The Randomness Complexity of Differential Privacy

Abstract
We initiate the study of the randomness complexity of differential privacy, i.e., how many random bits an algorithm needs in order to generate accurate differentially private releases. As a test case, we focus on the task of releasing the results of counting queries, or equivalently all one-way marginals on a -dimensional dataset with boolean attributes. While standard differentially private mechanisms for this task have randomness complexity that grows linearly with , we show that, surprisingly, only random bits (in expectation) suffice to achieve an error that depends polynomially on (and is independent of the size of the dataset), and furthermore this is possible with pure, unbounded differential privacy and privacy-loss parameter . Conversely, we show that at least random bits are also necessary for nontrivial accuracy, even with approximate, bounded DP, provided the privacy-loss parameters satisfy . We obtain our results by establishing a close connection between the randomness complexity of differentially private mechanisms and the geometric notion of “deterministic rounding schemes” recently introduced and studied by Vander Woude et al. (2022, 2023).
Keywords and phrases:
differential privacy, randomness, geometryFunding:
Clément L. Canonne: Supported by an ARC DECRA (DE230101329).Copyright and License:
2012 ACM Subject Classification:
Theory of computation Pseudorandomness and derandomization ; Theory of computation Computational complexity and cryptography ; Security and privacy ; Mathematics of computingAcknowledgements:
We thank Mark Bun for pointing out the connections to recent work on replicability, and anonymous referees for helpful corrections and comments.Editors:
Raghu MekaSeries and Publisher:
1 Introduction
Differential privacy [5] is a widely accepted theoretical framework for protecting the privacy of individuals in a database while analysts query the database for statistical information. Differentially private (DP) mechanisms provide quantitative guarantees and tradeoffs on the level of privacy afforded to individuals and the accuracy of answers to queries. In order to provide these guarantees, DP mechanisms rely on the use of carefully calibrated “random noise” to protect privacy. Thus, large-scale deployments of differential privacy can require a massive amount of high-quality random (or cryptographically pseudorandom) bits.111In this work, we focus on using truly random bits to achieve the standard definition of DP with information-theoretic security. Later in the introduction, we discuss how this relates to the use of pseudorandom bits to implement DP with computational security, as typically done in practice. Indeed, Garfinkel and LeClerc [7] estimate that the U.S. Census Bureau’s differentially private TopDown Algorithm as used for the 2020 Decennial Census required at least 90 terabytes of random bits, and described major engineering challenges in generating those bits with sufficient efficiency and security. As they write in their conclusion,
“The need to generate a large number of high-quality random numbers is a largely unrecognized requirement of a production differential privacy system.”
Motivated by these challenges, and following the long line of inquiry in theoretical computer science on the role and necessity of randomness in computation, we initiate the study of the randomness complexity of differential privacy:
What is the minimum amount of randomness required by differentially private mechanisms to achieve a specific level of accuracy?
We will quantify this “minimal amount of randomness” using either the maximum or expected number of random bits used by a differentially private algorithm, as a function of the dataset dimensions, privacy-loss parameters, and accuracy. For the sake of concreteness, we focus in this work on a specific task, summation (or one-way marginal) queries, which asks to provide an estimate of the sum of -dimensional (binary) vectors, each corresponding to a different individual in the dataset.
In more detail, the task of summation is as follows: the dataset consists of data from individuals, each contributing a -dimensional binary vector . We can think of as a matrix with rows . The mechanism must output an estimate of , such that with probability at least . We call such a mechanism -accurate. (See Definition 2.3 for a formal definition.)
We require that the mechanism also satisfies -differential privacy (-DP) for some parameters , which means that for every pair of datasets that differ on one row, we have
When , this is called pure differential privacy, and we say that is -DP. Our algorithm will work in the so-called unbounded DP setting, where the size of the dataset is private information and thus needs to be protected by differential privacy like any other statistic. In contrast, our lower bound applies to the (easier) bounded DP setting, where is public and fixed. (See Definitions 2.3 and 2.2 for formal definitions.)
We define the maximum randomness complexity of a mechanism as the maximum over databases of the maximum number of random bits used by on input . We define the expected randomness complexity of a mechanism as the maximum over databases of the expected number of random bits used by on input .
Differentially private summation is a well-studied question, for which many approximately optimal (in terms of accuracy) DP mechanisms have been proposed and analyzed. One of the simplest is the Laplace mechanism, which consists in adding -dimensional Laplace noise with scale parameter to the true value . This can be shown to have error with high probability, which is optimal up to log factors. (Here is shorthand for a function that is for an unspecified constant .) However, this comes at a significant cost, as adding continuous Laplace noise would technically require an infinite number of random bits. Instead, one can choose to add (independent) geometric noise to each coordinate of the true count, using a symmetrized Geometric random variable. This similarly will achieve nearly optimal error, but now with a finite expected randomness complexity. Unfortunately, the expected number of random bits required, , still scales at least linearly with the dimension. (Here the means that is treated as a constant, on which the hidden constants in the can depend.)
At first, this linear scaling seems inherent: For , to achieve non-trivial accuracy every DP mechanism must have entropy :
Lemma 1.1.
For every and and every -accurate -DP mechanism for binary counts, there is some database such that .
Here denotes the Shannon entropy of the output distribution , which is a lower bound on the expected number of random bits used by . (We provide a simple proof of Lemma 1.1 in the full version.) Given that, in the -dimensional summation task, the dimensions are totally independent, one might expect the entropy required to be additive across dimensions, leading to an lower bound on expected randomness complexity.
Our results
Surprisingly, the above intuition turns out to be false: by leveraging recent work on deterministic rounding schemes, we show that the expected randomness complexity can be made as low as , while still achieving good accuracy (i.e., an error that is polynomial in the dimension , independent of the size of the database):
Theorem 1.2 (Informal; see Corollary 3.2).
For every and , there is an -DP mechanism (in the unbounded DP setting) such that the expected randomness complexity of satisfies
and for every , is -accurate for summation with
Taking gives expected randomness complexity as claimed. Furthermore, with this setting of and , the accuracy is , independent of . If we instead take , we get near-optimal accuracy , but then the expected randomness complexity becomes . Choosing provides a tradeoff between these two extremes.
