Sparser Abelian High Dimensional Expanders

Abstract
The focus of this paper is the development of new elementary techniques for the construction and analysis of high dimensional expanders. Specifically, we present two new explicit constructions of Cayley high dimensional expanders (HDXs) over the abelian group . Our expansion proofs use only linear algebra and combinatorial arguments.
The first construction gives local spectral HDXs of any constant dimension and subpolynomial degree for every , improving on a construction by Golowich [50] which achieves . [50] derives these HDXs by sparsifying the complete Grassmann poset of subspaces. The novelty in our construction is the ability to sparsify any expanding Grassmann posets, leading to iterated sparsification and much smaller degrees. The sparse Grassmannian (which is of independent interest in the theory of HDXs) serves as the generating set of the Cayley graph.
Our second construction gives a 2-dimensional HDX of any polynomial degree ) for any constant , which is simultaneously a spectral expander and a coboundary expander. To the best of our knowledge, this is the first such non-trivial construction. We name it the Johnson complex, as it is derived from the classical Johnson scheme, whose vertices serve as the generating set of this Cayley graph. This construction may be viewed as a derandomization of the recent random geometric complexes of [74]. Establishing coboundary expansion through Gromov’s “cone method” and the associated isoperimetric inequalities is the most intricate aspect of this construction.
While these two constructions are quite different, we show that they both share a common structure, resembling the intersection patterns of vectors in the Hadamard code. We propose a general framework of such “Hadamard-like” constructions in the hope that it will yield new HDXs.
Keywords and phrases:
Local spectral expander, coboundary expander, Grassmannian expanderFunding:
Yotam Dikstein: This material is based upon work supported by the National Science Foundation under Grant No. DMS-1926686.Copyright and License:
2012 ACM Subject Classification:
Theory of computation ; Mathematics of computing Spectra of graphsAcknowledgements:
We thank Louis Golowich for helpful discussions and Gil Melnik for assistance with the figures.Editors:
Srikanth SrinivasanSeries and Publisher:
1 Introduction
Expander graphs are of central importance in many diverse parts of computer science and mathematics. Their structure and applications have been well studied for half a century, resulting in a rich theory (see e.g. [56, 76]). First, different definitions of expansion (spectral, combinatorial, probabilistic) are all known to be essentially equivalent. Second, we know that expanders abound; a random sparse graph is almost surely an expander [89]. Finally, there is a variety of methods for constructing and analyzing explicit expander graphs. Initially, these relied on deep algebraic and number theoretic methods [84, 45, 78]. However, the quest for elementary (e.g. combinatorial and linear-algebraic) constructions has been extremely fertile, and resulted in major breakthroughs in computer science and math; the zigzag method of [93] lead to [33, 92, 96], and the lifting method of [14] lead to [83, 82].
In contrast, the expansion of sparse high dimensional complexes (or simply hypergraphs) is still a young and growing research topic. The importance of high dimensional expanders (HDXs) in computer science and mathematics is consistently unfolding, with a number of recent breakthroughs which essentially depend on them, such as locally testable codes [34, 88], quantum coding [6] and Markov chains [5] as a partial list. High dimensional expanders differ from expander graphs in several important ways. First, different definitions of expansion are known to be non-equivalent [53]. Second, they seem rare, and no natural distributions of complexes are known which almost surely produce bounded-degree expanding complexes. Finally, so far the few existing explicit constructions of bounded degree HDXs use algebraic methods [12, 16, 72, 79, 68, 86, 25]. No elementary constructions are known where high dimensional expansion follows from a clear (combinatorial or linear algebraic) argument. This demands further understanding of HDXs and motivates much prior work as well as this one.
In this work we take a step towards answering this question by constructing sparser HDXs by elementary means. We construct sparse HDXs with two central notions of high dimensional expansion: local spectral expansion and coboundary expansion.
To better discuss our results, we define some notions of simplicial complexes and expansion. For simplicity, we only define them in the -dimensional case, though many of our results extend to arbitrary constant dimensions. For the full definitions see Section 2. A 2-dimensional simplicial complex is a hypergraph with vertices , edges and triangles (sets of size ). We require that if then all its edges are in , and all its vertices are in . We denote by the number of vertices. Given a vertex , its degree is the number of edges adjacent to it. An essential notion for HDXs is the local property of its links. A link of a vertex is the graph whose set of vertices is the neighborhood of ,
The edges correspond to the triangles incident on :
In this paper we focus on a particularly simple class of complexes, called Cayley complexes over . These are simplicial complexes whose underlying graph is a Cayley graph over , and so have vertices. It is well-known that constant-degree Cayley complexes over abelian groups cannot be high dimensional expanders . In fact, logarithmic degree is needed for a -dimensional complex, namely a graph, to be an expander [3]. In particular, random Cayley graphs over with degree (logarithmic in the number of vertices) are expanders with high probability. However, no abelian Cayley complex constructions with remotely close degree are known to have higher dimensional expansion, and a guiding question of this paper is to develop techniques for constructing and analyzing abliean Cayley HDXs of smallest possible degree.
