Kernel Multiaccuracy

Abstract
Predefined demographic groups often overlook the subpopulations most impacted by model errors, leading to a growing emphasis on data-driven methods that pinpoint where models underperform. The emerging field of multi-group fairness addresses this by ensuring models perform well across a wide range of group-defining functions, rather than relying on fixed demographic categories. We demonstrate that recently introduced notions of multi-group fairness can be equivalently formulated as integral probability metrics (IPM). IPMs are the common information-theoretic tool that underlie definitions such as multiaccuracy, multicalibration, and outcome indistinguishably. For multiaccuracy, this connection leads to a simple, yet powerful procedure for achieving multiaccuracy with respect to an infinite-dimensional class of functions defined by a reproducing kernel Hilbert space (RKHS): first perform a kernel regression of a model’s errors, then subtract the resulting function from a model’s predictions. We combine these results to develop a post-processing method that improves multiaccuracy with respect to bounded-norm functions in an RKHS, enjoys provable performance guarantees, and, in binary classification benchmarks, achieves favorable multiaccuracy relative to competing methods.
Keywords and phrases:
algorithmic fairness, integral probability metrics, information theoryCopyright and License:
2012 ACM Subject Classification:
Mathematics of computing Information theorySupplementary Material:
Software: https://github.com/Carol-Long/KMAccarchived at
Acknowledgements:
This material is based upon work supported by the National Science Foundation under Grant No FAI 2040880, CIF 2231707, and CIF 2312667.Editors:
Mark BunSeries and Publisher:
1 Introduction
Machine learning (ML) models can be inaccurate or miscalibrated on underrepresented population groups defined by categorical features such as race, religion, and sex [3]. Equitable treatment of groups defined by categorical features is a central aspect of the White House’s “Blueprint for an AI Bill of Rights” [23]. Over the past decade, hundreds of fairness metrics and interventions have been introduced to quantify and control an ML model’s performance disparities across pre-defined population groups [12, 24]. Examples of group-fairness-ensuring interventions include post-processing [21, 25, 2] or retraining [1] a model.
Although common, using pre-determined categorical features for measuring “fairness” in ML poses several limitations. Crucially, we design group attributes based on our preconception of where discrimination commonly occurs and whether group-denoting information can be readily measured and obtained. A more complex structure of unfairness can easily elude group-fairness interventions. For instance, [26] demonstrates that algorithms designed to ensure fairness on binary group attributes can be maximally unfair across more complex, intersectional groups – a phenomenon termed “fairness gerrymandering.” Recently, [31] shows that group fairness interventions do not control for – and may exacerbate – arbitrary treatment at the individual and subgroup level.
