Branch Prediction Analysis of Morris-Pratt and Knuth-Morris-Pratt Algorithms

Abstract
We investigate the classical Morris-Pratt and Knuth-Morris-Pratt pattern matching algorithms from the perspective of computer architecture, focusing on the effects of incorporating a simple branch prediction mechanism into the computational model. Assuming a fixed pattern and a random text, we derive precise estimates for the number of branch mispredictions incurred by these algorithms when using local predictors. Our analysis relies on tools from automata theory and Markov chains, offering a theoretical framework that can be extended to other text processing algorithms and more sophisticated branch prediction strategies.
Keywords and phrases:
Pattern matching, branch prediction, transducers, average case complexity, Markov chainsCopyright and License:
2012 ACM Subject Classification:
Theory of computation Design and analysis of algorithmsEditors:
Paola Bonizzoni and Veli MäkinenSeries and Publisher:
1 Introduction
Pipelining is a fundamental technique employed in modern processors to improve performance by executing multiple instructions in parallel, rather than sequentially. Instructions execution is divided into distinct stages, enabling the simultaneous processing of multiple instructions, much like an assembly line in a factory. Today, pipelining is ubiquitous, even in low-cost processors priced under a dollar. We refer the reader to the textbook reference [6] for more details on this important architectural feature.
The sequential execution model assumes that each instruction completes before the next one begins; however, this assumption does not hold in a pipelined processor. Specific conditions, known as hazards, may prevent the next instruction in the pipeline from executing during its designated clock cycle. Hazards introduce delays that undermine the performance benefits of pipelining and may stall the pipeline, thus reducing the theoretical speedup:
-
Structural hazards occur when resource conflicts arise, preventing the hardware from supporting all possible combinations of instructions during simultaneous executions.
-
Control hazards arise from the pipelining of jumps and other instructions that modify the order in which instructions are processed, by updating the Program Counter (PC).
-
Data hazards occur when an instruction depends on the result of a previous instruction, and this dependency is exposed by the overlap of instructions in the pipeline.
To minimize stalls due to control hazards and improve execution efficiency, modern computer architectures incorporate branch predictors. A branch predictor is a digital circuit that anticipates the outcome of a branch (e.g., an if–then–else structure) before it is determined.
Two-way branching is typically implemented using a conditional jump instruction, which can either be taken, updating the Program Counter to the target address specified by the jump instruction and redirecting the execution path to a different location in memory, or not taken, allowing execution to continue sequentially. The outcome of a conditional jump remains unknown until the condition is evaluated and the instruction reaches the actual execution stage in the pipeline. Without branch prediction, the processor would be forced to wait until the conditional jump instruction reaches this stage before the next instruction can enter the first stage in the pipeline. The branch predictor aims to reduce this delay by predicting whether the conditional jump is likely to be taken or not. The instruction corresponding to the predicted branch is then fetched and speculatively executed. If the prediction is later found to be incorrect (i.e., a misprediction occurs), the speculatively executed or partially executed instructions are discarded, and the pipeline is flushed and restarted with the correct branch, incurring a small delay.
The effectiveness of a branch prediction scheme depends on both its accuracy and the frequency of conditional branches. Static branch prediction is the simplest technique, as it does not depend on the code execution history and, therefore, cannot adapt to program behavior. In contrast, dynamic branch prediction takes advantage of runtime information (specifically, branch execution history) to determine whether branches were taken or not, allowing it to make more informed predictions about future branches.
A vast body of research is dedicated to dynamic branch prediction schemes. At the highest level, branch predictors are classified into two categories: global and local. A global branch predictor does not maintain separate history records for individual conditional jumps. Instead, it relies on a shared history of all jumps, allowing it to capture their correlations and improve prediction accuracy. In contrast, a local branch predictor maintains an independent history buffer for each conditional jump, enabling predictions based solely on the behavior of that specific branch. Since the 2000s, modern processors typically employ a combination of local and global branch prediction techniques, often incorporating even more sophisticated designs. For a deeper exploration of this topic, see [10], and for a comprehensive discussion of modern computer architecture, refer to [6].
In this study, we focus on local branch predictors implemented with saturated counters. A 1-bit saturating counter (essentially a flip-flop) records the most recent branch outcome. Although this is the simplest form of dynamic branch prediction, it offers limited accuracy. A 2-bit saturating counter (see Figure 1), by contrast, operates as a state machine with four possible states: Strongly not taken (), Weakly not taken (), Weakly taken (), and Strongly taken (). When the 2-bit saturated branch predictor is in the Strongly not taken or Weakly not taken state, it predicts that the branch will not be taken and execution will proceed sequentially. Conversely, when the predictor is in the Strongly taken or Weakly taken state, it predicts that the branch will be taken, meaning execution will jump to the target address. Each time a branch is evaluated, the corresponding state machine updates its state. If the branch is not taken, the state shifts toward Strongly not taken; if taken, it moves toward Strongly taken. A misprediction (corresponding to a bold edge in Figure 1) occurs when:
-
a branch is not taken, while the predictor is in either of the Taken states ( or );
-
a branch is taken, while the predictor is in either of the Not Taken states ( or ).
This mechanism gives the 2-bit saturating counter an advantage over the simpler 1-bit scheme: a branch must deviate twice from its usual behavior (i.e. a Strongly state) before the prediction changes, reducing the likelihood of mispredictions.
This paper presents an initial theoretical investigation into the techniques and results related to the analysis of pattern matching algorithms within computational models augmented by branch prediction mechanisms. In particular, we study the classical Morris-Pratt (MP) and Knuth-Morris-Pratt (KMP) algorithms [11, 7] in such models, with a primary focus on quantifying branch mispredictions under random text inputs. Over the past two decades, research in this area has evolved from experimental studies on sorting algorithms and fundamental data structures [2] to theoretical analyses of misprediction behavior in Java’s dual-pivot Quicksort [9], as well as the design of skewed variants of classical algorithms (e.g., binary search, exponentiation by squaring) aimed at improving branch prediction efficiency [1]. These studies have largely focused on local predictors – particularly 2-bit saturating counters (see Figure 1) – which also serve as the basis for the models considered in this work.
2 Algorithms and their encoding using transducers
Throughout the article, indices start at : if is a word of length over the alphabet , we represent it as , where each is a letter of . We also use to denote the letter . If where , and are words, then is a prefix of , is a factor and is a suffix. A prefix (resp. suffix) of is strict if it differs from . For any , we denote by the prefix of of length . A (strict) border of is a word that is both a (strict) prefix and a (strict) suffix of .