For bounding the maximum randomness complexity, we necessarily222If uses at most random bits, then for every database , the support of the distribution is of size at most . However, a pure DP algorithm must have the same support on every input database. A summation mechanism with nontrivial accuracy on datasets of size should at least distinguish the datasets where all rows are the same, and thus must have . relax to approximate DP:
Theorem 1.3 (Informal; see Corollary 3.4).
For every , , , there is an -DP mechanism (in the unbounded DP setting) such that the maximum randomness complexity of satisfies
and for every , is -accurate for summation with
Again, the randomness complexity is minimized at , which gives and , and the latter is again a factor of larger than the error achievable with unlimited randomness. Typically, is taken to be cryptographically negligible, so and our bound on the maximum randomness complexity becomes .
Next, we prove lower bounds showing that the randomness complexity we achieve is nearly optimal (in certain parameter regimes):
Theorem 1.4 (Informal; see Corollary 4.2).
Suppose that is an -DP mechanism (in the bounded DP setting) that is -accurate for summation, where . Then the maximum randomness complexity of satisfies
If in addition, , , and . Then both the maximum and expected randomness complexities of satisfy:
Let’s examine the constraint on the parameters. The constraint on essentially just requires that has nontrivial accuracy. Indeed, accuracy on datasets of size can trivially be achieved by the deterministic mechanism that always outputs ; this mechanism is -accurate, -DP, and has randomness complexity 0. The constraint on is quite mild, since is intended to be cryptographically small, and in particular subpolynomial in input size parameters like and . The constraints on and are more nontrivial. They match our upper bound, in the sense that Theorem 1.2 achieves expected randomness complexity even when . However, it would be interesting to know whether even smaller randomness complexity is possible when and are constants.
Connection to geometry
The key ingredient in our results is a two-way connection to the notion of deterministic rounding schemes recently introduced and studied by Vander Woude, Dixon, Pavan, Radcliffe, and Vinodchandran [11, 12]. Deterministic rounding schemes provide methods for rounding data in to nearby points so that any ball of small enough radius rounds to only a small number of points. As discussed in [11, 12], such rounding schemes are equivalent to the geometric notion of a secluded partition, which is a partition of into sets of bounded radius such that balls of a sufficiently small radius do not intersect too many sets of the partition. We tie these ideas to the randomness complexity of accurate DP algorithms. In particular, our upper and lower bounds on randomness complexity are intimately tied to the fact that in dimensions, bounded-radius sets that cover must contain intersections of at least size at certain points, and it is possible to find covers where no more than sets ever jointly intersect. In the theory of set intersections, these ideas are closely related to KKM covers of bounded polyhedra and the Polytopal Sperner lemma [3], and in fact our initial proofs of our results (not included here) came through these connections.
Related work on replicability
Recent work [4] has studied the randomness complexity of replicable algorithms using similar geometric tools. There are bidirectional conversions between replicable algorithms and approximate differentially private algorithms [8, 1] for problems about “population statistics,” where the dataset consists of iid samples from an unknown distribution and the goal is to estimate statistics abut the distribution. In contrast, our focus is on “empirical statistics,” where there is no iid assumption on the dataset and the goal is to estimate statistics of the dataset itself (as in the motivating use case of the 2020 U.S. Census). One can convert differentially private algorithms for population statistics into ones for empirical statistics (see, e.g., [2]), but this conversion incurs a high cost in randomness complexity (running the DP algorithm for population statistics on a dataset formed by sampling rows from the input dataset independently with replacement). In the reverse direction, differentially private algorithms for empirical statistics are also automatically differentially private algorithms for population statistics (provided the dataset size is large enough so that the empirical statistics approximate the population statistics with high probability), but converting a DP algorithm for population statistics into a replicable algorithm also appears to incur a large cost in randomness complexity. Thus neither our upper bound nor our lower bound appear to follow as a black box from the existing results on replicability, but it will be interesting to explore whether the techniques in either setting can be used to improve or extend any of the results in the other.
On using pseudorandom bits
In practice, implementations of differential privacy (including for the 2020 Decennial U.S. Census [7]) do not use truly random bits, but use pseudorandom bits generated by a cryptographically strong pseudorandom generator from a short seed, which is assumed to be truly random (or at least have sufficiently high entropy). If the differentially private algorithms satisfy the standard information-theoretic definition of DP (Definition 2.2) when run with truly random bits, then when executed using cryptographically strong pseudorandom bits, they satisfy a natural and convincing relaxation of differential privacy to computationally bounded adversaries [9]. Although the use of a pseudorandom generator reduces the number of truly random bits needed to equal the seed length of the generator, there is still a substantial cost if the differentially private algorithm is designed to use a huge number of random bits, since we must run the pseudorandom generator enough times to produce all of those bits. This is the cost referred to by Garfinkel and LeClerc [7], and it motivates our focus on the number of truly random bits needed to achieve information-theoretic DP. Furthermore, our Theorem 1.2 shows that we can reduce the expected number of truly random bits to be even smaller than the seed length of a cryptographic pseudorandom generator. Specifically, a cryptographic pseudorandom generator requires seed length at least , where is a bound on the probability with which any computationally bounded adversary can distinguish the pseudorandom bits from uniform. This plays an analogous role in computational differential privacy to the in information-theoretic -DP. Typically, is taken to be cryptographically negligible, so and the randomness complexity of Theorem 1.2 is asymptotically smaller than .
Overview of the proofs
The high-level idea of our upper bound (algorithmic result) starts with the following observation: if we could post-process the output of a DP mechanism to only allow a small number of outcomes on every database without hurting its accuracy too much, then we would be in good shape: for every database , having implies that is at most , and so we obtain a new mechanism with low entropy but similar accuracy. Now, could still have very high randomness complexity (since itself could have been using a lot of random bits), but it is a standard fact in information theory (based on Huffman coding) that any discrete random variable can be generated using at most random bits on average. Thus, there is yet another mechanism with randomness complexity at most .
