Near-Optimal Algorithm for Directed Expander Decompositions

Abstract
In this work, we present the first algorithm to compute expander decompositions in an -edge directed graph with near-optimal time 111In this article, we use notation to suppress factors logarithmic in , i.e. for every constant .. Further, our algorithm can maintain such a decomposition in a dynamic graph and again obtains near-optimal update times. Our result improves over previous algorithms [2, 18] that only obtained algorithms optimal up to subpolynomial factors.
In order to obtain our new algorithm, we present a new push-pull-relabel flow framework that generalizes the classic push-relabel flow algorithm [14] which was later dynamized for computing expander decompositions in undirected graphs [16, 31]. We then show that the flow problems formulated in recent work [18] to decompose directed graphs can be solved much more efficiently in the push-pull-relabel flow framework.
Recently, our algorithm has already been employed to obtain the currently fastest algorithm to compute min-cost flows [33]. We further believe that our algorithm can be used to speed-up and simplify recent breakthroughs in combinatorial graph algorithms towards fast maximum flow algorithms [11, 12, 1].
Keywords and phrases:
Directed Expander Decomposition, Push-Pull-Relabel AlgorithmCategory:
Track A: Algorithms, Complexity and GamesCopyright and License:
2012 ACM Subject Classification:
Theory of computation Dynamic graph algorithmsAcknowledgements:
The authors are thankful for many fruitful discussions and feedback on an earlier version of the paper from Rasmus Kyng, Simon Meierhans and Thatchaphol Saranurak.Funding:
The research leading to these results has received funding from the starting grant “A New Paradigm for Flow and Cut Algorithms” (no. TMSGI) of the Swiss National Science Foundation.Editors:
Keren Censor-Hillel, Fabrizio Grandoni, Joël Ouaknine, and Gabriele PuppisSeries and Publisher:
1 Introduction
Over the past two decades, expanders and expander decompositions have been pivotal in advancing on fundamental algorithmic graph problems. The development and application of the first fast algorithm to compute near-expander decompositions was given in the development of the first near-linear time Laplacian solvers [32], a breakthrough in modern graph algorithms. Subsequently, a line of research [16, 36, 28, 29] has focused on strengthening this result by developing fast flow-based pruning techniques that refine near-expander decompositions into expander decompositions. This line of research culminated in [31] where a new, faster, simpler, and more user-friendly expander decomposition framework was presented. This advancement has catalyzed the widespread use of expander decompositions as a tool in graph algorithms and was instrumental in the recent surge of applications of expander decompositions in both static and dynamic graph settings for various cut, flow, and shortest path problems [32, 21, 16, 36, 28, 29, 10, 2, 26, 5, 35, 30, 6, 25, 13, 15, 9, 3, 3, 24, 19, 34, 23, 7, 20, 12, 1, 33]. In this work, we study the problem of computing and maintaining expander decompositions in directed graphs, defined as follows.
Definition 1 (Directed Expander Decomposition).
Given an -edge directed graph , we say a partition of the vertex set of and a subset of edges forms an -expander decomposition if
-
1.
, is a -expander meaning for all cuts , and
-
2.
, and
-
3.
the graph , that is the graph minus the edges in where expander components in are contracted into supernodes, is a directed acyclic graph (DAG).
In our algorithm, we implicitly maintain an ordering of the partition sets in and let be the edges that go ’backward’ in this ordering of expander components. Note that we can only obtain a meaningful bound on the number of such ’backward’ edges since a bound on all edges between expander components cannot be achieved as can be seen from any graph that is acyclic (which implies that has to be a collection of singletons by Item 1 forcing all edges to be between components). Directed expanders and expander decompositions have been introduced in [2] in an attempt to derandomize algorithms to maintain strongly connected components and single-source shortest paths in directed graphs undergoing edge deletions. Recently, [18] gave an alternative algorithm to compute and maintain directed expander decomposition that refines the framework from [2] and heavily improves subpolynomial factors. Besides working on directed graphs, this algorithm also yields additional properties for expander decompositions that cannot be achieved with existing techniques - even in undirected graphs. In this article, we further refine these techniques to obtain an algorithm that is optimal up to logarithmic factors in - as opposed to subpolynomial factors. Since their invention, directed expander decompositions and the techniques to maintain such decompositions have been pivotal in the design of fast dynamic graph data structures and in ongoing research for fast ’combinatorial’ maximum flow algorithms. We discuss in Section 1.2 these recent lines of research and how our algorithm benefits recent breakthrough results.
1.1 Our Contribution
In this article, we finally give a simple algorithm that generalizes the algorithm from [31] in a clean way. Further, our algorithm is the first to obtain near-optimal runtimes for both static and dynamic expander decompositions in directed graphs. Our result is summarized in the theorem below.
Theorem 2.
Given a parameter for a fixed constant , and a directed -edge graph undergoing a sequence of edge deletions, there is a randomized data structure that constructs and maintains a -expander decomposition 222Here we use the augmented expander decomposition definition 7. of . The initialization of the data structure takes time and the amortized time to process each edge deletion is .
Further, our algorithm has the property that it is refining for up to edge deletions meaning that is a refinement of its earlier versions (every expander component in is a subset of an expander component in any earlier expander decomposition) and the size of does never exceed . Our algorithms are deterministic, however, they rely on calling a fast randomized algorithm to find balanced sparse cuts or certify that no such cut exists (see [22, 27]). Our new techniques are much simpler and more accessible than previous work, besides also being much faster. We hope that by giving a simpler algorithm for directed expander decompositions, we can help to make this tool more accessible to other researchers in the field with the hope that this can further accelerate recent advances in dynamic and static graph algorithms.
1.2 Applications
Our new algorithms have direct applications to the currently fastest approaches for bipartite matching/ maximum flow/ min-cost flows and the data structures that are employed to obtain these results:
-
1.
Our algorithm is already used in the fastest min-cost flow algorithm that is known to-date [33] which achieves runtime yielding the first improvement over the recent breakthrough in [8] achieving the first near-linear time algorithm for min-cost flows. In the framework of [33], our algorithmic techniques are used to maintain an expander decomposition of an undirected graph where it is heavily exploited that our algorithm maintains the expander decomposition such that it refines over time. This guarantee is pivotal in the construction of a fully-dynamic algorithm to maintain dynamic expander hierarchies which is the key data structure in the paper. While [33] could also have relied solely on the techniques [18] to obtain such a data structure with subpolynomial update and query times, these subpolynomial factors would have been substantially larger and would thus not have yielded a faster min-cost flow algorithm overall.
