RESCUE: Multi-Robot Planning Under Resource Uncertainty and Objective Criticality

Abstract
Robot planning in distributed systems, such as drone fleets performing active perception missions, presents complex challenges. These missions require cooperation to achieve objectives like collecting sensor data or capturing images. Multi-robot systems offer significant advantages, including faster execution and increased robustness, as robots can compensate for individual failures. However, resource costs, affected by environmental factors such as wind or terrain, are highly uncertain, impacting battery consumption and overall performance.
Mission objectives are often prioritized by criticality, such as retrieving data from low-battery sensors to prevent data loss. Addressing these priorities requires sophisticated scheduling to navigate high-dimensional state-action spaces. While heuristics are useful for approximating solutions, few approaches extend to multi-robot systems or adequately address cost uncertainty and criticality, particularly during replanning.
The Mixed-Criticality (MC) paradigm, extensively studied in real-time scheduling, provides a framework for handling cost uncertainty by ensuring the completion of high-critical tasks. Despite its potential, the application of MC in distributed systems remains limited.
To address the decision-making challenges faced by distributed robots operating under cost uncertainty and objective criticality, we propose four contributions: a comprehensive model integrating criticality, uncertainty, and robustness; distributed synchronization and replanning mechanisms; the incorporation of mixed-criticality principles into multi-robot systems; and enhanced resilience against robot failures.
We evaluated our solution, named RESCUE, in a simulated scenario and show how it increases the robustness by reducing the oversizing of the system and completing up to 40% more objectives. We found an increase in resilience of the multi-robot system as our solution not only guaranteed the safe return of every non-faulty robot, but also reduced the effects of a faulty robot by up to 14%. We also computed the performance gain compared to using MCTS in a single robot of up to 2.31 for 5 robots.
Keywords and phrases:
Multi-Robot Systems, Embedded Systems, Safety/Mixed-Critical Systems, Real-Time Systems, Monte-Carlo Tree SearchCopyright and License:
2012 ACM Subject Classification:
Computer systems organization Embedded and cyber-physical systems ; Computer systems organization Real-time systems ; Computing methodologies Planning and schedulingFunding:
This material is based upon work supported by the CIEDS (Interdisciplinary Centre for Defence and Security of Institut Polytechnique de Paris) and by the FARO project (Heuristic Foundations of Robot Swarms).Editors:
Renato MancusoSeries and Publisher:
1 Introduction
Autonomous robot mission planning presents numerous challenges, particularly within the context of a collaborative distributed system, such as a fleet of drones. The case we will study to illustrate our contribution concerns active perception missions, where robots actively collaborate to gather information about its surroundings. In such cases, multiple geographically distributed sensors collect data without being connected to a network. A drone’s objective may be to join up with a sensor and retrieve its data via Bluetooth. It can be critical to complete such an objective before a sensor runs out of battery or memory.
The deployment of multiple robots offers several advantages, as it speeds up mission execution and increases the system’s robustness to failure, with one robot able to compensate for another in case of a malfunction. The system’s resources can involve significant cost uncertainty during the mission. Environmental factors such as wind, precipitation, or muddy terrain can substantially impact battery consumption. Moreover, certain mission objectives may be prioritized based on their criticality, such as collecting data from a sensor with a low battery to avoid information loss. A multi-robot system can also enhance robustness against robot failure by ensuring the completion of high-critical objectives by other robots.
Robot planning entails complex scheduling challenges such as high-dimensional state-action spaces, motivating the development of heuristics to approximate optimal solutions efficiently [17]. However, few of these heuristics are applicable to multi-robot fleets, particularly in scenarios where dynamic replanning is necessary to adapt to changing operating conditions. Additionally, few of these heuristics address both cost uncertainty and mission criticality.
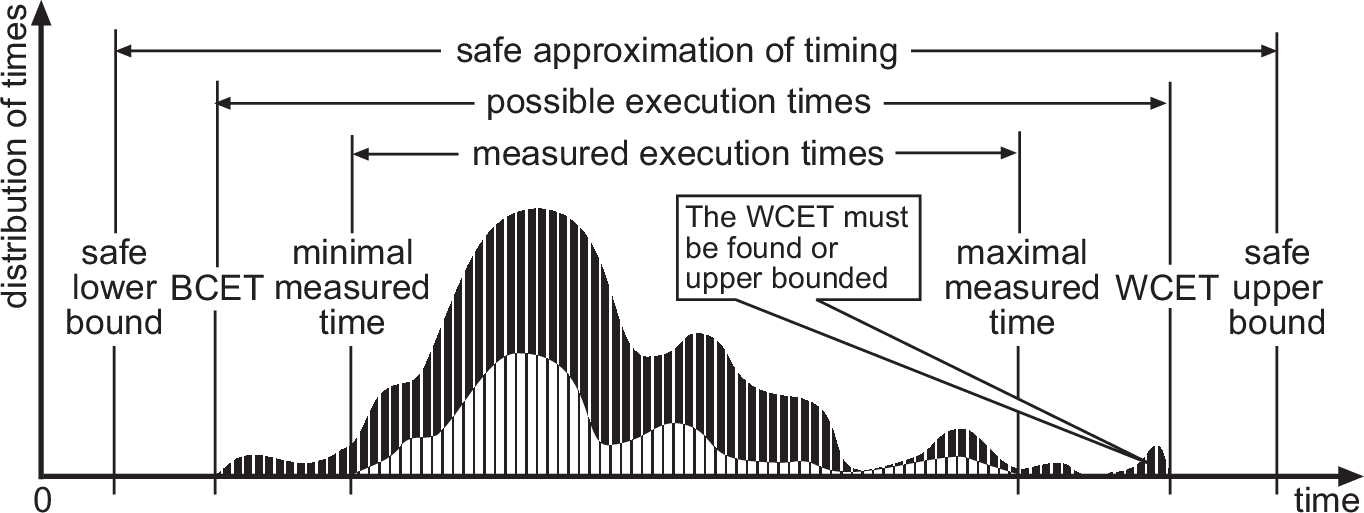
The real-time community has extensively studied cost uncertainty through the Mixed Criticality (MC) paradigm [29]. Indeed, WCET evaluations are often imprecise (Figure 1), with system designers favoring optimistic estimates (maximal measured time) and certification authorities relying on pessimistic ones (safe upper bound). While pessimistic estimates cause oversizing, optimistic ones risk exceeding resource budgets. In an MC system, low-critical tasks may be discarded or degraded to preserve high-critical tasks when time budgets exceed optimistic estimates. Only few approaches have applied the MC paradigm to distributed systems, despite its potential to improve robustness against system loss or overrun.
To address decision-making challenges in distributed robots with cost uncertainty and objective criticality, we propose four key contributions: a comprehensive model that accounts for criticality, uncertainty, and robustness in a robot fleet; synchronization and replanning mechanisms for the efficient management of distributed robots; the integration of mixed criticality into multi-robot planning; and enhanced resilience by mitigating the impact of robot failures on high-critical objectives first, followed by low-critical objectives.
The rest of the paper is organized as follows. In Section 2, we describe the system model and define some notations. Then, we formulate the problem and present our research objectives in Section 3. We present our RESCUE heuristic algorithm in Section 4. In Section 5, we evaluate our heuristic and demonstrate the performance improvements achieved by our approach. Finally, in Section 6, we provide a short review of related works in the fields of multi-robot plan building and safety-critical systems.
