Unraveling Universally Closest Refinements via Symmetric Density Decomposition and Fisher Market Equilibrium

Abstract
We investigate the closest distribution refinements problem, which involves a vertex-weighted bipartite graph as input, where the vertex weights on each side sum to 1 and represent a probability distribution. A refinement of one side’s distribution is an edge distribution that corresponds to distributing the weight of each vertex from that side to its incident edges. The objective is to identify a pair of distribution refinements for both sides of the bipartite graph such that the two edge distributions are as close as possible with respect to a specific divergence notion. This problem is a generalization of transportation, in which the special case occurs when the two closest distributions are identical. The problem has recently emerged in the context of composing differentially oblivious mechanisms.
Our main result demonstrates that a universal refinement pair exists, which is simultaneously closest under all divergence notions that satisfy the data processing inequality. Since differential obliviousness can be examined using various divergence notions, such a universally closest refinement pair offers a powerful tool in relation to such applications.
We discover that this pair can be achieved via locally verifiable optimality conditions. Specifically, we observe that it is equivalent to the following problems, which have been traditionally studied in distinct research communities: (1) hypergraph density decomposition, and (2) symmetric Fisher Market equilibrium.
We adopt a symmetric perspective of hypergraph density decomposition, in which hyperedges and nodes play equivalent roles. This symmetric decomposition serves as a tool for deriving precise characterizations of optimal solutions for other problems and enables the application of algorithms from one problem to another. This connection allows existing algorithms for computing or approximating the Fisher market equilibrium to be adapted for all the aforementioned problems. For example, this approach allows the well-known iterative proportional response process to provide approximations for the corresponding problems with multiplicative error in distributed settings, whereas previously, only absolute error had been achieved in these contexts. Our study contributes to the understanding of various problems within a unified framework, which may serve as a foundation for connecting other problems in the future.
Keywords and phrases:
closest distribution refinements, density decomposition, Fisher market equilibriumFunding:
T-H. Hubert Chan: This research was partially supported by the Hong Kong RGC grants 17201823, 17203122 and 17202121.Copyright and License:
2012 ACM Subject Classification:
Mathematics of computing Distribution functions ; Theory of computation Mathematical optimizationEditors:
Raghu MekaSeries and Publisher:
1 Introduction
In this work, we explore several existing and new problems
under the same unifying framework. By unraveling
previously unknown connections between these seemingly unrelated problems,
we offer deeper insights into them.
Moreover, existing solutions for one problem can readily
offer improvements to other problems. Input instances
for these problems all have the following form.
Input Instance. An instance
is a vertex-weighted bipartite graph
with vertex bipartition ,
edge set and positive111Vertices with
zero weights are removed and identified with the empty set . vertex weights .
For some problems, it is convenient to normalize the vertex weights
into distributions, i.e., the vertex weights on each side sum to 1;
in this case, we call this a distribution instance.
We use to index the two sides.
Given a side , we use to denote the other side.
Solution Concept. We shall see that in each
problem, refinement is the underlying solution concept.
Given a side , a refinement222Since vertex weights on one
side can be interpreted as a probability distribution,
allocating the weight of each vertex to its incident edges
can be viewed as a refinement of the original distribution.
on vertex weights on side indicates how each vertex distributes its weight among its incident edges in .
In other words, is a vector of edge weights in
such that for each , the sum of weights of edges incident on
equals . While some problems may require refinements of vertex weights
from one side only, it will still be insightful to consider
a refinement pair
of vertex weights on both sides.
The main problem we focus on is the closest distribution refinement problem, which we show is intricately related to other problems. In probability theory, a divergence notion quantifies how close two distributions are to each other, where a smaller quantity indicates that they are closer. Common examples of divergences include total variation distance and KL-divergence. Observe that a divergence notion needs not be symmetric, i.e. for two distributions and on the same sample space, it is possible that .
Definition 1 (Closest Distribution Refinement Problem).
Given a distribution instance and a divergence notion , the goal is to find a distribution refinement pair such that the distributions and on the edges are as close to each other as possible under , i.e., is minimized.
Universally Closest Refinement Pair. It is not clear a priori if a refinement pair achieving the minimum for one divergence notion would also achieve the minimum for another divergence notion. For a non-symmetric divergence , a pair minimizing may not necessarily achieve the minimum . The special case when consists of a pair of identical refinements is also known as -transportation or perfect fractional matching [9, 27, 34, 6], in which case is obviously the minimizer for all divergences.
In general, it would seem ambitious to request a universally closest refinement pair that simultaneously minimizes all “reasonable” divergence notions. In the literature, all commonly used divergence notions satisfy the data processing inequality, which intuitively says that the divergence of two distributions cannot increase after post-processing. Formally, for any deterministic function , the induced distribution and on satisfy the inequality: . Surprisingly, we show that such a universally closest pair exists.
Theorem 2 (Universally Closest Refinement Pair).
Given a distribution instance, there exists a distribution refinement pair that minimizes simultaneously for all divergence notions that satisfy the data processing inequality.
Moreover, this pair can be returned using the near-linear time algorithm of Chen et al. [14] for the minimum quadratic-cost flow problem.
Since Definition 1 gives a clean mathematical problem, we first describe the technical contributions and approaches of this work, and we describe its motivation and application in Section 1.2.
While the technical proofs are given in Sections 4 and 5, we give some motivation for why the problem is studied in the first place and sketch the key ideas for our proofs.
1.1 Our Technical Contributions and Approaches
In addition to the problem in Definition 1,
we shall see that the following solution properties
are also the key to solving other problems as well.
Desirable Solution Properties. Two desirable
solution properties are local maximin and proportional
response.
-
Local Maximin. A refinement on vertex weights on side can also be interpreted as how each vertex in allocates its weight to its neighbors on the other side via the edges in . Specifically, for and , is the payload received by from , where we rely on the superscript in to indicate that the payload is sent from side to side along an edge in . Consequently, induces a payload vector , where is the total payload received by in the allocation . Recalling that vertex also has a weight, the payload density (resulting from ) of is .
The refinement is locally maximin if for each , vertex distributes a non-zero payload to vertex only if is among the neighbors of with minimum payload densities (resulting from ).
The intuition of the term “maximin” is that vertex tries to maximize the minimum payload density among its neighbors by giving its weight to only neighbors that achieve the minimum payload density.
-
Proportional Response. Given a refinement on vertex weights on side , its proportional response is a refinement on vertex weights from the other side . Specifically, vertex distributes its weight proportionately according to its received payloads: .
Several problems in the literature studied in different contexts can be expressed with the same goal.
Goal 3 (High-Level Goal).
Given an instance , find a refinement pair such that both refinements are locally maximin and proportional response to each other.
This abstract problem have been studied extensively in the literature under different contexts, and various algorithms to exactly achieve or approximate (whose meaning we will explain) Goal 3 have been designed. One contribution of this work is to unify all these problems under our abstract framework. Consequently, we readily offer new approximation results for some problems that are unknown before this connection is discovered.