-
2.
In [2], directed expander decompositions for decremental graphs were used to obtain the first algorithm to maintain -approximate Single-Source Shortest-Paths (SSSPs) in a decremental graphs in time , though only for the special case of dense graphs. This problem is well-motivated as a simple reduction based on the Multiplicative Weights Update (MWU) framework implies that the maximum flow problem can be solved approximately by solving approximate decremental SSSP. By standard refinement of flows this yields an exact maximum flow algorithm. Very recently, Chuzhoy and Khanna [11, 12] showed that for the update sequence generated by the MWU to solve the bipartite matching problem - a special case of the maximum flow problem - decremental SSSP can be maintained in time by refining the techniques from [4, 2]. This yields the first near-optimal ’combinatorial’333We refrain from defining the scope of combinatorial algorithms here and refer the reader to [11, 12] for a discussion. algorithm for the bipartite matching problem for very dense graphs. While the above algorithms are ’combinatorial’, they are still very intricate. Most of these complications stem from the maintenance of the directed expander decomposition used internally by the decremental SSSP data structure. We hope that our technique can help to simplify and speed-up these components to yield a simpler algorithm overall.
-
3.
In independent work [1], an alternative ’combinatorial’ maximum flow that runs in time was given. This algorithm cleverly extends push-relabel algorithms to run more efficiently when given an ordering of vertices that roughly aligns with the topological order induced by the acyclic graph formed from the support of an optimal maximum flow solution. To obtain this approximate ordering they compute a static expander hierarchy of the directed input graph. This generalizes the notion of directed expander decompositions further. In their work, they heavily build on the techniques from [18] to obtain the expander hierarchy. Unfortunately, the algorithm to obtain this hierarchy is very involved. We hope that our new techniques can help to simplify and speed-up their algorithms.
1.3 Our Techniques
High-Level Strategy
We obtain our result by following the high-level strategy of [31] for undirected graphs: we draw on existing literature (specifically [22, 27]) for an algorithm that either outputs a balanced sparse cut which allows us to recurse on both sides; or outputs a witness that no such cut exists. This witness can be represented as an expander graph that embeds into with low congestion where is a set of few fake edges. In the second case, we set up a flow problem to extract a large expander (the first algorithm only finds balanced sparse cuts, so many unbalanced sparse cuts might remain) which suffices to again recurse efficiently.
The (Dynamic) Flow Problem in [31]
To outline our algorithm, we first sketch the techniques of [31]. In [31], the following sequence of flow problems is formulated: initially, we add units of source commodity to each endpoint of an edge in and then ask to route the commodity in where each vertex is a sink of value and each edge has capacity . It then runs an (approximate) maximum flow algorithm on the flow problem. Whenever the algorithm detects that no feasible flow exists444Technically, the algorithm might already output cuts when some cut has capacity less than a constant times the amount of flow that is required to be routed through the cut., it finds a cut where is the smaller side of the cut and then poses the same problem for the network where this time the source commodity is assigned for each edge in . The algorithm terminates once the flow problem can be solved and outputs the final induced graph. In [31], it is shown that once a feasible flow exists then the (induced) graph is a -expander. Further, it is shown that in the sequence of flow problems, each problem can be warm-started by re-using the flow computed in the previous instance to detect a cut induced on the remaining vertex set. This result is obtained by two main insights:
-
1.