Algorithms MP and KMP
The Morris-Pratt (MP) and Knuth-Morris-Pratt (KMP) algorithms are textbook solutions to the pattern matching problem [4, 5, 3]. Both rely on precomputing a failure function, which helps identify candidate positions for the pattern in the text . The general approach involves scanning from left to right, one letter at a time. Before moving to the next letter in , the algorithm determines the longest prefix of that is also a suffix of the discovered prefix of . The failure function allows this computation to be performed efficiently.
The function maps each prefix of to its longest strict border, with the convention that . The function is a refinement of defined by , , and for all prefixes of , where and , is the longest strict suffix of that is also a prefix of but such that is not. If no such strict suffix exists, then . See [5] for a more detailed discussion of these failure functions. In the following, we only require that Algorithm FIND remains correct regardless of which failure function is used. Within the algorithm, the function (or ) is transformed into a precomputed integer-valued array , defined as for , with the convention that .
Algorithm FIND utilizes the precomputed table from either or to efficiently locate potential occurrences of in . The indices and denote the current positions in and , respectively. The main while loop (Line 3) iterates once for each letter discovered in . At the start of each iteration, index holds the length of the longest matching prefix of . The inner while loop (Line 4) updates using the precomputed table . Finally, the if statement (Line 7) is triggered when an occurrence of is found, updating accordingly. For both MP and KMP, the table can be computed in time and FIND runs in time. More precisely, in the worst case, Algorithm FIND performs at most letter comparisons [4].
Note that in any programming language supporting short-circuit evaluation of Boolean operators, the condition and at Line 4 of Algorithm FIND is evaluated as two separate jumps by the compiler. As a result, Algorithm FIND contains a total of four branches: one at Line 3, two at Line 4, and one at Line 7. In our model, each of these four branches is assigned a local predictor, and all may potentially lead to mispredictions. When a conditional instruction is compiled, it results in a jump that can correspond to either a taken or a not-taken branch.111Most assembly languages provide both jump-if-true and jump-if-false instructions. For consistency, we define a successful condition – when the test evaluates to true – as always leading to a taken branch. This convention does not affect our analysis, as the predictors we consider are symmetric.
Associated automata
At the beginning of each iteration of the main while loop of Algorithm Find, the prefix of length of (i.e. from letter to letter ) has been discovered, and is the length of the longest suffix of that is a strict prefix of : we cannot have , because when it happens, the pattern is found and is directly updated to , Line 7.
The evolution of at each iteration of the main while loop is encoded by a deterministic and complete automaton . Its set of states is the set of strict prefixes of , identified by their unique lengths if necessary. Its transition function maps a pair to the longest suffix of which is in . Its initial state is . If , where is a letter, then when following the path labeled by starting from the initial state of , there is an occurrence of in exactly when the transition is used. This variant of the classical construction is more relevant for this article than the usual one [4, Sec. 7.1] which also has the state . The transition is the accepting transition to identify occurrences of . The automaton tracks the value of at the beginning of each iteration of the main loop, where corresponds to the length of the current state label. This value remains the same for both MP and KMP. An example of is depicted in Figure 2.
To refine the simulation of the Find algorithm using automata, we incorporate the failure functions. This is achieved by constructing the failure automaton. Specifically, for Algorithm MP, let be the automaton defined by:
-
A state set and an initial state .
-
Transitions for every .
-
Transitions for every such that .
-
A failure transition for every , used when attempting to read a letter where .
The automaton associated with KMP is identical to , except that its failure transitions are defined as for every . Both automata serve as graphical representations of the failure functions and , structured in a way that aligns with . An example of and is illustrated in Figure 3.
When reading a letter from a state in or , if the transition does not exist, the automaton follows failure transitions until a state with an outgoing transition labeled by is found. This process corresponds to a single backward transition in . Crucially, using a failure transition directly mirrors the execution of the nested while loop in Algorithm Find (Line 4) or triggers the if statement at Line 7 when an occurrence of is found. This construction captures what we need for the forthcoming analysis.
3 Expected number of letter comparisons for a given pattern
In this section, we refine the analysis of the expected number of letter comparisons performed by Algorithm FIND for a given pattern of length and a random text of length . The average-case complexity of classical pattern matching algorithms has been explored before, particularly in scenarios where both the pattern and the text are randomly generated. Early studies [12, 13] examined the expected number of comparisons in Algorithms MP and KMP under memoryless or Markovian source models, employing techniques from analytic combinatorics. Prior attempts based on Markov chains introduced substantial approximations, limiting their accuracy compared to more refined combinatorial methods [12, 13]. Here, we refine and extend this Markov chain-based methodology, providing a more precise foundation for analyzing the expected number of mispredictions (see Section 4).
Let be a probability measure on such that for all , (we also use the notation in formulas when convenient). For each and each , we define . For any , the measure is a probability on , where all letters are chosen independently following . We obtain the uniform distribution on if is the uniform distribution on , with for all .
Encoding the letter comparisons with transducers
Letter comparisons occur at Line 4 only if , due to the lazy evaluation of the and operator (when , is not compared to ). We can encode these comparisons within the automata of Section 2 by adding outputs to the transitions, thereby transforming them into transducers. In both and , each transition corresponds to matching letters, meaning the test evaluates to false. We denote this with the letter for a not taken branch. Conversely, following a failure transition indicates that the test is true, which we denote by for taken. Transitions from correspond to cases where is false, meaning no letter comparisons occur, as noted above. This construction is illustrated in Figure 4.
We keep track of the results of the comparisons in by simulating the reading of each letter in the transducer associated with and concatenating the outputs. This transforms into the transducer for MP, by adding an output function to as follows (see Figure 5 for an example).
| (1) |
Instead of we can use the output defined as except that mp is changed into kmp. This yields the transducer associated with KMP.
Recall that the output of a path in a transducer is the concatenation of the outputs of its transitions. As the transducers and are (input-)deterministic and complete, the output of a word is the output of its unique path that starts at the initial state. From the classical link between and Algorithm FIND [4] we have the following key statement.
Lemma 1.
The sequence of results of the comparisons when applying Algorithm Find to the pattern and text is equal to the output of the word in the transducer for Algorithm MP, and in the transducer for KMP.
State probability and expected number of comparisons
Since we can use exactly the same techniques, from now on we focus on KMP for the presentation. Recall that if we reach the state after reading the first letters of in , and hence in , then at the next iteration of the main while loop, index contains the value . For and , we are thus interested in the probability that after reading in we end in a state . Slightly abusing notation, we write . For any let denote the longest strict border of , with the convention that .
Lemma 2.
For any and any , does not depend on and we have with .
