Error-Correcting Graph Codes

Abstract
In this paper, we construct Error-Correcting Graph Codes. An error-correcting graph code of distance is a family of graphs, on a common vertex set of size , such that if we start with any graph in , we would have to modify the neighborhoods of at least vertices in order to obtain some other graph in . This is a natural graph generalization of the standard Hamming distance error-correcting codes for binary strings.
Yohananov and Yaakobi were the first to construct codes in this metric. We extend their work by showing
-
1.
Combinatorial results determining the optimal rate vs distance trade-off nonconstructively.
-
2.
Graph code analogues of Reed-Solomon codes and code concatenation, leading to positive distance codes for all rates and positive rate codes for all distances.
-
3.
Graph code analogues of dual-BCH codes, yielding large codes with distance . This gives an explicit “graph code of Ramsey graphs”.
Several recent works, starting with the paper of Alon, Gujgiczer, Körner, Milojević, and Simonyi, have studied more general graph codes; where the symmetric difference between any two graphs in the code is required to have some desired property. Error-correcting graph codes are a particularly interesting instantiation of this concept.
Keywords and phrases:
Graph codes, explicit construction, concatenation codes, tensor codesFunding:
Swastik Kopparty: Research supported by an NSERC Discovery Grant.Copyright and License:
2012 ACM Subject Classification:
Mathematics of computing Coding theoryAcknowledgements:
We are grateful to Mike Saks, Shubhangi Saraf and Pat Devlin for valuable discussions.Editors:
Raghu MekaSeries and Publisher:
1 Introduction
In this paper, we studi Error-Correcting Graph Codes. These are large families of undirected graphs on the same vertex set such that any two graphs in the family are “far apart” in a natural graph distance. Informally, the graph distance between two graphs on the same vertex set of size measures the minimum number of vertices one needs to delete to make the resulting graphs identical (not just isomorphic). This can also be thought of as (1) the number of vertices whose neighborhoods one has to modify to go from one graph to another, (2) the vertex cover number of the symmetric difference of the two graphs, or (3) minus the largest independent set in the symmetric difference of the two graphs.
Definition (Graph Distance).
Given two graphs and on vertex set , the graph distance is the size of the smallest set such that .
This is a very natural metric and encompasses deep information about graphs. For example, note the following two simple facts (1) the graph distance of a graph from the empty graph is minus the independence number of the graph. (2) the graph distance of a graph from the complete graph is minus the clique number of the graph. Thus the answer to the question: “how far can a graph be from both the empty graph and the complete graph?” is precisely the question of finding the right bound for the diagonal Ramsey numbers; the answer is .
Additionally, the notion of graph distance arises in the definition of node differential privacy (see for example [5, 8, 11, 9]). One instantiation of this setting is a graph encoding a social network where vertices correspond to people and edges correspond to social connections. The goal for node differential privacy is to design an algorithm that approximately computes certain statistics of the graph (such as counting edges, triangles, and connected components) while maintaining each individual’s privacy. Here, privacy is ensured by requiring that the output distribution on a certain graph does not change by much with any one vertex is deleted. In other words, for any graphs , of graph distance , the output distribution of on the and should be similar. Graph distances of greater than are then considered in the continual release model where the graph varies over time as studied in [9].
Codes in the graph-distance metric were initially studied by Yohananov, Efron, and Yaakobi [19, 18], who gave several optimal and near-optimal constructions in a variety of parameters. Their setting allows for arbitrary symbols to be written on the edges, and the graph is allowed to have self-loops. We provide several new constructions for the binary setting, and the graph is not allowed to have self-loops. We show that random codes are asymptotically optimal codes in this metric and so focus our attention on explicit constructions.
Error-correcting graph codes also fall into the general framework of graph codes defined by Alon, Gujgiczer, Körner, Milojević, and Simonyi [3], where for a fixed family of graphs, one seeks a large code of graphs on the same -vertex set such that the symmetric difference of any two graphs in does not lie in . This class of problems was studied for a wide variety of natural in a number of recent works [3, 2, 1]. As discussed in [2], for a suitable choice of , graph codes become equivalent to classical Hamming distance codes.
Finally, we note that error-correcting codes are pseudorandom objects, and the connection to Ramsey graphs suggests that error-correcting graph codes might be closely related to pseudorandom graphs. Thus, the problem of studying and explicitly constructing a pseudorandom family of pseudorandom graphs is interesting in its own right.
1.1 Related work
Similar to the Hamming setting, we briefly define the dimension, rate, and distance of a graph code on vertices where each edge is allowed to have an arbitrary symbol written on it.
-
Dimension. .
-
Rate. .
-
Distance. The distance of a code is the largest such that for each such that . The relative distance is .
Unless specified otherwise , we will always be interested in asymptotics of the above parameters as .
