New and Improved Bounds for Markov Paging

Abstract
In the Markov paging model, one assumes that page requests are drawn from a Markov chain over the pages in memory, and the goal is to maintain a fast cache that suffers few page faults in expectation. While computing the optimal online algorithm for this problem naively takes time exponential in the size of the cache, the best-known polynomial-time approximation algorithm is the dominating distribution algorithm due to Lund, Phillips and Reingold (FOCS 1994), who showed that the algorithm is -competitive against . We substantially improve their analysis and show that the dominating distribution algorithm is in fact -competitive against . We also show a lower bound of -competitiveness for this algorithm – to the best of our knowledge, no such lower bound was previously known.
Keywords and phrases:
Beyond Worst-case Analyis, Online Paging, Markov PagingCategory:
Track A: Algorithms, Complexity and GamesFunding:
Chirag Pabbaraju: Supported by Moses Charikar and Gregory Valiant’s Simons Investigator Awards.Copyright and License:
2012 ACM Subject Classification:
Theory of computation Online algorithms ; Theory of computation Approximation algorithms analysisAcknowledgements:
The authors would like to thank Avrim Blum for helpful pointers.Editors:
Keren Censor-Hillel, Fabrizio Grandoni, Joël Ouaknine, and Gabriele PuppisSeries and Publisher:
1 Introduction
The online paging problem is a fundamental problem in online algorithms. There are pages in slow memory, and requests for these pages arrive sequentially. We are allowed to maintain a fast cache of size , which initially comprises of some pages. At time step , if the page requested, say , exists in the cache, a cache hit occurs: we suffer no cost, the cache stays as is, and we move to the next request. Otherwise, we incur a cache miss/page fault, suffer a unit cost, and have to evict some page from the cache so as to bring from memory into the cache. A paging algorithm/policy is then specified by how it chooses the page to evict whenever it suffers a cache miss.
An optimal offline algorithm for this problem is the algorithm that has entire knowledge of the page request sequence, and makes its eviction choices in a way that minimizes the total number of cache misses it incurs. The classical Farthest-in-Future algorithm [3], which at any cache miss, evicts the page that is next requested latest in the remainder of the sequence, is known to be an optimal offline policy. In the spirit of competitive analysis as introduced by [22], one way to benchmark any online algorithm (i.e., one which does not have knowledge of the page request sequence) is to compute the ratio of the number of page faults that the algorithm suffers, to the number of page faults that the optimal offline algorithm suffers, on a worst-case sequence of page requests. It is known that any deterministic online algorithm has a worst-case ratio that is at least , while any randomized online algorithm has a worst-case ratio of .
Taking a slightly more optimistic view, one can also consider benchmarking an algorithm against the best online algorithm, that does not know beforehand the realized sequence of page requests. Additionally, in the context of beyond worst-case analysis, one can impose assumptions on the sequence of page requests to more accurately model the behavioral characteristics of real-world page requests on computers. For example, page requests generally follow the locality of reference principle, either in time (the next time a particular page is requested is close to its previous time) or in space (the page that will be requested next is likely to be in a nearby memory location).
The Markov Paging model, introduced by [14], is one of the ways to model locality of reference in the page requests. The model assumes that page requests are drawn from a (known) Markov chain over the pages. With this distributional assumption, one can ask how an online paging algorithm fares, in comparison to the optimal online algorithm that suffers the smallest number of page misses in expectation over the draw of a page sequence from the distribution. Indeed, one can compute an optimal online algorithm, but only in time exponential in the cache size . Therefore, one seeks efficient polynomial-time algorithms that are approximately optimal.
In 1994, [16] proposed an elegant randomized algorithm for the Markov Paging problem, known as the dominating distribution algorithm. The dominating distribution algorithm, whenever it suffers a cache miss, evicts a random page drawn from a special distribution, which has the property that a randomly drawn page is likely to be next requested latest among all the existing pages in the cache. This algorithm, which has since become a popular textbook algorithm due to its simplicity (e.g., see Chapter 5 in [4], or the lecture notes by [21]), runs in time polynomial in ; furthermore, [16] show that the algorithm suffers only 4 times more cache misses in expectation than the optimal online algorithm. Since then, this has remained state-of-the-art – we do not know any other polynomial-time algorithms that achieve a better performance guarantee. It has nevertheless been conjectured that the above guarantee for the dominating distribution algorithm is suboptimal (e.g., see Section 6.2 in [21]).
Our main result improves this bound for the dominating distribution algorithm.
Theorem 1.
The dominating distribution algorithm suffers at most 2 times more cache misses in expectation compared to the optimal online algorithm in the Markov Paging model.
In fact, as mentioned in [16], our guarantee for the performance of the dominating distribution algorithm holds more generally for pairwise-predictive distributions. These are distributions for which one can compute any time, for any pair of pages and in the cache, the probability that is next requested before in the future (conditioned on the most recent request).
While the dominating distribution algorithm is a randomized algorithm, [16] also propose a simple deterministic algorithm for the Markov Paging model, known as the median algorithm. On any cache miss, the median algorithm evicts the page in cache that has the largest median time at which it is requested next. [16] show that the median algorithm suffers at most 5 times more cache misses in expectation than the optimal online algorithm – to the best of our knowledge, this is the state of the art for deterministic algorithms. As a convenient consequence of our improved analysis, we can also improve this guarantee for the median algorithm.
Theorem 2.
