Identifying Approximate Minimizers Under Stochastic Uncertainity

Abstract
We study a fundamental stochastic selection problem involving independent random variables, each of which can be queried at some cost. Given a tolerance level , the goal is to find a -approximately minimum (or maximum) value over all the random variables, at minimum expected cost. A solution to this problem is an adaptive sequence of queries, where the choice of the next query may depend on previously-observed values. Two variants arise, depending on whether the goal is to find a -minimum value or a -minimizer. When all query costs are uniform, we provide a -approximation algorithm for both variants. When query costs are non-uniform, we provide a -approximation algorithm for the -minimum value and a -approximation for the -minimizer. All our algorithms rely on non-adaptive policies (that perform a fixed sequence of queries), so we also upper bound the corresponding “adaptivity” gaps. Our analysis relates the stopping probabilities in the algorithm and optimal policies, where a key step is in proving and using certain stochastic dominance properties.
Keywords and phrases:
Approximation algorithms, stochastic optimization, selection problemCategory:
Track A: Algorithms, Complexity and GamesFunding:
Hessa Al-Thani: This publication was made possible by the Graduate Sponsorship Research Award from the Qatar Research and Development Institute. The findings herein reflect the work, and are solely the responsibility, of the authors.Copyright and License:
2012 ACM Subject Classification:
Theory of computation Stochastic approximation ; Theory of computation Discrete optimizationEditors:
Keren Censor-Hillel, Fabrizio Grandoni, Joël Ouaknine, and Gabriele PuppisSeries and Publisher:
1 Introduction
We study a natural stochastic selection problem that involves querying a set of random variables so as to identify their minimum (or maximum) value within a desired precision. Consider a car manufacturer who wants to chose one design from options so as to optimize some attribute (e.g., maximum velocity or energy efficiency). Each option corresponds to an attribute value which is uncertain and drawn from a known probability distribution. It is possible to determine the exact value of by further testing – but this incurs some cost . Identifying the exact minimum (or maximum) value among the s might be too expensive. Instead, our goal is to identify an approximately minimum (or maximum) value, within a prescribed tolerance level. For example, we might be satisfied with a value (and corresponding option) that is within % of the true minimum. The objective is to minimize the expected cost. In this paper, we provide the first constant-factor approximation algorithm for this problem.
Our problem is related to two lines of work: stochastic combinatorial optimization and optimization under explorable uncertainty. In stochastic combinatorial optimization, a solution makes selections incrementally and adaptively (i.e., the next selection can depend on previously observed random outcomes). An optimal solution here may even require exponential space to describe. Nevertheless, there has been much recent success in obtaining (efficient) approximation algorithms for such problems, see e.g., [7, 14, 5, 15, 12, 19, 20, 17, 18]. Optimization problems under explorable uncertainty involve querying values drawn from known intervals in order to identify a minimizer. Typically, these results focus on the competitive ratio, which relates the algorithm’s (expected) query cost to the optimum query-cost in hindsight, see e.g., [21, 6, 10, 9, 22, 8, 4, 23]. In particular, for the problem of finding an exact minimizer among intervals, [21] obtained a 2-competitive algorithm in the adversarial setting and [6] obtained a -approximation algorithm in the stochastic setting. The problem we study is a significant generalization of the stochastic exact minimizer problem [6].
1.1 Problem Definition
In the stochastic minimum query () problem, there are independent discrete random variables that lie in intervals respectively. The random variables (r.v.s) may be negative. We assume that each interval is bounded and closed, i.e., for each . We also assume (without loss of generality) that each r.v. has non-zero probability at the endpoints of its interval, i.e., and for each .111Otherwise, we can just work with a smaller interval representing the same r.v. We will use the terms random variable (r.v.) and interval interchangeably. The exact value of any r.v. can only be determined by querying it, which incurs some cost . Additionally, we are given a “precision” value , where the goal is to identify the minimum value over all r.v.s up to an additive precision of . Formally, if then we want to find a deterministic value such that . Such a value is called a -minimum value. The objective in is to minimize the expected cost of the queried intervals. Note that it may be sufficient to probe only a (small) subset of intervals before stopping.
We also consider a related, but harder, problem where the goal is to identify some -minimizer , i.e., an interval that satisfies . We refer to this problem as stochastic minimum query for identification (). If a -minimum value is found then it also provides a -minimizer (see §1.4). However, the converse is not true. So, an solution may return an un-queried a -minimizer without determining a -minimum value.
