Private Estimation When Data and Privacy Demands Are Correlated
Abstract
Differential Privacy (DP) is the current gold-standard for ensuring privacy for statistical queries. Estimation problems under DP constraints appearing in the literature have largely focused on providing equal privacy to all users. We consider the problems of empirical mean estimation for univariate data and frequency estimation for categorical data, both subject to heterogeneous privacy constraints. Each user, contributing a sample to the dataset, is allowed to have a different privacy demand. The dataset itself is assumed to be worst-case and we study both problems under two different formulations – first, where privacy demands and data may be correlated, and second, where correlations are weakened by random permutation of the dataset. We establish theoretical performance guarantees for our proposed algorithms, under both PAC error and mean-squared error. These performance guarantees translate to minimax optimality in several instances, and experiments confirm superior performance of our algorithms over other baseline techniques.
Keywords and phrases:
Differential Privacy, Personalized Privacy, Heterogeneous Privacy, Correlations in PrivacyFunding:
Syomantak Chaudhuri: Supported by AI Policy Hub, U.C. Berkeley.Copyright and License:
2012 ACM Subject Classification:
Security and privacySupplementary Material:
Software (Source Code): https://github.com/syomantak/FORC25archived at
Funding:
Authors were supported from NSF CCF-1750430 and CCF-2007669Editors:
Mark BunSeries and Publisher:
1 Introduction
Mean and frequency estimation are pillars of data analysis. Empirical mean estimation plays a crucial role in fields like modern portfolio theory [35], machine learning [36], and healthcare [11] to name a few. For service providers, relative frequency of categorical data is an important statistic used, for example, to capture distribution of traffic across websites [46], age and geographical distribution of social media users [38], and so forth. Thus, it is well-motivated to study estimation of these two statistics through the lens of privacy due to the increased demand for such, as reflected in recent laws such as GDPR and CCPA. We adopt the popular framework of Differential Privacy (DP) [22, 23], which has found many real-world applications [24, 8, 1].
The trade-off between estimation accuracy and afforded privacy is one of the most fundamental questions in this field. An aspect of estimation subject to privacy constraints that has not been thoroughly studied in literature is the case when different users demand different levels of privacy for their data. Existing works mostly focus on a common privacy level for the users (see Wang et al. [43] for references), but this does not reflect the real world where different users have different privacy requirements [3]. These heterogeneous privacy demands naturally arise in social media platforms, where users can get more features by opting-in to share more data. For example, in a discontinued feature, users on Facebook could share their location with the platform in order to get notified if a friend is nearby [33]. Thus, heterogeneity in privacy requirements is an important consideration and there needs to be a greater understanding of the accuracy-privacy trade-off. The presented work focuses on understanding this trade-off for mean and frequency estimation.
1.1 Our Contribution and Problem Description
We consider the problem of mean estimation of univariate data and frequency estimation of categorical data under heterogeneous privacy demands in the central-DP model. In this model, users provide the server with their datapoint (such as their salary in mean estimation or salary bracket in frequency estimation) and a privacy level. The server is then tasked with publishing an estimate of the sample mean or relative sample frequencies of the categories in the dataset, while respecting the individual privacy constraints. We consider the adversarial minimax setting where the dataset is the worst-case for the algorithm. This is in contrast to the statistical minimax setting where the dataset is sampled from a worst-case distribution. For this adversarial model, we formulate two distinct settings: the so-called correlated and weakly-correlated settings. These are explained below, and formally defined in Section 2. Both estimation problems are studied in both correlated and weakly-correlated settings, under both PAC error and mean-squared error.
Since we assume that we are given the heterogeneous privacy demands, simply considering the worst-case dataset leads to arbitrary correlations between user data values and their individual privacy requirements. Correlations may be reasonable for certain cases. For example, users sharing their salary may demand higher privacy if they are have an extremely high or low salary. Such correlations make it harder to estimate frequencies of categories in which users demand a lot more privacy. We emphasize that such correlations, although often accepted to be present in real-world, have never been modeled in the literature prior to this work that the authors are aware of.
It is equally well-motivated to consider the weakly-correlated setting where users do not have a strong correlation between their data and privacy demand. For example, for frequency estimation of users’ geographical-region, there may be no meaningful correlation between a user’s location and their privacy demand. We formulate this “weakly-correlated” setting by modeling the realization of the dataset as a uniformly random permutation of a worst-case dataset.
We propose algorithms for both PAC error and mean-squared error, for both correlated and weakly-correlated settings, for both mean and frequency estimation. Thus, in this work, we investigate eight different minimax rates. To obtain tight upper bounds on the minimax rates, we consider slightly different algorithms tailored to each combination of problem, setting, and error metric. However, we also present a fast heuristic algorithm that is agnostic to the underlying modeling assumptions and performs well in practice for all eight problems. Through experiments, we compare our algorithms to natural baseline algorithms and show superior performance of our algorithms. We also prove the minimax optimality of our algorithms for some combinations of problems and error metrics.
Organization: We define the problem in Section 2 and describe our algorithm in Section 3. Experiments are presented in Section 4, followed by theoretical analysis of the minimax rate in Section 5. Extended discussion can be found in Section 6, followed by concluding remarks on possible future directions of work.
1.2 Related Work
The two most common models for DP are the central-DP model [22] and the local-DP model [32]; we focus on the central-DP model. The problem of frequency estimation under privacy constraints is well-studied under homogeneous DP [23, 29, 24, 44]. Mean estimation under privacy is also well-studied (see Biswas et al. [13] for references); although most work on mean estimation focuses on the statistical setting, one can use the ideas from empirical frequency estimation of Dwork et al. [23] and corresponding lower bounds from Vadhan [40] to obtain good error bounds for empirical mean estimation.
