Near-Optimal Resilient Labeling Schemes

Abstract
Labeling schemes are a prevalent paradigm in various computing settings. In such schemes, an oracle is given an input graph and produces a label for each of its nodes, enabling the labels to be used for various tasks. Fundamental examples in distributed settings include distance labeling schemes, proof labeling schemes, advice schemes, and more. This paper addresses the question of what happens in a labeling scheme if some labels are erased, e.g., due to communication loss with the oracle or hardware errors. We adapt the notion of resilient proof-labeling schemes of Fischer, Oshman, Shamir [OPODIS 2021] and consider resiliency in general labeling schemes. A resilient labeling scheme consists of two parts – a transformation of any given labeling to a new one, executed by the oracle, and a distributed algorithm in which the nodes can restore their original labels given the new ones, despite some label erasures.
Our contribution is a resilient labeling scheme that can handle such erasures. Given a labeling of bits per node, it produces new labels with multiplicative and additive overheads of and , respectively. The running time of the distributed reconstruction algorithm is in the Congest model.
This improves upon what can be deduced from the work of Bick, Kol, and Oshman [SODA 2022], for non-constant values of . It is not hard to show that the running time of our distributed algorithm is optimal, making our construction near-optimal, up to the additive overhead in the label size.
Keywords and phrases:
Labeling schemes, ErasuresFunding:
Keren Censor-Hillel: The research is supported in part by the Israel Science Foundation (grant 529/23).Copyright and License:
2012 ACM Subject Classification:
Theory of computation Distributed algorithms ; Mathematics of computing Graph algorithmsAcknowledgements:
We thank Alkida Balliu and Dennis Olivetti for useful discussions about the state of the art for computing ruling sets.Funding:
This research is supported in part by the Israel Science Foundation (grant 529/23).Editors:
Silvia Bonomi, Letterio Galletta, Etienne Rivière, and Valerio SchiavoniSeries and Publisher:
1 Introduction
Assigning labels to nodes of a graph is a part of many fundamental computing paradigms. In distributed computing, cornerstone examples include distance and connectivity labeling schemes, as well as labeling schemes for nearest common ancestor [38, 41, 21, 22, 5, 1, 32, 30, 27, 39, 28, 9, 23, 2], proof labeling schemes and distributed proofs [31, 15, 35, 13, 11, 25, 26, 34, 33, 10, 8], advice schemes [17, 19, 18, 20], and more, where the above are only samples of the extensive literature on these topics. The common theme in all of the above is that an oracle assigns labels to nodes in a graph, which are then used by the nodes in a distributed algorithm. Since distributed networks are prone to various types of failures, Fischer, Oshman and Shamir [16] posed the natural question of how to cope with nodes whose labels have been erased and defined the notion of resilient proof labeling schemes.
We will use the following definition, which applies to a labeling scheme for any purpose but captures the same essence. A resilient labeling scheme consists of two parts. The first part is an oracle transformation of an input labeling into an output labeling , where . The second part is a distributed 111In the model, nodes of a graph communicate in synchronous rounds by exchanging -bit messages along the edges of the graph. algorithm, in which each node receives as its input, except for at most nodes where is erased, and each node must recover . The parameters of interest are (i) the number of allowed label erasures, (ii) the multiplicative overhead and the additive overhead in the label sizes, and (iii) the round complexity of the distributed algorithm.
The aforementioned work of Fischer et al. [16] provides a resilient labeling scheme for the case of uniform labels, i.e., when the labels of all nodes are the same. For a general case, the work by Bick, Kol, and Oshman [7] implies a labeling scheme that is resilient to failures, with a constant multiplicative overhead in the label size, within rounds. In this paper, we ask how far we can reduce the overhead costs in the label size and the round complexity of the distributed algorithm.
Question.
What are the costs of resilient labeling schemes?
When is constant, the work of Bick et al. [7] achieves constant overheads in the label size and algorithm complexity. We show that for larger values of , one can do better. The following states our contribution.
Theorem 1.
There exists a resilient labeling scheme that tolerates label erasures, has and multiplicative and additive overheads to the size of the labels, respectively, and whose distributed algorithm for recovering the original labels has a complexity of at most rounds.
Notice that is a straightforward lower bound for the complexity of such a distributed algorithm. To see this, suppose the network is a path. If the labels of consecutive nodes along the path get erased, then for the middle node to obtain any information about its label, it must receive information from some node whose label is not erased. A message from such a node can only reach after rounds. Further, this example shows that is also a lower bound for the number of rounds, due to an information-theoretic argument: the nodes on the subpath of consisting of its middle nodes must obtain bits of information. This number of bits must pass over the two single edges that connect this subpath to the rest of . Since each of the two edges can carry at most bits, we get that rounds are required. This implies that our scheme is nearly optimal, leaving only the additive overhead in the size of the label as an open question.
1.1 Technical Overview
To use a labeling scheme despite erasures, it must be strengthened by backing up information in case it is lost. Erasure-correcting codes are designed for this purpose, but they apply in a different setting – the entire codeword is available to the computing device, except for some bounded number of erasures. Yet, to handle label erasures, we need to encode the information and split the codeword among several nodes. Thus, when labels in a labeling scheme are erased, restoring them requires faulty nodes to obtain information from other nodes. This means that the oracle that assigns labels must encode its original labels into new, longer ones, and the nodes must communicate to restore their possibly erased labels.
Partitioning.
By the above discussion on using error-correction codes, it is clear that if we partition the nodes of the graph into groups of size , we can encode the labels within each such subgraph, as follows. By ensuring that each group forms a connected subgraph, the nodes can quickly collect all non-erased labels within a group in rounds, and thus decode and reconstruct all original labels.
When is large, simple methods can construct such a partition with negligible complexity overhead compared to . However, when is small, such overheads become significant. While this motivation is clear for the complexity of the distributed algorithm, it also applies to the overhead in the label size: much work is invested in providing labels of small size, e.g., the MST advice construction of Fraigniaud, Korman, and Lebhar [19].
The caveat is that if is small, there may not exist a distributed algorithm for such a partitioning that completes within rounds. To see why, consider a simple reduction from -coloring a ring, which is known to have a lower bound of by Linial [36]. Given a partition into groups (paths) of size at least , we can color each group node-by-node in parallel, except for its two endpoints. This takes at most rounds, as this is the size of each group. In a constant number of additional rounds, we can in parallel stitch all groups by coloring every pair of adjacent endpoints in a manner consistent with their other two neighbors, which are already colored. Thus, an -round algorithm for obtaining such a partition contradicts the lower bound for small values of .