We next describe how our abstract framework is related to each considered problem and what new insights or results are achieved, which also provide the tools to solve or approximate the problem in Definition 1.
1.1.1 Hypergraph Density Decomposition
An instance is interpreted as a hypergraph . Each element in is a hyperedge and each element in is a node, where means that node is contained in hyperedge . Observe that in this hypergraph, both the hyperedges and the nodes are weighted.
Densest Subset Problem.
Given a subset of nodes in a (weighted) hypergraph, its density is , where is the collection of hyperedges containing only nodes inside . The densest subset problem requests a subset with the maximum density.
Density Decomposition.
The decomposition can be described by an iterative process that generates a density vector for the nodes in the hypergraph by repeated peeling off densest subsets. First, the (unique) maximal densest subset is obtained, and each will be assigned the density of . Then, the hyperedges and the subset are removed from the instance; note that any hyperedge containing a node outside will remain. The process is applied to the remaining instance until eventually every node in is removed and assigned its density. The collection of subsets found in the iterative process forms the density decomposition .
Connection with the Local Maximin Condition.
Charikar [13] gave an LP (that can be easily generalized to weighted hypergraphs) which solves the densest subset problem exactly, and a refinement on the weights of hyperedges corresponds exactly to a feasible solution of the dual LP. Replacing the linear function in this dual LP with a quadratic function while keeping the same feasible variable , Danisch et al. [15] considered a quadratic program (that has also appeared in [19]). They showed that a refinement corresponds to an optimal solution to the quadratic program iff it is locally maximin333Instead of using the term “maximin”, the same concept is called “stability” in [15].. Moreover, a locally maximin refinement also induces the aforementioned density vector .
As observed in [22], the quadratic program can be expressed as a minimum quadratic-cost flow problem, which can be solved optimally using the nearly-linear time algorithm of Chen et al. [14]. As we shall show that our considered problems are all equivalent to Goal 3, this implies the algorithmic result in Theorem 2.
Symmetry of Density Decomposition.
We observe that the density decomposition is symmetric between the hyperedges and the nodes. Recall that in iteration of the density decomposition, a subset is produced, together with its corresponding collection of hyperedges that determines the density . Therefore, in addition to a partition of nodes, there is a corresponding decomposition of the hyperedges .
Given an abstract instance , one could have interpreted it differently with as nodes and as hyperedges. When the density decomposition is constructed with the roles reversed, the exact sequence of pairs is obtained, but in reversed order. Intuitively, is the densest from the perspective of , but it is the least dense from the perspective of .
The symmetric nature of the density decomposition has been mentioned recently by Harb et al. [23, Theorem 13], but we shall explain later this fact may be inferred when different earlier works are viewed together. Hence, this observation may be considered as part of the folklore. Since we need some crucial properties of the symmetric density decomposition to prove Theorem 2, for the sake of completeness, the connection of Goal 3 and this folklore result is described in Section 3.
Approximation Notions.
Even though the exact density decomposition can be achieved via LP or maximum flow, it can be computationally expensive in practice. In the literature, efficient approximation algorithms have been considered. While there are different attempts to define approximation notions for density decompositions, it is less clear what they mean when they are applied to different problems.
Observe that a refinement pair achieving Goal 3 may not be unique, but the induced payload vectors and density vectors are unique. When we say approximating Goal 3, we mean finding a refinement pair such that the induced payload and density vectors have some approximation guarantees. We shall see that approximation guarantees444See Definition 12 for approximation notions of muliplicative vs absolute errors on vectors. on these vectors can be translated readily to approximation notions for various problems.
1.1.2 Unraveling Universally Closest Distribution Refinements via Symmetric Density Decomposition
Restricted Class of Divergence.
As a first step towards proving Theorem 2, we consider a restricted class of divergences known as hockey-stick divergence. For each ,
The hockey-stick divergence is related to the well-known -differential privacy inequality. Specifically, iff for all subsets ,
Universal Refinement Matching Problem.
Given an instance and two non-negative weights , we use to denote the instance of (fractional) maximum matching on the bipartite graph with vertex capacity constraints. For side and , the capacity constraint at vertex is . A fractional solution consists of assigning non-negative weights to the edges in such that the weighted degree of every vertex does not exceed its capacity constraint. Observe that for any refinement pair , the fractional matching defined below is a feasible solution to :
The goal is to find a refinement pair such that for any weight pair , the edge weights form an optimal (fractional) solution to the maximum matching instance .
The structure of the symmetric density decomposition described in Section 1.1.1 makes it convenient to apply a primal-dual analysis to achieve the following in Section 4.
Theorem 4 (Universal Maximum Refinement Matching).
Given an instance , suppose a distribution refinement pair satisfies Goal 3. Then, for any , the (fractional) solution is optimal for the maximum matching instance .
Extension to General Case.
To extend Theorem 2
beyond the restricted divergence class
,
we consider the closest distribution refinement
problem under a more general probability distance
notion.
Capturing All Data Processing Divergences via Power Functions.
As opposed to using a single number by a divergence notion
to measure the closeness of two distributions,
the power function
between distributions
and captures enough information to recover all divergence notions that satisfy
the data processing inequality.
We will give a formal explanation in Section 5.
A main result is given in Theorem 37, which states that
any distribution refinement pair satisfying Goal 3
achieves the minimal power function,
from which Theorem 2 follows immediately.
Approximation Results.
In the full version [12], we show that a refinement that induces a payload with multiplicative error can lead to approximation guarantees for other problems. For the universal refinement matching problem, a natural approximation notion is based on the standard approximation ratio for the maximum matching problem.
On the other hand, achieving a meaningful approximation notion for the universally closest distribution refinement problem in terms of divergence values is more difficult. The reason is that any strictly increasing function on a data processing divergence still satisfies the data processing inequality. Therefore, any non-zero deviation from the correct answer may be magnified arbitrarily. Instead of giving approximation guarantees directly on the divergence values, we consider a technical notion of power function stretching, and the approximation quality of a refinement pair is quantified by how much the optimal power function is stretched. The formal statement is given in the full version [12].
1.1.3 Achieving Multiplicative Error via Proportional Response in Fisher Markets
We next interpret an instance as a special symmetric case of linear Fisher markets [18], which is itself a special case of the more general Arrow-Debreu markets [2]. This allows us to transfer any algorithmic results for Fisher/Arrow-Debreu market equilibrium to counterparts for Goal 3. Specifically, we can use a quick iterative procedure proportional response [39, 40] to approximate the densities of vertices in the density decomposition in Section 1.1.1 with multiplicative error, where only absolute error has been achieved before [15, 22]. In addition to being interesting in its own right, multiplicative error is also used to achieve the approximation results in Section 1.1.2.
Market Interpretation.
Even though in an instance, the roles of the two sides
are symmetric, it will be intuitive to think of
as buyers and as sellers.
For buyer , the weight is its budget.
In the symmetric variant, the utilities of buyers have a special form.