In terms of heterogeneity in privacy demands, a special case considered in the literature is the existence of a dataset requiring homogeneous privacy in conjunction with a public dataset [9, 10, 34, 5, 37, 30, 6, 42, 12]. Some early works on Heterogeneous DP (HDP) [4, 28] propose task-agnostic methods to deal with the heterogeneity in privacy. While the methods are versatile since they are task agnostic, one can not expect competitive performance from their methods for specific tasks like mean or frequency estimation. Further, neither of the methods can handle the case if there is a single user having no privacy demand (public data). Mean estimation under HDP is considered by Ferrando et al. [26] in the local-DP model, assuming the variance of the distribution is known. HDP mean estimation under the central-DP model has been studied in the statistical setting where users have i.i.d. data [25, 16, 18, 19]. Acharya et al. [2] study the problem of ridge regression under HDP and provide an algorithm similar to one of our baseline techniques we use in the experiments.111Their method can perform arbitrarily worse than the minimax optimal ridge regression algorithm; see the “Prop” algorithm in Section 4. HDP has also been considered in the context of mechanism design, auctions, and data valuation [25, 7, 31]. The problem of creating confidence intervals for the mean under sequential observations in local-DP was studied by Waudby-Smith et al. [45] for univariate random variables with heterogeneity in privacy demand. Canonne and Yucheng [15] present the problem of testing whether two datasets are from the same multinomial distribution under a different privacy constraint for each dataset.
Chaudhuri et al. [18] find the minimax optimal mean estimator for a given heterogeneous privacy demand when the user data is sampled i.i.d. from some unknown univariate distribution. The estimators employed in this work are similar in spirit to their work and our weakly-correlated setting exhibits a minimax rate closely related to their minimax rate. The exact relation between the two minimax rates, while intuitive, is non-trivial. The correlated setting we consider is significantly different from their set up and the results are proved using different techniques.
In the context of modeling correlations between privacy demand and data, Ghosh and Roth [27] show a negative result in the context of mechanism design. Ghosh and Roth [27] show that a dominant strategy incentive compatible mechanism for selling privacy at an auction, where privacy is provided to both user’s data and privacy sensitivity, is not possible in a meaningful way. However, we do not operate in the setting of an auction so the question of how to deal with correlations between data and privacy remains open. However, aside from Ghosh and Roth [27], the literature so far lacks any clear formulation of this problem, let alone a solution.
2 Problem Definition
2.1 Notation
The probability simplex in -dimensions is represented by . The notation is used to denote . We use to refer to the modified ceiling function . The notation denotes the vector, of appropriate length, with all entries being equal to . In this work, the notation , denoting a randomized algorithm mapping to a probability distribution on , will interchangeably be used to refer to the output distribution or a sample from it. For vectors and , shall represent element-wise division. The notations and denote inequality and equality that hold up to a universal multiplicative constant.
2.2 Problem Definition
Heterogeneous Differential Privacy (HDP) permits users to have different privacy requirements. The standard definition for HDP is presented in Definition 1 [4, 25].
Definition 1 (Heterogeneous Differential Privacy).
A randomized algorithm is said to be -DP for if
| (1) |
for all measurable sets , where are any two “neighboring” datasets that differ arbitrarily in only the -th component.
In the DP framework, smaller means higher privacy. The privacy levels can range from zero to infinity.
Let be the number of users and let the heterogeneous privacy demand of the users be the vector . Without loss of generality, we assume it is arranged in a non-decreasing order, i.e., user has privacy requirement , and for . We operate in the central-DP regime.
For normalized empirical frequency estimation with categories (or bins), we have and ; the parameter is assumed to be known. For empirical mean estimation, without loss of generality, we consider and . We study the problem in the adversarial minimax regime – for an algorithm, the worst case performance over all datasets is analyzed. We formulate two settings to capture possible correlations.
-
1.
Correlated setting: In this setting, for the privacy demand and -DP mechanism given, an adversary chooses a worst-case dataset . In other words, for user with privacy demand , adversary chooses the datapoint for .
-
2.
Weakly-correlated setting: In this setting, for the privacy demand and -DP mechanism given, an adversary chooses a worst-case dataset that gets randomly permuted. That is, if denotes a uniformly random permutation over then user with privacy demand is assigned the datapoint . Henceforth, we let denote the permuted dataset.
Section 2.3 motivates these two settings. Let refer to the true empirical statistic of the dataset. In other words,
-
For mean estimation, and it is defined as .
-
For frequency estimation, and the -th component of is defined as .
Note that these functions are permutation-invariant, i.e., . Let refer to the set of all -DP mechanisms from to . We define the minimax rates of frequency estimation in Definition 2.
Definition 2 (Minimax Rates for Frequency Estimation).
The PAC-minimax rate for bins, privacy demand , and error probability is
the minimum value of the -th quantile of the error under the worst-case dataset for any -DP algorithm.
The MSE-minimax rate is similarly defined.
(A) Correlated setting: The PAC-minimax rate is given by
| (2) |
the MSE-minimax rate is given by
| (3) |
where the expectations are taken over the randomness in .
(B) Weakly-correlated setting: The PAC-minimax rate is given by
| (4) |
the MSE-minimax rate is given by
| (5) |
where the expectations are taken over the randomness in and .
Similarly, we define the minimax rates for mean estimation in Definition 3, deferred to Appendix A.
2.3 Modeling Choice & Motivation
Since we consider the error bounds for a given privacy demand and an adversarial dataset, there could be an arbitrary correlation between the dataset and the privacy demand in the correlated setting. Considering arbitrary worst-case correlations avoids the need for obscure assumptions on joint distribution between privacy and data. This may or may not be desired, depending on the application. For example, if the categorical data consists of salary range of users, then the users in the highest and lowest salary range might demand a higher privacy leading to correlations between data and privacy demands.
A counterexample is if the categorical data consists of different types of cancers in patients; in this case such correlations need not exist in a meaningful way. Thus, to model such setting without meaningful correlations, we formulate the weakly correlated setting. Another possible way to break the correlation is to go to the statistical minimax setting where the samples are generated i.i.d. from some distribution, independent of the privacy demands, and the goal is to estimate the underlying multinomial distribution. The weakly correlated minimax rates and the statistical minimax rates are closely related (see Theorem 3). In other words, the random permutation of the worst-case dataset in the weakly correlated setting effectively breaks the correlations between the privacy demand and the dataset.