We stress that it is essential that the partition obtained by such a partitioning algorithm is exactly the same one used by the oracle for encoding. In particular, this rules out randomized partitioning algorithms or algorithms whose obtained partition depends on the identity of nodes with label erasures.
Our approach to address this issue is to have the oracle include partitioning information in the new labeling . This way, even if rounds are insufficient to construct the partition from scratch, the nodes can still reconstruct the partition using the labels within rounds, despite any label erasures. A straightforward method would be to include all the node IDs of a group in each label. However, this would increase the size of the new labeling to at least , which for small values of is an overhead we aim to avoid. Thus, we need a way to hint at the partition without explicitly listing it.
Ruling sets.
To this end, we employ ruling sets. An -ruling set is a set such that the distance between every two nodes in is at least , and every node is within distance at most to the set . Given a ruling set with values of that are , we prove that rounds are sufficient for obtaining a good partition.
Interestingly, the properties of the partition we obtain are slightly weaker but still sufficient for our needs (and still rule out an -round algorithm for constructing them from scratch, by a similar reduction from -coloring a ring). The partition we arrive at is a partition into groups of nodes, where each group may not be connected but has low-congestion shortcuts of diameter and congestion . This will allow us to collect all labels within a group in rounds.
More concretely, we aim to construct a -ruling set , for some parameter . For intuition, assume . We create groups by constructing a BFS tree rooted at each node , capped at a distance of (with ties broken according to the smaller root ID). We then communicate only over tree edges to divide the nodes of into groups. We choose as a lower bound for the distance between two nodes in , ensuring that each root has at least nodes in its tree. These nodes are within distance from and cannot be within that distance from any other node in the ruling set due to our choice of . Additionally, to ensure that the round complexity does not exceed , we need to bound the diameter of each tree. Any would suffice. However, as we will argue, computing the ruling set in the distributed algorithm of our resilient labeling scheme is too expensive. Thus, the oracle must provide information in its new labels to help nodes reconstruct the ruling set . We choose so that a node at distance from a vertex can determine it must be in even if its label is erased.
As promised, we note that due to the lower bound of Balliu, Brandt, Kuhn, and Olivetti [4], no distributed algorithm can compute even the simpler task of a -ruling set in fewer than rounds. Thus, in an algorithm that takes rounds to construct a ruling set with , must be at least . This leaves the range as an intriguing area. We emphasize that such label sizes are addressed by substantial research on labeling schemes, e.g.: Korman, Kutten, and Peleg [35] assert that for every value of , there exists a proof-labeling scheme with this label length. Baruch, Fraigniaud, and Patt-Shamir [6] prove that a proof-labeling scheme of a given length can be converted into a randomized version with logarithmic length. Patt-Shamir and Perry [40] provide additional proof-labeling schemes with small non-constant labels, e.g., they prove the existence of a proof-labeling scheme for the -maximum flow problem with a label size of .222To our knowledge, the fastest deterministic construction in takes rounds, due to Faour, Ghaffari, Grunau, Kuhn, and Václav [12]. Therefore, the actual complexity may be even larger, which would further widen the range of in which our construction outperforms other methods.
The existence of this lower bound could be overcome by adding a single bit to each node’s new label to indicate whether the node is in the ruling set. However, another significant obstacle is that the nodes need to reconstruct the ruling set given erasures. This turns out to be a major issue, as follows.
Suppose we have a path , with two nodes connected to , and the rest of the graph is connected through . Suppose a -ruling set contains and one of or , and that . If the labels of and both get erased, then the node cannot determine whether it should be part of the tree or not. Its distance from and is , but the ID comparisons for and yield different results: if , then should join , but if , then should join . Notice that all nodes with non-erased labels have the same distance to as to , making it impossible to distinguish between the two possibilities.
This seems to bring us to a dead-end, as the simple workaround of providing each node with the identity of its closest node in the ruling set is too costly. It would require adding bits to the new labeling , which we wish to avoid.
Greedy ruling sets.
Our main technical contribution overcomes this challenge by demonstrating that a greedy ruling set does allow the nodes to recover it given label erasures. Such a ruling set is constructed by iterating over the nodes in increasing order of IDs. When a node is reached, it is added to the ruling set, and all nodes within distance from are excluded from the ruling set and ignored in later iterations. Intuitively, in our above example, this ensures that contains and not . Thus, when their labels are erased, the nodes can deduce that should be in because it has a smaller ID.
While this approach solves the previous example, it is still insufficient. Suppose there is a sequence of nodes with decreasing IDs whose labels get erased and are not covered by any other node in (a node is covered by a node in if their distance is at most ). Assume that the distance between every two consecutive nodes in the sequence is . This means that each node knows it needs to be in the ruling set if and only if is not, essentially unveiling the decisions of the greedy algorithm. However, this implies that needs to receive information about , which may be at distance of , implying more rounds than our target running time.
To cope with the latter example, the oracle will provide each node with its distance from . This incurs an additive bits in the label size. This information is useful for deciding, for some of the nodes with erased labels, whether they are in or not and, in particular, it breaks the long chain of the latter example. Yet, notice that in the former example, this information does not help us, since all nodes apart from and have the same distance to as to . The reason this helps in one example but not in the other is as follows. For any two nodes and with erased labels that need to decide which of them is in , as long as we have at least additional nodes with a different distance from and , we can easily choose between and , because in total there can be at most label erasures, so one of these reveals which node needs to be chosen.
Thus, to reconstruct a greedy -ruling set using the above information in the non-erased labels, the nodes do the following. First, a node that sees a non-erased label in within distance from it can deduce that it is not in . Second, a node for which all labels within distance are not erased and are not in can deduce that it is in . For a remaining node with an erased label, the distance from of the non-erased labels in its neighborhood helps in deciding whether is in or not: if it has a node within this distance whose distance from differs from its distance from , then is not in . At this point in the reconstruction algorithm, the only remaining case is a node which is not known to be covered by nodes in at this stage and has a non-empty set of nodes within distance from it whose labels are erased. We show that such nodes cannot create distant node sequences as in the latter example, which allows to simply check if it has the smallest ID in , indicating whether it should be in .
Formally, we refer to such nodes as alternative nodes, defined as follows. Let be the distance between nodes and , and let be the set of nodes at distance at most from . For a node , a node is called an alternative node if and there are at most nodes with . We emphasize that proving that the only remaining case of alternative nodes is technical and non-trivial.