Each seller has one divisible unit of good
for which a buyer has a positive utility exactly when
, in which case the utility per unit of good
is (that is common for all buyers that have a positive utility for ).
For a general Fisher market, a buyer can have
an arbitrary utility for one unit of good .
Market Allocation and Equilibrium.
For the symmetric variant, an allocation
can be represented by a refinement pair ,
in which must be a proportional response to .
For the refinement on the buyers’ budgets,
the induced payload vector on the sellers corresponds to the price vector
on goods.
For the refinement on the sellers’ weights,
the induced payload vector on the buyers corresponds
to the utilities received by the buyers.
It is well-known (explained in the full version [12])
that
a market equilibrium is characterized by a locally maximin
refinement of buyers’ budgets
together with its proportional response .
From our theory of symmetric density decomposition in Section 1.1.1,
this is equivalent to Goal 3.
Alternative Characterization.
The fact that the local maximin condition on the buyers’ budget allocation is equivalent to Fisher market equilibrium readily allows us to borrow any algorithmic results for market equilibrium to solve or approximate Goal 3. In the full version [12], we give details on the following observations.
-
In linear Fisher markets (not necessarily symmetric), we show that the local maximin condition on sellers’ goods allocation to buyers can be used to characterize a market equilibrium. This is an alternative characterization of linear Fisher market equilibrium that involves only goods allocation and buyers’ utilities, but not involving good prices.
-
On the other hand, we show that there exists an Arrow-Debreu market such that there is a goods allocation satisfying the local maximin condition, but it is not an equilibrium.
1.2 Motivation and Application for Universally Closest Distribution Refinements
The problem in Definition 26 arises in the study of the composition of differentially oblivious mechanisms [41, 42], which is a generalization of the more well-known concept of differential privacy (DP) [17].
A Quick Introduction to Differential Privacy/Obliviousness.
Consider a (randomized) mechanism that takes an input from space and returns an output from space that will be passed to a second mechanism. During the computation of , an adversary can observe some view from space that might not necessarily include the output in general. Suppose at first we just consider the privacy/obliviousness of on its own, which measures how much information the adversary can learn about the input from its view. Intuitively, it should be difficult for the adversary to distinguish between two similar inputs from their corresponding views produced by the mechanism. Formally, similar inputs in are captured by a neighboring symmetric relation, and the privacy/obliviousness of the mechanism requires that the two distributions of views produced by neighboring inputs are “close”, where closeness can be quantified by some notion of divergence. As mentioned in Section 1.1.2, the popular notion of -DP is captured using hockey-stick divergences.
Composition of Differentially Oblivious Mechanisms.
Suppose the output of mechanism from space is passed as an input to a second mechanism , which is differentially oblivious with respect to some neighboring relation on . Hence, given input to , one should consider the joint distribution on the space of views and outputs.
The notion of neighbor-preserving differential obliviousness (NPDO) has been introduced [41, 42] to give sufficient conditions on that allows composition with such a mechanism so that the overall composition preserves differential obliviousness.
Specifically, given neighboring inputs , conditions are specified on the two distributions and . Unlike the case for differential privacy/obliviousness, it is not appropriate to just require that the two distributions are close. This is because the adversary can only observe the view component of . Moreover, one also needs to incorporate the neighboring relation on the output space , which is needed for the privacy guarantee for the second mechanism .
The definition of NPDO is more conveniently described via the terminology offered by our abstract instance . Here, the sets and are two copies of . For each , the weights on corresponds to the distribution . Finally, and are neighbors in iff and are neighboring in .
In the original definition [42], the mechanism is said to be -NPDO with respect to divergence if for the constructed instance , there exists a distribution refinement pair , which may depend on the divergence , such that . Examples of considered divergences include the standard hockey-stick divergence and Rényi divergence [31].
Since it only makes sense to consider divergences satisfying the data processing inequality in the privacy context, the universally closest refinement pair guaranteed in Theorem 2 makes the notion of NPDO conceptually simpler, because the closest refinement pair does not need to specifically depend on the considered divergence.
We believe that this simplification will be a very useful tool. In fact, to achieve advanced composition in [42], a very complicated argument has been used to prove the following fact, which is just an easy corollary of Theorem 2.
Fact 5 (Lemma B.1 in [42]).
Given a distribution instance , suppose there exist two refinement pairs and such that the hockey-stick divergences and are both at most .
Then, there exists a single refinement pair such that both and are at most .
1.3 Related Work
The densest subset problem is a classical problem in combinatorial optimization with numerous real-world applications in data mining, network analysis, and machine learning [21, 13, 26, 30, 1, 35, 29], and it is the basic subroutine in defining the density decomposition.
Density Decomposition.
As mentioned in Section 1.1.1, the earliest reference to the density decomposition and its associated quadratic program were introduced by Fujishige [19]. Even though this decomposition was defined for the more general submodular or supermodular case, the procedure has been rediscovered independently many times in the literature for the special bipartite graph case (or equivalently its hypergraph interpretation).
Earlier we described the decomposition procedure by repeatedly peeling off maximal densest subsets in a hypergraph. This was the approach by Tatti and Gionis [37, 36] and Danisch et al. [15] . Moreover, the same procedure has been used to define hypergraph Laplacians in the context of the spectral properties of hypergraphs [11].
In the literature, there is another line of research that defines the decomposition by repeatedly peeling off least densest subsets instead. However, given a subset of nodes in a weighted hypergraph , a different notion of density is considered: , where is the collection of hyperedges that have non-empty intersection with . The difference is that before we consider that is the collection of hyperedges totally contained inside . Then, an alternative procedure can be defined by peeling off a maximal least densest subset under and performing recursion on the remaining graph.
This was the approach used by Goel et al. [20] to consider the communication and streaming complexity of maximum bipartite matching. The same procedure has been used by Bernstein et al. [7] to analyze the replacement cost of online maximum bipartite matching maintenance. Lee and Singla [28] also used this decomposition to investigate the the batch arrival model of online bipartite matching. Bansal and Cohen [4] have independently discovered this decomposition procedure to consider maximin allocation of hyperedge weights to incident nodes.
Symmetric Nature of Density Decomposition.
At this point, the reader may ask how we know that the two procedures will give the same decomposition (but in reversed order). The answer is that exactly the same quadratic program has been used in [15] and [7] to analyze the corresponding approaches. This observation has also been made recently by Harb et al. [23, Theorem 13]. It is not too difficult to see that the least densest subset using the modified density is equivalent to the densest subset with the roles of vertices and hyperedges reversed. Therefore, Theorem 20 can also be obtained indirectly through these observations.
Connection between Density Decomposition and Fisher Market Equilibrium.
Even before this work in which we highlight the local maximin condition, density decomposition has already surreptitiously appeared in algorithms computing Fisher market equilibrium. Jain and Vazirani [24] considered submodular utility allocation (SUA) markets, which generalize linear Fisher markets. Their procedure [24, Algorithm 9] for computing an SUA market equilibrium can be viewed as a masqueraded variant of the density decomposition by Fujishige [19]. Buchbinder et al. [10] used a variant of SUA market equilibrium to analyze online maintenance of matroid intersections, where equilibrium prices are also obtained by the density decomposition procedure.