The paradigm of fairness over categorical groups is an instance of embedded human bias in ML: tools are developed to fit a pre-defined metric on predefined groups, and once a contrived audit is passed, we call the algorithm “fair.” Defining groups by indicator functions over categorical groups is not expressive enough, and the most discriminated groups may not be known a priori. This fact has fueled recent calls for new data-driven methods that uncover groups where a model errs the most. In particular, the burgeoning field of multi-group fairness, and definitions such as multicalibration and multiaccuracy [22, 28, 9], are important steps towards a more holistic view of fairness in ML, requiring a model to be calibrated on a large, potentially uncountable number of group-denoting functions instead of pre-defined categorical groups [22].
Multi-group fairness notions trade the choice of pre-determined categorical features for selecting a function class over features. Here, the group most correlated with a classifier’s errors (multiaccuracy) or against which a classifier is most miscalibrated (multicalibration) is indexed by a function in this class. [22] describes the class as being computable by a circuit of a fixed size. More concretely, [28] and [15] take this class to be linear regression, ridge regression, or shallow decision trees.
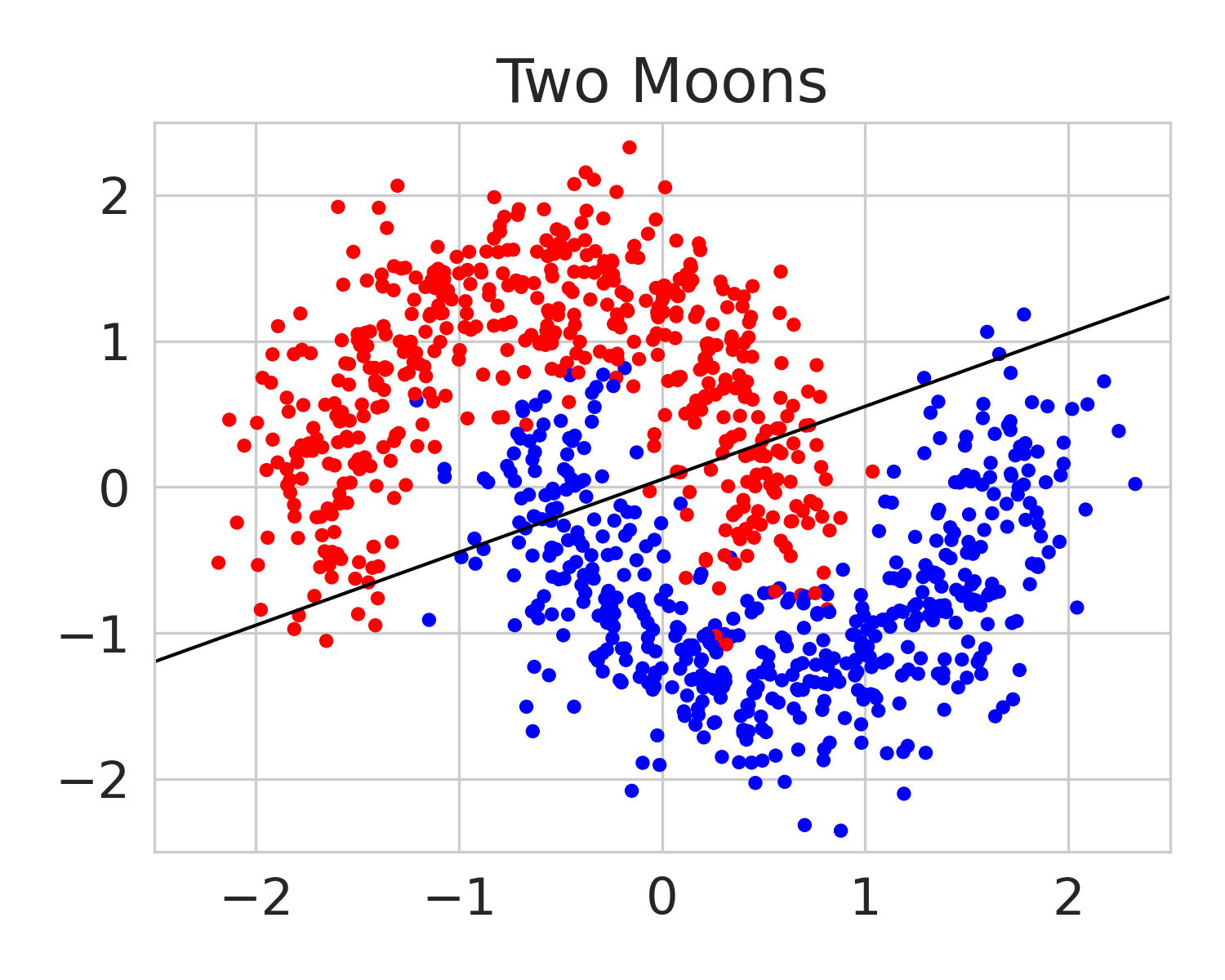
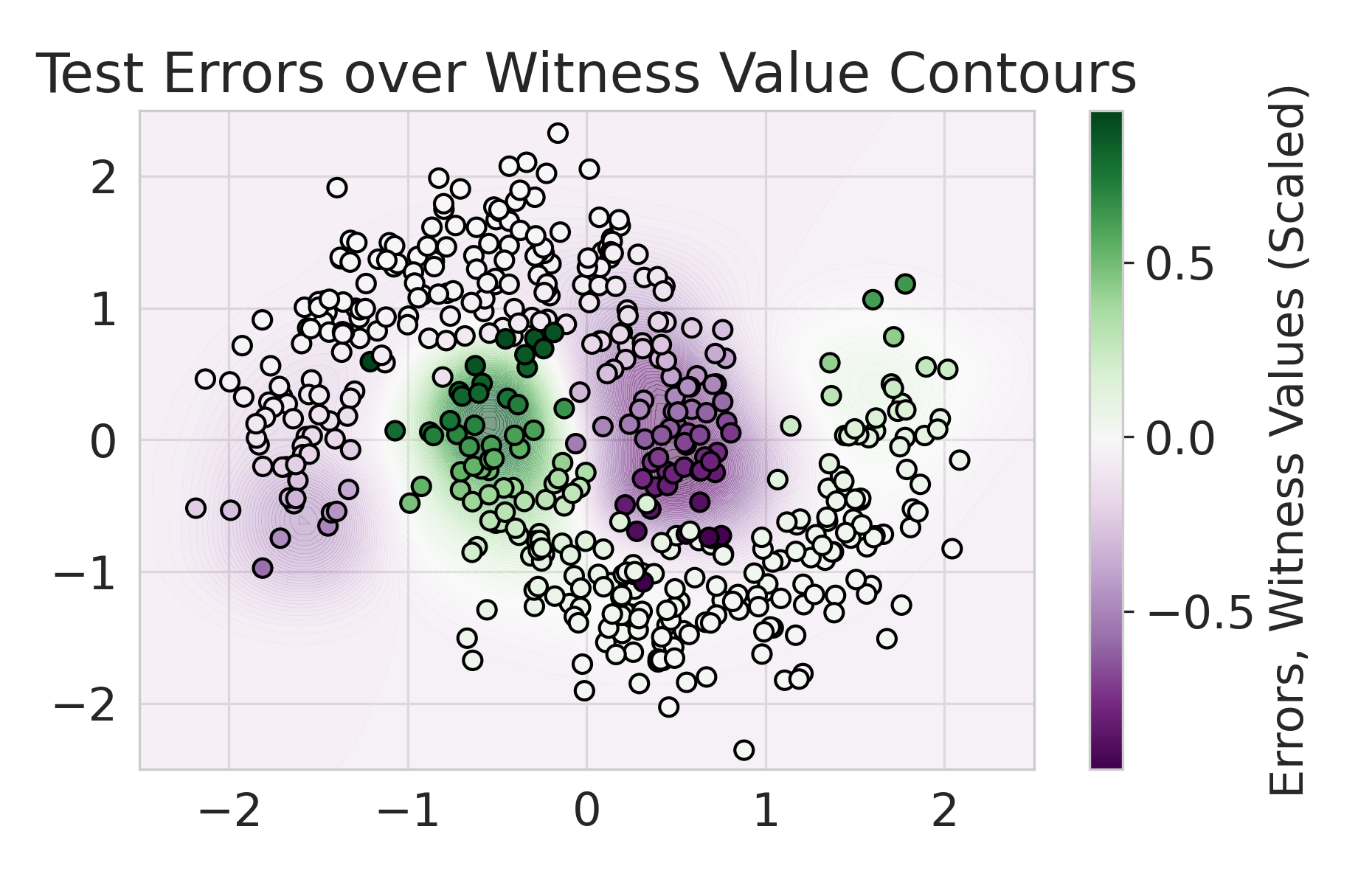
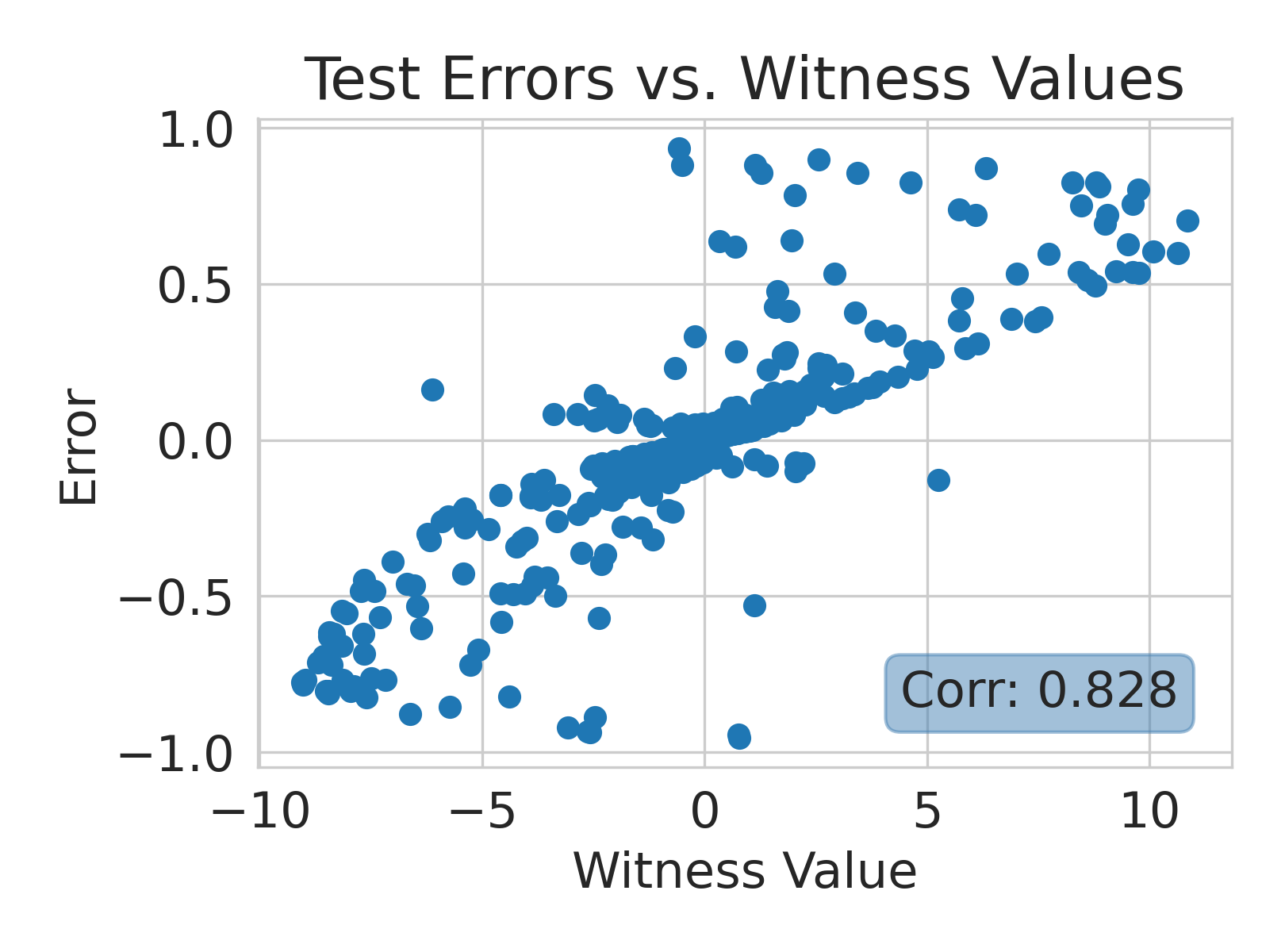
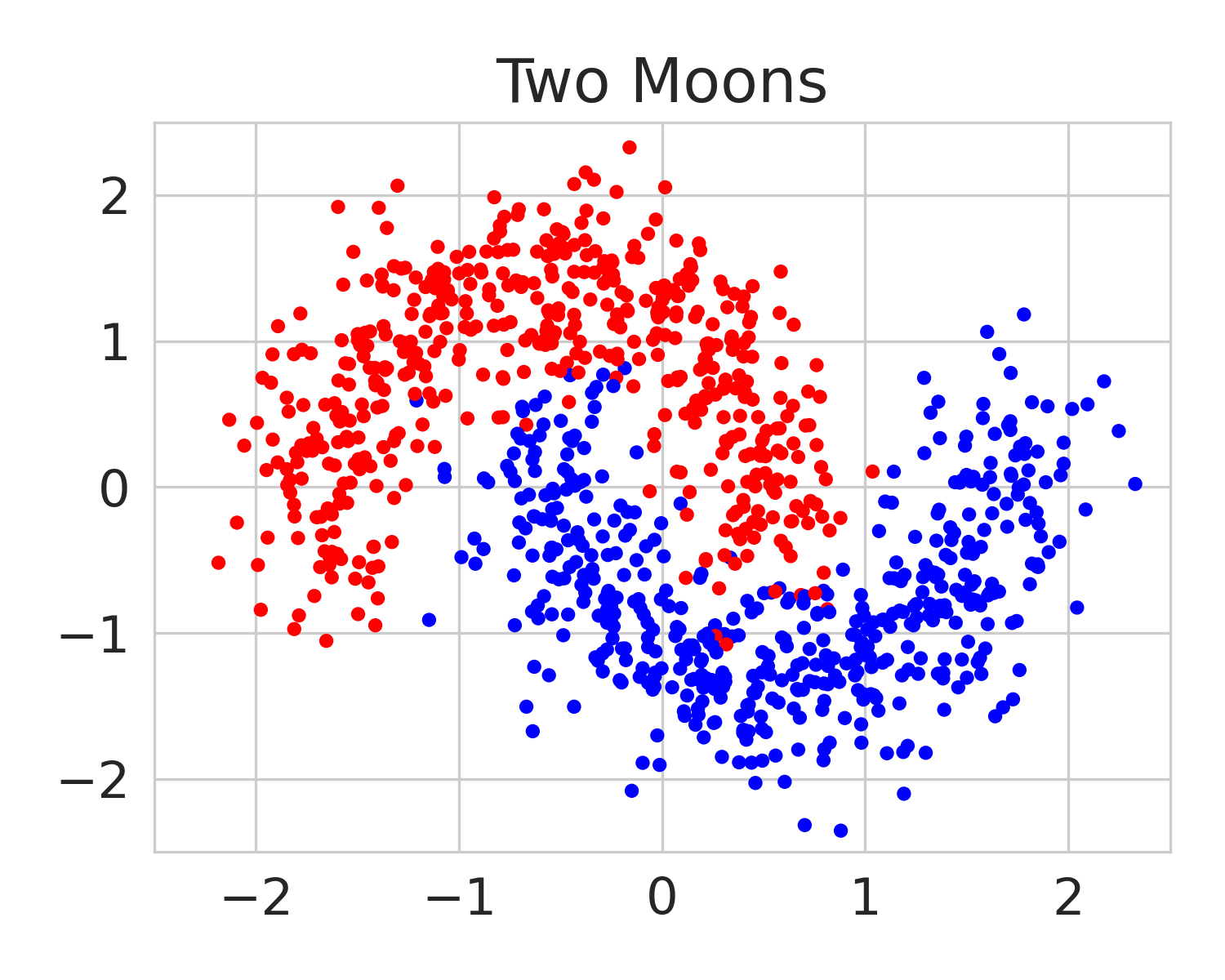
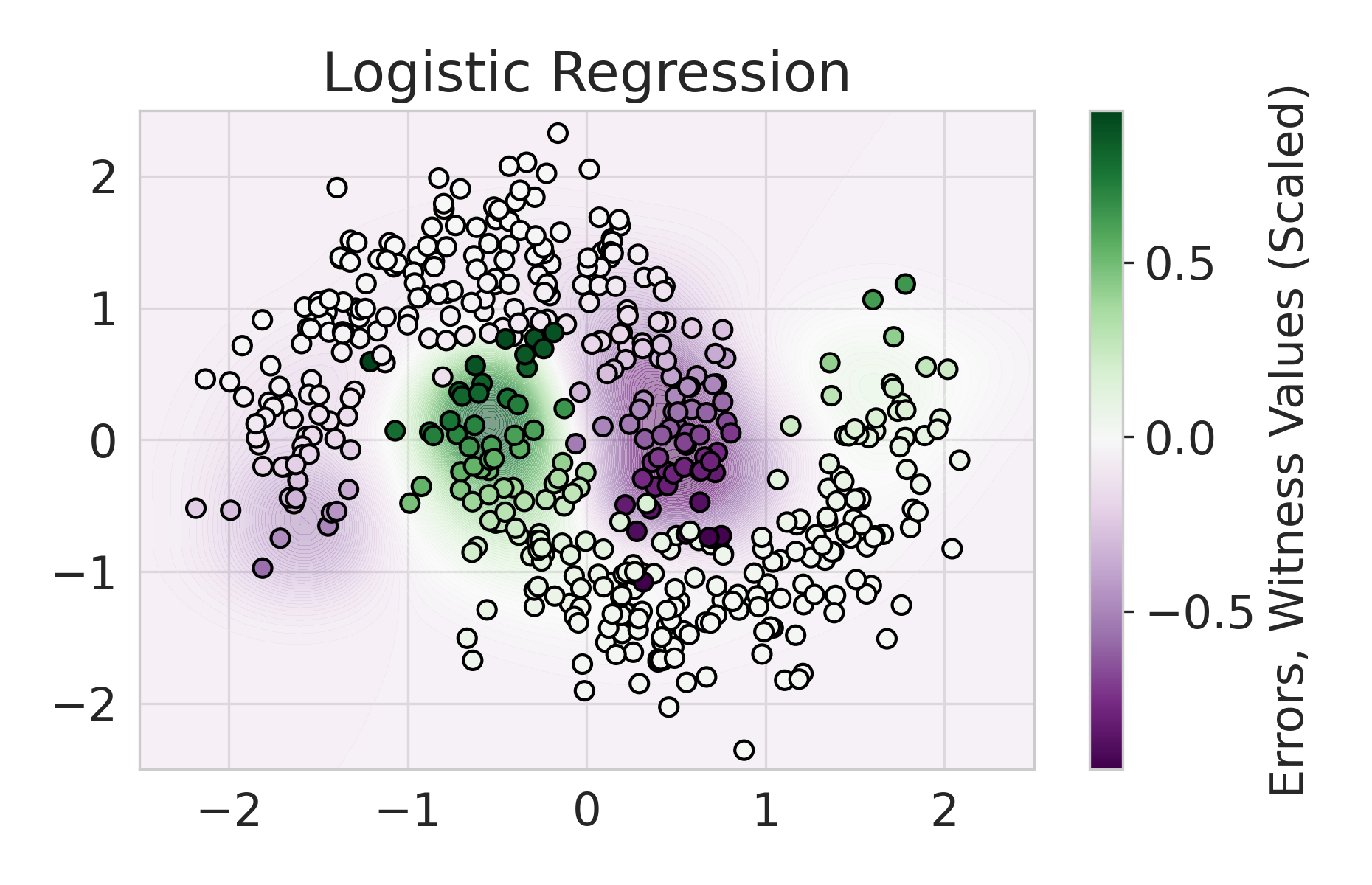
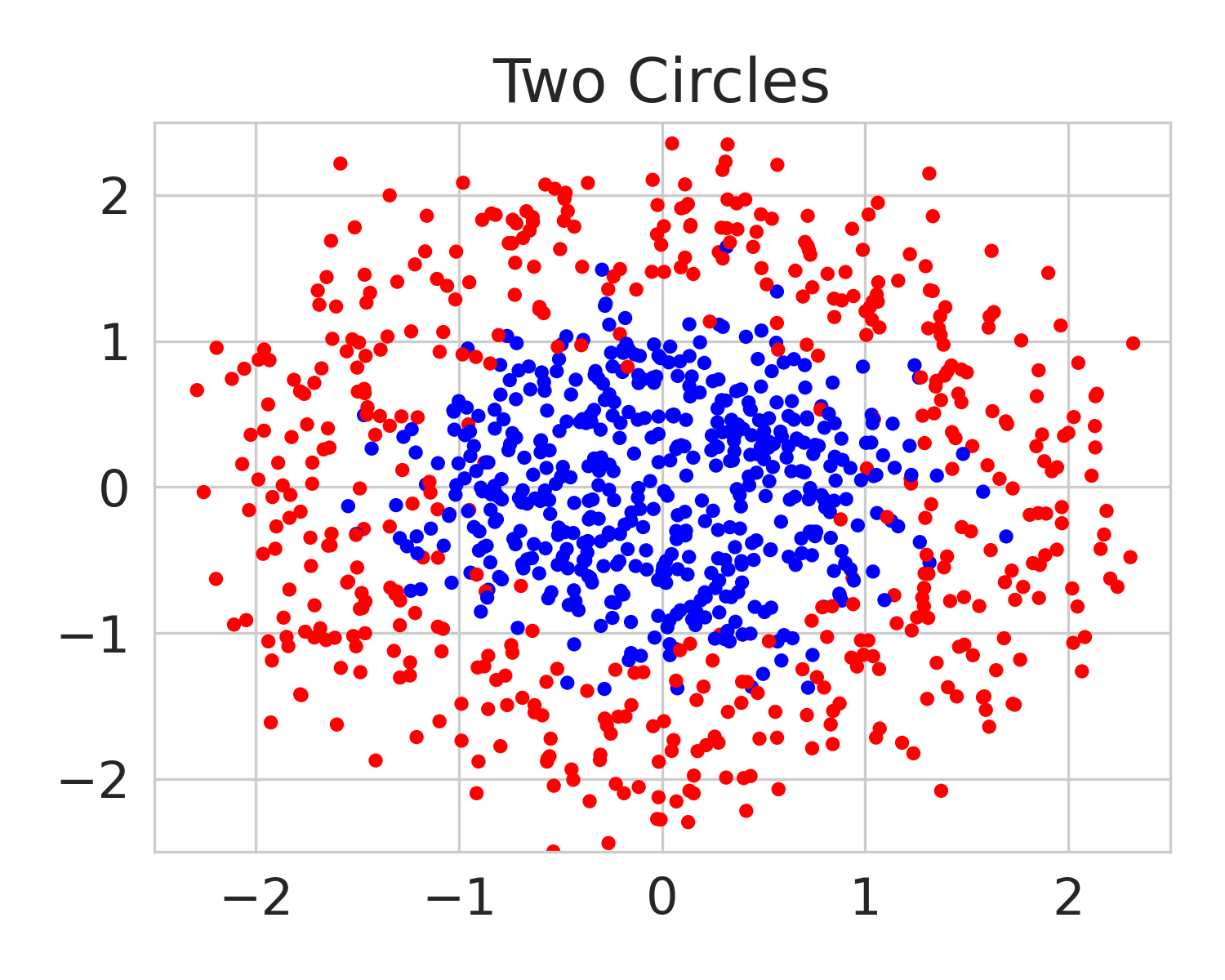
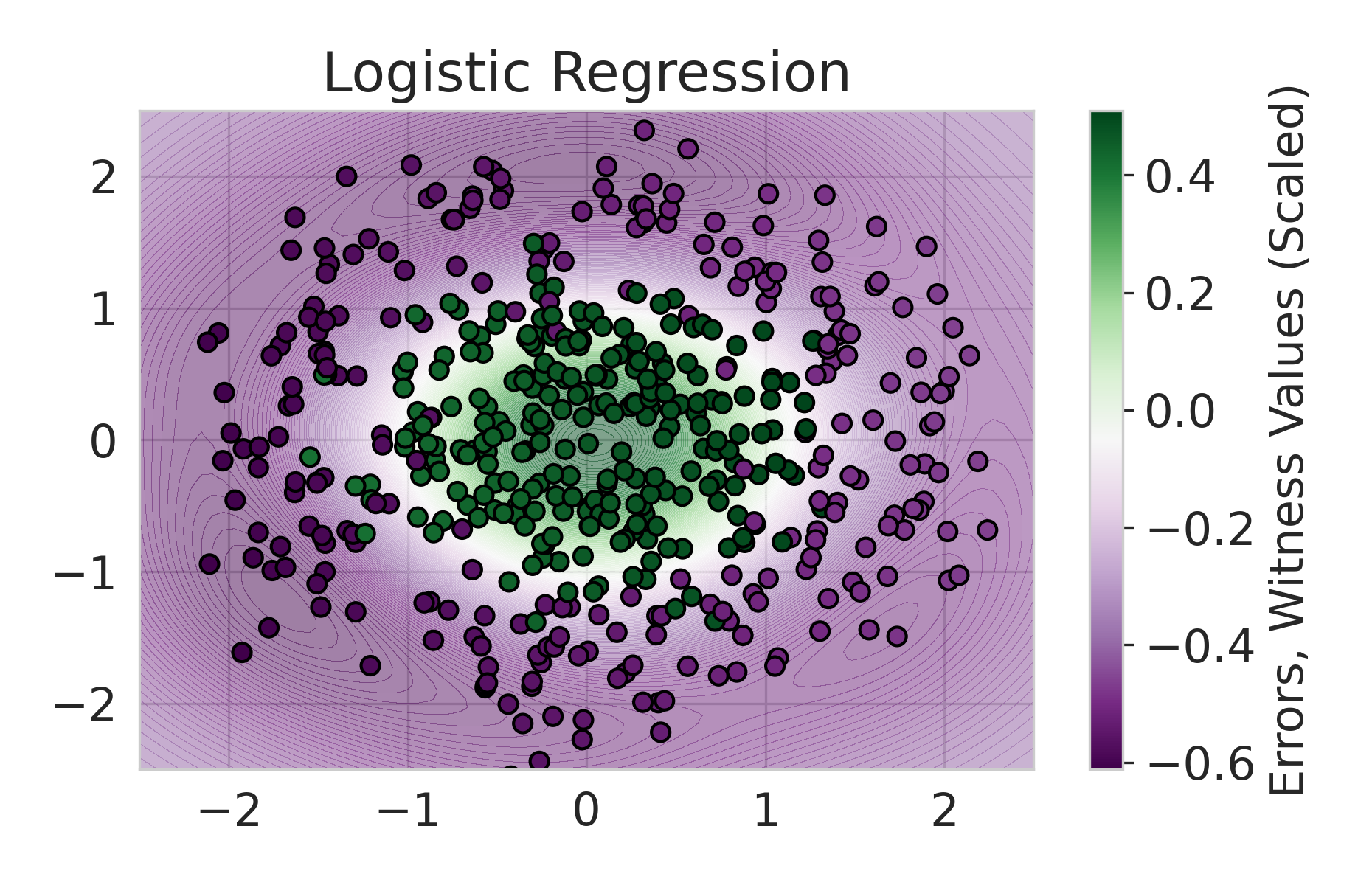
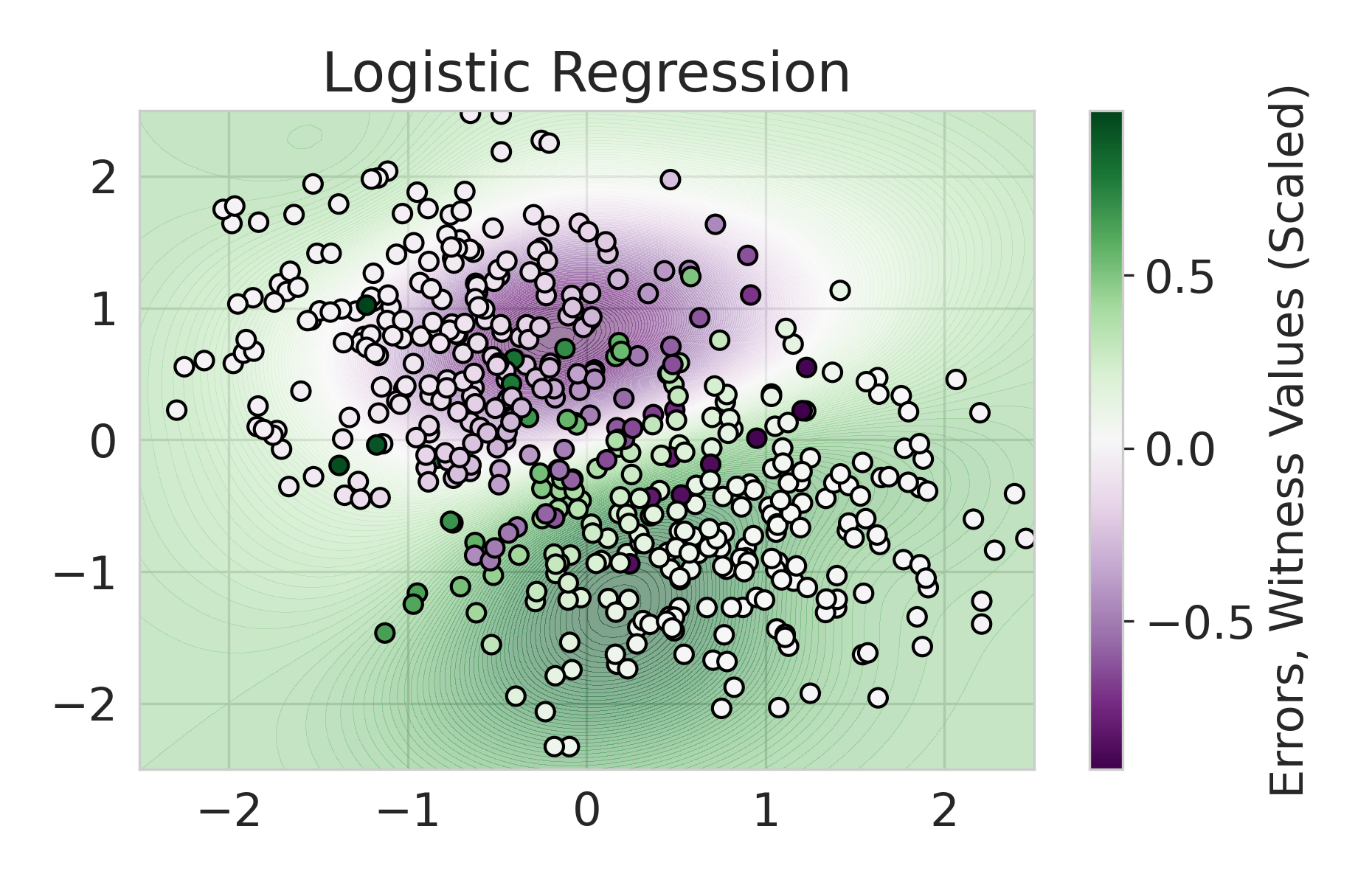
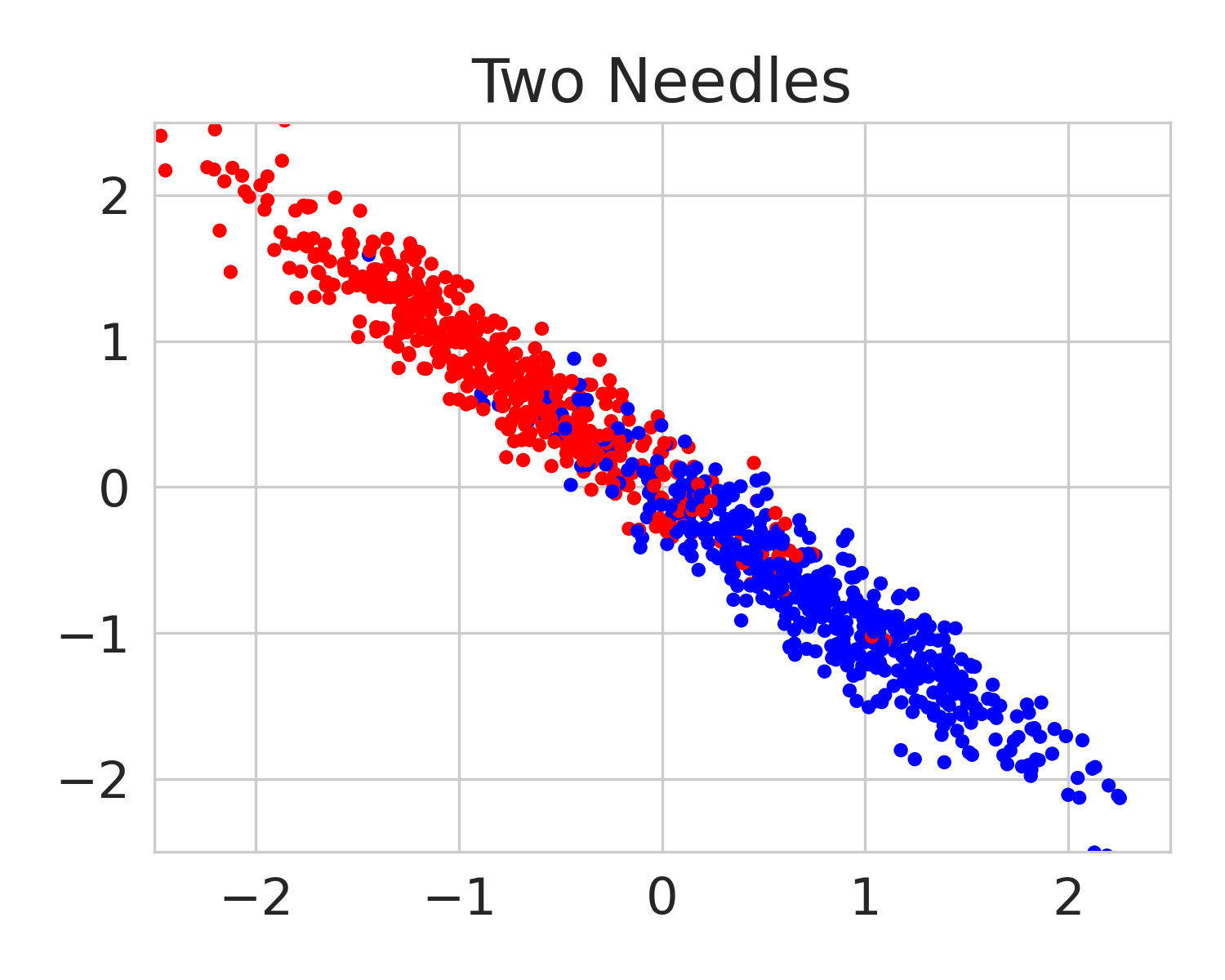
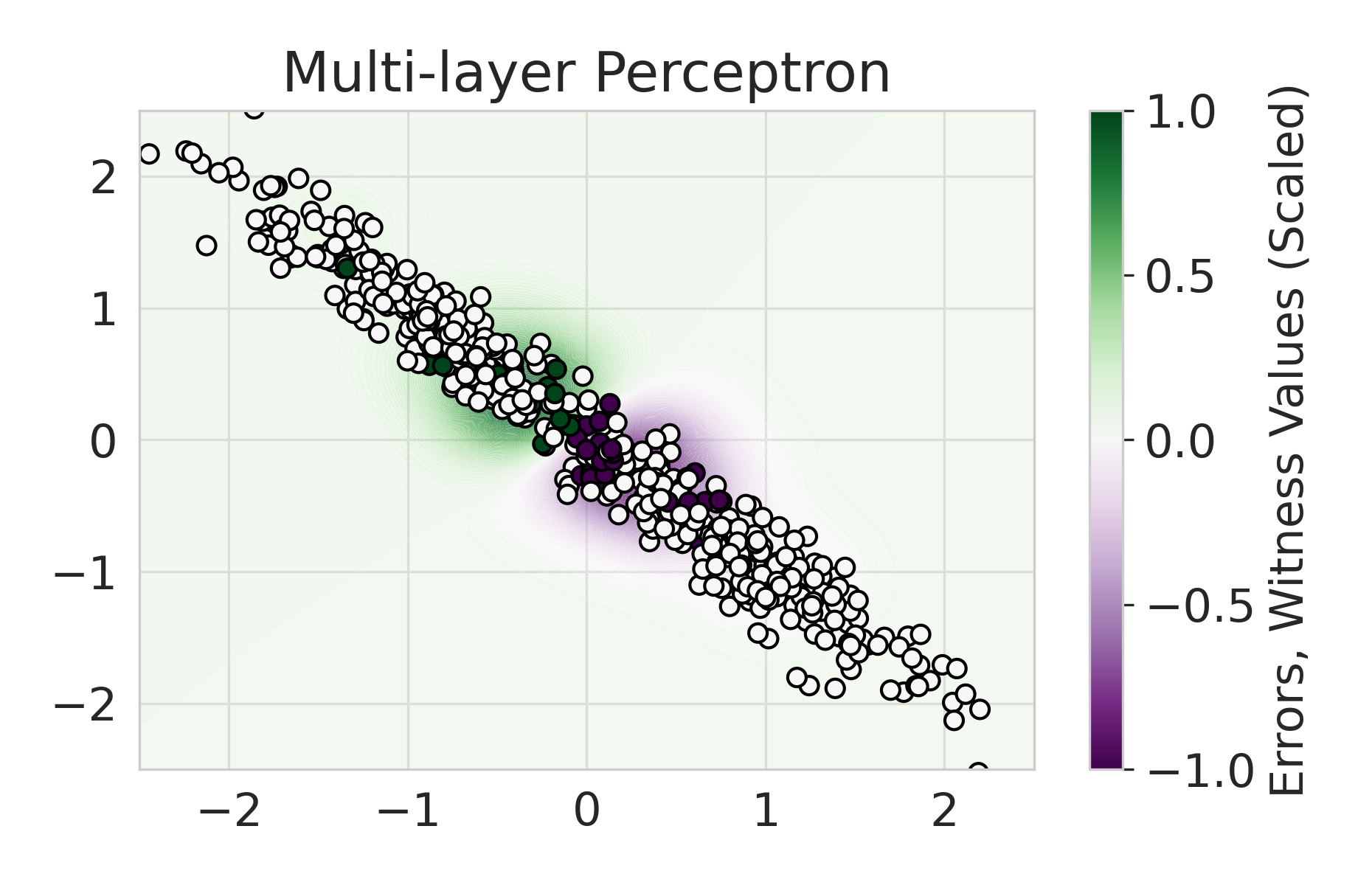
We build on this line of work by considering a more general class of functions given by a Reproducing Kernel Hilbert Space (RKHS), defined on an infinite-dimensional feature space [38]. In fact, an RKHS with a universal kernel is a dense subset of the space of continuous functions [39]. Surprisingly, by leveraging results from information and statistical learning theory [33, 37], we show that the multi-group fairness problem in an RKHS is tractable: the most biased group has a closed form up to a proportionality constant. This leads to an exceedingly simple algorithm (KMAcc, Algorithm 1), which first identifies the function in the RKHS that correlates the most with error (called the witness function), and then improves multiaccuracy by subtracting this function from the original predictions. As an example, Figure 1 illustrates that the error of a logistic regression model on the Two Moons synthetic dataset shows a strong correlation with the witness function values.