The median algorithm suffers at most 4 times more cache misses in expectation compared to the optimal online algorithm in the Markov Paging model.
Given the improved performance guarantee in Theorem 1, one can ask: is this the best bound achievable for the dominating distribution algorithm? Or can we show that it is the optimal online algorithm? A detail here is that the dominating distribution algorithm is defined as any algorithm satisfying a specific property (see (3)); in particular, there can exist different dominating distribution algorithms. Our upper bound (Theorem 1) holds uniformly for all dominating distribution algorithms. Our next theorem shows a lower bound that at least one of these is suboptimal.
Theorem 3.
There exists a dominating distribution algorithm that suffers at least times more cache misses in expectation compared to the optimal online algorithm in Markov Paging.
Theorem 3 shows that one cannot hope to show optimality uniformly for all dominating distribution algorithms. To the best of our knowledge, no such lower bounds for the dominating distribution algorithm have been previously shown. While we believe that the bound in Theorem 1 is the correct bound, it would be interesting to close the gap between the upper and lower bound.
Finally, we also consider a setting where the algorithm does not exactly know the Markov chain generating the requests, but only has access to a dataset of past requests. In this case, one can use standard estimators from the literature to approximate the transition matrix of the Markov chain from the dataset. But can an approximate estimate of the transition matrix translate to a tight competitive ratio for a paging algorithm, and if so, how large of a dataset does it require? The robustness of the analysis111In fact, we borrow this robustness from the original analysis of [16]. of Theorem 1 lends a precise learning-theoretic result (Theorem 17 in Section 7) showing that the dominating distribution algorithm, when trained on a dataset of size , is no more than times worse than the optimal online algorithm on a fresh sequence.
This result is especially relevant in the context of data-driven and learning-augmented algorithms. For instance, by treating the learned Markov chain as a learned oracle and combining it with a worst-case approach, such as the Marker algorithm, similarly to the approach proposed in [19, 18], the resulting algorithm achieves -consistency and -robustness guarantees for the online paging problem.
| Algorithm | Reference | Upper Bound | Lower Bound |
|---|---|---|---|
| [16] | 4 | - | |
| Dominating Distribution | (Theorem 3.5) | ||
| (Randomized) | This Work | 2 | 1.5907 |
| (Theorem 1) | (Theorem 3) | ||
| [16] | 5 | 1.511222[16] only provide a proof for a lower bound of 1.4, but mention that they also obtained 1.511. | |
| Median | (Theorem 2.4) | (Theorem 5.4) | |
| (Deterministic) | This Work | 4 | - |
| (Theorem 2) |
1.1 Other Related Work
There is a rich literature by this point on studying the online paging problem under assumptions on the permissible page requests that are supposed to model real-world scenarios (see e.g., the excellent surveys by [12] and [7]). In particular, several models are motivated by the aforementioned locality of reference principle. The access graph model, proposed originally by [5], and developed further in the works of [13], [8] and [9], assumes an underlying graph on the pages, which a request sequence is supposed to abide by. Namely, if a page has been requested at time , then only the neighbors of in the graph may be requested at time . In this sense, the Markov Paging model can be thought of as a probabilistic variant of the access graph model. [23] models locality of reference based on the “working sets” concept, introduced by [6], and also shows how a finite lookahead of the page sequence can be used to obtain improved guarantees. A related form of competitive analysis, proposed by [15], assumes that there is a family of valid distributions, and page sequences are drawn from some distribution belonging to this family. The goal is to be simultaneously competitive with the optimal algorithm for every distribution in the family. A particular family of interest suggested by [15] (which is incomparable to the Markov Paging model) is that of diffuse adversaries, which has since been developed further in follow-up works by [25, 26] and [2]. Finally, [1] study paging under the bijective analysis framework, which compares algorithms under bijections on page request sequences.
2 Background and Setup
2.1 Markov Paging
The Markov Paging model assumes that the page requests are drawn from a time-homogeneous Markov chain, whose state space is the set of all pages. More precisely, the Markov Paging model is specified by an initial distribution on the pages, and a transition matrix , where specifies the probability that page is requested next, conditioned on the most recently requested page being . The form of the initial distribution will not be too important for our purposes, but for concreteness, we can assume it to be the uniform distribution on the pages. It is typically assumed that the transition matrix is completely known to the paging algorithm/page eviction policy – however, the realized page sequence is not. Upon drawing page requests from the Markov chain, the objective function that a page eviction policy seeks to minimize is:
| (1) |
where the expectation is with respect to both the random page request sequence drawn from , and the randomness in the policy . We denote by the policy that minimizes the objective in (1). For , an eviction policy is said to -competitive against if for every , .
It is worth emphasizing that the competitive analysis above is with respect to the optimal online strategy, in that does not know beforehand the realized sequence of requests. As mentioned previously, the Farthest-in-Future policy [3] is known to be an optimal offline policy.
It is indeed possible to compute exactly – however, the best known ways do this are computationally very expensive, requiring an exponential amount of computation in .
Theorem 4 (Theorems 1, 2 in [14]).
The optimal online policy that minimizes over all policies can be computed exactly by solving a linear program in variables. Furthermore, for any finite , an optimal online policy that minimizes can be computed in time .
Unfortunately, we do not know of any better algorithms that are both optimal and run in polynomial time in . Therefore, one seeks efficient polynomial time (in ) algorithms that are approximately optimal, i.e., achieve -competitiveness with for as close to as possible.