In this work, we observe conversely that algorithms for approximating market equilibrium can also be directly used for approximating density decompositions. For the simple special case in which the input graph contains a perfect fractional matching, Motwani et al. [32] showed that several randomized balls-into-bins procedures attempting to maintain the locally maximin condition can achieve -approximation.
Distributed Iterative Approximation Algorithms.
Even though efficient exact algorithms are known to achieve Goal 3, distributed iterative approximation algorithms have been considered for practical scenarios.
Density Decomposition.
By applying the first-order iterative approach of Frank-Wolfe to the quadratic program, Danisch et al. [15] showed that iterations, each of which takes work and may be parallelized, can achieve an absolute error of on the density vector . Harb et al. [23] showed that the method Greedy++ can be viewed as a noisy variant of Frank-Wolfe and hence has a similar convergence result.
By using a first-order method augmented with Nesterov momentum [33] such as accelerated FISTA [5], Elfarouk et al. [22] readily concluded that iterations can achieve an absolute error of . However, observe that if there is a vertex such that , an absolute error of may produce an estimate that is arbitrarily small.
Inspired by estimates of ,
several notions of approximate density decompositions have been considered in previous works [37, 15, 22].
However, it is not clear if there
is any meaningful interpretations of these approximate
decompositions in the context of
closest distribution refinements or market equilibrium.
Fisher Market Equilibrium.
Market dynamics have been considered to
investigate how agents’ mutual interaction can lead
to convergence to a market equilibrium.
The proportional response (PR, aka tit-for-tat) protocol
has been used by Wu and Zhang [39]
to analyze bandwidth trading in a peer-to-peer network
with vertex weights . This can be seen as a special case of
our instance
, where and are two copies
of , and and are neighbors
in iff the corresponding pair
are neighbors in .
Interestingly,
they consider a bottleneck decomposition
of the graph which can be recovered from our symmetric density decomposition.
They showed that the PR protocol converges to some equilibrium under this special model.
Subsequently, Zhang [40] showed that the PR protocol can be applied in Fisher markets between buyers and sellers, and analyzed the convergence rate to the market equilibrium in terms of multiplicative error. Birnbaum et al. [8] later improved the analysis of the PR protocol by demonstrating that it can be viewed as a generalized gradient descent algorithm.
1.4 Potential Impacts and Paper Organization
This work unifies diverse problems under a single framework, revealing connections and providing new approximation results. Future research directions are abundant. Examining the implications of various market models or equilibrium concepts on the densest subset problem and density decomposition opens the door for further exploration of the relationships between economic markets and combinatorial optimization problems. This line of inquiry could also lead to new insights into economics, particularly regarding market participants’ behavior and the efficiency of different market mechanisms.
Paper Organization.
In Section 2, we introduce the precise notation that will be used throughout the paper. In Section 3, we summarize the structural results regarding
the symmetric density decomposition, which is used as a technical tool to analyze other problems.
As mentioned in the introduction,
Section 4 investigates the
universal refinement matching problem which is the precursor
for tackling the more challenging universally
closest distribution refinements problem in Section 5.
In Section 5.1, we first consider
the special case of hockey-stick divergences; by considering power functions,
we prove Theorem 2 in Section 5.2.
Additional Materials in the Full Version.
In the full version [12],
we present approximation results for the universal closest refinements problem
by defining a stretching operation on power functions.
Moreover,
we recap the connection
between the symmetric density decomposition and
the symmetric Fisher market equilibrium.
We give an alternative characterization of the Fisher market equilibrium
in terms of the local maximin condition on sellers’ goods allocation to buyers. Furthermore,
we give details on the convergence rates of
how the iterative proportional response protocol
can achieve an approximation with multiplicative error
for Goal 3.
2 Preliminaries
We shall consider several problems, whose inputs are in the form of vertex-weighted bipartite graphs.
Definition 6 (Input Instance).
An instance of the input consists of the following:
-
Two disjoint vertex sets and .
For the side , we use to indicate the other side different from .
-
A collection of unordered pairs of vertices that is interpreted as a bipartite graph between vertex sets and ; in other words, if , then exactly one element of is in and the other is in . In this case, we also denote or just .
A vertex is isolated if it has no neighbor.
-
Positive555Vertices with zero weight do not play any role and may be excluded. vertex weights ; for a vertex , we use or to denote its weight.
For , we also use to denote the weight vector for each side.
This notation highlights the symmetry between the two sets and .
Remark 7.
In this work, we focus on the case that and are finite. Even though it is possible to extend the results to continuous and uncountable sets (which are relevant when those sets are interpreted as continuous probability spaces), the mathematical notations and tools involved are outside the scope of the typical computer science community.
Definition 8 (Allocation Refinement and Payload).
Given an input instance as in Definition 6, for side , an allocation refinement (or simply refinement) of can be interpreted as edge weights on such that for each non-isolated vertex ,
In other words, if a vertex has at least one neighbor, it distributes its weight among its neighboring edges such that . These edge weights due to the refinement can be interpreted as received by vertices on the other side ; this induces a payload vector defined by:
With respect to the weights of vertices in , the (payload) density is defined by:
When there is no risk of ambiguity, the superscripts and may be omitted.
Definition 9 (Proportional Response).
Suppose for side , is a refinement of the vertex weights on . Then, a proportional response to is a refinement of the vertex weights on the other side satisfying the following:
-
If receives a positive payload from , then for each ,
.
-
If a non-isolated vertex receives zero payload from , then in , vertex may distributes its weight arbitrarily among its incident edges in .
Definition 10 (Local Maximin Condition).
Given an input instance as in Definition 6, for , suppose a refinement of induces a payload density vector as in Definition 8. Then, is locally maximin if,
In other words, the local maximin condition states that each vertex attempts to send a positive weight to a neighbor only if achieves the minimum among the neighbors of .
Remark 11.
Observe that if satisfies the local maximin condition, then every non-isolated vertex in must receive a positive payload. This means that its proportional response is uniquely determined.
Definition 12 (Notions of Error).
Given a vector , we consider two notions of error for an approximation vector .
-
Absolute error with respect to norm . We have: .
A common example is the standard -norm.
-
Multiplicative error . For all coordinates , .
3 Folklore: Symmetric Density Decomposition
An instance , as in Definition 6, may be interpreted as a hypergraph . We have the vertex set (aka the ground set) and the hyperedge set (aka the auxiliary set), where and are neighbors in iffthe hyperedge contains the vertex . Moreover, assigns weights to both and in the hypergraph.
Notation: Ground and Auxiliary Sets.
For side ,
the open neighborhood
of a non-empty subset
consists of vertices on the other side that
have at least one neighbor in , i.e.,
.
Its closed neighborhood
is ,
i.e., a vertex is in
iff it has at least one neighbor and all its neighbors
are contained in .