 |
 |
 |
The main contributions of this work include:
-
1.
We show that multiaccuracy, multicalibration, and outcome indistinguishability are integral probability metrics (IPMs), a well-studied family of statistical distance measures. When the groups or distinguishers lie in an RKHS, these IPMs have closed-form estimators, characterized by a witness function that achieves the supremum.
-
2.
We introduce a consistent estimator for multiaccuracy, which flags the most discriminated group in terms of a function in Hilbert space, effectively revealing the previously unknown group that suffers the most from inaccurate predictions.
-
3.
We propose an algorithm, KMAcc (Algorithm 1), which provably corrects the given predictor’s scores against its witness function. Empirically, our algorithm improves multiaccuracy and multicalibration after applying a standard score quantization technique, without the need for the iterative updates required by competing boosting-based models.
-
4.
We conduct extensive experiments on both synthetic and real-world tabular datasets commonly used in fairness research. We show competitive or improved performance compared to competing models, both in terms of multi-group fairness metrics and AUC.
1.1 Related Literature
Multiaccuracy and Multicalibration.
Multiaccuracy and multicalibration, which emerged from theoretical computer science, ensure fairness over the set of computationally identifiable subgroups [22]. Multiaccuracy aims to make classification errors uncorrelated with subgroups, while multicalibration additionally requires predictions to be calibrated. [22] and [28] ensure multiaccuracy and multicalibration via a two-step process: identify subgroups with accuracy disparities, then apply a transformation to the classification function to boost accuracy over those groups – a method akin to weak agnostic learning [11]. Subsequent works [18, 17, 15] connect multicalibration to the general framework of loss minimization, introducing new techniques including reducing squared multicalibration error and projection-based error corrections [15, 8]. Recent developments include online multicalibration algorithms across Lipschitz convex loss functions [13] and via a game-theoretic approach [20]. In addition, [41] adopts multicalibration for multi-dimensional outputs for fair risk control.
A common thread across work on multigroup fairness is to define subgroups in terms of function classes instead of pre-determined discrete combinations of group-denoting features [28, 9, 18, 29]. Examples of such function classes include “learnable” classes (in the usual statistical learning sense) [28] and the set of indicator functions [10]. Practical implementations of multigroup-fairness ensuring algorithms include MCBoost [28], which uses ridge regression and decision tree regression, and LSBoost [15], which uses linear regression and decision trees. Here, we use both methods as benchmarks. Unlike prior work, we consider the class of functions to be an RKHS and show that this class yields closed-form expressions for the function that correlates the most with error, allowing an efficient multiaccuracy intervention.
Kernel-Based Calibration Metrics.
Calibration ensures that probabilistic predictions are neither over- nor under-confident [40]. Prior works have formulated calibration errors for tasks such as classification [7, 34], regression [36], and beyond [40]. Calibration constraints may be directly incorporated into the training objective of a model [30]. [30, 39, 32, 6] have adopted RKHS as the class of functions to ensure calibration. We build on this prior work and develop kernel-based metrics and consistent estimators focused on multi-group fairness.
Integral Probability Measures (IPMs).
[9] introduces outcome indistinguishability to unify multiaccuracy, multicalibration through a pseudo-randomness perspective – whether one can(not) tell apart “Nature’s” and the predictor’s predictions. We provide an alternative unifying perspective through distances between Nature’s and the predictor’s distributions. As discussed in [9], outcome indistinguishability is closely connected to statistical distance (total variation distance), which, in turn, is one instantiation of an IPM [33], an extensively studied concept in statistical theory that measures the distance between two distributions with respect to a class of functions. [37] provides estimators for IPM defined on various classes of functions, which we apply to develop a consistent estimator for multiaccuracy.
1.2 Notation
We consider a pair of random variables and , taking values in and respectively, where denotes the input features space to a prediction task and the output space. Often, we will take , i.e., binary prediction. The pair is distributed according to a fixed unknown joint distribution (Nature’s distribution) with marginals and . In binary prediction, we refer to a measurable function as a predictor. The predictor gives rise to a conditional distribution . We think of as an estimate of Nature’s distribution, i.e., . The induced joint distribution for is denoted by ; this joint distribution will be referred to as the predictor’s distribution. The marginal distribution is the same for both and ; only the conditional distribution changes due to using .
Given a measurable function and a random variable , we interchangeably denote expectation by depending on what is clearer from context. If is a finite set of i.i.d. samples, then we denote the empirical average by .
2 Multi-Group Fairness as Integral Probability Metrics
We show the connection between IPMs [33, 37] – a concept rooted in statistical learning theory – and multi-group fairness notions such as multiaccuracy, multicalibration [22], and outcome indistinguishability [10]. The key property allowing for these connections is that the multi-group fairness notions and IPMs are both variational forms of measures of deviation between probability distributions. IPMs give perhaps the most general form of such variational representations, and we recall the definition next.
Definition 1 (Integral Probability Metric [33, 37]).
Given two probability measures and supported on and a collection of functions . We define the integral probability metric (IPM) between and with respect to by
| (1) |
Example 2.
IPMs recover other familiar metrics on probability measures, such as the total variation (statistical distance) metric. Indeed, when is the unit ball of real-valued functions, i.e., , then .
As the example above shows, the complete freedom in choosing the set allows IPMs the ability to subsume existing metrics on probability measures. We show that the expressiveness of IPMs carries through to multi-group fairness notions. Later, in Section 3, we instantiate our IPM framework for multiaccuracy to the particular case when is the unit ball in an infinite-dimensional Hilbert space, which then recovers another familiar metric on probability measures called the maximum mean discrepancy (MMD) or kernel distance.
2.1 Multi-group Fairness Notions
We recall the definitions of multiaccuracy and multicalibration from [28, 29], where the guarantees are parametrized by a class of real-valued functions . We call herein the set of calibrating functions. Intuitively, multi-group notions ensure that for every group-denoting function is uncorrelated with a model’s errors .
Multicalibration proposed by [22] requires the predictor to be unbiased and calibrated against groups denoted by functions in .
Definition 4 (Multicalibration [22, 29, 8]).
Fix a collection of functions and a distribution supported on . Fix a predictor such that is a discrete random variable.333Alternatively, one can consider a quantization of such as done in [14]. We say that is ()-multicalibrated over if for all and :
| (3) |
As discussed in [9], multi-group fairness constraints are equivalent to a broader framework of learning called outcome indistinguishability (OI). The object of interest is the distance between the two distributions – the ones induced by the predictor and by Nature.
2.2 Equivalence Between Multi-group Fairness Notions and IPMs
Since multiaccuracy, multicalibration, and outcome indistinguishability all pertain to finding the largest distance between distributions with respect to a collection of functions, we can unify them in terms of IPMs. First, we show that ensuring a predictor’s multiaccuracy with respect to a set of calibrating functions is equivalent to ensuring an upper bound on the IPM between Nature’s and the predictor’s distribution with respect to a modified set of function , given explicitly in the following result.
Proposition 6 (Multiaccuracy as an IPM).
Fix a collection of functions , and let . Fix a predictor inducing the distribution . Denote the modified set of functions
| (4) |
Then, for any , the predictor is ()-multiaccurate if and only if the IPM between Nature’s distribution and the predictor’s distribution is upper bounded by :
| (5) |
Proof.
Let be an identical copy of . Using the notation in (2) in the definition of multiaccuracy (Definition 3), we have that for every
| (6) | ||||
| (7) | ||||
| (8) | ||||
| (9) | ||||
| (10) | ||||
| (11) |
where . By definition of multiaccuracy, we have that is -multiaccurate if and only if . This is equivalent, by the above, to having the IPM bound , where is as defined in the proposition statement, i.e., it is the collection of modified functions as ranges over .
Expressing multiaccuracy as an IPM bound will allow us to rigorously accomplish two goals: 1) quantifying multiaccuracy from finitely many samples of , and 2) correcting a given predictor to be multiaccurate. These two goals are the subject of Section 3. Similarly, multicalibration and OI can be expressed as IPMs.
Proposition 7 (Multicalibration as an IPM).
Fix a collection of functions , and let . Fix a predictor inducing the distribution . Moreover, let . Let , be a discrete, finite quantization of , where for all . Define the set of functions
Then is ()-multicalibrated if and only if for every .
Proof.
Let be an identical copy of . Using the notation in the definition of multicalibration (Definition 4), we have that for every ,
| (12) | ||||
| (13) | ||||
| (14) | ||||
| (15) | ||||
| (16) |
where .
Proposition 8 (OI as an IPM).
Let be a collection of functions, and fix a predictor inducing the distribution on via composing with . Define the set of function
| (17) |
Then, for any , is ()-OI if and only if
Proof.
3 Multiaccuracy in Hilbert Space
We develop a theoretical framework and an algorithm for quantifying and ensuring -multiaccuracy. We consider the group-denoting functions to be the unit ball in an infinite-dimensional Hilbert space, namely, an RKHS defined by a given kernel (Definition 9). The proposed set of calibration functions can easily exhibit and exceed the expressivity of group-denoting indicator functions. Surprisingly, despite the expressiveness of , we show that the calibration function that maximizes multiaccuracy error, i.e. the witness function (Definition 10), has a closed form – in contrast to when is, for example, a set of decision trees [15, 28]. This enables us to derive a procedure for ensuring multiaccuracy (KMAcc, Algorithm 1).
3.1 Calibration Functions in RKHS and its Witness Function for Multiaccuracy
Our choice of calibrating functions is the set of functions with bounded norm in an RKHS. First, recall that an RKHS can be defined via kernal functions, as follows444The characterizing property of a real RKHS is that it is a Hilbert space of functions for which every evaluation map is a continuous function from to for each fixed ..
Definition 9 (Reproducing kernel Hilbert space (RKHS)).
Let be a real Hilbert space with inner product , and fix a function . We say that is a reproducing kernel Hilbert space with kernel if it holds that for all and for all and . We denote by if is given.
We use the structure of the RKHS as our group-denoting functions. Thus, for a prescribed multiaccuracy level , we will need to restrict attention to elements of whose norm satisfies a given bound. To normalize, we choose the unit ball in as our set of calibration functions, i.e.
| (22) |
We note that when the class of functions is the unit ball in an RKHS, the induced IPM is called the maximum mean discrepancy (MMD) [37].
Of particular importance are calibration functions that attain the maximal multiaccuracy error (the LHS of (2)). Such functions, called witness functions [27], encode the multiaccuracy definition without the need to consider the full set .
Definition 10 (Witness function for multiaccuracy).
For a fixed set of calibration functions , predictor , and distribution , we say that is a witness function for multiaccuracy of with respect to if it attains the maximum on the LHS in (2):
| (23) |
While an RKHS can encompass a broader class of functions than shallow decision trees or linear models, finding the function in the RKHS that errs the most (i.e., the witness function as per Definition 10) is surprisingly simple. Firstly, it can be shown that for the IPM (where is the unit ball in ), the function that maximizes the RHS of (1) is in closed form, up to a multiplicative constant [19, 27]
| (24) |
By the connection between IPM and multiaccuracy, we can similarly find the closed form of the witness function for multiaccuracy(Definition 10).
Proposition 11 (Witness function for multiaccuracy).
Given a the kernel function and distribution over . We assume that 555 denotes the space of real-valued functions that are integrable against , i.e. .. Fix a predictor satisfying . Then, there exists a unique (up to sign) witness function for multiaccuracy of with respect to (as per Definition 10), and it is given by
| (25) |
where is a normalizing constant so that .
Proof.
First, by continuity of the evaluation functionals on , we obtain that pointwise for each as [4, Chapter 1, Corollary 1]. Let . Next, applying Proposition 6, -multiaccuracy of is equivalent to the IPM bound , where and are as constructed in Proposition 6. Next, we use the definition of IPMs to deduce the formula for the witness function.
We rewrite the function inside the maximization definition of as an inner product in . Fix as above. Then, with , we have that
| (26) | ||||
| (27) | ||||
| (28) | ||||
| (29) | ||||
| (30) |
where (29) follows by continuity of the inner product and (30) by Fubini’s theorem since . The same steps follow for in place of , and subtracting the ensuing two equations we obtain
| (31) | ||||
| (32) |
Therefore, the maximizing function is given up to a normalizing constant by
In the presence of finitely many samples, one must resort to numerical approximations of the witness function.
Definition 12 (Empirical Witness Function).
Let be a finite set of i.i.d. samples from . We define the empirical witness function as the plug-in estimator of (25):
| (33) |
where is a normalizing constant so that .
Observe that given a training dataset , the witness function for a new sample is proportional to the sum of the error of weighted by – the distance between and the new sample in the kernel space. The witness function is performing a kernel regression of a model’s errors. From the definition of the witness function, it attains the supremum in the IPM, which measures the distance between Nature and the Predictor’s distribution. Hence, if a new sample attains a high witness function value, is likely erroneous.
We call the multiaccuracy error when comes from an RKHS the kernel multiaccuracy error, defined with the witness function which attains the maximum error.
Definition 13 (Kernel Multiaccuracy Error (KME)).
Let be the set of calibration functions in the RKHS as defined in (22). Given a predictor , the kernel multiaccuracy error (KME) is defined as
| (34) |
The empirical version has the plug-in estimator of the witness function .
Definition 14 (Empirical KME).
Given a test set of freshly sampled i.i.d. datapoints , we define the empirical KME by
| (35) |
Remark 15 (Overcoming the Curse of Dimensionality).
One important observation is that the MMD estimator depends on the dataset only through the kernel . Hence, once is known, the complexity of the estimator is independent of the dimensionality of – e.g., for , sample complexity does not scale exponentially with (see the end of Section 2.1 in [37].
We give the consistency and rate of convergence of KME – the finite-sample estimation of KME converges to the true expectation, following a direct application of [37, Corollary 3.5].
Theorem 16 (Consistency of the KME Estimator, [37, Corollary 3.5]).
Suppose the kernel is measurable and satisfies . Then, with probability at least over the choice of i.i.d. samples from and for every predictor , there is a constant such that the inequality
| (36) |
In addition, we have the almost-sure convergence as .
Next, we proceed to show an algorithm, KMAcc, that corrects a given predictor of its multiaccuracy error using the empirical witness function.
3.2 KMAcc: Proposed Algorithm for Multiaccuracy
We propose a simple algorithm KMAcc (Algorithm 1) that corrects the original predictor from multiaccuracy error. Notably, KMAcc does not require iterative updates, unlike all competing boosting or projection-based models [28, 15, 8]. In a nutshell, KMAcc first identifies the function in the RKHS that correlates the most with the predictor’s error (called the witness function) and subtracts this function from the original prediction to get a multi-group fair model. The first step is surprisingly simple – as we have shown above, the witness function of an RKHS has a closed form up to a proportionality constant. The second step is an additive update followed by clipping.