As noted in [19], an argument similar to the Singleton bound states that for a graph code of dimension , and distance , we have
| (1) |
In terms of and rate , and relative distance , we have
| (2) |
A code is called optimal if it , equivalently, .
The relevant constructions in [19], [18] are summarized in Table 1. Note that all of the constructions in Table 1 are for undirected graphs where self-loops are allowed. One can impose linear constraints to get codes with no self-loops (zeros on the diagonals of the adjacency matrix). Since the block length of these codes is , adding these these constraints changes the rate by .
| Name | Field | Tradeoff | |
|---|---|---|---|
| [19] (Construction 1) | Optimal | ||
| [19] (Construction 3) | Optimal | ||
| [19] (Construction 5) | |||
| [18] (Construction 1) | Optimal | ||
| [18] (Construction 2) | Optimal |
Construction 5 of [19] leverages a connection to symmetric array codes and construction by Schmidt [15]. The trade-off achieved, is close to optimal for very small.
Construction 3 of [19] translates Hamming distance into graph distance using the tensor product. Although this construction doesn’t directly imply anything about binary codes due to the requirement on field size, a similar code will be an important ingredient in our constructions.
1.2 Results
Our main results are:
-
1.
We show that there are optimal binary codes for any constant .
-
2.
We give constructions of graph codes that have positive constant for all constant . In particular, we give a quasi-polynomial time explicit construction achieving , while optimal codes have . We also give an explicit construction with , and a strongly explicit construction with . Although these codes are not optimal, they are the first binary error-correcting graph codes achieving with a constant rate.
-
3.
We give (strongly) explicit constructions of graph codes with very high and for constant . This gives a “graph code of Ramsey graphs” as will be discussed later.
Independent work
Pat Devlin and Cole Franks [6] independently proposed the study of graph error-correcting codes under this metric, determined the optimal vs tradeoff, and gave some weaker explicit constructions of graph codes that worked for certain ranges of and .
1.3 Techniques
We now discuss our techniques. We will often specify graphs by their adjacency matrices, viewed as matrices with entries.
Our nonconstructive existence result is a straightforward application of the probabilistic method. We consider a uniformly random -linear subspace of the -linear space of symmetric -diagonal matrices (i.e., the space of all adjacency matrices of graphs); this turns out to give a good graph code with optimal vs tradeoff. Such graph codes can be specified by an basis for it. We say that a construction is explicit if this basis can be produced in time. We say it is strongly explicit if, given , the entry of the ’th basis element can be computed in time.
To get asymptotically good codes for any constant we take a longer detour.
-
1.
We start with a slight variation of [19] (Construction 3), which gives a way to get a good graph code from a classical Hamming-distance linear code . We first consider the tensor code , where the elements are matrices all of whose rows and columns are codewords of . A-priori, could contain matrices that are neither symmetric, not have a diagonal. But interestingly, if we consider the set of all matrices in that are symmetric and have diagonal, then is a linear space with quite large dimension. In particular, if the classical Hamming distance code has positive rate, then so does the graph code . We call this construction (Symmetric Tensor Code with Zero Diagonals).
It turns out that if has good relative distance (in the Hamming metric), then has good distance in the graph metric. However the relative graph distance of such a code is bounded by the relative distance of – and since is a binary code, this is at most .
-
2.
Now, we bring in another idea from the Hamming code world: code concatenation. Instead of constructing a graph code of symmetric zero-diagonal matrices over , we instead construct a “large-alphabet graph code” of symmetric zero-diagonal matrices over for some large and then try to reduce the alphabet size down to by replacing the -ary symbols with -matrices with suitable properties.
Applying the analog of to a large alphabet code allows one to get large-alphabet graph codes with large , approaching (since over large alphabets Hamming distance codes can have length approaching ). Using Reed-Solomon codes as these large alphabet codes also allows us to make the construction strongly explicit. Furthermore, when applied to Reed-Solomon codes, these codes have a natural direct description: these are the evaluation tables of low-degree bivariate polynomials on product sets that are (1) symmetric (to get a symmetric matrix), and (2) multiples of (to get zero diagonal).
-
3.
What remains now is to develop the right kind of concatenation so that the resulting graph code has good distance. This turns out to be subtle and requires an “inner code” with a stronger “directed graph distance” property with nearly 1. Fortunately, this inner code we seek is of very slowly growing size, and we may find this by brute force search. This concludes our description of our explicit construction of graph codes with approaching and positive constant .