In the rest of the introduction we will explain our constructions. In Section 1.1 we present our construction of local spectral Cayley complexes with arbitrarily good spectral expansion and a subpolynomial degree. In Section 1.2 we present our family of Cayley complexes that are both coboundary expanders and non-trivial local spectral expanders, with arbitrarily small polynomial degree. In Section 1.3 we discuss the common structure of our two constructions that relies on the Hadamard code. In Section 1.4 we present some open questions.
1.1 Local spectral expanders
We start with definitions and motivation, review past results and then state ours. The first notion of high dimensional expansion we consider is local spectral expansion. The spectral expansion of a graph is the second largest eigenvalue of its random walk matrix in absolute value, denoted . Local spectral expansion of complexes is the spectral expansion of every link.
Definition 1 (Local spectral expansion).
Let . A -dimensional simplicial complex is a -local spectral expander if the underlying graph is connected and for every , .
Local spectral expansion is the most well-known definition of high dimensional expansion. It was first introduced implicitly by [47] for studying the real cohomology of simplicial complexes. A few decades later, a few other works observed that properties of specific local spectral expanders are of interest to the computer science community [79, 60, 62]. The definition above was given in [38], for the purpose of constructing agreement tests. These are strong property tests that are a staple in PCPs (see further discussion in Section 1.2). Since then they have found many more applications that we now discuss.
Applications of local spectral expanders
One important application of local spectral expansion is in approximate sampling and Glauber dynamics. Local spectral expansion implies optimal spectral bounds on random walks defined on the sets of the complex. These are known as the Glauber dynamics or the up-down walks. This property has lead to a lot of results in approximate sampling and counting. These include works on Matroid sampling [5], random graph coloring [20] and mixing of Glauber dynamics on the Ising model [4].
Local spectral expanders have also found applications in error correcting codes. Their sampling properties give rise to construction of good codes with efficient list-decoding algorithms [1, 37, 59]. One can also use the to construct locally testable codes that sparsify the Reed-Muller codes [39].
The list decoding algorithms in [1, 59] rely on their work on constraint satisfaction problems on local spectral expanders. These works generalize classical algorithms for solving CSPs on dense hypergraphs, to algorithms that solve CSPs on local spectral expanders. These works build on the “dense-like” properties of these complexes, and prove that CSPs on local spectral expanders are easy. It is interesting to note that local spectral expanders have rich enough structure so that one can also construct CSPs over them that are also hard for Sum-of-Squares semidefinite programs [35, 57]111In fact, [1] uses Sum-of-Squares to solve CSPs on local spectral expanders. It seems contradictory, but the hardness results in [35, 57] use CSPs where the variables are the edges of the HDX. The CSPs in [1] use its vertices as variables..
Some of the most important applications of local spectral expansion are constructions of derandomized agreement tests [38, 26, 51, 9, 31] and even PCPs [11]. Most of these works also involve coboundary expansion so we discuss these in Section 1.2.
Local spectral expanders have other applications in combinatorics as well. They are especially useful in sparsifying central objects like the complete uniform hypergraph and the boolean hypercube. The HDX based sparsifications maintain many of their important properties such as spectral gap, Chernoff bounds and hypercontractivity (see [62, 30, 67, 54, 8, 32] as a partial list).
Previous constructions
Attempts to construct bounded degree local spectral expanders with sufficient expansion for applications have limited success besides the algebraic constructions mentioned above [12, 16, 72, 79, 68, 86, 25]. Random complexes in the high dimensional Erdős–Rényi model defined by [73] are not local spectral expanders with overwhelming probability when the average degree is below and no other bounded degree model is known. The current state of the art is the random geometric graphs on the sphere [74], that achieve non-trivial local spectral expansion and arbitrarily small polynomial degree (but their expansion is also bounded from below, see discussion in Section 1.2). Even allowing an unbounded degree, the only other known construction that is non-trivially sparse complexes is the one in [50] mentioned in the abstract.
Our result
The first construction we present is a family of Cayley local spectral expanders. Namely,
Theorem 2.
For every and integer there exists an infinite family of -dimensional Cayley -local spectral expanders over the vertices with degree at most .
This construction builds on an ingenious construction by Golowich [50], which proved this theorem for . As far as we know, this is the sparsest construction that achieves an arbitrarily small -local spectral expansion other than the algebraic constructions.