Its density is defined as ,
where the superscript may be omitted when the context is clear.
When we consider the densities of subsets
in , the set plays the role of the
ground set and the set plays the role of
the auxiliary set.
Observe that this definition is consistent
with the hypergraph interpretation when plays the role of
the vertex set .
Extension to Empty Set.
In some of our applications, it makes sense to have isolated vertices
in the input instance.
For ,
we extend .
For the purpose of defining ,
we use the convention that and
for .
Definition 13 (Densest Subset).
When plays the role of the ground set, a subset is a densest subset, if it attains .
The following well-known fact characterizes a property of maximal densest subset (see [3, Lemma 4.1] for a proof).
Fact 14.
With respect to set inclusion, the maximal densest subset in is unique and contains all densest subsets.
Definition 15 (Sub-Instance).
Given an instance , the subsets and naturally induces a sub-instance , where and are restrictions of and , respectively, to .
The following definition is essentially the same as the density decomposition of a hypergraph [37, 36].
Definition 16 (Density Decomposition with Ground Set).
Given an instance , suppose for , we consider as the ground set. The density decomposition with as the ground set is a sequence of pairs , together with a density vector , defined by the following iterative process.
Initially, we set to be the original given instance, and initialize .
-
1.
If is an instance where the vertex sets on both sides are empty, the process stops.
-
2.
Otherwise, let be the maximal densest subset in with side being the ground set, where is the corresponding density; let be its closed neighborhood in .
For each , define .
-
3.
Let be the sub-instance induced by removing and from ; note that edges in incident to removed vertices are also removed.
Increment and go to the next iteration.
Remark 17 (Isolated Vertices).
Observe that if each side has isolated vertices that have no neighbors, then they will also appear at the beginning and the end of the decomposition sequence as and .
When is the ground set, the density of vertices in is zero. In the rest of this section, we may assume that isolated vertices are removed from the instance.
The following fact has been proved in [15] when the vertices in the ground set have uniform weights. The same proof generalizes to the case where both sides have general positive weights.
Fact 18 (Local Maximin Condition Gives Density Decomposition).
Given an instance , consider side as the ground set. Suppose is a refinement of the vertex weights on side , which induces the payload density vector on side as in Definition 8.
Suppose further that satisfies the local maximin condition in Definition 10. Then, coincides exactly with the density vector achieved by the density decomposition in Definition 16 with side being the ground set.
Moreover, if is a pair in the density decomposition, then is exactly the collection of vertices that send positive payload to in .
Symmetry in Density Decomposition.
In Definition 16, one side plays the role of the ground set. If we switch the ground set to the other side , the same sequence will be produced in the density decomposition, but in the reversed order. While a similar observation has been made by Harb et al. [23, Theorem 13], we re-establish this fact by considering the proportional response to a locally maximin refinement in the following lemma, whose proof is given in the full version [12].
Lemma 19 (Proportional Response to Locally Maximin Refinement).
Let be a refinement of vertex weights in that satisfies the local maximin condition. By Remark 11, suppose the refinement on vertex weights in is the unique proportional response to . Moreover, for each side , the refinement induces the payload density vector on vertices on the other side . Then, the following holds:
-
For any and such that and , their received payload densities due to the refinements satisfy .
-
The refinement also satisfies the local maximin condition.
-
We get back as the proportional response to .
In addition to being used to establish the symmetry of the density decomposition in Theorem 20, Lemma 19 will be used later as a technical tool for analyzing the universal refinement matching problem in Section 4.
Theorem 20 (Folklore: Symmetry of Density Decomposition).
Given an instance , suppose the sequence of pairs is the density decomposition using as the ground set.
Then, the density decomposition using as the ground set produces the same sequence of pairs in reversed order.
4 Universal Refinement Matching Problem
As mentioned in Section 1, an instance in Definition 6 can be interpreted as inputs in various problems. As a precursor to the universally closest distribution refinements problem studied in Section 5, we consider a matching problem. Here, an instance is interpreted as the input of the vertex-constrained fractional matching problem, where the vertex constraints on each side is scaled by the same multiplicative factor.
Definition 21 (Vertex-Constrained Matching Instance).
Given an instance as in Definition 6 and two non-negative weights , we use to denote the instance of (fractional) matching on the bipartite graph with vertex capacity constraints. For side and , the capacity constraint at vertex is .
LP Interpretation.
The maximum (fractional) matching problem instance is captured by the following linear program.
We will also consider the dual in our analysis:
Definition 22 (Fractional Matching Induced by Refinement Pair).
Given an instance and a non-negative weight pair , a refinement pair , where is a refinement on vertex weights in , induces a feasible fractional matching for that is denoted as follows:
, for all .
Remark 23.
The feasibility of the fractional matching to the instance follows directly because each is a refinement of the vertex weights in .
Definition 24 (Universal Refinement Pair for Matching).
Given an instance and , a refinement pair is -universal for matching in , if for any non-negative weight pair , the solution achieves -approximation for the maximum matching problem on .
For , we simply say is universal (for matching in ).
Intuition for Universal Refinement Pair.
Besides being a technical tool for later sections, the notion of a universal refinement pair is interesting in terms of understanding the structure of vertex-constrained bipartite matching. Suppose it is known that the vertex weights on each side are correlated and may vary but follow some fixed relative ratios among themselves. The idea of a universal refinement pair is that some pre-computation can be performed such that when the vertex weights on each side change proportionally, the matching can be updated quickly to get a (nearly) optimal solution without computing from scratch.
Observe that the density decomposition in Definition 16 does not change if the vertex weights on one side are multiplied by the same scalar. Informally, the decomposition identifies different levels of “congestion” when a matching is performed between vertices on the two sides. The following result formalizes the connection between the density decomposition and universal refinement pairs.
Lemma 25 (Local Maximin Achieves Universal for Matching).
Suppose in an instance , for side , the refinement on vertex weights in is locally maximin, and the refinement is the (unique) proportional response to . Then, the refinement pair is universal for matching in .
Moreover, suppose in the density decomposition, for side , is the payload density vector and is the payload vector. Then, for any , the weight of the maximum matching in is:
Proof.
By Lemma 19, and are proportional responses to each other and both are locally maximin. Fix some and we show that is an optimal solution to .
Let be the density decomposition with being the ground set. (Recall that the density decomposition is symmetric between and , where the forward or backward order of the sequence depends on which side is the ground set.)
From Fact 18, recall that and are non-zero only if there exists some such that .
Let and .
Observe that for , . Therefore, for all and , .
Moreover, for all , for all and , and are not neighbors in , from the definition of the density decomposition.
Hence, we can construct a feasible dual solution to as follows.
-
For : for , ; for , .
-
For : for , ; for , .
The dual feasibility of holds because if and such that , then it must be the case that and are not neighbors in .
Next, we check that the dual solution has the same objective value as the primal solution to .
Observe that for , for , we have
.
Hence, , where the first equality holds because restricted to is a refinement of vertex weights in .