Finally, we discuss our constructions for very high distances, . In this regime, as mentioned earlier, this is related to constructions of Ramsey graphs, a difficult problem in pseudorandomness with a long history. Our constructions work up to ; concretely, we get a large linear space of graphs such that all graphs in the family have no clique or independent set of size . The construction is based on polynomials over finite fields of characteristic : When , we consider a linear space of certain low degree univariate polynomials over , and create the matrix with rows and columns indexed by whose entry is . Here is the finite field trace map from to . The use of of polynomials is inspired by the construction of dual-BCH codes. We then show that any such matrix has no large clique or independent set unless is identically or identically (corresponding to the empty and complete graphs respectively). The proof uses the Weil bounds on character sums and a Fourier analytic approach to bound the independence number for the graphs. Our constructions are listed in Table 2.
| Name | Approximate Tradeoffs | Strongly Explicit? |
|---|---|---|
| Random Linear Codes (Proposition 4) | No | |
| Concatenated RS Tensor Codes (19) | No | |
| Double Concatenated RS Tensor Codes | No | |
| Triple Concatenated RS Tensor Codes (22) | Yes | |
| Dual BCH Codes (28) | Yes |
1.4 Concluding thoughts and questions
The most interesting question in this context is to obtain explicit constructions of graph codes with optimal vs tradeoff. While we have several constructions achieving nontrivial parameters in various regimes, it would even be interesting to get the right asymptotic behavior for the endpoints with approaching . The setting of large (including ) seems especially challenging, given the connection with the notorious problem of constructing Ramsey graphs.
Another interesting question is to get decoding algorithms for graph codes. For a certain graph code , if we are given a graph that is promised to be close in graph distance to some graph in . Then, can we efficiently find ?
A more general context relevant to error-correcting graph codes is the error correction of strings under more general error patterns. Suppose we have a collection of subsets for , where . These denote the corruption zones; a single “corruption” of a string entails, for some , changing to something arbitrary in . We want to design a code such that starting at any if we do fewer than corruptions to , we do not end up at any with . When the are all of size and form a partition of into parts, then such a code is exactly the same as a classical Hamming distance code an alphabet of size . Error-correcting graph codes give a first step into the challenging setting where the all pairwise intersect - here we have , , the (which correspond to all edges incident on a given vertex) all have size , and every pair and intersect in exactly element. It would be interesting to develop this theory – to both find the limits of what is achievable and to develop techniques for constructing codes against this error model.
Finally, there are many other themes from classical coding theory that could make sense to study in the context of graph codes and graph distance, including in the context of sublinear time algorithms. It would be interesting to explore this.
Organization of this paper
2 Graph codes: Basics
Definitions and notations
All graphs will be simple, undirected graphs on the vertex set unless otherwise noted. For any graph , use to denote the adjacency matrix of , and view as an element of the vector space . For two graphs , , let be the symmetric difference of the two graphs, i.e. . For a subset , we use to denote the subgraph of induced by the vertex set . If is a matrix and , let be the sub-matrix indexed by on the rows and on the columns. For , we use to denote the binary entropy function.
Definition 1 (Graph distance and relative graph distance).
-
The graph distance between two graphs and , denoted by , is the smallest such that there is a set , , and .
-
The relative graph distance, or simply relative distance, between and is denoted by , and is the quantity .
In the above definition, we require that the graphs and be identical and not just isomorphic. Lemma 2 describes several equivalent characterizations of graph distance.
Proposition 2 (Alternate characterizations of ).
Suppose and are graphs on the same vertex set. Then
-
1.
is the minimum vertex cover size of .
-
2.
is the minimum number of vertices whose neighborhoods you need to edit to transform into
-
3.
is the minimum number of vertices whose neighborhoods you need to edit to transform into the empty graph.
Note that is a metric (see [19], Lemma 5).
Definition 3 (Graph code).
We say that a set is a graph code on with distance if for every pair of graph , we have that .
-
The rate of , denoted by , is the quantity .
-
The distance (resp. relative distance) of , denoted by (resp. ), is the quantity (resp. ).
Upper bound
As noted in [19], the Singleton bound can be used to obtain an upper bound on the rate of a graph code. We include a proof here for completeness.
Proposition 4.
Any graph code with relative distance has dimension at most .
Proof.
Consider any graph code of relative distance . Let be any subset of at most vertices. For any two distinct , we have that the graphs induced on the vertices outside , and , are different. Indeed, since otherwise, is a vertex cover of , contradicting the relative distance assumption. So, we have that
Expressed in terms of rate and distance, Proposition 4 implies that for constant relative distance , .
3 Existence of optimal graph codes
As with other objects in the theory of error-correcting codes, the first question we seek to answer relates to the optimal rate-distance tradeoff.
In contrast to the Hamming world, we find that, in the graph distance, random linear codes meet the Singleton bound.
Proposition 5.
Let . Then, there exists a linear graph code with distance greater than and dimension at least
Proof.
We only consider the case when , and prove this by a probabilistic construction. Let , be the Erdös-Rényi random graph distribution where the vertices are , and each of the possible edges are selected independently with probability 1/2. Let , and let be graphs chosen independently from . Consider the -linear space . We wish to show that has distance at least with high probability.