Unfortunately, if we want to achieve pure DP as in Theorem 1.2, it is too much to hope for bounding the randomness complexity via support size. (See Footnote 2.) Instead, we will ensure that there is a set of size at most such that with probability at least , for a small ; we’ll take . If we can also ensure that the entropy of conditioned on is bounded by , then this suffices to achieve an overall entropy of at most .
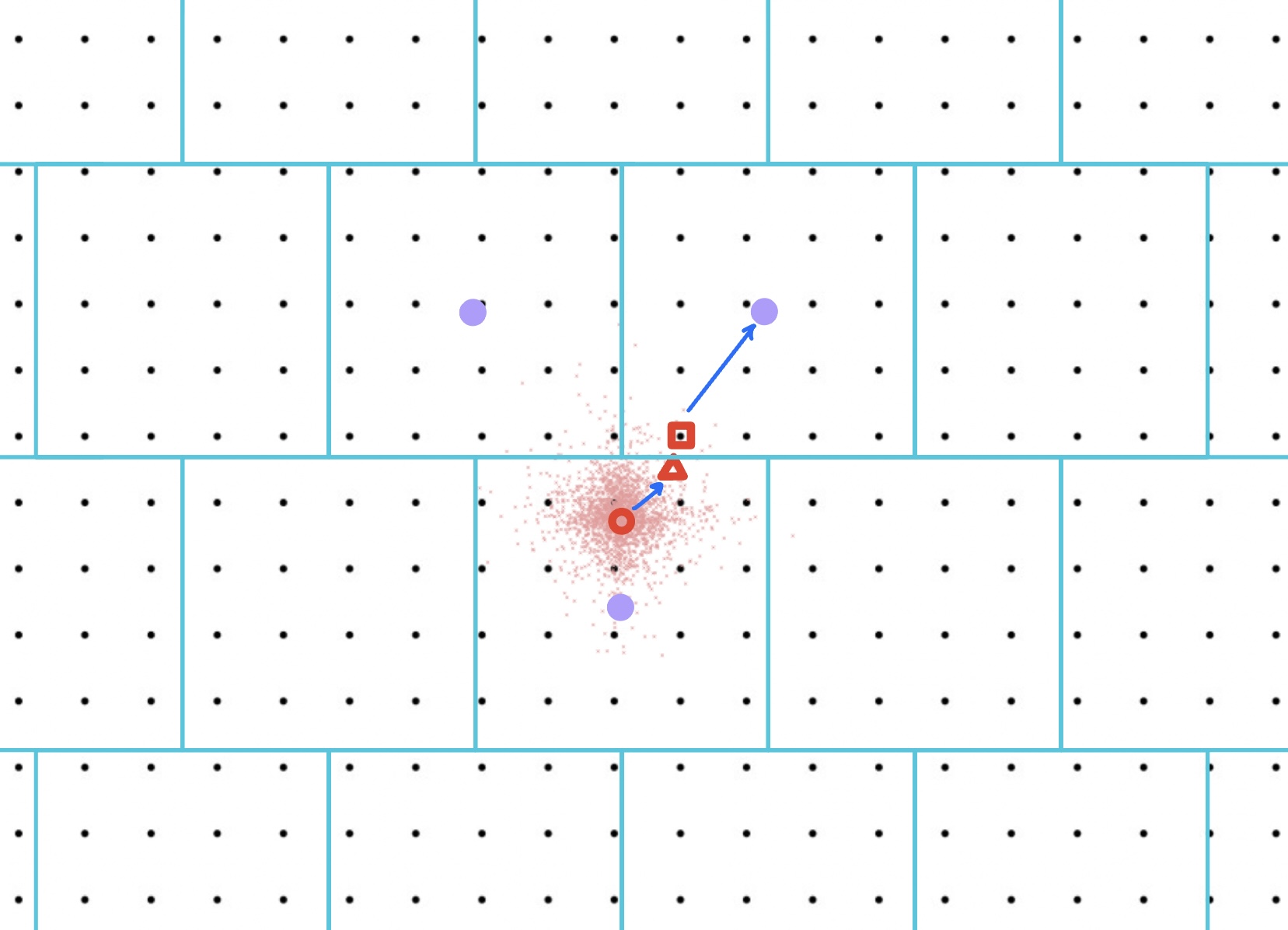
To implement the above plan, we start with any accurate -DP mechanism , say one based on the Laplace mechanism. The crucial step is then how to achieve the post-processing step. This we do with a deterministic rounding scheme . Such a scheme will take the output and round it to a nearby point , say at distance at most from . We choose to be large enough so that the noise in will be of magnitude (in norm) at most with high probability, for a sufficiently small . is called a deterministic rounding scheme of radius if on every ball of radius , takes on at most distinct values. With such a scheme, we get that lies in a set of size with high probability.
So then the question becomes what parameters are possible, and this is exactly what is addressed in the work of Vander Woude et al. [12]. In particular, they construct a scheme with and , which is what we use in Theorem 1.2. As noted above, completing the proof of the theorem requires controlling the entropy of also conditioned on the event that the noise is large. This we achieve by an additional coarsening of the output of , via a standard rounding of every coordinate to a multiple of , before applying the deterministic rounding scheme .
For our upper bound on maximum randomness complexity (Theorem 1.3), we apply the same strategy as above to the Gaussian mechanism for differential privacy. In this case, we replace our use of Huffman coding with the fact that if we have a random variable that lies in a set of size at most with probability at least , then for every , using at most random bits, we can generate a random variable that is at total variation distance at most from .