2 System Model
We consider a group of homogeneous robots collaborating to achieve a set of objectives . To achieve these objectives, each robot executes , a sequence of actions. The robot planning literature uses both the terms task and action for the robot operations that change the state of the system [1] [2]. We prefer to use the term action instead of task to avoid confusion with real-time system tasks.
In robot planning, actions such as movement are conventionally modeled as atomic to mitigate computational complexity arising from intermediary state enumeration. This aligns with established Task and Motion Planning (TAMP) approaches, where high-level actions may encompass multiple elementary operations (e.g., move to a point of interest and then manipulate an object) while maintaining atomicity at the planning level [24, 13, 8]. We adopt these principles and consider that actions are atomic and composed of multiple operations. We also consider an objective fulfilled only upon full action execution. This one-to-one mapping between atomic actions and objectives follows established principles in robot planning [14].
To guarantee the fulfillment of constraints required for achieving an objective, each action is associated with a set of prerequisites, such as the prior completion of another objective or the availability of necessary sensors. These prerequisites are verified to generate the feasible set of action sequences that a robot can perform. Consequently, actions do not need to be mutually independent. However, this work does not account for joint actions, wherein multiple robots must coordinate synchronously to accomplish the same objective.
In terms of system architecture, the robots have synchronous, reliable communication with a coordinator. The coordinator is the entity in charge of computing the plan and coordinating the replanning during the mission. It can be a ground control station or one of the robots in the swarm. We assume a maximum message delay of between any robot and the coordinator. We also assume no faults can occur on the coordinator, only on the robots. The rationale and consequences of these assumptions will be discussed in Section 4.4.2.
A robot may encounter a fault, assumed to be a fail-stop fault, and consequently be removed from the fleet. An objective previously assigned to the failing robot in the current plan will be marked as incomplete if its status is unknown, and it will not be reassigned automatically. If the designer wishes to reassign such an objective to another robot, they must ensure that the objective is idempotent, meaning that completing it twice is equivalent to completing it once.
Each action is associated with an actual cost , a tuple whose elements represent the different resources used by the robots. In our case, the cost tuple would be . (resp ) designates the actual action duration (resp energy ) it takes to run action . Note that the value of is not known a priori; it is observed while performing . Also, that cost is the total cost on all resources for the execution of every robot operation included in the action. Its value depends on the state of the system at the moment of the action’s execution, but that is left implicit in the notation, consistent with conventions in the robot planning literature [14]. Each sequence of actions is associated with an actual accumulated cost for resource .
The system designer assigns a criticality level to each action based on the consequences of its failure. In this work, we consider only two criticality levels, meaning that actions belong either to the set of high-critical actions, , or the set of low-critical actions, . High-critical actions (hi-actions) are essential for the correct execution of the mission, while low-critical actions (lo-actions) contribute to its optimal completion. The extension to multiple criticality levels, while feasible, introduces non-trivial complexity and is therefore reserved for future work.
Each robot executes in a criticality mode, either an optimistic execution mode, the low-critical mode (lo-mode), or a pessimistic one, the high-critical mode (hi-mode). lo-mode is the initial execution mode. In this mode, the robot executes all planned actions normally. We define two resource cost estimates for each action and two accumulated cost estimates for each sequence .
represents the optimistic worst-case cost of an action in resource when the system executes in lo-mode. Analogously to , this value is a function of the state of the system at the moment of execution. Its value can be obtained from the favorable expected speed and energy consumption of the robot. Similarly to , we define the optimistic worst-case accumulated cost of a sequence as . If exceeds , the system switches to hi-mode, indicating an unfavorable environment.
represents the pessimistic worst-case cost of an action in resource when the system executes in hi-mode and . Its value can be obtained under unfavorable operating conditions, for example, from the lowest speed and highest energy consumption. Note that a lo-action also has a cost in hi-mode. Indeed, we consider actions to be atomic. Thus, a lo-action may have to be completed after surpassing its lo-mode budget. The pessimistic worst-case accumulated cost takes into account the worst case accumulated cost possible when a mode change occurs during the execution of any action of a sequence. Once the mode change has occurred, the lo-actions are ignored and hi-actions have their cost in hi-mode. The formula in this case will be detailed later.
3 Problem Statement
Our goal is to generate a scheduling plan that maximizes the value of a global objective function , while considering both uncertain action costs and objectives with different levels of criticality. For instance, drone objectives can involve retrieving data via Bluetooth from geographically dispersed offline sensors. Some of these objectives can be critical, as sensors run out of battery. Our approach aims to reduce oversizing by leveraging the advantages of distributed systems to enhance mission objective fulfillment and reduce overall mission completion time. We define oversizing as the suboptimal allocation of resources to the robot fleet beyond what is strictly required to accomplish the given objectives, resulting in inefficient resource utilization.
Existing solutions for multi-robot planning fail to adequately tackle all these interrelated challenges. Decentralized approaches, such as [2], face scalability issues due to the complexity of collaborative plan building, data sharing, and achieving consensus within a large robot fleet. These limitations hinder their practical implementation in real-world scenarios. On the other hand, centralized approaches, such as TA-MCTS [27], lack the capabilities for dynamic replanning and distributed synchronization, making them ineffective in handling dynamic changes in resource availability and environmental conditions. Consequently, an alternative approach is required to support efficient online replanning and synchronization while ensuring computational feasibility and execution consistency.
Another critical aspect of multi-robot planning is the prioritization of high-critical (hi) actions over low-critical (lo) actions. Given the uncertainty in action costs, our approach must allocate adequate resources to ensure that the selected hi-actions are successfully executed even under worst-case conditions. Unlike existing methods such as (MC)2TS [9], which focus on single-robot planning under MC constraints, our solution must extend these principles to multi-robot and distributed systems. Furthermore, anticipating and mitigating robot failures is essential to maintain mission integrity. Our approach must proactively detect failures and dynamically adjust the plan to preserve critical objective execution, thus increasing overall system resilience.
To address these challenges, we define the following research objectives for our approach:
- Resilience:
-
As a correctness criterion, given cost uncertainty and the criticality of objectives, ensure the execution of allocated hi-objectives under pessimistic conditions in case of no faulty robot. As optimization goals, maximize the reward from completing objectives in more favorable environments while ensuring correctness. Additionally, mitigate the impact of a faulty robot by minimizing, first, the non-completion of hi-objectives and, second, the non-completion of lo-objectives.
- Robustness:
-
As an optimization goal, ensure that minor resource overruns do not lead to disproportionate responses [7]. For example, an overrun on a single objective should only cause a mode change limited to the affected robot, without impacting the entire fleet. Additionally, enable a quick return to an execution mode that maximizes objectives achievement as soon as conditions allow.
- Adaptability:
-
As an optimization goal, regularly distribute and reassign objectives among robots through replanning. This replanning should be based on actual resource consumption to optimize objective completion as execution conditions evolve. As a correctness criterion, ensure that after replanning, the reward obtained from the execution of hi-objectives in the new plan is greater or equal than in the current one. Thus, effective synchronization among robots is also essential for achieving global adaptation in favorable environments.