Although our formulation above uses additive precision (we aim to find a value that is at most ), we can also handle multiplicative precision where the goal is to find a value that is at most . This just requires a simple logarithmic transformation; see Appendix A. We can also handle the goal of finding the maximum value by working with negated r.v.s .
Throughout, we use to denote the index set of the r.v.s.
Adaptive and Non-adaptive policies.
Any solution to involves querying r.v.s sequentially until a -minimum value is found. In general, the sequence of queries may depend on the realizations of previously queried r.v.s. We refer to such solutions as adaptive policies. Formally, such a solution can be described as a decision tree where each node corresponds to the next r.v. to query and the branches out of a node represent the realization of the queried r.v. Non-adaptive policies are a special class of solutions where the sequence of queries is fixed upfront: the policy then performs queries in this order until a -minimum value is found. A central notion in stochastic optimization is the adaptivity gap [7], which is the worst-case ratio between the optimal non-adaptive value and the optimal adaptive value. All our algorithms produce non-adaptive policies and hence also bound the adaptivity gap.
1.2 Results
Our first result is on the problem with unit costs, for which we provide a -approximation algorithm. Moreover, we achieve this result via a non-adaptive policy, which also proves an upper bound of on the adaptivity gap. This algorithm relies on combining two natural policies. The first policy simply queries the r.v. with the smallest left-endpoint. The second policy queries the r.v. that maximizes the probability of stopping in the very next step. When used in isolation, both these policies have unbounded approximation ratios. However, interleaving the two policies leads to a constant-factor approximation algorithm.
We also consider the (harder) unit-cost problem and show that the same policy leads to a -approximation algorithm: the only change is in the criterion to stop, which is now more relaxed. While the algorithm is the same as , the analysis for is significantly more complex due to the new stopping criterion, which allows us to infer a -minimizer even when it has not been queried. Specifically, we prove a stochastic dominance property between r.v.s in our algorithm and the optimum (conditioned on the stopping criterion not occurring), and use this in relating the stopping-probability in the algorithm and the optimum.
Our next result is for the problem with non-uniform costs. We obtain a constant-factor approximation again, with a slightly worse ratio of . This is based on combining ideas from the unit-cost algorithm with a “power-of-two” approach. In particular, the algorithm proceeds in several iterations, where the iteration incurs cost roughly . In each iteration , the algorithm selects a subset of r.v.s with cost based on the following two criteria (i) smallest left-endpoint and (ii) maximum probability of stopping in one step. In order to select the r.v.s for criterion (ii) we need to use a PTAS for an appropriate version of the knapsack problem.
Finally, we consider the problem with non-uniform costs. Directly using the algorithm for (as in the unit-cost case) does not work here: it leads to a poor approximation ratio. However, a modification of the algorithm works. Specifically, we modify step (i) above: instead of just selecting a prefix of intervals with the smallest left-endpoints, we select an “almost prefix” set by skipping some expensive intervals. We show that this approach leads to an approximation ratio of , which is slightly worse than what we obtain for . The analysis combines aspects of unit-cost and with non-uniform costs.
1.3 Related Work
Computing an approximately minimum or maximum value by querying a set of random variables is a central question in stochastic optimization. Most of the prior works on this topic have focused on budgeted variants. Here, one wants to select a subset of queries of total cost within some budget so as to maximize or minimize the value among the queried r.v.s. The results for the minimization and maximization versions are drastically different. A approximation algorithm for the budgeted max-value problem follows from results on stochastic submodular maximization [3]; more complex “budget” constraints can also be handled in this setting [1, 16]. These results also bound the adaptivity gap. In addition, PTASes are known for non-adaptive and adaptive versions of budgeted max-value [11, 24]. For the budgeted min-value problem, it is known that the adaptivity gap is unbounded and results for the non-adaptive and adaptive versions are based on entirely different techniques. [13] obtained a bi-criteria approximation algorithm for the non-adaptive problem (the queried subset must be fixed upfront) that achieves a approximation to the optimal value while exceeding the budget by at most an factor, where each r.v. takes an integer value in the range . Subsequently, [26] studied the adaptive setting (the queried subset may depend on observed realizations) and obtained a -approximation while exceeding the budget by at most an factor. In contrast to these results, the goal in is to achieve a value close to the true minimum/maximum taken over all random variables (not just the queried ones). Moreover, we want to find an approximately min/max value with probability one, as opposed to optimizing the expected min/max value.