if the flow to find the cut is a pre-flow, that is a flow that respects capacities and has no negative excess at any vertex (i.e. it does not route away more flow from a vertex than is inputted by the source), then injecting additional source flow for any edge guarantees that the induced flow is a pre-flow in the flow problem formulated for . That is because the amount of flow that was routed via such a cut edge is at most and thus placing new source commodity at the endpoint ensures that no negative excess exists in the induced flow ,
-
2.
the classic push-relabel framework can naturally be extended to warm-start on such a flow as it is built to just further refine pre-flows at every step.
This dynamization of the push-relabel framework allows to bound the cost of computation of all flow problems linearly in the amount of source commodity which in term is bounded by the number of edges that appear in either or one of the identified min-cuts. Finally, [31] shows that the amount of source commodity remaining in decreases over the sequence of flow problems proportional to the volume of the set of vertices that are removed at each step. Indeed, they observe that at each vertex in at least many commodity units are absorbed and that the total amount of source injected due to the cut edges is bounded by . This yields that the final induced graph is still large. Thus, the final graph outputted is a large expander, as desired.
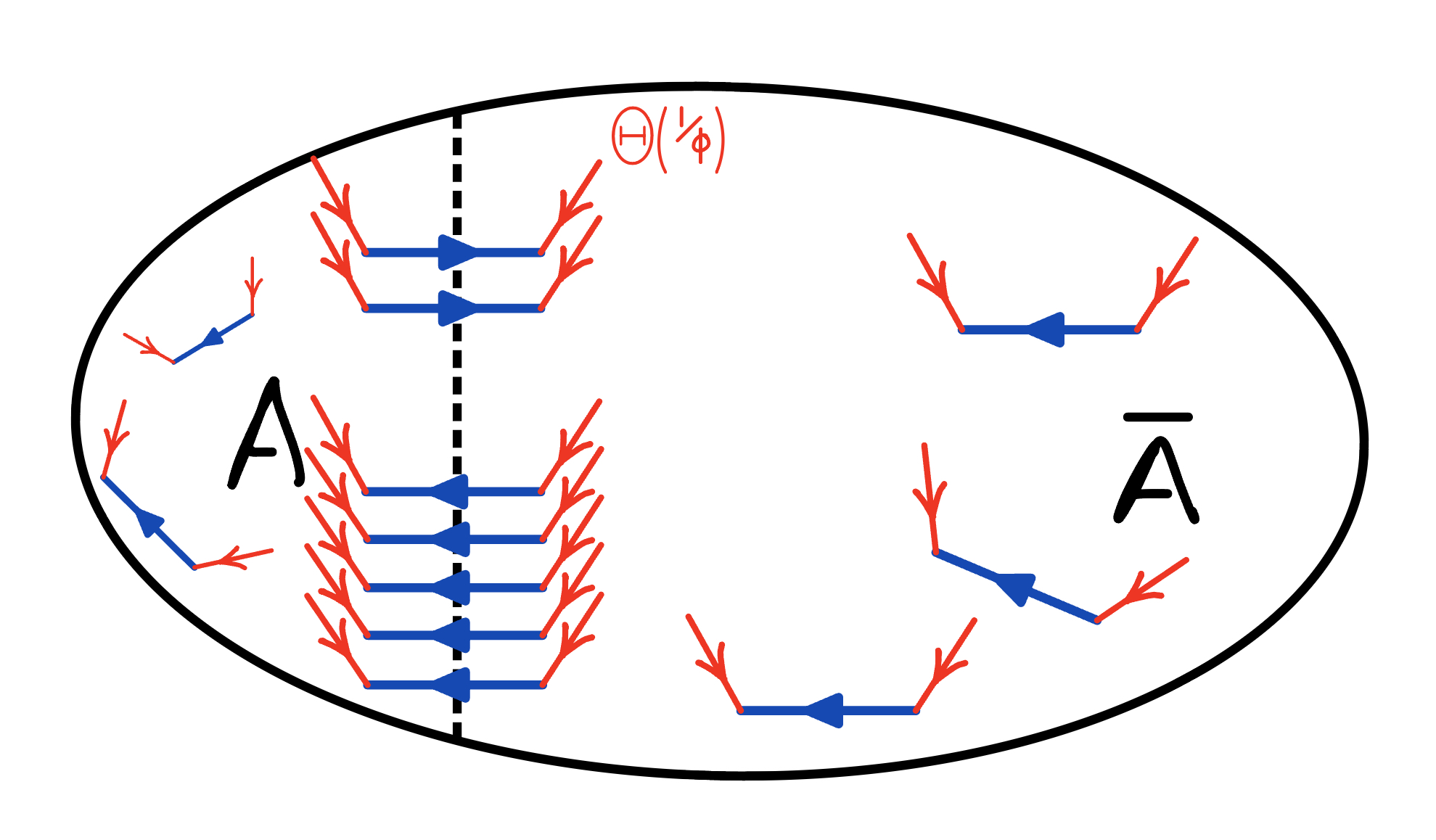
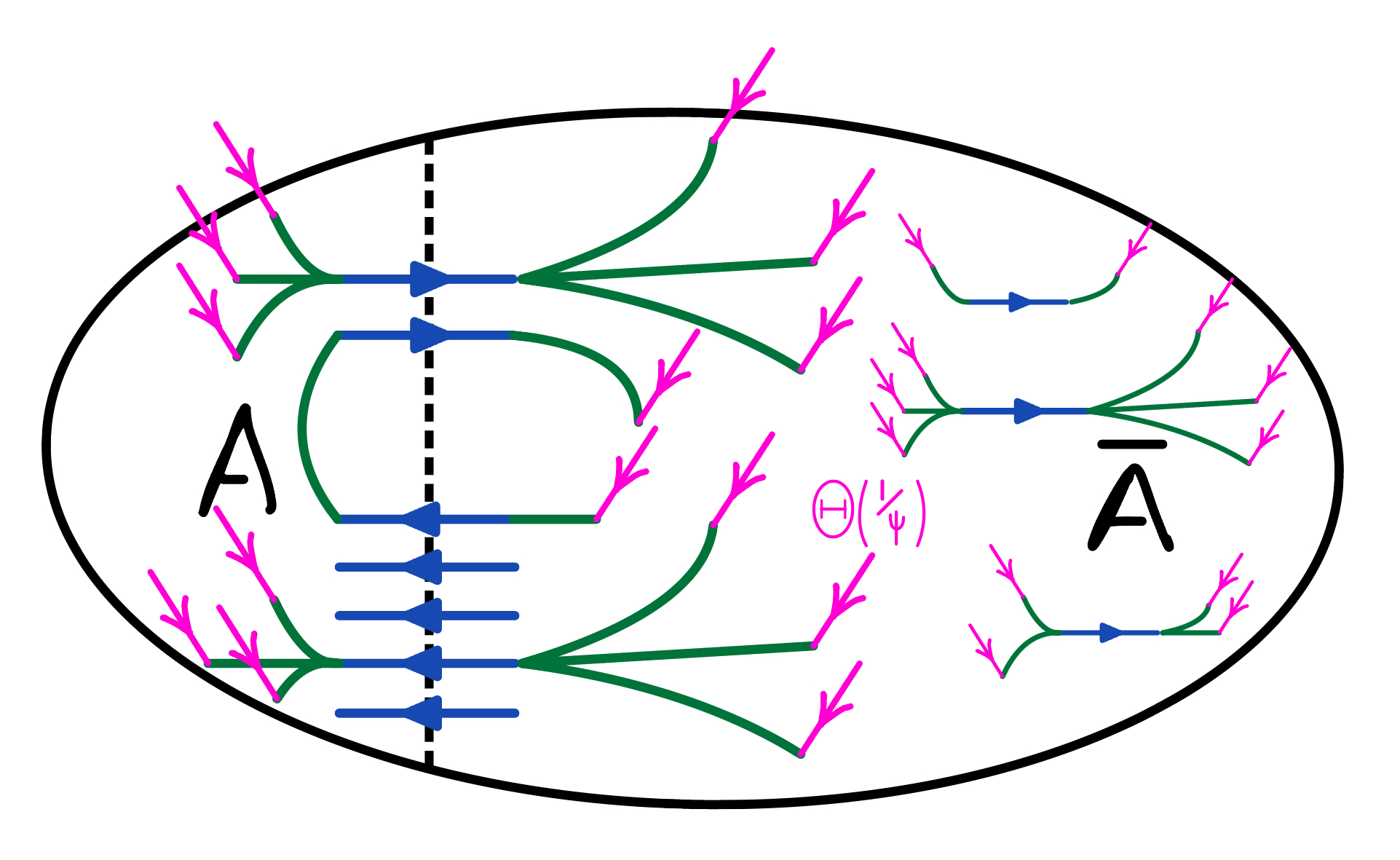
The (Dynamic) Flow Problem in Directed Graphs
In directed graphs, while the above flow problem upon becoming feasible also certifies that the remaining graph is a -expander, the argument that the sequence of flow problems terminates does not work: the asymmetry of cuts might force us for a small cut to induce on while having many edges in each of which would add source flow to the new flow problem (see Figure 1(a)). Hence, we might end up injecting up to more flow due to the cut edges. This makes it seemingly impossible to argue that the amount of source commodity in the next flow problem is smaller. To recover the argument that the sequence of flow problems terminates (with the remaining expander graph being large) both [2, 18] suggest setting up the flow problems more carefully such that each cut that is found in this sequence and induced upon is a sparse cut. Here, we only describe the less lossy flow problem formulation developed in [18]. To ensure that each cut that is found is a sparse cut, [18] proposes a slightly different flow problem: instead of adding source commodity per endpoint of an edge that is fake or not fully contained in the induced graph, it tailors the amount of new source commodity using the witness graph , possibly injecting much less source commodity in the process. Concretely, we have that is a -expander over the same vertex set as with degrees similar to degrees in up to a factor of and an embedding into with congestion , for . To set-up the flow problem, we inject units at the endpoints of any edge in the witness whose embedding path goes through an edge in . We note that any such witness embedding path either crosses the sparse cut or has an endpoint in . This allows to bound the additional source injected by where we use that . But while correctness and termination of the flow problem sequence are now ensured, this leaves a significant problem: the current flow that was used to find the cut no longer has the property that is a pre-flow in the flow problem formulated on network even if is a pre-flow. While capacity constraints are still enforced, i.e. still is a pseudo-flow (see [17] for reference on pseudo-flow), some vertices might now have negative excess since the additional commodity might be injected in the interior of far from the cut (see Figure 1(b)). Indeed, for an edge in a lot of flow might have been routed through but no additional commodity might be injected at since all witness embedding paths passing through might not end in . Thus, dynamizing the push-relabel framework does not appear natural for this sequence of problems as it crucially requires that the maintained flow is a pre-flow at all times. In [18], an involved batching technique is used instead (based on the technique in [29]) that does not use dynamic flow problems but instead reduces to few static flow problems, however, at the loss of quality and runtime by subpolynomial factors.