- Efficiency:
-
As optimization goals, minimize resources spent waiting for replanning to enhance replanning efficiency (e.g., reducing energy and time costs during stationary flight); incorporate these cost metrics directly into the plan-building process to enable optimal decision-making; and generate sustainable long-duration plans that reduce replanning frequency. The approach must demonstrate a significant performance gain, validating the efficiency advantages of parallel multi-robot collaboration over a single robot performing the same objectives.
4 Approach
RESCUE (Robustness and Efficiency in Multi-Robot Systems under Critical and Uncertain Environments) is designed to achieve the research objectives outlined in Section 3. Combining ideas from TA-MCTS and (MC)2TS, it defines and integrates new algorithms and mechanisms to provide resilience, robustness, adaptability, and efficiency in distributed multi-robot systems operating under execution cost uncertainties. We provide an overview of these foundational components, then we describe RESCUE, our solution that fulfills the research objectives.
4.1 MCTS: Robot Planning Heuristic
Monte Carlo Tree Search (MCTS) is a sampling-based heuristic that incrementally builds a search tree and evaluates actions through simulated outcomes. Combining tree search algorithms and Monte Carlo simulations, it constructs the tree iteratively by simulating action sequences and assessing their results. The process consists of four distinct phases, depicted in Figure 2. In the selection phase, the heuristic selects an expandable and promising node, driving the tree-building process through recursive traversal. An expandable node is a node where at least one child node can be added, meaning all the requirements for at least one action are met, including budget constraints. During the expansion phase, leaf nodes are added to represent possible actions. The simulation phase involves selecting actions based on a rollout policy, which determines the action selection strategy, and evaluating outcomes using predefined criteria, such as an upper bound on expected rewards. A random rollout policy selects actions randomly for this phase. Finally, in the back-propagation phase, the simulation results are propagated back through the tree to update node values.
The algorithm continues these iterations until a computational budget (e.g., time limit or iteration count) is reached, after which the action corresponding to the most promising child of the root node is selected. In our approach, we assume that only one (potentially complex) action is needed to achieve one objective. For example, this action might involve multiple movements followed by data loading to accomplish the objective.
4.2 TA-MCTS: Multi-Robot Planning Heuristic
Task Allocation Monte Carlo Tree Search (TA-MCTS) [27] is a variant of MCTS tailored to address task or objective allocation challenges in multi-robot systems. TA-MCTS incorporates two heuristics: the first one partitions robots and objectives into smaller groups to enhance scalability, while the second one generates conflict-free plans for each group. In our work, we revisit and refine the second heuristic, focusing on creating significantly enriched conflict-free plans for groups of robots and objectives.
In its first heuristic, TA-MCTS creates groups of objectives with the same number of objectives in each one. depends on the number of objectives to be assigned to each group of robots. For this partitioning, TA-MCTS uses a modified implementation of K-means called Uniform Distribution K-means, or UD-Kmeans, to classify objectives according to their physical distance from each other. Since the average distance between the objectives is minimized by K-means, the group of robots will remain relatively close to each other. This is important for our reliable communication assumption, as the robots must remain within communication range of the coordinator for our solution to be viable.
To adapt MCTS for a multi-robot scenario, TA-MCTS combines the trees of all robots into a unified single tree, focusing on simulating the best combinations of actions. But, in a single tree MCTS approach, an action can be assigned to multiple nodes. For example, MCTS can evaluate both combinations of and . Consequently, in a multi-robot tree, the same action might be assigned to nodes belonging to different robots. To address this, TA-MCTS maintains a set of assigned actions, ensuring that each action is allocated to only one robot while preserving the optimization advantages of the multi-tree approach. Moreover, the actions in TA-MCTS consist of moving to a point of interest and delivering a package. However, in their solution, only the cost of moving from one delivery point to another is taken into account as cost of the action. In our approach, we take into account the cost of the whole action, which allows us to differentiate costs between resources (i.e. flight time and energy consumed).
One iteration of TA-MCTS is described in Figure 3. First, robot is chosen at random to have its tree expanded. The selection phase shown in Figure 3(a) is executed on the tree representing robot , and node representing the action sequence is selected. During the expansion phase, a new node representing action is added to the tree, indicating that this iteration will evaluate the reward of robot executing the action sequence .To prevent simulating scenarii in which two robots attempt to execute the same action, we build a set of assigned actions () at each iteration that stores the actions already assigned to a robot. The actions in are thus added to . Subsequently, as shown in Figure 3(b) the iteration proceeds to pick robot at random to select its most probable sequence of actions considering that it cannot execute the actions contained in . Starting from the root, action is ignored and action is picked instead. As action is in , the selection for stops, selecting action sequence . The actions in are then added to . This cycle continues until a sequence of actions is selected for each robot.
Finally, the simulation and backpropagation phases are executed. During the simulation phase shown in Figure 3(c), the sequence of actions for each robot is simulated, and random future actions of robot are sampled. The resulting expected reward is stored in the new added node. The backpropagation phase is then executed for robot as shown in Figure 3(d), and the assigned actions set is emptied. After the last iteration, the same selection phase is executed to pick the best action sequence for each robot, and the algorithm returns .
4.3 (MC)2TS: Mixed-Criticality Robot Planning Heuristic
Mixed-Criticality Monte Carlo Tree Search ((MC)2TS) [9] incorporates mixed-criticality into MCTS for a single robot. (MC)2TS is an extension of MCTS designed to handle single-robot planning with uncertain action costs and critical objectives using the MC approach. As described in Section 2, to comply with Mixed-Critical System model, each action has two resource costs, one for each criticality mode. In (MC)2TS, it also has two accumulated resource costs.
The accumulated costs for lo-actions are:
| (1) |
while the accumulated costs for hi-actions are:
| (2) |
where is either the node with the previous hi-action in the tree branch of node or the root node.
During the plan execution, is checked after, and only after, the execution of action . If its value surpasses the value of computed during the planning, then a mode change occurs, and every subsequent lo-action is dropped. The value of can only be surpassed if there is a failure in the system’s design.
The mode change is thus triggered by surpassing and the current plan may continue to be executed by ignoring every lo-action. The replanning is triggered only when a predetermined replan horizon is reached. Therefore, a mode change does not trigger a replanning. However, since replanning reallocates every available resource, the system may safely return to lo-mode when executing the new plan.
When configuring rewards, it is crucial to ensure that lo-actions do not monopolize resources to the detriment of hi-actions. Consequently, the reward for performing a hi-action must be higher than the sum of the rewards for performing all lo-actions: .
4.4 RESCUE
Our approach, RESCUE, is designed to enhance multi-robot systems by offering improved properties and guarantees, including resilience, robustness, adaptability, and efficiency (see Section 3). It integrates key concepts inspired by (MC)2TS and TA-MCTS.
4.4.1 Mixed-Criticality in Multi-Robots Planning
RESCUE integrates the partitioned and hierarchical planning concepts from TA-MCTS with the local mode change described in (MC)2TS, and extends them with online replanning capabilities and a special IDLE objective. The integration of these concepts forms a plan building algorithm for a mixed-criticality multi-robot system.