A different formulation of the minimum-element problem is studied in [25]: this combines the query-cost and the value of the minimum-queried element into a single objective. They obtain an exact algorithm for this setting, which also extends to a wider class of constrained problems.
Closely related to our work, [6] studied the problem with exact precision, i.e., . In particular, their goal is to identify an interval that is an exact minimizer. [6] obtained a -approximation ratio for general query costs. The problem that we study allows for arbitrary precision , and is significantly more complex than the setting in [6]. One indication of the difficulty of handling arbitrary is that the simpler problem with (where we want to find the exact minimum value) admits a straightforward exact algorithm that queries by increasing left-endpoint; however, this algorithm has an unbounded ratio for with arbitrary (see §2 for an example).
As mentioned earlier, the problem is also related to optimization problems under explorable uncertainty. Apart from the minimum-value problem [21], various other problems like computing the median [10], minimum spanning tree [9, 22] and set selection [8, 4, 23] have been studied in this setting. The key difference from our work is that these results focus on the competitive ratio. In contrast, we compare to the optimal policy that is limited in the same manner as the algorithm. We note that there is an lower bound on the competitive ratio for and ; see Appendix B. Our results show that much better (constant) approximation ratios are achievable for and in the stochastic setting, relative to an optimal policy.
1.4 Preliminaries
Stopping rule for SMQ.
Even without querying any interval, we know that the minimum value is at most , the minimum right-endpoint. In order to simplify notation, we incorporate this information using a dummy r.v. that is queried at the start of any policy and incurs no cost. We now formally define the condition under which a policy for is allowed to stop. We will refer to the partial observations at any point in a policy (i.e., values of r.v.s queried so far) as the state. Consider any state, given by a subset of queried r.v.s along with their observations . The minimum observed value is and the minimum possible value among the un-queried r.v.s is . The stopping criterion is:
| (1) |
If this criterion is met then is guaranteed to satisfy , where . Also, is a -minimizer. On the other hand, if this criterion is not met then there is no value that guarantees : there is a non-zero probability that the minimum value is or (and these values are more than apart). So,
Proposition 1.1.
A policy for can stop if and only if criterion (1) holds.
The stopping rule for is described in §2.2. An policy can stop either due to the stopping rule (above) or by inferring an un-queried interval as a -minimizer.
Adaptivity gap.
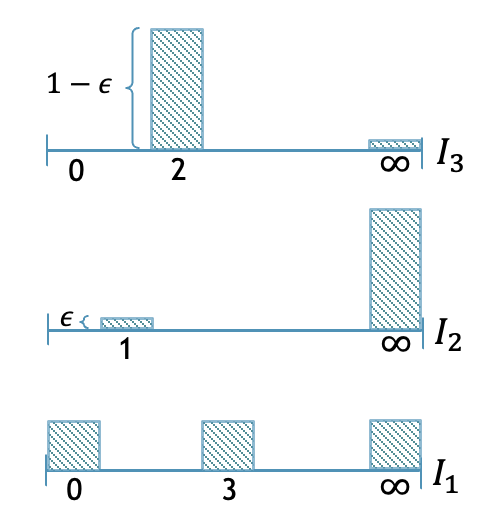
We show that the adaptivity gap for the problem is more than one: so adaptive policies may indeed perform better. This example also builds some intuition for the problem. Consider an instance with three intervals as shown in Figure 2. In particular, , , and . Let . An adaptive policy is shown in Figure 2, which has cost at most . We present a case analysis in [2] and show that the best non-adaptive cost is . Setting , we obtain an adaptivity gap of . We can also modify this instance slightly to get a worse adaptivity gap of .
Fixed threshold problem.
In our analysis, we relate to the following simpler problem. Given r.v.s with costs as before, a fixed threshold and budget , find a policy having query-cost at most that maximizes the probability of observing a realization less than . A useful property of this fixed threshold problem is that it has adaptivity gap one [2].
Proposition 1.2.
Consider any instance of the fixed threshold problem. Let and denote the maximum success probabilities over adaptive and non-adaptive policies respectively. Then,
2 Algorithm for Unit Costs
Before presenting our algorithm, we discuss two simple greedy policies and show why they fail to achieve a good approximation.
-
1.