To prove our lower bound of (second part of Theorem 1.4) on expected randomness complexity, we show how randomness-efficient DP mechanisms for summation with good accuracy imply the existence of deterministic rounding schemes with good parameters: where the parameters of the rounding schemes are directly related to the randomness complexity of the DP mechanism . This allows us to invoke impossibility results from [11, 12] on the existence of “too-good-to-be-true” deterministic rounding schemes to rule out DP mechanisms which are simultaneously accurate and randomness-efficient. In more detail, the main steps of the lower bound are as follows: given a purported -DP mechanism for summation with low randomness complexity, (1) we embed the hypergrid into the space of -dimensional datasets of size , , such that distance in the former maps to Hamming distance in the latter and computing summation on a given dataset allows one to retrieve the original hypergrid vector . (2) We use the randomness guarantees of to extract, from its output distribution on a given database , the highest-probability representative output , which defines a deterministic rounding scheme :
(3) we leverage the accuracy guarantees of to argue that this rounding is indeed close to ; and, finally, (4) we invoke the (group) privacy guarantee of to show that the image of any given ball by our newly-defined rounding scheme cannot contain too many “representatives” . There is one last step required, as the rounding scheme outline above is only defined on : to conclude, we need to “lift” this rounding scheme to the whole of while preserving its properties, which we do by a careful tiling of the space with translations and reflections of the hypergrid.
The lower bound of on maximum randomness complexity follows from observing that any -DP mechanism that uses less than random bits is -DP for some finite , and then we can apply the argument of Footnote 2 to deduce .
Directions for Future Work
We conclude this introduction by mentioning some open questions, and directions for future work.
The first question is whether one can close the gap between our upper and lower bounds. Our upper bounds show that randomness complexity can be achieved with accuracy , but to achieve near-optimal accuracy , we only achieve randomness complexity . Can our algorithm be improved to achieve logarithmic randomness complexity with near-optimal accuracy? Or can our lower bound be improved to show that linear randomness complexity is necessary for near-optimal accuracy? As discussed earlier, another question is to remove some of the constraints on parameters, like and , in our lower bound, or else show that sub-logarithmic randomness complexity is possible when these parameters are constant.
A second question whether one can obtain efficient low-randomness DP mechanisms, e.g., running in time . Recall that our mechanisms from Theorem 1.2 and Theorem 1.3 rely on computationally inefficient procedures (e.g., Huffman coding) to convert a mechanism with low output entropy into one with low randomness complexity. For this reason, as well as the aforementioned accuracy loss, we would not recommend using our mechanisms in practice (even though our work was inspired by the practical concerns raised in [7]). Still, it raises the hope for practical DP mechanisms that are much more randomness-efficient than ones currently used.
As a test case we focused in this paper on the task of differentially private summation: extending our study of the randomness requirement of DP mechanisms to other statistical releases, or attempting to provide a general treatment of the randomness complexity of differential privacy, would be an interesting direction.
Finally, as mentioned earlier, exploring connections to recent work on replicable algorithms may also prove to be fruitful.
2 Preliminaries
2.1 Differential Privacy
Consider a database consisting of entries chosen from some domain : that is, is an element of . If each entry of the database consists of numerical attributes, then might be or (for discrete data) or (for binary data). It is convenient to think of as an matrix, with each row of the matrix being the vector . In general, when the size of the database is unknown, or allowed to grow, we will denote it by , and accordingly consider databases in .
Definition 2.1 (Database metrics and adjacency).
For two databases , their insert-delete distance (aka LCS distance) is the number of insertions and deletions of elements of to transform into . For two databases such that , their Hamming distance is the number of rows such that . If , we define . For a database metric , we say that and are adjacent with respect to , denoted if .
We use to capture unbounded differential privacy, where the size of the dataset is unknown and considered private information that needs to be protected. captures bounded differential privacy, where the size is public information, known to a potential adversary. Since for databases of the same size, unbounded-DP algorithms are also bounded DP, up to a factor of 2 in the privacy-loss parameters. We state our positive result in the unbounded-DP setting and our negative result in the bounded-DP setting, making both results stronger.
Definition 2.2 (Differential privacy).
Fix and . A randomized algorithm is -differentially private (or -DP) with respect to database metric if for every pair of adjacent databases in and every measurable , we have
If , we simply say is -DP.
We restrict our attention in this article to databases where each record has binary attributes, so , and to mechanisms that output an estimate of the sum of the attributes. This motivates the following definition:
Definition 2.3 (Accuracy).
Given and , a randomized algorithm is said to be -accurate for summation if for every , we have
where
Note that we used rather than as the domain of . This allows for the possibility that, even in the unbounded DP setting, the accuracy of the mechanism depends on the size of the dataset, as well as the dimension and the privacy parameters and .
Two key features of differential privacy are its immunity to post-processing and its group privacy property:
Lemma 2.4 (Postprocessing).
Let be an -DP mechanism, and be any (possibly randomized) function. Then is -DP.
Lemma 2.5 (Group privacy).
Let be an -DP mechanism with respect to database metric , and be two databases at distance . Then, for every measurable , we have
We refer the reader to, e.g., [6, 10] for more background on differential privacy and the proof of these properties. We also briefly recall the definition and guarantees of two of the standard noise mechanisms used in differential privacy, the Laplace and Gaussian mechanisms:
Lemma 2.6 (Laplace mechanism; see e.g., [6, Theorems 3.6 and 3.8]).
Suppose has sensitivity , that is, . Then, for every , the mechanism defined by
is -DP, where denotes the product distribution over with iid marginals distributed as a Laplace with scale parameter (i.e., probability density function ). Moreover, its accuracy satisfies the following: for every ,
Lemma 2.7 (Gaussian mechanism; see e.g., [6, Theorems 3.22 and A.1]).
Suppose has sensitivity , that is, . Then, for every and , the mechanism defined by
is -DP, where denotes the product distribution over with iid marginals distributed as a Normal distribution with mean 0 and variance . Moreover, its accuracy satisfies the following: for every ,
2.2 Randomness Complexity
We work with a model of randomized algorithms where the algorithm has access to a coin-tossing oracle that returns an independent, unbiased random bit on each invocation. The number of random bits used by on a particular execution is defined to be the number of the calls to the coin-tossing oracle (which is a random variable, as the algorithm could adaptively decide whether to call the oracle again or not depending on the results of prior coin tosses). We require that on all inputs, the algorithm halts with probability 1 over the coin tosses received.
We define below two natural measures of randomness complexity. Like with accuracy, we will use as the domain rather than to allow the possibility that the randomness complexity depends on the size of the dataset.