As outlined in Algorithm 1, the algorithm takes in a pre-trained base predictor , a proportionality constant , and a (testing) dataset on which the model is evaluated. Additionally, to define the witness function and the RKHS, the algorithm is given a dataset reserved for learning the witness function and a kernel function . With these, for each sample, the algorithm first computes the witness function value, and subtracts away the witness function value multiplied by , the proportionality constant which we learn from data (described in the next paragraph). Finally, we clip the output to fall within .
Learning the Proportionality Constant.
There are multiple approaches to obtaining the proportionality constant that scales the witness function appropriately. As an example, we adopt a data-driven approach to find . We use a validation set to perform a grid search on to get the that produces a predictor that is closest to in terms of distance, while also satisfying a multiaccuracy with a specified 666When the multiaccuracy constraint cannot be met, we output the that achieves the lowest multiaccuracy error using the witness values of ..
Remark 17 (One-Step Update).
For the linear kernel , we show that KMAcc yields a -multiaccurate predictor in a single step. While this property does not extend to nonlinear kernels, we observe empirically that the one-step update in KMAcc significantly reduces the empirical KME for RBF kernels. See Appendix C. for a detailed discussion.
We discuss in the following section a theoretical framework that gives rise to KMAcc and the grid-search approach.
3.3 Theoretical Framework for KMAcc
We formulate an optimization that, given a prediction that is not necessarily multiaccurate, finds the “closest” predictor that is corrected for multiaccuracy with respect to the empirical witness function of . Specifically, we consider the mean-squared loss to obtain the problem:
| (37) | ||||
| subject to |
where and are sets of i.i.d. samples that are sampled independently of each other.
A closer look at (37) shows that it is a quadratic program (QP)777Please find details of QP formulation in Appendix A. Thus, we can solve this QP through its dual problem to obtain a closed-form formula for the solution . The following formula follows by applying standard results on QP [5, Chapter 4.4].
Theorem 18.
Fix two independently sampled sets of i.i.d. samples and from with , and let , , , and be the fixed vectors and matrix as defined in (41)–(44). Denote an optimization variable and let and . Let be the unique solution to the QP
| (38) |
Then, the predictors solving the optimization (37) are determined by their restriction to as
| (39) |