Proof overview
Our construction is based on the well studied Grassmann poset, the partially ordered set of subspaces of , ordered by containment. This object is the vector space equivalent of high dimensional expander, and was previously studied in [30, 69, 46, 50]. To understand our construction, we first describe the one in [50]. Golowich begins by sparsifying the Grassmann poset, to obtain a subposet. The generators of the Cayley complex in [50] are all (non-zero vectors in) the one-dimensional subspaces in the subposet. The analysis of expansion in [50] depends on the expansion properties of the subposet. The degree is just the number of one-dimensional vector spaces in the subposet, which is .
Our construction takes a modular approach to this idea. We modify the poset sparsification in [50] so that instead of the entire Grassmann poset, we can plug in any subposet of the Grassmann, and obtain a sparsification whose size depends on (not the complete Grassmann).
Having this flexible sparsification step, we iterate. We start with , the complete Grassmann poset, we obtain a sequence of sparser and sparser subposets. The vectors in are low-rank matrices whose rows and columns are vectors in subspaces of .
We comment that while this is a powerful paradigm, it does have a drawback. The dimension of is logarithmic in the dimension of (the dimension of is the maximal dimension of a space inside ). Thus for a given complex we can only perform this sparsification a constant number of steps keeping constant. Our infinite family is generated by taking an infinite family of ’s, and using our sparsification procedure on every one of them separately.
This construction of sparsified posets produces local spectral expanders of any constant dimension, as observed by [50]. The higher dimensional sets in the resulting simplicial complex correspond to the higher dimensional subspaces of the sparsification we obtain. We refer the reader to Section 3 for more details.
The analysis of the local spectral expansion is delicate, so we will not describe it here. One property that is necessary for it is the fact that every rank- matrix has many decompositions into sums of rank- matrices. Therefore, to upper bound spectral expansion we study graphs that arise from decompositions of matrices.
In addition, we wish to highlight a local-to-global argument in our analysis that uses a theorem by [81]. Given a graph that we wish to analyze, we find a set of expanding subgraphs of (that are allowed to overlap). We consider the decomposition graph whose vertices are and whose edges are all such that there exists an such that . If every is an expander and the decomposition graph is also an expander, then itself is an expander [81]. This decomposition is particularly useful in our setup. The graphs we need to analyze in order to prove the expansion of our complexes, can be decomposed into smaller subgraphs . These ’s are isomorphic to graphs coming from the original construction of [50]. Using this decomposition we are able to reduce the expansion of the links to the expansion of some well studied containment graphs in the original Grassmann we sparsify.
Remark 3 (Degree lower bounds for Cayley local spectral expanders).
The best known lower bound on the degree of Cayley -local spectral expanders over is [2]. This bound is obtained simply because the underlying graph of a Cayley -local spectral expander is an -spectral expander itself [87]. In Appendix I we investigate this question further, and provide some additional lower bounds on the degree of Cayley complexes based on their link structure. We prove that if the Cayley complex has a connected link then its degree is lower bounded by (compared to if the link is not connected). If the link mildly expands, we provide a bound that grows with the degree of a vertex inside the link. However, these bounds do not rule out Cayley -local spectral expanders whose generator set has size . The best trade-off between local spectral expansion and the degree of the complex is still open.
1.2 Our coboundary expanders
Our next main result is an explicit construction of a family of -dimensional complexes with an arbitrarily small polynomial degree, that have both non-trivial local spectral expansion and coboundary expansion. To the best of our knowledge, this is the first such nontrivial construction. Again, these are Cayley complexes of .
Coboundary expansion is a less understood notion compared to local spectral expansion. Therefore, before presenting our result we build intuition for it slowly by introducing a testing-based definition of coboundary expanders. After the definition, we will discuss the motivation behind coboundary expansion and applications of known coboundary expanders.
As mentioned before, there are several nonequivalent definitions of expansion for higher-dimensional complexes. In particular, coboundary expansion generalizes the notion of edge expansion in graphs to simplicial complexes. Coboundary expansion was defined independently by [73],[85] and [52]. The original motivation for this definition came from discrete topology; more connections to property testing were discovered later. We will expand on these connections after giving the definition. This definition we give is equivalent to the standard definition, but is described in the language of property testing rather than cohomology.
The more general and conventional definition for arbitrary groups can be found in Section 5.1.
Definition 4.
Let be a -dimensional simplicial complex. Consider the code whose generating matrix is the vertex-edge incidence matrix , and the local test of membership in this code for given by first sampling a uniformly random triangle and then accepting if and only if over .
Let . is a -coboundary expander over if
where is the relative distance from to the closest codeword in .
Observe that the triangles are parity checks of , and so if the input is a codeword, the test always accepts. A coboundary expander’s local test should reject inputs which are “far” from the code with probability proportional to their distance from it. The proportionality constant captures the quality of the tester (and coboundary expansion). We note that although the triangles are some parity checks of the code , they do not necessarily span all parity checks. In such cases, is not a coboundary expander for any .