For , let be the graph with the adjacency matrix . Recalling the definition of graph distance, we need that for any distinct , must have minimum vertex cover size at greater than . Since , it suffices to show that for any non-zero , that has no vertex cover of size .
For any , has the same law as . Let be the event that has a vertex cover of size . We have
where the first inequality uses the union bound over subsets of size , and the fact that there are edges outside of a vertex cover that all have to be unselected. Then, union bounding over the choices of , we get
Therefore, with probability at least , there does not exist , such that , and has a vertex cover of size , and hence is a code with relative distance greater than .
Finally, note that if does not have a vertex cover of size , then is not the empty graph. Thus, the fact that there does not exist , such that has a vertex cover of size implies that are linearly independent. Hence, the dimension of is , as required.
As a result, we have the following corollaries.
Corollary 6.
For any constant , there exist optimal linear graph codes with relative distance at least .
Corollary 7.
For any constant , there exists a linear graph code with dimension at least and relative distance at least .
4 Explicit graph codes for high distance: Concatenated Codes
To get explicit codes of distance , we start with Construction 3 of [19]. The construction utilizes the tensor product code introduced by [17], where elements of the code are matrices where all rows and columns are codewords over some base Hamming code. The elements of the tensor code are then the adjacency matrices of graphs. Since we consider undirected graphs and do not allow self-loops, we take the subcode of the tensor code containing only symmetric matrices with zeros on the diagonal.
Definition 8 (Symmetric Tensor Code with Zeros on the Diagonal).
Let be a code over . The symmetric tensor code with zeros on the diagonal built on denoted is the set of matrices over such that (1) is symmetric, (2) the rows and columns of are codewords of , and (3) the entries on the diagonal are all 0.
Properties of elements of Tensor Product Codes that are symmetric and zero-diagonal were also previously studied, in the context of constructing a gap-preserving reduction from SAT to the Minimum Distance of a Code problem, by Austrin and Khot [4].
We will also define another notion of distance that will be useful later on.
Definition 9 (Directed graph distance).
Let , and be matrices over some field. Define the directed graph distance denoted to be the minimum such that there exists sets of size where .
For weighted, directed graphs, , and , abbreviate . To better distinguish between and , we sometimes refer to as the undirected graph distance.
When and are weighted directed graphs, can be viewed as the minimum such that you can go from to by editing the incoming edges of vertices and the outgoing edges of vertices. The main difference between directed and undirected graph distance is that directed graph distance allows the subset of rows and the subset of columns to be edited to be different. Insisting that in the definition for directed graph distance recovers the undirected graph distance. From this, it easily follows that if and are undirected graphs, then . Thus, to find codes with high graph distance, it suffices to find codes with large directed graph distance, where all the elements are adjacency matrices of undirected, unweighted graphs (i.e., 0/1 matrices that are symmetric and zero diagonal). Note that when discussing rate directed graph codes , we are referring to the quantity instead of .
In the next lemma, we show several properties of . Most importantly, the Hamming distance of translates to the directed graph distance of .
Lemma 10.
Let be a linear -code, then is linear, has dimension at least , and has directed graph distance .
Proof.
Let be a linear -code, and let . is linear because is linear, and the sum of symmetric matrices is symmetric.
WLOG, we assume that is systematic, i.e., it has generator matrix , where is the identity and is a matrix. Then, for every , the following has rows and columns belonging to
Furthermore, is symmetric and has zeros on the diagonal iff is symmetric, has zeros on the diagonal, and has zeros on the diagonal. This imposes linear constraints on the entries of . Thus, the subspace of for which has dimension at least .
Since is linear, to show the distance property, it suffices to show that for every non-zero . Let be a non-zero element of , we’ll show that for any , with , and , .
Since is non-zero, there is some non-zero entry . Since the rows are elements of a linear code of distance , the Hamming weight of the th row is at least . Since , there is some such that is non-zero. Then, the th column is also a non-zero codeword of , so it also has Hamming weight at least . Since , there is some such that is non-zero. Thus, .
Remark 11.
A simple calculation shows that if has constant rate, , then has rate as a directed graph code.
Given this lemma (and using the fact that ), for any binary code with rate and relative distance , is a (undirected) graph code with rate , and relative distance . Thus, if has rate distance tradeoff , then has rate distance tradeoff . Immediately, we get that taking the of any asymptotically good binary code yields an asymptotically good graph code.
There are two problems with this construction. Firstly, these codes may not be strongly explicit. Secondly, the Plotkin bound [13] implies that any binary code with distance has vanishing rate. So this falls short of our goal of obtaining strongly explicit, asymptotically good codes with .
We will address the first problem by showing that if the base code is a Reed Solomon code [14], then there is a large subcode that is strongly explicit.
Code 12 (Reed Solomon Code [14]).
The Reed Solomon Code with parameters , , and , where , is a code over with rate and distance .
Lemma 13.