From Lemma 2 we can easily estimate the expected number of comparisons for any fixed pattern , when the length of tends to infinity. Indeed, except when , the probability does not depends on . Moreover, if we are in state , from the length of the outputs of we can directly compute the expected number of comparisons during the next iteration of the main while loop. See Figure 6 for a graphical representation.
Proposition 3.
As , the expected number of letter comparisons performed by Algorithm FIND with KMP (or MP with ) is asymptotically equivalent to , where
Observe that Lemma 2 can also be derived by transforming into a Markov chain and computing its stationary distribution [8]. However, Lemma 2 provides a more direct and simpler formula, which appears to have gone unnoticed in the literature. Markov chains will prove very useful in Section 4.2.
4 Expected number of mispredictions
We now turn to our main objective: a theoretical analysis of the number of mispredictions for a fixed pattern and a random text . The analysis depends on the type of predictor used (see Section 1). In what follows, all results are stated for local 2-bit saturated counters, such as the one in Figure 1. Let denote its transition function extended to binary words. For example, . Additionally, let denote the number of mispredictions encountered when following the path in the predictor starting from state and labeled by . For instance, .
As previously noted, Algorithm FIND contains four branches in total: one at Line 3, two at Line 4, and one at Line 7. Each of these branches is assigned a local predictor, and all have the potential to generate mispredictions. The mispredictions generated by the main while loop (i.e. Line 3) are easily analyzed. Indeed, the test holds true for times and then becomes false. Hence, the sequence of taken/not taken outcomes for this branch is . Therefore, starting from any state of the 2-bit saturated predictor, at most three mispredictions can occur. It is asymptotically negligible, as we will demonstrate that the other branches produce a linear number of mispredictions on average.
4.1 Mispredictions of the counter update
We analyze the expected number of mispredictions induced by the counter update at Line 7. The sequence of taken/not-taken outcomes for this if statement is defined by if and only if ends with the pattern , for all . This is easy to analyze, especially when the pattern is not the repetition of a single letter. Proposition 4 establishes that, on average, there is approximately one misprediction for each occurrence of the pattern in the text.
Proposition 4.
If contains at least two distinct letters, then the expected number of mispredictions caused by the counter update is asymptotically equivalent to .
Proof (sketch).
Since contains at least two distinct letters, it cannot be a suffix of both and . Hence, the sequence is of the form . This means that every step to the right in the local predictor (for every in sequence ), which corresponds to a match, is followed by a step to the left, except possibly for the last step. Thus, if the local predictor reaches state , it remains in or forever. Having three consecutive positions in without an occurrence of is sufficient to reach state . This happens in fewer than iterations with high probability, and at this point there is exactly one misprediction each time the pattern is found. This concludes the proof, as the expected number of occurrences of in is asymptotically equivalent to .
The analysis of the case , where consists of a repeated single letter, is more intricate. We first present the proof sketch for , which captures all the essential ideas. Let and write , where with and . Depending on the value of , one can compute the sequence of taken/not taken outcomes induced by a factor , which is either preceded by a letter or nothing: yields , yields , yields , and so on. Thus, more generally, yields and yields for . We then examine the state of the predictor and the number of mispredictions produced after each factor is read. For instance, if just before reading the predictor state is , then the associated sequence produces three mispredictions and the predictor ends in the same state , which can be seen on the path . Since cannot be reached except at the very beginning or at the very end, it has a negligible contribution to the expectation, and we can list all the relevant possibilities as follows:
In the table above, the states and produce identical outcomes and can therefore be merged into a single state, denoted as , for the analysis. The resulting transitions form a graph with two vertices, which is then converted into a Markov chain by incorporating the transition probabilities , as illustrated in Figure 7.
The stationary distribution of this Markov chain is straightforward to compute, yielding and , where . From each state, the expected number of mispredictions can be computed using the transition table. For instance, starting from , a misprediction occurs when with probability , and three mispredictions occur when with probability . Therefore, the expected number of mispredictions when reading the next factor from is given by . Finally, with high probability there are around factors of the form in the decomposition of , which corresponds to roughly the same number of steps in the Markov chain. The general statement for is as follows.
Proposition 5.
If , the expected number of mispredictions caused by the counter update is asymptotically , with for , and
4.2 Expected number of mispredictions during letter comparisons
In this section, we analyze the expected number of mispredictions caused by letter comparisons in KMP (similar results can be derived for MP).
According to Lemma 1, the outcome of letter comparisons in KMP is encoded by the transducer . More precisely, following a transition in this transducer simulates a single iteration of the main loop of Algorithm FIND, starting with and processing the letter . At the end of this iteration, , and is the sequence of taken/not-taken outcomes for the test .
The mispredictions occurring during this single iteration of the main loop depend on the predictor’s initial state and the sequence which is computed using . The number of mispredictions is retrieved by following the path starting from state and labeled by in the predictor, corresponding to the transition . This is formalized by using a coupling of with the predictor in Figure 1, forming a product transducer , defined as follows (see Figure 8 for an example):
-
the set of states is ,
-
there is a transition for every state and every letter , where is the output of the transition in .
By construction, at the beginning of an iteration of the main loop in Algorithm FIND, if , is the initial state of the 2-bit saturated predictor, and , then, during the next iteration, mispredictions occur, and the predictor terminates in state , where in . This leads to the following statement.
Lemma 6.
The number of mispredictions caused by letter comparisons in KMP, when applied to the text and the pattern , is given by the sum of the outputs along the path that starts at and is labeled by in , where is the initial state of the local predictor associated with the letter comparison.
We can then proceed as in Proposition 5: the transducer is converted into a Markov chain by assigning a weight of to the transitions labeled by a letter . From this, we compute the stationary distribution over the set of states, allowing us to determine the asymptotic expected number of mispredictions per letter of . This quantity, , satisfies
| (2) |
Observe that when processing a long sequence of letters different from , the letter comparisons produce a sequence of ’s, causing the 2-bit saturated predictor to settle in state while in the algorithm. Consequently, the state is reachable from every other state. Hence, the Markov chain has a unique terminal strongly connected component (i.e. there are no transitions from any vertex in this strongly connected component to any vertex outside of it), which includes along with a self-loop at this state. Thus, our analysis focuses on this component, allowing us to apply classical results on primitive Markov chains [8], ultimately leading to Equation (2). Notably, this result is independent of the predictor’s initial state. The computation of can be easily carried out using computer algebra, since computing the stationary probability reduces to inverting a matrix.
Proposition 7.
The expected number of mispredictions caused by letter comparisons in KMP on a random text of length and a pattern , is asymptotically equivalent to .