Towards this, [14] showed that several intuitive eviction policies are at least an factor suboptimal compared to . They then showed a policy that is provably -competitive against ; however, the constant in the is somewhat large. Thereafter, [17]333We reference the journal version [17] in lieu of the conference version [16] hereafter. proposed an elegant polynomial-time policy, referred to as the dominating distribution algorithm, and showed that it is -competitive against . We describe this policy ahead.
2.2 Dominating Distribution Algorithm
The dominating distribution algorithm, proposed by [17] and denoted hereon, operates as follows. At any page request, if suffers a cache miss, it computes a so-called dominating distribution over the currently-existing pages in the cache. Thereafter, it draws a page , and evicts . First, we will specify the properties of this dominating distribution.
Intuitively, we want to be a distribution such that a typical page drawn from will be highly likely to be next requested later than every other page in the cache. Formally, suppose that the most recently requested page (that caused a cache miss) is . Fix any two pages and and let
| (2) |
and let for all pages . Here, the probability is only over the draw of page requests from the Markov chain. It is possible to compute values for all pairs in cache by solving linear systems (i.e., in time ), provided that we know the transition matrix (see Appendix A). For notational convenience, we will hereafter frequently denote simply by , implicitly assuming conditioning on the most frequently requested page.
Equipped with all these values, let us define to be a distribution over the pages in the cache satisfying the following property: for every fixed page in the cache,
| (3) |
This is the required dominating distribution. A somewhat surprising fact here is that such a dominating distribution provably always exists, and furthermore can be constructed efficiently by solving a linear program with just variables (i.e., in time).
Theorem 5 (Theorem 3.4 in [17]).
A distribution satisfying the condition in (3) necessarily exists and can be computed by solving a linear program in variables.
Thus, the total computation required by at each cache miss is only (to solve the linear program that constructs ), assuming all values are precomputed initially. In summary, the overall computation cost of across page requests is at most .
It remains to argue that if evicts on a cache miss, it compares well with . The following claim, whose proof follows from the definition of , will be useful.
Claim 6.
Let be the most recently requested page. The dominating distribution satisfies the following property: for every fixed page in the cache, we have that
| (4) |
Using this property of , [17] show that incurs only times as many cache misses as in expectation. The following section provides this part of their result.
3 4-competitive Analysis of [17]
We restate and provide a detailed proof of the crucial technical lemma from [17], which is particularly useful for our improved -competitive analysis in Section 5.
Lemma 7 (Lemma 2.5 in [17]).
Let be a paging algorithm. Suppose that whenever suffers a cache miss, the page that it chooses to evict is chosen from a distribution such that the following property is satisfied: for every page in the cache, the probability (over the choice of and the random sequence ahead, conditioned on the most recently requested page) that is next requested no later than the next request for is at least . Then is -competitive against .
Proof.
Consider an infinite sequence of page requests, and consider running and (independently) on this sequence. At any time that suffers a cache miss (say on a request to page ), suppose that chooses to evict page . Let denote the contents in the cache of just before the request. Similarly, let denote the contents in the cache of just after the request.
The proof uses a carefully designed charging scheme:444The charging scheme is purely for analysis purposes. if has to evict a page at time (due to a request for page ), assigns a charge to a page that is not in the cache of after the request at time . Ideally, this page will be requested again before , causing to incur a cache miss at that later time. The specific charging scheme is as follows:
Suppose that at time , there is a request for page .
-
1.
Set .
-
2.
If evicts some page , is selected as follows:
-
(a)
If , set .
-
(b)
If , find a page that has no charges from . Set .555for any page that might evict which satisfies the condition , we make the same choice of .
-
(a)
-
3.
If evicts some page and , set .
At any time for any page , will either be , or some (single) page. Furthermore, before the request at any time, if and only if is not currently in the cache of .
The first action (Item 1) at the time of any page request is the clearing of charges: when a page is requested, if was giving a charge (either to itself or another page), it is duly cleared. If suffers a cache miss, and evicts , then our task is to find a page which is not going to be in the cache of just after time , and assign a charge from to this page.
If is not in (Item 2a), we assign ’s charge to itself. Otherwise, is in (i.e., is a page in ), and we need to find a different page to charge. In this case, we will argue the existence of a page that satisfies the condition in Item 2b, for that fall into this case. Let us remove the common set from each of and , and consider the sets , . Note that both these sets have the same size, and is in , but not in . Furthermore, in our initial step, we set . Thus, even if every page in other than assigns a charge to a page in , at least one page remains unassigned. We select this page (say the first one in a natural ordering) as , the required charge recipient for . Either way, note that is not in , and if is requested before , then incurs a cache miss. In this sense, can be thought of as the “savior” page for .
Item 3 simply reassigns the charge that a page gives if it is eventually evicted from . Specifically, may have initially set when evicted , as still remained in ’s cache. However, if later evicts , we can safely transfer the responsibility back from to .
The nice property about this charging scheme is that no page ever has more than charges on it. Specifically, a page can hold at most one charge from itself and at most one charge from another page (because of Item 2b and Item 3). In fact, the only way a page can have two charges is if it first receives a charge from another page and later gets evicted by , assigning itself a self-charge.
Now, fix a finite time horizon : we will reason about the number of cache misses suffered by and over the course of the page requests at . First, let denote the random variable that is the number of pages that were not present in the cache initially666Note that both and start with the same initial cache., but were requested at some : suffers a cache miss for each of these pages.