Given any , we prove that providing each node with a single-bit indication of whether it is in the greedy -ruling set and an additional bits holding its distance from is sufficient for the nodes to reconstruct in rounds, despite erasures. Due to the codes we choose, we will need to be slightly larger than . However, it is sufficient to choose , so to reconstruct the greedy ruling set, the label size needs an additive overhead of and the number of rounds remains .
Wrap-up.
We can now describe our resilient labeling scheme in full.
In Section 2, we use a greedy ruling set with to construct groups and apply an error-correcting code to the labels of their nodes. This provides the entire algorithm of the oracle for transforming an -labeling into an -labeling , such that has a constant multiplicative overhead for coding and an additive overhead of for restoring the greedy -ruling set.
In Section 3, we provide a distributed algorithm for restoring the greedy -ruling set given the labeling despite label erasures, within rounds. In Section 4, the nodes partition themselves into the same groups as the oracle, within rounds. Finally, Section 5 presents our complete resilient labeling scheme, which requires an additional number of rounds for communicating the non-erased labels within each group and decode to obtain the original labeling .
1.2 Preliminaries
Throughout the paper, let be the network graph, which without loss of generality is considered to be connected. Let denote the number of nodes in . After labels are assigned to nodes by the oracle, there is a parameter of the number of erasures of labels that may occur. For each node , we denote by the unique identifier of .
We denote by the distance between two nodes and , and by some shortest path between them. The ball of radius centered at a node consists of all nodes within distance from and is denoted by .
Throughout the paper, we use to refer to the concatenation of two strings and .
1.3 Related Work
As mentioned earlier, the work of Bick, Kol, and Oshman [7] implicitly suggests a resilient labeling scheme with an multiplicative overhead to the label size in rounds. This is achieved by constructing a so-called -helper assignment, which assigns helper nodes to each node in the graph, with paths of length at most from each to all of its helper nodes, such that each edge belongs to at most paths, and a node is assigned as a helper node to at most nodes . The paper computes a -helper assignment in rounds, using messages of bits. Plugging in gives the aforementioned resilient labeling scheme. For , the parameters we obtain improve upon the above.
Ostrovsky, Perry, and Rosenbaum [37] introduced -proof labeling schemes, which generalize the classic definition by allowing rounds for verification, and study the tradeoff between and the label size. This line of work was followed up by Feuilloley, Fraigniaud, Horvonen, Paz, and Perry [15], and Fischer, Oshman, and Shamir [16]. All of these papers provide constructions of groups of nodes that allow sharing label information to reduce the label size in this context. However, our construction is necessary for handling: (i) general graphs, (ii) in the model, (iii) with arbitrary labels, and (iv) while achieving our goal complexity. It is likely that our algorithm can be applied to this task as well. Error-correcting codes have already been embedded in the aforementioned approaches of Bick et al. [7] and Fischer et al. [16], and we do not consider their usage a novelty of our result.
Note that Feuilloley and Fraigniaud [14] design error-sensitive proof-labeling schemes, whose name may seem to hint at a similar task, but are unrelated to our work: these are proof-labeling schemes where a proof that is far from being correct needs to be detected by many nodes.
2 Assigning Labels
To allow the nodes in the distributed algorithm to decode their original labels despite label erasures, we employ an error-correcting code in our resilient labeling scheme. Known codes can correct a certain number of errors at the cost of only a constant overhead in the number of bits. Therefore, we can split the nodes into groups of size and encode the labels within each group. We include in the new labels information about the group partitioning to allow the distributed algorithm to quickly reconstruct the same groups. This information comes in the form of a ruling set, on which we base the group partitioning. To ensure that this reconstruction can be done despite label erasures, we ensure that the oracle uses a greedy ruling set. We present the oracle’s algorithm and then prove its guarantees in Theorem 3.
Overview.
In Algorithm 1, the oracle first constructs a greedy -ruling set . For every node , let be a single bit indicating whether , and let be an -bit value which is the distance between and .
The oracle then partitions the nodes into groups of size . To later allow the distributed algorithm to reconstruct the same groups, the oracle uses the same algorithm the nodes will later use, i.e., Algorithm 3. However, for the description in this section, any partitioning with the same guarantees would give the desired result in Theorem 3 below.
Finally, the oracle applies an error-correcting code to each index of the labels of all nodes in each group. The new label it assigns to each node is a concatenation of its and values, along with the encoded label.
Choice of code.
Different codes result in different overheads of compared to . A simple repetition code takes the string of length and repeats it for blocks to create the resulting codeword , which is trivially decodable given any blocks erasures. Splitting back to pieces implies that equals for every node in the group. Taking , this results in . Since the group size is always , we get a multiplicative overhead of and an additive overhead of . To reduce the multiplicative overhead to , we use a code with better parameters. Formally, a binary code maps strings of bits into strings of bits called codewords. The ratio is the code’s rate. The relative distance, , ensures the Hamming distance (number of indices where the strings differ) between any two codewords is at most . Such a code can correct erasures.
Lemma 2 (Justesen Codes [29], phrasing adopted from [3]).
For any given rate and for any , there exists a binary code with such that the code has rate and relative distance , where is the binary entropy function. Encoding and decoding can be done in polynomial time.
Given the bound on the number of label erasures, we need to choose a value of to work with. Then, given a group of size such that , we need to choose values for and that determine the code . We set these parameters as follows. We let , and for every such we choose . To choose , notice that Lemma 2 gives that for any , the number of bits we can encode is . We choose the smallest such that is at least .
The next theorem proves that the overhead for the number of bits held by each node per coded bit is constant and that, given the coded blocks,it is possible to decode the original string of bits if up to blocks are erased. The proof is presented in Appendix A.
Theorem 3.
Let and let . Let be the sequence of nodes in a group of size , such that , ordered by increasing IDs. Let be a string obtained by concatenating a single bit associated with each according to their order, and let be a codeword obtained in Step 1 of Algorithm 1, by using a code from Lemma 2, with a value of that is the smallest such that . Then,
-
1.
it holds that , and
-
2.
the string is decodable given with up to erasures of blocks .
For later use by the distributed algorithm in our resilient labeling scheme, we denote by the function that takes as input a node and the values for all the nodes in (along with their IDs so that they can be ordered correctly) and produces the bit of in the string which was encoded into , by Theorem 3.