A natural approach is to select intervals by increasing left-endpoint. Indeed, [21] shows that this algorithm is optimal when , even in an online setting (with open intervals). Consider the instance with two types of intervals as shown in Figure 3. The r.v.s are identically distributed with w.p. and otherwise. The remaining r.v.s are identically distributed with w.p. and otherwise. The greedy policy queries r.v.s in the order , resulting in an expected cost of as it can stop only when it observes a “low” realization for some r.v. However, the policy that probes in the reverse order has constant expected cost: the policy can stop upon observing any “low” realization (even if a value of is observed, it is guaranteed to be within of the true minimum). So the approximation ratio of this greedy policy is .
Figure 3: Bad example for greedy by left-endpoint. -
2.
A different greedy policy (based on the instance in Figure 3) is to always select the interval that maximizes the likelihood of stopping in one step. Now consider another instance with three types of intervals; see Figure 4. The r.v. is always . The r.v. takes value w.p. and has value otherwise. The remaining r.v.s are identically distributed with w.p. and otherwise. As long as is not queried, the probability of stopping (in one step) is as follows: for , for and zero for . So this greedy policy will query in the order resulting in an expected cost. On the other hand, querying the r.v.s and guarantees that the policy can stop. So the optimal cost is at most , implying an approximation ratio.
Figure 4: Bad example for greedy by stopping probability.
Our approach is to interleave the above two greedy criteria. In particular, each iteration of our algorithm makes two queries: the interval with the smallest left-endpoint and the interval that maximizes the probability of stopping in one step. We will show that this leads to a constant-factor approximation. We first re-number intervals by increasing order of their left-endpoint, i.e., . For each , let . Algorithm 1 describes our algorithm formally.
Equivalently, we can view Algorithm 1 as first computing the permutation (without querying) and then performing queries in the order given by until the stopping criterion is met. Note that Algorithm 1 is non-adaptive because it uses observations only to determine when to stop. So, our analysis also upper bounds the adaptivity gap.
We overload notation slightly and use to also denote the non-adaptive policy given in Algorithm 1. Note that each iteration in this policy involves two queries. We use to denote the optimal (adaptive) policy. Let and denote the expected number of queries in policies and , respectively. The key step in the analysis is to relate the termination probabilities in these two policies, formalized below.
Lemma 2.1.
For any , we have
We will prove this lemma in the next subsection. First, we complete the analysis using this.
Theorem 2.2.
We have .
Proof.
Let denote the random variable that captures the number of queries made by the optimal policy . Similarly, let denote the number of queries made by our policy. Using Lemma 2.1 and the fact that policy makes two queries in each iteration, for any we have
| (2) |
Hence,
| (3) |
The first equality in (3) is by a change of variables .
2.1 Proof of Key Lemma
We now prove Lemma 2.1. Fix any and define threshold .
Let denote the optimal solution to the non-adaptive “fixed threshold” problem:
| (4) |
We then proceed in two steps, as follows.
The first inequality is shown in Lemma 2.3: this uses the fact that the fixed-threshold problem has adaptivity gap one (Proposition 1.2). The second inequality is shown in Lemma 2.4: this relies on the greedy criteria used in our algorithm.
Lemma 2.3.
.
Proof.
Let denote the optimal policy truncated after queries: so the cost of is always at most . Let denote the smallest un-queried left-endpoint at the end of ; this is a random value because is an adaptive policy. Then,
| (5) | ||||
| (6) | ||||
| (7) |
Equality (5) is by the stopping criterion for . The inequality in (6) uses the observation that after any queries, the smallest un-queried left-endpoint must be at most : so always. The equality in (6) is by definition of the threshold . Inequality (7) follows from Proposition 1.2: we view is a feasible adaptive policy for the fixed-threshold problem and is the optimal non-adaptive policy.
Lemma 2.4.
.
Proof.
Recall that each iteration of Algorithm 1 selects two intervals: in Step 3 and in Step 4. Let be the set of intervals chosen by our policy in Step 4 of the first iterations. We partition into and . Let .
| (8) | ||||
| (9) | ||||
| (10) |
(8) follows from the definition of . (10) just uses that and are disjoint subsets of . The key step above is (9), which we prove using two cases:
-
Suppose that . Then, using we obtain , which proves (9) for this case.
-
Suppose that . In this case, is well-defined. We now claim that:
(11) Indeed, consider any such and suppose that . As is a valid choice for , the greedy rule implies:
Further, using the fact that , we get
which proves (11). Let denote the number of iterations where . Note that , where we used . Using (11), it follows that for all . Hence,
Combined with the fact that (as before), we obtain (9).