4.3 Expected number of mispredictions of the test
We conclude the analysis by examining the mispredictions caused by the test at Line 4 of Algorithm FIND. To this end, we use the previously constructed transducer (or equivalently , as the approach remains the same) to capture the behavior of this test through a straightforward transformation of the outputs. Recall that a transition in , with indicates that when reading the letter , the inner while loop performs character comparisons, with the result encoded by the symbols of . Due to the loop structure, always takes one of two forms:
-
and the loop terminates because eventually, or
-
and the loop terminates because eventually.
In the first case, the condition holds for iterations. In the second case, the condition holds for iterations before failing once. Thus, we define the transducer identically to , except for its output function:
| (3) |
The same transformation can be applied to for MP. At this stage, we could directly reuse the framework from Section 4.2 to compute the asymptotic expected number of mispredictions for any given pattern . However, a shortcut allows for a simpler formulation while offering deeper insight into the mispredictions caused by the test .
Since each output is either for some or , the local predictor state generally moves toward , except in the case of . In this latter case, the predictor either remains in the same state or transitions from to . Moreover, from any state of , there always exists a letter such that in or (for instance, the transition that goes to the right or when the pattern is found). As a result, with high probability, the predictor reaches the state in at most iterations of the main loop of Algorithm FIND. Once in , the predictor remains confined to the states and indefinitely. Thus, with high probability, except for a small number of initial steps, the predictor consistently predicts that the branch is taken. At this point, a misprediction occurs if and only if the output belongs to , which happens precisely when a non-accepting transition in leads to the state . Since and differ only in their output functions, this result holds for both MP and KMP, allowing us to work directly with . Applying Lemma 2, we obtain the following statement.
Proposition 8.
When Algorithms MP or KMP are applied to a random text of length with a given pattern , the expected number of mispredictions caused by the test is equal to the expected number of times a transition ending in is taken along the path labeled by in , up to an error term of . As a result, the expected number of such mispredictions is asymptotically equivalent to , where .
5 Results for small patterns, discussion and perspectives
| X | i = m | i >= 0 | Algo. | X[i] != T[j] |
|---|---|---|---|---|
| aa | MP | |||
| KMP | ||||
| ab | both | |||
| aaa | MP | |||
| KMP | ||||
| aab | MP | |||
| KMP | ||||
| aba | MP | |||
| KMP | ||||
| abb | both |
We conducted a comprehensive study of local branch prediction for MP and KMP and provide the code222Python notebook (using sympy), available at https://github.com/vialette/branch-prediction/ that allows to quantify mispredictions for any alphabet size, any given pattern and any memoryless source for the input text (as for the examples given in Table 1).
Notably, the expressions for the number of mispredicted letter comparisons become increasingly complex as the pattern length grows and as the alphabet size increases. For instance, for the pattern , with and , we obtain:
The results given in Table 2 illustrate this for the uniform distribution, for small patterns and alphabets. In particular, the branch , which is poorly predicted by its local predictor, exhibits a very high number of mispredictions when , while the branch that comes from letter comparisons, , experiences fewer mispredictions. This trend becomes more pronounced as the size of the alphabet increases: for and , the misprediction rate for the test reaches 0.96, whereas for , it drops to 0.041.
Our work presents an initial theoretical exploration of pattern matching algorithms within computational models enhanced by local branch prediction. However, modern processors often employ hybrid prediction mechanisms that integrate both local and global predictors, with global predictors capturing correlations between branch outcomes across different execution contexts – in our simulations with PAPI333https://icl.utk.edu/papi/ on a personal computer, the actual number of mispredictions is roughly divided by in practice. A key direction for further research is to develop a theoretical model that incorporates both predictors, allowing for more precise measurement in real-world scenarios. Another important line of research is to account for enhanced probabilistic distributions for texts, as real-word texts are often badly modeled by memoryless sources. For instance, Markovian sources should be manageable within our model and could provide a more accurate framework for the analysis.
| X | i=m | i>=0 | algo | X[i]!=T[j] | Total | i=m | i>=0 | algo | X[i]!=T[j] | Total |
| aa | 0.283 | 0.5 | MP | 0.571 | 1.353 | 0.073 | 0.75 | MP | 0.295 | 1.117 |
| KMP | 0.5 | 1.283 | KMP | 0.3 | 1.123 | |||||
| ab | 0.25 | 0.25 | both | 0.571 | 1.321 | 0.062 | 0.688 | both | 0.375 | 1.186 |
| aaa | 0.14 | 0.5 | MP | 0.563 | 1.202 | 0.018 | 0.75 | MP | 0.293 | 1.06 |
| KMP | 0.5 | 1.14 | kmp | 0.3 | 1.068 | |||||
| aab | 0.125 | 0.375 | MP | 0.605 | 1.23 | 0.015 | 0.734 | MP | 0.322 | 1.086 |
| KMP | 0.542 | 1.166 | KMP | 0.322 | 1.086 | |||||
| aba | 0.125 | 0.25 | MP | 0.708 | 1.083 | 0.015 | 0.688 | MP | 0.367 | 1.068 |
| KMP | 0.571 | 0.946 | KMP | 0.375 | 1.076 | |||||
| abb | 0.125 | 0.125 | both | 0.547 | 0.921 | 0.015 | 0.672 | both | 0.397 | 1.098 |
References
- [1] Nicolas Auger, Cyril Nicaud, and Carine Pivoteau. Good predictions are worth a few comparisons. In Nicolas Ollinger and Heribert Vollmer, editors, 33rd Symposium on Theoretical Aspects of Computer Science, STACS 2016, February 17-20, 2016, Orléans, France, volume 47 of LIPIcs, pages 12:1–12:14. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2016. doi:10.4230/LIPICS.STACS.2016.12.
- [2] Gerth Stølting Brodal and Gabriel Moruz. Tradeoffs between branch mispredictions and comparisons for sorting algorithms. In Frank K. H. A. Dehne, Alejandro López-Ortiz, and Jörg-Rüdiger Sack, editors, Algorithms and Data Structures, 9th International Workshop, WADS 2005, Waterloo, Canada, August 15-17, 2005, Proceedings, volume 3608 of Lecture Notes in Computer Science, pages 385–395. Springer, 2005. doi:10.1007/11534273_34.
- [3] Maxime Crochemore, Christophe Hancart, and Thierry Lecroq. Algorithms on strings. Cambridge University Press, 2007.
- [4] Maxime Crochemore and Wojciech Rytter. Text Algorithms. Oxford University Press, 1994.
- [5] Dan Gusfield. Algorithms on Strings, Trees, and Sequences - Computer Science and Computational Biology. Cambridge University Press, 1997. doi:10.1017/CBO9780511574931.