3 Restoring a Greedy Ruling Set Despite Erasures
In this section we present a distributed algorithm that restores a greedy ruling set despite label erasures. Nodes are faulty if their label are erased, and non-faulty otherwise. Each node aims to restore its value so that the set is exactly the given ruling set . Once a faulty node sets its value , it is no longer considered faulty for the remainder of the algorithm. The number of label erasures our algorithm can tolerate is denoted by , and in a setting with at most label erasures, the algorithm can be executed correctly for any value .
Theorem 4.
Let be a graph and let be a greedy -ruling set . Suppose that, apart from up to at most faulty nodes, each node is provided with a label , where if and otherwise, and . Then, there exists a deterministic algorithm at the end of which every node restores its value . The algorithm runs in rounds.
Before presenting and analyzing our algorithm for Theorem 4, we recall the definition of alternative nodes.
Definition 5 (Alternative Nodes).
For a node , a node is called an alternative node, if and there are at most nodes with . Denote by the set of alternative nodes for .
A key tool in our analysis is the proof that a greedy ruling set excludes nodes with alternative nodes having smaller ID. In Appendix A, we prove the following.
Lemma 6.
Let be a greedy -ruling set. Then, there exists no node for which there is an alternative node with .
We are now ready to prove Theorem 4. We begin by presenting the algorithm.
Overview.
In Algorithm 2, nodes restore a greedy ruling set as follows. Before the algorithm starts, each non-faulty node sets its value to the first bit of its label. At the beginning of the algorithm, non-faulty nodes in broadcast a bit “1” for rounds. Here, every node that receives a bit “1” during these rounds forwards it to all of its neighbors. Faulty nodes that receive a bit during these rounds sets , as this indicates that for some such and thus .
Next, each faulty node propagates its ID through a distance of . Faulty nodes that do not receive any other ID set , as this means no other faulty nodes are in and thus .
Now, every remaining faulty node propagate a message of the form through a distance of , where starts at 0 and is increased by 1 by each node along the way, corresponding to the length of the path. For each node , let be the smallest value received for , representing the actual distance between and .
Each node receives the message and checks if it is possible that by verifying whether . If this equality does not hold, propagates a message with through a distance of . Since , if , then . If propagates , then this is not the case, so when receives its own ID, it can conclude that it is not in and sets .
Now, we are left with faulty nodes and faulty nodes . We will prove that is an alternative node for a faulty node . Thus, every faulty node must have the lowest ID among faulty nodes in and can deduce that it is in and set . Similarly, every faulty node must have a faulty node within such that , allowing to deduce it is not in and set .
Following is the formal algorithm and proof.
Proof of Theorem 4.
To prove that the algorithm restores the set , we prove that every node holds at the end of Algorithm 2, such that . By Step 2, this holds for all non-faulty nodes, so it remains to prove it for faulty nodes. In what follows, we go over each step in the algorithm where nodes may set their output (Steps 2,2,2, and 2), and we show that any node which sets its output during that step does so correctly.
Step 2.
Step 2.
Afterwards, in Step 2, each faulty node propagates a message with its ID through a distance of . Every faulty node that does not receive any other ID during these rounds and did not receive a “1” during Step 2 sets , because this implies that there is no other faulty node in and hence it must hold that . So, it is correct that sets in Step 2.
Step 2.
Then, in Step 2, every node that is still faulty propagates a message of the form through a distance of , where starts at and is increased by before the message is propagated further. This corresponds to the length of the path that this message traverses. Every node receives the above message and checks if it is possible that by verifying whether . We denote by the value of from the message that receives. If equality does not hold, then propagates a message with through a distance of . Since , if , then for every other node such that , it holds that . Thus, , and since we have . But if propagates , then this is not the case, so . Thus, it is correct that sets in Step 2.
Step 2.
First we prove that every node that is still faulty at the beginning of this step and every node are alternative nodes. By definition of alternative nodes, we need to prove that and that and have at most nodes with .
First, since , it must be that . Second, we prove that and have at most nodes with . Assume, towards a contradiction, that there are at least nodes with . Since is still faulty in Step 2, there are at most nodes in with , because otherwise would receive a message with from such a non-faulty node during Step 2 and would set in Step 2. Therefore, there exists a node that is still faulty in Step 2. We consider two cases, obtaining a contradiction in both, and conclude that the assumption is incorrect. Thus, and have at most nodes with .
Case 1: No node exists on .
An illustration of this case is presented in Figure 1.
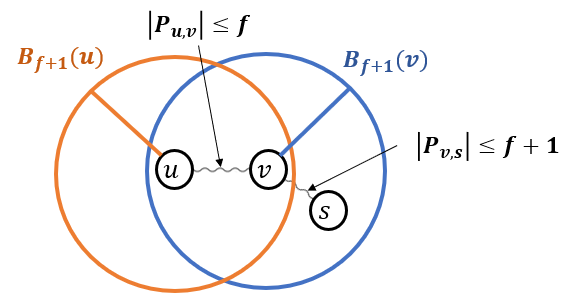
In this case, every node on satisfies that , except at most one node (such a node exists if is even and is exactly in the middle of ). Additionally, every node on satisfies that , as otherwise , which contradicts the assumption that . Denote by the path at a distance of at most from . There are nodes on that are neither nor . Additionally, excluding the node , we have nodes on with , and they are all in . This contradicts the assumption that there are at most such nodes. Therefore, this case in not possible.
Case 2: There exists a node on .
An illustration of this case is presented in Figure 2.
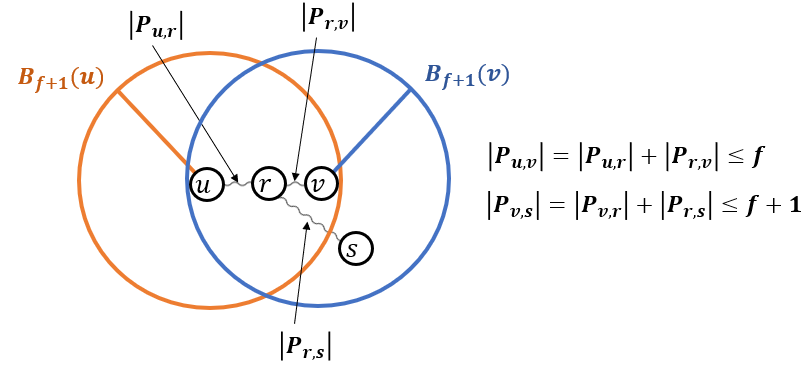
We consider to be the closest node to in . In this case, every node on satisfies that , except at most one node , as we proved in the previous case. Therefore, it is also correct for . Additionally, every node on satisfies that , as otherwise , contradicting the assumption that .