Let where . Then, there exists a strongly explicit subcode such that the dimension of is at least .
Proof.
Essentially, we will evaluate symmetric polynomials that are a multiple of on a grid.
Suppose is a symmetric polynomial of individual degree at most , and let be the evaluations of on a grid. is symmetric and has zeros on the diagonal. Furthermore, for a fixed value, , is a univariate polynomial in of degree at most , and hence the column indexed by is an element of a Reed Solomon code of dimension , and block length . Similarly, the rows are also elements of the same code. Thus .
Let be the space of bivariate symmetric polynomials of degree at most . For , define polynomials . Notice that is symmetric, and furthermore the set
is linearly independent. Thus , as desired.
To extend this construction to the setting of , we use the concatenation paradigm from standard error-correcting code theory, initially introduced by Forney [7].
We will start with a code over a large alphabet and then concatenate with an inner code, which will be an optimal directed graph code.
Lemma 14.
For any , and sufficiently large , for any , there exists a linear directed graph code over of dimension and distance at least .
The proof is standard and similar to that of Proposition 5. So we will omit it.
Code 15 (Optimal Directed Graph Code ).
Require . Refer to a code with the properties in Lemma 14 as .
4.1 Symmetric concatenation
Since our inner code is not guaranteed to be symmetric, simply replacing each field element in the outer code with its encoding might result in an asymmetric matrix. To remedy this, we transpose the encoding for entries below the diagonal. This is made formal below.
Definition 16 (Symmetric Concatenation).
Let be prime powers, and be positive integers. Let and such that . Define to be the code obtained by taking codewords of and replacing each symbol of the outer alphabet with by their encodings under if they lie above or on the diagonal, and with the transpose of their encodings if they lie below the diagonal.
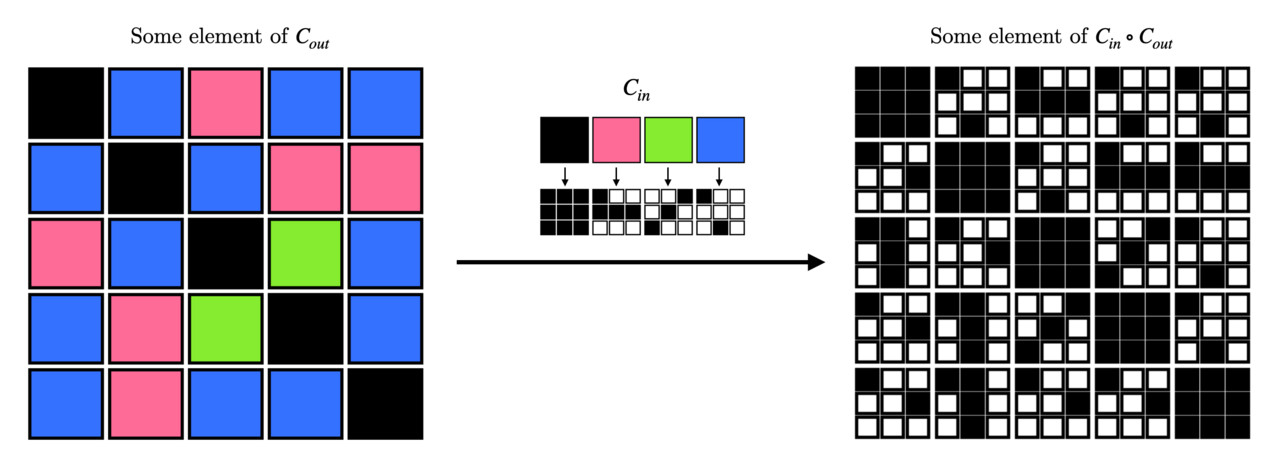
Figure 1 visualizes an example of symmetric concatenation. We now show that distance and dimension concatenate exactly like it does for standard error-correcting codes.
Lemma 17.
Suppose and are linear codes as in the previous definition with directed graph distance and , respectively. Let be the dimension of , and be the dimension of . Note . Then is linear and has distance at least , and dimension .
Proof.
Let . First note that can be made linear by using a -linear map from to before encoding with the inner code.
Consider a non-zero outer codeword , and let be the codeword after concatenation. Let be of size less than . We’ll show that . Partition into blocks, where the ’th block for , is the matrix encoding the symbol at . Identify the indices with where the tuple corresponds to the ’th index in the ’th block.
For , let be the set rows in in the ’th block. Define similarly. Let , be the set of blocks in which there are at least elements in , and similarly define , , and .
Since , , we have , and . Since the outer code has directed distance , , so there exists , and such that is non-zero. So, the ’th block of is a non-zero codeword or the transpose of a non-zero codeword of . Let us call it , and suppose that .
Since , and , and the inner code has distance at least , we have that . To finish the proof, note that by switching the roles of and in the definition of directed graph distance.