We are now ready to complete the proof. Using the stopping criterion and the fact that queries all the intervals in within iterations,
Combined with (10),
where we use the definition .
2.2 Finding the minimum interval
In this section, we consider the problem, where the goal is to identify an interval that is guaranteed to be a -minimizer. Unlike the previous setting (where we find a -minimum value), for we just want to identify some interval such that . Recall that . It is important to note that the interval may not have been queried. It is easy to see that any policy is also feasible to . Indeed, by the stopping rule (1) for , the -minimum value returned is always the minimum value of a queried interval: so we also identify . However, an policy may return an interval without querying it. So the optimal value of may be smaller than .
Remark.
We note that the optimal values of and differ by at most the maximum query cost . As noted above, the optimal value is at most that of . On the other hand, the optimal value is at most the optimal value plus the cost to query . In the unit-cost setting, and any policy has expected cost at least : so the optimal values of and are within a factor two of each other. This immediately implies that Algorithm 1 is also an -approximation for unit-cost . In the rest of this subsection, we will prove a stronger result, that Algorithm 1 is a -approximation for . Apart from the improved constant factor, these ideas will also be helpful for with general costs. We note that under general costs, the optimal and values may differ by an arbitrarily large factor because is not a lower bound on the optimal value.
Stopping criteria for SMQI.
Consider any state, given by a subset of queried r.v.s along with their observations . There are two conditions under which the policy can stop.
-
The first stopping rule is just the one for (1), which corresponds to the situation that interval is queried. We restate this rule below for easy reference:
(12) In this case, we return . We refer to this as the old stopping rule.
-
The second stopping rule handles the situation where an un-queried interval is returned. For any , define the “almost prefix” set . Note that either or is a prefix of . (As before, we assume that intervals are indexed by increasing order of their left-endpoint, i.e., .) The new rule is:
(13) In other words, there is some interval where (1) all intervals with left-endpoint have been queried, and (2) the minimum value of these r.v.s is at least . In this case, we return (we may not know a -minimum value). We refer to this as the new stopping rule. See Figure 5 for an example.
Our algorithm for with unit costs remains the same as for (Algorithm 1). The only difference is in the new stopping criterion (described above). Recall that is the permutation used by our non-adaptive policy. When it is clear from the context, we will also use to denote our policy that performs queries in the order of until stopping criteria (12) or (13) applies.
Theorem 2.6.
The non-adaptive policy is a -approximation algorithm for .
We now prove this result. Let denote an optimal adaptive policy for . For any , we will show:
| (14) |
This would suffice to prove the -approximation, exactly as in Theorem 2.2.
Handling the old stopping criterion.
Let denote the smallest un-queried left-endpoint at the end of iteration in . Note that is a deterministic value as is a non-adaptive policy. Moreover, as would have queried the first r.v.s. Let be the event that for all intervals queried by in its first iterations. In other words, is precisely the event that stopping criterion (12) does not apply at the end of iteration in , i.e., . By Lemma 2.4,
Similarly, let be that event that for all intervals in the first queries of . From the proof of Lemma 2.3, we obtain and
Combining the above two inequalities, we have
| (15) |
Handling the new stopping criterion.
Let be the event that for all r.v.s . Similarly, let be the event that for all . Clearly,
| (16) |
We will now prove that
| (17) |
If finishes due to (13) in queries then : otherwise which contradicts with the fact that all r.v.s in must be queried. Let be all such intervals. It now follows that the event (which corresponds to policy ) is a subset of the event
| (18) |
Note that is independent of the policy: it only depends on the realizations of the r.v.s (and doesn’t depend on whether/not an interval has been queried).
Moreover, our policy queries all the r.v.s in within iterations. So, for all , the r.v.s in are queried by in iterations. Hence, event (which corresponds to policy ) contains event .
Recall that the event (resp. ) in policy (resp. ) means that every r.v. is more than (resp. ). Also, , which means
In other words, for any , if (resp. ) is the r.v. conditioned on (resp. ) then stochastically dominates .222We say that r.v. stochastically dominates if for all . Note also that the r.v.s s (resp. s) are independent. Using the fact that event corresponds to a monotone function, we obtain:
Lemma 2.7.
Let and be independent r.v.s such that stochastically dominates for each . Then, where event is a function of independent r.v.s as defined in (18).
Proof.
It suffices to prove the following.