Next, let denote the first time after that there is a request for page . Define:
| (5) | ||||
| (6) |
where is a random variable denoting the evicted page. Note that .
Observe that the indicator represents a cache miss for (in the infinite sequence of requests) due to a request for the savior page . Note, however, that a request to the savior page might occur after the time horizon . This can be addressed by counting the number of open charges remaining after the request at time . Specifically, let denote the number of charges assigned by pages that are not in ’s cache after the request at time . Upon subtraction of , the quantity counts the number of cache misses suffered by due to requests to savior pages. A final detail is that a savior page could potentially have two charges on it, and hence we may count the same cache miss for twice in the above calculation. Concretely, suppose at time , gets evicted by , and assigns a charge to . Then, suppose that at time but , is itself evicted by , resulting also in a charge . Now, suppose that gets requested after but before . In this case, we have that both and , but these are really the same cache miss in . Thus, we need to account for a possible double-counting of cache misses in – one way to (very conservatively) do this is simply dividing the expression by 2. In total, we obtain that
| (7) |
and hence
The expectation on the left side above is only with respect to the randomness in the sequence of page requests and , whereas the expectation on the right side is over the randomness in the sequence of requests, as well as . From here, using the defining property of the algorithm from the lemma statement, we can show that . Furthermore, we can also argue that the random variable is always non-negative. Both these together imply the lemma. We defer the details of these last two steps to Appendix B.
Corollary 8.
The dominating distribution algorithm is 4-competitive against .
Proof.
Remark 9.
Consider setting in Lemma 7: this corresponds to effectively being an offline algorithm, that knows the page in cache that is going to next be requested farthest in the future. We already know that such an algorithm is optimal, i.e., is 1-competitive against . However, the guarantee given by Lemma 7 for such an algorithm is still only -competitiveness. This at least suggests that there is scope to improve the guarantee to -competitiveness.
4 Sources of Looseness in the Analysis
We systematically identify the sources of looseness in the above analysis with illustrative examples, before proceeding to individually tighten them in the subsequent section.
4.1 A Conservative Approach to Handling Doubly-Charged Pages
Recall that in the summation above, a cache miss for may be double-counted if the same page is assigned two charges. Although one way to address this overcounting is to divide the summation by 2, this approach is overly conservative, as it undercounts every cache miss in that results from a request to a singly-charged page. For instance, consider the following situation:
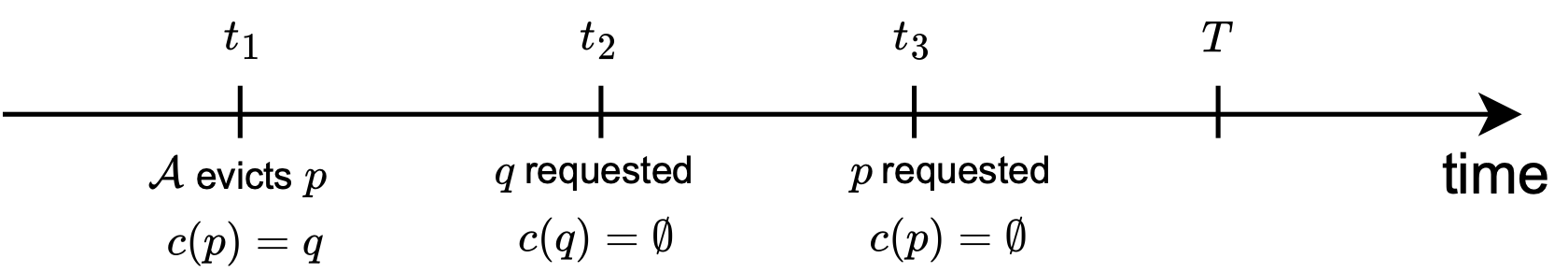
Here, at time , evicts a page . Suppose that continues to live in the cache of after the request at , and hence is assigned to some in ’s cache. Now, say that is requested at time , which is before . Furthermore, assume that at , only had the single charge on itself (by ), i.e., was not evicted by in the time between and . Then, , but we are wastefully dividing it by 2 in our calculation.
4.2 Inexhaustive Clearing of Charges upon a Page Request
Consider the first item in the charging scheme (Item 1) – whenever a page is requested, any charges that might be giving are cleared (i.e., ). Intuitively, this is supposed to account for the fact that, while was holding some page responsible for being requested before itself, either this did happen, in which case we happily clear the already-paid charge, or this did not quite happen and got requested before , in which case we should let go of the charge and focus on the future. However, consider instead the case where does not have a charge on any other page, but is itself the bearer of a charge by some other page, say . In this case, has successfully paid the charge that was expected of it – but this charge would only be cleared upon the next request to ! If it so happens that is next requested after the time horizon , then even if successfully paid the charge due to , since this charge was not cleared when it was requested, it would be counted in as part of the open charges post time , and wastefully subtracted in the calculation. This is concretely illustrated in the situation below:

This suggests that whenever a page is requested, we should clear not only the charges it gives but also any charges it bears, preventing unnecessary inclusion in . This approach ensures that a page discards its imposed charge immediately upon “paying it off” rather than with a delay.