For the claim about dimension, note that the number of codewords in is the number of codewords in , which is . The dimension of is then .
Additionally, it is clear from the definition of symmetric concatenation that if is symmetric and zero-diagonal, so is .
Remark 18.
Lemma 17 also holds for the standard definition of concatenation (without transposing blocks below the diagonal). However, we will not need this fact.
4.2 Concatenated graph codes
We can instantiate the concatenated code using Reed Solomon codes.
Code 19 (Concatenated Code ).
Let be the size of the alphabet of the outer code. Let , and , to be integers satisfying , and . Then,
The following theorem follows directly from Lemmas 10 and 17. As a reminder, here we are considering the rate of the codes as a (undirected) graph code.
Theorem 20.
Let be parameters satisfying the requirements listed in 19, then is a graph code with rate , and relative distance .
Note that using this construction, we can get asymptotically good codes for any constant rate and distance - including for distances , which was not obtained in any of the previous constructions. We get by setting .
One drawback of this construction is that it is not strongly explicit or even explicit. The outer code can be made strongly explicit using Lemma 13, however, the inner code was an optimal code which we obtained by a randomized construction. The complexity of searching for such a code by brute force is too large. In particular, the optimal code has dimension , and block length . Since we need the size of the code to be equal to the size of the outer alphabet, we have , so . Then, there are at least generator matrices to search over. Thus, we cannot find such a code efficiently.
To address this, we reduce the search space by concatenating multiple times. The resulting code will have a slightly worse distance/rate tradeoff but will still be asymptotically good for any constant distance or rate.
We also note that can also be made strongly explicit using a Justensen-like construction. However, although this code is again asymptotically good, it has distance bounded away from 1. We present this construction in the Appendix.
4.3 Multiple concatenation
While concatenating twice suffices to obtain an explicit code, it is not clear that the obtained code is strongly explicit. This may be addressed by concatenating three times, at the cost of slightly weaker parameters. Here, we will also use the tensor product code as a building block. For any linear code let be the tensor product code of . As a reminder, is the code consisting of matrices such that each row and each column of are elements of .
Remark 21.
Suppose is a linear code with distance and rate . Then, it follows from the proof of Lemma 10 that has directed graph distance at least . It is also well known that has rate .
Below we present the analysis for triple concatenation.
Code 22 (Triple Concatenation ).
For and an integer , let be the subcode of in Lemma 13. Then
where and are picked to make the concatenation work, i.e., , and so on.
Notice that only the outer-most code needs to be symmetric and have zero diagonal since we use the symmetric concatenation operation (entries below the diagonal will be transposed). Thus, using the Tensor Product Code for the two middle codes (instead of STCZD) is sufficient and saves a factor of 2 (each time) on the rate.
Theorem 23.
Let be a positive integer and . Then has distance at least , and rate . Furthermore, is strongly explicit.
Proof.
The claims about rate and distance follow directly from Lemma 17.
We’ll now show that this code is strongly explicit. The outermost code is strongly explicit, and the two codes in the middle built on Reed Solomon codes are also strongly explicit. The idea is that the concatenation steps middle allow us to shrink the alphabet size from to (less than) . Searching for optimal codes of this size can be done easily by brute force.
The dimension of is , so the number of codewords is , and for the concatenation to work, we need this to be at least . That is, we need , which we can get easily by setting . For the same reason, we can take .
This is now small enough to do a brute-force search for an optimal code. The inner-most code has dimension , so we need , or . There are then possible generator matrices to search over. So the total number of codes we will need to search over is at most .
The tradeoff for this code is then
Thus, we get strongly explicit asymptotically good codes for any constant distance or rate.
If we just wanted explicit codes (instead of strongly explicit), concatenating twice would suffice. In particular, the search space for the inner-most code has size
which is smaller than any polynomial in , but not polylogarithmic. The corresponding tradeoff for the double concatenated code is .
5 Explicit graph codes with very high distance: dual-BCH Codes
In this section, we give explicit constructions of graph codes for the setting of very high distance (). As noted earlier, when the complete graph and the empty graph are part of the code, this is a generalization of the problem of constructing explicit Ramsey graphs (i.e., graphs with no large clique or independent set), which corresponds to graph codes of size at least .
Our main result here is an explicit construction of a graph code with distance and dimension , for all .
Theorem 24.
For all , there is a strongly explicit construction construction of a code with dimension and distance .
In analogy with the situation for Hamming-distance codes, these are the dual-BCH codes of the graph-distance world.
5.1 Warmup: a graph code with dimension
As a warmup, we first construct code with distance with growing dimension.
Let . Let denote the finite field trace map. Concretely, it is given by:
For each , consider the matrix , where the rows and columns of are indexed by elements of , given by:
Note that each is symmetric. Consider the code
Code 25.
For of the form , let us define the family of codes
We have that is a linear code of dimension .
Theorem 26.