- Partitioned Planning:
-
In a first step, RESCUE dispatches objectives over small groups of robots as TA-MCTS would do (section 4.2). In a second step, RESCUE partitions the objectives of a group across its robots, allowing each robot to independently schedule and execute its assigned objectives using the single-robot mixed-criticality planning approach of (MC)2TS. This second step is analogous to a partitioned scheduling algorithm for multi-processor systems based on uniprocessor scheduling algorithms. Indeed, this approach decomposes the decision-making problem for N robots into N single-robot problems. Since a mode change should be local to the affected robot to enhance robustness (see Section 3), the single-robot mixed-criticality (MC)2TS can be effectively utilized.
- Local Mode Change:
-
Once each robot receives its assigned plan from the coordinator, it begins executing the sequence of actions in lo-mode, meaning all actions are executed as planned. However, if the robot consumes more resources than anticipated by the accumulated cost in lo-mode calculated during planning, it locally switches to hi-mode, discarding any subsequent lo-actions.
The robot can return to lo-mode if its current accumulated cost drops below the accumulated cost in lo-mode. For example, if the robot had previously switched to hi-mode and, after executing its next hi-objective, observes that its cost is back on track under the scheduled lo-mode cost at that point of execution, it switches back to lo-mode and can execute its next objective, even if it is a lo-objective. This minimizes the number of lo-objectives that are skipped because the robot had previously switched to hi-mode.
- Online Replanning:
-
To improve the efficiency and robustness of our approach, unlike in TA-MCTS, a robot can trigger replanning when it completes its assigned actions and is ready to continue the mission. This also allows the robots to return to lo-mode, as a new plan redistributes all the fleet’s resources. Furthermore, if all objectives have already been assigned, a robot in a single-robot scenario should complete its mission and return to the charging station after completing its assigned tasks. In a multi-robot scenario, however, if a robot with no remaining assigned objectives returns to the station, the fleet loses a valuable resource that could be utilized should a new event arise. For example, if another robot switches to the hi mode, the inactive robot – provided it has remained in lo-mode – can execute objectives that were discarded by the robot in hi-mode. Therefore, delaying the return of a robot, even when it has no remaining objectives, can be advantageous.
- IDLE Objective:
-
To address this delay, we introduce idle, a general-purpose objective that requires a robot to remain idle. In this context, being idle means waiting in place until the allocated resources, as determined by the coordinator, are depleted. Specifically, the idle objective is used to keep a robot waiting for the global completion of the mission, even when it has sufficient resources to achieve its local mission.
During the planning phase, idle is considered as any other action. Since staying idle consumes resources (e.g., stationary flight), the coordinator configures the resource cost of the idle action to ensure that, upon completing this action, the robot retains just enough resources in hi-mode to safely complete its local mission (i.e., return to the charging station). There is no need for any particular reward for this action, as its execution implies finishing the mission. Thus, the reward will be a consequence of the objectives completed before its execution.
During the execution phase, when assigned an idle objective, the robot remains in place for no longer than the allocated resource cost planned by the coordinator. If a replanning event occurs while the robot is executing the objective, the robot immediately terminates it, informs the coordinator of its availability, and becomes eligible for reassignment. If no replanning is triggered, the robot safely returns to the base once it has exhausted the resources allocated to the idle action.
4.4.2 Distributed Synchronisation in Multi-Robots Replanning
RESCUE incorporates a replanning process supported by lightweight distributed synchronization. The details of this replanning process are outlined in Figure 4. Note that we assume reliable time-bounded communication. As previously mentioned, all communications are constrained by a time limit of . Therefore, the coordinator can detect a robot experiencing a fail-stop fault and remove it from the fleet. Intermittent communication problems are tolerated, as long as the two parties manage to reestablish communication within a period of . Longer lasting communication problems shall be treated as a permanent fault (see Section 4.4.3).
Replanning occurs after a predetermined replan horizon. The replan horizon is the number of actions a robot executes before requesting a replan. Consequently, the coordinator does not need to dispatch action sequences longer than the replan horizon, as the robots will receive new action sequences as a result of the replanning process. If frequent communication is not desirable, the replan horizon can be increased, reducing the number of times the coordinator must communicate with the robots.
As soon as a robot completes its assigned objectives and is ready to continue the mission, a replanning process is initiated (see Figure 4). The robot notifies the coordinator of the completion of its objectives and shares its current state, including current position and resource budget available. The coordinator retrieves the current status of all robots, equivalent to an atomic snapshot. To achieve this, the coordinator sends a broadcast requesting all robots to pause before starting their next respective action. This broadcast acts as a lock operation. In response, each robot reports its current state, including its ongoing action, position, and remaining resources, which serves as a read operation. Once their states have been communicated, the robots proceed with their current actions but refrain from initiating any new actions until the replanning process is finalized.
The coordinator then executes the RESCUE algorithm and constructs . To generate an accurate plan, it must predict the worst-case future resources of each robot based on its current state, assuming completion of its ongoing action . Several strategies can be considered for this prediction. The more general solution we adopted for its flexibility and practicality is to use the actual accumulated costs from the robot’s previous objective, and , and combine these with and for the ongoing action. Finally, the coordinator dispatches the new objective sequences assigned to each robot, enabling them to resume the mission.
A final aspect to consider is the resources required to implement the replanning process. Indeed, the robot must remain in place, waiting for the replanning and engaging in communication, which, in our case, consumes resources such as energy and flight time. Note that in this case, the robot is not achieving an objective, and this cost must be incorporated into the hi-action costs, similar to how preemption costs are handled in WCET computation. It is not necessary to add this cost to other actions since a replan will reallocate the resources for the next action sequence and guarantee the budget for the new plan and a potential future replanning.
The longest waiting time for a replanning calculation occurs for the robot that triggers it, as it must send the Initiate message (see Figure 4) before proceeding with the rest of the protocol like the other robots. In this case, the worst waiting time for a replanning calculation corresponds to four message exchanges, , plus the time needed to generate the plan, , which is directly linked to the computational budget.
4.4.3 Robustness in Mixed-Criticality Multi-Robots Planning
To ensure resilience and robustness, our approach attempts to minimize the impact of losing a robot, whether due to a real failure or to a perceived loss of communication. If a robot fails to receive a response from the coordinator within a time interval of (round-trip time) after a replanning request, or after following a status request, it can safely return to the base, confident that its prior plan provided sufficient resources to do so. This mechanism can be used in case of both a communication failure or a fault in the coordinator. From the coordinator’s side, if a robot does not respond within , it can be excluded from the planning process, and a new plan will be created for the remaining robots. The objectives assigned to the faulty robots will be treated as detailed in Section 2. These objectives can not be guaranteed execution anymore, but they may be redistributed to other robots in a new plan.
The planning process should not only detect and handle failures but also proactively minimize their impact by allocating objectives more uniformly across robots. This enhances resilience, ensuring that in a system with hi-objectives and robots, a failure leads to a reduction in the number of attained objectives closer to than to all of them. Since the probability of a fault is usually very small, using it directly during the plan building would not result in significant changes in the plan, as MCTS relies on the most probable results to decide on a plan. Therefore, the possibility of a fault should be considered analytically.
