On Cascades of Reset Automata

Abstract
The Krohn-Rhodes decomposition theorem is a pivotal result in automata theory. It introduces the concept of cascade product, where two semiautomata, that is, automata devoid of initial and final states, are combined in a feed-forward fashion. The theorem states that any semiautomaton can be decomposed into a sequence of permutation-reset semiautomata. For the counter-free case, this decomposition consists entirely of reset components with two states each. This decomposition has significantly impacted recent research in various areas of computer science, including the identification of a class of transformer encoders equivalent to star-free languages and the conversion of Linear Temporal Logic formulas into past-only expressions (pastification).
The paper revisits the cascade product in the context of reset automata, thus considering each component of the cascade as a language acceptor. First, we give regular expression counterparts of cascades of reset automata. We then establish several expressiveness results, identifying hierarchies of languages based on the restriction of the height (number of components) of the cascade or of the number of states in each level. We also show that any cascade of reset automata can be transformed, with a quadratic increase in height, into a cascade that only includes two-state components. Finally, we show that some fundamental operations on cascades, like intersection, union, negation, and concatenation with a symbol to the left, can be directly and efficiently computed by adding a two-state component.
Keywords and phrases:
Automata, Cascade products, Regular expressions, Krohn-Rhodes theoryCopyright and License:
2012 ACM Subject Classification:
Theory of computation Regular languages ; Theory of computation Automata extensionsAcknowledgements:
The authors would like to thank Alessio Mansutti for his valuable comments during the preparation of this paper.Funding:
Luca Geatti and Angelo Montanari acknowledge the support from the 2024 Italian INdAM-GNCS project “Certificazione, monitoraggio, ed interpretabilità in sistemi di intelligenza artificiale”, ref. no. CUP E53C23001670001 and the support from the Interconnected Nord-Est Innovation Ecosystem (iNEST), which received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR) – MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.5 -– D.D. 1058 23/06/2022, ECS00000043). In addition, Marco Montali and Angelo Montanari acknowledges the support from the MUR PNRR project FAIR - Future AI Research (PE00000013) also funded by the European Union Next-GenerationEU.Editors:
Olaf Beyersdorff, Michał Pilipczuk, Elaine Pimentel, and Nguyễn Kim ThắngSeries and Publisher:
1 Introduction
The Krohn-Rhodes decomposition theorem is a fundamental result both in automata theory and in semigroup algebra [12]. It relies on the concept of cascade product of two semiautomata, i.e., automata devoid of initial and final states, and thus, ultimately, edge-labeled graphs. In this setup, the first semiautomaton operates on an alphabet , while the second one reads symbols belonging to the Cartesian product of and the set of states of the first semiautomaton. The key feature of the cascade product, which extends the notion of direct product, is that the second semiautomaton transitions from state to state by reading the pair if and only if the input symbol is and the first semiautomaton is in state .
The Krohn-Rhodes theorem states that any semiautomaton can be decomposed into a cascade (i.e., a sequence of cascade products) of permutation-reset semiautomata.111Formally, the decomposition is guaranteed to preserve a homomorphism from the cascade to the initial semiautomaton. In such semiautomata, each symbol of the alphabet induces a function on the set of states that is either a permutation, i.e., a bijective function, or a reset, that is, there is a specific state to which all other states are mapped into when reading that symbol. Crucially, if the semiautomaton is counter-free, that is, it does not contain non-trivial cycles [18], the Krohn-Rhodes theorem guarantees the existence of a decomposition that consists of reset automata only, i.e., automata where all symbols induce reset functions (as described above) or the identity function.
The Krohn-Rhodes theorem, in particular the decomposition of counter-free automata into reset automata, had a significant impact on some meaningful problems of current research in computer science. A notable example comes from Angluin et al. [1], who employ the Krohn-Rhodes decomposition theorem to prove that Linear Temporal Logic ( [19]) is equivalent to transformer encoders with hard attention and strict future masking (see also [13]). Specifically, they show how reset semiautomata can be encoded in B-RASP, a minimal programming language that compiles into transformers. Similarly, studies such as [21, 10, 11] utilized this theorem to analyze the sample complexity of cascades and the expressiveness of Recurrent Neural Networks without circular dependencies. Another example is provided by Maler [14, 15], who used the decomposition theorem to transform any formula of , interpreted over finite words, into an equivalent formula using only past operators (see also [20]), a problem now known as pastification [2].
In this paper, we revisit the cascade product in the reset automata setting, i.e., language acceptors whose underlying semiautomaton is a reset. We address various expressiveness issues for cascade products by themselves and in relation to regular expressions. These results represent a necessary step towards a more efficient exploitation of Krohn-Rhodes decomposition in pastification, with the ultimate goal of lowering its current, triply exponential upper bound, which is far away from the know, singly exponential lower bound.
The paper consists of three main parts. In the first part, we address the question: given a cascade of reset automata, which is its corresponding regular expression? We begin by focusing on cascades of height , proving that the language corresponding to a reset automaton over the alphabet is always of the form , for some , such that and either or . Then, we extend the analysis to cascades of reset automata of arbitrary height. As a first step, we show that the last level can always be transformed into a two-state automaton, and then, by exploiting such a result, we derive the regular expression corresponding to a generic cascade of reset automata.
In the second part, we build on the previously obtained results and establish several expressiveness results about cascades of reset automata. We structure the analysis into three types of cascades:
-
(i)
short cascades (whose height is bounded by 2),
-
(ii)
narrow cascades (where each component has two states, but there is not a height limitation), and
-
(iii)
general cascades (with no limitations on the height or on the number of states per level).
As for short cascades, we prove that any language over an alphabet of cardinality that is definable by a reset cascade of height can also be defined by one where the first component has at most states. Additionally, we show that increasing the number of states in the first component results in a strict increase in expressiveness: there exists a family of languages which are definable by a two-reset cascade whose first component has states, but are not definable if the first component is restricted to states. Similarly, for narrow cascades, we show that increasing the height results in an increase in expressiveness. These two results – the increase in the number of states in the first component for short cascades and the increase in height for narrow cascades – lead to two hierarchies (with infinitely many levels) of languages that are not definable at previous levels. Finally, we show that any general cascade can be transformed into one whose components have all 2 states, with an increase in height of at most a quadratic factor (relative to the height of the original cascade).