Similarly, for , we have .
Therefore, the feasible primal solution and the feasible dual solution have the same objective value, which implies that both are optimal.
Finally, we compute the weight of the maximum matching in . For simpler notation, it is understood that in each sum below, we include only pairs such that both and are non-zero.
5 Universally Closest Distribution Refinements Problem
In this section, we show that when an instance is interpreted as two distributions on two sample spaces imposed with a neighboring relation, a refinement pair satisfying Goal 3 is an optimal solution to the universally closest distribution refinements problem.
Distribution Instance.
In Definition 6, an input is a distribution instance, if, in addition, we require that for each side , the vertex weights satisfies , i.e., is a probability distribution on .
Observe that given a distribution instance , for each side , a refinement of the vertex weights is a probability distribution on . A high-level problem is to find a refinement pair such that the distributions and on are as “close” to each other as possible.
Divergence Notion.
Given two distributions and on the same sample space , a notion of divergence measures how close two distributions are, where a smaller value typically means that the two distributions are closer. An example is the total variation distance . However, note that in general, a divergence needs not be symmetric, i.e., it is possible that . An example of a non-symmetric divergence notion is .
Definition 26 (Closest Refinement Pair).
Given a distribution instance and a divergence notion , a refinement pair (as in Definition 8) is closest (with respect to ) if, the pair attains the minimum among all refinement pairs, whose value we denote as .
Remark 27.
Since a divergence is typically continuous and the collection of refinement pairs forms a compact set, the minimum is attainable in such a case.
However, note that since is not necessarily symmetric, from Definition 26 alone, it is not clear if a pair minimizing would also minimize .
Definition 28 (Universally Closest Refinement Pair).
Given a distribution instance and a collection of divergence notions, a refinement pair is universally closest (with respect to ) if, for all , .
5.1 Class of Hockey-Stick Divergences
We first consider the class of hockey-stick divergences.
Definition 29 (Hockey-Stick Divergence).
Given distributions and on the same sample space and , the (reversed666In the literature, the hockey-stick divergence is defined with the roles of and interchanged: . We change the convention to make the notation consistent when we consider power functions later.) hockey-stick divergence is defined as
Remark 30.
The hockey-stick divergence is related to the well-known -differential privacy inequality. Specifically, iff for all subsets ,
To express the other direction of the inequality, i.e., , we could consider another parameter and keep the order of arguments in . Specifically, by considering the complement of events in the above inequality, we can deduce that: iff .
We consider universal closest distribution refinements with respect to the class of hockey-stick divergences .
The following lemma shows that the hockey-stick divergence is closely related to the matching instance defined in Definition 21.
Lemma 31 (Hockey-Stick Divergence and Matching).
Suppose is a distribution instance and is a refinement pair. For , consider the pair of weights .
Then, the weight of the fractional matching in the matching instance is exactly .
In order words, finding a closest refinement pair for the divergence is equivalent to finding a maximum matching in .
Proof.
Let .
Observe that .
Finally, the weight of the matching is:
as required.
Theorem 32 (Locally Maximin Pair is Closest for ).
Suppose in a distribution instance , is a distribution refinement pair that is locally maximin and proportional response to each other. Then, is universally closest with respect to the class of hockey-stick divergences.
Proof.
5.2 Class of Data Processing Divergences
Extending Theorem 32, we show that a locally maximin pair is actually the closest with respect to a wide class of divergences. In fact, for any reasonable usage of divergence, it is intuitive that taking a partial view of a pair of objects should not increase the divergence between them. This is formally captured by the data processing inequality.
Definition 33 (Data Processing Inequality).
A divergence notion satisfies the data processing inequality if given any two distributions and on the sample space and any function , the induced distributions and on satisfy the monotone property:
We use to denote the class of divergences satisfying the data processing inequality.
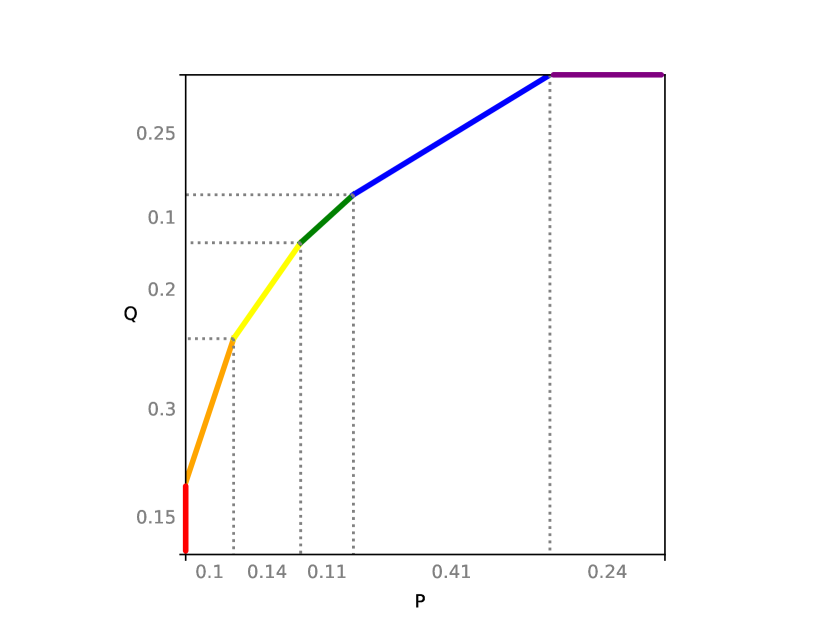
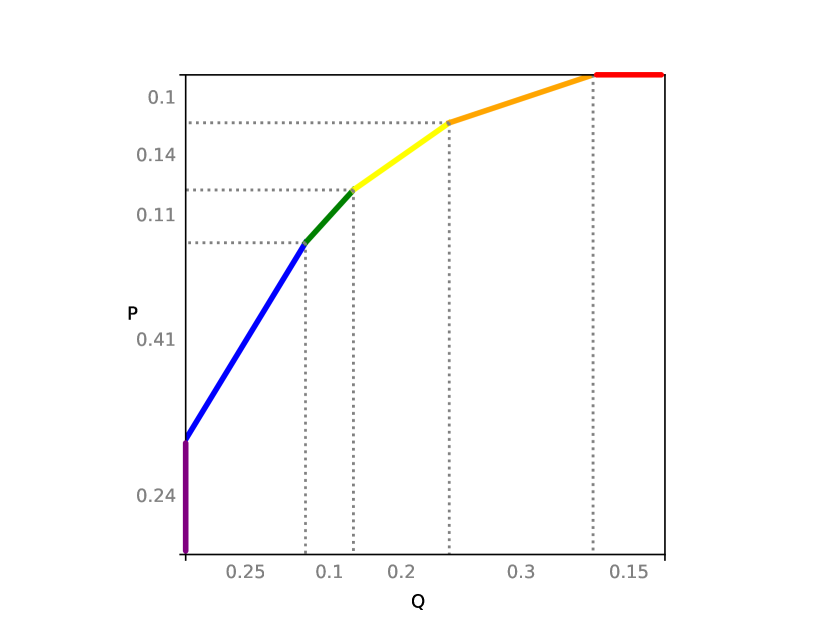
It is known that all divergences in between two distributions and can be recovered from the power function between them. Recall that in this work, we focus on finite sample spaces; see Figure 1 for an example. It is known that power functions have a fractional knapsack interpretation [25].