Definition 5.
A set of -dimensional simplicial complexes is a family of coboundary expanders if there exists some such that for all , is a -coboundary expander.
Applications of coboundary expansion
We mention three different motivations to the study of coboundary expansion: from agreement testing, discrete geometry, and algebraic topology.
Coboundary expanders are useful for constructing derandomized agreement tests for the low-soundness (list-decoding) regime. As we mentioned before, agreement tests (also known as derandomized direct product tests) are a strong property test that arise naturally in many PCP constructions [33, 90, 48, 58] and low degree tests [94, 7, 91]. They were introduced by [48]. In these tests one gets oracle access to “local” partial functions on small subsets of a variable set, and is supposed to determine by as few queries as possible, whether these functions are correlated with a “global” function on the whole set of variables. The “small soundness regime”, is the regime of tests where one wants to argue about closeness to a “global” function even when the “local” partial functions pass the test with very small success probability (see [36] for a more formal definition). Works such as [36, 58, 40] studied this regime over complete simplicial complexes and Grassmanians, but until recently these were essentially the only known examples. Works by [51, 10, 27] reduced the agreement testing problems to unique games constraint satisfaction problems, and showed existence of a solution via coboundary expansion (over some symmetric groups), following an idea by [41]. This lead to derandomized tests that come from bounded degree complexes [31, 9].
In discrete geometry, a classical result asserts that for any points in the plane, there exists a point that is contained in at least a constant fraction of the triangles spanned by the points [13] 222This can also be generalized to any dimension by replacing triangles with simplices [15].. In the language of complexes, for every embedding of the vertices of the complete -dimensional complex to the plane, such a heavily covered point exists. One can ask whether such a point exists even when one allows the edges in the embedding to be arbitrary continuous curves. If for every embedding of a complex to the plane (where the edges are continuous curves), there exists a point that lays inside a constant fraction of the triangles of , we say has the topological overlapping property. The celebrated result by Gromov states that the complete complex indeed has this property [52]. It is more challenging to prove this property for a given complex.
In [52], Gromov asked whether there exists a family of bounded-degree complexes with the topological overlapping property. Towards finding an answer, Gromov proved that every coboundary expander has this property. This question has been extremely difficult. An important progress is made in [43], where they defined cosystolic expansion, a relaxation of coboundary expansion, and proved that this weaker expansion also implies the topological overlapping property. The problem was eventually resolved in [60] for dimension and in [44] for dimension where the authors show that the [79] Ramanujan complexes are bounded-degree cosystolic expanders.
Coboundary expansion has other applications in algebraic topology as well. Linial, Meshulam, and Wallach defined coboundary expansion independently, initiating a study on high dimensional connectivity and cohomologies of random complexes [73, 85]. Lower bounding coboundary expansion turned out to be a powerful method to argue about the vanishing of cohomology in high dimensional random complexes [42, 55].
Known coboundary expanders
Most of the applications mentioned above call for complexes that are simultaneously coboundary expanders and non-trivial local spectral expanders. So far there are no known constructions of such complexes with arbitrarily small polynomial degree even in dimension 333By coboundary expanders, we are referring to complexes that have coboundary expansion over every group, not just .. Here we summarize some known results.
Spherical buildings of type are dense complexes that appear as the links of the Ramanujan complexes in [79]. The vertex set of a spherical building consists of all proper subspaces of some ambient vector space . [52] proved that spherical buildings are coboundary expanders (see also [77]). Geometric lattices are simplicial complexes that generalize spherical buildings. They were first defined in [71]. Most recently, [28] show that geometric lattices are coboundary expanders. [68] show that the -dimensional vertex links of the coset geometry complexes from [66] are coboundary expanders.
If we restrict our interest to coboundary expanders over a single finite group instead of all groups, bounded degree coboundary expanders that are local spectral expanders are known. [60] solved this for the case conditioned on a conjecture by Serre. [19] constructed such complexes for the unconditionally, and their idea was extended by [31, 9] to every fixed finite group, which lead to the aforementioned agreement soundness result. Unfortunately, their approach cannot be leveraged to constructing a coboundary expander with respect to all groups simultaneously.
We note that the coboundary expanders mentioned above are also local spectral expanders and that if we do not enforce the local spectral expansion property, coboundary expanders are trivial yet less useful.
To the best of our knowledge, all known constructions of -dimensional coboundary expanders (over all groups) that are also non-trivial local spectral expanders have vertex degree at least for some fixed , where is the number of vertices (see e.g. [79, 66]).444To the best of our knowledge, this constant is . The diameter of all of those complexes is at most a fixed constant, which implies this lower bound on the maximal degree. In this work, we give the first such construction with arbitrarily small polynomial degree.