4.3 No Accounting for Uncharged, Non-first-timer Pages
Finally, observe that in the accounting of cache misses for , we only count those that occur due to requests to charged/savior pages (as counted by the ’s), and those that occur due to first-time requests to pages not initially in the cache (as counted by ). However, can also suffer cache misses due to a request to an uncharged page. Namely, if there is a request to a page that was previously evicted by , but at the time that it is requested, is bearing no charges at all, then the cache miss due to is not being counted in the calculation. This is illustrated below:

evicts at time and assigns a charge to , implying that is not in the cache of after the request at (but was instead previously evicted by ). Next, at , is requested, and this clears the charge it had on . Since got requested before , . Then, at , is requested – has no charges on it at this point. Notice that this still causes a cache miss for at . However, this cache miss is not accounted for in our calculation, either by , or by (since this is not the first time that is being brought into the cache).
5 Tightening the Analysis to 2-competitiveness
Having identified the loose ends in the analysis of [17] above, we are able to tighten their analysis and prove the following lemma:
Lemma 10.
Let be a paging algorithm. Suppose that whenever suffers a cache miss, the page that it chooses to evict is chosen from a distribution such that the following property is satisfied: for every page in the cache, the probability (over the choice of and the random sequence ahead, conditioned on the most recently requested page) that is next requested no later than the next request for is at least . Then is -competitive against .
Proof.
We make one small change (highlighted in green) to Item 1 in the charging scheme (Algorithm 1) from the analysis of [17] – whenever a new page is requested, any charges that this page might be giving are cleared, but also any charges that other pages might be having on the requested page are also cleared. This fixes the issue about uncleared charges from Section 4.2.
Suppose that at time , there is a request for page .
-
1.
-
(a)
Set .
-
(b)
For any page that has , set .
-
(a)
-
2.
If evicts some page , is selected as follows:
-
(a)
If , set .
-
(b)
If , find a page that has no charges from . Set .
-
(a)
-
3.
If evicts some page and , set .
Let and be the same random variables as defined in (5), (3) in the proof of Lemma 7. Further, let and be the same random variables as defined there as well. Note that even with the slightly-changed charging scheme, remains quantitatively the same; the random variable however changes – in particular, it potentially becomes a smaller number, because we are clearing charges more aggressively. The random variable nevertheless still counts the cache misses suffered by due to requests to savior pages, while potentially double-counting a few misses. However, to account for this double-counting, instead of dividing every miss by 2 (which was the issue discussed in Section 4.1), we explicitly keep track if some corresponds to a request to a doubly-charged page, and subtract it from our calculation. Formally, let
| (8) |
Then, the quantity counts the cache misses suffered by due to requests to savior pages more precisely, and without double-counting any miss. This crucially allows us to avoid an unnecessary factor of .
Lastly, in order for the analysis to go through, we have to also fix the final issue regarding requests to uncharged pages described in Section 4.3. We simply do this by keeping track of an additional quantity that counts this, and add it to our calculation. Namely, let
| Page requested at time does not exist in ’s cache at this time | ||||
| (9) |
Then, combining all of the above, we have that
| (10) |
Comparing this to the accounting in (7), it at least seems plausible that by not halving, we might be able to save a factor of 2. Namely, taking expectations, we obtain that
where the first inequality follows from the same analysis that we did in the proof of Lemma 7. It remains to argue that the quantity is nonnegative. Note that the random variable starts out being before the very first request at time . We will argue that it always stays nonnegative thereafter via two following two claims.
Claim 11.
If the page requested at time satisfies the following condition: exists in ’s cache and does not exist in ’s cache and is not giving a charge and is not bearing any charges, then the random variable decreases by 1 from to . Furthermore, if the page requested at time does not satisfy this condition, then either increases or stays the same from to .
The proof of this claim involves straightforward but exhaustive casework; it is deferred to Appendix C. In particular, for the latter part of the claim, we need to show that if the requested page violates any part of the condition, cannot decrease.
Claim 12.
If the page requested at time satisfies the condition: exists in ’s cache and does not exist in ’s cache and is not giving a charge and is not bearing any charges, then is strictly positive just before this request.
Proof.
Consider any time where the requested page satisfies the condition. We can associate to the page two past events occurring at times and (where ) such that: (1) evicts at , but continues to live in ’s cache, resulting in giving a charge to some other page in ’s cache (Item 2b), and (2) gets requested at , before the request to at , thereby clearing the charge by on (as per Item 1b). Observe that these two past events need to necessarily occur for to satisfy the condition. Now observe that when gets requested at , is the bearer of a single charge. Thus, over the course of this request to , remain unchanged. Because ’s charge on gets cleared, decreases by . Finally, because is in ’s cache at this time, no new charges are added to . Thus, strictly increases by 1 at step (2). Also, note that for each distinct time step where the requested page satisfies the condition, there is a distinct associated (past) step (2).
Now consider the first time where the requested page satisfies the condition. Then, by Claim 11, at every previous time step, either increased or remained the same. Given that started out being 0, and recalling that step (2) (which happened before ) caused a strict increase in the quantity, we have that is strictly positive at .
Just after the request at , decreases by 1 (by Claim 11), and is now only guaranteed to be nonnegative, instead of positive. Then, consider the next time when a page satisfying the condition is requested. We can again trace its associated (distinct) step (2) that happened in the past. If this happened before , then stayed positive after the request at . Alternatively, if this happened in between and , still turns positive (if it ever became zero at all). In either case, is positive before the request at . The claim follows by induction.
The above two claims establish that if at any time , then cannot decrease at time . Furthermore, if at all does decrease (from being a positive number), it only decreases by 1. Together, this means that is always nonnegative, and hence it is nonnegative in expectation. This concludes the proof of Lemma 10
Corollary 13.
The dominating distribution algorithm is 2-competitive against .