In the last part, we deal with closure properties of the languages recognized by reset cascades, and show that some fundamental operations can be computed in an efficient way. More precisely, we prove that the operations of intersection, union, negation, and concatenation with to the left (“next operation”) all require the addition of one component with 2 states only.
The paper is structured as follows. Related work is discussed in Section 2. In Section 3, we provide some background knowledge. In Section 4, we introduce the cascades of reset automata, we state some basic results about them, and we provide a characterization of the languages that they recognize in terms of regular expressions. In Section 5, we present some expressiveness results for short, narrow, and general cascades of reset automata. Section 6 focus on closure properties and the efficient computation of some basic operations. Finally, Section 7 provides an assessment of the work done, and it outlines some directions for future research.
2 Related Work
The Krohn-Rhodes theorem and the cascade product turn out be quite useful in understanding the structure and the expressiveness of finite-state systems, in particular in the context of automata and neural networks, and their connection to logic. Various recent contributions have leveraged this foundational theory to explore the expressiveness, modularity, and learning potential of automata in such a context.
A pivotal contribution in this area is the work by Maler on the cascade decomposition of semiautomata [14, 15]. It revisits the Eilenberg’s variant of the Krohn-Rhodes theorem [6] and offers a constructive proof that any semiautomaton can be decomposed into a cascade of elementary (permutation and reset) semiautomata. The paper introduces the holonomy tree as a data structure to represent cascade decompositions and an algorithm to build such a tree. Crucially, the algorithm carefully maps the permutations of the obtained cascade product to non-trivial cycles of the starting semiautomaton: this guarantees that, whenever the starting semiautomaton is counter-free, that is, devoid of non-trivial cycles, the generated cascade decomposition only consists of reset components. An exponential bound on the size of the cascade decomposition in terms of the size of the starting semiautomaton is given. This algorithm can be used to actually translate counter-free automata to temporal logic. More precisely, Maler shows how to translate any cascade product of reset semiautomata into a pure past formula, that is, a formula featuring only past temporal modalities. Together with the transformation of the future fragment of , interpreted over finite words, into counter-free automata, this leads to a triply exponential upper bound to the problem of transforming pure-future over finite words into pure-past (pastification problem). Equivalently, in the case of interpreted over infinite words, Maler shows how to use the proposed algorithm to normalize every formula by mapping it into one belonging to the Reactivity class [16], at a cost of a triply exponential blowup. For both problems, that is, pastification and normalization, the best known lower bounds are singly exponential [3, 17].
The Krohn-Rhodes theorem has also been applied to analyze the complexity of semigroups, as shown in [9]. This study examines semigroups of upper triangular matrices over finite fields and establishes that the Krohn-Rhodes complexity of these semigroups corresponds to , where is the matrix dimension. These results underline the deep connection between the algebraic structure of semigroups and their matrix representations, providing a measure of how intricate the cascade product representation needs to be for such semigroups.
In [8], the Krohn-Rhodes theorem is used to characterize piecewise testable and commutative languages. The authors define biased reset semiautomata, where the current state changes at most once, and characterize cascades , where is a biased reset semiautomaton. Theorem 4.12 in Section 4 can be seen as a simplification and a generalization (to cascades of unbounded height) of such a characterization. Finally, the authors propose the notion of scope of a cascade, which is used to analyze the dot-depth of star-free languages.
In [21], Ronca builds on the Krohn-Rhodes theorem, proposing automata cascades as a structured and modular framework to describe complex systems. The resulting framework allows automata to be decomposed into components with specific functionalities, enabling fine-grained control of their expressiveness. By focusing on component-based decomposition, the study demonstrates that the sample complexity of learning automata cascades is linear in the number of components and their individual complexities, up to logarithmic factors. This contrasts with traditional state-centric perspectives, where sample complexity scales with the number of states, often limiting the feasibility of learning large systems. The relationships between the cascade product and neural networks are investigated in [10]. Recurrent Neural Cascades (RNCs) are a class of networks with acyclic connections, which naturally align with the cascade product of automata. By exploiting the Krohn-Rhodes theorem, the authors prove that RNCs capture star-free regular languages.
The Krohn-Rhodes theorem also underpins the exploration of transformer models in [13]. While transformers lack recurrence, the paper demonstrates that their layered architecture can simulate the cascade decomposition of finite automata. Leveraging Krohn-Rhodes theory, the authors show that shallow transformers can hierarchically approximate automata computations, enabling polynomial-sized and constant-depth shortcuts for specific automata.
In [1], Angluin et al. draws direct parallels between the expressive power of masked hard-attention transformers and star-free regular languages. These models, constrained by strict future masking, are shown to be equivalent to and counter-free automata – both closely tied to the Krohn-Rhodes cascade framework. The study underscores how the structured limitations of these transformers, akin to a cascade decomposition, yield expressive yet computationally efficient models.
Together, these contributions extend the applicability of the Krohn-Rhodes theory to neural networks, transformers, and beyond, demonstrating the versatiliy of the cascade framework as a powerful principle in computation.
3 Background
A semiautomaton is a tuple such that:
-
(i)
is a (finite) alphabet;
-
(ii)
is a set of states;
-
(iii)
is a transition function.
An automaton is a semiautomaton extended with an initial state and a set of final states. With we denote the Kleene’s closure of . We say that is two-state iff .
Given an automaton and a (finite) word , the run induced by is a sequence such that , for all . We say that is accepting iff . A word is accepted by iff the run induced by is accepting. We define the language of , denoted by , as the set of accepted words. Given a state , let be the set of words inducing a run with . The classic direct product of automata is defined as follows.
Definition 3.1 (Direct product of automata).
Let and be two automata. The direct product of and , denoted by , is the automaton such that, for all and for all , it holds that .