- [6] John L. Hennessy and David A. Patterson. Computer Architecture, Sixth Edition: A Quantitative Approach. Morgan Kaufmann Publishers Inc., 6th edition, 2017.
- [7] Donald E. Knuth, James H. Morris Jr., and Vaughan R. Pratt. Fast pattern matching in strings. SIAM J. Comput., 6(2):323–350, 1977. doi:10.1137/0206024.
- [8] David A. Levin, Yuval Peres, and Elizabeth L. Wilmer. Markov Chains and Mixing Times. American Mathematical Society, 2008.
- [9] Conrado Martínez, Markus E. Nebel, and Sebastian Wild. Analysis of branch misses in quicksort. In Proceedings of the Twelfth Workshop on Analytic Algorithmics and Combinatorics, ANALCO 2015, San Diego, CA, USA, January 4, 2015, pages 114–128, 2015. doi:10.1137/1.9781611973761.11.
- [10] Sparsh Mittal. A survey of techniques for dynamic branch prediction. Concurrency and Computation: Practice and Experience, 31, 2018.
- [11] James H Morris, Jr and Vaughan R Pratt. A Linear Pattern-Matching Algorithm. Technical report, University of California, Berkeley, CA, January 1970.
- [12] Mireille Régnier. Knuth-morris-pratt algorithm: An analysis. In Antoni Kreczmar and Grazyna Mirkowska, editors, Mathematical Foundations of Computer Science 1989, MFCS’89, Porabka-Kozubnik, Poland, August 28 - September 1, 1989, Proceedings, volume 379 of Lecture Notes in Computer Science, pages 431–444. Springer, 1989. doi:10.1007/3-540-51486-4_90.
- [13] Mireille Régnier and Wojciech Szpankowski. Complexity of sequential pattern matching algorithms. In Michael Luby, José D. P. Rolim, and Maria J. Serna, editors, Randomization and Approximation Techniques in Computer Science, Second International