Equation (3) illustrates a possible objective function. Additional parameters can be integrated to enrich the objective function. Here, is the corresponding reward of an action .
| (3) |
Let us consider a set of plans that achieve the same objectives for a global reward but allocate them differently among robots. Our goal is to avoid allocations where one robot is assigned the majority of objectives or hi-objectives. While these plans yield the same reward, we introduce a penalty in the objective function that increases as objectives are more concentrated on a single robot. However, the penalty should not be so high that it favors a plan with a reward smaller than that includes fewer hi-objectives.
To prevent unbalanced allocations, equation (4) defines a penalty based on the difference in rewards between robots, where is the new objective function, and is a constant. The robot with the highest and lowest mission reward are compared. This difference prioritizes hi-objectives over lo-objectives, as the reward for an hi-action must be greater than the combined reward for all lo-actions, as explained in Section 4.3.
| (4) |
We define the spreading factor as the extent to which the objective allocation function deviates from the optimum to ensure a more balanced distribution of objectives among the robots. The higher the probability of a fault, the higher should be the value of to minimize the consequences of a fault. Three allocation options are defined:
-
1.
The first option is the one with no balancing where .
-
2.
In the second option, we ensure that penalizing plans does not favor those that include less hi-objectives than those in the plans with the same reward . However, lo-actions are potentially excluded. We define as the lowest reward for a hi-objective and equations (5a) and (5b) determine the maximum penalty so that it does not exceed . Equation (5c) defines an upper bound for the reward difference that is independent of the plans, allowing it to be used in the objective function.
(5a) (5b) (5c) Equation (6) derives a bound for for not excluding hi-objectives even when the difference in rewards is maximum. Higher fault probabilities should result in values of closer to this upper bound.
(6) - 3.
5 Evaluation
We evaluate our approach’s performance on a data collecting scenario when considering the research objectives listed in Section 3. We thus try to accomplish the following objectives:
- Robustness:
-
we compare our approach with TA-MCTS-R-P, a TA-MCTS implementation that replans (R) according to the process described in Section 4.4.2 and operates with pessimistic costs (P). In this experiment, every action in the plan should be safely executed, and RESCUE should be less pessimistic.
- Resilience:
-
we compare RESCUE to TA-MCTS-R-O, which exclusively uses optimistic costs (O). Unlike RESCUE, TA-MCTS-R-O does not guarantee the safe execution of all hi-actions in this experiment. Additionally, we simulate a scenario where one robot experiences a fault at the start of the mission. We evaluate our approach’s resilience in the worst case.
- Efficiency:
-
we compute the performance gain of using robots instead of a single robot when the fleet has enough resources to complete all objectives. We evaluate our approach’s efficiency in the average case.
- Adaptability:
-
we evaluate the influence of the number of robots in cases where the fleet is not able to complete every objective. We also evaluate the influence of the replan horizon (see Section 4.4.2), as more frequent replanning should increase the rate at which the robots exchange objectives and adapt to a new environment.
5.1 Experiment Setup
We considered an active perception scenario on a 100×100 grid-based terrain, where robots can move freely within the field. The area contains 20 randomly distributed objectives, including 5 high-critical and 15 low-critical objectives. A charging station, serving as both the starting point and the safe return location for the robots, is positioned at one corner of the grid. The robots must collaborate to maximize the reward from completed objectives while ensuring a safe return to the charging station.
For the MCTS parameters, we used a random rollout policy and use the Upper Confidence Bound for Trees (UCT) [21] as the selection policy. UCT is a best-first approach that computes an upper confidence bound to estimate the expected reward of a selected node. The computational budget was set to 5000, representing the number of RESCUE iterations, with one node being added to one random tree at each iteration. This value must ideally allow each tree to have its most promising branch completely explored to the same depth as the replan horizon. Since the algorithm usually explores some branches deeper than the others, it is impossible to know the necessary number of iterations prior to the execution. Therefore, we picked an arbitrary value that is higher than the necessary to completely explore each tree to the second layer if each tree is explored the same amount of times. The horizon was set to 5, defining the maximum length of action sequences evaluated during rollouts. The C parameter in UCT, which controls the balance between exploring new paths and exploiting the best-known path, is fixed at 0.5.
In our implementation, the actions considered are reaching an objective point, and retrieving the data from the sensor located at that point. The costs for actions are shown in Table 1. Since their cost is a function of the robot’s position at the beginning of their execution, we give the cost of movement per unit of distance. The total cost for an action is thus the sum of the movement and the data retrieving costs. The energy budget was fixed on 100%. The distance between the previous objective point and the next one was used to compute the cost of a move action.
| Action | Ci(lo) | Ci(lo) | Ci(hi) | Ci(hi) |
|---|---|---|---|---|
| [duration] | [energy] | [duration] | [energy] | |
| Move (one unit) | 2.0 | 0.1% | 4.0 | 0.2% |
| Retrieve data | 5.0 | 1.0% | 10.0 | 2.0% |
The costs in time and energy of an action depend on the state of the environment. If the environment is favorable for the mission (e.g., no wind), the costs will be equal to . However, if the environment is unfavorable (e.g., a strong wind), then the costs will be equal to . In tests that evaluate performance, we evaluated the results in a favorable environment, as that is the normal state of operation. In tests that evaluate safety, we simulated an unfavorable environment.
The objective function considered was
| (7) |
where is the reward for completing action , is the time consumed from the beginning of the mission until the end of the last action and is the total time budget available.
The expression is used to prioritize plans that accomplish the same objectives in a shorter duration. The weight ensures that this value remains lower than the reward for completing an objective.
For RESCUE, we used as , as it is the accumulated cost for the optimistic mode of operation. The reward for completing a hi-action grants 0.166, and executing a lo-action provides 0.0104. The idle action does not provide any reward, but its availability is a prerequisite for all other actions. This, before incorporating any action into the tree, we ensure that idle remains executable afterward, ensuring the robot can return to the charging station.
Fifty different random scenarios were generated with different random positions for the 20 objectives. This number is similar to the number of objectives in a group in the TA-MCTS evaluation[27]. The and coordinates of each objective was sampled from a uniform distribution between 1 and 99. On each scenario, we ran RESCUE 100 times and evaluated the results. This process was executed with different time budgets, number of robots similar to the ones evaluated in a TA-MCTS group, replan horizons and spreading factors, .
5.2 Robustness: Pessimistic Costs
We evaluated the performance of RESCUE when compared to TA-MCTS-R-P. TA-MCTS-R-P ignores mixed-criticality costs and operates with pessimistic costs. We aim to demonstrate how it is more pessimistic than RESCUE.
When considering a favorable environment, the pessimism of TA-MCTS-R-P may cause it to execute fewer actions than RESCUE. Thus, we evaluate the number of objectives achieved by RESCUE compared with that of TA-MCTS-R-P by simulating an environment where actions cost . The robot fleet used contained 5 robots and replanning was made each 2 actions.
The experimental results are shown in Figure 5. RESCUE outperforms TA-MCTS-R-P in this scenario when the budget is not big enough to accomplish all objectives. This is due to RESCUE having an accumulated cost closer to the execution in a favorable environment, allowing it to explore more action sequences thanks to the previously spared budget. Thus, RESCUE reduces the oversizing of the system.
5.3 Resilience: Optimistic Costs
We evaluated the performance of RESCUE when compared to TA-MCTS-R-O in the situation where both are executed in an unfavorable environment. TA-MCTS-R-O does not consider mixed-criticality mechanisms, and we aim to demonstrate how it is unsafe, unlike RESCUE.