The cascade product of semiautomata is defined as follows.
Definition 3.2 (Cascade Product of semiautomata [15, 22]).
Let be a finite alphabet and let and be two semiautomata over the alphabets and , respectively. We define the cascade product between and , denoted with , as the semiautomaton such that, for all and for all :
| (2) |
We will often simply use “cascade” for “cascade product”.
It is worth noticing that the cascade product of semiautomata is a generalization of the classic direct product: the latter can be recovered by imposing the alphabet of the second semiautomaton to be (i.e., the alphabet of the first one) instead of .
The cascade product is an associative operation, meaning that is the same semiautomaton as . We define the height of the product as .
We now introduce two classes of semiautomata, reset and permutation, depending on the form of their transitions. We first define the notion of function induced by a symbol.
Definition 3.3 (Function induced by a symbol).
Let be a semiautomaton. For each symbol , we define the function induced by in , denoted by (or simply when is clear from the context), as the transformation such that, for all , it holds iff .
Reset and permutation functions are defined as follows.
Definition 3.4 (Reset and permutation functions).
Let . We say that is a reset function iff there exists such that , for all . In this case, we say that is a reset on . If is a bijection, then it is called a permutation.
On the basis of the functions induced by the symbols of their alphabet, we define the following classes of semiautomata.
Definition 3.5 (Classes of semiautomata).
Let be a semiautomaton. We say that is:
-
a permutation-reset semiautomaton iff, for each , is either a permutation or a reset.
-
a permutation semiautomaton iff, for each , is a permutation;
-
a reset semiautomaton iff, for each , is either the identity function or a reset function;
-
a pure-reset semiautomaton iff, for each , is a reset function.
We now introduce counter-free semiautomata [18]. Let . From now on, we denote by the word generated by concatenating times the word to itself. A word , with , defines a nontrivial cycle in a semiautomaton if there exists a state such that:
-
(i)
-
(ii)
, for some .
We say that a semiautomaton is counter-free if there are no words that define a nontrivial cycle. Counter-free automata recognize exactly the set of languages definable by star-free regular expressions, i.e., expressions devoid of Kleene’star. We denote this set by .
A fundamental result in the field is the Krohn-Rhodes Cascade Decomposition Theorem. The theorem’s initial formulation was expressed in the context of semigroups [12], and its automata-theoretic counterpart [14] can be articulated as follows.
4 Cascades of automata
In this section, we begin our study of the languages recognized by cascades of automata. We start by formally defining them and stating some basic properties. Then, we focus on cascades of reset automata, and provide a characterization of the languages they recognize in terms of regular expressions.
4.1 Definitions and basic properties
To begin with, we generalize the notion of cascade product of semiautomata (Definition 3.2) to automata.
Definition 4.1 (Cascade product of automata).
Let be a finite alphabet and let and be two automata over the alphabets and , respectively. We define the cascade product of and , denoted by , as the automaton where is defined as in Definition 3.2.
We say that a language is definable by a cascade iff . Figure 1 shows the cascade product of two reset automata defining the language .
In the following, we will use the term cascade to refer both to the component automata and to the resulting automaton.
We now show how to compute the language recognized by a cascade of automata on the basis of the languages recognized by its components. Let and be two alphabets. Let and be two words of length . We define as the word .
Definition 4.2 (Language of at a state over ).
Let and be two automata. The language of at state over , denoted by , is defined as follows: the empty word only belongs to ; a word , with , belongs to if
-
(i)
induces a run on ; and
-
(ii)
.
The language of a cascade can be computed from those of its components as follows. Let be a cascade. The words forcing to reach a state are exactly those words such that:
-
(i)
they force to reach state ; and
-
(ii)
they force to reach state , when augmented with the run of .
Proposition 4.3 (Language of a cascade in terms of its components).
Let and be two automata. It holds that:
-
1.
, for all states and ;
-
2.
.
We now show that, as it happens with semiautomata, the direct product of automata is just a special case of the cascade product. To this end, we first define the notion of augmentation of an automaton.
Definition 4.4 (Augmentation).
Let and be two automata such that either or , for an arbitrary finite set . We define the augmentation of relative to , denoted by , as the automaton such that:
-
if , then and for all and all , ;
-
if , then and, for all and for all , it holds that .
Given a cascade over , we define the augmentation of relative to , denoted by , as the cascade .
The notion of augmentation can be generalized to a pair of cascades and by treating as a single automaton: from now on, when we will refer to the cascade product of and , we will interpret it as the cascade product of the automaton generated by and .
The next proposition shows that direct product can be simulated by means of augmentation and cascade product.
Proposition 4.5 (Direct product by means of cascade product).
Let be an automaton and let be a cascade over . It holds that .
Furthermore, augmenting an automaton does not affect its property of being reset (or permutation), as stated by the following Proposition 4.6.
Proposition 4.6.
Let be a finite alphabet and let be an automaton over or , for an arbitrary finite set . If is a reset (resp., permutation) automaton, then, for any automaton over , is a reset (resp., permutation) automaton.
It follows that, in particular, if is a cascade of reset (resp., permutation) automata, then is a cascade of reset (resp., permutation) automata. From Propositions 4.5 and 4.6, it follows directly that, given two cascades and of height and of reset (resp., permutation) automata, there exists a cascade of height of reset (resp., permutation) automata for . In Section 6, we will show how to compute other basic operations on cascades of resets.
4.2 Languages of cascades of resets
In this part, we characterize the language recognized by a cascade of reset automata in terms of regular expressions. We begin with the case of cascades of height and then we move to cascades of unbounded height.
4.2.1 Cascades of height 1
The study of which regular expressions characterize height-1 cascades of resets coincides with the study of the languages recognized by reset automata. The following theorem gives a characterization of reset automata in terms of regular expressions.
Theorem 4.7 (The languages of reset automata).
Let be a finite alphabet. A language is recognized by a reset automaton if and only if for some such that and either or .