The Push-Pull-Relabel Framework
The main technical contribution of this paper is a new framework that refines pseudo-flows as efficiently as the push-relabel framework refines pre-flows. Thus, we give a generalization of the latter widely-used and well-studied framework that we believe might have applications well beyond our problem. Recall that the classic push-relabel framework maintains labels for all vertices and a pre-flow . In each iteration, it ’pushes’ positive excess flow at a vertex to a vertex at a lower label (to be precise to a vertex at level ); or if no ’push’ is possible, it increases the labels of some vertices: it ’relabels’. Using a clever potential-based analysis, one can show that it suffices to only increase the labels to a certain threshold before all flow is settled. In our framework, we allow deleting edges, without compensating by adding source commodity at the endpoints, which might create negative excess leaving a pseudo-flow (instead of a pre-flow). Now, while our framework applies the same strategy for ’pushes’ and ’relabels’, we also need a new operation ’pull’. Intuitively, our algorithm tries to ’pull’ back the source commodity that now causes the negative excess (this unit of commodity was ’pushed’ earlier to some other vertices). To do so, a vertex with negative excess can ’pull’ commodity from vertices at a higher level (again it can only pull from a vertex at level ). But it is not difficult to construct an example where this strategy does not suffice: therefore, we also need to sometimes decrease the label of a vertex to ensure correctness. However, the latter change to the ’relabel’ operation breaks the property that labels are non-decreasing over time. A property that is crucial in the existing efficiency analysis. Instead, we give a much more careful argument to analyze the potentials that bound the number of push, pull, and relabeling operations that deal with the non-monotonicity of the levels over time. The argument is sketched below. Combining this framework with the above-discussed set-up of dynamic flow problems as proposed in [18] then yields the first near-optimal algorithm to compute an expander decomposition in a directed graph. Further, our technique extends seamlessly to also deal with edge deletions to , yielding an algorithm to prune expander graphs that undergo edge deletions.
A Sketch of the Runtime of Push-Pull-Relabel
The run-time analysis in standard push-relabel considers the run-time contribution of the push and relabel operations separately. Using a potential argument, one can then relate the contribution of the push operations to the relabeling operations. A similar argument albeit much more delicate also allows to relate the contribution of the push and the pull operations to the contribution of the relabeling operations in the extended push-pull-relabel algorithm. What might seem more daunting is to bound the run-time contribution of the relabelings given that the level function is no longer point-wise non-decreasing. Let us revisit the argument to bound the run-time contribution of the relabelings in the push-relabel of [31]. Any relabeling of , incurs a cost of as each incident edge has to be checked before a relabeling. At such a relabeling of , the sink of , which has by choice capacity , must be full and any commodity unit in it remains there till termination. Since the label of does not decrease and is bounded by , we may thus charge for the run-time contribution of the relabelings of each unit in the sink of exactly . Over all vertices, we conclude that any commodity unit was charged at most units. In the push-pull-relabel algorithm, a commodity unit might end up in various sinks. So a more clever charging argument needs to be devised. To guide intuition an analogy to flows of protons and electrons is useful. The protons correspond to commodity units and the electrons to the lack of commodity units. We are now moving protons and electrons around in the network and whenever a proton and an electron meet at a vertex they form a neutron which stays put at the vertex indefinitely. The neutrons will provide a means to charge work in the analysis. The sink of each vertex can absorb commodity units or put differently protons. Electrons only form when we delete an edge , i.e. exactly new electrons form at . By choice, we now say that if we perform a push from to of one unit then exactly one proton moves from to , while if we perform a pull from to then exactly one electron moves from to . Since we only perform a push away from if there are more than free protons (not part of a neutron) at and a pull towards if there are free electrons at , we find that , where denotes the number of protons at (including the ones in a neutron) and denotes the number of electrons at , is non-decreasing. This fact allows us to conclude that whenever we change from increasing to decreasing at least new neutrons have formed at . Since any neutron at stays put indefinitely, we can charge the run-time contributions of the relabelings of to the number of neutrons at .
Roadmap
2 Preliminaries
Graphs
We let denote the degree vector of graph . For all vertex , we have equal to the number of edges incident to (both incoming and outgoing are counted). Moreover, for any subset of edges we denote by the graph with vertex set and edge set and by the degree vector of the subgraph . We denote by for any , the sum of degrees of vertices in . We denote by for any the set of directed edges in with tail in and head in . We define and . For any partition of , we denote the graph obtained by contracting each partition class to a single vertex by . Two vertices in are adjacent if there is an edge between the corresponding partition classes in . Moreover, for any vertex we denote by the vector with all entries equal to zero apart from the entry at equaling one.
