, such that the adversary cannot change the composition of faulty processes in witness sets before processes timeout.
Lemma 9.
If two correct processes and deliver and , then .
Proof.
There are three different scenarios according to the algorithm in which and deliver messages: both deliver in line 15 (Algorithm1), one delivers in line 15 and the other in lines 28 or 41 (Algorithm 7), or both deliver in lines 28 or 41.
In the first case, since at most witnesses are faulty in each witness set, correct processes receive messages from at least one correct witness in lines 10 and 14, which guarantees (see proof of Theorem 2).
For the second case, if delivers in line 28, it is guaranteed to receive a reply from at least a correct process . Since processes only take step in Algorithm 7 after timing out or delivering a message, it must be that delivered in line 15. From the first case, .
On the other hand, if delivers in line 41, it received . Suppose that , then processes sent (sufficient to make a correct process send ready for ). But since delivers after receiving from at least a correct witness, it is also the case that at least processes sent .
Consequently, a correct process must have sent both and . Two scenarios are possible: if sent in line 34, then it had readies for and stored (since receives recovery messages, as least one contains a ), a contradiction with the guard of line 33. If it was in line 36, then a correct process sent , also a contradiction since two correct processes sent for distinct messages and (see proof of Theorem 2).
In the third case, suppose delivers in line 28 and delivers in line41. There is a correct process that delivers in line 15 and sent a reply to , which from the second case above implies . If both deliver and in line 41, there is at least one correct process that send both and . Since correct processes do not send readies for distinct messages, .
Lemma 10.
If a correct process delivers a message, then every correct process eventually delivers a message.
Proof.
A correct process can deliver a message in three possible occasions: in line 15 (Algorithm 1), and lines 28 and 41 (Algorithm 7).
If delivers in line 15, because ’s witness set has at least one correct witness that sends to everyone, every correct process either times-out or delivers a message in line 15 (using witnesses). Moreover, from Theorem 9, no correct process delivers . At least one correct witness sent to , processes sent to , from which at least are correct.
If another process times-out, it can deliver by receiving replies from a message. Suppose does not receive enough replies, then at least correct processes do not deliver in line 15 (Algorithm 1), that is, they timeout. Consequently, every correct process receives messages and also send (even if they already delivered ). then gathers messages, and since there is at least one correct process among them that sent , echoes (if is the only gathered message, line 33).
If receives a distinct before echoing a message, it waits for messages containing , which is guaranteed to happen (since at least correct processes previously sent ). Thus, every correct process echoes , gathers echoes and sends . Any process that has not delivered a message then receives readies and deliver .
In the case where delivers in line 28, at least one correct process sent reply to and delivered in Algorithm 1, which implies the situation described above.
Now suppose that delivers in line 41, and no correct process delivers a message in Algorithm 1. received , which at least are from correct processes. Moreover, because correct processes wait for echoes (or readies) before sending , they cannot send for distinct messages and , since that would imply that a correct process sent for both messages. Therefore, every correct process is able to receive readies for and also send ready for it. then receives readies and deliver .
Lemma 11.
If a correct process broadcasts , every correct process eventually delivers .
Proof.
If any correct process delivers , from Lemma 10 every correct process delivers it. Suppose that is the source and that no process delivers before it times-out. then sends (including ) to every process, so that even if reaches no correct witnesses, correct processes still receive a protocol message and initializes the instance. Since no correct process delivers before timing-out, they also trigger and send with .
Because is correct, it sends no protocol message for . Every correct process then gathers enough messages to send and later . eventually gathers readies and deliver .
Appendix E Applications and Ramifications
In this section, we briefly overview two potential applications of our broadcast protocol: asynchronous asset transfer and a generic accountability mechanism. We also discuss open questions inspired by these applications.
E.1 Asset Transfer
The users of an asset-transfer system (or a cryptocurrency system) exchange assets via transactions. A transaction is a tuple , where and are the sender’s and receiver’s account respectively, is the transferred amount and is a sequence number. Each user maintains a local set of transactions and it adds a transaction to (we also say that commits ), when confirms that (i) all previous transactions from are committed, (ii) has not issued a conflicting transaction with the same sequence number, and (iii) based on the currently committed transactions, indeed has the assets it is about to transfer.171717Please refer to [14] for more details.
One can build such an abstraction atop (probabilistic) reliable broadcast: to issue a transaction , a user invokes . When a user receives an upcall it puts on hold until conditions (i)-(iii) above are met and then commits . Asset-transfer systems based on classical broadcast algorithms [6] exhibit significant practical advantages over the consensus-based protocols [14, 4]. One can reduce the costs even further by using our broadcast protocol. The downside is that there is a small probability of double spending. A malicious user may make different users deliver conflicting transactions and overspend its account by exploiting “weak” (not having enough correct members) witness sets or over-optimistic evaluation of communication delays in the recovery protocol. We can temporarily tolerate such an overspending and compensate it with a reconfiguration mechanism that detects and evicts misbehaving users from the system, as well as adjusting the total balance. It is appealing to explore whether such a solution would be acceptable in practice.
E.2 Accountability and beyond
In our approach probabilistic protocol, every broadcast event is validated by a set of witnesses. The validation here consists in ensuring that the source does not attempt to broadcast different messages with the same sequence number. As a result, with high probability, all correct processes observe the same sequence of messages issued by a given source.
One can generalize this solution to implement a lightweight accountability mechanism (in the vein of [26, 25]): witnesses collectively make sure that the sequence of events generated by a process corresponds to its specification. Here a process commits not only to the messages it sends, but also to the messages it receives. This way the witnesses may verify if its behavior respects the protocol the process is assigned.
Notice that one can generalize this approach even further, as the verified events do not have to be assigned to any specific process. In the extreme case, we can even think of a probabilistic state-machine replication protocol [29, 10]. What if the processes try to agree on an ever-growing sequence of events generated by all of them in a decentralized way? Every next event (say, at position ) may then be associated with a dynamically determined pseudo-random set of witnesses that try to make sure that no different event is accepted at position . Of course, we need to make sure that the probability of losing consistency and/or progress is acceptable and a probability analysis of this kind of algorithms is an appealing question for future research.