Intuitively, an automaton reading a symbol that induces a reset function on a final state is forced to end up in that state, regardless of which state it was in before. Furthermore, it remains in that state if all subsequent symbols induce identity functions. In the case of words containing multiple resets on a final state, only the last of these symbols matters, resulting in words of the form . The case of arises when the initial state is also final. In this scenario, to accept a word, the automaton does not need to read a symbol that induces a reset on a final state (since it is already there), but only needs to stay in the initial state.
A by-product of Theorem 4.7 is that any reset automaton is equivalent to one with two states, only one of which is final. The rationale is as follows:
-
(i)
the symbols in induce a reset on the single final state;
-
(ii)
the symbols in act as identities; and
-
(iii)
the symbols neither in nor in induce resets on the single non-final state.
Moreover, the initial state is also the final state if and only if . A graphical account is given in Figure 2.
Proposition 4.8.
For every reset automaton, there exists an equivalent one with two states, exactly one of which is final.
Theorem 4.7 allows us to establish a first connection between Linear Temporal Logic on finite traces ( [5]) formulas and equivalent reset cascades. As highlighted in the introduction, the languages expressible in are exactly the star-free languages, that is, those languages that can be represented by regular expressions that do not use the Kleene star, or equivalently, by languages whose minimal automaton is counter-free [18]. By Krohn-Rhodes’ theorem (Theorem 3.6), it follows that the languages definable in are precisely those expressible through cascades of resets. Given the relevance of reset cascade decomposition in problems such as pastification [2, 4] and normalization [7] of temporal logic formulas, it is crucial to understand which formulas can be expressed with cascades of a specific height. The following result shows that even simple formulas like (the proposition letter “p” holds at the initial time point) or (there is a future point where “q” holds, and until then, “p” remains true) cannot be expressed with cascades of resets of height 1. In fact, the languages they recognize333Here, assuming a set of atomic propositions , the languages of formulas over are defined over the alphabet . Moreover, given any , we indicate with all the letters such that . are respectively and , which are not of the form , for any choice of , , and . However, the formula (there exists a point in the future where “p” holds) can be expressed with reset cascades of height 1, as its language is of the form , choosing , , and .
Corollary 4.9.
The languages defined by the formulas and are not definable with height-1 cascades of resets.
4.2.2 Cascades of unbounded-height
In this section we derive regular expressions for cascades of arbitrary height. As a first step, we show that a cascade of height of reset automata, say , can be transformed into an equivalent cascade of the same height, still consisting of reset automata, where the last automaton () has exactly two states, one of which is the only accepting state. This result forms the basis for Theorem 4.12, which provides the characterization of cascades of arbitrary height.
Lemma 4.10.
Let be an automaton with set of states over the alphabet , and let be a reset automaton over the alphabet . There exists a 2-states reset automaton , with exactly one final state, such that .
The proof of Lemma 4.10 heavily relies on the characterization of cascades of height 1. More precisely, since is a reset automaton over the alphabet , by Proposition 4.8, there exists an equivalent reset automaton with two states (one of which is the only accepting state) over the same alphabet. Since is at the bottom of the cascade, the language of the cascade is the same as the language of . This is because there are no other automata below in the cascade that can exploit information about ’s current state. As a matter of fact, in Section 5, we will prove that this no longer true when applying the same procedure to : there exist languages definable by a cascade , where has 3 states and has 2 states, that cannot be expressed if the number of states of is limited to 2.
Let us now introduce the notion of filtered automaton, which is obtained from a given automaton by removing (filtering) certain outgoing transitions and possibly changing its initial state.
Definition 4.11 (Filtered Automaton).
Let be an automaton. A filter is pair , where and . The partial automaton , filtered by , denoted as , is the automaton where if , or is undefined otherwise.
Before formally stating Theorem 4.12, that characterizes the languages of cascades of unbounded-height, we give an intuitive account of it. Let be a cascade, with an automaton and a reset automaton, where, w.l.o.g. (Lemma 4.10), has only two states and exactly one final state. Any word accepted by must drive both and to an accepting state. Its language can be captured by analyzing the symbols inducing a reset function that leads to a final state of , and the symbols inducing identities in . The words in the language of are precisely those consisting of
-
(i)
a prefix that, for any symbol inducing a reset on a final state of , drives automaton to state ;
-
(ii)
followed by the symbol (let be the state reached by after reading it);
-
(iii)
a suffix that forces to remain in its accepting state through its identity functions , and forces to reach a final state starting from .
In addition, cannot transition from state when reading a symbol if the pair does not belong to ’s identity functions, as this would cause to leave its accepting state. Therefore, the suffix corresponds to the language of automaton , filtered by . This is formally expressed by the following theorem.
Theorem 4.12 (Languages of cascades of unbounded-height).
Let be an automaton and let , with , be a two-state reset automaton with one final state. It holds that:
| (3) |
where is the set of symbols in that induce a reset function on state , and if or otherwise.
Figure 3 gives an example of application of Theorem 4.12 to a cascade over the alphabet of two reset automata, (on the left) and (on the center), with two states each, recognizing the language . Using Theorem 4.12, we have that , where is the automaton obtained from filtered by the identities of automaton . Since and , we obtain . The following is a corollary of Theorem 4.12 in the case in which is a pure-reset automaton.
Corollary 4.13.
Let be an automaton and let be a two-state pure-reset automaton with one final state. It holds that
| (4) |
where if and , or otherwise.
It is worth noticing that the regular expressions in Theorems 4.12 and 4.13 refer to states of the cascade under consideration. This is a major difference with the characterization of reset cascades of height 1 (Theorem 4.7). In order to prove some undefinability results in the next section, we provide a characterization of the languages recognized by cascades of two-states resets of height where the second component is pure-reset, based on regular expressions that do not refer to states of the cascade.
Lemma 4.14.
Let be a language. is definable by a cascade of height in which the second component is pure-reset if and only if for some , , and such that:
-
(i)
is either or ;
-
(ii)
;
-
(iii)
for all it holds ;
-
(iv)
there exists a language recognizable by a two-state reset automaton such that for all , either is or is .