Flows
We call a tuple a flow problem, if is a directed graph, the capacity function is such that for all we have , and denote the source and the sink capacities. We denote flows on as functions such that is anti-symmetric, i.e. . Given a vertex we introduce the notation and likewise Moreover, we write . Given a flow , we say a vertex has excess. We say that it has positive excess if and has negative excess if For a subset , we induce the flow , and the sink , source and edge capacities onto in a function sense and write . Moreover, for any subset , we write for the flow induced by onto the subgraph of consisting only of the edges . We say that a flow is a pseudo-flow if it satisfies the capacity constraints:
We say is a pre-flow if is a pseudo-flow and has no negative excess at any vertex. We say a flow is feasible if it is a pre-flow and additionally no vertex has positive excess. Moreover, for any subset we denote by the sum respectively and for any subset we denote by the sum
Expanders
Given graph , we say a cut is -out sparse if and . We say is a -out expander if it has no -out-sparse cut. We say is a -expander if and , the graph where all edges of are reversed, are both -out expander. The next lemma that is folklore and crucial in our expander pruning argument.
Lemma 3.
Given a -expander , then take and a set of edge deletions . We have that implies
Proof.
If , then .
Graph Embeddings
Given two graphs and over the same vertex set , we say that is an embedding of into if for every edge , is a simple -path in . We define the congestion of an edge induced by the embedding to be the maximum number of paths in the image of that contain . We define the congestion of to be the maximum congestion achieved by any such edge . Moreover, for any edge we will denote by the set of edges such that is an edge on the path . Given an entire set of edges , we denote by the set of edges such that some edge of the path is in . Given two graphs on the same vertex set and embeddings then we denote by the embedding of the graph . We denote by the graph obtained from by reversing all edges. Given an embedding , we denote by the embedding obtained by reversing the direction of all embedding paths.
Expander Decompositions with Witnesses
For the rest of the article, we use a definition of expander decompositions that encodes much more structure than given in Definition 1. In particular, the definition below incorporates the use of witness graphs which are instrumental to our algorithm.
Definition 4.
Given a directed graph , we say is a -out-witness for if 1) is a -out-expander, and 2) embeds into with congestion at most , and 3) . If is a -out-witness for and for , then we say that is a -witness for .
Fact 5.
If is a -out-witness for and is a -out-witness for then is a -witness for .
Proof.
We observe that for any cut
Item 2, 3 are immediate.
The next fact establishes that a -(out-)witness for certifies that is a -(out-) expander, justifying the name witness.
Fact 6 (see [18], Claim 2.1).
If is a -witness for , then is a -expander.
Proof.
For any set , we have in the witness that
Since for any one of these cut edges there is an embedding path crossing the cut and since the congestion of the embedding is at most , we have
Definition 7 (Augmented Expander Decomposition).
We call a collection and a subset a -expander decomposition of a graph , if
-
1.
, has a -witness ,
-
2.
,
-
3.
is a DAG, where .
Given two expander decompositions of the graph and of the graph , where , we say refines if 1) for all partition classes , where , there is a class , where , such that and 2) .
3 The Push-Pull-Relabel Framework
In the push-relabel framework as presented in [14], we are trying to compute a feasible flow for a flow problem by maintaining a pre-flow together with a level function . The algorithm then runs in iterations terminating once has no positive excess at any vertex. In each iteration of the algorithm, the algorithm identifies a vertex that still has positive excess at a vertex . This positive excess is then pushed to neighbors on lower levels such that the capacity constraint is still enforced. If this is not possible is relabeled meaning that its label is increased. In this section, we are extending the push-relabel framework to the dynamic setting, where we allow for increasing the source function and the deletion of edges from . To do so, we need to introduce the notion of negative excess. Because for a flow of the flow problem, it might happen that once we delete an edge there is more flow leaving the vertex than is entering or sourced, i.e. . Hence, we need to extend the discussion to include negative excess in the dynamic version. Similar to the standard push-relabel algorithm, we maintain a pseudo-flow and a vertex labeling in so-called valid states . The only difference is that in the standard push-relabel algorithm, is a pre-flow (not only a pseudo-flow).
Definition 8.
Given a level function and a pseudo-flow , we call a tuple a state for if for all edges having implies
We call the state valid if for all vertices 1) implies , 2) implies
For the remainder of the paper, we have . To provide the reader with some intuition about the definitions, we remark that the pseudo-flow of a valid state is not feasible in the usual sense. Indeed, some vertices might have positive or negative excess. But these vertices are guaranteed to either be at level or at level . Moreover, we point out that if a valid state has no vertices at level , then might still not be a feasible flow since there might be a vertex with . But it is straightforward to obtain from a feasible flow: extract from at each vertex exactly unit flow paths (possibly empty paths starting and ending in ). Let us briefly outline how we will use Lemma 9 in the directed expander pruning algorithm 3. In the directed expander pruning algorithm, we start with an out-expander and an adversary performs a number of vertex or edge deletions. We aim to find a small pruning set of vertices such that if we prune away this small pruning set from the remaining graph, then we can certify that the obtained graph is still an expander. The classical way (see [31]) to either certify expansion of the remaining graph or to find a pruning set is by setting up a flow problem, where we inject for any deletion some additional source flow and where each vertex has sink capacity equal to its degree (this is the reason for the condition in Lemma 9). We will solve this flow problem using the flow provided by our ValidState algorithm (see Algorithm 1). We maintain this flow problem using the interface functions IncreaseSource, RemoveEdges under both adversarial deletions and under necessary pruning deletions. If the valid state computed after any such update has an additional vertex on level , this will indicate that more vertices need to be pruned away. If on the other hand all vertices are on levels strictly below , we will certify that the remaining graph is an expander.
Lemma 9.
Given a flow problem , where . Then, there is a deterministic data structure (see Algorithm 1) that initially computes a valid state and after every update of the form
-
where , we set to ,
-
: where , sets to (initially ),
the algorithm explicitly updates the tuple such that thereafter is a valid state for the current flow instance . The run-time is , where is equal to at the time is deleted and is the variable at the end of the algorithm.