Definition 2.8 (randomness complexity).
For a randomized algorithm and , we define:
-
= the maximum over of the expected number of random bits used by on input , where the expectation is taken over the coin tosses of .
-
: the maximum over of the maximum number of random bits used by on input .
Rather than work directly with randomness complexity, it is more convenient for us to work with measures of output entropy:
Definition 2.9.
For a randomized algorithm , we define
-
, where denotes the Shannon entropy of random variable (in bits), defined as .
-
, where denotes the min-entropy of random variable , defined as .
-
, where denotes the max-entropy of random variable , defined as .
-
, where denotes the -smoothed max-entropy of random variable , which is defined to be the minimum of over (probabilistic) events of probability at least .
Some basic relations between the randomness complexity measures and the output entropy measures are as follows:
Lemma 2.10.
For any randomized algorithm , the following hold:
-
1.
, , .
-
2.
and .
-
3.
For every , there is an such that and on every input , is identically distributed to .
-
4.
For every and , there is an such that and for every , is at total variation distance at most from .
2.3 Deterministic Rounding Schemes and Secluded Partitions
A crucial building block for our results is the notion of deterministic rounding scheme, recently introduced by Vander Woude, Dixon, Pavan, Radcliffe, and Vinodchandran [12]. Although they defined such a scheme as a function , we generalize their definition slightly to include functions on an arbitrary domain and a radius parameter that becomes necessary when is not all of :
Definition 2.11.
For , , and , a function is said to be a -deterministic rounding scheme of radius on if the following two conditions hold:
-
1.
for all , ;
-
2.
for all , .
where denotes the closed ball of radius centered at . That is, each “rounds” inputs to nearby points (within ), and inputs that are close (in a -ball) can only be rounded to a small number of representatives.
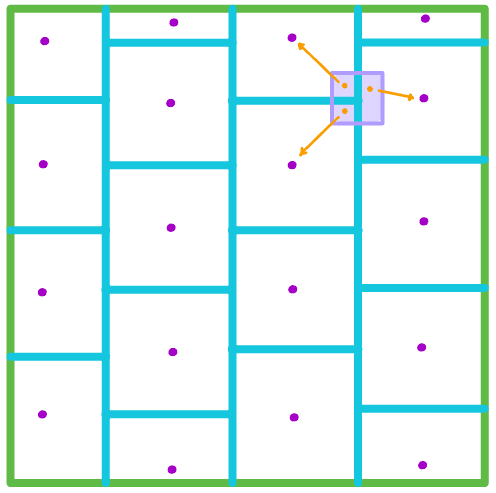
When , the parameter is not important; if is a deterministic rounding scheme of radius , then for every , we see that is a deterministic rounding scheme of radius . When is not specified, its default value is , matching the radius of “round-to-the-nearest-integer.” However, we will also consider deterministic rounding schemes on ; then the choice of is more important. Indeed, has a trivial -deterministic rounding scheme of radius , where all points get rounded to the center of , but it has no -deterministic rounding scheme of radius .
As pointed out by Vander Woude et al. [12, Observation 1.3], deterministic rounding schemes have a nice geometric interpretation as -secluded partitions: partitions of by sets of radius at most such that every ball of radius intersects at most sets in the partition. Using this geometric perspective, Vander Woude et al. prove the following upper and lower bounds:
3 Upper bounds for summation
In this section, we establish our upper bound results, which state that good deterministic rounding schemes imply differentially private mechanisms for summation with low randomness complexity (Theorem 3.1).
We begin with our upper bound on expected randomness complexity.
Theorem 3.1.
Suppose there exists a -deterministic rounding scheme . Then for every , there is a mechanism that is -DP with respect to satisfying
such that, for every , is -accurate for summation for
Combining this with Theorem 2.12 and the conversion from output entropy to randomness complexity (Lemma 2.10, Item 3), we get:
Corollary 3.2.
For every , there is a mechanism that is -DP with respect to satisfying
such that, for every , is -accurate for summation for
In particular, taking , we obtain and
Proof of Theorem 3.1.
Let be a -deterministic rounding scheme. Without loss of generality, by scaling, we can assume that has radius , for a parameter to be determined later in the proof. Then we have that for every ,
-
1.
, and
-
2.
.
Now define this mechanism on a database :
Mechanism .
-
1.
Draw , and let ,333Note that the distribution of is not the same as applying the Geometric Mechanism (i.e. Discrete Laplace Mechanism) supported on integer multiples of . To apply the Geometric Mechanism, we would need to first round to a multiple of , which would substantially increase the sensitivity and increase the amount of noise we need to add. We could apply the Geometric Mechanism to instead of the Laplace Mechanism prior to the rounding step, but it does not simplify anything in the analysis below.
-
2.
Output .
By the post-processing property of differential privacy and the -DP guarantees of the Laplace mechanism, is itself -DP: it remains to argue about its accuracy and randomness complexity. By the accuracy of the Laplace mechanism (Lemma 2.6), we have that, with probability at least , the noise infusion introduces an error of at most
Rounding the coordinates of to the nearest multiple of and replacing with increase the error by at most , so we have -accuracy for
For the randomness complexity, by the same analysis as in the accuracy above (but replacing with ), we have that with probability at least , the following event holds:
Conditioned on , the point lies in an ball of radius around . By setting , lies in a ball of radius , and the fact that is a deterministic rounding scheme of radius tell us that, conditioned on , the support size of is at most , and in particular has entropy at most . Thus, we have .
To bound overall, we also need to bound the entropy of conditioned on , which is upper bounded by the entropy of conditioned on . is the event that at least one coordinate of has magnitude larger than ; the remainder may or may not have magnitude larger than . Conditional on , coordinate of is distributed as , where is a mixture of conditioned on having magnitude at most and conditioned on having magnitude greater than . Provided that , such a distribution has entropy , similarly to how a geometric distribution with parameter has entropy .444For a bit more detail: observe that, before conditioning, the distribution of is a mixture of a point mass and two geometric distributions: a point mass on , a geometric distribution on the multiples of smaller than (assuming wlog that ), and a geometric distribution supported on the multiples of greater than or equal to . Under the assumption that , the parameter of these geometric distributions is bounded away from 1, i.e., the probability mass of each point in the support is a constant factor smaller than the point in the support closer to . This latter property is preserved under conditioning on or conditioning on , and suffices to ensure entropy . By our setting of above, is larger than by a factor of . With entropy contributed from each coordinate, we get entropy overall conditioned on . (The coordinates of are not independent conditioned on , but entropy is subadditive even for dependent random variables.)