where and . Furthermore, the value of may be chosen888To see this, note that, thinking of and as constants, the optimization over a single pair takes the form of minimizing over and . The optimal value for this can be easily seen to be if , or if , or if . This translates to clipping to be within . so that is projected onto . In particular, applying KMAcc (Algorithm 1) with the value attains a solution to (37).
4 Experiments
 |
We benchmark our proposed algorithm, KMAcc (Algorithm 1), on four synthetic datasets and eight real-world tabular datasets111111Implementation of KMAcccan be found at https://github.com/Carol-Long/KMAcc. We demonstrate KMAcc’s competitive or improved performance among competing interventions, both in multi-group fairness metrics and in AUC. Full experimental results are provided in Appendix B.
4.1 Datasets
We provide experimental results from the US Census dataset FolkTables. We conduct 4 binary classification tasks, including ACSIncome, ACSPublicCoverage, ACSMobility, ACSEmployment, using two different states for each of these tasks. In addition, we generate four synthetic datasets using the sklearn.datasets class in Scikit-Learn [35] – moons, concentric circles, blobs with varied variance, and anisotropically distributed data.
4.2 Competing Methods
We benchmark our method against LSBoost121212We use the official implementation of LSBoost available at https://github.com/Declancharrison/Level-Set-Boosting. by [15] and MCBoost131313We use the official implementation of MCBoost available at https://osf.io/kfpr4/?view_only=adf843b070f54bde9f529f910944cd99. by [29], which are (to the best of our knowledge) the two existing algorithms of multi-group fairness with usable Python implementations.
The mechanism of LSBoost is the following: over a number of level set partitions, each called , LSBoost finds a function through a squared error regression oracle before updating a function as a rounding of the values to each level set using a successive updating of indicator values as to which set they lie in under the previous combined with the learned : , and . This updating continues so long as an error term measured by the expectation of the squared error continues to decrease at a rate above a parameterized value. is taken to be linear regression or decision trees.
The MCBoost algorithm performs an iterative multiplicative weights update applied to successively learned functions. Starting with an initial predictor , it learns a series of grouping functions , that maximize multiaccuracy error. The algorithm now stores a set of both calibration points and validation points , at each step generating the set by, , having . Then, using the weak agnostic learner on , it produces a function which has its multiaccuracy checked on the validation set with the empirical estimate of the multiaccuracy error before enacting a multiplicative weights update if the multiaccuracy error is large. There are three different classes it might draw from – either taking sub-populations parameterized by some number of intersections of features, using ridge regression, or using shallow decision trees.