Our result
We now state our main result in this subsection. For every integer , and constant we construct a family of -dimensional simplicial complexes called the Johnson complexes. For any -dimensional simplicial complex , we use the notation (the -skeleton of ) to denote the -dimensional simplicial complex consists of the vertex, edge, and triangle sets of .
Theorem 6 (Informal version of Theorem 86, Lemma 59, and Lemma 91).
For any integer , , the -skeletons of the Johnson complexes are -local spectral expanders and -coboundary expanders (over every group ).
Moreover, if , the -skeletons of s’ vertex links are -coboundary expanders .
Fix . For every satisfying , we briefly describe the -skeletons of . The underlying graph of is simply the Cayley graph where consists of vectors with even Hamming weight, and is the set of vectors with Hamming weight . Thus the number of vertices in the graph is while the vertex degree is 555Here is the binary entropy function.. The triangles are given by:
Observe that the link of every vertex is isomorphic to the classically studied Johnson graph of -subsets of , that are connected if their intersection is (for ). We will use some of the known properties of this graph in our analysis.
We additionally show that when , we can extend the above construction to get -dimensional simplicial complexes with the exact same vertex set, edge set, and triangle set as defined above. Moreover we show that for every integer , the link of an -face in the complex is also a non-trivial local spectral expander (Lemma 59).
Remark 7.
Let . We note that all vertices in are in edges and all vertices in the links of are in edges. We remark that using a graph sparsification result due to [21], we can randomly subsample the triangles in to obtain a random subcomplex which is still a local spectral expander with high probability but whose links have vertex degree . A detailed discussion can be found in Appendix F.
Before giving a high-level overview of the proof for Theorem 6, we describe a general approach for showing coboundary expansion called the cone method. Appearing implicitly in [52], it was used in a variety of works (see [77, 71, 68] as a partial list). We also take this approach to show that the Johnson complexes are coboundary expanders.
Coboundary expansion for links of the [50] Cayley local spectral expanders
Even though most of our results on coboundary expansion are for the Johnson complexes, we can also use the methods in this paper to prove that the vertex links of the [50] Cayley local spectral expanders are coboundary expanders. This implies that these Cayley local spectral expanders are cosystolic expanders (see [60, 28]), the relaxation of coboundary expansion mentioned above. This makes them useful for constructing agreement tests and complexes with the topological overlapping property. We note that [50] observed that these complexes are not coboundary expanders so this relaxation is necessary. A definition of cosystolic expansion and a detailed proof can be found in Section 6.3.
Cones and isoperimetry
Recall first the definition of -coboundary expansion above. We start with the code of edge functions which arise from vertex labelings by elements of some group . This implies that composing (in order) the values of along the edges of any cycle will give the identity element . This holds in particular for triangles, which are our “parity checks”.
We digress to discuss an analogous situation in geometric group theory, of the word problem for finitely presented groups. In this context, we are given a word in the generators of a group and need to check if it simplifies to the identity under the given relations. In our context the given word is the labeling of along some cycle, and a sequence of relations (here, triangles) is applied to successively “contract” this word to the identity. The tight upper bound on the number of such contractions in terms of the length of the word (called the Dehn function of the presentation), captures important properties of the group, e.g. whether or not it is hyperbolic. This ratio between the contraction size and the word length is key to the cone method.
One convenient way of capturing the number of contractions is the so-called “van Kampen diagram”, which simply “tiles” the cycle with triangles in the plane (all edges are consistently labeled by group elements). The van Kampen lemma ensures that if a given word can be tiled with tiles, then there is a sequence of contractions that reduce it to the identity [97]. The value in this viewpoint is that tiling is a static object, which can be drawn on the plane, and allows one to forget about the ordering of the contractions. We will make use of this in our arguments, and for completeness derive the van Kampen lemma in our context. Note that a bound on the minimum number of tiles (a notion of area) needed to cover any cycle of a given length (a notion of boundary length) can be easily seen as an isoperimetric inequality! The cone method will require such isoperimetric inequality, and the Dehn function gives an upper bound on it.
Back to -coboundary expansion. Here the given may not be in , and we need to prove that if it is “far” from , then the proportion of triangles which do not compose to the identity on will be at least . The cone method localizes this task. To use this method, one needs to specify a family of cycles (also called a cone) in the underlying graph of the complex. Gromov observed that the complex’s coboundary expansion has a lower bound that is inverse proportional to the number of triangles (in the complex) needed to tile a cycle from this cone [52]. This number is also referred to as the cone area. Thus, bounding the coboundary expansion of the complex reduces to computing the cone area of some cone. Needless to say, an upper bound on the Dehn function, which gives the worst case area for all cycles, certainly suffices for bounding the cone area of any cone.666We note that in a sense the converse is also true - computing the cone area for cones with cycles of “minimal” length suffices for computing the Dehn function. We indeed give such a strong bound.