Thus, letting be the indicator random variable for event , we have
The accuracy bound follows by plugging our setting for and into the expression for above.
Now we turn to our upper bound on maximum randomness complexity.
Theorem 3.3.
Suppose there exists a -deterministic rounding scheme . Then for every , there is a mechanism that is -DP with respect to satisfying and such that, for every , is -accurate for summation for
Combining this with Theorem 2.12 and the conversion from output entropy to randomness complexity (Lemma 2.10, Item 4), we get:
Corollary 3.4.
For every , and , there is a mechanism that is -DP with respect to satisfying
such that, for every , is -accurate for summation for
In particular, taking , we obtain and
Proof Sketch of Theorem 3.3.
Follow the proof of Theorem 3.1 but replace the use of the Laplace mechanism (Lemma 2.6) with the Gaussian mechanism (Lemma 2.7), and define the event using the accuracy bound that holds with probability at least (rather than ). In this proof, there is no need to analyze .
4 Lower bound for summation
We now turn to establishing a lower bound on the randomness complexity of any accurate DP mechanism for summation. To strengthen the result, we will consider the bounded DP setting and allow approximate DP mechanisms; and our conclusion will yield a lower bound on the min-entropy of any such DP mechanism.
Theorem 4.1.
Suppose that is a mechanism that is a -DP mechanism with respect to with that is -accurate for summation for and . Then, for every , there exists a -deterministic rounding scheme with
where
Observe that when we take , we have , so, at least when our upper bound on becomes . By the lower bound on deterministic rounding schemes (Theorem 2.13), we know that , so we obtain an entropy lower bound of . When , this matches our best upper bound on randomness complexity up to an additive constant (the case in Corollary 3.2). For positive , we only lose an additive constant in the lower bound provided that . Using the fact that , we obtain:
Corollary 4.2.
Suppose that is a mechanism that is -DP mechanism with respect to with , , , and . Then
(The conditions involving in Theorem 4.1 disappear by doing a case analysis. If , then we are done. Otherwise, we can set in Theorem 4.1.)
We will prove Theorem 4.1 by first constructing a deterministic rounding scheme for the cube and then lifting it to a deterministic rounding scheme for all of by the following lemma (whose proof we defer to later).
Lemma 4.3.
Suppose there exists a -deterministic rounding scheme of radius , where . Then there exists a -deterministic rounding scheme , for .
Proof of Theorem 4.1.
By Lemma 4.3, it suffices to to construct a -deterministic rounding scheme of radius with or .
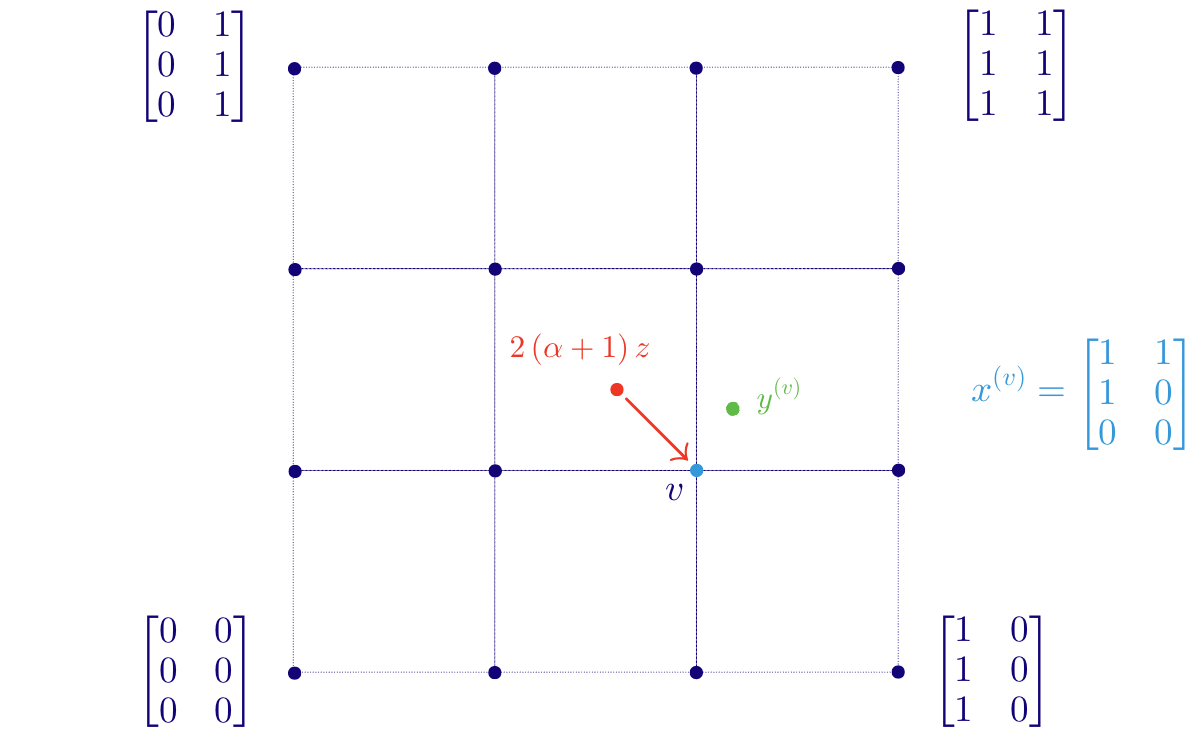
Let be the -dimensional hypergrid: we identify each point of the grid with a dataset in the following fashion. For row and column , we have
where denotes the indicator function. That is, if , then is an matrix where in each column , the first entries are ones and any remaining entries are zeroes. It follows that , and if are at distance at most , then and are at distance at most from each other as datasets: .