Notice that the Lemma above can be easily extended to the case in which the first automaton in the cascade has states, for some . This is done by relaxing (iv) and imposing that can be chosen between languages such that is a partition of and each is definable by a cascade of resets of height 1. Constraint (ii) is also relaxed to .
We will use Theorem 4.12, Corollary 4.13, and Lemma 4.14 in the next section to prove undefinability results of certain languages by cascades of a given height and with a specified number of states at each level.
5 Expressiveness results
In this section, we analyze the expressive power of various types of reset automaton cascades. We begin by defining several language classes, and subsequently structure our analysis into short cascades (where the height is constrained to at most two), narrow cascades (where the height is unbounded but each component contains two states), and general cascades (with no restrictions on either the height or the number of states).
Definition 5.1 (Classes and ).
Let and let . We denote by the class of languages definable by a cascade of reset automata such that has states, for each . We denote by the subclass of where the last automaton () is required to be pure-reset. For and , we define as the set of languages definable by a cascade of height , where each component has at most states. We define as the set of languages definable by any cascade of reset automata. The classes and are defined analogously.
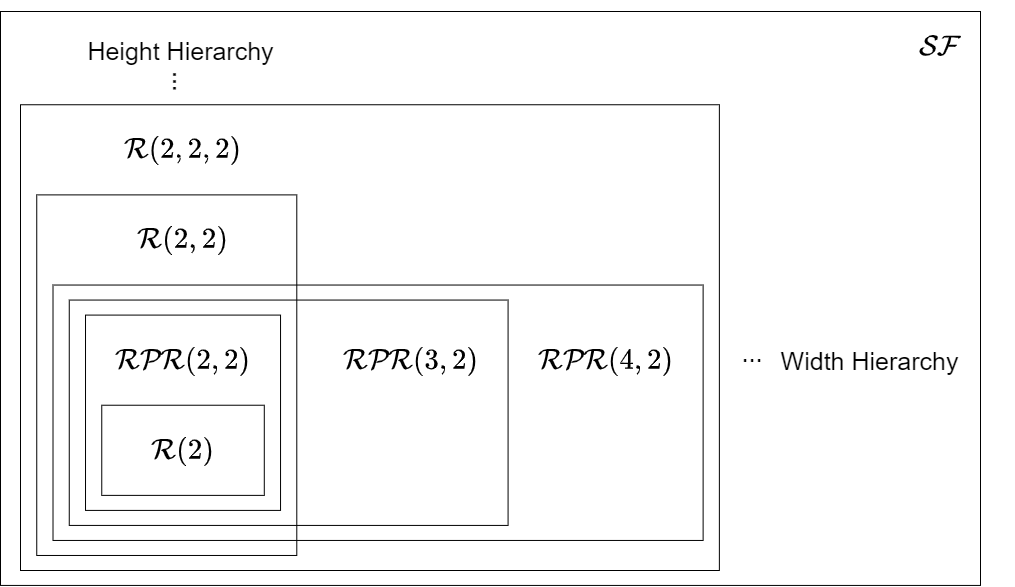
Figure 4 provides an overview of (some of) the results presented in this section. Specifically, it illustrates that increasing the cascade height and increasing the number of states at the first level lead to two distinct language hierarchies.
5.1 Short Cascades
We begin by considering short cascades, i.e. cascades of reset automata of height 2. As a first step, we start by comparing the classes and , and then we focus on and for every .
We already know that with a single pure-reset automaton we can recognize the set of all words ending with a certain symbol of the alphabet (this follows from Theorem 4.7 in the special case in which ). As an example, it holds that . Now, if we introduce an additional pure-reset layer, we can effectively recognize the set of words ending with a two-character suffix. However, we also demonstrate that this is impossible using a single reset automaton.
Lemma 5.2.
Let . It holds that:
-
(i)
;
-
(ii)
.
Lemma 5.2 shows that increasing the height of a cascade, even of height and even with a pure-reset automaton, results into a gain of expressive power.
In the upcoming lemma, we demonstrate that, at the same height, prohibiting identities in the final layer results in a loss of expressive power. To illustrate this, let us consider the language . As shown in Figure 1, this language can be defined using a cascade of two reset automata, with the last one specifically containing identities. Building upon Lemma 4.14, we further demonstrate that achieving the same language recognition is not possible when prohibiting identities in the final layer, no matter of the number of states of the first automaton.
Lemma 5.3.
Let be an alphabet with at least two symbols, let . It holds that:
-
(i)
;
-
(ii)
, for every .
In Lemma 4.10, we have shown that the final component of a cascade can always be restricted to two states. A natural question arises: Can the first component also be limited to just two states? The answer is negative, as illustrated by the following example. Consider an alphabet of three symbols and the language consisting of all words that end with two distinct symbols (e.g. but ). As demonstrated in Figure 5, this language can be recognized by a cascade of two reset automata where the first component has three states. However, we will prove that it cannot be recognized if the first component has only two states. Intuitively, the first component’s role is to remember the second-to-last symbol, but with an alphabet of three symbols and only two states, this task becomes impossible. The following Width-Hierarchy Lemma formalizes this intuition, demonstrating the existence of an infinite hierarchy of languages that can be defined using cascades of two resets where the first component contains states, but cannot be defined when the first component is restricted to states.
Lemma 5.4 (Width-Hierarchy Lemma).
For each , let . Let , it holds that:
-
(i)
;
-
(ii)
.
The following corollary (depicted in Figure 4) follows from Lemmas 5.2, 5.3, and 5.4.
Corollary 5.5.
It holds that:
-
;
-
and .
Additionally, we prove that for a fixed alphabet of cardinality , any language over expressible by a cascade of height 2 can also be expressed by a cascade of height 2 where the first component has at most states. The intuition behind this is that, due to the restriction of transitions to resets or identities, only a finite number of states can be reached from the initial state. This is formalized in the next lemma, which also establishes the optimality of the bound on the number of states of the first component.
Lemma 5.6.