Denote by the path at a distance of at most from . There are nodes on that are not . Additionally, excluding the node , we have nodes on with , and they are all in . This contradicts the assumption that there are at most such nodes. Therefore, this case in not possible.
This completes the proof that every node that is still faulty at the beginning of this step and every node are alternative nodes.
Now, we prove that if sets in this step, then it satisfies that . In this case, since sets , there exists a node with . Since is an alternative node for with , it follows that by Lemma 6.
Finally, we prove that every faulty node that sets satisfies that . By the definition of a -ruling set, there exists a node such that (which may be itself). We claim that . Assume otherwise, i.e., that . Notice that have at least nodes with on , since there are nodes on , and at most one of them has (such a node exists if is even and is exactly in the middle of ). Therefore, if , consider nodes on the path that are at a distance of at most from . There are at least such nodes with , and so at least one of them is not faulty, which would lead to setting in Step 2. But, is faulty at the beginning of Step 2, which leads to a contradiction.
Thus, . Additionally, because in Step 2, is still faulty, and therefore, in Step 2, does not set , so must also still be faulty in Step 2. Since and is still faulty in Step 2, receives a message with in Step 2. Note that if is not faulty in Step 2, then either it is non-faulty to begin with, in which case would have already set in Step 2, or sets in Step 2. The latter is impossible because and is still faulty in Step 2. Thus, is still faulty in Step 2, which means that would receive a message from in Step 2 and not set in Step 2. Thus, is also still faulty in Step 2, and since , then .
Thus, since sets , every node satisfies . Since, , then as we proved, is an alternative node for . By Lemma 6, this implies that cannot be in . Since , it must hold that . Thus , as needed.
This completes the proof that, at the end of Algorithm 2, we set for every node correctly, satisfying . Finally, we sum the number of rounds the algorithm takes. In every broadcast in the algorithm, we have at most different messages (each of which fits in bits). Moreover, a node passes such a message only once. Thus, each broadcast takes rounds. Since there are only a constant number of steps with such broadcasts, the algorithm completes in rounds.
4 Partitioning
The nodes use the restored ruling set to partition themselves into groups, with each group containing an error correction code to recover the erased labels. The algorithm they follow is the same as that of the oracle, ensuring determinism and independence from faulty nodes. This guarantees consistent partitioning and correct decoding.
To ensure fast communication within each group, our goal is to partition the graph nodes into groups of size . Our algorithm achieves guarantees that are slightly weaker, in the sense that a group may be a disconnected component in the graph, but its weak diameter (its diameter in the original graph) is still . In general, such a guarantee may still be insufficient for fast communication within each group, as some edges may be used by multiple groups, causing congestion. However, our algorithm will make sure to provide low-congestion shortcuts. That is, it constructs groups of size with a weak diameter of , such that each edge is associated with a constant number of groups that communicate over it. A formal definition of this concept is as follows.
Definition 7 (Low-Congestion Shortcuts [24]).
Given a graph and a partition of into disjoint subsets , a set of subgraphs is called a set of -shortcuts, if:
-
1.
The subgraph is connected.
-
2.
For each , the diameter of the subgraph is at most .
-
3.
For each edge , the number of subgraphs containing is at most .
With the above definition, we can now state the properties of our partitioning algorithm.
Theorem 8.
Let be a graph, and let be a -ruling set where each node knows whether it is in . There exists a deterministic algorithm that partitions into disjoint groups with sizes ranging from to , and provides a set of -shortcuts for these groups. The algorithm completes in rounds.
Overview.
Algorithm 3 constructs the required partition as follows. Initially, each node computes a BFS tree to depth by propagating its ID. Nodes that receive multiple root IDs choose the smallest and use that tree only. The rest of the algorithm operates within each tree independently.
Within each tree, each node divides the nodes in its subtree into groups of size , with a remainder of up to nodes. This remaining number is sent to its parent , who handles dividing the remainders of its children similarly. The procedure sorts ’s children by increasing IDs, appends itself, and then forms groups by summing the remaining values of its children. Once a group reaches the desired size, a new group starts from the next child. Each child receives its group ID from . When a node receives its group allocation, it may need to inform some of its children to ensure that remaining nodes from its subtree join this group as well. This is handled by the procedure, in which node relays the group ID. During this process, also sets the local variable which is used for constructing low-congestion shortcuts for communication among the nodes of each group. Finally, if there is a small remainder at the root , the root appends these nodes to one of the groups created in or, if no such group was constructed by , it appends them to a group with the closest node from this group to . This is done by obtaining the required group ID and relaying it to the relevant remaining nodes.
Following is the formal algorithm and proof.
Procedure .
The node initializes a counter , an empty sequence , an empty set , and a variable . It then loops over and computes until .
When this happens for some index , the node adds the item to the sequence , sets , and continues looping over the nodes in from in the same manner. That is, it computes until for some value , after which it adds the item to , and so on. Thus, every item in is of the form , where is the ID of the node , which serves as the group identifier for all nodes for .
Let be the last group created by , so is the last child of whose value is grouped. The node computes . If and , updates to .
For each item in , inserts a tuple of into for every child where and . Thus, every item is of the form: . For each item , the node inserts the edge into the set .
Procedure .
Let be the last group that created during its procedure. The node initializes an empty set . Then, inserts a tuple into for every child where . Thus, every item is of the form . As in , for each item , the node inserts the edge into the set .
This concludes the description of the algorithm. Appendix A has the proof of Theorem 8, as well as for the following claim derived from it, which will be useful in the subsequent section.
Claim 9.
In parallel, each node can collect bits of information from all nodes in its group within rounds, where each node holds bits of information and the group sizes are .
5 Resilient Labeling Schemes
In this section, we wrap up the previous parts to obtain our resilient labeling scheme.
See 1
Overview.
Algorithm 4 gives our full resilient labeling scheme. The oracle executes Algorithm 1 to assign new labels to each node. In the distributed algorithm, each node parses its new label, which is done correctly since the length of each item in the string is known. The node then uses this label to reconstruct the greedy -ruling set (with ) using Algorithm 2 and to obtain its group in the partition according to Algorithm 3. Finally, the nodes exchange all their labels within a group and decode their original labels, as guaranteed by Theorem 3.
Proof of Theorem 1.
Correctness:
By Theorem 3, the values correspond to a greedy -ruling set , meaning that . Thus, according to Theorem 4, after running Algorithm 2 in Step 4, each node holds its value . Since Algorithm 3 is deterministic and the oracle uses the same algorithm in Algorithm 1 in Step 4, after running Algorithm 3 in Step 4, each node will have the same as determined by the oracle in Step 1 of Algorithm 1. Therefore, by Theorem 3, the operation in Step 4 will yield the value of for each node .