In an unfavorable environment, TA-MCTS-R-O generates plans that exceed the allocated resources for completion. To assess its reliability in worst-case scenarios, we simulate it in an initially favorable environment where conditions deteriorate over time. Additionally, we compare the total number of objectives achieved by RESCUE against TA-MCTS-R-O in these missions. If TA-MCTS-R-O fails to return safely, the simulation is terminated, and the number of successfully achieved objectives is recorded as zero. The robot fleet consists of five robots, with replanning occurring every two actions.
The experimental results are shown in Figure 6. The first graph shows that the lower the resource budget, the more TA-MCTS-R-O fails midway through the execution of the mission, reducing its effectiveness. This can also be observed on the second figure, as the number of objectives achieved is compromised by its unsafety. Thus, RESCUE increases the safety of the system.
5.4 Efficiency: Performance Gain
To evaluate the benefits of using a fleet instead of a single robot, we ran the previously described scenario with a single robot while varying the time budget. We then repeated the experiment with a fleet of two to five robots and compared the number of objectives reached. As expected, under a tighter budget, a larger fleet was able to achieve more objectives, as shown in Figure 7.
| Number of robots | Mission completion time | Performance gain |
|---|---|---|
| 1 | 713.17 | 1.00 |
| 2 | 494.09 | 1.44 |
| 3 | 426.10 | 1.67 |
| 4 | 367.33 | 1.94 |
| 5 | 319.02 | 2.31 |
In order to compute the performance gain, which is the ratio of the mission execution time using one robot to the mission execution time with robots, we allocated enough resources to the robots to complete every objective in the mission and compared the time taken by each fleet to finish. In this configuration, each fleet always completes the same number of objectives – 20 in total. The time budget used was 1000, and replanning was performed every two actions.
The results are shown in Table 2. The performance increases rapidly with the addition of the first robots; however, it does not increase indefinitely. As the number of robots approaches the number of objectives, the fleet completes the mission as quickly as possible, with each robot completing one objective. However, the results show how RESCUE allows a reduction in mission time.
5.5 Adaptability: Replan Horizon
A key question is whether reducing the frequency of replanning significantly degrades performance. This frequency is derived from the replan horizon, which specifies the number of actions completed before a robot initiates a replan. To assess the impact on algorithm performance, we varied the replan horizon and simulated a scenario where replanning time is negligible compared to the mission duration. The simulations involved a fleet of 2 robots operating in an unfavorable environment. The results, presented in Figure 8, show that, as expected, a longer replan horizon reduces mission efficiency.
However, even though it increases the efficiency of the mission, replanning is resource consuming. Therefore, it may be desirable to replan less often to save resources. We simulated the same experiment as before but considering that replanning takes in total 30 units of time (computation and communication included). This time cost for replanning is similar to accomplishing an objective that’s at 10 units of distance in hi-mode. Therefore, it might be preferable to accomplish another objective instead of replanning.
| Time budget | Replan horizon | Average objectives |
| 450 | 1 | 9.78 |
| 450 | 2 | 10.42 |
| 450 | 3 | 9.75 |
| 480 | 1 | 10.69 |
| 480 | 2 | 11.32 |
| 480 | 3 | 10.69 |
The experimental results are shown in Table 3, frequent replanning can reduce the fleet’s resources to a point where the robots complete fewer objectives. In the time budgets presented in the table, replanning every action performs similar to replanning every 3 actions. In this case, the time saved by not replanning every action was used by the robots to produce better results. Therefore, the replan horizon should be adjusted by considering the replanning time and, more precisely, the communication time.
5.6 Resilience: Faulty Robot
In this experiment, we demonstrate that our solution minimizes, first, the non-completion of hi-objectives and, second, the non-completion of lo-objectives in the case of a faulty robot. We consider a worst-case scenario in which the hi-objectives are spread in the top-left quarter of the grid, while the lo-objectives are spread in the bottom-right quarter of the grid as shown in Figure 9.
In our first experiment, the fleet consists of two robots. We simulate a configuration where one of the robots fails at the start of the mission and does not reach any of the objectives. The environment is set to be unfavorable (actions cost ). The given budget is 670 time units and the replan is performed every two actions. This amount of resource budget only allows the robots to go to one agglomeration of objectives, cross the map to the other agglomeration, and return to the base. We compare the simulation results using our solution with spreading factors and , the spreading factor indicating the ability to deviate from the optimum in favor of a better distribution of objectives.
| fault | Average objectives | ||
|---|---|---|---|
| 2 | one | 0.0 | 14.53 |
| 2 | one | 0.16 | 16.67 |
| 5 | none | 0.0 | 17.73 |
| 5 | none | 0.1 | 17.74 |
The results are shown in Table 4. The difference in average objectives in the experiment with a faulty robot can be explained by the difference on how each algorithm dispatches the two robots. In the case where , RESCUE is more likely to dispatch each robot to a different corner of the map to minimize the total amount of time to finish the mission. The faulty robot may be assigned to either lo or hi-objectives, with the hi-objective assignment being random since all robots start identical. When the faulty robot is assigned to the hi-objectives, the other robot is sent to cross the map to ensure the completion of the hi-objectives after reaching the first replan horizon. The remaining robot is unable to return to the lo-objectives after crossing the map and therefore completes fewer objectives.
In the case where however, RESCUE is more likely to send the two robots to complete the hi-objectives first. Indeed, sending the robots together to complete the hi-objectives reduce the difference in the reward accomplished by each robot. Therefore, the loss of one of the robots only causes the remaining robot to take the hi-objectives that are already close to it. This leaves enough resources for the remaining robot to cross the map and execute the lo-objectives before returning.
In our second experiment, we examine a more general case with a fleet of five robots. We assess its performance under both spreading factors, assuming no faults occur, to understand their impact in a fault-free scenario. As shown in Table 4, there is no significant difference between the results for both factors. This demonstrates that, in the general case, the spreading factor does not affect the fleet’s performance. Therefore, in a random scenario, the spreading factor can mitigate the consequences of a fault without noticeably reducing performance when no faults occur.
These experiments show that RESCUE successfully reduces the consequences of faults while preserving performance under anormal scenario.
Thus, we have successfully shown how RESCUE can reduce the impact of a fault while maintaining performance in normal scenarii.
6 Related Works
In this section, we first review the literature on multi-robot planning. Next, we focus on Monte Carlo Tree Search and Mixed-Criticality Systems, as these two domains are crucial to our proposed framework for optimizing multi-robot planning.
6.1 Multi-Robot Mission Planning
As path planning is an NP-hard problem in optimization [22], the multi-robot planning version has high computational complexity. This complexity results in a lack of algorithms that are both optimal and computationally efficient [16]. A thorough review of approaches for multi-robot path planning can be found in [1].
A common metaheuristic for multi-robot path planning is Particle Swarm Optimization (PSO), an optimization algorithm based on the social behavior of animals. It initializes the workspace with stochastic particles, each randomly seeking an optimal position and velocity to optimize a fitness function [28]. However, its stochastic foundation does not allow for hard guarantees on the completion of hi-objectives.