4.3 Performance Metrics
We evaluate the performance of baseline and multi-group fair models across three metrics: Kernel Multiaccuracy Error (KME, Definition 13), Area Under the ROC Curve (AUC), and Mean-Squared Calibration Error (MSCE), where MSCE is defined as follows.
Definition 19 (Mean-Squared Calibration Error (MSCE), [15]).
The Mean-Squared Calibration Error (MSCE) over a dataset of a predictor with a countable range is defined by
Our algorithm optimizes for KME and utility, while LSBoost [15] optimizes for MSCE. Hence, both of these metrics are reported. MCBoost [28] optimizes for multiaccuracy error (without considering calibration functions in the kernel space) and classification accuracy. We report AUC since it captures the models’ performance across all classification thresholds.
4.4 Methodology
To implement and benchmark KMAcc, we proceed through the following steps.
Data splits.
We assume access to a set of i.i.d. samples drawn from , where is a distribution over . We randomly partition into four disjoint subsets: (for training the baseline predictor ), for computing the witness function , for finding the proportionality constant ), and finally for benchmarking the performance of KMAcc in a test set against the state-of-the-art methods.
Baseline predictor .
Using the training data , we learn a baseline classifier . Our algorithm treats this function as a black box. For our experiments, we use four distinct supervised learning classification models as a baseline: Logistic Regression, 2-layer Neural Network, Random Forests, and Gaussian Naive Bayes, all implemented by Scikit-learn [35]. We train these on , values that are not used in learning our witness or in KMAcc.
Learning the witness function.
We take as our class of calibration functions the unit ball in the RKHS (Equation 22) with the kernel being the RBF kernel, given explicitly for a parameter by
| (40) |
The value of is a hyperparameter that we finetune using . We conduct a grid search over the parameter to find a such that has maximal correlation with the errors , thus obtaining in terms of , , and (see Proposition 11). To carry out this step, we run grid search on using K-fold validation on the data . The value of the normalizing constant in Proposition 11 (for attaining ) can be skipped in this step for the sake of finding the optimal multiaccurate predictor solving (37), because can be subsumed in the value of the optimal parameter .
Performing KMAcc.
4.5 Results
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
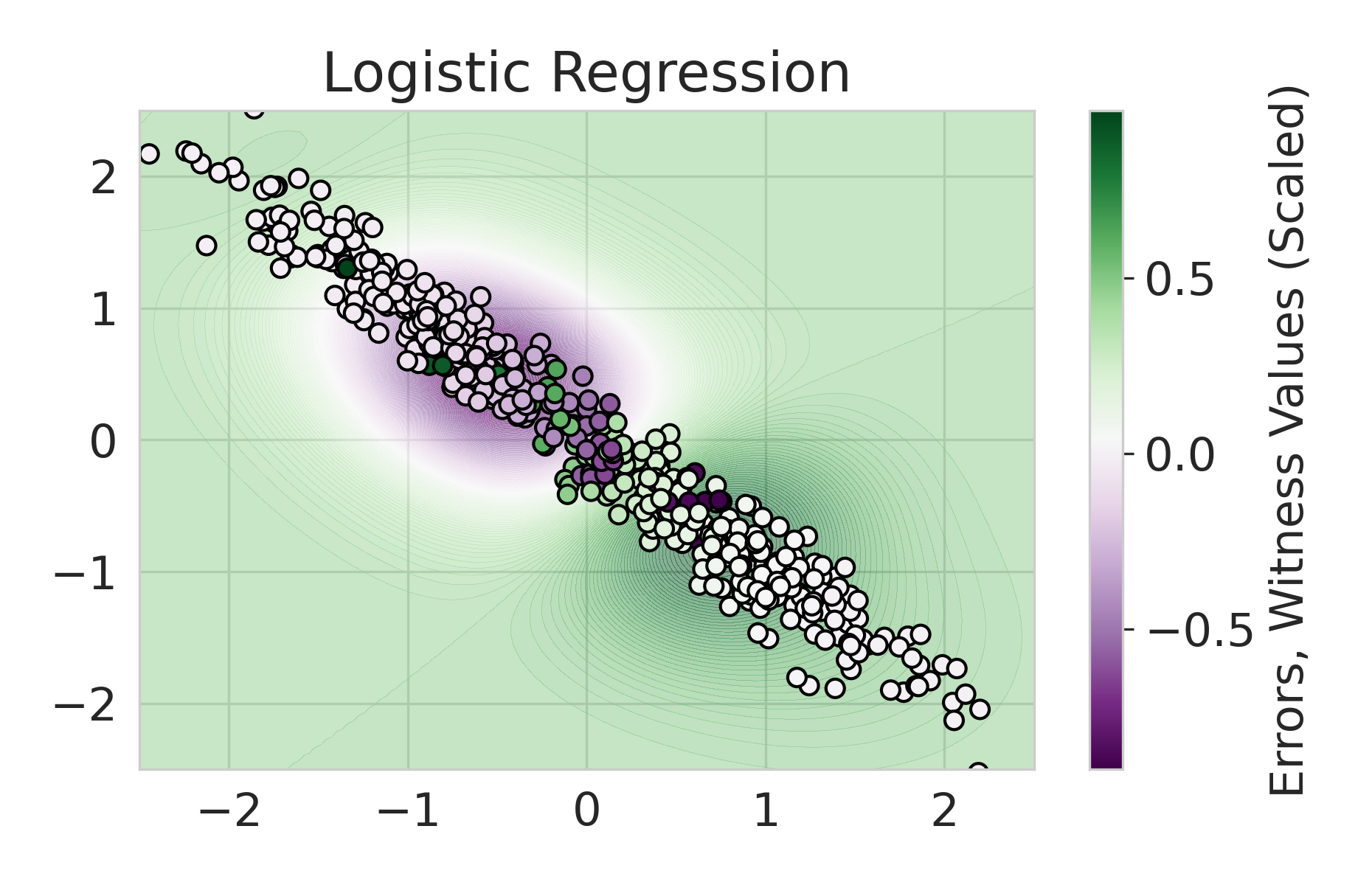
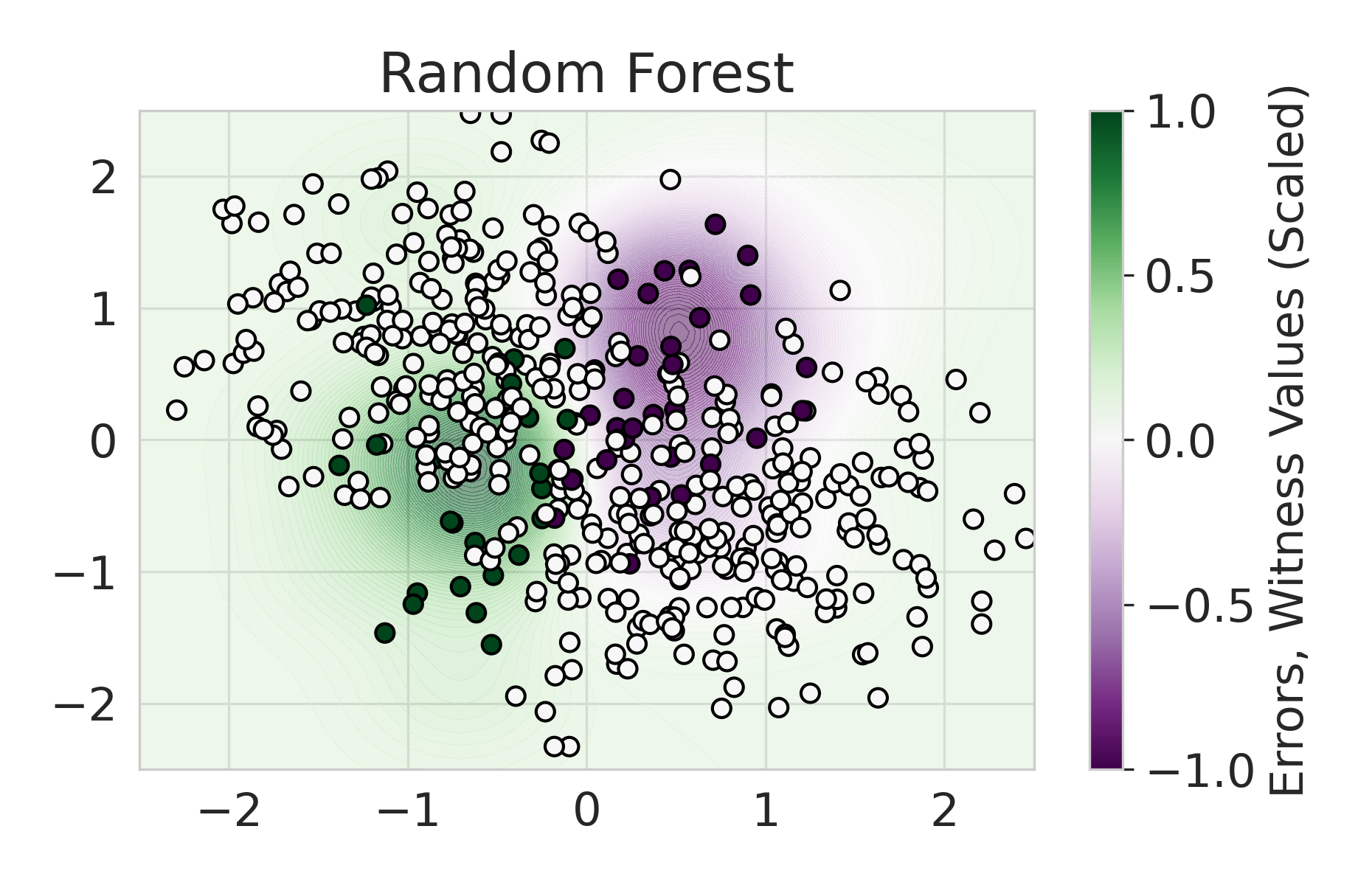 |
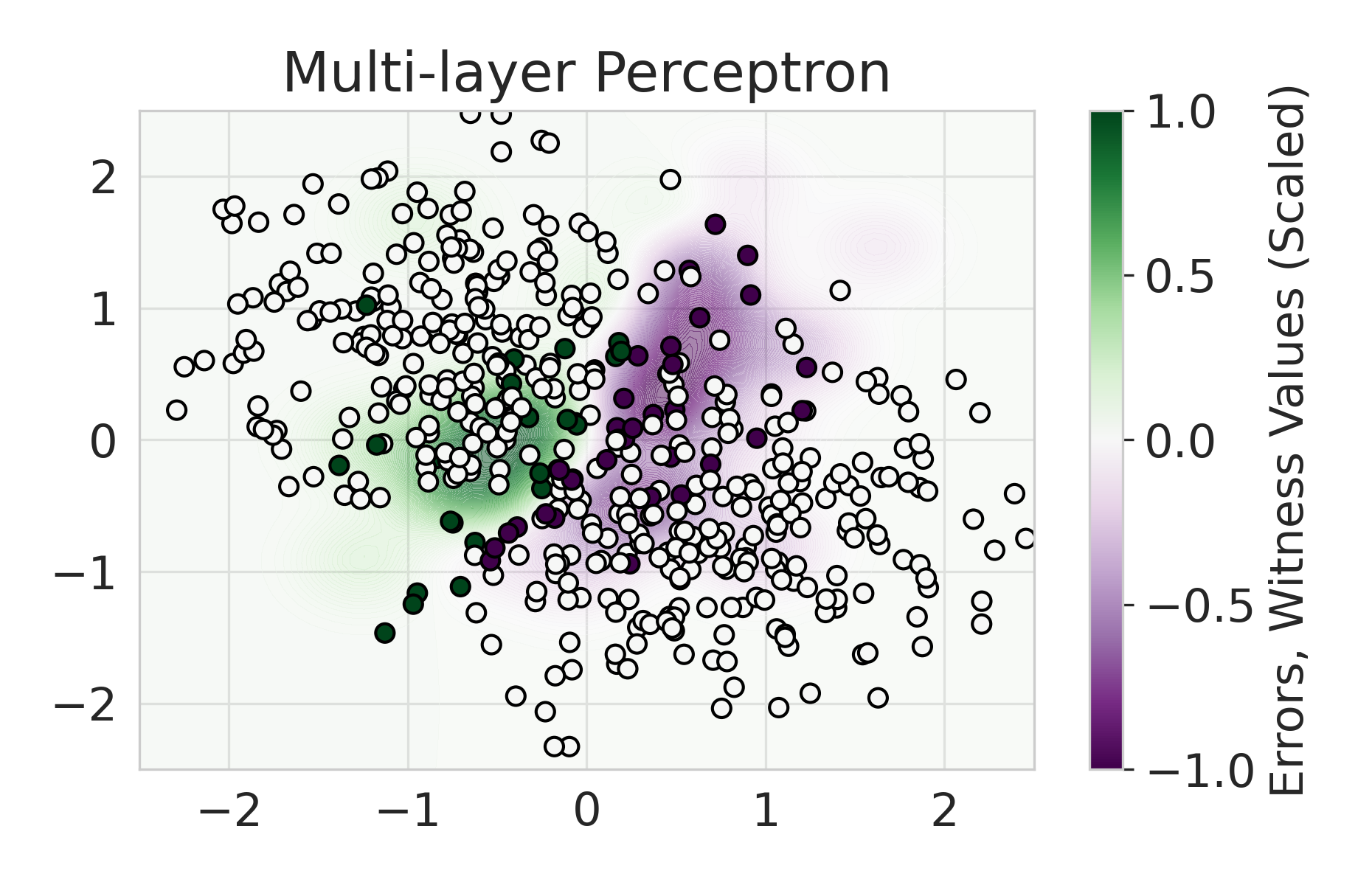 |
 |
 |
 |
 |
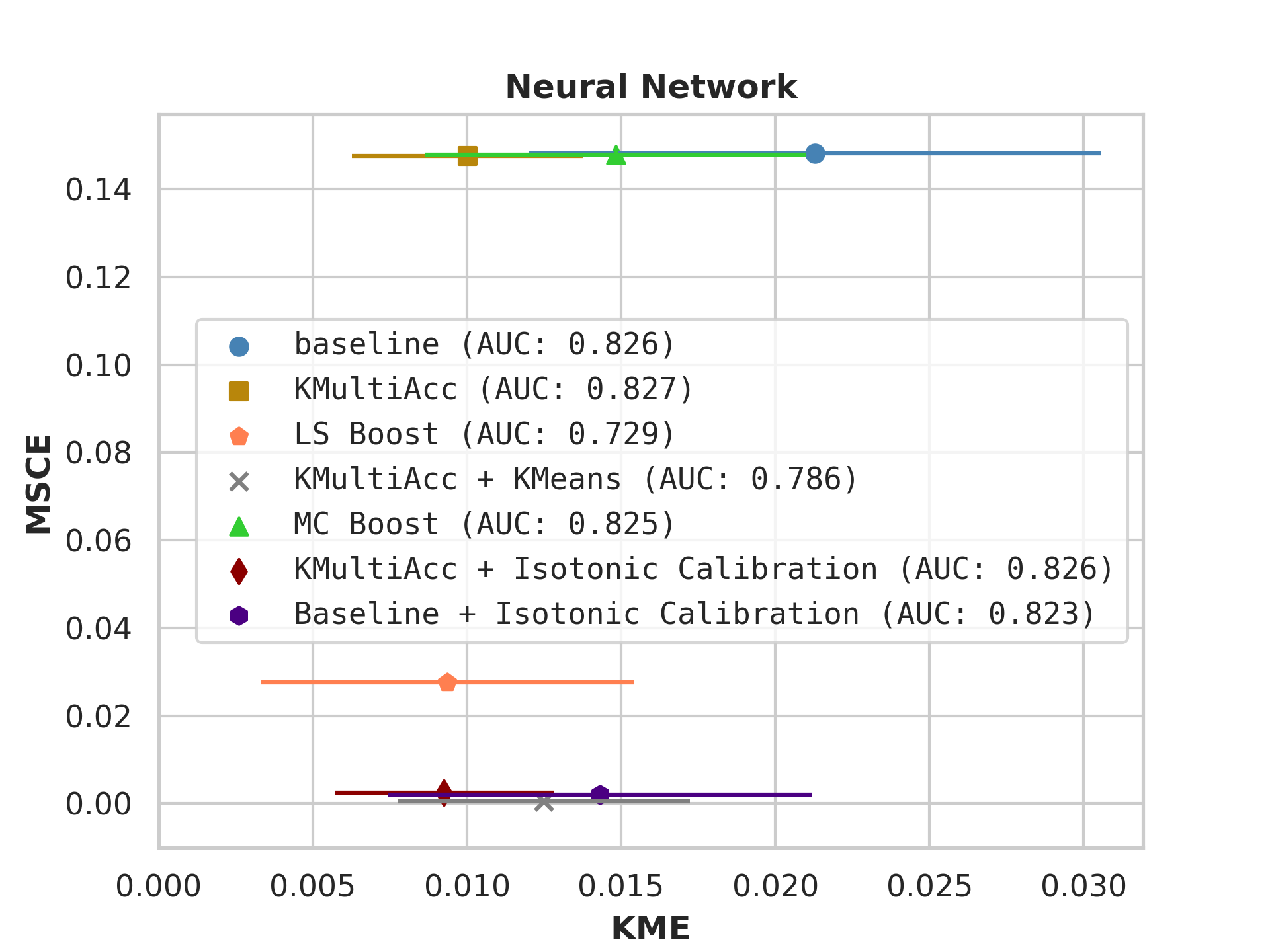
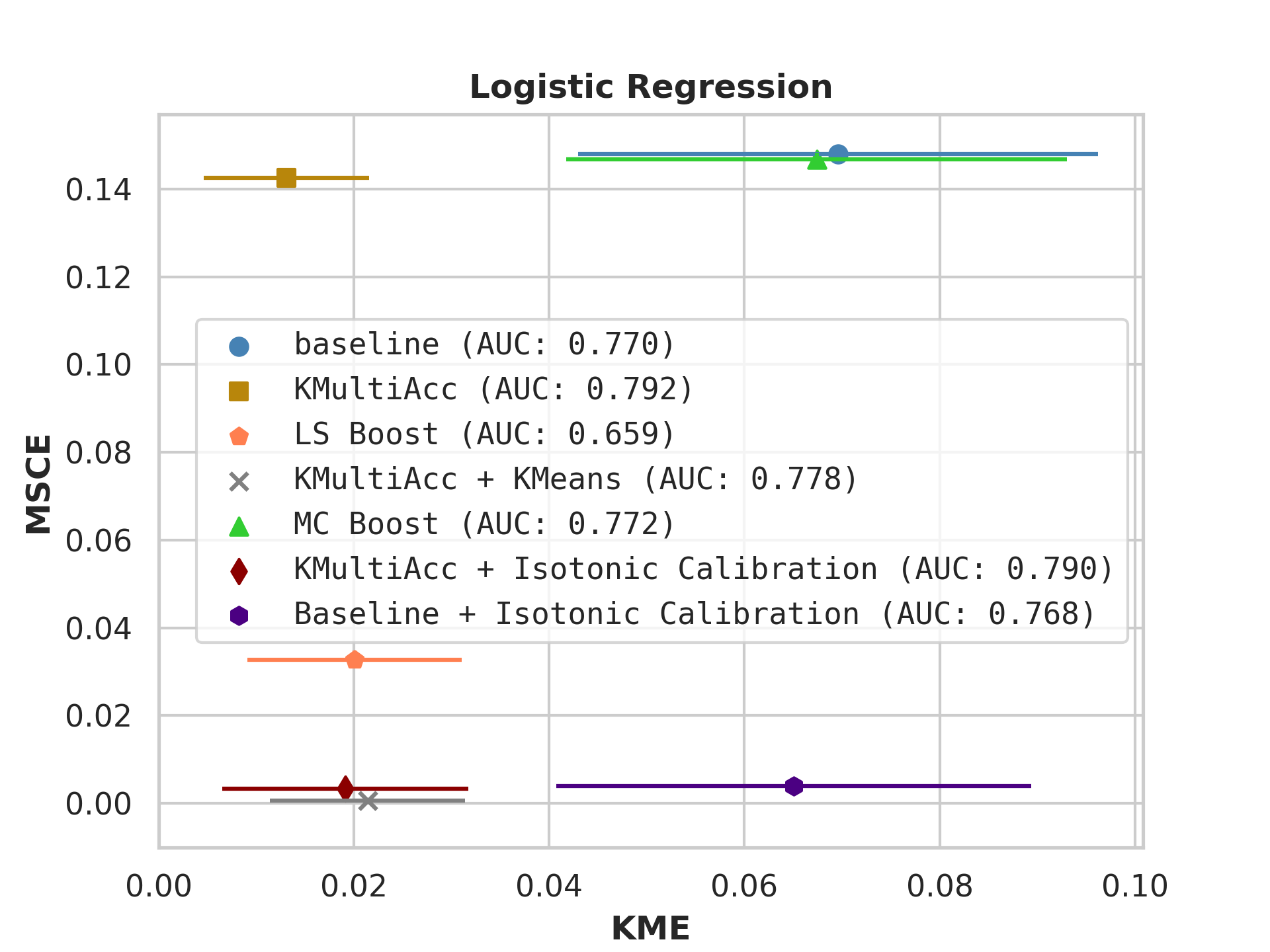