Workshop, RANDOM’98, Barcelona, Spain, October 8-10, 1998, Proceedings, volume 1518 of Lecture Notes in Computer Science, pages 187–199. Springer, 1998. doi:10.1007/3-540-49543-6_16.
6 Appendix
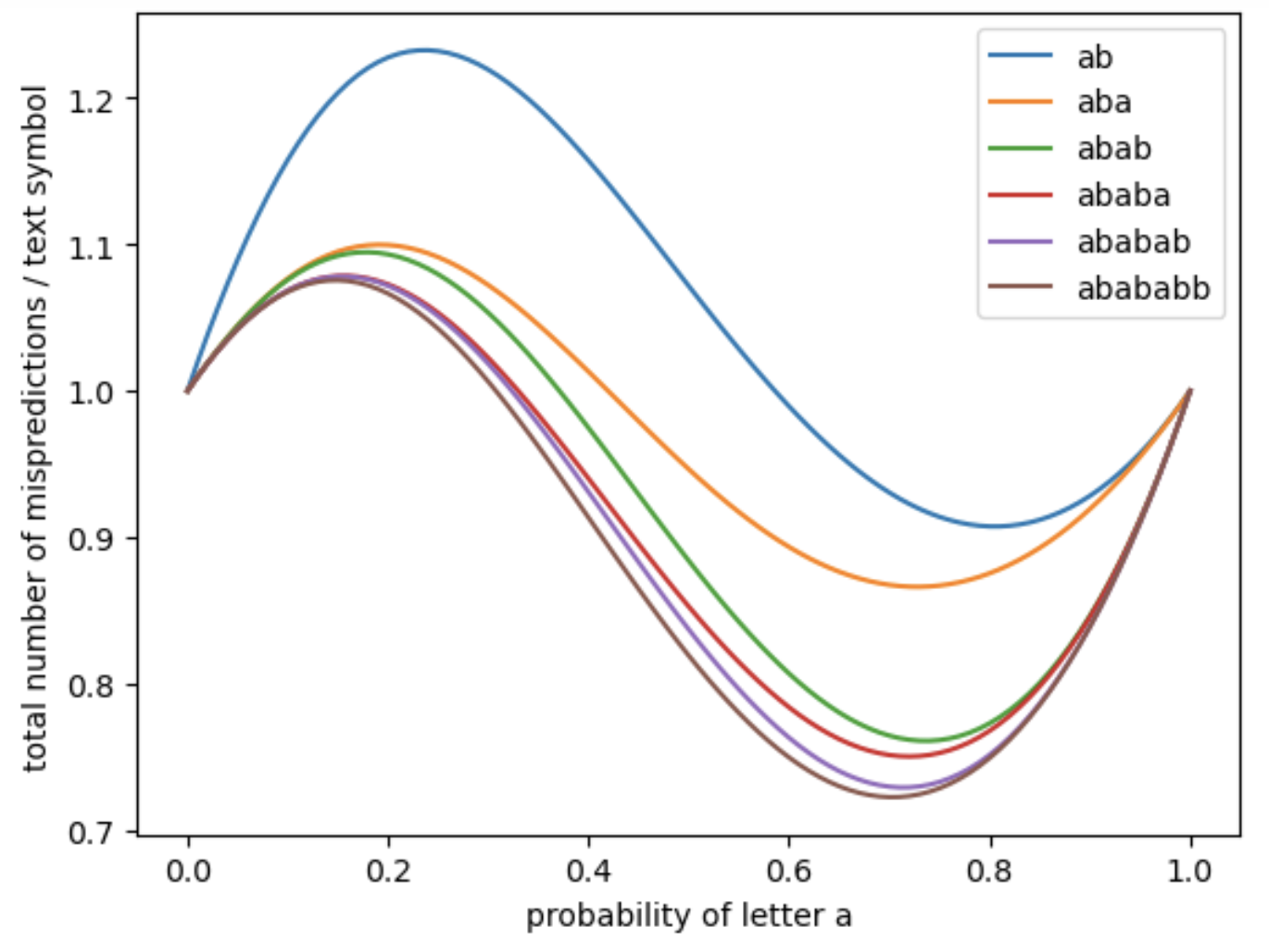
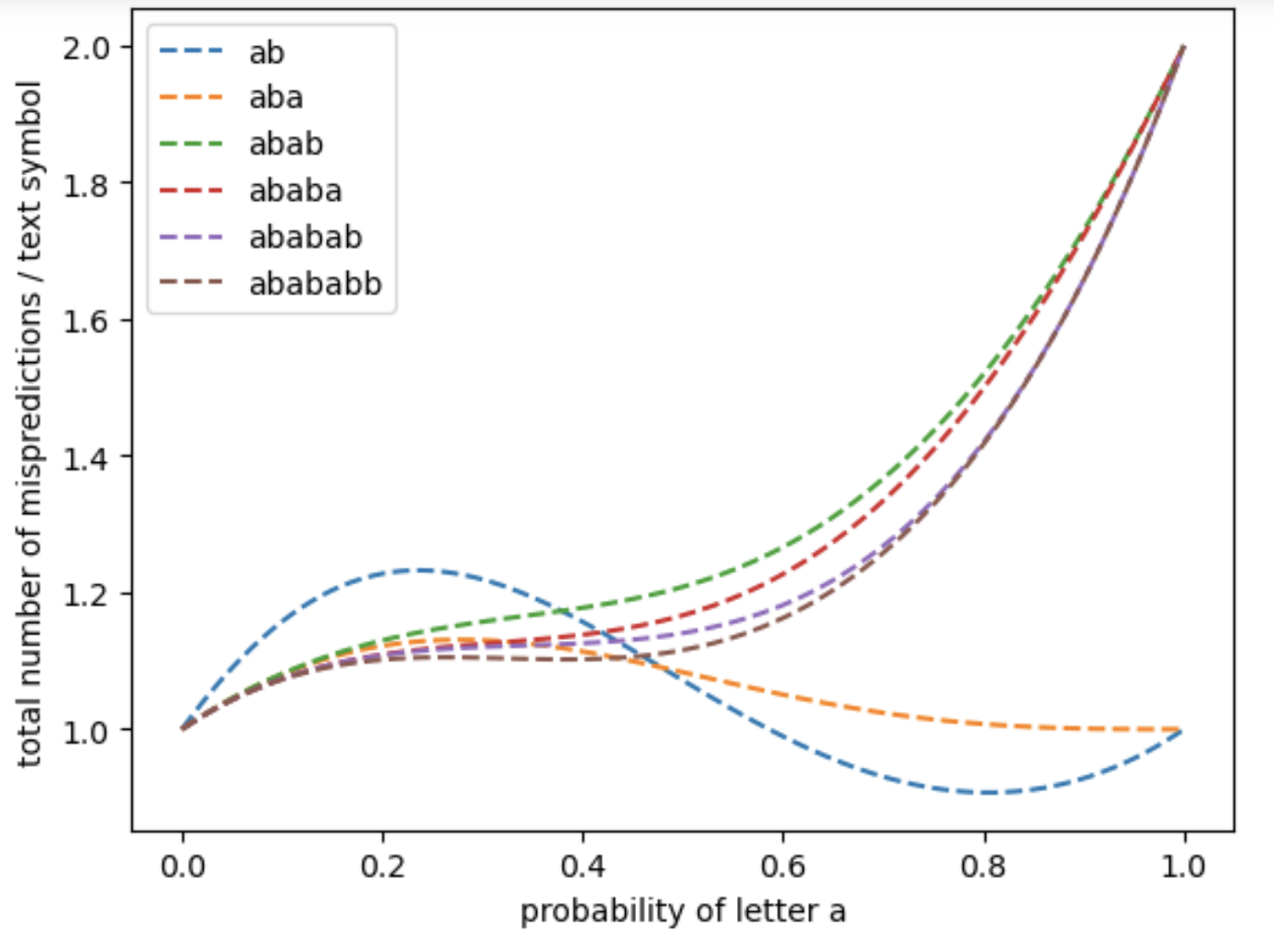
In the first series of four figures (Figure 9, Figure 10, Figure 11 and Figure 12), we apply the analytical formulas developed in the article to compute the expected number of mispredictions for each branch, as well as the total number of mispredictions across the entire matching process. These computations are performed as a function of the character probability , which varies in the interval under the assumption of an i.i.d. binary text model over the alphabet . Each figure corresponds to a different pattern: , , , and . Each plot was computed in under a few seconds on a personal laptop.