Round complexity:
By Theorems 4 and 8, Algorithms 2 and 3 in Steps 4 and 4, respectively, each take rounds. Additionally, according to Claim 9, every node can collect bits of information from all nodes in its group in parallel, within rounds, as each node holds bits of information and each group is of size . Thus, Step 4 completes in rounds. In total, the distributed algorithm completes in rounds. Since , we have rounds.
Label size:
According to Theorem 3, each of the original bits corresponds to a constant number of bits in the coded version. Additionally, there is one bit for the ruling set indication and bits for , making the new label size .
References
- [1] Ittai Abraham, Shiri Chechik, and Cyril Gavoille. Fully dynamic approximate distance oracles for planar graphs via forbidden-set distance labels. In Proceedings of the forty-fourth annual ACM symposium on Theory of computing, pages 1199–1218, 2012. doi:10.1145/2213977.2214084.
- [2] Stephen Alstrup, Cyril Gavoille, Haim Kaplan, and Theis Rauhe. Nearest common ancestors: a survey and a new distributed algorithm. In Proceedings of the fourteenth annual ACM symposium on Parallel algorithms and architectures, pages 258–264, 2002. doi:10.1145/564870.564914.
- [3] Yagel Ashkenazi, Ran Gelles, and Amir Leshem. Noisy beeping networks. Inf. Comput., 289(Part):104925, 2022. doi:10.1016/J.IC.2022.104925.
- [4] Alkida Balliu, Sebastian Brandt, Fabian Kuhn, and Dennis Olivetti. Distributed -coloring plays hide-and-seek. In Stefano Leonardi and Anupam Gupta, editors, STOC ’22: 54th Annual ACM SIGACT Symposium on Theory of Computing, Rome, Italy, June 20 - 24, 2022, pages 464–477. ACM, 2022. doi:10.1145/3519935.3520027.
- [5] Aviv Bar-Natan, Panagiotis Charalampopoulos, Paweł Gawrychowski, Shay Mozes, and Oren Weimann. Fault-tolerant distance labeling for planar graphs. Theoretical Computer Science, 918:48–59, 2022. doi:10.1016/J.TCS.2022.03.020.
- [6] Mor Baruch, Pierre Fraigniaud, and Boaz Patt-Shamir. Randomized proof-labeling schemes. In Proceedings of the 2015 ACM Symposium on Principles of Distributed Computing, pages 315–324, 2015. doi:10.1145/2767386.2767421.
- [7] Aviv Bick, Gillat Kol, and Rotem Oshman. Distributed zero-knowledge proofs over networks. In Proceedings of the 2022 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2426–2458. SIAM, 2022. doi:10.1137/1.9781611977073.97.
- [8] Keren Censor-Hillel, Ami Paz, and Mor Perry. Approximate proof-labeling schemes. Theor. Comput. Sci., 811:112–124, 2020. doi:10.1016/J.TCS.2018.08.020.
- [9] Michal Dory and Merav Parter. Fault-tolerant labeling and compact routing schemes. In Proceedings of the 2021 ACM Symposium on Principles of Distributed Computing, pages 445–455, 2021. doi:10.1145/3465084.3467929.
- [10] Yuval Emek and Yuval Gil. Twenty-two new approximate proof labeling schemes. In Hagit Attiya, editor, 34th International Symposium on Distributed Computing, DISC 2020, October 12-16, 2020, Virtual Conference, volume 179 of LIPIcs, pages 20:1–20:14. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2020. doi:10.4230/LIPICS.DISC.2020.20.
- [11] Yuval Emek, Yuval Gil, and Shay Kutten. Locally Restricted Proof Labeling Schemes. In Christian Scheideler, editor, 36th International Symposium on Distributed Computing (DISC 2022), volume 246 of LIPIcs, pages 20:1–20:22, Dagstuhl, Germany, 2022. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. doi:10.4230/LIPIcs.DISC.2022.20.
- [12] Salwa Faour, Mohsen Ghaffari, Christoph Grunau, Fabian Kuhn, and Václav Rozhoň. Local distributed rounding: Generalized to mis, matching, set cover, and beyond. In Proceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 4409–4447. SIAM, 2023. doi:10.1137/1.9781611977554.CH168.
- [13] Laurent Feuilloley. Introduction to local certification. Discrete Mathematics & Theoretical Computer Science, 23(Distributed Computing and Networking), 2021. doi:10.46298/DMTCS.6280.
- [14] Laurent Feuilloley and Pierre Fraigniaud. Error-sensitive proof-labeling schemes. J. Parallel Distributed Comput., 166:149–165, 2022. doi:10.1016/J.JPDC.2022.04.015.
- [15] Laurent Feuilloley, Pierre Fraigniaud, Juho Hirvonen, Ami Paz, and Mor Perry. Redundancy in distributed proofs. Distributed Computing, 34:113–132, 2021. doi:10.1007/S00446-020-00386-Z.
- [16] Orr Fischer, Rotem Oshman, and Dana Shamir. Explicit space-time tradeoffs for proof labeling schemes in graphs with small separators. In Quentin Bramas, Vincent Gramoli, and Alessia Milani, editors, 25th International Conference on Principles of Distributed Systems (OPODIS 2021), LIPIcs, pages 21:1–21:22, Dagstuhl, Germany, 2022. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, Schloss Dagstuhl – Leibniz-Zentrum für Informatik. doi:10.4230/LIPIcs.OPODIS.2021.21.
- [17] Pierre Fraigniaud, Cyril Gavoille, David Ilcinkas, and Andrzej Pelc. Distributed computing with advice: information sensitivity of graph coloring. Distributed Computing, 21:395–403, 2009. doi:10.1007/S00446-008-0076-Y.
- [18] Pierre Fraigniaud, David Ilcinkas, and Andrzej Pelc. Communication algorithms with advice. Journal of Computer and System Sciences, 76(3-4):222–232, 2010. doi:10.1016/J.JCSS.2009.07.002.
- [19] Pierre Fraigniaud, Amos Korman, and Emmanuelle Lebhar. Local mst computation with short advice. In Proceedings of the nineteenth annual ACM symposium on Parallel algorithms and architectures, pages 154–160, 2007. doi:10.1145/1248377.1248402.