Let be a finite alphabet with size . Let be a language such that . For every , if , then . Furthermore, there exists a language such that but .
5.2 Narrow Cascades
Thus far, our discussion has centered around cascades composed of one or two components. Now, we shift our focus to narrow cascades, i.e. cascades of greater height but in which each components is restricted to have two states (i.e. ). Just as we have seen that some languages cannot be expressed by cascades of height 1, we will demonstrate that for any given height, there exists a language that cannot be captured at that height, provided the components of the cascade are restricted to two states. We call this the Height-Hierarchy Lemma, and is a counterpart of the Width-Hierarchy Lemma (Lemma 5.4) focused on the height of cascades. It is based on the following family of languages: for each , we consider the language , that is all words that contain symbol “” precisely at position . The Height-Hierarchy Lemma below proves that, for any , the language is not definable by cascades of two states reset automata of height less than .
Lemma 5.7 (Height-Hierarchy Lemma).
For each , let . It holds that:
-
(i)
;
-
(ii)
.
We briefly explain the intuition behind Lemma 5.7. Regarding point (i) , the construction of the two-state reset cascade proceeds as follows. The base case corresponds to Figure 1, while the inductive step for height involves the use of the two-state reset automaton (illustrated in Figure 7) in cascade with the augmentation of the cascade for the case . Intuitively, recognizes all words containing at least one symbol. Using in cascade copies of together with the cascade in Figure 1, corresponds exactly to the language . In Figure 8, we provide an example of the construction for the case .
The proof that is more involved and proceeds by induction on . For the base case (), we have . This case is verified by Lemma 5.3. For the inductive step, assume that the statement holds for every . We need to prove that it also holds for . Suppose, by contradiction, that . By definition, this would imply the existence of a cascade of two-state reset automata such that . However, starting from , the proof shows how to construct a new cascade of two-state reset automata such that . The existence of contradicts the inductive hypothesis, which states that . Therefore, the assumption that must be false, and the cascade cannot exist.
5.3 General Cascades
In this subsection, we examine cascades of reset automata without imposing restrictions on the number of states in each component or on the total number of components. In the previous part, Lemma 5.6 demonstrates that, for cascade of two resets over the alphabet , the maximum expressiveness is achieved when the first component has states. Here, we extend this result to cascades of unbounded height in the Width-Collapse Lemma, that provides lower bounds on the number of states in each component, for which adding states at certain levels does not affect expressiveness.
Lemma 5.8 (Width-Collapse Lemma).
Let be a finite alphabet with . Let be a language. For any positive integers and , if , then , where .
We now demonstrate how to transform general cascades into narrow cascades. Specifically, we show how any cascade of reset automata (of height and with states at level , for each ) can be transformed into an equivalent narrow cascade (i.e. made of two-state resets), at the cost of increasing its height at most by a factor of . This result is based on two key points:
-
1.
Given a general cascade, we can always append a pure-reset automaton at the end without altering its language;
-
2.
the Narrowing Lemma, which we prove below, demonstrates that any cascade of reset automata, whose final component is pure-reset and containing a component with states (and ), can be transformed into a new cascade where is replaced by two new automata, with and states each.
Instrumental to the Narrowing Lemma, the following result demonstrates that, given a general cascade whose last component is a pure-reset automaton, we can modify this last component to make all the states of the preceding components final, without altering the recognized language.
Lemma 5.9.
Consider a cascade of automata, where is a two-state pure-reset automaton. Let be the automaton obtained from by making all states final. Then, there exists a two-state pure-reset automaton such that .
The Narrowing Lemma is stated as follows.
Lemma 5.10 (Narrowing Lemma).
Let be a cascade where is a reset automaton with states for each , and is a pure-reset automaton. Let be an index such that . Then, there exists a cascade of reset automata
| (5) |
such that:
-
(i)
each has states for ;
-
(ii)
if is pure-reset (resp., reset), then also is pure-reset (resp., reset), for ;
-
(iii)
has states and has states; and
-
(iv)
.
By iteratively applying the Narrowing Lemma to every component with more than two states, we obtain a procedure that, given a cascade of reset automata, produces an equivalent cascade where all components are two-state reset automata. Moreover, it is worth noticing that:
-
(i)
by Lemma 4.10, w.l.o.g. the last component of any cascades of reset (or pure-resets) has two states, and therefore the Narrowing Lemma does not need to be applied at the last level;
-
(ii)
if the final component of a cascade is not a pure-reset, a new pure-reset level can always be added without affecting the language of the cascade.
This leads to the following inclusions.
Corollary 5.11.
For each positive it holds that
-
1.
-
2.
where .
Combining Lemma 5.8 and Corollary 5.11, we conclude that if a language is recognized by a cascade of resets of height , it can also be recognized by a cascade of height composed entirely of two-state resets.
Corollary 5.12.
Let be an alphabet such that and let be a language. If admits a cascade of reset automata of height , then where . If , then .
Exploiting the bound for the case , we can prove undefinability of certain languages by general cascades, i.e. without any bound on their height nor on the number of states of its component. As an example, by Lemma 5.7, we know that the language over the alphabet does not belong to the class . If could be recognized by a cascade of height , then it would also be recognized by a two-state cascade of height , leading to the following conclusion: with , the language does not admit any cascade of resets of height 3.
Building upon this reasoning, we can formulate the Generalized Height-Hierarchy Lemma. Unlike the original Height-Hierarchy Lemma, which focuses solely on two-state cascades, the generalized version addresses the undefinability of cascades in a broader context, encompassing general cascades.
Lemma 5.13 (Generalized Height-Hierarchy Lemma).
Let be a positive integer, and define . Consider the language , where and is a two-symbol alphabet. The language cannot be recognized by any cascade of reset automata of height , but it holds that .