Note that the r.v.s above only differ at position . To keep notation simple, for any let if and if . So, we need to show . We condition on the realizations of the r.v.s. For each let denote the realization of the r.v. . Having conditioned on these r.v.s, the only randomness is in and . We will show:
| (19) |
Using the definition of the event from (18), let . In other words, corresponds to those “clauses” in (18) that have not evaluated to true or false based on the realizations . If there is some clause in (18) that already evaluates to true (based on ) then holds regardless of or . So, (19) holds in this case (both terms are one). Now, we assume that no clause in (18) already evaluates to true. We can write
where is a deterministic value.333If then we set . Similarly, we have
Using the fact that (resp. ) is independent of and that stochastically dominates ,
This completes the proof of (19). De-conditioning the r.v.s, we obtain as desired.
Wrapping up.
3 Algorithm for General Costs
We now consider the problem with non-uniform query costs. The high-level idea is similar to the unit-cost case: interleaving the two greedy criteria of smallest left-endpoint and highest probability of stopping. However, we need to incorporate the costs carefully. To this end, we use an iterative algorithm that in every iteration , makes a batch of queries having total cost about . (In order to optimize the approximation ratio, we use a generic base for the exponential costs.)
We extend the algorithm and analysis in this section to get a 7.47 approximation for the with non-uniform costs in [2].
For any subset , let denote the cost of querying all intervals in . Again, we renumber intervals so that .
Definition 3.1.
For any , let be the maximal prefix of intervals having cost at most .
The complete algorithm is given in Algorithm 2. The optimization problem (KP) solved in Step 5 is a variant of the classic knapsack problem: in Theorem 3.2 we provide a bicriteria approximation algorithm for (KP) for any constant . In particular, this ensures that and
Note that the left-hand-side above equals as all r.v.s are independent.
Theorem 3.2.
Given discrete random variables with costs , budget and threshold , there is an time algorithm that finds such that and , for any . Here,
Furthermore, just like Algorithm 1, we can view Algorithm 2 as first computing the permutation (without querying) and then performing queries in that order until the stopping criterion. So, our algorithm is a non-adaptive policy and our analysis also upper-bounds the adaptivity gap.
3.1 Analysis
We use to denote the optimal (adaptive) policy and to denote our non-adaptive policy.
Definition 3.3.
For any , let
Similarly, for our policy we define
We also define to be the optimal policy truncated at cost , i.e., the total cost of queried intervals is always at most . Similarly, we define to be our policy truncated at the end of iteration .
The key part of the analysis lies in relating the non-stopping probabilities and in the optimal and algorithmic policies: see Lemma 3.5. Our first lemma bounds the (worst-case) cost incurred in iterations of our policy.
Lemma 3.4.
The cost of our policy until the end of iteration is
Proof.
We handle separately the costs of intervals queried in Steps 3 and 6. The total cost incurred in Step 3 of the first iterations is : this uses because are prefixes. The total cost due to Step 6 can be bounded using a geometric series:
The inequality above is by the cost guarantee for (KP). The lemma now follows.
Lemma 3.5.
For all , we have .
Proof.
Recall that denotes the optimal policy truncated at cost . We let be the smallest un-queried left-endpoint: this is a random value as is adaptive. In the algorithm, consider iteration and let ; note that the threshold in Step 4. Let denote the list after Step 3 in iteration . Note that the optimization in (KP) of iteration is over , which yields . Also, .
| (21) | ||||
| (22) | ||||
| (23) | ||||
| (24) | ||||
| (25) | ||||
| (26) |
The equality in (21) is given by the definition of and the stopping rule. The inequality in (21) uses the fact that always, which in turn is because has cost at most and is the maximal prefix within this cost. The inequality in (22) uses . The inequality in (23) is by Proposition 1.2: we view as a feasible adaptive policy for the fixed-threshold problem with threshold and budget . The equality in (24) follows from independence of the random variables. The first equality in (25) uses the definition of from (KP) and independence. The first inequality in (26) uses the choice of and Theorem 3.2. The equality in (26) is by . To see the last inequality in (26), note that if then finishes by iteration .
In Lemma 3.6 we lower bound the expected cost of the optimal policy. Let and denote the expected cost of our greedy policy and the optimal policy, respectively.
Lemma 3.6.
For any base , we have .
Proof.