Proof overview
It remains to construct a cone in and upper bound its cone area. We now provide a high level intuition for our approach. First observe that the diameter of the complex is . The proof then proceeds as follows.
-
1.
We move to a denser -dimensional complex whose underlying graph is the Cayley graph where consists of vectors with even Hamming weight, and is the set of vectors with even Hamming weight . The triangle set consists of all -cliques in the Cayley graph. We note that has the same vertex set as but has more edges and triangles than the Johnson complex.
-
2.
Then we carefully construct a cone in with cone area .
-
3.
We show that every edge in translates to a length- path in , and every -cycle (boundary of a triangle) in translates to a -cycle in which can be tiled by triangles from .
-
4.
We translate the cone in into a cone in by replacing every edge in the cycles of with a certain length- path in . Thus every cycle can be tiled by first tiling its corresponding cycle with triangles and then tiling each of the triangles with triangles. Thereby we conclude that has cone area .
Local spectral expansion and comparison to random geometric complexes
These Johnson complexes also have non-trivial local spectral expansion. While they do not achieve arbitrarily small -local spectral expansion, they do pass the barrier. From a combinatorial point of view, is an important threshold. For , there are elementary bounded-degree constructions of -local spectral expanders [22, 17, 23, 75, 49] but these fail to satisfy any of the local-to-global properties in HDXs. For all these constructions break. For this regime, all bounded degree constructions rely on algebraic tools. This is not by accident; below there are a number of high dimensional global properties suddenly begin to hold. For instance, a theorem by [47] implies that when all real cohomologies of the complex vanish. Another example is the “Trickle-Down” theorem by [87] which says that the expansion of the skeleton is non-trivial whenever . These are strong properties, and we do not know how produce them in elementary constructions. Therefore, when constructions of local spectral expanders are considered non-trivial only when .
To show local spectral expansion, we first note that the Johnson complex is symmetric for each vertex. Hence, it suffices to focus on the link of . Because the triangle set is well-structured, we can show that the link graph of is isomorphic to tensor products of Johnson graphs (Proposition 62). This allows us to use the theory of association schemes to bound their eigenvalues.
We also note that since all boolean vectors in lie on a sphere in centered at , the Johnson complex can be viewed as a geometric complex whose vertices are associated with points over a sphere and two vertices form an edge if and only if their corresponding points’ distance is . Previously [74] prove that randomized -dimensional geometric complexes are local spectral expanders. Comparing the two constructions, we conclude that Johnson complexes are sparser local spectral expanders than random geometric complexes.
1.3 The common structure between the two constructions
Taking a step back, we wish to highlight that the two constructions in our paper share a common structure. Both of these constructions can be described via “induced Hadamard encoding”. For a (not necessarily linear) function , the “induced” Hadamard encoding is the linear map given by
where and the sum is over . Our two constructions of Cayley HDXs take the generating set of the Cayley graph to be all bases of spaces , for carefully chosen functions as above; the choice determines the construction. We note that the “orthogonality” of vectors of the Hadamard code manifests itself very differently in the two constructions: in the Johnson complexes it can be viewed via the Hamming weight metric, while in the other construction it may be viewed via the matrix rank metric. We connect the structure of links in our constructions, to the restrictions of these induced Hadamard encodings to affine subspaces of . Using this connection we show that one can decompose the link into a tensor product of simpler graphs, which are amenable to our analysis. A special case of this observation was also used in the analysis of the complexes constructed by [50].
1.4 Open questions
Local spectral expanders
As mentioned above, we do not know how sparse a Cayley local spectral expander can be. To what extent can we close the gaps between the lower and upper bounds for various types of abelian Cayley HDXs? In particular, can we show that any nontrivial abelian Cayley expanders must have degree ? Conversely, can we construct Cayley HDXs where the degree is upper bounded by some polynomial in ? Limits of our iterated sparsification technique would also be of interest.
So far, the approach of constructing Cayley local spectral expanders over by sparsifying Grassmann posets yields the sparsest known such complexes. In contrast to the success of this approach, we have limited understanding of its full power. To this end, we propose several questions: what codes can be used in place of the Hadamard codes so that the sparsification step preserves local spectral expansion? Could this approach be generalized to obtain local spectral expanders over other abelian groups? As mentioned above, we know that the approach we use can not give a complex of polynomial degree in without introducing new ideas.
Coboundary expanders
Another fundamental question regards the isoperimetric inequalities we describe above. In this paper and many others, one uses the approach pioneered by Gromov [52] that applies isoperimetric inequalities to lower bounding coboundary expansion. A natural question is whether an isoperimetric inequality is also necessary to obtain coboundary expansion. An equivalence between coboundary expansion and isoperimetry will give us a simple alternative description for coboundary expansion. A counterexample to such a statement would motivate finding alternative approaches for showing coboundary expansion.