The above described statistical minimax rate is not related to the correlated adversarial minimax rate in a meaningful way. To see this, consider the case where all the users have no privacy constraint; the correlated adversarial minimax error is zero but the statistical minimax error is of the order (PAC or square-root of MSE). Conversely, consider the case where users demand no privacy and rest of the users demand ; the statistical rate is of the order but the correlated adversarial minimax rate is of the order .
We do not consider the worst case of since the worst-case is trivial when every user demands full privacy () and no meaningful estimation can be done. Other possible modeling choices, not presented in this work, include a different norm for errors, the statistical setting where the underlying dataset and privacy demand is jointly generated according to some distribution, and so on.
3 Algorithm Description
We propose Heterogeneous Private Frequency (HPM), a family of mechanisms with the skeleton code presented in Algorithm 1. Laplace distribution with parameter is denoted by L in Algorithm 1. Table 1 outlines our suggested weights to be used in HPF for the relevant setting. Note that these different weight suggestions are mainly to obtain theoretically good performance in the respective setting. For example, to get good theoretical performance under PAC metric for error level in the correlated setting, one would use the weights given by HPF-C from the table. The second-last letter of the algorithm names specify if the algorithm is for correlated setting (C) or weakly-correlated setting (W). The last letter specifies if the algorithm is geared for optimizing the PAC error () error or the MSE error ().
While these methods are intended to facilitate characterization of fundamental limits, an alternate fast, heuristic-based algorithm HPF-A is also described which can be used in either setting and error metric, i.e., it is agnostic to the modeling assumptions and error metric. We stress that while we propose a different algorithm based on the setting and error metric for proving theoretical guarantees, HPF-A can be used agnostic to the setting since it enjoys good performance (see Section 4) across the settings and metric, and can be employed in practice.
Similarly, for mean estimation, we propose the family of algorithms HPM presented in Algorithm 2 and the corresponding weights are presented in Table 3, both deferred to Appendix A.
The performance guarantees for the algorithms and lower bounds on the minimax rate can be found in Section 5. Lemma 1 guarantees that the algorithms described in Algorithm 1 satisfy the privacy constraint; the proof can be found in [17, Appendix D].
| Algorithm | Weights |
|---|---|
| HPF-C | |
| HPF-C | |
| HPF-W | |
| HPF-W | |
| HPF-A |
Lemma 1 (Privacy Guarantee).
The proposed family of algorithms HPF and HPM satisfy the -DP constraint defined in Definition 1.
Broadly, our proposed algorithms assign different weights to different users instead of equally weighing the users for the estimation task. For example, in frequency estimation, for weights , if user has a datapoint in bin , then HPF adds to bin instead of . In particular, if the users with more stringent privacy are weighed less, then the magnitude of noise that is required to be added to the frequency estimate for ensuring -DP can be significantly less. On the flip side, this reweighing introduces bias in the output as the data from less privacy stringent users dominates. Thus, the weights need to be carefully chosen to optimize this trade-off.
The minimization in the algorithm minimizes an upper bound for error metric in the relevant setting. For example, HPF-C minimizes an upper bound for the -th quantile of the -error over the set of weights . All the optimization problems are quadratic programs with linear constraints and can be solved using a numerical optimizer like cvxpy [20]. Faster approximations of the algorithms which can be solved exactly in time are discussed in Section 6.
4 Representative Experiments
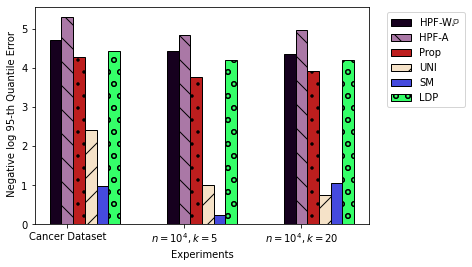
We present some representative experiments for frequency estimation in this section in Figure 1. More extensive experiments and exact implementation details can be found in Appendix B. In Figure 1(A), we consider three different datasets and construct a privacy demand that is correlated with the categorical data. We aim to optimize the MSE (-error) so the variant of HPF that we employ is HPF-C. The negative of the log MSE is plotted for the different algorithms. Similarly, in Figure 1(B), we construct a privacy demand and consider three different datasets under weak-correlations. We aim to optimize the PAC error with , i.e., the 95-th quantile of the error so the variant of HPF that we employ is HPF-W with . The negative of the log of the 95-th empirical error quantile is plotted for the different algorithms.
Overall, in both correlated and weakly-correlated settings, under both PAC and MSE, HPF-A is a superior algorithm due to it good performance and being agnostic to the modeling choices and the error metric.
5 Performance Analysis
We summarize our theoretical results in this section. Let
| (6) | ||||
| (7) |
The functions and track the errors incurred by the mechanisms on using weights in the correlated and the weakly-correlated setting respectively. The first term corresponds to the bias due to the weighing scheme and the second term accounts for the necessary noise due to the privacy requirement. We denote their corresponding minimum values by
| (8) |
and
| (9) |
Table 2 summarizes the results presented in this work. As one would expect, the upper bounds in the correlated setting is always greater than the corresponding one in weakly-correlated setting – in both mean and frequency estimation under both PAC and MSE bounds. The theorems can be found in Appendix C. For the rest of the section, we focus on the question of minimax optimality - are our algorithms minimax optimal?
| Setting | Algorithm | UB | LB | UB LB? |
|---|---|---|---|---|
| F, C, | HPF-C | Theorem 6 | Yes | |
| F, C, | HPF-C | ✗ | N/A | |
| F, W, | HPF-W | Theorem 6 | Under certain assumptions | |
| F, W, | HPF-W | Theorem 7 | Near-optimal | |
| M, C, | HPM-C | Theorem 6 | Yes | |
| M, C, | HPM-C | ✗ | N/A | |
| M, W, | HPM-W | Theorem 6 | Under certain assumptions | |
| M, W, | HPM-W | Theorem 7 | Yes |
5.1 Minimax Optimality in Correlated Regime
In the correlated regime, we present Theorem 1 on the minimax optimality of HPF-C and HPM-C in a certain regime of interest of the PAC minimax rate. The proof is presented in [17, Appendix I].