- [20] Emanuele G Fusco and Andrzej Pelc. Trade-offs between the size of advice and broadcasting time in trees. In Proceedings of the twentieth annual symposium on Parallelism in algorithms and architectures, pages 77–84, 2008. doi:10.1145/1378533.1378545.
- [21] Cyril Gavoille and David Peleg. Compact and localized distributed data structures. Distributed Computing, 16:111–120, 2003. doi:10.1007/S00446-002-0073-5.
- [22] Cyril Gavoille, David Peleg, Stéphane Pérennes, and Ran Raz. Distance labeling in graphs. Journal of algorithms, 53(1):85–112, 2004. doi:10.1016/J.JALGOR.2004.05.002.
- [23] Paweł Gawrychowski, Fabian Kuhn, Jakub Łopuszański, Konstantinos Panagiotou, and Pascal Su. Labeling schemes for nearest common ancestors through minor-universal trees. In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 2604–2619. SIAM, 2018.
- [24] Mohsen Ghaffari and Bernhard Haeupler. Distributed algorithms for planar networks ii: Low-congestion shortcuts, mst, and min-cut. In Proceedings of the twenty-seventh annual ACM-SIAM symposium on Discrete algorithms, pages 202–219. SIAM, 2016. doi:10.1137/1.9781611974331.CH16.
- [25] Mika Göös and Jukka Suomela. Locally checkable proofs. In Proceedings of the 30th annual ACM SIGACT-SIGOPS symposium on Principles of distributed computing, pages 159–168, 2011. doi:10.1145/1993806.1993829.
- [26] Mika Göös and Jukka Suomela. Locally checkable proofs in distributed computing. Theory of Computing, 12(1):1–33, 2016. doi:10.4086/TOC.2016.V012A019.
- [27] Rani Izsak and Zeev Nutov. A note on labeling schemes for graph connectivity. Information processing letters, 112(1-2):39–43, 2012. doi:10.1016/J.IPL.2011.10.001.
- [28] Taisuke Izumi, Yuval Emek, Tadashi Wadayama, and Toshimitsu Masuzawa. Deterministic fault-tolerant connectivity labeling scheme. In Proceedings of the 2023 ACM Symposium on Principles of Distributed Computing, pages 190–199, 2023. doi:10.1145/3583668.3594584.
- [29] Jørn Justesen. Class of constructive asymptotically good algebraic codes. IEEE Transactions on information theory, 18(5):652–656, 1972. doi:10.1109/TIT.1972.1054893.
- [30] Michal Katz, Nir A Katz, Amos Korman, and David Peleg. Labeling schemes for flow and connectivity. SIAM Journal on Computing, 34(1):23–40, 2004. doi:10.1137/S0097539703433912.
- [31] Gillat Kol, Rotem Oshman, and Raghuvansh R Saxena. Interactive distributed proofs. In Proceedings of the 2018 ACM Symposium on Principles of Distributed Computing, pages 255–264, 2018. URL: https://dl.acm.org/citation.cfm?id=3212771.
- [32] Amos Korman. Labeling schemes for vertex connectivity. ACM Transactions on Algorithms (TALG), 6(2):1–10, 2010. doi:10.1145/1721837.1721855.
- [33] Amos Korman and Shay Kutten. Distributed verification of minimum spanning trees. In Proceedings of the twenty-fifth annual ACM symposium on Principles of distributed computing, pages 26–34, 2006. doi:10.1145/1146381.1146389.
- [34] Amos Korman and Shay Kutten. On distributed verification. In Distributed Computing and Networking: 8th International Conference, ICDCN 2006, Guwahati, India, December 27-30, 2006. Proceedings 8, pages 100–114. Springer, 2006. doi:10.1007/11947950_12.
- [35] Amos Korman, Shay Kutten, and David Peleg. Proof labeling schemes. Distributed Comput., 22(4):215–233, 2010. doi:10.1007/S00446-010-0095-3.
- [36] Nathan Linial. Locality in distributed graph algorithms. SIAM Journal on computing, 21(1):193–201, 1992. doi:10.1137/0221015.
- [37] Rafail Ostrovsky, Mor Perry, and Will Rosenbaum. Space-time tradeoffs for distributed verification. In Shantanu Das and Sébastien Tixeuil, editors, Structural Information and Communication Complexity - 24th International Colloquium, SIROCCO 2017, Porquerolles, France, June 19-22, 2017, Revised Selected Papers, volume 10641 of Lecture Notes in Computer Science, pages 53–70. Springer, 2017. doi:10.1007/978-3-319-72050-0_4.
- [38] Merav Parter and Asaf Petruschka. Õptimal dual vertex failure connectivity labels. In Christian Scheideler, editor, 36th International Symposium on Distributed Computing, DISC 2022, October 25-27, 2022, Augusta, Georgia, USA, volume 246 of LIPIcs, pages 32:1–32:19. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2022. doi:10.4230/LIPICS.DISC.2022.32.
- [39] Merav Parter, Asaf Petruschka, and Seth Pettie. Connectivity labeling for multiple vertex failures. arXiv preprint, 2023. doi:10.48550/arXiv.2307.06276.
- [40] Boaz Patt-Shamir and Mor Perry. Proof-labeling schemes: Broadcast, unicast and in between. In International Symposium on Stabilization, Safety, and Security of Distributed Systems, pages 1–17. Springer, 2017. doi:10.1007/978-3-319-69084-1_1.
- [41] David Peleg. Proximity-preserving labeling schemes. Journal of Graph Theory, 33(3):167–176, 2000. doi:10.1002/(SICI)1097-0118(200003)33:3\%3C167::AID-JGT7\%3E3.0.CO;2-5.
Appendix A Missing Proofs
A.1 Proof of Theorem 3
In order to prove this theorem, we need the following claim on .
Claim 10.
For every , it holds that .
Proof of Claim 10.
For every , the value of is defined as , and so we have for :
where the last inequality follows since and thus .
We now prove the aforementioned properties of the code implied by our choice of parameters using a very crude analysis of the constants, which is sufficient for our needs.
Proof of Theorem 3.
Since is the smallest such that , we have that , or in other words, . We prove in Claim 10 above that is at most . Combining these two with the fact that , gives that
where the last inequality follows since . This gives that is at most . To encode, we take the bits and pad them with zeros concatenated at their end. We get bits that are split among the nodes, so now the number of bits that each node has is at most . We know that and that is at most , so each node holds at most bits. This proves Item (1).