Since , for every , there is some output such that . (If there are several such outputs, choose the lexicographically largest.)
Now we construct our function as follows. For every , let be a point in obtained by rounding all coordinates of to the nearest integer (and rounding up if halfway between integers). The resulting is in because , and by construction is at distance at most from . Then exists as noted above. See Figure 3. Set
To show that is a deterministic rounding scheme, we analyze the two properties separately.
-
To show that , we use the accuracy of the mechanism. Fix any : by construction, and are at distance at most . Recall that we have
and
Since , the outcome of has probability at most of being farther than from . Since the particular outcome has probability greater than , then must be at distance at most from , and hence at distance at most from . Hence, is at distance at most from .
-
For the second, we use the privacy guarantee of the mechanism: consider a closed ball and points such that there are distinct outputs . Let be the corresponding gridpoints, i.e., . Recall that , so the ’s are all distinct.
Since are all in , the gridpoints are all at distance at most from , which is itself at distance at most from some gridpoint . In particular, each is at distance at most from , so the dataset is at distance at most from in Hamming distance, for
By (group) differential privacy, for each , we have
Summing over , we get
Reorganizing and upper bounding , we have
as desired.
As mentioned earlier, all that remains is to invoke Lemma 4.3 to lift our deterministic rounding scheme from to the whole of .
It only remains to establish Lemma 4.3.
Proof of Lemma 4.3.
Fix a -deterministic rounding scheme of radius , with . Although the image of might extend to points outside by -distance , we may assume without loss of generality that the image of is contained in because projecting the outputs of to the nearest point in preserves both properties of a deterministic rounding scheme.
We first modify so that it behaves nicely near the faces of the cube to get a rounding scheme , then we show how to extend that to all of to get the desired rounding scheme .
We define by the following process, which is also illustrated in Figure 4.
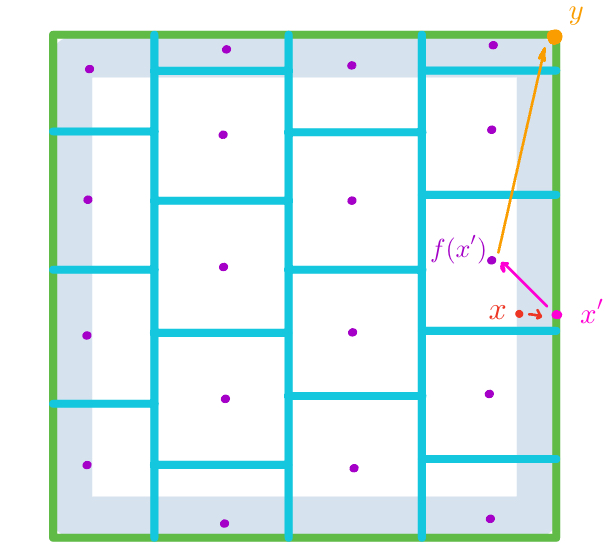
-
1.
Given , for each , set
That is, if is in a “moat” of width , then it is -close to one (or possibly several) face(s) of the cube and is the projection of onto (the intersection of) the face(s). Otherwise, set . Note that is well-defined by our assumption that .
-
2.
For each , set
(Recall that we can assume without loss of generality that the image of is in .) That is, we round to the nearest corner of the cube.
-
3.
Set .
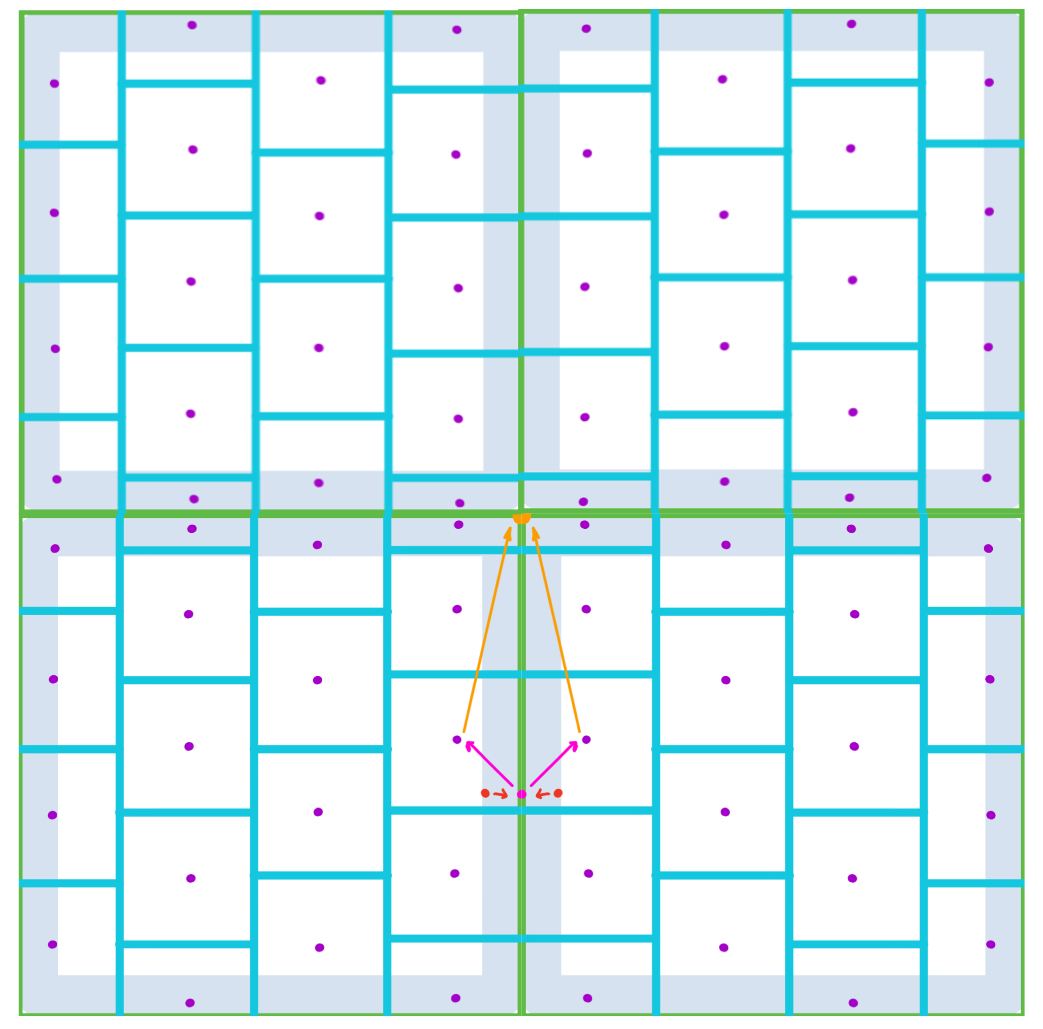
To understand the radius of , consider Figure 4. The first step from to is bounded (in distance) by (and is zero if is not in the moat). The second step from to is bounded by (the radius of ). The third step from to is bounded by (since it is rounding to a cube corner). The triangle inequality shows the total distance from to is bounded by , but Figure 4 suggests we can improve this bound: some cancellation is occurring in axes directions where is close to the boundary. To make this intuition precise, we do casework.