Definition 34 (Power Function).
Suppose and are distributions on the same sample space .
-
For a discrete sample space , the power function can be defined in terms of the fractional knapsack problem.
Given a collection of items, suppose has weight and value . Then, given , is the maximum value attained with weight capacity constraint , where items may be taken fractionally.
-
For a continuous sample space , given , is the supremum of over measurable subsets satisfying .
In the literature (see [16] for instance), the tradeoff function , which has essentially equivalent mathematical properties, has also been considered. However, power functions have the same notation interpretation as divergences in the sense that “smaller” means “closer” distributions. In fact, Vadhan and Zhang [38] defined an abstract concept of generalized probability distance (with the tradeoff function as the main example) such that the notation agrees with this interpretation. We recap some well-known properties of power functions.
Fact 35 (Valid power functions [16, Proposition 2.2]).
Suppose is a function. Then, there exist distributions and such that iff is continuous, concave and for all .
Partial Order on Power Functions.
We consider a partial order on power functions. Given such functions and , we denote iff for all , .
We next state formally how a divergence satisfying Definition 33 can be recovered from the power function.
Fact 36 (Recovering Divergence From Power Function [16, Proposition B.1]).
For any divergence , there exists a functional such that for any distributions and on the same sample space, .
Moreover, if , then .
The following is the main result of this section, which states that a locally maximin pair essentially solves the closest distribution refinement problem optimally in the most general sense.
Theorem 37 (Locally Maximin Pair Gives Minimal Power Function).
Suppose in a distribution instance , is a distribution refinement pair that is locally maximin and proportional response to each other. Then, the power function between any other distribution refinement pair of satisfies . Consequently, any such locally maximin pair gives rise to the same power function, and we denote .
From Fact 36, this implies that is a universally closest refinement pair with respect to .
Remark 38.
Observe that given any and any strictly increasing function , we still have . Since any deviation from the correct answer can be arbitrarily magnified by , it is difficult to give any meaningful approximation guarantee on the value of a general divergence in .
We prove Theorem 37 by analyzing the relationship between hockey-stick divergence and power function, and extend the result from Theorem 32. Similar to convex functions, we also consider the notion of subgradient for power functions.
Definition 39 (Subgradient).
Suppose is a power function and . Then, the subgradient of at is defined as the collection of real numbers satisfying:
iff for all , .
In other words, the line segment with slope touching the curve at never goes below the curve.
The following is a special case of Fact 36, and describes explicitly how a hockey-stick divergence is recovered from a power function. See Figure 2 for an illustration.
Fact 40 (Recovering Hockey-Stick Divergence From Power Function).
Suppose and are distributions on the same sample space , where is the power function between them. Then, for any , there exists such that and .
In other words, one can find a line segment with slope touching the curve and the -intercept of the line will give .
Proof.
The result should be standard, but we include a short proof for completeness. One can imagine a line segment with slope starting high above and gradually being lowered until touching the curve at some . Observe that the line segment may touch the curve at more than 1 point, in which case we take to be the infimum.
We partition the sample space into and . Observe that and .
Then, it follows that , as required.
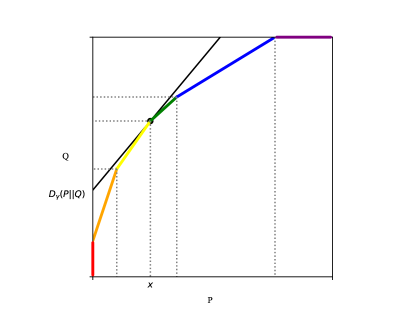
Proof of Theorem 37.
Suppose is the power function between the given locally maximin pair . For the sake of contradiction, suppose some other refinement pair produces the power function such that for some , .
Fix some and consider the line segment with slope touching curve at . By Fact 40, the hockey-stick divergence is the -intercept of .
However, since , to find a line segment with slope touching curve , we must move strictly upwards. This implies that , contradicting Theorem 32 which states that is universally closest with respect to .
References
- [1] Albert Angel, Nikos Sarkas, Nick Koudas, and Divesh Srivastava. Dense subgraph maintenance under streaming edge weight updates for real-time story identification. Proceedings of the VLDB Endowment, 5(6):574–585, 2012. doi:10.14778/2168651.2168658.
- [2] Kenneth J Arrow and Gerard Debreu. Existence of an equilibrium for a competitive economy. Econometrica: Journal of the Econometric Society, pages 265–290, 1954.
- [3] Oana Denisa Balalau, Francesco Bonchi, T.-H. Hubert Chan, Francesco Gullo, and Mauro Sozio. Finding subgraphs with maximum total density and limited overlap. In WSDM, pages 379–388. ACM, 2015. doi:10.1145/2684822.2685298.
- [4] Nikhil Bansal and Ilan Reuven Cohen. Contention resolution, matrix scaling and fair allocation. In WAOA, volume 12982 of Lecture Notes in Computer Science, pages 252–274. Springer, 2021. doi:10.1007/978-3-030-92702-8_16.
- [5] Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences, 2(1):183–202, 2009. doi:10.1137/080716542.
- [6] Roger E Behrend. Fractional perfect b-matching polytopes i: General theory. Linear Algebra and its Applications, 439(12):3822–3858, 2013.
- [7] Aaron Bernstein, Jacob Holm, and Eva Rotenberg. Online bipartite matching with amortized O(log n) replacements. J. ACM, 66(5):37:1–37:23, 2019. doi:10.1145/3344999.
- [8] Benjamin Birnbaum, Nikhil R Devanur, and Lin Xiao. Distributed algorithms via gradient descent for fisher markets. In Proceedings of the 12th ACM conference on Electronic commerce, pages 127–136, 2011. doi:10.1145/1993574.1993594.
- [9] Richard A Brualdi. Combinatorial matrix classes, volume 13. Cambridge University Press, 2006.
- [10] Niv Buchbinder, Anupam Gupta, Daniel Hathcock, Anna R. Karlin, and Sherry Sarkar. Maintaining matroid intersections online. In SODA, pages 4283–4304. SIAM, 2024. doi:10.1137/1.9781611977912.149.
- [11] T.-H. Hubert Chan, Anand Louis, Zhihao Gavin Tang, and Chenzi Zhang. Spectral properties of hypergraph laplacian and approximation algorithms. J. ACM, 65(3):15:1–15:48, 2018. doi:10.1145/3178123.
- [12] T.-H. Hubert Chan and Quan Xue. Symmetric splendor: Unraveling universally closest refinements and fisher market equilibrium through density-friendly decomposition. CoRR, abs/2406.17964, 2024. doi:10.48550/arXiv.2406.17964.