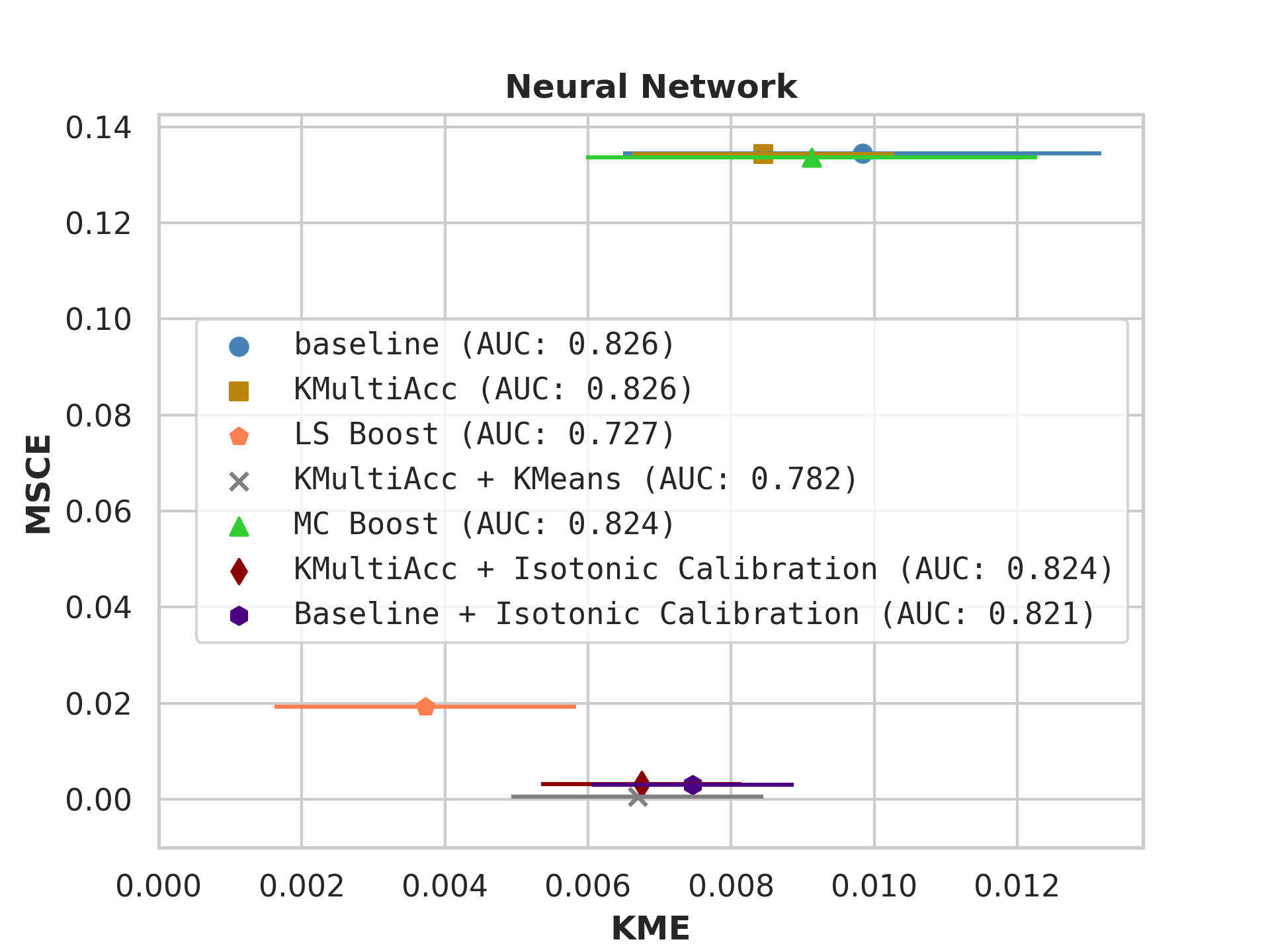
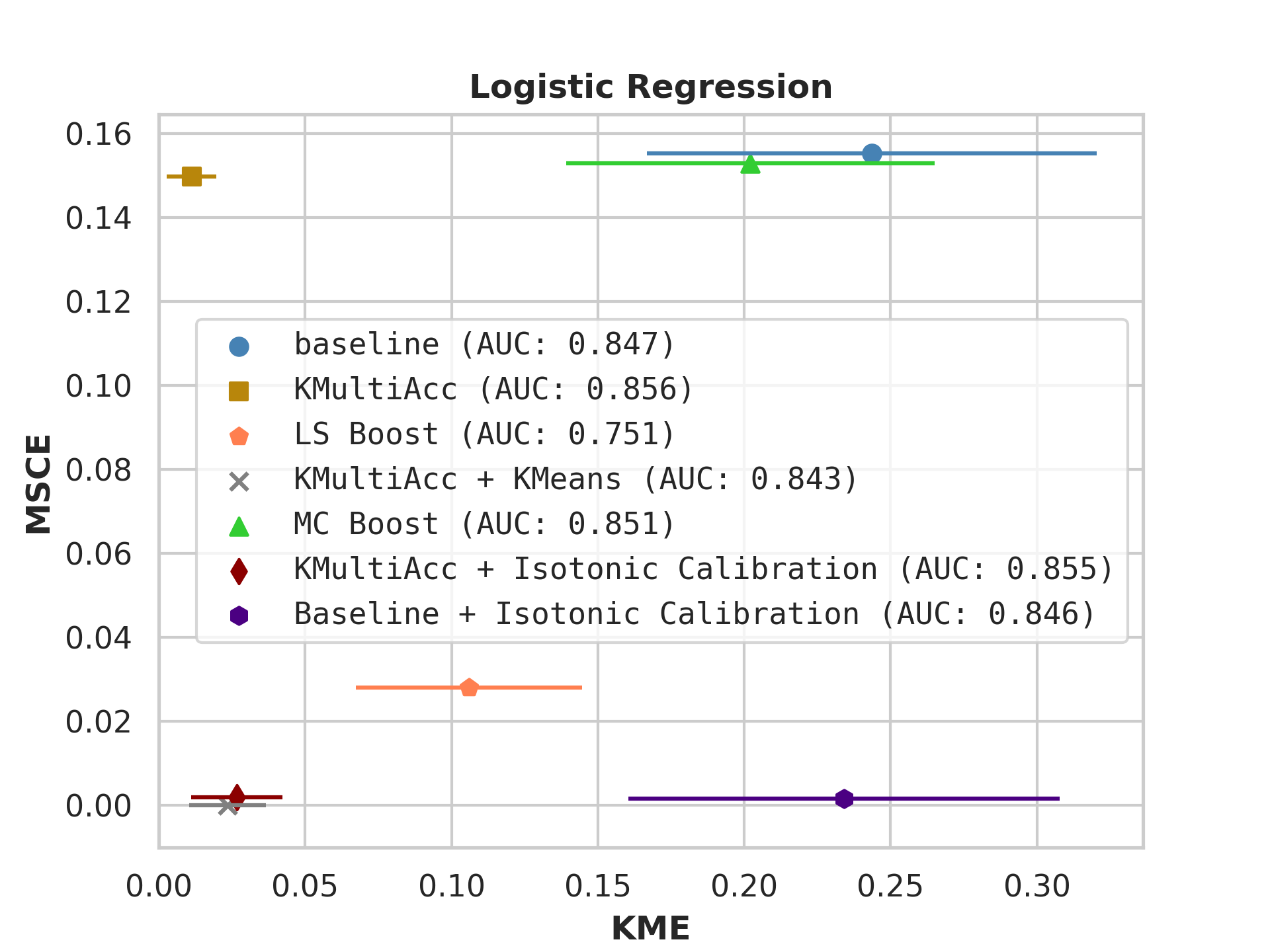
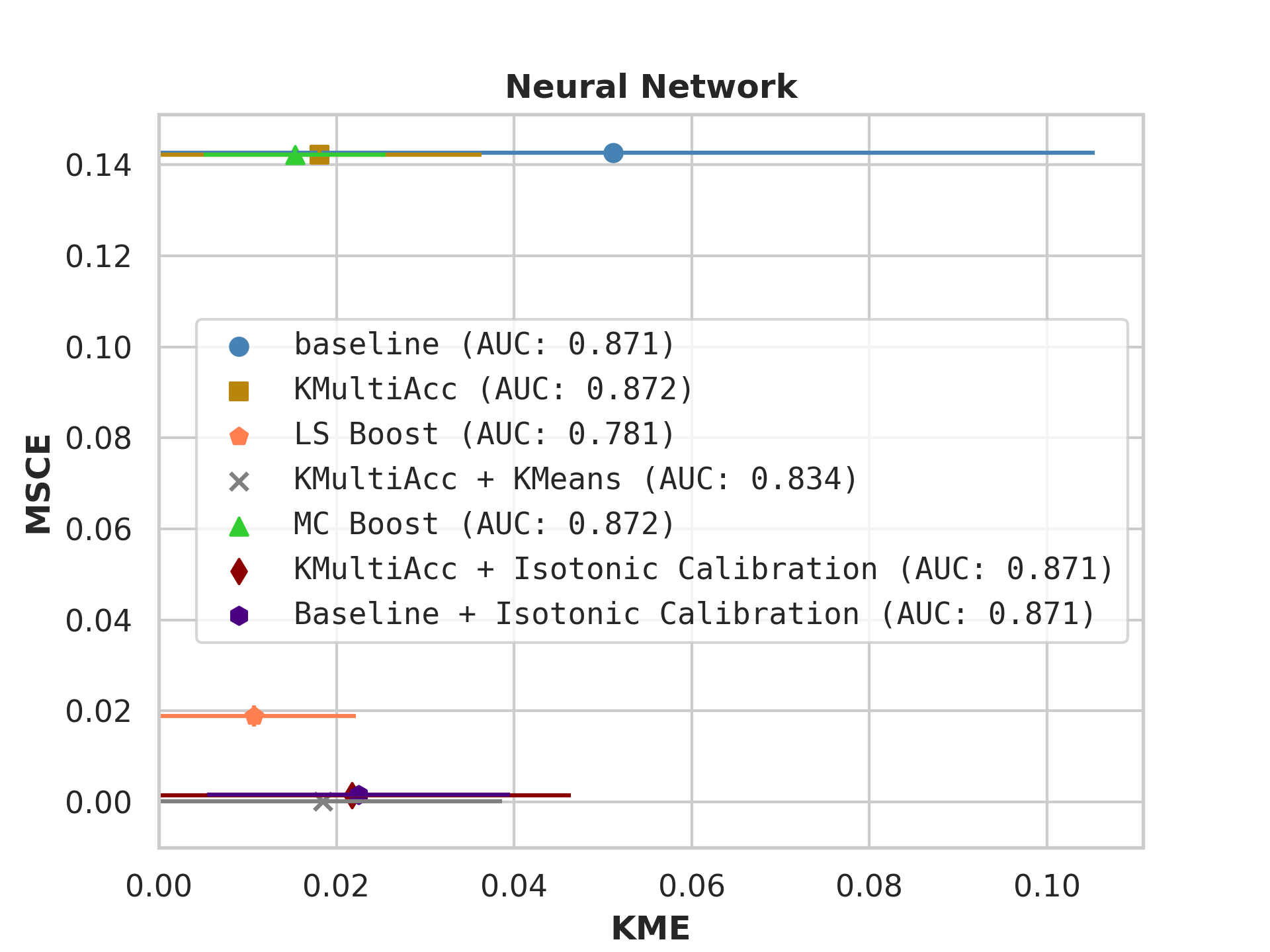
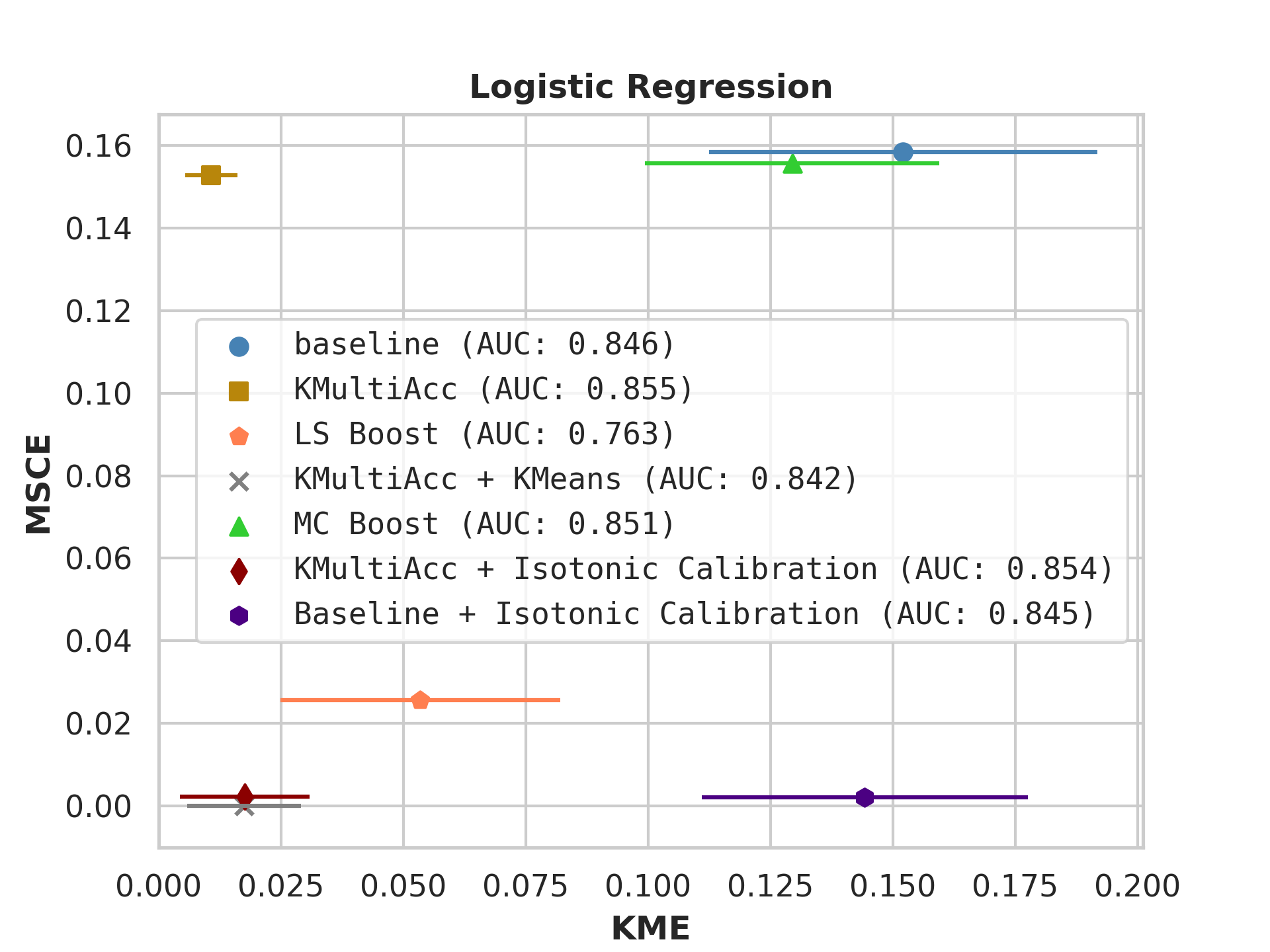
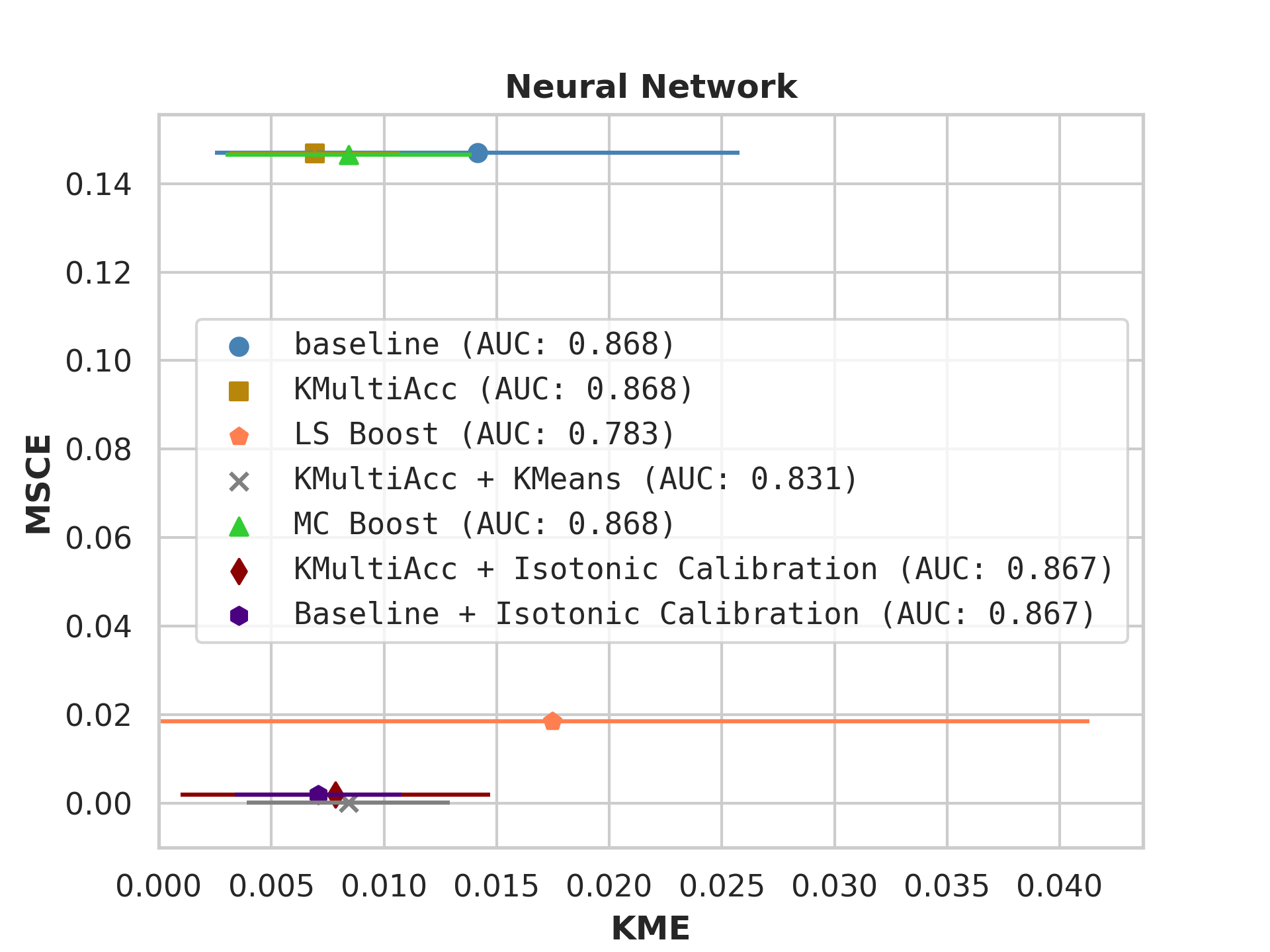
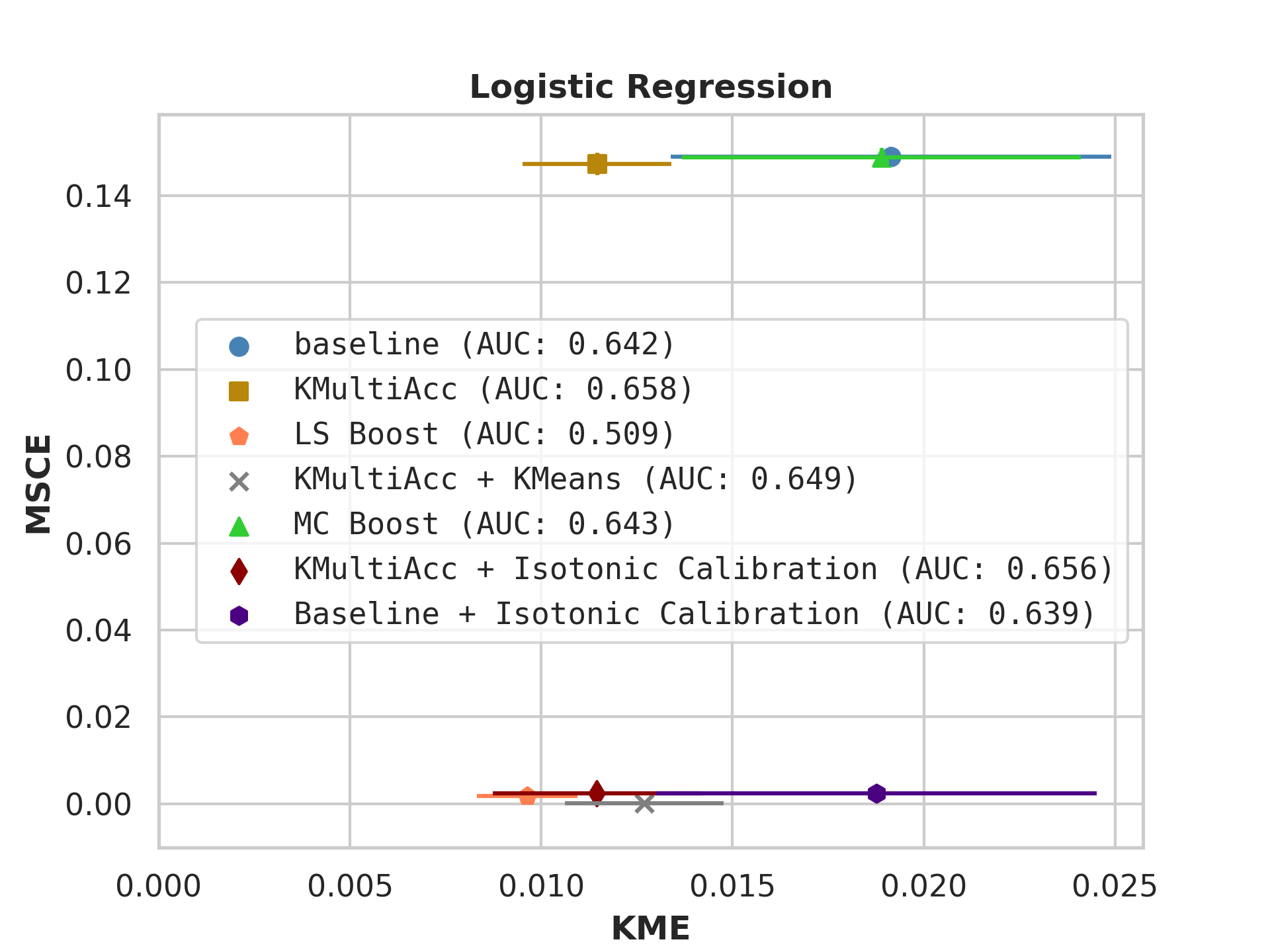
With the process described in Section 4.4, we test KMAccacross various baseline classifiers using implementations in Scikit-Learn [35]. In each US Census dataset, we execute five runs of each model on which we report, showing the mean value of each metric alongside error bars.
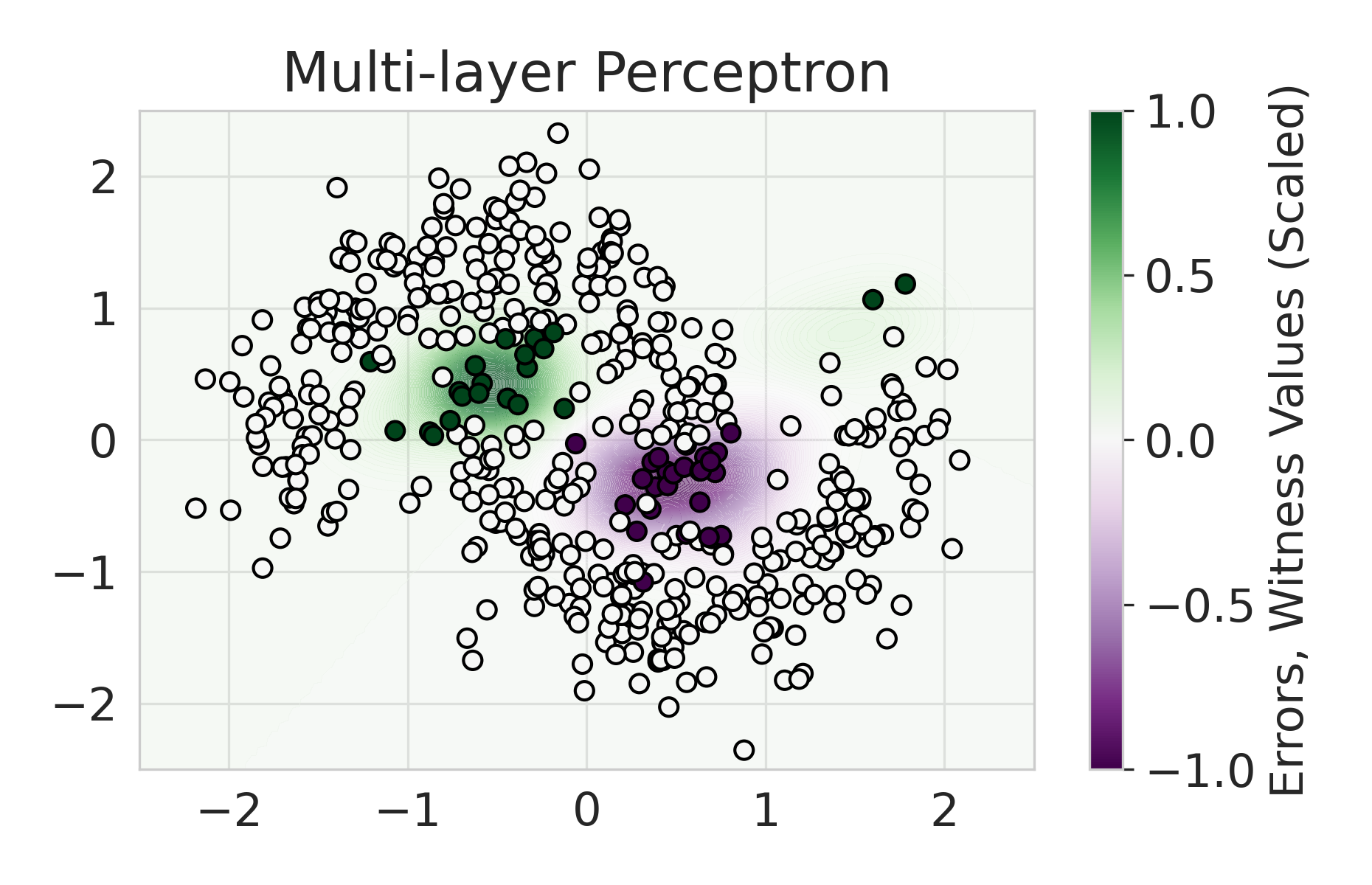
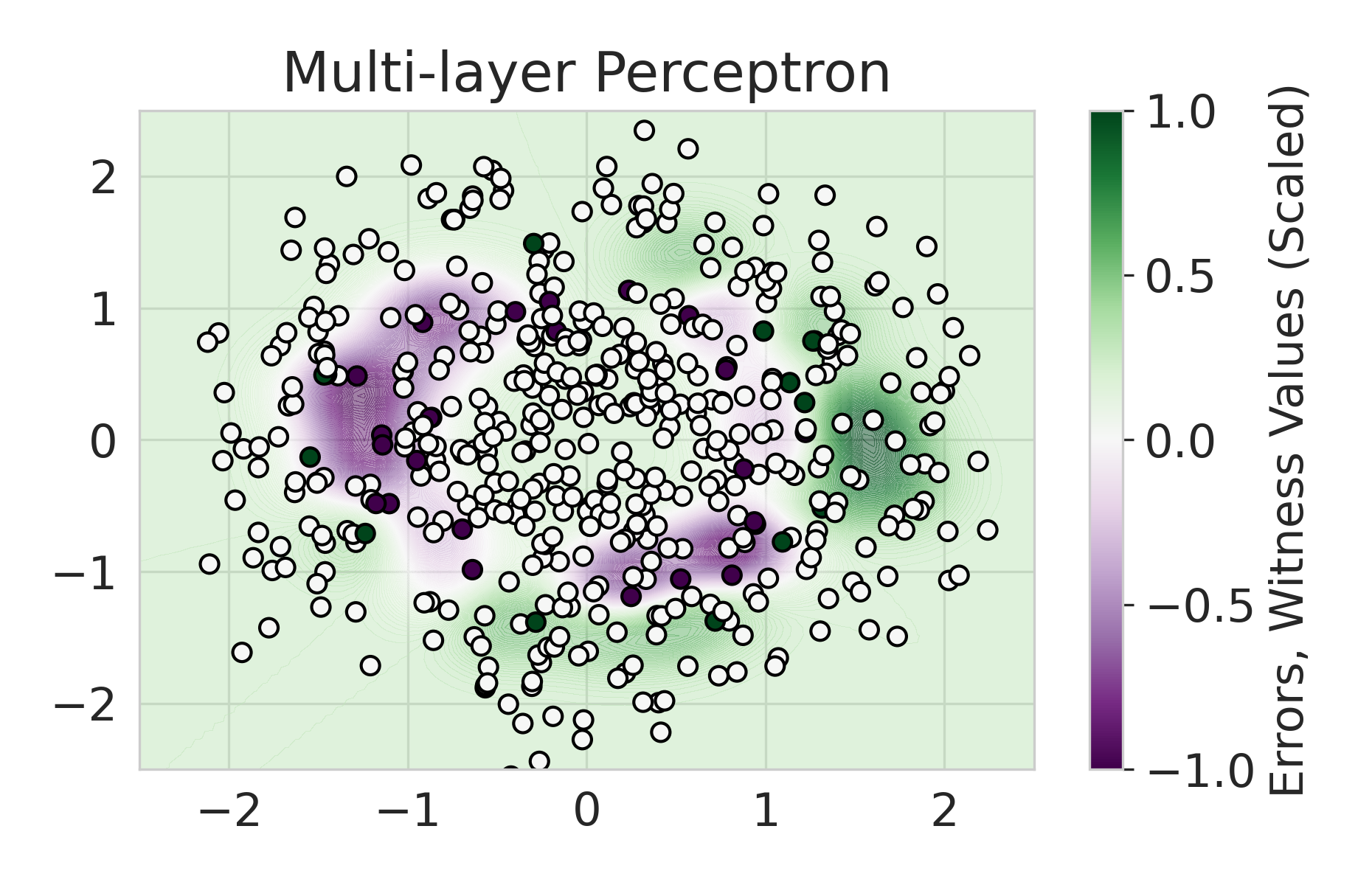
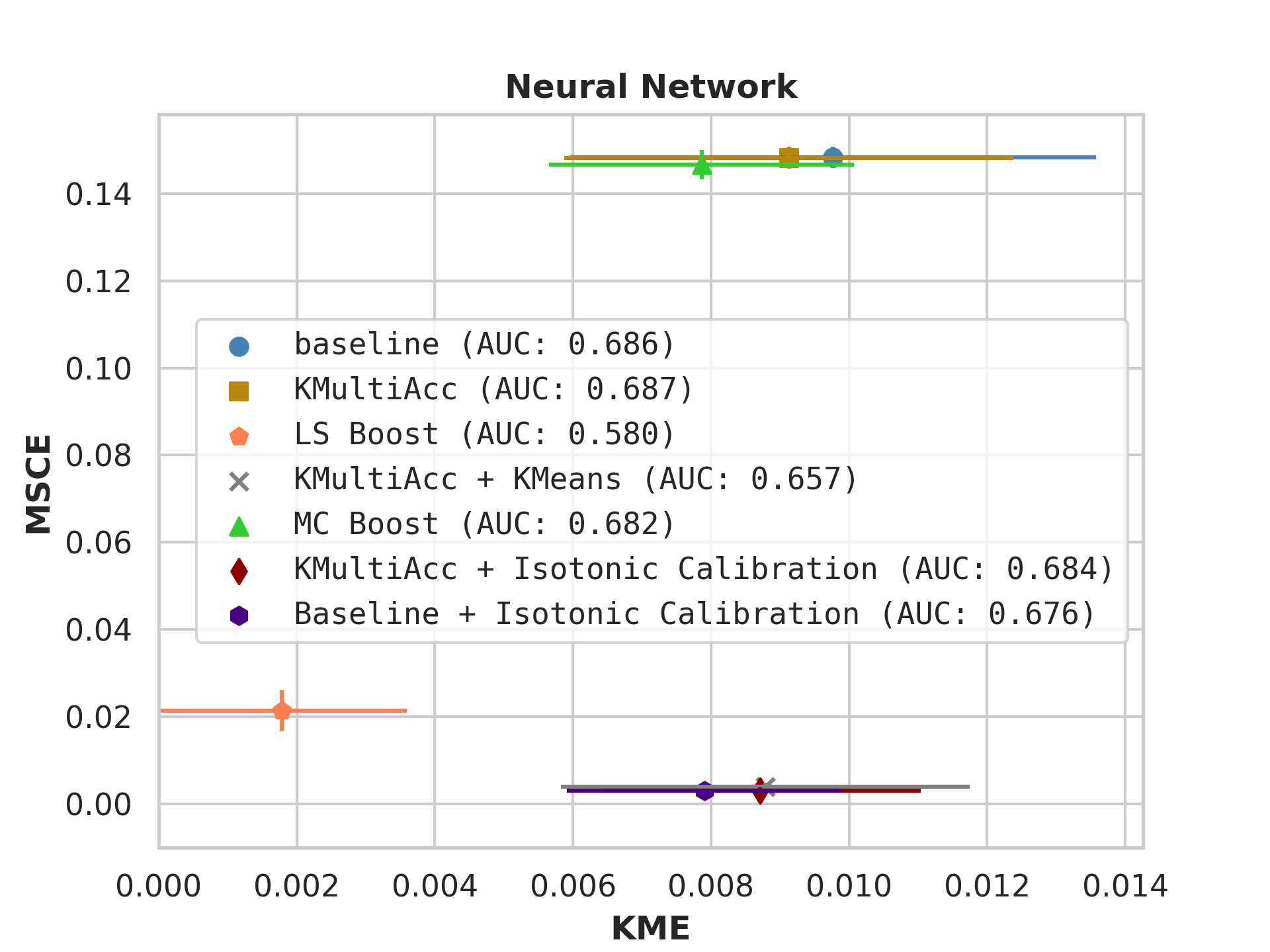
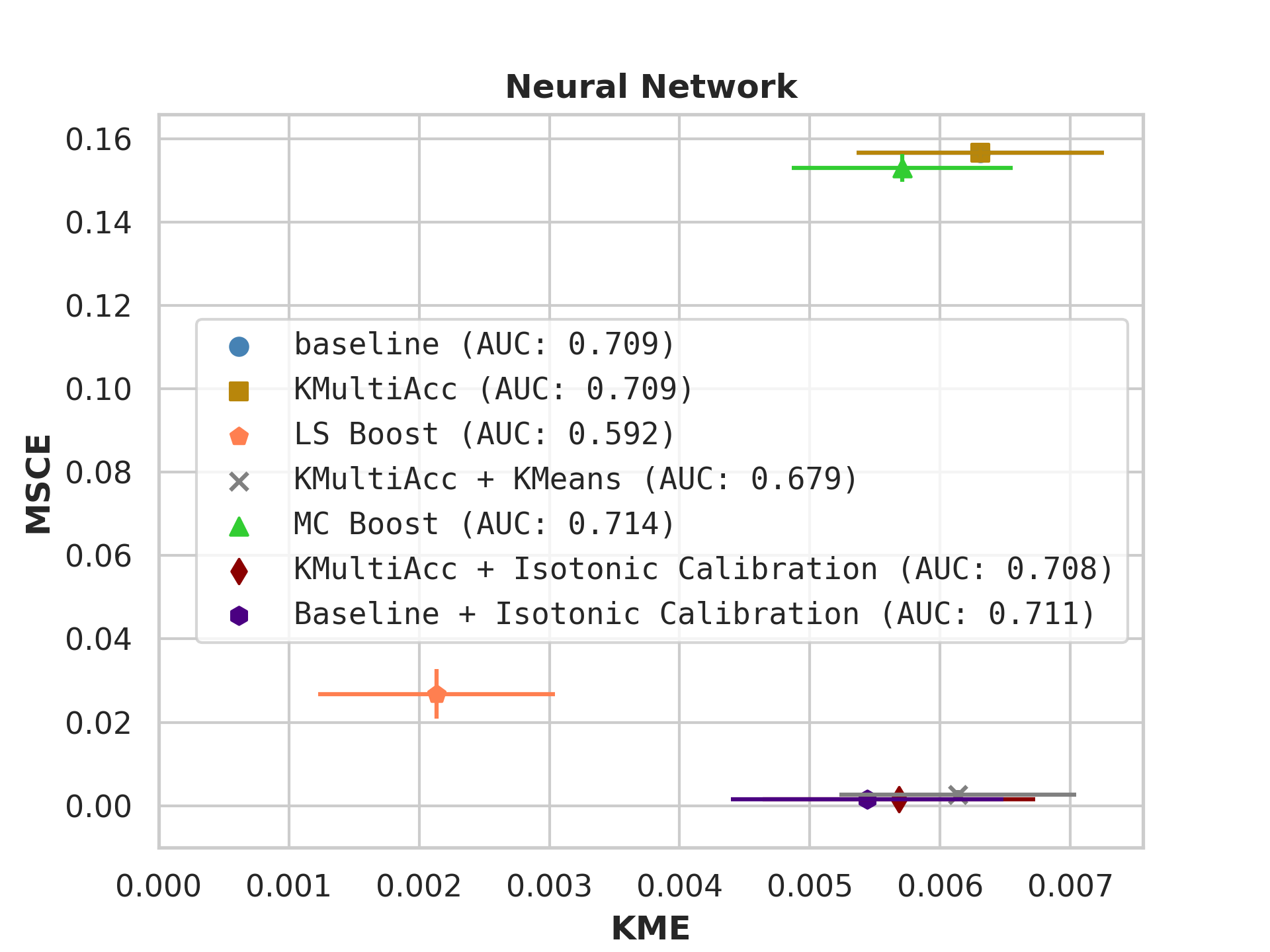
Firstly, on synthetic datasets, we demonstrate that the witness function is a good predictor of classifier error. In Figure 1, we train a logistic regression classifier on the moon and circle datasets to perform binary classification. The classifier has an accuracy of 0.85 and AUC of 0.94, and most errors occur in the middle where the red and blue classes are not linearly separable. Indeed, samples with high errors in scores also receive high predicted errors in terms of witness function values. Indeed, the scatter plot (Right Column) illustrates the linear correlation between test error and witness value, with a high Pearson correlation coefficients of 0.828. Complete results using additional baseline models (Random Forest and Multi-layer Perceptron) are shown in Figure 3.
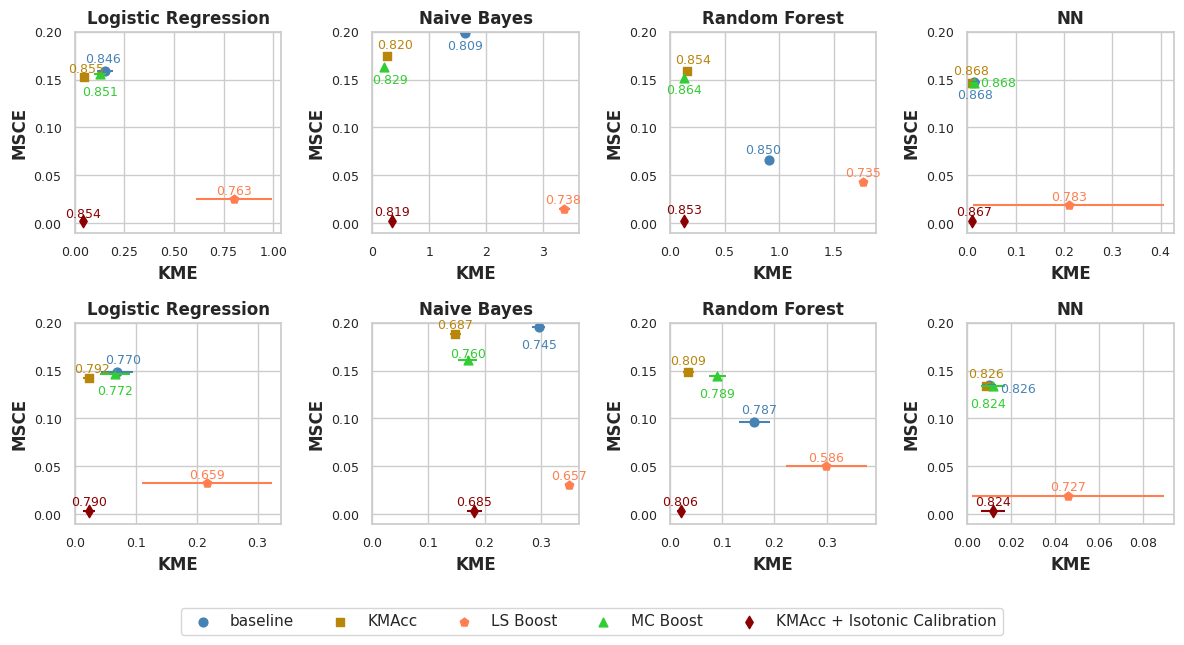
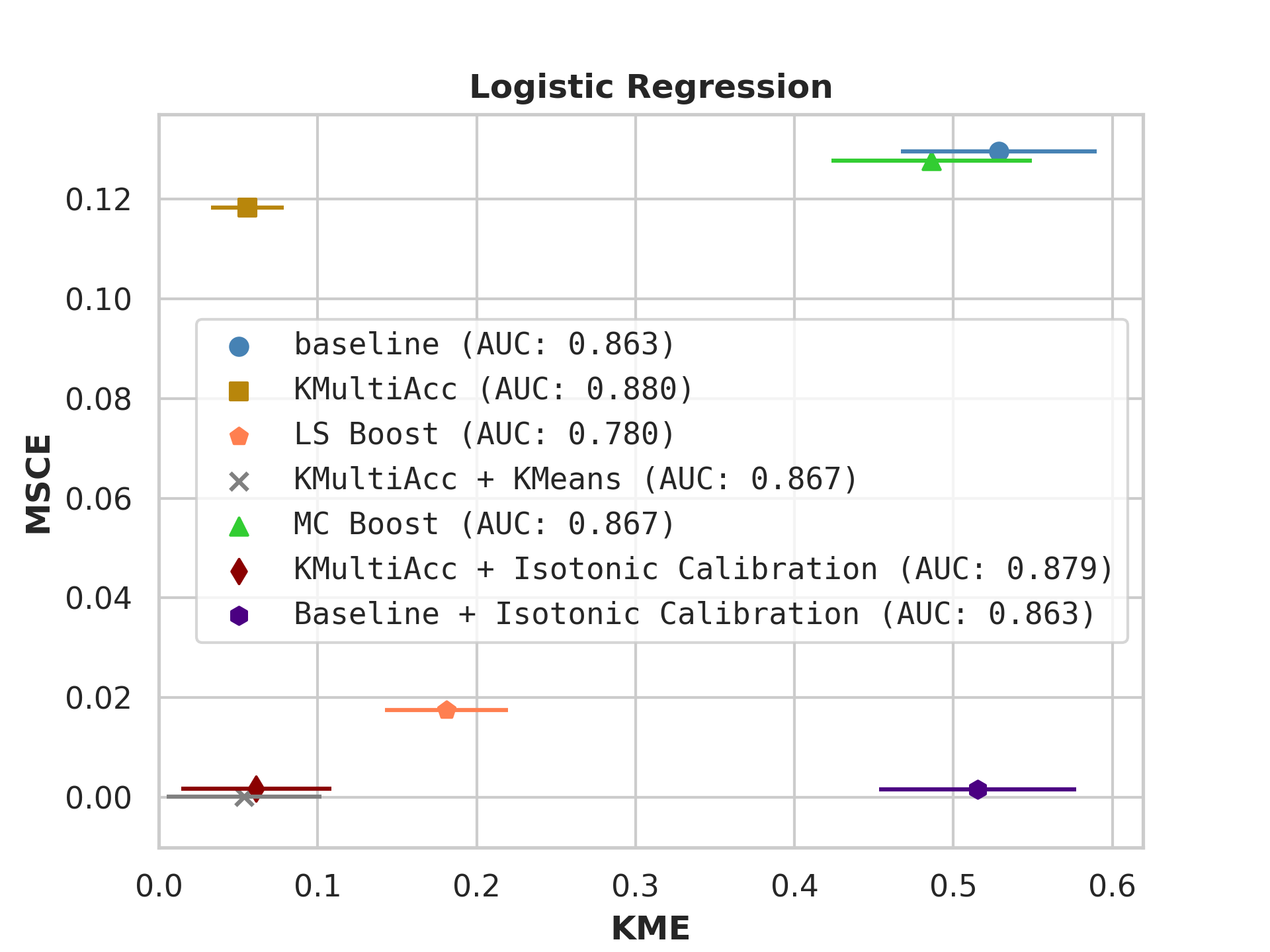
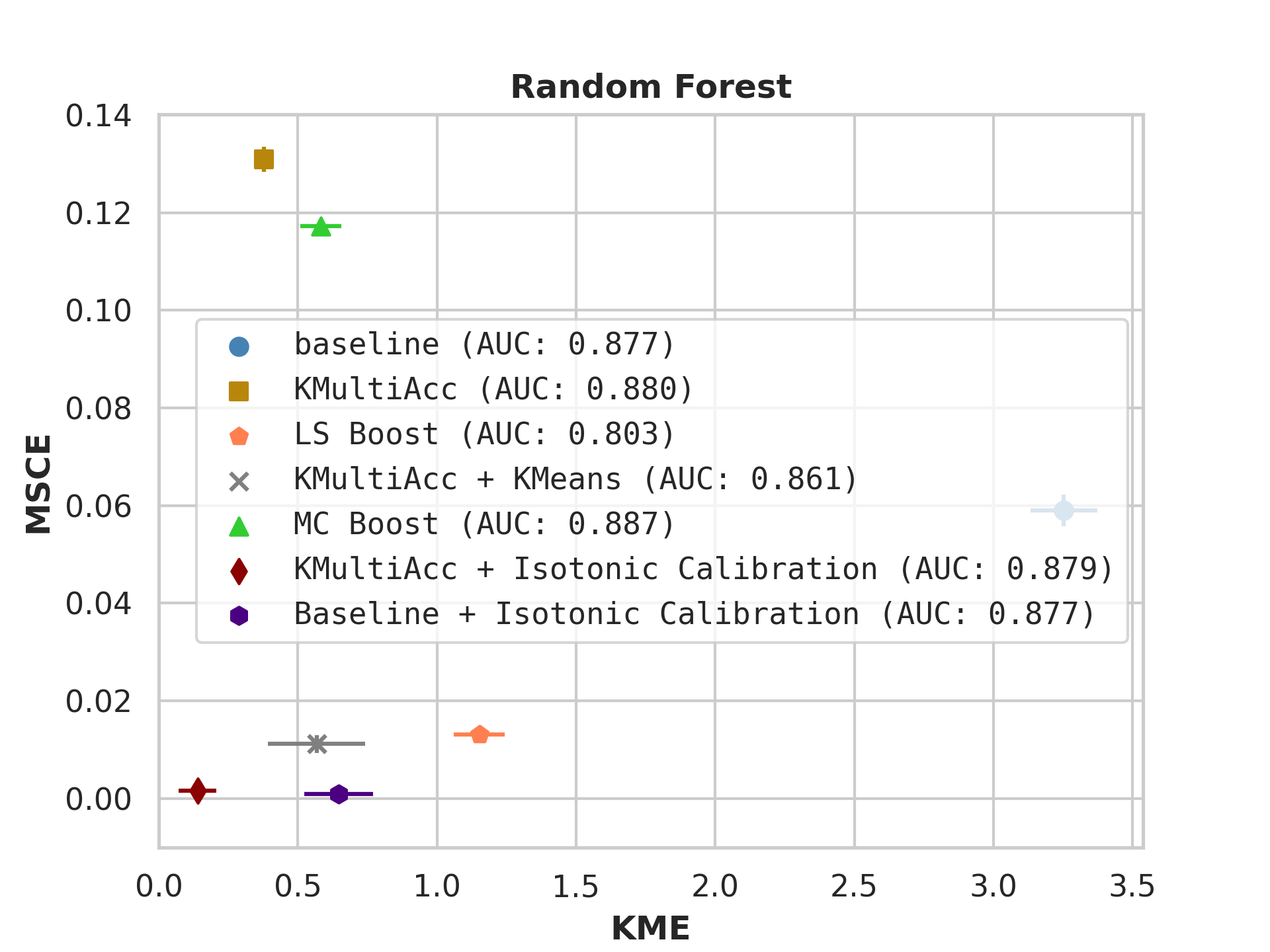
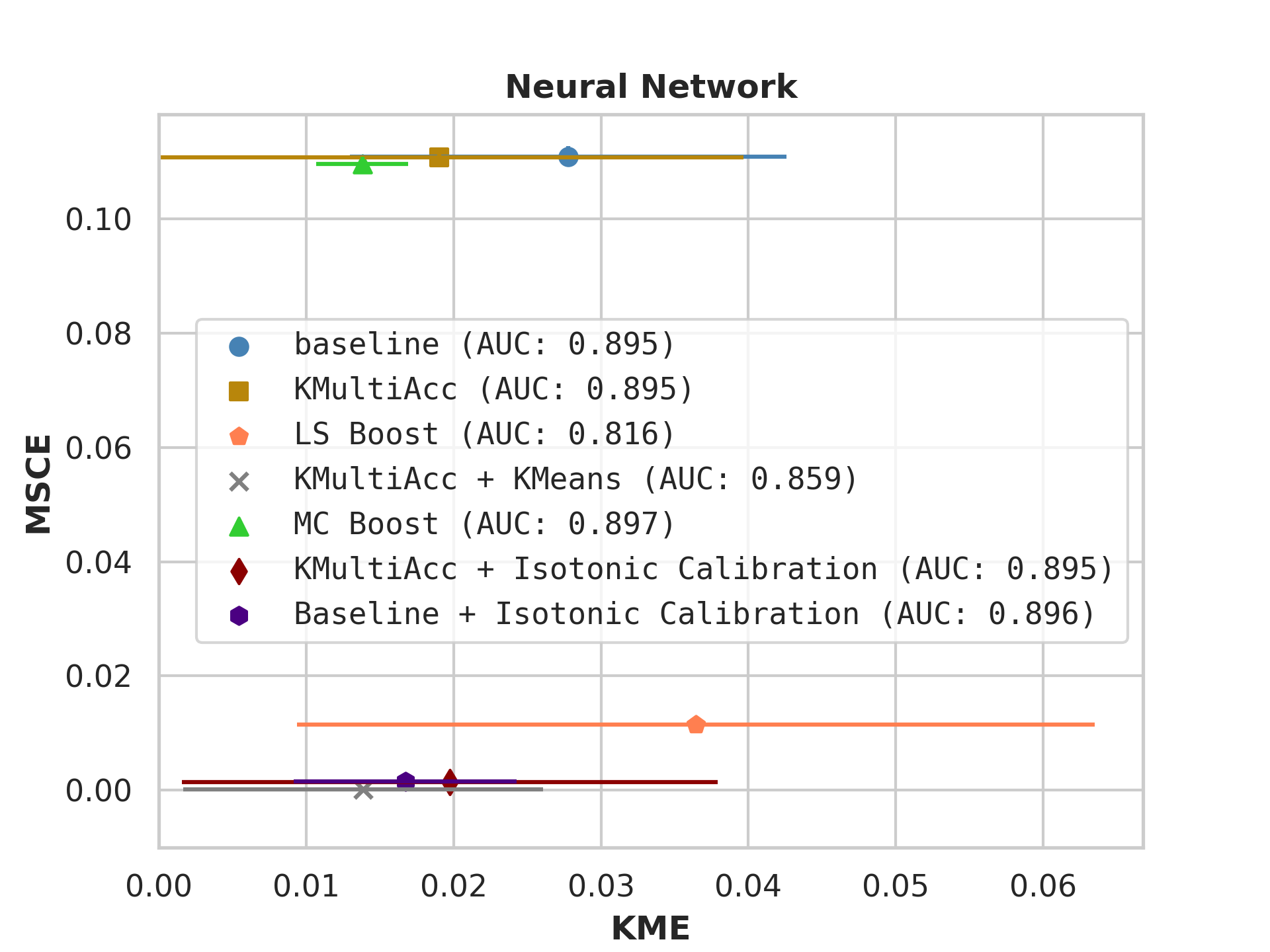
On US Census datasets and as demonstrated in Figure 10, KMAcc achieves the lowest KME relative to competing models without sacrificing AUC, and KMAcc paired with isotonic calibration achieves the lowest multi-group metrics (KME and MSCE) while maintaining competitive AUC. In Figure 10, baseline models (blue circle) have high MSCE, and most have non-negligible KME, with the exception of neural networks. Post-processing the baseline models using KMAcc (yellow rectangle), we see a significant reduction in KME from the baseline (shifting to the left of the plot), and in a majority of experiments, the post-processed models achieve, on the test set, the pre-specified KME constraint with . To target low calibration error (measured by MSCE on the y-axis), we apply off-the-shelf isotonic calibration on top of KMAcc. We observe that applying KMAccIsotonic Calibration (red diamond) to baseline results in low errors on both axes (KME and MSCE). Across all baselines and experiments, applying either KMAccor KMAccIsotonic Calibration does not degrade the predictive power of the models – the AUCs (labeled next to each model) of models corrected by the proposed methods either stay relatively unchanged or improved.