The user interface of the data structure ValidState are the functions Init, IncreaseSource and RemoveEdges. These functions can be used to initialize or update the flow problem. After any such update the internal state has to be updated to remain valid for the new flow problem. To facilitate these necessary updates to these functions make calls to the internal functions PushRelabel and PullRelabel. As described before, the function PushRelabel performs push and relabel operations to handle any positive excess, while the function PullRelabel performs pull and relabel operations to handle any negative excess. Let us take a closer look at the individual functions: using Init we set up the flow problem. It makes an internal call to PushRelabel to compute the first valid state using the standard push-relabel algorithm. Note that at this point no negative excess has been introduced and thus we do not need to resort to any pull operations. The function IncreaseSource can be used to increase the source of the current flow problem and again this does not introduce any negative excess and hence we can again update the valid state using the standard push-relabel algorithm. Using the function RemoveEdges, we can restrict the flow problem to a subgraph. The function induces the capacities and the flow to the subgraph and then makes calls to both PushRelabel and PullRelabel to update the state. The function PushRelabel is just the standard push-relabel algorithm. We look for a vertex with positive excess at level below . We pick a vertex on the lowest level possible. We try to push flow along some unsaturated outgoing edge to a vertex on a lower level. If it is not possible to push flow, we increase the label of the vertex and repeat. The function PullRelabel is the analog of the push-relabel algorithm for negative excess. Here, we look for a vertex with negative excess at level above . We pick a vertex on the highest level possible. We try to pull flow along some unsaturated incoming edge from a vertex on a higher level. If it is not possible to pull flow then all edges where must be saturated and it is safe to decrease the label of the vertex and repeat.
Proof of Lemma 9..
Since we only decrease the node label when all edges , where , are saturated and since we only increase the node label when all edges , where , are saturated, we maintain that is a state. Since we keep on performing push, pull or relabel operations as long as there is a vertex with or , it is guaranteed that the algorithm computes a valid state eventually. It thus suffices to bound the run-time.
Note that by maintaining at each vertex , a linked-list containing all non-saturated edges where , we can implement a push in time . We can maintain such a linked-list for every vertex by spending time every time we relabel a vertex plus time for each push. We maintain a corresponding list for all pull operations. It thus suffices to bound the contribution of the push, pull, and relabel operations to the run-time. Let us index by starting with the push, pull, relabel operations as well as the calls to in the order they occur. We denote by the state of the variables at index . We note that is supported on the edges .
Let us introduce functions where can be interpreted as the amount of positive/ negative units present at vertex at time . These functions will satisfy
| (1) |
Initially, we have where denotes the variable at initialization of the data structure. We describe how evolve over time. If the t-th action is
-
1.
a push of units from to , then
-
2.
a pull of units from to , then
-
3.
, then
-
4.
RemoveEdges(D), then
Clearly and are non-decreasing, we denote the final values by . Let us verify that indeed the transitions above preserve the property in (1). For type 1/2/3 actions, this is immediate. For type 4, we observe that for any vertex when inducing the flow onto every unit of increases the commodity at by one and every unit of decreases the commodity at by one.
Claim 10.
We can bound the size of by
where denotes the final state of the variable.
Proof.
Only IncreaseSource and RemoveEdges can increase . The bound follows immediately from 3, 4 above.
Claim 11.
The contribution to the run-time of the relabeling operations is bounded by
Proof.
Since , we can bound the run-time contribution of the relabeling operations by . It thus suffices to bound this expression. We treat each individually. W.l.o.g. increases at some time , otherwise the contribution of to the sum is trivially zero. Let us consider the following time stamps such that is the first time and
Additionally, we define the time stamps such that
Let us introduce the vector (this corresponds to the neutrons introduced in the introduction). We observe that is non-decreasing. Indeed, if we push away from there must be commodity excess, i.e. or equivalently , and if we pull towards there must be negative commodity excess, i.e. or equivalently . We will now establish that . Consider the time stamps since the -th operation cannot be a push away from and thus . Combining it with the definition of the time stamp , we find
This in turn implies that
where we used in the first and the last inequality that is non-decreasing and in the third the definition of the time stamp . By induction, we have This allows us to bound
where the is due to the fact that is non-decreasing between and non-increasing between . Summing over and bounding concludes the argument.
Claim 12.
The contribution to the run-time of the push operations and the pull operations is bounded by
Proof.
Let us introduce the function . We remark that any push or pull operation of units from to , where , decreases by and increases by at most while preserving all other entries. Hence, any such push or pull operation decreases the function . This allows us to bound the run-time contribution of the push and pull operations by Since at termination the state is valid and thus all vertices with negative excess are on level , we have for all . Together with , this implies that it suffices to bound the increases to . As argued before push and pull operations can only decrease the potential. So let be the subset of indices that do not correspond to a push or a pull. Let us denote by all indices at which we perform a call to IncreaseSource or RemoveEdges. For any we denote by all time indices in where (where for notational convenience). To ease notation, we write
As a first step, we observe
where the first term of the expression is due to the relabeling operations in and the second term is due to the function call at index . Since can only increase if increases, we may thus bound the contribution of a vertex of the second term by
| (2) |
Combining Claim 10, Claim 11, we find that . We may thus subtract and reduce the discussion to bounding the expression
| (3) |
We treat each vertex individually. Let be maximum such that or Let us consider the first term of the expression (3). Note that if then after any push or pull operation at time , we still have that . This implies that for all It thus suffices to consider for each the expression
| (4) |
Let us consider the vertices such that the quantity above is strictly positive. Clearly, or . Let us consider the first case.
Since at time the tuple is valid, we must have that otherwise and hence .
Since can only increase if increases, we can bound
Moreover, the label can only increase during and hence . We may thus bound the contribution of such a vertex to (3) by
| (5) |
If on the other hand , then since at time the tuple is valid we must have that otherwise and hence . Since can only decrease if increases, we can bound
Moreover, the label can only decrease during and hence . We may thus bound the contribution of such a vertex to (3) by
| (6) |
Summing over all time indices and combining Claim 10, Claim 11, we can bound both equation 2, 5, 6 by . This yields the conclusion.
4 Directed Expander Decompositions via the Push-Pull-Relabel Framework
In this section, we discuss our main technical result that states that if is initially a -expander, then an expander decomposition can be maintained efficiently. The algorithm behind this theorem heavily relies on the new push-pull-relabel algorithm presented in the previous section.
Theorem 13.
Given a -expander with -witness , there is a deterministic data structure (see Algorithm 2). After every update of the form
-
: where , sets to (initially ),
the algorithm explicitly updates and the tuple , where and is a partition of (initially ), such that both and are non-decreasing and such that after the update
-
1.
the graph has a -witness ,
-
2.
-
3.
-
4.
is a directed acyclic graph (DAG),
provided . The run-time is , where denotes the variable at the end of all updates and denotes all intercluster edges of the partition .