Let denote the random variable that represents the cost of the optimal policy : so . Let be the indicator variable for when ; so . We now show that:
| (27) |
To see this, suppose that for some integer . Then the left-hand-side of (27) equals
which proves (27). Taking the expectation of (27) proves the lemma.
Theorem 3.7.
There is a -approximation for the problem with general costs.
Proof.
By Lemma 3.4, we have . Now,
| (28) | ||||
| (29) |
The inequality in (28) is by Lemma 3.4 and . The first inequality in (29) uses and the second inequality is by Lemma 3.6.
Hence, we obtain . Now, optimizing for , we obtain the stated approximation ratio.
References
- [1] Marek Adamczyk, Maxim Sviridenko, and Justin Ward. Submodular stochastic probing on matroids. Math. Oper. Res., 41(3):1022–1038, 2016. doi:10.1287/MOOR.2015.0766.
- [2] Hessa Al-Thani and Viswanath Nagarajan. Identifying approximate minimizers under stochastic uncertainty, 2025. arXiv:2504.17019.
- [3] Arash Asadpour and Hamid Nazerzadeh. Maximizing stochastic monotone submodular functions. Manag. Sci., 62(8):2374–2391, 2016. doi:10.1287/MNSC.2015.2254.
- [4] Evripidis Bampis, Christoph Dürr, Thomas Erlebach, Murilo Santos de Lima, Nicole Megow, and Jens Schlöter. Orienting (hyper)graphs under explorable stochastic uncertainty. In 29th Annual European Symposium on Algorithms (ESA), volume 204 of LIPIcs, pages 10:1–10:18, 2021. doi:10.4230/LIPICS.ESA.2021.10.
- [5] N. Bansal, A. Gupta, J. Li, J. Mestre, V. Nagarajan, and A. Rudra. When LP is the cure for your matching woes: Improved bounds for stochastic matchings. Algorithmica, 63(4):733–762, 2012. doi:10.1007/S00453-011-9511-8.
- [6] Steven Chaplick, Magnús M. Halldórsson, Murilo S. de Lima, and Tigran Tonoyan. Query minimization under stochastic uncertainty. Theoretical Computer Science, 895:75–95, 2021. doi:10.1016/J.TCS.2021.09.032.
- [7] B. C. Dean, M. X. Goemans, and J. Vondrák. Approximating the stochastic knapsack problem: The benefit of adaptivity. Math. Oper. Res., 33(4):945–964, 2008. doi:10.1287/MOOR.1080.0330.
- [8] Thomas Erlebach, Michael Hoffmann, and Frank Kammer. Query-competitive algorithms for cheapest set problems under uncertainty. Theoretical Computer Science, 613:51–64, 2016. doi:10.1016/J.TCS.2015.11.025.
- [9] Thomas Erlebach, Michael Hoffmann, Danny Krizanc, Matús Mihal’Ák, and Rajeev Raman. Computing minimum spanning trees with uncertainty. In STACS, pages 277–288, 2008.
- [10] Tomás Feder, Rajeev Motwani, Rina Panigrahy, Chris Olston, and Jennifer Widom. Computing the median with uncertainty. In Proceedings of the thirty-second annual ACM symposium on Theory of computing, pages 602–607, 2000. doi:10.1145/335305.335386.
- [11] Hao Fu, Jian Li, and Pan Xu. A PTAS for a class of stochastic dynamic programs. In 45th International Colloquium on Automata, Languages, and Programming (ICALP), volume 107 of LIPIcs, pages 56:1–56:14, 2018. doi:10.4230/LIPICS.ICALP.2018.56.
- [12] Dimitrios Gkenosis, Nathaniel Grammel, Lisa Hellerstein, and Devorah Kletenik. The Stochastic Score Classification Problem. In 26th Annual European Symposium on Algorithms (ESA), pages 36:1–36:14, 2018. doi:10.4230/LIPICS.ESA.2018.36.
- [13] Ashish Goel, Sudipto Guha, and Kamesh Munagala. How to probe for an extreme value. ACM Transactions on Algorithms (TALG), 7(1):1–20, 2010. doi:10.1145/1868237.1868250.
- [14] Sudipto Guha and Kamesh Munagala. Approximation algorithms for budgeted learning problems. In 39th Annual ACM Symposium on Theory of Computing (STOC), pages 104–113. ACM, 2007. doi:10.1145/1250790.1250807.