Competing method MCBoost achieves effective reduction in KME with minimal improvement on MSCE, without sacrificing AUC. We note that KMAcc+Isotonic Calibration enjoys comparable or better performance with regards to MCBoost on KME and better performance on MSCE, while eliminating the need for iterative updates to minimize miscalibration that is required in MCBoost. LSBoost(orange polygon) achieves low MSCE while worsening both KME and AUC.
5 Discussion and Conclusion
We connect the multi-group notions to Integral Probability Measures (IPM), providing a unifying statistical perspective on Multiaccuracy, Multicalibration, and OI. This perspective leads us to a simple yet powerful algorithm (KMAcc) for achieving multiaccuracy with respect to a class of functions defined by an RKHS. KMAcc boils down to first predicting the error of the classifier using the witness function, and then subtracting the error away. This algorithm enjoys provable performance guarantees and empirically achieves favorable accuracy and multi-group metrics relative to competing methods.
A limitation of our empirical analysis in comparison to other methods is that we optimize over the calibration function class being the unit-ball RKHS with the RBF kernel, which may not be the set of calibration functions for which other benchmarks achieve the lowest multiaccuracy or multicalibration error on. Furthermore, while the proposed method achieves favorable multicalibration results, this algorithm does not have provable guarantees for multicalibration. Developing a multicalibration-ensuring algorithm through the IPM perspective is an exciting future direction.
To conclude, this work contributes to the greater effort of reducing embedded human bias in ML fairness. To this end, we adopt RKHS as the expressive group-denoting function class to ensure multi-group notions on, rather than using predefined groups. It remains an open question to explore the structure of the witness function – the most biased group-denoting function in the RKHS – and its relationship to the predefined group attributes, which may inform us of the intersectionality and the structure of errors in ML models.
References
- [1] Alekh Agarwal, Alina Beygelzimer, Miroslav Dudík, John Langford, and Hanna Wallach. A reductions approach to fair classification. In International conference on machine learning, pages 60–69. PMLR, 2018. URL: http://proceedings.mlr.press/v80/agarwal18a.html.
- [2] Wael Alghamdi, Hsiang Hsu, Haewon Jeong, Hao Wang, Peter Michalak, Shahab Asoodeh, and Flavio Calmon. Beyond adult and compas: Fair multi-class prediction via information projection. Advances in Neural Information Processing Systems, 35:38747–38760, 2022.
- [3] Solon Barocas, Moritz Hardt, and Arvind Narayanan. Fairness and machine learning: Limitations and opportunities. MIT Press, 2023.
- [4] Alain Berlinet and Christine Thomas-Agnan. Reproducing Kernel Hilbert Spaces in Probability and Statistics. Springer, 1 edition, 2004. doi:10.1007/9781441990969.
- [5] Stephen P Boyd and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.
- [6] Peng Cui, Wenbo Hu, and Jun Zhu. Calibrated reliable regression using maximum mean discrepancy. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 17164–17175. Curran Associates, Inc., 2020. URL: https://proceedings.neurips.cc/paper_files/paper/2020/file/c74c4bf0dad9cbae3d80faa054b7d8ca-Paper.pdf.
- [7] A Philip Dawid. The well-calibrated bayesian. Journal of the American Statistical Association, 77(379):605–610, 1982.
- [8] Zhun Deng, Cynthia Dwork, and Linjun Zhang. Happymap: A generalized multi-calibration method. arXiv preprint arXiv:2303.04379, 2023. doi:10.48550/arXiv.2303.04379.
- [9] Cynthia Dwork, Michael P Kim, Omer Reingold, Guy N Rothblum, and Gal Yona. Outcome indistinguishability. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 1095–1108, 2021. doi:10.1145/3406325.3451064.
- [10] Cynthia Dwork, Daniel Lee, Huijia Lin, and Pranay Tankala. From pseudorandomness to multi-group fairness and back. In The Thirty Sixth Annual Conference on Learning Theory, pages 3566–3614. PMLR, 2023. URL: https://proceedings.mlr.press/v195/dwork23a.html.
- [11] Vitaly Feldman. Distribution-specific agnostic boosting. In International Conference on Supercomputing, 2009. URL: https://api.semanticscholar.org/CorpusID:2787595.
- [12] Sorelle A Friedler, Carlos Scheidegger, Suresh Venkatasubramanian, Sonam Choudhary, Evan P Hamilton, and Derek Roth. A comparative study of fairness-enhancing interventions in machine learning. In Proceedings of the conference on fairness, accountability, and transparency, pages 329–338, 2019. doi:10.1145/3287560.3287589.
- [13] Sumegha Garg, Christopher Jung, Omer Reingold, and Aaron Roth. Oracle efficient online multicalibration and omniprediction. In Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2725–2792. SIAM, 2024. doi:10.1137/1.9781611977912.98.
- [14] Ira Globus-Harris, Varun Gupta, Christopher Jung, Michael Kearns, Jamie Morgenstern, and Aaron Roth. Multicalibrated regression for downstream fairness. arXiv preprint arXiv:2209.07312, 2022. doi:10.48550/arXiv.2209.07312.
- [15] Ira Globus-Harris, Declan Harrison, Michael Kearns, Aaron Roth, and Jessica Sorrell. Multicalibration as boosting for regression. arXiv preprint arXiv:2301.13767, 2023. doi:10.48550/arXiv.2301.13767.
- [16] Robert Kent Goodrich. A riesz representation theorem. In Proc. Amer. Math. Soc, volume 24, pages 629–636, 1970.
- [17] Parikshit Gopalan, Lunjia Hu, Michael P Kim, Omer Reingold, and Udi Wieder. Loss minimization through the lens of outcome indistinguishability. arXiv preprint arXiv:2210.08649, 2022. doi:10.48550/arXiv.2210.08649.
- [18] Parikshit Gopalan, Adam Tauman Kalai, Omer Reingold, Vatsal Sharan, and Udi Wieder. Omnipredictors. arXiv preprint arXiv:2109.05389, 2021. arXiv:2109.05389.
- [19] Arthur Gretton, Karsten Borgwardt, Malte Rasch, Bernhard Schölkopf, and Alex Smola. A kernel method for the two-sample-problem. Advances in neural information processing systems, 19, 2006.
- [20] Nika Haghtalab, Michael Jordan, and Eric Zhao. A unifying perspective on multi-calibration: Game dynamics for multi-objective learning. Advances in Neural Information Processing Systems, 36, 2024.
- [21] Moritz Hardt, Eric Price, and Nati Srebro. Equality of opportunity in supervised learning. Advances in neural information processing systems, 29, 2016.
- [22] Ursula Hébert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. Multicalibration: Calibration for the (computationally-identifiable) masses. In International Conference on Machine Learning, pages 1939–1948. PMLR, 2018.
- [23] Emmie Hine and Luciano Floridi. The blueprint for an ai bill of rights: in search of enaction, at risk of inaction. Minds and Machines, pages 1–8, 2023.
- [24] Max Hort, Zhenpeng Chen, Jie M Zhang, Federica Sarro, and Mark Harman. Bia mitigation for machine learning classifiers: A comprehensive survey. arXiv preprint arXiv:2207.07068, 2022. doi:10.48550/arXiv.2207.07068.
- [25] Faisal Kamiran, Asim Karim, and Xiangliang Zhang. Decision theory for discrimination-aware classification. In 2012 IEEE 12th international conference on data mining, pages 924–929. IEEE, 2012. doi:10.1109/ICDM.2012.45.
- [26] Michael Kearns, Seth Neel, Aaron Roth, and Zhiwei Steven Wu. Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In International conference on machine learning, pages 2564–2572. PMLR, 2018.
- [27] Been Kim, Rajiv Khanna, and Oluwasanmi O Koyejo. Examples are not enough, learn to criticize! criticism for interpretability. Advances in neural information processing systems, 29, 2016.
- [28] Michael P Kim, Amirata Ghorbani, and James Zou. Multiaccuracy: Black-box post-processing for fairness in classification. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 247–254, 2019. doi:10.1145/3306618.3314287.
- [29] Michael P. Kim, Christoph Kern, Shafi Goldwasser, and Frauke Krueter. Universal adaptability: Target-independent inference that competes with propensity scoring. Proceedings of the National Academy of Sciences, page 119(4):e2108097119, 2022.
- [30] Aviral Kumar, Sunita Sarawagi, and Ujjwal Jain. Trainable calibration measures for neural networks from kernel mean embeddings. In International Conference on Machine Learning, pages 2805–2814. PMLR, 2018.
- [31] Carol Xuan Long, Hsiang Hsu, Wael Alghamdi, and Flavio Calmon. Individual arbitrariness and group fairness. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [32] Charles Marx, Sofian Zalouk, and Stefano Ermon. Calibration by distribution matching: Trainable kernel calibration metrics. arXiv preprint arXiv:2310.20211, 2023. doi:10.48550/arXiv.2310.20211.
- [33] Alfred Müller. Integral probability metrics and their generating classes of functions. Advances in applied probability, 29(2):429–443, 1997.
- [34] Alexandru Niculescu-Mizil and Rich Caruana. Predicting good probabilities with supervised learning. In Proceedings of the 22nd international conference on Machine learning, pages 625–632, 2005. doi:10.1145/1102351.1102430.
- [35] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011. doi:10.5555/1953048.2078195.
- [36] Hao Song, Tom Diethe, Meelis Kull, and Peter Flach. Distribution calibration for regression. In International Conference on Machine Learning, pages 5897–5906. PMLR, 2019. URL: http://proceedings.mlr.press/v97/song19a.html.
- [37] Bharath K Sriperumbudur, Kenji Fukumizu, Arthur Gretton, Bernhard Schölkopf, and Gert RG Lanckriet. On the empirical estimation of integral probability metrics, 2012.
- [38] Bharath K Sriperumbudur, Kenji Fukumizu, and Gert RG Lanckriet. Universality, characteristic kernels and rkhs embedding of measures. Journal of Machine Learning Research, 12(7), 2011.
- [39] David Widmann, Fredrik Lindsten, and Dave Zachariah. Calibration tests in multi-class classification: A unifying framework. Advances in neural information processing systems, 32, 2019.
- [40] David Widmann, Fredrik Lindsten, and Dave Zachariah. Calibration tests beyond classification. arXiv preprint arXiv:2210.13355, 2022. doi:10.48550/arXiv.2210.13355.
- [41] Lujing Zhang, Aaron Roth, and Linjun Zhang. Fair risk control: A generalized framework for calibrating multi-group fairness risks. arXiv preprint arXiv:2405.02225, 2024. doi:10.48550/arXiv.2405.02225.
Appendix
Appendix A Details of Theoretical Framework
From Equation (37), we show that it is a quadratic program (QP). To begin, writing and denoting
| (41) |
the objective function becomes the quadratic function . Similarly, the constraint is a linear inequality in , which we write as , where and are fixed and determined by and in view of equation (33) for the empirical witness function . Explicitly, denoting , let us use the shorthands
| (42) |
Then, the multiaccuracy constraint in (37) can be written as . Taking the search space into consideration (i.e., evaluates to ), we see that (37) may be rewritten as the the following QP:
| (43) | ||||
| subject to |
where we define the constraint’s matrix and vector by
| (44) |
Note that the witness function for a kernel , dataset , and predictor is given by
| (45) |
| (46) |
where is the vector-valued function defined by , and are fixed vectors, and is a normalizing constant that is unique up to sign. We may compute by setting , namely, we have
| (47) |
where is a fixed matrix. Thus, the multiaccuracy constraint becomes
| (48) |
where and . With and , the objective becomes . At each iteration of , check if .
We may compute the KME of a predictor with respect to class and dataset via the equation
| (49) |
where are computed on as above, and are fixed vectors, and is a fixed matrix. Note that if is used for computing for a given predictor and then is obtained using (so was used for deriving ), then one should report for a freshly sampled at the testing phase.
Appendix B Complete Experimental Results
Ablation.
As we have presented evidence that isotonic calibration plus KMAcc can be an effective post-processing method, for the purpose of ablation we now analyze isotonic calibration being applied directly to the baseline classifier. We note that isotonic calibration tends to maintain an equivalent or higher AUC because the monotonic function preserves ranking of the samples up to tie breaking (which rarely has an influence) [34]. Our ablation method frequently achieves a similar or better MSCE than LSBoost (as discussed, the baseline plus isotonic calibration achieves a MSCE less than in all benchmarks, while LSBoost only achieves this in of benchmarks), and a better average MSCE than KMAcc alone in all benchmarks. However, isotonic calibration alone has a significantly lower KME than KMAcc in of benchmarchs, confirming the utility of an algorithm targeting optimizing for multiaccuracy error as well.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|
|
|
Appendix C KMAcc: Conditions for One-Step Sufficiency
A one-step update using the witness function in KMAccleads to a -multiaccurate predictor all functions in the RKHS for the linear kernel and very specific constructions of nonlinear kernel. Running KMAcc as an iterative procedure is redundant under these restricted settings. This is a property of RKHSs that follows from the Riesz Representation Theorem [16].
Remark 20.
To gain an intuition on why multiaccuracy may be zero upon a one-step update, we can observe an analogous result in the Euclidean space . Given a linear subspace , a prediction vector and true labels , multiaccuracy can be similarly defined as
The error of a classifier can be decomposed into two components: the projection of onto the subspace and the residual. Hence, we have . Then, once we subtract away , multiaccuracy error boils down to the dot product , which equals 0. ∎
Next, we proceed with an RKHS . Given a base predictor , the kernel function w.r.t an RKHS . Again, denotes the space of real-valued functions that are integrable against , i.e. . Let the multiaccuracy error of one function be . By the reproducing property of , we have for all . We can thus rewrite the multiaccuracy error as the following:
where . For the second step, since , we can invoke the Fubini’s Theorem to interchange expectation and inner product. Under the assumption of integrability, . By the Riesz Representation Theorem, the linear functional has a unique representer , which is the function defined above. Specifically, by the Riesz Representation Theorem, there exists a unique such that for all ,
where the function is defined as the normalized direction of , i.e. , and This is identical to as defined in (25). From Proposition 11, achieves the supremum over : . This simplifies , where we substitute . Let the updated predictor be: .
The multiaccuracy error after the one-step update is given by:
For the linear kernel (as we have observed in the remark), we operate in the Euclidean space, and . Hence, By taking , we have
For non-linear kernels, in general, and equality holds only when
where is a scalar constant.
To see this, we need to simplify in the kernel space:
In the first equality, we substitute in the definition of . In the second equality, we apply Fubini’s Theorem to swap the two expectations. In the third equality, we apply the reproducing property where . In the fourth equality, we interchange the expectation and inner product by Fubini’s theorem under integrability conditions. In the last equality, we expand into iterative expectations.