Following the high-level approach of [31], we obtain our main result Theorem 2 for the special case where is static by running a generalization of the cut-matching game to directed graphs [22, 27] and then apply Theorem 13 to handle unbalanced cuts. Combining this result again with Theorem 13, we obtain our main result Theorem 2 in full generality. Both of these reductions have been known from previous work [2, 18] and are omitted.
4.1 Reduction to Out-Expanders
In this subsection, we show that the task of maintaining an expander decomposition as described in Theorem 13 can be reduced to a simpler problem that only requires maintaining out-expanders (however under edge and vertex deletions). In particular, we reduce to the following statement whose algorithm is deferred to Section 5 and the proof is omitted.
Lemma 14.
For every -out-expander with -witness , there is a deterministic data structure (see Algorithm 3). After every update of the form (initially )
-
: where , sets to ,
-
: where , sets to , to , to to and to
the algorithm explicitly updates and the tuple , where and is a partition of (initially ), such that both and are non-decreasing and such that after the update
-
1.
the graph has a -out-witness ,
-
2.
-
3.
-
4.
, where is equal to at the time is added to ,
provided , where denotes the variable at the end of all updates and denotes all intercluster edges of the partition . The algorithm runs in total time .
We present BiDirectedExpanderPruning (see Algorithm 2), which implements this reduction. The Init function initializes two out-expander pruning data structure. One for the graph with witness with variables and one for the graph with witness with variables . From the guarantees of the one directional DirectedExpanderPruning algorithm, we will have that after each update and are out-expanders. To conclude that the is in fact an expander in both directions, we will ensure using the function AdjustPartition that agree. If they do not agree, we will remove the vertices from using the function RemoveVertices of the algorithm DirectedExpanderPruning (see Algorithm 3). Using the function RemoveEdges of BiDirectedExpanderPruning, we can remove edges from . This is again accomplish by calling the analogous function RemoveEdges of DirectedExpanderPruning for both directions. Again we have to adjust the partition such that agree afterwards. The algorithm and the proof are omitted.
5 Maintaining Out-Expanders
It remains to prove Lemma 14. Algorithm 3 implements of DirectedExpanderPruning. The Init function initializes for an out-expander the expander pruning variables as well as a first valid state of the ValidState algorithm (see Algorithm 1).
This valid state , we will use to find the pruning cuts in function Prune. Using RemoveEdges the user can remove edges from . Removing edges might force us to prune away some part of the and add the pruned part to the collection of pruning sets . To find the pruning set , we adopt a similar strategy as in [31]. We inject additional source flow into the flow problem: for any witness edge , where an edge on the embedding path is in , we increase the sources by . Since we updated the flow problem by increasing the source capacities and removing edges, we need to update the valid state . This new valid state , then allows us to locate the pruning set in the function AdjustPartition. In AdjustPartition, we check whether there is a vertex in the remaining graph on level . If there is no such vertex, it will certify that in fact has already a good out-witness and we don’t need to prune away any subgraph. If on the other hand, there is a vertex on level we will find a pruning set using the function Prune. This set is then added to the collection of pruning sets and the vertices in are removed from . The cut edges are added to the remove edges . Since has become smaller, we need to update the valid state again. We do this once more by injecting additional source at the endpoints of any witness edge , where some edge on the path is in . Thereafter we again check whether in the new valid state there is a vertex in on level . We keep on doing this procedure until there no longer is a vertex on level . We will prove that the volume of the pruning sets can be related to the size of the set of edges initially removed by the user. So far we have not explained how to find the pruning set in function Prune. This is accomplished by a standard level cutting procedure. We start with being all vertices on level and then check whether the vertices on the next level have volume at least . If it is the case, we add vertices on the next level to and otherwise return . Through the function RemoveVertices the user can remove vertices from . Similar to the function RemoveEdges, we will have to inject additional source at the endpoints of the witness edges , where some edge of is in , and update the valid state accordingly. This might again leave some vertices on level and will again force us to prune some vertices. This is again accomplished by a call to AdjustPartition. And similar to RemoveEdges, we will again prove that the volume of the pruning sets can be related to the volume of the set initially removed by the user.
References
- [1] Aaron Bernstein, Joakim Blikstad, Thatchaphol Saranurak, and Ta-Wei Tu. Maximum flow by augmenting paths in time. to appear at FOCS’24, 2024.
- [2] Aaron Bernstein, Maximilian Probst Gutenberg, and Thatchaphol Saranurak. Deterministic decremental reachability, scc, and shortest paths via directed expanders and congestion balancing. In 2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS), pages 1123–1134. IEEE, 2020. doi:10.1109/FOCS46700.2020.00108.
- [3] Aaron Bernstein, Maximilian Probst Gutenberg, and Thatchaphol Saranurak. Deterministic decremental sssp and approximate min-cost flow in almost-linear time. In 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), pages 1000–1008. IEEE, 2022.
- [4] Aaron Bernstein, Maximilian Probst Gutenberg, and Christian Wulff-Nilsen. Near-optimal decremental sssp in dense weighted digraphs. In 2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS), pages 1112–1122. IEEE, 2020. doi:10.1109/FOCS46700.2020.00107.
- [5] Aaron Bernstein, Jan van den Brand, Maximilian Probst Gutenberg, Danupon Nanongkai, Thatchaphol Saranurak, Aaron Sidford, and He Sun. Fully-dynamic graph sparsifiers against an adaptive adversary. In 49th International Colloquium on Automata, Languages, and Programming (ICALP 2022). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2022.
- [6] Parinya Chalermsook, Syamantak Das, Yunbum Kook, Bundit Laekhanukit, Yang P Liu, Richard Peng, Mark Sellke, and Daniel Vaz. Vertex sparsification for edge connectivity. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1206–1225. SIAM, 2021. doi:10.1137/1.9781611976465.74.
- [7] Li Chen, Rasmus Kyng, Yang P Liu, Simon Meierhans, and Maximilian Probst Gutenberg. Almost-linear time algorithms for incremental graphs: Cycle detection, sccs, - shortest path, and minimum-cost flow. to appear at STOC’24, 2024.
- [8] Li Chen, Rasmus Kyng, Yang P Liu, Richard Peng, Maximilian Probst Gutenberg, and Sushant Sachdeva. Maximum flow and minimum-cost flow in almost-linear time. In 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), pages 612–623. IEEE, 2022. doi:10.1109/FOCS54457.2022.00064.
- [9] Julia Chuzhoy. Decremental all-pairs shortest paths in deterministic near-linear time. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 626–639, 2021. doi:10.1145/3406325.3451025.