Theorem 1 (PAC Minimax Optimality in Correlated Setting).
In particular, when the PAC minimax rate is at least and at most , then our upper bound is of the same order as the minimax rate, for both mean and frequency estimation. We emphasize that this really is the regime of interest for the problem being considered; without any privacy constraint, normalized mean and frequency count is naturally of the precision . Theorem 6 also assumes that the PAC minimax rate is bounded away from the trivial upper bound of . Thus, for the practically important regime of values of the PAC minimax rate, our proposed algorithms are order optimal.
5.2 Minimax Optimality in Weakly-correlated Regime
In the weakly-correlated regime, to compare the PAC upper and lower bounds, we consider two regimes. This is primarily because of the lower bounds presented in Theorem 6 are difficult to analyze without further simplifications. Let denote the empirical variance of the vector . Theorem 2 shows how the upper and lower bounds behave in the high privacy regime; the proof can be found in [17, Appendix I].
Theorem 2 (PAC Minimax Optimality in Weakly-correlated Setting).
Assume high privacy demand where , for the two problems.
(A) Frequency Estimation: In the regime ,
we have the following upper and lower bound on ,
| (10) |
The upper bound is achieved by HPF-W and HPF-A. Further, if , then we have
| (11) |
(B) Mean Estimation: In the regime , we have the following upper and lower bound on ,
| (12) |
The upper bound is achieved by HPM-W and HPM-A. Further, if , then we have
| (13) |
The high privacy assumption, i.e., , is helpful for dealing with the implicit lower bounds presented in terms of expectation in Theorem 6. Such assumptions on the privacy level are frequent in the literature, even for homogeneous privacy [25, 21]. The downside to this regime is that it does not explain what occurs if there are some users desiring no privacy , i.e., there is some public data. While HPF-W and HPM-W can handle such , the theorem can not. We remark that the assumptions made in Theorem 2 might be a shortcoming of the analysis and not the algorithm. For the homogeneous privacy demand , one can recover the minimax rate from the theorem since the variance term is zero; see Dwork et al. [23] and Vadhan [40] for upper and lower bounds respectively.
Before presenting MSE minimax optimality result for the weakly-correlated setting in Theorem 3, we define another minimax rate closely related to the problem. For some set , let denote the set of probability distributions on ; for a distribution , let denote its mean. Similar to the MSE-minimax rates, we define the minimax rate for mean estimation under -DP from i.i.d. data as
| (14) |
We take a moment to comment on . For -users with no privacy demand, let , then note that as this is the standard minimax rate for mean estimation without privacy constraints [41]. Note that we have . In Theorem 3, we show MSE-minimax optimality of the proposed algorithms for the weakly-correlated setting in the regime of privacy demands where causes a non-trivial increase in the statistical rate to be greater than . In fact, in this regime, the MSE-minimax rates for empirical mean and frequency estimation are nearly the same as the MSE-minimax rate for statistical mean estimation.
Theorem 3 (MSE Minimax Optimality in Weakly-correlated Setting).
For values of satisfying , HPF-W and HPM-W are minimax optimal.
Further,
| (15) |
for frequency estimation and
| (16) |
for mean estimation.
The proof can be found in [17, Appendix J]. The -factor difference in the upper and lower bounds for can probably be improved with a tighter lower bound.
6 Extended Discussion
Efficient and approximate versions of HPF and HPM algorithms: The minimizations in the HPF and HPM algorithms (except HPF-A and HPM-A) can be the bottleneck in terms of computation and numerical stability. In order to address these two concerns, one can consider making the upper bound loose by replacing the -norm with -norm (the latter upper bounds the former). These variants of the algorithm can be efficiently implemented in time using the algorithm presented by Chaudhuri et al. [18]. Some experiments with this variant of the algorithm are presented in [17, Appendix M].
Free Privacy.
An interesting phenomenon in the context of estimation under heterogeneous privacy constraints is the emergence of extra privacy given by the algorithm to some of the users than what is required, contrary to the intuition that providing less privacy should lead to improved performance; such observations have been made in literature before [25, 16, 18]. When an HPF or HPM algorithm uses weights (in either setting), the privacy guarantee for user is . The equality only holds for every user when the weights are chosen proportional to the privacy parameter, i.e., . In the context of minimax optimality, we know that this proportional weighing can be strictly sub-optimal. Thus, there is a phenomenon of free and extra privacy afforded to the users by the algorithm.
7 Future Work: Alternate threat models for HDP
In this work, we implicitly assume a strong threat model where an adversary that observes the mechanism output is aware of the privacy demands of the users – this is because we use Definition 1 that does not necessarily protect the privacy demanded by the users. In some applications, the privacy demand may already be public such as social media where others can see if some user has decided to keep their profile private. It seems interesting to investigate an alternative threat model, where the adversary does not have access to the privacy demands. This raises several new challenges, such as design of mechanisms that leak limited information about both the dataset and the potentially correlated privacy demands. It’s not even clear that standard definitions of differential privacy (e.g., Definition 1) are suitable for this new threat model.
References
- [1] John M. Abowd. The u.s. census bureau adopts differential privacy. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Association for Computing Machinery, 2018. doi:10.1145/3219819.3226070.
- [2] Krishna Acharya, Franziska Boenisch, Rakshit Naidu, and Juba Ziani. Personalized differential privacy for ridge regression. arXiv preprint arXiv:2401.17127, 2024. doi:10.48550/arXiv.2401.17127.
- [3] Mark S. Ackerman, Lorrie Faith Cranor, and Joseph Reagle. Privacy in e-commerce: examining user scenarios and privacy preferences. In Proceedings of the 1st ACM Conference on Electronic Commerce, EC ’99, pages 1–8. Association for Computing Machinery, 1999. doi:10.1145/336992.336995.
- [4] Mohammad Alaggan, Sébastien Gambs, and Anne-Marie Kermarrec. Heterogeneous differential privacy. Journal of Privacy and Confidentiality, 2017. doi:10.29012/jpc.v7i2.652.