To prove Item (2), note that the code has a relative distance . The code can fix up to erasures, which is more than a fraction of . Since and the number of blocks is at least (which is at least ), any erasure of blocks erases at most a fraction of the blocks. Some blocks may be of size and others of size , which may differ by 1 and the larger blocks may get erased. However, even if we denote and assume , then in the worst case, the fraction of bit erasures caused by block erasures is at most , which is at most (since ). Thus, this may erase at most a fraction of bits of . Because the code can fix up to a fraction of erasures, we can decode , obtaining Item (2) as needed.
A.2 Proof of Lemma 6
Proof of Lemma 6.
Let and be alternative nodes, and let . We claim that if and only if . This implies that if then is a -ruling set. In particular, this means that apart from , the node does not have a node within distance at most from it. Therefore, cannot be smaller than , since otherwise the greedy algorithm would reach before when iterating over the nodes and would inserted into .
To prove that if and only if , we assume that and prove that . The proof for the other direction is symmetric. Assume towards a contradiction that it is not the case, so . Thus, using the triangle inequality we have
where the last inequality follows from the definition of as alternative nodes. Thus, . Assume towards a contradiction that there is a node on such that . Since is on then . Therefore,
This contradicts the assumption that . Thus, every node on satisfies .
Because , there are at least nodes on such that , and at least of them are at a distance of at most from . Thus, is not an alternative node for , contradicting the assumption. Therefore, .
A.3 Proof of Theorem 8
Proof of Theorem 8.
Since is a -ruling set, every node has a node within distance of at most from it. Thus, belongs to exactly one tree, and in the BFS in Step 3 in the algorithm, the node chooses one node to be its leader. Let be the tree rooted at .
The BFS tree of every node satisfies that .
For every node , there are at least nodes within distance from it (including itself), since the graph is connected. These nodes cannot be within distance from any other node , and thus they join the BFS tree . This proves that for all trees. In particular, there exists a partition of the nodes in into groups of sizes at least .
The algorithm obtains a partitioning of the nodes in every tree into groups with sizes ranging from to .
Fix and consider only nodes in . First, we prove that all groups created until the end of Step 3 are of size ranging from to . Let . In Step 3, the node runs the procedure . During the procedure, when creating a group, the node starts with the first child in and adds children according to until the counter of their values is at least . For a group that starts with child and ends with child , in Step 3 the node sends this group’s identifier to every child for which . Then, each sends in in Step 3 this group identifier to all its children for which it did not assign a group yet during the procedure , and its children relay this identifier in the same manner. Thus, the value of is the size of the group, and so this size is at least .
Notice that if is at most , when adding of some child , we get that the updated is at most (any value is always at most , as otherwise would form a group from these at least nodes). A special case is when a root of a subtree adds itself to a group it created, and then is at most . Therefore, since the size of a group is the value of , then the size of a group ranges from to .
This proves that all groups created until the end of Step 3 are of size ranging from to , but there still could be some values that needs to handle whose sum is . For every node , an ancestor of handles these values. But, the algorithm for the root in this case differs, as it has no ancestors. Steps 3-3 provide the root with a group ID to which it adds its remainder, so the size of that group may become at most . Thus, all the group sizes range from to .
Notice that since every node belongs to exactly one group, then all the groups are disjoint.
For each edge , the number of subgraphs containing is at most .
An edge is inserted into if sends the group identifier to and this happens only if sends to in Step 3. There are two cases. The first is that assigns a group during the steps of creating groups. Thus, does not assign another group in this or later steps. Therefore, in this case, the edge is inserted into only one set of . The same argument applies if the edge is inserted into during the steps of relaying group IDs.
The second case is that receives from its parent during the steps of handling the root remainder. Then, the root satisfies that . Thus, according to the algorithm, it assigns additional nodes to an existing group. Therefore, can be inserted into at most one additional group. Overall, there are at most two groups for which assigns to .
The diameter of the subgraph is at most .
Consider two cases, based on whether the group contains the root or not.
Case 1: Let be a group which does not contain the root , and let be the node that builds during . Since the group identifier is the ID of the first child in the group, there can be only a single that creates a group with this ID, and only nodes in the subtree of can belong to it.
Let . In Step 3, sends to and inserts the edge into . Additionally, if , then also receives from its parent and sets in Step 3 of procedure . This process continues until we reach a node which is a child of . Since also receives from in Step 3, then inserts the edge into , and sets in Step 3 of procedure . Thus, on the path from to , all the edges belong to , and all the nodes on the path from to belong to including and . Since this holds for every node , the subgraph is connected, and the distance between and in the tree is bounded by , as otherwise, has enough nodes to create a group of size which includes , contradicting the fact that is in the group created by . Thus, the diameter of every such group is bounded by .
Case 2: Let be the group which contains the root .
There are two possibilities. If , then the remainder of is assigned by itself to one of the groups it creates, and the same argument as in the previous case applies.
Otherwise, if , then in the steps handling the root remainder, the node assigns its remainder of nodes to a group that one of its descendants created. We prove that the distance of from the deepest node in is bounded by . This implies that the diameter of is bounded by .
Let be the node which created the group in its procedure. If before handling the root remainder, then at that point since otherwise, would receive during Step 3 instead of and thus would not be in that created. Thus, sets and the same argument applies to every ancestor of . This implies that the distance from to the root is at most , since all of the nodes on that path join , and if the distance was larger then there would be enough nodes to create a group that is separate from . Moreover, the distance from to every node in its subtree that is in is at most , as otherwise the child of in that subtree would have to create that group. Together, this means that the distance from of any node in is at most .
If before handling the root remainder, then a similar argument applies: any child of which is in has distance at most to any other node in its subtree that is in . The node itself is again within distance at most to . Thus, the distance from of any node in is at most .
The above proves that the set of subgraphs is a set of -shortcuts.
Round complexity:
Note that for every and , we have that . Thus, downcasting and upcasting messages in takes at most rounds by standard pipelining. Since we only downcast or upcast a constant number of times, we have that the algorithm completes in rounds.
A.4 Proof of Claim 9
Proof of Claim 9.
Every node holds a set for every group that needs to communicate through . This set contain edges to children of . From Theorem 8, for each edge , the number of subgraphs containing is at most . Thus, every node can send to its children which edges belong to which group so that the group can communicate over them. Thus, all groups can communicate over their edges in parallel. Additionally, the size of every group is . Therefore, on every edge, we need to pass messages, where each message is of size . Moreover, according to Theorem 8, for each group , the diameter of the subgraph is at most . Hence, by standard pipelining, for every node, it can collect bits of information from all nodes in its group, within rounds.