- [13] Moses Charikar. Greedy approximation algorithms for finding dense components in a graph. In Klaus Jansen and Samir Khuller, editors, Approximation Algorithms for Combinatorial Optimization, pages 84–95, Berlin, Heidelberg, 2000. Springer Berlin Heidelberg. doi:10.1007/3-540-44436-X_10.
- [14] Li Chen, Rasmus Kyng, Yang P. Liu, Richard Peng, Maximilian Probst Gutenberg, and Sushant Sachdeva. Maximum flow and minimum-cost flow in almost-linear time. In FOCS, pages 612–623. IEEE, 2022. doi:10.1109/FOCS54457.2022.00064.
- [15] Maximilien Danisch, T.-H. Hubert Chan, and Mauro Sozio. Large scale density-friendly graph decomposition via convex programming. In WWW, pages 233–242. ACM, 2017. doi:10.1145/3038912.3052619.
- [16] Jinshuo Dong, Aaron Roth, and Weijie J Su. Gaussian differential privacy. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1):3–37, 2022.
- [17] Cynthia Dwork. Differential privacy. In ICALP (2), volume 4052 of Lecture Notes in Computer Science, pages 1–12. Springer, 2006. doi:10.1007/11787006_1.
- [18] Irving Fisher. Mathematical investigations in the theory of value and prices, 1892.
- [19] Satoru Fujishige. Lexicographically optimal base of a polymatroid with respect to a weight vector. Mathematics of Operations Research, 5(2):186–196, 1980. doi:10.1287/MOOR.5.2.186.
- [20] Ashish Goel, Michael Kapralov, and Sanjeev Khanna. On the communication and streaming complexity of maximum bipartite matching. In SODA, pages 468–485. SIAM, 2012. doi:10.1137/1.9781611973099.41.
- [21] Andrew V Goldberg. Finding a maximum density subgraph, 1984.
- [22] Elfarouk Harb, Kent Quanrud, and Chandra Chekuri. Faster and scalable algorithms for densest subgraph and decomposition. Advances in Neural Information Processing Systems, 35:26966–26979, 2022.
- [23] Elfarouk Harb, Kent Quanrud, and Chandra Chekuri. Convergence to lexicographically optimal base in a (contra)polymatroid and applications to densest subgraph and tree packing. In ESA, volume 274 of LIPIcs, pages 56:1–56:17. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2023. doi:10.4230/LIPICS.ESA.2023.56.
- [24] Kamal Jain and Vijay V. Vazirani. Eisenberg-gale markets: Algorithms and game-theoretic properties. Games Econ. Behav., 70(1):84–106, 2010. doi:10.1016/J.GEB.2008.11.011.
- [25] Joseph B Kadane. Discrete search and the neyman-pearson lemma. Journal of Mathematical Analysis and Applications, 22(1):156–171, 1968.
- [26] Samir Khuller and Barna Saha. On finding dense subgraphs. In International colloquium on automata, languages, and programming, pages 597–608. Springer, 2009. doi:10.1007/978-3-642-02927-1_50.
- [27] Bernhard H. Korte. Combinatorial optimization: theory and algorithms. Springer, 2000.
- [28] Euiwoong Lee and Sahil Singla. Maximum matching in the online batch-arrival model. ACM Trans. Algorithms, 16(4):49:1–49:31, 2020. doi:10.1145/3399676.
- [29] Xiangfeng Li, Shenghua Liu, Zifeng Li, Xiaotian Han, Chuan Shi, Bryan Hooi, He Huang, and Xueqi Cheng. Flowscope: Spotting money laundering based on graphs. In Proceedings of the AAAI conference on artificial intelligence, volume 34(04), pages 4731–4738, 2020. doi:10.1609/AAAI.V34I04.5906.
- [30] Chenhao Ma, Yixiang Fang, Reynold Cheng, Laks VS Lakshmanan, Wenjie Zhang, and Xuemin Lin. Efficient algorithms for densest subgraph discovery on large directed graphs. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pages 1051–1066, 2020. doi:10.1145/3318464.3389697.
- [31] Ilya Mironov. Rényi differential privacy. In CSF, pages 263–275. IEEE Computer Society, 2017. doi:10.1109/CSF.2017.11.
- [32] Rajeev Motwani, Rina Panigrahy, and Ying Xu. Fractional matching via balls-and-bins. In APPROX-RANDOM, volume 4110 of Lecture Notes in Computer Science, pages 487–498. Springer, 2006. doi:10.1007/11830924_44.
- [33] Yurii Nesterov. A method for solving the convex programming problem with convergence rate . Proceedings of the USSR Academy of Sciences, 269:543–547, 1983. URL: https://api.semanticscholar.org/CorpusID:145918791.
- [34] Alexander Schrijver et al. Combinatorial optimization: polyhedra and efficiency, volume 24(2). Springer, 2003.
- [35] Kijung Shin, Tina Eliassi-Rad, and Christos Faloutsos. Corescope: Graph mining using k-core analysis – Patterns, anomalies and algorithms. In 2016 IEEE 16th international conference on data mining (ICDM), pages 469–478. IEEE, 2016. doi:10.1109/ICDM.2016.0058.
- [36] Nikolaj Tatti. Density-friendly graph decomposition. ACM Transactions on Knowledge Discovery from Data (TKDD), 13(5):1–29, 2019. doi:10.1145/3344210.
- [37] Nikolaj Tatti and Aristides Gionis. Density-friendly graph decomposition. In Proceedings of the 24th International Conference on World Wide Web, pages 1089–1099, 2015. doi:10.1145/2736277.2741119.
- [38] Salil P. Vadhan and Wanrong Zhang. Concurrent composition theorems for differential privacy. In STOC, pages 507–519. ACM, 2023. doi:10.1145/3564246.3585241.
- [39] Fang Wu and Li Zhang. Proportional response dynamics leads to market equilibrium. In Proceedings of the thirty-ninth annual ACM symposium on Theory of computing, pages 354–363, 2007. doi:10.1145/1250790.1250844.
- [40] Li Zhang. Proportional response dynamics in the fisher market. In ICALP (2), volume 5556 of Lecture Notes in Computer Science, pages 583–594. Springer, 2009. doi:10.1007/978-3-642-02930-1_48.
- [41] Mingxun Zhou, Elaine Shi, T.-H. Hubert Chan, and Shir Maimon. A theory of composition for differential obliviousness. In EUROCRYPT (3), volume 14006 of Lecture Notes in Computer Science, pages 3–34. Springer, 2023. doi:10.1007/978-3-031-30620-4_1.
- [42] Mingxun Zhou, Mengshi Zhao, T.-H. Hubert Chan, and Elaine Shi. Advanced composition theorems for differential obliviousness. In ITCS, volume 287 of LIPIcs, pages 103:1–103:24. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2024. doi:10.4230/LIPICS.ITCS.2024.103.