- [5] Noga Alon, Raef Bassily, and Shay Moran. Limits of private learning with access to public data. Advances in neural information processing systems, 2019. doi:10.48550/arXiv.1910.11519.
- [6] Ehsan Amid, Arun Ganesh, Rajiv Mathews, Swaroop Ramaswamy, Shuang Song, Thomas Steinke, Vinith M Suriyakumar, Om Thakkar, and Abhradeep Thakurta. Public data-assisted mirror descent for private model training. In International Conference on Machine Learning. PMLR, 2022. URL: https://proceedings.mlr.press/v162/amid22a.html.
- [7] Ameya Anjarlekar, S. Rasoul Etesami, and R. Srikant. Striking a balance: An optimal mechanism design for heterogenous differentially private data acquisition for logistic regression. CoRR, abs/2309.10340, 2023. doi:10.48550/arXiv.2309.10340.
- [8] Apple. Learning with privacy at scale differential, 2017. URL: https://api.semanticscholar.org/CorpusID:43986173.
- [9] Raef Bassily, Albert Cheu, Shay Moran, Aleksandar Nikolov, Jonathan Ullman, and Steven Wu. Private query release assisted by public data. In International Conference on Machine Learning. PMLR, 2020. URL: http://proceedings.mlr.press/v119/bassily20a.html.
- [10] Raef Bassily, Shay Moran, and Anupama Nandi. Learning from mixtures of private and public populations. Advances in Neural Information Processing Systems, 2020. doi:10.48550/arXiv.2008.00331.
- [11] Kornelia M. Batko and Andrzej Slezak. The use of big data analytics in healthcare. J. Big Data, 9(1):3, 2022. doi:10.1186/s40537-021-00553-4.
- [12] Alex Bie, Gautam Kamath, and Vikrant Singhal. Private estimation with public data. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL: http://papers.nips.cc/paper_files/paper/2022/hash/765ec49952dd0140ac754d6d3f9bc899-Abstract-Conference.html.
- [13] Sourav Biswas, Yihe Dong, Gautam Kamath, and Jonathan Ullman. Coinpress: Practical private mean and covariance estimation. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, volume 33, pages 14475–14485, 2020. URL: https://proceedings.neurips.cc/paper/2020/hash/a684eceee76fc522773286a895bc8436-Abstract.html.
- [14] CA State Controller. University of california salary data, 2022. Accessed: 2024-01-22. URL: https://publicpay.ca.gov/Reports/RawExport.aspx.
- [15] Clément L. Canonne and Yucheng Sun. Private distribution testing with heterogeneous constraints: Your epsilon might not be mine. CoRR, abs/2309.06068, 2023. doi:10.48550/arXiv.2309.06068.
- [16] Syomantak Chaudhuri and Thomas A. Courtade. Mean estimation under heterogeneous privacy: Some privacy can be free. In IEEE International Symposium on Information Theory, ISIT 2023, Taipei, Taiwan, June 25-30, 2023, pages 1639–1644. IEEE, 2023. doi:10.1109/ISIT54713.2023.10206746.
- [17] Syomantak Chaudhuri and Thomas A. Courtade. Private estimation when data and privacy demands are correlated, 2024. doi:10.48550/arXiv.2407.11274.
- [18] Syomantak Chaudhuri, Konstantin Miagkov, and Thomas A. Courtade. Mean estimation under heterogeneous privacy demands. IEEE Trans. Inf. Theory, 71(2):1362–1375, 2025. doi:10.1109/TIT.2024.3511498.
- [19] Rachel Cummings, Hadi Elzayn, Emmanouil Pountourakis, Vasilis Gkatzelis, and Juba Ziani. Optimal data acquisition with privacy-aware agents. In 2023 IEEE Conference on Secure and Trustworthy Machine Learning, SaTML 2023, Raleigh, NC, USA, February 8-10, 2023, pages 210–224. IEEE, IEEE, 2023. doi:10.1109/SaTML54575.2023.00023.
- [20] Steven Diamond and Stephen Boyd. CVXPY: A Python-embedded modeling language for convex optimization. Journal of Machine Learning Research, 2016. URL: https://jmlr.org/papers/v17/15-408.html.
- [21] John C. Duchi, Martin J. Wainwright, and Michael I. Jordan. Local privacy and minimax bounds: Sharp rates for probability estimation. In Christopher J. C. Burges, Léon Bottou, Zoubin Ghahramani, and Kilian Q. Weinberger, editors, Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, pages 1529–1537, 2013. URL: https://proceedings.neurips.cc/paper/2013/hash/5807a685d1a9ab3b599035bc566ce2b9-Abstract.html.
- [22] Cynthia Dwork, Krishnaram Kenthapadi, Frank McSherry, Ilya Mironov, and Moni Naor. Our data, ourselves: Privacy via distributed noise generation. In Serge Vaudenay, editor, Advances in Cryptology - EUROCRYPT 2006, 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, May 28 - June 1, 2006, Proceedings, volume 4004 of Lecture Notes in Computer Science, pages 486–503. Springer, Springer, 2006. doi:10.1007/11761679_29.
- [23] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam D. Smith. Calibrating noise to sensitivity in private data analysis. In Shai Halevi and Tal Rabin, editors, Theory of Cryptography, Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006, Proceedings, volume 3876 of Lecture Notes in Computer Science, pages 265–284. Springer, Springer, 2006. doi:10.1007/11681878_14.
- [24] Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova. RAPPOR: randomized aggregatable privacy-preserving ordinal response. In Gail-Joon Ahn, Moti Yung, and Ninghui Li, editors, Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, November 3-7, 2014, pages 1054–1067, Scottsdale, Arizona, 2014. ACM. doi:10.1145/2660267.2660348.
- [25] Alireza Fallah, Ali Makhdoumi, Azarakhsh Malekian, and Asuman E. Ozdaglar. Optimal and differentially private data acquisition: Central and local mechanisms. Oper. Res., 72(3):1105–1123, 2024. doi:10.1287/opre.2022.0014.
- [26] Cecilia Ferrando, Jennifer Gillenwater, and Alex Kulesza. Combining public and private data. CoRR, abs/2111.00115, 2021. doi:10.48550/arXiv.2111.00115.