The problem of assigning various tasks to a swarm of robots is an active research topic in the artificial intelligence community as well. However, most authors concentrate on global performance in an ideal or slightly disturbed environment, or on robot cooperation for complex tasks. In [12], Galati et al. propose an auction-based allocation system with quick dynamic task reallocations after a perturbation occurs, thus adapting to a dynamic environment. However, they do not guarantee that planned or better hi-objectives will be satisfied, and they require human supervision to validate the plan.
When dealing with possible faults, fault detection becomes a more complex problem. As the robots interact and cooperate, the detection and diagnosis for each robot become more complex in a decentralized system compared to a single-robot system [20]. For fault tolerance, Bramblett et al. propose centralized mission planning based on a genetic algorithm where the robots plan to meet intermittently to check for faults [3]. They also propose a replanning algorithm to handle detected faults. While this solution reduces the effects of faults, it requires the robots to meet periodically and for each to be capable of executing a mission replan. Moreover, it does not consider the criticality of objectives.
6.2 Monte-Carlo Tree Search
Monte-Carlo Tree Search (MCTS) has proven to be pivotal in addressing complex decision-making problems, such as gaming, planning, optimization, and scheduling [18, 5].
Regarding multi-robot plan building, Best et al. proposed a distributed solution called Dec-MCTS [2], where each robot builds its own plan and shares information regarding the probability of its future actions with others. This approach is more tolerant to faults in the ground control station, as the robots are independent. However, it requires the robots to have enough processing power to build their plans and communicate with all other robots. Moreover, if two robots are equally capable of pursuing an objective, there is no guarantee that they will not compete to accomplish the same objective.
D’Urso et al. expanded that idea by proposing a hierarchical approach for coordinating surface vessels [11]. In the studied scenario, vessels had to drop floats and pick them up later to obtain information about an area of the ocean. The authors propose dividing the problem into two parts: finding a set of drop-off and corresponding pick-up actions that observe all the space, and scheduling the found actions to a set of robots. MCTS is used in both parts: a centralized MCTS for deciding the actions, and then Dec-MCTS for assigning the actions to the robots.
To address possible faults in a multi-robot system, Bramblett et al. propose an epistemic replanning mechanism [3]. This approach uses a centralized planner that rewards intermittent rendezvous between the robots to detect possible failures. If a robot fails to meet with another, it adjusts its local plan to compensate for the faulty robot by using a genetic algorithm and MCTS while communicating with other robots to share beliefs about the system. This approach does not enforce a budget for the robots, and uncertainties in the cost of actions are not considered during the MCTS phase.
6.3 Mixed-Criticality Systems
Mixed-criticality systems (MCS) [29] have been extensively studied in the context of real-time embedded systems, where tasks with different levels of criticality share computational resources. The majority of the research has focused on Real-Time Scheduling [6] and does not address other decision-making algorithms.
A partitioned multiprocessor system closely parallels a multi-robot application, with task allocation on processors being the primary challenge. Lakshmanan et al. [23] adapted a single processor approach using a Compress-on-Overload scheme.
Various research efforts have explored applying the mixed-criticality paradigm to networked systems by assigning criticality levels to communication, such as FlexRay [15] and switched Ethernet [10]. However, in our work, there is no requirement for criticality levels on communication resources.
In the context of distributed IoT systems, JMC [25] is an efficient scheduling framework designed to maximize the performance of lo flows while ensuring the schedulability of hi flows. It uses jitters to evaluate runtime pessimism and trigger criticality mode transitions based on predefined thresholds and policies. The lazy or proactive policies minimize the impact either on the lo or hi flows.
Some studies [26, 19, 30] tackle energy-aware systems and use DVFS or DVFS with EDF-VD scheduling to reduce energy consumption in mixed-criticality systems by degrading low-critical (lo) tasks in high-critical (hi) mode. However, these approaches do not inherently prioritize hi-tasks over lo-tasks and do not consider energy as a primary resource.
(MC)2TS enhances action planning under uncertain costs, reducing overestimations and resource waste [9]. Compared to previous projects, it expands the MC approach beyond execution time to consider energy as a first-class citizen within the system. (MC)2TS also introduces the MC paradigm to MCTS, expanding its traditional use in Real-Time Scheduling. However, it is limited to single robots.
7 Conclusions
In distributed robotic systems, such as drone fleets on active perception missions, effective planning is crucial for overcoming complex challenges. Under the right conditions, collaboration between robots can shorten mission execution time and increase overall resilience. However, unpredictable resource costs – such as varying battery consumption or travel time due to wind or terrain – demand intelligent scheduling and anticipation. Prioritizing critical objectives, such as retrieving data from low-battery sensors, requires advanced strategies that can adapt dynamically. While heuristics offer approximations of efficient solutions, few approaches extend to multi-robot systems while addressing both uncertainty of costs and criticality of objectives. Advancing planning techniques in this field is essential for improving efficiency, reliability, and real-world applicability.
RESCUE (Robustness and Efficiency in Multi-Robot Systems under Critical and Uncertain Environments) combines concepts from TA-MCTS and (MC)2TS into a unified framework designed to address mixed-criticality and multi-robot challenges. It incorporates novel algorithms and mechanisms, including distributed synchronization and techniques, to enhance robustness, resilience, adaptability, and efficiency in distributed multi-robot systems operating under cost uncertainties and different levels of objective criticality.
The framework is designed to ensure robustness by limiting the impact of minor resource overruns to localized mode changes, thereby preventing disproportionate, system-wide disruptions. The objective spreading factor mitigates the effects of robot failures on the number of incomplete hi-objectives, enhancing overall resilience. This was confirmed by our evaluation, showing that we reduce the effects of a fault without compromising overall performance. Our experiments also show that the framework’s adaptability is strengthened by frequent replanning, enabled through a distributed synchronization mechanism, allowing outcomes to exceed those envisioned in the initial plan. Furthermore, in terms of efficiency, the computational overhead of replanning is incorporated into the planning process, while waiting delays during calculations are accounted for through a novel objective, idle. This approach ensures that all costs are considered during mission planning and replanning. Our evaluation at last shows a significant performance gain by using multiple robots instead of a single one.
As future work, we plan to extend our RESCUE heuristic algorithm to include more than two levels of criticality. This will allow us to map these levels more directly to existing criticality standards, such as the DO-178C avionics safety standard, which defines five criticality levels [4]. Finally, we will enforce hard deadlines for individual objectives rather than depending on a single mission-wide deadline.
References
- [1] Semonti Banik, Sajal Chandra Banik, and Sarker Safat Mahmud. Path planning approaches in multi-robot system: A review. Engineering Reports, page e13035, 2024. doi:10.1002/eng2.13035.
- [2] Graeme Best, Oliver M Cliff, Timothy Patten, Ramgopal R Mettu, and Robert Fitch. Dec-MCTS: Decentralized planning for multi-robot active perception. The International Journal of Robotics Research, 38(2-3):316–337, 2019. doi:10.1177/0278364918755924.
- [3] Lauren Bramblett, Branko Miloradović, Patrick Sherman, Alessandro V Papadopoulos, and Nicola Bezzo. Robust online epistemic replanning of multi-robot missions. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13229–13236. IEEE, 2024. doi:10.1109/IROS58592.2024.10802214.