We call our family of -dimensional simplicial complexes that are both local spectral expanders and -dimensional coboundary expanders Johnson complexes. This construction can be generalized to yield families of -dimensional Johnson complexes that are still local spectral expanders. However, it remains open whether they are also coboundary expanders in dimension .
1.5 Organization of this paper
In Section 2, we give preliminaries on simplicial complexes and local spectral expansion. We also define Grassmann posets–the vector space analogue for HDXs–which we use in our constructions. Other elementary backgrounds on graphs and expansion are given there as well.
In Section 3, we construct the subpolynomial degree Cayley complexes, proving Theorem 2. Most of this section discusses Grassmann posets instead of Cayley HDXs, but we describe the connection between the two given by [50] in this section too. We defer some of the more technical expansion upper bounds to Appendix D.
In Section 4 we construct the Johnson complexes which are both coboundary expanders and local spectral expanders. In this section we prove that they are local spectral expanders, leaving coboundary expansion to be the focus of the next two sections. We also give a detailed comparison of this construction to the one in [74], and discuss how to further sparsify our complexes by random subsampling.
In Section 5 we take a detour to formally define coboundary expansion and discuss its connection to isoperimetric inequalities. In this section we also give our version of the van-Kampen lemma, generalized to the setting of coboundary expansion. This may be of independent interest, as the van-Kampen lemma simplifies many proofs of coboundary expansion.
In Section 6 we prove that the Johnson complexes are coboundary expanders (Theorem 86), and local coboundary expanders (Theorem 89). We also prove that links in the construction of [50] are coboundary expanders.
In Section 7 we show that both the Johnson complex and the matrix complexes are special cases of a more general construction. In this section we show that the two complexes have a similar link structure, which is necessary for analyzing the local spectral expansion in both Cayley HDXs.
The appendices contain some of the more technical claims for ease of reading. In Appendix I we also give a lower bound on the degree of Cayley local spectral expanders, based on the degree of the link.
2 Preliminaries
We denote by .
2.1 Graphs and expansion
Let be a weighted graph where are the weights. In this paper we assume that is a probability distribution that gives every edge a positive measure. When is clear from context we do not specify it. We extend to a measure on vertices where . When is connected this is the stationary distribution of the graph. The adjacency operator of the graph sends to with . We denote by the usual inner product, and recall the classic fact that is self adjoint with respect to this inner product. We denote by its second largest eigenvalue in absolute value. Sometimes we also write instead of . It is well-known that .
Definition 8 (Expander graph).
Let . A graph is a -expander if .
This definition is usually referred to as -two-sided spectral expansion. We note that the one-sided definition where one only gets an upper bound on the eigenvalues of is also interesting, but is out of our paper’s scope (see e.g. [56]).
When is a bipartite graph, we also have inner products on each side defined by , with respect to restricted to (and similarly to real valued functions on ). The left-to-right bipartite graph operator that sends to with (resp. right-to-left bipartite operator). It is well known that is equal to the second largest eigenvalue of the non bipartite adjacency operator defined above (not in absolute value). We also denote this quantity (it will be clear that whenever is bipartite this is the expansion parameter in question).
Definition 9 (Bipartite expander graph).
Let . A bipartite graph is a -bipartite expander if .
We use the following standard auxiliary statements.
Claim 10.
Let be adjacency matrices of two graphs over the same vertex set and have the same stationary distribution. Let . Then .
We will usually instantiate this claim with being the complete graph with self loops, i.e. the edge distribution is just two independent choices of vertices. This has so we get this corollary.
Corollary 11.
Let be an adjacency matrix of a weighted graph .
-
1.
.
-
2.
In particular, if is uniform over a set with then .
We also define a tensor product of graphs.
Definition 12.
Let be graphs. The tensor product is a graph with vertices and edges if and . The measure on is the product of the original graphs’ measures.
We record the following well-known fact.
| (2.1) |
In fact, if are the eigenvalues of and are the eigenvalues of , then the eigenvalues of are the multiset .
We also need the notion of a double cover.
Definition 13 (Double cover).
Let be a graph and be the graph that contains a single edge. The double cover of is the graph . Explicitly, its vertex set is and we connect if and .
The following observation is well known.
Observation 14.
A graph is a -expander if and only if its double cover is a -bipartite expander.
2.1.1 A local to global lemma
We will use the following “local-to-global” proposition due to [81, Theorem 1.1]. We prove it in Appendix A to be self contained. This lemma is an application of the Garland method [47], which is quite common in the high dimensional expander literature (see e.g. [87]). Let us set it up as follows.
Let be a graph where is the distribution over edges. A local-decomposition of is a pair as follows. is a set such that are a subgraph of and is a weight distribution over . is a distribution over . Assume that is sampled according to the following process:
-
1.
Sample .
-
2.
Sample .