Proof.
Remark 14.
As in Remark 9, if we set in Lemma 10, our lemma says that a policy that has essentially seen the future and evicts the page that is next scheduled to be requested latest is 1-competitive against , i.e., it is optimal. Thus, our analysis, while establishing the best-possible guarantee for algorithms satisfying the condition of the lemma, additionally recovers an alternate, charging-scheme-based proof of the optimality of the Farthest-in-Future eviction policy.
Remark 15.
The factor of 4 in the analysis of [16] constituted a factor of 2 arising due to doubly-charged pages, and a factor of 2 arising from the property of the dominating distribution algorithm. While we got rid of the first factor, the second factor seems inherent to the dominating distribution algorithm; it would be interesting to see if this factor could be improved as well.
Lemma 10 also allows us to improve the approximation guarantee for another intuitive deterministic algorithm considered by [17], namely the median algorithm. At any cache miss, the median algorithm evicts the page in cache that has the largest median time of next request. For deterministic algorithms satisfying the condition of Lemma 7, [17] employ a slightly more specialized analysis of the charging scheme in Algorithm 1 (Lemma 2.3 in [17]) to obtain a -competitive guarantee against (instead of -competitiveness). Thereafter, by arguing that the median algorithm satisfies the condition with , (Theorem 2.4 in [17]), they are able to show that the median algorithm is 5-competitive against . Our tighter analysis in Lemma 10 applies to any algorithm (deterministic/randomized), and hence also improves the guarantee for deterministic algorithms obtained by [17]. More importantly, it improves the performance guarantee that we can state for the median algorithm.
Corollary 16.
The median algorithm is 4-competitive against .
6 Lower Bound for Dominating Distribution Algorithms
We now show that there exist problem instances where a dominating distribution algorithm888Note that we cannot hope to prove a lower bound that applies to all dominating distribution algorithms, since the optimal Farthest-in-Future algorithm is technically also a dominating distribution algorithm. can provably be at least times worse than , for . We present a simpler bound of here, and defer the proof of the improved bound to the full version.
Consider a simple Markov cain on 3 total pages, and a cache of size 2. At each time step independently, page 1 is requested with probability , and page 2 and 3 are requested each with probability . This corresponds to the Markov chain with the transition matrix
We start with the initial cache being . The reference algorithm we will compete against always keeps page 1 in its cache. If it suffers a cache miss, it swaps out the other page with the requested page. At any time , the probability that suffers a miss is therefore exactly , and hence the expected total number of misses through timesteps is .
Now, consider . We want to capitalize on the fact that evicts page 1 with some positive probability, in contrast to . Namely, observe that
| (11) |
where we denote . The latter probability is non-zero for , which already makes its expected total number of misses larger than that of . We will therefore aim to maximize this difference. Observe that
We can analytically calculate the last probability. Say the cache of at is, without loss of generality, . Given that is not requested, we have that either of or are requested, each with probability . If is requested, there is no cache miss. If on the other hand, is requested, calculates a dominating distribution over . This can be easily calculated. Let again be the probability that is requested next before (conditioned on the current page, which in this case, does not matter since the distributions at every time step are independent and identical). We have that
The condition for the dominating distribution is that, for every fixed page in the cache, . Letting so that , this translates to
We want to be large as possible, because we want to evict with the highest feasible probability, so that it will suffer a lot of cache misses. Thus, we set . This gives us that,
Plugging this in our calculation for from above, we get that
Unrolling the recurrence, and using that , we obtain that for ,
Summing up until , and substituting from above, we get that
Taking the limit as , we get that
Substituting the values of and , and taking the limit as , the ratio above converges to .
7 Learning the Markov Chain from Samples
It is worth pointing out that the form of Lemma 10 allows us to obtain performance guarantees even when we only have approximate estimates of the values, as also noted in passing by [17]. In particular, suppose that we only have -approximate (multiplicate or additive) estimates of , that still satisfy , and . Suppose that at each cache miss, we use these values to compute a dominating distribution , and draw the page to evict from . Even with such an approximate dominating distribution, we can still guarantee either -competitiveness (in the case that ), or -competitiveness (in the case that ). This follows as a direct consequence of Claim 6 and Lemma 10.
Perhaps the first scenario to consider here is when we do not assume prior knowledge of the transition matrix , but only have access to samples previously drawn from the Markov chain. For example, we can imagine that the algorithm designer has available a large training dataset of past page requests. This dataset can be used to derive estimates of the entries in the transition matrix , for instance, using one of the several existing estimators [10, 24, 11]. In fact, recall that the computation of the values requires only for us to solve a linear system determined by the entries in the transition matrix (Appendix A). Hence, if we have accurate estimates for the entries in , we can use the theory of perturbed linear systems to bound the resulting error in the estimates of the values. Thereafter, using the argument from the previous paragraph, we can obtain a performance guarantee for the competitiveness of a dominating distribution algorithm that uses these estimates.
We can turn the above informal argument into a formal learning-theoretic result. We choose to adopt the following result of [10] for our exposition:
Theorem 17 (Theorem 4 in [10]).
Suppose we unroll a Markov chain to obtain samples , where the initial distribution of is arbitrary, but the transition matrix of the Markov chain satisfies for every . Then, there exists an estimator that satisfies
for every , where (respectively ) denotes the row of (respectively ).
Using this theorem, we can obtain the following result:
Theorem 18.