The distance of is at least .
Proof.
Fix any . Let be an arbitrary subset of vertices. It suffices to show that if is bigger than , then there exist some such that
Suppose not. Then we have:
By Cauchy-Schwarz, we get:
For , let be the polynomial
The key observation is that for most , the trace of the polynomial is a nonconstant -linear function, and thus the inner sum:
equals .
Lemma 27.
If , then
is a nonconstant -linear function unless .
The proof is standard, and we omit it.
By the lemma, we get that there are at most choices of such that the inner sum is non-zero (namely those for which , which are few in number by the Schwartz-Zippel lemma).
Thus we get:
from which we get , as desired.
5.2 Larger dimension
We now see how to get graph codes of distance with and larger rate.
For a polynomial , let be matrix with rows and columns indexed by for which:
Let be the -linear space of all polynomials of the form:
where the .
Then, let us define our construction.
Code 28.
For of the form and , let us define the family of codes
Theorem 29.
We have that is a linear graph code of distance and dimension .
Proof.
The proof is very similar to the proof of Theorem 26. Consider any with . It suffices to show that the independence number222An essentially identical proof shows that the clique number also has the same bound. The only change is to replace the LHS of (3) by , and this sign change does not affect anything later because we immediately apply Cauchy-Schwarz to get (4). This justifies our referring to this code as a “code of Ramsey graphs”. of is .
Assume that is an independent set in . Then
| (3) |
As in the proof of Theorem 26, by the Cauchy-Schwartz inequality and some simple manipulations, we get:
| (4) |
where:
At this point, we need an upper bound in the inner sum:
To get this, we will invoke the deep and powerful Weil bound:
Theorem 30 ([16], Chapter II, Theorem 2E).
Suppose is a nonzero polynomial of odd degree with degree at most . Then:
We will use this to show that all but a few pairs , are small.
Lemma 31.
For all but pairs ,
is at most .
Assuming this for the moment, we can proceed with Equation (4):
Thus:
which implies that , as desired.
Proof of Lemma 31
Proof.
Theorem 30 only applies to polynomials with odd degree. We first recall a standard trick involving the map to deduce consequences for arbitrary degree polynomials.
Note that for all , and that every element of has a square root. Thus for any positive degree monomial , where with odd, the equality:
for each , where is the odd degree monomial given by:
Extending by linearity, this allows us to associate, to every polynomial , a polynomial with
for all , and where every monomial of (except possibly the constant term) has odd degree.
The key observation is that whenever is nonconstant, it has odd degree, and so we can apply the Weil bound. In this case, since:
for each , we get:
| (5) | ||||
| (6) |
where the last step follows from the Weil bound (Theorem 30).
Thus we simply need to show that there are at most pairs for which is a constant.
Suppose has degree exactly . Let be the coefficient of in .
Define by:
Note that . It is easy to check that and .
Then we have:
Then by definition,
We are trying to show that for most , this is nonconstant. We will do this by identifying a monomial of positive degree which often has a nonzero coefficient. Let with odd. We will focus on the coefficient of . It equals:
By linearity of the map , this can be expressed in the form , where is a bivariate polynomial of degree at most . Furthermore, using the fact that , the homogeneous part of of degree exactly equals:
which is nonzero. Thus is a nonzero polynomial.
Thus by the Schwartz-Zippel lemma, for , there are at most values of such that . Thus there are at most values of for which the coefficient of in is . Whenever it is nonzero, Equation (6) bounding applies, and we get the desired result.
References
- [1] Noga Alon. Connectivity graph-codes. arXiv preprint, 2023. arXiv:2308.07653.
- [2] Noga Alon. Graph-codes. arXiv preprint, 2023. arXiv:2301.13305.
- [3] Noga Alon, Anna Gujgiczer, János Körner, Aleksa Milojević, and Gábor Simonyi. Structured codes of graphs. SIAM Journal on Discrete Mathematics, 37(1):379–403, 2023. doi:10.1137/22M1487989.
- [4] Per Austrin and Subhash Khot. A Simple Deterministic Reduction for the Gap Minimum Distance of Code Problem. IEEE Transactions on Information Theory, 60(10):6636–6645, 2014. doi:10.1109/TIT.2014.2340869.
- [5] Shixi Chen and Shuigeng Zhou. Recursive mechanism: Towards node differential privacy and unrestricted joins. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, SIGMOD ’13, pages 653–664. Association for Computing Machinery, 2013. doi:10.1145/2463676.2465304.
- [6] Pat Devlin. Personal Communication.
- [7] G David Forney. Concatenated codes. Technical report, Massachusetts Institute of Technology, Research Laboratory of Electronics, 1965.
- [8] Michael Hay, Chao Li, Gerome Miklau, and David Jensen. Accurate Estimation of the Degree Distribution of Private Networks. In 2009 Ninth IEEE International Conference on Data Mining, pages 169–178, 2009. doi:10.1109/ICDM.2009.11.