- [27] Arpita Ghosh and Aaron Roth. Selling privacy at auction. In Yoav Shoham, Yan Chen, and Tim Roughgarden, editors, Proceedings 12th ACM Conference on Electronic Commerce (EC-2011), San Jose, CA, USA, June 5-9, 2011, pages 199–208. ACM, 2011. doi:10.1145/1993574.1993605.
- [28] Zach Jorgensen, Ting Yu, and Graham Cormode. Conservative or liberal? personalized differential privacy. In Johannes Gehrke, Wolfgang Lehner, Kyuseok Shim, Sang Kyun Cha, and Guy M. Lohman, editors, 31st IEEE International Conference on Data Engineering, ICDE 2015, Seoul, South Korea, April 13-17, 2015, pages 1023–1034. IEEE Computer Society, 2015. doi:10.1109/ICDE.2015.7113353.
- [29] Peter Kairouz, Kallista A. Bonawitz, and Daniel Ramage. Discrete distribution estimation under local privacy. In Maria-Florina Balcan and Kilian Q. Weinberger, editors, Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, volume 48 of JMLR Workshop and Conference Proceedings, pages 2436–2444. PMLR, JMLR.org, 2016. URL: http://proceedings.mlr.press/v48/kairouz16.html.
- [30] Peter Kairouz, Mónica Ribero Diaz, Keith Rush, and Abhradeep Thakurta. (nearly) dimension independent private ERM with adagrad ratesvia publicly estimated subspaces. In Mikhail Belkin and Samory Kpotufe, editors, Conference on Learning Theory, COLT 2021, 15-19 August 2021, Boulder, Colorado, USA, volume 134 of Proceedings of Machine Learning Research, pages 2717–2746. PMLR, PMLR, 2021. URL: http://proceedings.mlr.press/v134/kairouz21a.html.
- [31] Justin Singh Kang, Ramtin Pedarsani, and Kannan Ramchandran. The fair value of data under heterogeneous privacy constraints in federated learning. Trans. Mach. Learn. Res., 2024, 2024. URL: https://openreview.net/forum?id=ynG5Ak7n7Q.
- [32] Shiva Prasad Kasiviswanathan, Homin K. Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam D. Smith. What can we learn privately? SIAM J. Comput., 40(3):793–826, 2011. doi:10.1137/090756090.
- [33] Hong Ping Li, Haibo Hu, and Jianliang Xu. Nearby friend alert: Location anonymity in mobile geosocial networks. IEEE Pervasive Comput., 12(4):62–70, 2013. doi:10.1109/MPRV.2012.82.
- [34] Terrance Liu, Giuseppe Vietri, Thomas Steinke, Jonathan R. Ullman, and Zhiwei Steven Wu. Leveraging public data for practical private query release. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pages 6968–6977. PMLR, PMLR, 2021. URL: http://proceedings.mlr.press/v139/liu21w.html.
- [35] Harry Markowitz. Portfolio selection. The Journal of Finance, 7(1):77–91, 1952. URL: http://www.jstor.org/stable/2975974.
- [36] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Aarti Singh and Xiaojin (Jerry) Zhu, editors, Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA, volume 54 of Proceedings of Machine Learning Research, pages 1273–1282. PMLR, PMLR, 2017. URL: http://proceedings.mlr.press/v54/mcmahan17a.html.
- [37] Anupama Nandi and Raef Bassily. Privately answering classification queries in the agnostic PAC model. In Aryeh Kontorovich and Gergely Neu, editors, Algorithmic Learning Theory, ALT 2020, 8-11 February 2020, San Diego, CA, USA, volume 117 of Proceedings of Machine Learning Research, pages 687–703. PMLR, PMLR, 2020. URL: http://proceedings.mlr.press/v117/nandi20a.html.
- [38] Koustuv Saha, Yozen Liu, Nicholas Vincent, Farhan Asif Chowdhury, Leonardo Neves, Neil Shah, and Maarten W. Bos. Advertiming matters: Examining user ad consumption for effective ad allocations on social media. In Yoshifumi Kitamura, Aaron Quigley, Katherine Isbister, Takeo Igarashi, Pernille Bjørn, and Steven Mark Drucker, editors, CHI ’21: CHI Conference on Human Factors in Computing Systems, Virtual Event / Yokohama, Japan, May 8-13, 2021, pages 581:1–581:18. ACM, 2021. doi:10.1145/3411764.3445394.
- [39] U.S. Department of Health and Human Services, Centers for Disease Control and Prevention, and National Cancer Institute. U.s. cancer statistics data visualizations tool, based on 2022 submission data (1999-2020), 2020. Accessed: 2024-01-22. URL: https://gis.cdc.gov/Cancer/USCS/#/AtAGlance/.
- [40] Salil P. Vadhan. The complexity of differential privacy. In Yehuda Lindell, editor, Tutorials on the Foundations of Cryptography, pages 347–450. Springer International Publishing, 2017. doi:10.1007/978-3-319-57048-8_7.
- [41] Martin J Wainwright. High-dimensional statistics: A non-asymptotic viewpoint. Cambridge university press, 2019.
- [42] Di Wang, Huangyu Zhang, Marco Gaboardi, and Jinhui Xu. Estimating smooth GLM in non-interactive local differential privacy model with public unlabeled data. In Vitaly Feldman, Katrina Ligett, and Sivan Sabato, editors, Algorithmic Learning Theory, 16-19 March 2021, Virtual Conference, Worldwide, volume 132 of Proceedings of Machine Learning Research, pages 1207–1213. PMLR, PMLR, 2021. URL: http://proceedings.mlr.press/v132/wang21a.html.
- [43] Teng Wang, Xuefeng Zhang, Jingyu Feng, and Xinyu Yang. A comprehensive survey on local differential privacy toward data statistics and analysis. Sensors, 20(24):7030, 2020. doi:10.3390/s20247030.