Suppose that the page requests are generated from an unknown Markov chain where every entry in the transition matrix is at least . Given a training dataset of past page requests from , there is an algorithm which is -competitive against with probability at least over the samples..
The proof of this theorem is given in the full version, and follows the outline sketched above. We remark that the in the bound for hides a constant that depends on the conditioning of the linear systems that determine the values.
References
- [1] Spyros Angelopoulos and Pascal Schweitzer. Paging and list update under bijective analysis. In Proceedings of the twentieth annual ACM-SIAM symposium on Discrete algorithms, pages 1136–1145. SIAM, 2009. doi:10.1137/1.9781611973068.123.
- [2] Luca Becchetti. Modeling locality: A probabilistic analysis of lru and fwf. In Algorithms–ESA 2004: 12th Annual European Symposium, Bergen, Norway, September 14-17, 2004. Proceedings 12, pages 98–109. Springer, 2004. doi:10.1007/978-3-540-30140-0_11.
- [3] Laszlo A. Belady. A study of replacement algorithms for a virtual-storage computer. IBM Systems journal, 5(2):78–101, 1966. doi:10.1147/sj.52.0078.
- [4] Allan Borodin and Ran El-Yaniv. Online computation and competitive analysis. cambridge university press, 2005.
- [5] Allan Borodin, Prabhakar Raghavan, Sandy Irani, and Baruch Schieber. Competitive paging with locality of reference. In Proceedings of the twenty-third annual ACM symposium on Theory of computing, pages 249–259, 1991.
- [6] Peter J Denning. The working set model for program behavior. Communications of the ACM, 11(5):323–333, 1968. doi:10.1145/363095.363141.
- [7] Reza Dorrigiv and Alejandro López-Ortiz. A survey of performance measures for on-line algorithms. SIGACT News, 36(3):67–81, 2005. URL: http://dl.acm.org/citation.cfm?id=1086670.
- [8] Amos Fiat and Anna R Karlin. Randomized and multipointer paging with locality of reference. In Proceedings of the twenty-seventh annual ACM symposium on Theory of computing, pages 626–634, 1995. doi:10.1145/225058.225280.
- [9] Amos Fiat and Manor Mendel. Truly online paging with locality of reference. In Proceedings 38th Annual Symposium on Foundations of Computer Science, pages 326–335. IEEE, 1997. doi:10.1109/SFCS.1997.646121.
- [10] Yi Hao, Alon Orlitsky, and Venkatadheeraj Pichapati. On learning markov chains. Advances in Neural Information Processing Systems, 31, 2018.
- [11] De Huang and Xiangyuan Li. Non-asymptotic estimates for markov transition matrices with rigorous error bounds. arXiv preprint arXiv:2408.05963, 2024.
- [12] Sandy Irani. Competitive analysis of paging. Online Algorithms: The State of the Art, pages 52–73, 2005.
- [13] Sandy Irani, Anna R Karlin, and Steven Phillips. Strongly competitive algorithms for paging with locality of reference. In Proceedings of the third annual ACM-SIAM symposium on Discrete algorithms, pages 228–236, 1992. URL: http://dl.acm.org/citation.cfm?id=139404.139455.
- [14] AR Karlin, SJ Phillips, and P Raghavan. Markov paging. In Proceedings of the 33rd Annual Symposium on Foundations of Computer Science, pages 208–217, 1992.
- [15] Elias Koutsoupias and Christos H Papadimitriou. Beyond competitive analysis. SIAM Journal on Computing, 30(1):300–317, 2000. doi:10.1137/S0097539796299540.
- [16] Carsten Lund, Steven Phillips, and Nick Reingold. IP over connection-oriented networks and distributional paging. In Proceedings 35th Annual Symposium on Foundations of Computer Science, pages 424–434. IEEE, 1994. doi:10.1109/SFCS.1994.365674.
- [17] Carsten Lund, Steven Phillips, and Nick Reingold. Paging against a distribution and IP networking. Journal of Computer and System Sciences, 58(1):222–231, 1999. doi:10.1006/jcss.1997.1498.
- [18] Thodoris Lykouris and Sergei Vassilvitskii. Competitive caching with machine learned advice. Journal of the ACM (JACM), 68(4):1–25, 2021. doi:10.1145/3447579.
- [19] Mohammad Mahdian, Hamid Nazerzadeh, and Amin Saberi. Online optimization with uncertain information. ACM Transactions on Algorithms (TALG), 8(1):1–29, 2012. doi:10.1145/2071379.2071381.
- [20] Chirag Pabbaraju and Ali Vakilian. New and improved bounds for markov paging. arXiv preprint arXiv:2502.05511, 2025. doi:10.48550/arXiv.2502.05511.
- [21] Tim Roughgarden. CS 369N Beyond Worst-Case Analysis, Lecture Notes 2: Models of Data in Online Paging. https://timroughgarden.org/f11/l2.pdf, 2010.
- [22] Daniel D Sleator and Robert E Tarjan. Amortized efficiency of list update and paging rules. Communications of the ACM, 28(2):202–208, 1985. doi:10.1145/2786.2793.
- [23] Eric Torng. A unified analysis of paging and caching. Algorithmica, 20:175–200, 1998. doi:10.1007/PL00009192.
- [24] Geoffrey Wolfer and Aryeh Kontorovich. Statistical estimation of ergodic markov chain kernel over discrete state space. Bernoulli, 27(1):532–553, 2021.