6 Efficient closure properties of cascades of reset automata
In this section, we present an efficient method for computing specific closure properties of reset cascades. For instance, for the case in which the operation is binary, given two cascades of resets and (made of only two-states components), we show how it is possible to compute a cascade of two-states resets that recognizes by adding at most one two-state reset automaton (that, in this context, we call brick). We show this for the following operations:
-
(i)
intersection;
-
(ii)
complementation;
-
(iii)
union; and
-
(iv)
left-concatenation of , i.e. given a language to compute .444It is worth noticing that this operation corresponds to compute the closure under the next modality.
Proposition 4.5 already shows that intersection can be implemented efficiently for cascades of resets: given two reset cascades and (with and two-states components, respectively), there exists a cascade for with two-state resets.
Before showing the construction for the remaining operations, we give the following key definitions. We define the finalized version of an automaton , denoted with , as the automaton obtained from by setting all its states as final. The definition naturally extends to cascades: the finalized version of , denoted with , is defined as . Clearly, if is a cascade of reset automata, is still a cascade of reset automata. We define the reachability set of an automaton relative to a set of states as follows.
Definition 6.1 (Reachability Set).
Let be an automaton. Let be a set of states. The reachability set of with respect to , denoted with , is the set . We denote with the set . We write to refer to .
We now show how to efficiently compute the remaining closure properties.
Complementation
To compute complementation, we introduce the negation brick, whose structure is illustrated in Figure 9 and is formally defined here below.
Definition 6.2 (Negation brick).
Let be an automaton. The negation brick for , denoted with , is the two-state pure-reset automaton such that:
-
(i)
the final state is if and only if ;
-
(ii)
the function induced by symbols in maps all states in the non-final state, i.e. ;
-
(iii)
the function induced by symbols in maps all states in the final one, i.e. .
The intuition is that the negation brick, when appended to the end of a cascade , reaches its final state if and only if the underlying cascade is not in a final state. Consequently, by setting all the states of as final, we obtain a cascade that recognizes the complement of , as proved by the following lemma.
Lemma 6.3.
Let be a cascade of automata. The cascade recognizes the language . Moreover, if is a cascade of reset automata, then so is .
Interestingly, if the cascade terminates with a pure-reset layer , this automaton can itself serve the function of the negation brick, without the need of an additional component.
Lemma 6.4.
Let be a cascade of automata such that is a pure-reset automaton. There exists a cascade such that:
-
(i)
;
-
(ii)
each automaton has the same number of states as ;
-
(iii)
if is a reset (resp., pure-reset), then is also a reset (resp., pure-reset).
Union
Given two cascades and of height and , respectively, since , it is possible to build cascade for of height , using the previously discussed constructions. In this section, we present a more efficient construction that introduces only one additional component, referred to as the union brick, resulting in a cascade for of height .
Definition 6.5 (Union brick).
Let and be two automata. Let the set of states . Let . The union brick of and , denoted with , is the two-state pure-reset automaton such that:
-
(i)
the final state is if and only if ;
-
(ii)
the function induced by symbols in maps all states in the final one, i.e. ;
-
(iii)
the function induced by symbols in maps all states in the non-final state, i.e. .
Similarly to the case of complementation, when appended to the end of a cascade , the union brick reaches its final state if and only if either is in a final state or is in a final state. This leads to the following lemma.
Lemma 6.6.
Let and be two cascade of automata. The cascade recognizes the language . Moreover, if and are cascades of reset automata, then so is .
Also in this case, if one of the two automata corresponds to a cascade terminating with a pure-reset component , the union can be performed without the need for additional layers: the automaton effectively serves as the union brick.
Left-concatenation of
Given a cascade , we demonstrate how to construct a cascade that recognizes the language , adding only one brick and guaranteeing that the property of being a reset cascade is preserved. As a by-product of this construction, we obtain that, given a cascade of resets of height equivalent to an formula (interpreted over finite words), it is possible to construct a cascades of resets for of height , where is the next modality of .
We first define the next version of an automaton. The next version of an automaton , denoted as , is defined considering the Cartesian product between the alphabet of and the set . Intuitively, if transitions from to with a symbols , so does with the symbol . On the contrary, all symbols force to transition to the initial state. The formal definition of is given here below.
Definition 6.7 (Next version of an automaton).
Let be an automaton such that either or , for an arbitrary finite set . We define the next version of , denoted as , as the automaton such that:
-
if , then and, for all and for all , it holds: and .
-
if , then and, for all and for all , it holds that: and .
Given a cascade over , we define the next version of , denoted with , as the cascade over .
Figure 10 shows the next versions of the automata in Figure 1. Crucially, computing the next version of an automaton does not alter its property of being a reset automaton.
Lemma 6.8.
Let be a finite alphabet and let be an automaton over or over for an arbitrary finite set . If is reset automaton, then also is a reset automaton.
Now, given any cascade , to capture the language , it suffices to consider the automaton (depicted in Figure 7) with the next version of . In fact, considering that initially both and are in their initial states (which, for , is state ), reading the first input symbol forces:
-
(i)
to transition to state ; and
-
(ii)
to remain in its initial state, because the symbol it reads is .
After the first symbol and for all the rest of the input word, remains in state , while operates like because it reads symbols of the form . As shown by the following lemma, this captures exactly .
Lemma 6.9.
Let be a cascade of automata. The cascade recognizes the language . Moreover, if is a cascade of reset automata, then so is .
7 Conclusions and Future Work
In this paper, we investigated some fundamental properties of cascades of reset automata. Unlike the approach commonly followed in the literature, where the cascade product is restricted to semi-automata, we focused on the case of automata. This allowed us to study the properties of the recognized languages. As an initial step, we showed how to compute regular expressions equivalent to a cascade. Then, on the basis of such a transformation, we established some meaningful expressiveness results, in particular lower bounds to the height and to the minimum number of states per level of a cascade of resets for specific families of languages. Finally, we showed how to compute the closure of reset cascades under certain basic operations by adding at most one brick to the end of the cascade.
As for the future developments of the work, finding an efficient construction for the closure of reset cascades under the concatenation operation is undoubtedly a crucial direction. This would enable the design of an efficient approach to handling the eventually and until operators of , providing, together with the results given in the last section of the paper, an efficient decomposition into reset cascades for full . This would improve the triply-exponential upper bound to such a decomposition achieved by Maler’s algorithm [4, 15]. Last but not least, giving analogous expressiveness and closure results for permutation automata appears to be another promising avenue for further investigation.