- [44] Tianhao Wang, Jeremiah Blocki, Ninghui Li, and Somesh Jha. Locally differentially private protocols for frequency estimation. In Engin Kirda and Thomas Ristenpart, editors, 26th USENIX Security Symposium, USENIX Security 2017, Vancouver, BC, Canada, August 16-18, 2017, pages 729–745. USENIX Association, 2017. URL: https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/wang-tianhao.
- [45] Ian Waudby-Smith, Zhiwei Steven Wu, and Aaditya Ramdas. Nonparametric extensions of randomized response for private confidence sets. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 36748–36789. PMLR, 23–29 July 2023. URL: https://proceedings.mlr.press/v202/waudby-smith23a.html.
- [46] Tong Yang, Jie Jiang, Peng Liu, Qun Huang, Junzhi Gong, Yang Zhou, Rui Miao, Xiaoming Li, and Steve Uhlig. Elastic sketch: adaptive and fast network-wide measurements. In Sergey Gorinsky and János Tapolcai, editors, Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, SIGCOMM 2018, Budapest, Hungary, August 20-25, 2018, pages 561–575. ACM, 2018. doi:10.1145/3230543.3230544.
Appendix A Mean Estimation: Definition and HPM Mechanism
Definition 3 (Minimax Rates for Mean Estimation).
(A) Correlated setting: The PAC-minimax rate is given by
| (17) |
the MSE-minimax rate is given by
| (18) |
where the expectations are taken over the randomness in the map .
(B) Weakly-correlated setting: The PAC-minimax rate is given by
| (19) |
the MSE-minimax rate is given by
| (20) |
where the expectations are taken over the randomness in the maps and .
The family of algorithms HPM is presented in Algorithm 2, along with the choices of weights in Table 3.
| Algorithm | Weights |
|---|---|
| HPM-C | |
| HPM-C | |
| HPM-W | |
| HPM-W | |
| HPM-A |
Appendix B Experiments
For PAC error evaluation, we set for all experiments for obtaining the weights for the PAC variants of HPF and HPM algorithms. We run the experiments on both synthetic and real datasets. Keeping the dataset and privacy demand fixed, several trials of the algorithms are performed for each experiment. For the weakly-correlated setting, in each trial, the dataset is randomly permuted.
For experiments on PAC error, we report the empirical -th quantile of the -error of the algorithms across the trials. For experiments on MSE error, we report the empirical mean squared -error.
The experiments are straightforward to implement but please feel free to reach out to the authors to obtain the code to reproduce the results.
B.1 Baseline Methods for Comparison
Uniformly enforce -DP (UNI).
This approach offers the highest privacy level to all the datapoints and uses the known minimax estimator for homogeneous -DP mean and frequency estimation, depending on the problem. UNI can be arbitrarily worse than the optimal algorithm – consider a dataset with a single high and several low privacy datapoints.
Proportional Weighing (Prop).
This approach uses the weights . This weighing minimizes the amount of Laplace noise required over all possible weights, but it comes at the cost of a higher bias. In the case that have a high variance, this weighing strategy can perform rather poorly. For example, in the case that there is just one user requiring no privacy (), this strategy would disregard the data of all other users.
Sampling Mechanism (SM).
This mechanism was proposed by Jorgensen et al. [28]. Let . Then sample -th datapoint independently with probability . On the sub-sampled dataset, we can use any homogeneous -DP algorithm and this will be -DP. A shortcoming of this mechanism is of just one user requires no privacy, the SM algorithm disregards the rest of the dataset.
Local Differential Private Frequency (LDP).
A simple Local-DP approach to heterogeneous DP is to send the user ’s data to the server via an -DP channel.
-
Mean estimation: the LDP channels adds Laplace noise to the user ’s data.
The exact scheme used by us for combining these estimates from different users at the server in outlined in [17, Appendix I]. While this is not a completely fair comparison with other algorithms since local-DP is typically more noisy than central-DP, it is still insightful to see the performance difference. In fact, the carefully designed scheme in our implementation of this local-DP mechanism under heterogeneous privacy is on par with some of the baseline central-DP techniques for frequency estimation.
B.2 Frequency Estimation under Correlated Setting
For the correlated setting, we sub-sample the University of California (UC) salary data for 2022 [14] consisting of the salaries of 50K employees in the UC system. We partition the salaries into 12 bins and assign less privacy demand to the people in the more central bins. In particular, a user that belongs to bin has a privacy demand randomly sampled as Uniform. We sample the privacy demands once and keep it fixed, while running several trials. Results of the experiments are outlined in Table 4. Our proposed algorithms HPF-C and HPF-C outperforms the other algorithms, while HPF-A also performs competitively.
We also consider two synthetic datasets with ; the number of bins is set as and . The privacy demand is randomly sampled, with different distributions for users in different bins. LDP’s performance is impressive since local-DP typically performs significantly worse than central-DP. In the synthetic datasets, HPF-A outperforms HPF-C and HPF-C.
B.3 Frequency Estimation under Weakly-correlated Setting
For the weakly-correlated setting, we consider the number of new cancers in the state of Colorado in 2020 [39] containing data of about 17K surgeries with ten different types of cancers. We sample Uniform and keep fixed. For each trial, the dataset, mapping privacy demand to a cancer type datapoint, is randomly permuted. We perform trials to get meaningful results due to the random permutations. Our proposed algorithms HPF-A, HPF-W, and HPF-W perform better than the other baseline algorithms.