- [9] Palak Jain, Adam Smith, and Connor Wagaman. Time-Aware Projections: Truly Node-Private Graph Statistics under Continual Observation. arXiv, 2024. doi:10.48550/arXiv.2403.04630.
- [10] J. Justesen. Class of constructive asymptotically good algebraic codes. IEEE Transactions on Information Theory, 18(5):652–656, 1972. doi:10.1109/TIT.1972.1054893.
- [11] Shiva Prasad Kasiviswanathan, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. Analyzing graphs with node differential privacy. In Proceedings of the 10th Theory of Cryptography Conference on Theory of Cryptography, TCC’13, pages 457–476. Springer-Verlag, 2013. doi:10.1007/978-3-642-36594-2_26.
- [12] James L Massey. Threshold decoding. Technical report, Massachusetts Institute of Technology, Research Laboratory of Electronics, 1963.
- [13] M. Plotkin. Binary codes with specified minimum distance. IRE Transactions on Information Theory, 6(4):445–450, 1960. doi:10.1109/TIT.1960.1057584.
- [14] I. S. Reed and G. Solomon. Polynomial Codes Over Certain Finite Fields. Journal of the Society for Industrial and Applied Mathematics, 8(2):300–304, 1960. doi:10.1137/0108018.
- [15] Kai-Uwe Schmidt. Symmetric bilinear forms over finite fields with applications to coding theory. Journal of Algebraic Combinatorics, 42(2):635–670, 2015. doi:10.1007/s10801-015-0595-0.
- [16] W.M. Schmidt. Equations over Finite Fields: An Elementary Approach. Lecture Notes in Mathematics. Springer Berlin Heidelberg, 2006. URL: https://books.google.co.uk/books?id=up97CwAAQBAJ.
- [17] J. Wolf. On codes derivable from the tensor product of check matrices. IEEE Transactions on Information Theory, 11(2):281–284, 1965. doi:10.1109/TIT.1965.1053771.
- [18] Lev Yohananov, Yuval Efron, and Eitan Yaakobi. Double and Triple Node-Erasure-Correcting Codes Over Complete Graphs. IEEE Transactions on Information Theory, 66(7):4089–4103, 2020. doi:10.1109/TIT.2020.2971997.
- [19] Lev Yohananov and Eitan Yaakobi. Codes for Graph Erasures. IEEE Transactions on Information Theory, 65(9):5433–5453, 2019. doi:10.1109/TIT.2019.2910040.
Appendix A Justensen-like code
The construction in this example is inspired by the Justensen code [10], which uses an ensemble of codes for the inner code instead of a single inner code. Justensen uses an ensemble known as the Wozencraft Ensemble [12] with the following properties.
Theorem 32 (Wozencraft Ensemble).
For every large enough , there exists codes over with rate , where fraction of them have distance at least .
Since our goal is graph distance, we use the operation to covert the Wozencraft Ensemble from codes over strings with good Hamming distance to codes of matrices with good graph distance.
Lemma 33 (Wozencraft Ensemble Modification).
For any , and large enough , there exists codes over . View these as directed graph codes. Then these codes have rate , and at least a fraction of them have distance at least .
Proof.
Let be the Wozencraft Ensemble. For each , define . Note that each is a code over . Note that by lemma Lemma 10, each of the codes has rate . Since the operation translates Hamming distance to directed graph distance, we also have the same guarantee as the original Wozencraft Ensemble - at least fraction of the codes have distance at least .
Concatenating with the modified Wozencraft Ensemble in a particular arrangement yields our next construction.
Code 34 (Justensen-like ).
Require . Let , and .
Let be the modified Wozencraft Ensemble Lemma 33.
Then is the code where for each element of , for each , we replace the symbol at with its encoding under . If , we transpose the encoding (to keep the matrix symmetric).
Figure 2 shows where each inner code is applied.
Theorem 35.
For any , and , a sufficiently large integer, is a strongly explicit linear graph code with rate , and distance at least .
Proof.
Let , and be the side lengths of the inner and outer codes, respectively. First note that is a linear graph code over , since both the inner and outer codes are linear, and we can apply a linear map from before encoding with the inner code.
Rate.
Distance.
Let be a non-zero outer codeword. For convenience, let , and be the side length of the inner code. We claim the distance is at least .
Call , bad if the distance of , and good otherwise. Let be the subset of bad indices. By the guarantee of the Wozencraft ensemble, we know that . Since gets encoded with , if , then is encoded with an inner code of distance at least .
Define as in the proof of Lemma 17. Let . Similarly, define . Then . Then . Since this is less than the outer distance of the code, we have that for some , and . In other words, , , and is encoded with a code of directed graph distance at least . Thus, by the inner distance, there remains a non-zero element in the th block outside of , and .