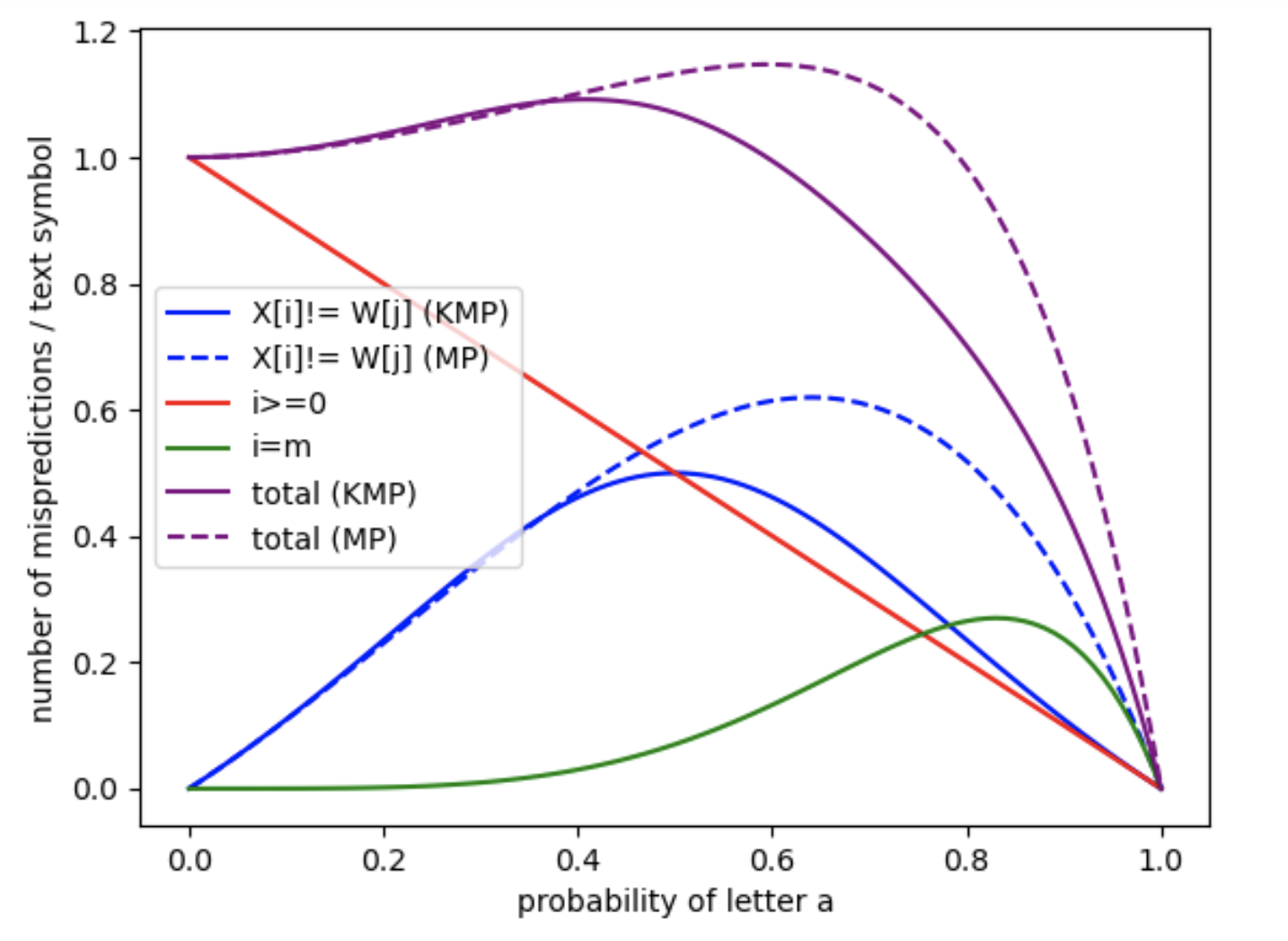
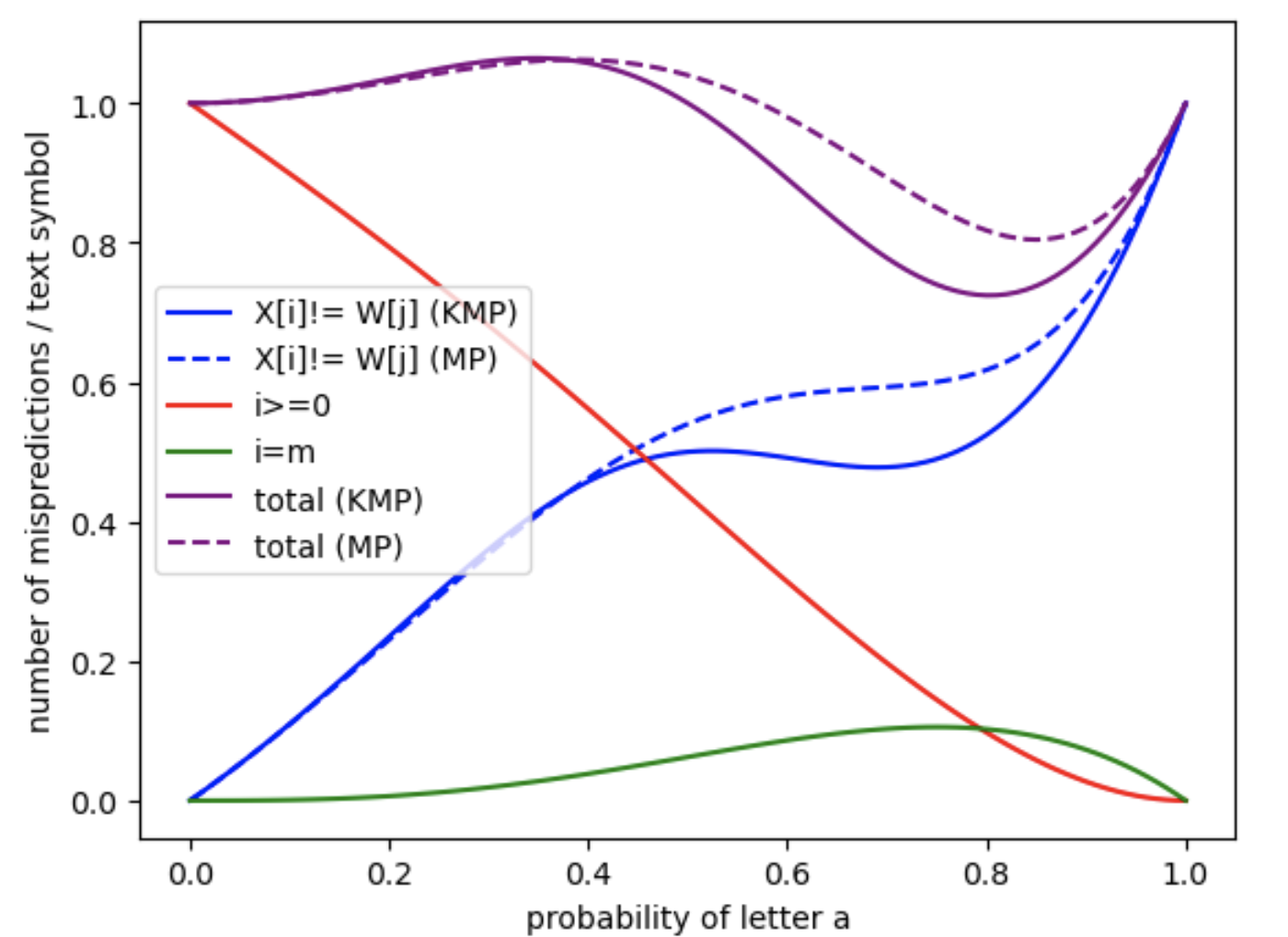
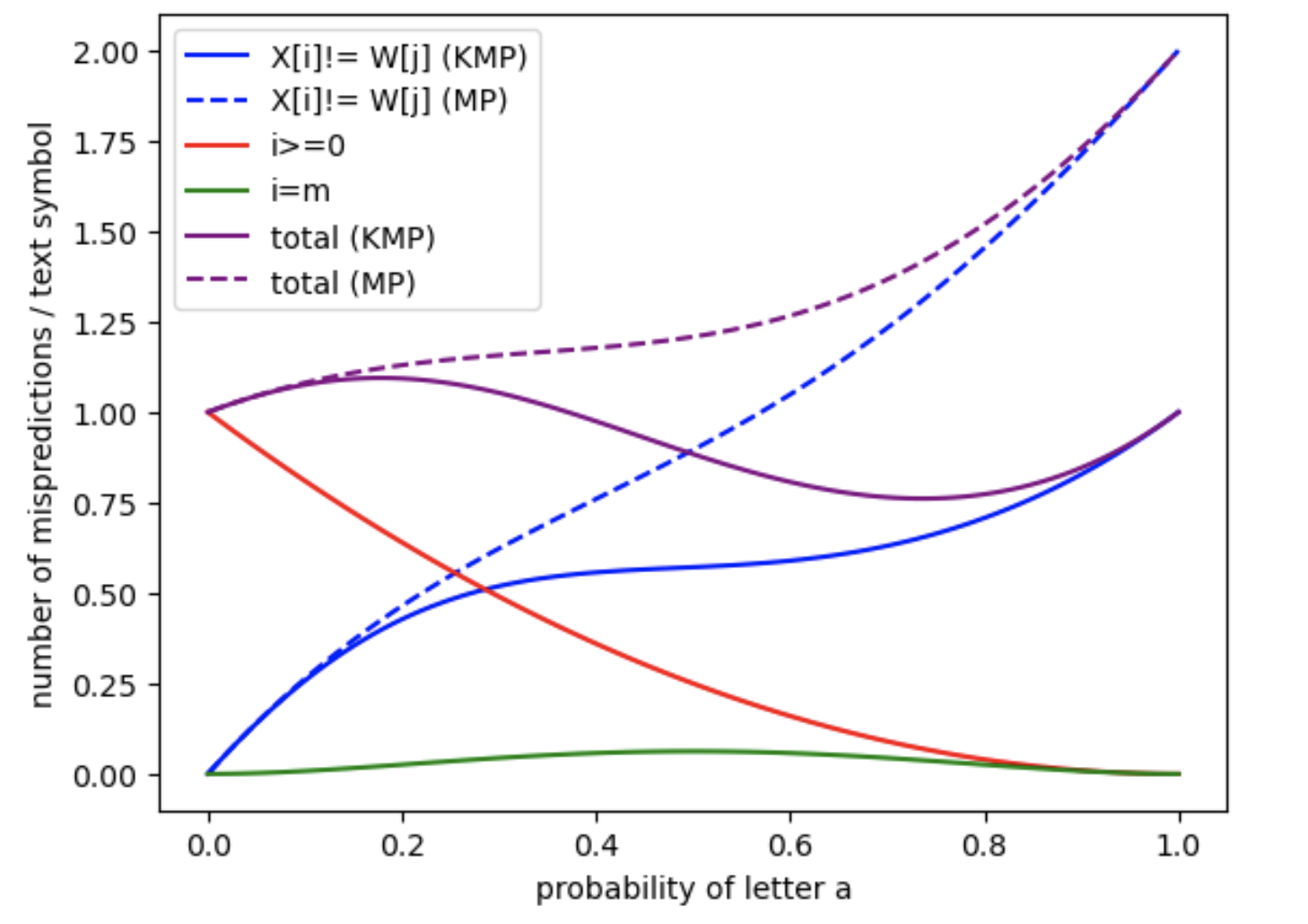
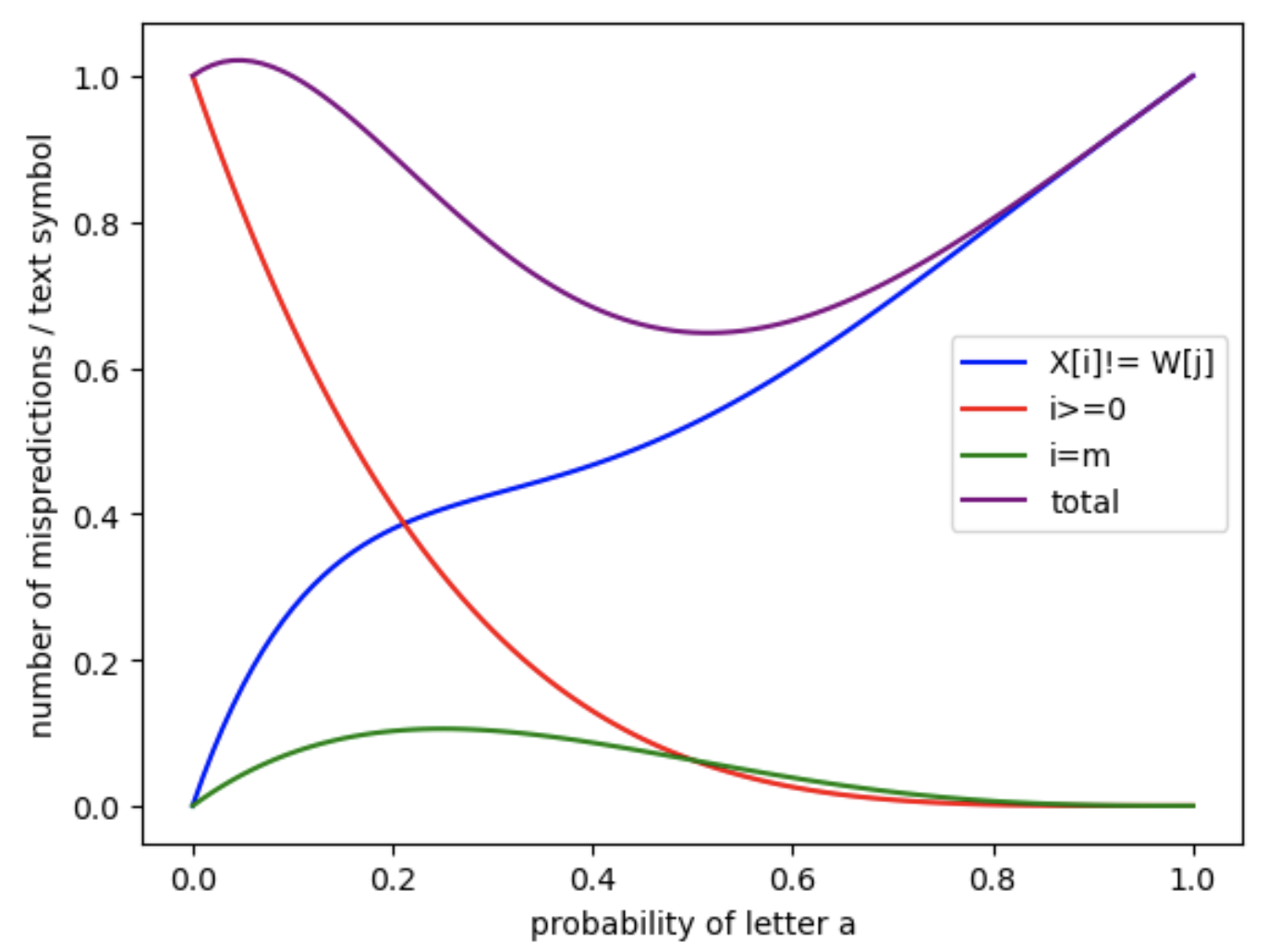
In the last two figures (Figure 13 and Figure 14), we focus on a more detailed case study. We consider all non-trivial prefixes (i.e., of length at least ) of the pattern , and for each prefix, we compute the expected number of mispredictions per text symbol as the text length tends to infinity. This is done for both the MP and the KMP algorithms. The results suggest a form of convergence as the length of the prefix increases. This is consistent with theoretical expectations, as longer prefixes imply that deeper states of the automaton become increasingly less likely to be reached in practice.