- [15] Anupam Gupta, Ravishankar Krishnaswamy, Viswanath Nagarajan, and R. Ravi. Running errands in time: Approximation algorithms for stochastic orienteering. Math. Oper. Res., 40(1):56–79, 2015. doi:10.1287/MOOR.2014.0656.
- [16] Anupam Gupta, Viswanath Nagarajan, and Sahil Singla. Adaptivity gaps for stochastic probing: Submodular and XOS functions. In Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1688–1702. SIAM, 2017. doi:10.1137/1.9781611974782.111.
- [17] Lisa Hellerstein, Devorah Kletenik, and Srinivasan Parthasarathy. A tight bound for stochastic submodular cover. J. Artif. Intell. Res., 71:347–370, 2021. doi:10.1613/JAIR.1.12368.
- [18] Lisa Hellerstein, Naifeng Liu, and Kevin Schewior. Quickly determining who won an election. In 15th Innovations in Theoretical Computer Science Conference (ITCS), LIPIcs, pages 61:1–61:14, 2024. doi:10.4230/LIPICS.ITCS.2024.61.
- [19] Sungjin Im, Viswanath Nagarajan, and Ruben van der Zwaan. Minimum latency submodular cover. ACM Trans. Algorithms, 13(1):13:1–13:28, 2016. doi:10.1145/2987751.
- [20] Haotian Jiang, Jian Li, Daogao Liu, and Sahil Singla. Algorithms and adaptivity gaps for stochastic k-tsp. In 11th Innovations in Theoretical Computer Science Conference (ITCS), volume 151 of LIPIcs, pages 45:1–45:25, 2020. doi:10.4230/LIPICS.ITCS.2020.45.
- [21] Simon Kahan. A model for data in motion. In Proceedings of the Twenty-third Annual ACM Symposium on Theory of computing, pages 265–277, 1991.
- [22] Nicole Megow, Julie Meißner, and Martin Skutella. Randomization helps computing a minimum spanning tree under uncertainty. SIAM Journal on Computing, 46(4):1217–1240, 2017. doi:10.1137/16M1088375.
- [23] Nicole Megow and Jens Schlöter. Set selection under explorable stochastic uncertainty via covering techniques. In International Conference on Integer Programming and Combinatorial Optimization, pages 319–333. Springer, 2023. doi:10.1007/978-3-031-32726-1_23.
- [24] Danny Segev and Sahil Singla. Efficient approximation schemes for stochastic probing and prophet problems. In 22nd ACM Conference on Economics and Computation (EC), pages 793–794. ACM, 2021. doi:10.1145/3465456.3467614.
- [25] Sahil Singla. The price of information in combinatorial optimization. In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2523–2532. SIAM, 2018. doi:10.1137/1.9781611975031.161.
- [26] Weina Wang, Anupam Gupta, and Jalani K Williams. Probing to minimize. In 13th Innovations in Theoretical Computer Science Conference (ITCS 2022), volume 215, page 120, 2022.
Appendix A Multiplicative Precision
Given an instance with non-negative r.v.s and multiplicative precision , consider a new instance of with r.v.s and additive precision . Note that
An -approximately minimum value for the original instance satisfies , where . Then, satisfies , i.e., is a -minimum value for the new instance. Similarly, if is a -minimum value for the new instance then is an -approximately minimum value for the original instance.
Appendix B Bad Example for Competitive Ratio
We provide an example that rules out any reasonable competitive ratio bound for and with precision . This is in sharp contrast to the corresponding problem with exact precision () for which a constant competitive ratio is known [21]. We note that results in the online setting assume open intervals, which in our setting (with discrete r.v.s) corresponds to all left-endpoints being distinct.444Alternatively, our example can be modified into one with open intervals where the competivity ratio is still . The benchmark in the online setting is the hindsight optimum, which is the minimum number (or cost) of queries that are needed to verify a -minimum value conditioned on the realizations of the r.v.s.
Consider an instance with r.v.s with and for all . All costs are unit and the precision . We refer to the values as low values: note that any low value is a -minimum value for this instance.
We first consider the hindsight optimum. If any of the r.v.s (say ) realizes to a low value then verifying the -minimum value just requires querying , which has cost . On the other hand, the probability that none of the r.v.s realizes to a low value is : in this case the optimal verification cost is (querying all r.v.s). So the expected optimal cost is at most .
Now, consider an policy: this does not know the realizations. It is easy to see that the only way to stop querying is when some low value is observed (or all r.v.s are queried). So, the expected cost of any policy is at least . Hence the competitive ratio for is .