- [4] Benjamin M. Brosgol. DO-178C: the next avionics safety standard. In Ricky E. Sward, Michael B. Feldman, Dan Eilers, Jean-Pierre Rosen, Frank Singhoff, Julien Delange, Mark Gardinier, Karl A. Nyberg, and Jeff Boleng, editors, Proceedings of the 2011 Annual ACM SIGAda International Conference on Ada, Denver, Colorado, USA, November 6-10, 2011, SIGAda ’11, pages 5–6, New York, NY, USA, 2011. ACM. doi:10.1145/2070337.2070341.
- [5] Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012. doi:10.1109/TCIAIG.2012.2186810.
- [6] Alan Burns and Robert I. Davis. A survey of research into mixed criticality systems. ACM Computing Surveys, 50(6):82:1–82:37, November 2018. doi:10.1145/3131347.
- [7] Alan Burns, Robert I. Davis, Sanjoy Baruah, and Iain Bate. Robust mixed-criticality systems. IEEE Transactions on Computers, 67(10):1478–1491, 2018. doi:10.1109/TC.2018.2831227.
- [8] Hamza Chakraa, François Guérin, Edouard Leclercq, and Dimitri Lefebvre. Optimization techniques for multi-robot task allocation problems: Review on the state-of-the-art. Robotics and Autonomous Systems, 168:104492, October 2023. doi:10.1016/j.robot.2023.104492.
- [9] Franco Cordeiro, Samuel Tardieu, and Laurent Pautet. Shackling uncertainty using mixed criticality in monte-carlo tree search. In 2024 IEEE 14th International Symposium on Industrial Embedded Systems (SIES), pages 34–41. IEEE, 2024. doi:10.1109/SIES62473.2024.10767910.
- [10] Olivier Cros, Laurent George, and Xiaoting Li. A protocol for mixed-criticality management in switched ethernet networks. In Workshop on Mixed Criticality Systems (WMC), 2015. URL: https://api.semanticscholar.org/CorpusID:20814803.
- [11] Giovanni D’urso, James Ju Heon Lee, Oscar Pizarro, Chanyeol Yoo, and Robert Fitch. Hierarchical MCTS for scalable multi-vessel multi-float systems. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 8664–8670. IEEE, 2021. doi:10.1109/ICRA48506.2021.9561064.
- [12] Giada Galati, Stefano Primatesta, and Alessandro Rizzo. Auction-based task allocation and motion planning for multi-robot systems with human supervision. Journal of Intelligent & Robotic Systems, 109(2):24, September 2023. doi:10.1007/s10846-023-01935-x.
- [13] Caelan Reed Garrett, Rohan Chitnis, Rachel Holladay, Beomjoon Kim, Tom Silver, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Integrated task and motion planning. Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021. doi:10.1146/annurev-control-091420-084139.
- [14] Brian P Gerkey and Maja J Matarić. A formal analysis and taxonomy of task allocation in multi-robot systems. The International journal of robotics research, 23(9):939–954, 2004. doi:10.1177/0278364904045564.
- [15] Dip Goswami, Martin Lukasiewycz, Reinhard Schneider, and Samarjit Chakraborty. Time-triggered implementations of mixed-criticality automotive software. In Wolfgang Rosenstiel and Lothar Thiele, editors, 2012 Design, Automation & Test in Europe Conference & Exhibition (DATE), pages 1227–1232. IEEE, 2012. doi:10.1109/DATE.2012.6176680.
- [16] Shuai D Han, Edgar J Rodriguez, and Jingjin Yu. Sear: A polynomial-time multi-robot path planning algorithm with expected constant-factor optimality guarantee. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1–9. IEEE, 2018. doi:10.1109/IROS.2018.8594417.
- [17] Zaharuddeen Haruna, Muhammed Bashir Mu’azu, Abubakar Umar, and Glory Okpowodu Ufuoma. Path planning algorithms for mobile robots: A survey. In Motion Planning for Dynamic Agents. IntechOpen, 2023. doi:10.5772/intechopen.1002655.
- [18] Constantin Hofmann, Xinhong Liu, Marvin May, and Gisela Lanza. Hybrid monte carlo tree search based multi-objective scheduling. Production Engineering, 17:133–144, 2022. doi:10.5445/IR/1000150664.
- [19] Pengcheng Huang, Pratyush Kumar, Georgia Giannopoulou, and Lothar Thiele. Energy efficient dvfs scheduling for mixed-criticality systems. In International Conference on Embedded Software (EMSOFT), pages 1–10, 2014. doi:10.1145/2656045.2656057.
- [20] Eliahu Khalastchi and Meir Kalech. Fault detection and diagnosis in multi-robot systems: A survey. Sensors, 19(18):4019, 2019. doi:10.3390/s19184019.
- [21] Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. In European conference on machine learning, pages 282–293. Springer, 2006. doi:10.1007/11871842_29.
- [22] Georgios Kyprianou, Lefteris Doitsidis, and Savvas A Chatzichristofis. Towards the achievement of path planning with multi-robot systems in dynamic environments. Journal of Intelligent & Robotic Systems, 104(1):15, 2022. doi:10.1007/s10846-021-01555-3.
- [23] Karthik Lakshmanan, Dionisio de Niz, Ragunathan Rajkumar, and Gabriel Moreno. Resource allocation in distributed mixed-criticality cyber-physical systems. In 2010 IEEE 30th International Conference on Distributed Computing Systems, pages 169–178. IEEE Computer Society, 2010. doi:10.1109/ICDCS.2010.91.
- [24] Steven M. LaValle. Planning algorithms. Cambridge University Press, 2006.
- [25] Kilho Lee, Minsu Kim, Hayeon Kim, Hoon Sung Chwa, Jaewoo Lee, Jinkyu Lee, and Insik Shin. JMC: Jitter-based mixed-criticality scheduling for distributed real-time systems. IEEE Internet of Things Journal, 6(4):6310–6324, 2019. doi:10.1109/JIOT.2019.2915790.
- [26] Di Liu, Jelena Spasic, Nan Guan, Gang Chen, Songran Liu, Todor Stefanov, and Wang Yi. EDF-VD scheduling of mixed-criticality systems with degraded quality guarantees. In 2016 IEEE Real-Time Systems Symposium (RTSS). IEEE, November 2016. doi:10.1109/rtss.2016.013.
- [27] Zeyuan Ma and Jing Chen. Multi-UAV urban logistics task allocation method based on MCTS. Drones, 7(11):679, 2023. doi:10.3390/drones7110679.
- [28] Eslam Nabil Mobarez, A Sarhan, and MM Ashry. Obstacle avoidance for multi-uav path planning based on particle swarm optimization. In IOP Conference Series: Materials Science and Engineering, volume 1172, page 012039. IOP Publishing, 2021. doi:10.1088/1757-899X/1172/1/012039.
- [29] Steve Vestal. Preemptive scheduling of multi-criticality systems with varying degrees of execution time assurance. In 28th IEEE International Real-Time Systems Symposium (RTSS 2007), pages 239–243, 2007. doi:10.1109/RTSS.2007.47.
- [30] Yi-Wen Zhang and Rong-Kun Chen. A survey of energy-aware scheduling in mixed-criticality systems. Journal of Systems Architecture, 127:102524, 2022. doi:10.1016/j.sysarc.2022.102524.