-
If or , then since , we see from ’s definition that so that
-
If , then since , we have
But when we also have , which implies that
Since , the bound never exceeds either or . So, for all ,
establishing the bound on the radius.
Observe that for every ball of radius , we have
This is because if , then , and we obtain by applying to and then projecting.
From , we construct a deterministic rounding scheme by using in each unit cube, but reflected so that points on either side of a unit cube boundary behave similarly. See Figure 5. We define as follows:
Given .
-
1.
For each , write , where , , and . Note that this is not unique when , as two decompositions are then possible with either and one with (but both with the same value of ).555Specifically: if is an even integer, then could be either or . If is an odd integer, then the two options are and . We will show that the output is independent of the choice we make.
-
2.
Let .
-
3.
For each , set .
-
4.
Set .
The fact that is well-defined, regardless of the non-unique decompositions when is boolean follows from the facts that (a) the vector is independent of how those choices are made (already noted above), and (b) when , we have and (shown earlier for points where close to or ), so that , regardless of whether we chose to use or .
We can now analyze the guarantees this provides. For every , since for all we get
recalling the radius of established earlier. Next, consider any ball of radius at most . We claim that for an ball that is entirely contained within a single unit hypercube whose corners are in , and thus by the guarantees of . The reason is that if is within distance from a face of a unit hypercube, , where is the projection of to . Thus we can remove portions of that are on the opposite side of a face from its center without changing . (More formally, if we write , then for any dimension where there is an integer strictly between and , we can replace the interval with the shorter of and without changing )
Therefore, is a -deterministic rounding scheme of radius
References
- [1] Mark Bun, Marco Gaboardi, Max Hopkins, Russell Impagliazzo, Rex Lei, Toniann Pitassi, Satchit Sivakumar, and Jessica Sorrell. Stability is stable: Connections between replicability, privacy, and adaptive generalization. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, STOC 2023, pages 520–527, New York, NY, USA, 2023. Association for Computing Machinery. doi:10.1145/3564246.3585246.
- [2] Mark Bun, Kobbi Nissim, Uri Stemmer, and Salil Vadhan. Differentially private release and learning of threshold functions. In Proceedings of the 56th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘15), pages 634–649. IEEE, 18–20 october 2015. Full version posted as arXiv:1504.07553. arXiv:1504.07553.
- [3] Jesus A De Loera, Elisha Peterson, and Francis Edward Su. A polytopal generalization of Sperner’s lemma. Journal of Combinatorial Theory, Series A, 100(1):1–26, 2002. doi:10.1006/JCTA.2002.3274.
- [4] Peter Dixon, A. Pavan, Jason Vander Woude, and N. V. Vinodchandran. List and certificate complexities in replicable learning. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS ‘23), NeurIPS ’23, Red Hook, NY, USA, 2023. Curran Associates Inc.
- [5] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. In Theory of cryptography, volume 3876 of Lecture Notes in Comput. Sci., pages 265–284. Springer, Berlin, 2006. doi:10.1007/11681878_14.
- [6] Cynthia Dwork and Aaron Roth. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci., 9(3-4):211–407, 2014. doi:10.1561/0400000042.
- [7] Simson L. Garfinkel and Philip Leclerc. Randomness concerns when deploying differential privacy. In WPES@CCS, pages 73–86. ACM, 2020. doi:10.1145/3411497.3420211.
- [8] Badih Ghazi, Ravi Kumar, and Pasin Manurangsi. User-level differentially private learning via correlated sampling. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 20172–20184, 2021. URL: https://proceedings.neurips.cc/paper/2021/hash/a89cf525e1d9f04d16ce31165e139a4b-Abstract.html.
- [9] Ilya Mironov, Omkant Pandey, Omer Reingold, and Salil Vadhan. Computational differential privacy. In S. Halevi, editor, Advances in Cryptology—CRYPTO ‘09, volume 5677 of Lecture Notes in Computer Science, pages 126–142. Springer-Verlag, 16–20 august 2009. doi:10.1007/978-3-642-03356-8_8.
- [10] Salil P. Vadhan. The complexity of differential privacy. In Tutorials on the Foundations of Cryptography, pages 347–450. Springer International Publishing, 2017. doi:10.1007/978-3-319-57048-8_7.
- [11] Jason Vander Woude, Peter Dixon, Aduri Pavan, Jamie Radcliffe, and N. V. Vinodchandran. Geometry of rounding. CoRR, abs/2211.02694, 2022. doi:10.48550/arXiv.2211.02694.
- [12] Jason Vander Woude, Peter Dixon, Aduri Pavan, Jamie Radcliffe, and N. V. Vinodchandran. Geometry of rounding: Near optimal bounds and a new neighborhood Sperner’s lemma. CoRR, abs/2304.04837, 2023. doi:10.48550/arXiv.2304.04837.