References
- [1] Dana Angluin, David Chiang, and Andy Yang. Masked hard-attention transformers and boolean RASP recognize exactly the star-free languages. CoRR, abs/2310.13897, 2023. doi:10.48550/arXiv.2310.13897.
- [2] Alessandro Artale, Luca Geatti, Nicola Gigante, Andrea Mazzullo, and Angelo Montanari. A Singly Exponential Transformation of LTL[X, F] into Pure Past LTL. In Pierre Marquis, Tran Cao Son, and Gabriele Kern-Isberner, editors, Proceedings of the 20th International Conference on Principles of Knowledge Representation and Reasoning, KR 2023, Rhodes, Greece, September 2-8, 2023, pages 65–74, 2023. doi:10.24963/KR.2023/7.
- [3] Alessandro Artale, Luca Geatti, Nicola Gigante, Andrea Mazzullo, and Angelo Montanari. Succinctness issues for LTLf and safety and cosafety fragments of LTL. Information and Computation, 302:105262, 2025. doi:10.1016/j.ic.2024.105262.
- [4] Giuseppe De Giacomo, Antonio Di Stasio, Francesco Fuggitti, and Sasha Rubin. Pure-past linear temporal and dynamic logic on finite traces. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 4959–4965, 2021.
- [5] Giuseppe De Giacomo and Moshe Y. Vardi. Linear Temporal Logic and Linear Dynamic Logic on Finite Traces. In Francesca Rossi, editor, Proceedings of the 23rd International Joint Conference on Artificial Intelligence, pages 854–860. IJCAI/AAAI, 2013. URL: http://www.aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/view/6997.
- [6] Samuel Eilenberg. Automata, languages, and machines., B. Pure and applied mathematics. Academic Press, 1976. URL: https://www.worldcat.org/oclc/310535259.
- [7] Javier Esparza, Rubén Rubio, and Salomon Sickert. Efficient Normalization of Linear Temporal Logic. J. ACM, 71(2):16:1–16:42, 2024. doi:10.1145/3651152.
- [8] Marcus Gelderie. Classifying regular languages via cascade products of automata. In Language and Automata Theory and Applications: 5th International Conference, LATA 2011, Tarragona, Spain, May 26-31, 2011. Proceedings 5, pages 286–297. Springer, 2011. doi:10.1007/978-3-642-21254-3_22.
- [9] Mark Kambites. On the krohn-rhodes complexity of semigroups of upper triangular matrices. Int. J. Algebra Comput., 17(1):187–201, 2007. doi:10.1142/S0218196707003548.
- [10] Nadezda Alexandrovna Knorozova and Alessandro Ronca. On the expressivity of recurrent neural cascades. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 10589–10596. AAAI Press, 2024. doi:10.1609/AAAI.V38I9.28929.
- [11] Nadezda Alexandrovna Knorozova and Alessandro Ronca. On the expressivity of recurrent neural cascades with identity. In Pierre Marquis, Magdalena Ortiz, and Maurice Pagnucco, editors, Proceedings of the 21st International Conference on Principles of Knowledge Representation and Reasoning, KR 2024, Hanoi, Vietnam. November 2-8, 2024, 2024. doi:10.24963/KR.2024/82.
- [12] Kenneth Krohn and John Rhodes. Algebraic theory of machines. I. Prime decomposition theorem for finite semigroups and machines. Transactions of the American Mathematical Society, 116:450–464, 1965.
- [13] Bingbin Liu, Jordan T. Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL: https://openreview.net/forum?id=De4FYqjFueZ.
- [14] Oded Maler. On the Krohn-Rhodes Cascaded Decomposition Theorem. In Zohar Manna and Doron A. Peled, editors, Time for Verification, Essays in Memory of Amir Pnueli, volume 6200 of Lecture Notes in Computer Science, pages 260–278. Springer, 2010. doi:10.1007/978-3-642-13754-9_12.
- [15] Oded Maler and Amir Pnueli. Tight Bounds on the Complexity of Cascaded Decomposition of Automata. In 31st Annual Symposium on Foundations of Computer Science, St. Louis, Missouri, USA, October 22-24, 1990, Volume II, pages 672–682. IEEE Computer Society, 1990. doi:10.1109/FSCS.1990.89589.
- [16] Zohar Manna and Amir Pnueli. A hierarchy of temporal properties (invited paper, 1989). In Proceedings of the 9th annual ACM symposium on Principles of distributed computing, pages 377–410, 1990. doi:10.1145/93385.93442.
- [17] Nicolas Markey. Temporal logic with past is exponentially more succinct, concurrency column. Bull. EATCS, 79:122–128, 2003.
- [18] Robert McNaughton and Seymour A Papert. Counter-Free Automata (MIT research monograph no. 65). The MIT Press, 1971.
- [19] Amir Pnueli. The temporal logic of programs. In 18th Annual Symposium on Foundations of Computer Science (sfcs 1977), pages 46–57. IEEE, 1977. doi:10.1109/SFCS.1977.32.
- [20] Alessandro Ronca. The transformation logics. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI 2024, Jeju, South Korea, August 3-9, 2024, pages 3549–3557. ijcai.org, 2024. URL: https://www.ijcai.org/proceedings/2024/393.
- [21] Alessandro Ronca, Nadezda Alexandrovna Knorozova, and Giuseppe De Giacomo. Automata cascades: Expressivity and sample complexity. In Brian Williams, Yiling Chen, and Jennifer Neville, editors, Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2023, Washington, DC, USA, February 7-14, 2023, pages 9588–9595. AAAI Press, 2023. doi:10.1609/AAAI.V37I8.26147.
- [22] Karl-Heinz Zimmermann. On Krohn-Rhodes theory for semiautomata. CoRR, abs/2010.16235, 2020. arXiv:2010.16235.