- [25] Neal E Young. Bounding the diffuse adversary. In Proceedings of the ninth annual ACM-SIAM symposium on Discrete algorithms, pages 420–425, 1998. URL: http://dl.acm.org/citation.cfm?id=314613.314772.
- [26] Neal E Young. On-line paging against adversarially biased random inputs. Journal of Algorithms, 37(1):218–235, 2000. doi:10.1006/jagm.2000.1099.
Appendix A Linear System for Computing
Let be the transition matrix on pages, and let . Note that , . For any other page , note that
Thus, upon solving the linear system given by
| (12) |
where and are row vectors with a in the and coordinates, respectively, and elsewhere, is the desired value . In this way, we can solve a linear system for each of the possible pairs for , and compute all values in time .
Appendix B Finishing the Proof of Lemma 7
Fix any . Let denote a fixed sequence of page requests, denote the execution of on these page requests, and denote the execution of on all but the last of these page requests, such that together result in a cache miss for at time . Then, we have that
Let us use the shorthand , and focus on the latter term in the summation. Note that once we have conditioned on , the configuration of ’s cache (before the page request at ) is determined – denote its pages by . At the last page request in , suffers a cache miss, and chooses a page to evict from from a (conditional) distribution satisfying the property given in the lemma statement. Namely,
But note that conditioning on , determines the cache of after time : let its contents be denoted by . Then, according to our charging scheme, for any , is as follows: if , whereas if , for some fixed that satisfies the condition in Item 2b. Note importantly that we make the same choice of for any in the latter case.
where in the last line, we used the property of the distribution from the lemma statement. Tracing backwards, we have obtained that
Finally, we observe that the random variable is always nonnegative. This is because, any page that is in the cache of after the request at time , or not in the cache of after time but giving a charge, must necessarily have either been in the initial cache, or must have been requested at some time . This implies that , which implies that . In total,
as required.
Appendix C Proof of Claim 11
Proof.
We first show that if the page requested at time satisfies the condition, then decreases by 1. Since is in ’s cache, the request to does not change (see the definition in (9)). Moreover, being in ’s cache implies it was either in the initial cache or previously requested, so also remains unchanged. Similarly, because is not doubly charged, remains unchanged. Thus, we only need to account for the change in .
Because is neither giving nor bearing any charges, both Item 1a and Item 1b cause no change in . Finally, because does not exist in ’s cache and results in a cache miss, Item 2 creates a new charge, causing to increase by 1. In total, decreases by 1.
Next, we will show that if does not satisfy the condition, then either increases or stays the same. Towards this, consider each of the following cases:
Case 1: is a doubly-charged page.
In this case, increases by 1. Note that one of the charges on is by itself, and the other charge is by some other page . In particular, is not giving a charge to a page other than itself. Thus, when is requested, Item 1a and Item 1b ensure that the charge by on itself as well as the charge on by are both dropped.999Note how Item 1b was necessary to ensure this. However, note also that is not in the cache of (since it has a charge on itself, it was previously evicted by ), and hence this request has caused a cache miss in , resulting in the creation of a new charge in Item 2. Item 3 can only reassign a charge, and thus, the net change in is . Finally, and remain the same. Therefore, the overall change in is 0.
Case 2: is a singly-charged page.
This means that either is not in the cache of and is charging itself, or is in the cache of and is bearing a charge given by some other page at the time of its eviction.
In the former case, observe that none of , or are affected. The clearing of charges in Item 1 causes to decrease by 1, and the cache miss causes the creation of a new charge in Item 2. In total, stays unchanged. In the latter case, observe that the charge on is cleared in Item 1b, causing to decrease by 1. Furthermore, because is in the cache of , there is no creation of a new charge in Item 2. Thus, increases by 1.
Case 3: is not in ’s cache.
If is either singly or doubly-charged, we fall under Case 1 or 2. If has no charges on it, then:
Subcase 3a: has never been requested before.
In this case, increases by 1. Also, cannot be giving or bearing any charges; thus Item 1a and Item 1b cause no change to . However, the request to causes a cache miss in , resulting in an eviction, and the creation of a new charge. Thus, increases by 1. Additionally, and remain the same. Thus, the net change in is 0.
Subcase 3b: has been requested before.
This means that was previously in ’s cache at some time but was since evicted. Also, has no charges on it. Thus, increases by 1, while and remain unchanged. It remains to reason about . Because has no charges on it, Item 1b causes no change in . Item 1a either decreases by 1 or causes no change to it. While the request to can cause a cache miss to , this can only result in the creation of a single new charge, and can increase by at most 1 due to this. In total, either increases or stays the same.
Case 4: is in ’s cache.
This means that is giving no charges. Then, either is singly-charged or has no charges on it. It cannot be doubly-charged because it would have to be out of ’s cache for that. If it is singly-charged, we fall under Case 2. If it has no charges on it, we reason as follows: both Item 1 and Item 2 leave unaffected. Moreover, and remain unaffected. Finally, depending on whether is or isn’t in ’s cache, either stays the same or increases. Hence, either stays the same or increases.
Case 5: is giving a charge.
If has any charges on it, we fall under Case 1 or 2. So we assume that has no charges on it. This means that is not in ’s cache, but is still in ’s cache. Note then that remain unchanged. We reason about the change in as follows: Item 1a clears the charge that is giving and decreases by 1, whereas Item 2 creates a new charge and increases by 1. In total, remains unchanged.
Thus, in any way that the requested page might not satisfy the condition, either increases or stays the same, concluding the proof.