In a similar manner as the correlated setting, we also test the algorithms under synthetic datasets. From Table 4, it can be seen that while HPF-A performs superior to the other algorithms, HPF-W and HPF-W also enjoy good performance.
| Dataset, Regime, Metric | HPF | HPF-A | Prop | UNI | SM | LDP |
|---|---|---|---|---|---|---|
| UC Salary, C, | 0.118 | 0.174 | 0.273 | 1.000 | 0.459 | 0.420 |
| UC Salary, C, | 0.011 | 0.030 | 0.074 | 0.396 | 0.180 | 0.087 |
| (10000, 5), C, | 0.105 | 0.083 | 0.202 | 1.000 | 0.924 | 0.253 |
| (10000, 5), C, | 0.012 | 0.007 | 0.041 | 0.834 | 0.779 | 0.027 |
| (10000, 20), C, | 0.020 | 0.003 | 0.090 | 0.233 | 1.000 | 0.125 |
| (10000, 20), C, | 3 | 7 | 0.008 | 0.022 | 0.779 | 0.008 |
| Cancer Types, W, | 0.009 | 0.005 | 0.014 | 0.091 | 0.382 | 0.012 |
| Cancer Types, W, | 5 | 1 | 8 | 0.003 | 0.036 | 7 |
| (10000, 5), W, | 0.012 | 0.008 | 0.023 | 0.370 | 0.798 | 0.0152 |
| (10000, 5), W, | 1 | 3 | 2 | 0.043 | 0.198 | 1 |
| (10000, 20), W, | 0.013 | 0.007 | 0.020 | 0.482 | 0.348 | 0.015 |
| (10000, 20), W, | 1 | 2 | 2 | 0.095 | 0.028 | 1 |
B.4 Mean Estimation
For the correlated setting, we consider the UC Dataset and use the method described in frequency estimation to get a correlated data and privacy demand. Results of the experiments are outlined in Table 5. We also consider a synthetic datasets with and use a method similar to the frequency estimation experiments to obtain correlated data and privacy demand.
For the weakly-correlated setting, we test the algorithms under a synthetic dataset. Overall, HPM-A performs superior as compared to the other algorithms.
| Dataset, Regime, Metric | HPM | HPM-A | Prop | UNI | SM | LDP |
|---|---|---|---|---|---|---|
| UC Salary, C, | 0.064 | 0.005 | 0.005 | 0.066 | 0.005 | 1.000 |
| UC Salary, C, | 2 | 2 | 2 | 0.001 | 2 | 0.832 |
| 10000, C, | 0.008 | 0.009 | 0.009 | 0.027 | 0.052 | 0.085 |
| 10000, C, | 4 | 7 | 8 | 2 | 2 | 0.002 |
| 10000, W, | 0.008 | 0.001 | 0.004 | 0.027 | 0.110 | 0.086 |
| 10000, W, | 4 | 3 | 5 | 1 | 0.003 | 0.002 |
Appendix C Upper and Lower Bounds
C.1 Upper Bounds
Recall the functions and from (6) and (7), and their corresponding minimum values and from (8) and (9), respectively.
For a choice of weights in Algorithm 1 or Algorithm 2, the term in and are due to the bias from having weights different from . The term accounts for noise needed to satisfy the privacy demand. The algorithms minimizing their respective errors over the choices of weights .
Theorem 4 provides upper bounds for the PAC-minimax rates in the two settings and the two problems; its proof can be found in [17, Appendix E].
Theorem 4 (PAC Upper Bound).
(A) Correlated Setting:
For frequency estimation
| (21) |
and for mean estimation
| (22) |
(B) Weakly-correlated Setting: For frequency estimation
| (23) |
and for mean estimation
| (24) |
Since we are considering PAC error under -norm for frequency estimation, the captures the effect of union bound. Simply substituting recovers the guarantee for mean estimation.
Theorem 5 provides an upper bound on the MSE-minimax rates for the two settings for both frequency and mean estimation, its proof can be found in [17, Appendix F].
Theorem 5 (MSE Upper Bound).
(A) Correlated Setting: For frequency estimation
| (25) |
and for mean estimation
| (26) |
(B) Weakly-correlated Setting: For frequency estimation
| (27) |
and for mean estimation
| (28) |
We mention that for frequency estimation in Theorem 5, the MSE upper bound has term instead of so we just set in and for brevity. Similarly, for mean estimation, there is no term in our upper bounds; hence, we substitute the constant in the and functions for brevity. We also assume for frequency estimation to make simplifications like in the proof. Theorem 5 is obtained by some concentration inequalities and the tail-sum identity for expectation, using the PAC bounds in Theorem 4.
As one would expect, the upper bounds in the correlated setting is always greater than the corresponding one in weakly-correlated setting – in both mean and frequency estimation under both PAC and MSE bounds.
For comparison, in frequency estimation, consider the straw-man approach of assigning every user equal weight222This is the UNI algorithm defined in Section 4. and adding i.i.d. Laplace noise to each bin., leading to the PAC-error of the order and MSE-error of the order (in both settings). This method has a clear drawback in case there is one user demanding an extremely high privacy () and the rest of the users requiring no privacy. It is simply better to ignore the first user and do non-private frequency calculation for the rest of the users; in correlated setting, this leads to a PAC-error of at most from Theorem 4, and MSE-error of from Theorem 5. In the weakly-correlated setting, it leads to PAC-error of at most and MSE-error of . A similar case can be made for mean estimation, highlighting the improved guarantees afforded by our proposed algorithms.
C.2 Lower Bounds
For frequency estimation, the trivial output of achieves an error of . Therefore, we have . Similarly, for mean estimation we have . When the minimax rates are strictly less than half, we show that the minimax rate must satisfy the conditions in Theorem 6. The proof can be found in [17, Appendix G]. Our lower bounds for PAC rates follow from a packing argument and are presented in Theorem 6. We remind the readers that is assumed to be in non-decreasing order.
Theorem 6 (Implicit PAC Lower Bound).
The minimax rates satify .
(A) Correlated Setting: if , then it also satisfies
| (29) |
Similarly, if , then it also satisfies
| (30) |
(B) Weakly-correlated Setting:
Let be sampled without replacement from the entries of .
If , then it also satisfies
| (31) | ||||
| (32) |
Similarly, if , then it also satisfies
| (33) | ||||
| (34) |
While the conditions presented in Theorem 6 are implicit, it should be noted that the conditions imply a lower limit to the minimax rates.
We present MSE lower bounds in the weakly-correlated setting in Theorem 7; the proof can be found in [17, Appendix H].
Theorem 7 (MSE Lower Bound for Weakly-correlated Setting).
The minimax rates satisfy .
Further, both satisfy
| (35) |
In Theorem 7, we use the notation to refer to the function . We interpret this lower bound in Section 5.2 and compare it with the upper bound. We mention that we do not present any lower bounds for the MSE-minimax rates and .