- [10] Julia Chuzhoy and Sanjeev Khanna. A new algorithm for decremental single-source shortest paths with applications to vertex-capacitated flow and cut problems. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pages 389–400, 2019. doi:10.1145/3313276.3316320.
- [11] Julia Chuzhoy and Sanjeev Khanna. A faster combinatorial algorithm for maximum bipartite matching. In Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2185–2235. SIAM, 2024. doi:10.1137/1.9781611977912.79.
- [12] Julia Chuzhoy and Sanjeev Khanna. Maximum bipartite matching in time via a combinatorial algorithm. to appear at STOC’24, 2024.
- [13] Julia Chuzhoy and Thatchaphol Saranurak. Deterministic algorithms for decremental shortest paths via layered core decomposition. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2478–2496. SIAM, 2021. doi:10.1137/1.9781611976465.147.
- [14] Andrew V Goldberg and Robert E Tarjan. A new approach to the maximum-flow problem. Journal of the ACM (JACM), 35(4):921–940, 1988. doi:10.1145/48014.61051.
- [15] Gramoz Goranci, Harald Räcke, Thatchaphol Saranurak, and Zihan Tan. The expander hierarchy and its applications to dynamic graph algorithms. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2212–2228. SIAM, 2021. doi:10.1137/1.9781611976465.132.
- [16] Monika Henzinger, Satish Rao, and Di Wang. Local flow partitioning for faster edge connectivity. SIAM Journal on Computing, 49(1):1–36, 2020. doi:10.1137/18M1180335.
- [17] Dorit S Hochbaum. The pseudoflow algorithm: A new algorithm for the maximum-flow problem. Operations research, 56(4):992–1009, 2008. doi:10.1287/OPRE.1080.0524.
- [18] Yiding Hua, Rasmus Kyng, Maximilian Probst Gutenberg, and Zihang Wu. Maintaining expander decompositions via sparse cuts. In Proceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 48–69. SIAM, 2023. doi:10.1137/1.9781611977554.CH2.
- [19] Wenyu Jin and Xiaorui Sun. Fully dynamic st edge connectivity in subpolynomial time. In 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), pages 861–872. IEEE, 2022.
- [20] Wenyu Jin, Xiaorui Sun, and Mikkel Thorup. Fully dynamic min-cut of superconstant size in subpolynomial time. In Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2999–3026. SIAM, 2024. doi:10.1137/1.9781611977912.107.
- [21] Jonathan A Kelner, Yin Tat Lee, Lorenzo Orecchia, and Aaron Sidford. An almost-linear-time algorithm for approximate max flow in undirected graphs, and its multicommodity generalizations. In Proceedings of the twenty-fifth annual ACM-SIAM symposium on Discrete algorithms, pages 217–226. SIAM, 2014. doi:10.1137/1.9781611973402.16.
- [22] Rohit Khandekar, Satish Rao, and Umesh Vazirani. Graph partitioning using single commodity flows. Journal of the ACM (JACM), 56(4):1–15, 2009. doi:10.1145/1538902.1538903.
- [23] Rasmus Kyng, Simon Meierhans, and Maximilian Probst Gutenberg. A dynamic shortest paths toolbox: Low-congestion vertex sparsifiers and their applications. to appear at STOC’24, 2024.
- [24] Rasmus Kyng, Simon Meierhans, and Maximilian Probst. Derandomizing directed random walks in almost-linear time. In 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), pages 407–418. IEEE, 2022. doi:10.1109/FOCS54457.2022.00046.
- [25] Jason Li. Deterministic mincut in almost-linear time. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 384–395, 2021. doi:10.1145/3406325.3451114.
- [26] Yang P Liu. Vertex sparsification for edge connectivity in polynomial time. In 14th Innovations in Theoretical Computer Science Conference (ITCS 2023). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2023.
- [27] Anand Louis. Cut-matching games on directed graphs. arXiv preprint arXiv:1010.1047, 2010. arXiv:1010.1047.
- [28] Danupon Nanongkai and Thatchaphol Saranurak. Dynamic spanning forest with worst-case update time: adaptive, las vegas, and o (n1/2-)-time. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, pages 1122–1129, 2017. doi:10.1145/3055399.3055447.
- [29] Danupon Nanongkai, Thatchaphol Saranurak, and Christian Wulff-Nilsen. Dynamic minimum spanning forest with subpolynomial worst-case update time. In 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS), pages 950–961. IEEE, 2017. doi:10.1109/FOCS.2017.92.
- [30] Thatchaphol Saranurak. A simple deterministic algorithm for edge connectivity. In Symposium on Simplicity in Algorithms (SOSA), pages 80–85. SIAM, 2021. doi:10.1137/1.9781611976496.9.
- [31] Thatchaphol Saranurak and Di Wang. Expander decomposition and pruning: Faster, stronger, and simpler. In Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 2616–2635. SIAM, 2019. doi:10.1137/1.9781611975482.162.
- [32] Daniel A Spielman and Shang-Hua Teng. Nearly-linear time algorithms for graph partitioning, graph sparsification, and solving linear systems. In Proceedings of the thirty-sixth annual ACM symposium on Theory of computing, pages 81–90, 2004. doi:10.1145/1007352.1007372.
- [33] Jan Van Den Brand, Li Chen, Rasmus Kyng, Yang P Liu, Simon Meierhans, Maximilian Probst Gutenberg, and Sushant Sachdeva. Almost-linear time algorithms for decremental graphs: Min-cost flow and more via duality. to appear at FOCS’24, 2024.
- [34] Jan Van Den Brand, Li Chen, Richard Peng, Rasmus Kyng, Yang P Liu, Maximilian Probst Gutenberg, Sushant Sachdeva, and Aaron Sidford. A deterministic almost-linear time algorithm for minimum-cost flow. In 2023 IEEE 64th Annual Symposium on Foundations of Computer Science (FOCS), pages 503–514. IEEE, 2023. doi:10.1109/FOCS57990.2023.00037.
- [35] Jan Van Den Brand, Yin Tat Lee, Yang P Liu, Thatchaphol Saranurak, Aaron Sidford, Zhao Song, and Di Wang. Minimum cost flows, mdps, and l1-regression in nearly linear time for dense instances. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 859–869, 2021. doi:10.1145/3406325.3451108.
- [36] Christian Wulff-Nilsen. Fully-dynamic minimum spanning forest with improved worst-case update time. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, pages 1130–1143, 2017. doi:10.1145/3055399.3055415.