The local-to-global graph is the bipartite graph on and whose edge distribution is
-
1.
Sample .
-
2.
Sample a vertex 777i.e. is sampled with probability ..
-
3.
Output .
Note that the probability of under and that under (conditioned on the side) are the same.
Lemma 15 ([81, Theorem 1.1]).
Let be as above. Let and . Then .
We will also use the one-sided version of [81, Theorem 1.1]. For a formal proof see [26, Lemma 4.14]. We formalize it in our language.
Lemma 16.
Let be a bipartite graph. Let be a local decomposition. Let be the restriction of to the vertices of (resp. ). Then
2.2 Vector spaces
Unless stated otherwise, all vector spaces are over . For a vector space and subspaces we say their intersection is trivial if it is equal to . We denote the sum . If the sum is direct, that is the intersection of and is trivial, we write . We shall use this notation to refer both to the statement that and to the object . We need the following claim.
Claim 17.
Let be a vector space. Let be three subspaces such that . Then .
Proof.
Let where . Thus which by assumption means that and . As it follows that and the intersection is trivial.
2.3 Grassmann posets
In this paper all vector spaces are with respect to unless otherwise stated. Let be a vector space. The Grassmann partially ordered set (poset) is the poset of subspaces of ordered by containment. When is clear from the context we sometimes just write .
Definition 18 (Grassman Subposet).
Let , be an -dimensional vector space, and . An -dimensional Grassmann subposet is a subposet of such that
-
1.
every maximal subspace in has dimension ,
-
2.
if and , then .
We sometimes write . The -dimensional subspaces in are denoted . The vector space is sometimes called the ambient space of .999formally there could be many such spaces, but in this paper we usually assume that is spanned by the subspaces in .
A measured subposet is a pair where is an -dimensional Grassmann subposet and is a probability distribution over -dimensional subspaces such that . We extend to a distribution on flags of subspaces by sampling and then sampling a flag uniformly at random. Sometimes we abuse notation and write where is the marginal over said flags. We sometimes say that is measured without specifying for brevity. When we write we mean that the distribution is uniform.
The containment graph is a bipartite graph with sides and whose edges are such that . There is a natural distribution on the edges of this graph induced by the marginal of of the flag above.
Let be an -dimensional Grassmann poset. For the Grassmann poset is the poset that contains every subspace in of dimension .
A link of a subspace is denoted . It consists of all subspaces in the poset that contain , namely . If is measured, the distribution over is the distribution conditioned on the sampled flag having . We note that if is the ambient space of then is (isomorphic to) a Grassmann subposet with ambient space by the usual quotient map.
For any -dimensional subposet , any , , and , we denote . The underlying graph of the link is the following graph (which we also denote by when there is no confusion). The vertices are
and the edges are
We note that sometimes the link graph is defined by taking the vertices to be and the edges to be all such that . These two graphs are closely related:
Claim 19.
Let be a Grassmann poset. Let be a subspace and let be the underlying graph of its link as defined above. Let be the graph whose vertices are and whose edges are such that . Then .
Proof.
Let be the complete graph over vertices including self loops. We prove that . As it will follow by (2.1) that . For every we order the vectors in according to some arbitrary ordering . Our isomorphism from to sends where and the in the subscript is according to the ordering of . It is direct to check that this is a bijection.
Moreover, in if and only if . This span is equal to . Therefore if and only if the left coordinates of the images and are connected in . As is an edge in the complete graph with self loops, it follows that is in if and only if the corresponding images are connected in . The claim follows.
Thus we henceforth use our definition of a link.
We say that such a subposet is a -expander if for every and the graph is a -two-sided spectral expander. We also state the following claim, whose proof is standard.
Claim 20.
The poset is a -expander.
Sketch.
Let . By Claim 19, to analyze the expansion of the link of , it suffices to consider the graph whose vertices are the subspaces and whose edges are if . In this case, it is easy to see that this graph is just the complete graph (without self loops) with vertices. The claim follows by the expansion of the complete complex.
We also need the following claim.
Claim 21 ([30]).
Let be a Grassmann poset that is -expander. Then for every and , the containment graph between and is a -bipartite expander.
This claim was proven [30] without the explicit constant . Hence we reprove it in Appendix H with the constant.
2.4 The matrix domination poset
In this section we give preliminaries on the matrix domination posets. These posets are essential for proving that the HDX construction given in Section 3 sufficiently expands. They were a crucial component in the construction of abelian HDXs in [50]. We believe that the matrix domination posets are also interesting on their own right, being another important family of posets to be studied as those in [30, 69].
Let be matrices over for some fixed . Let . The partial order on this set is the domination order.
Definition 22 (Matrix domination partial order).
Let . We say that dominates if . In this case we write .
Another important notion is the direct sum.
Definition 23 (Matrix direct sum).
We say that two matrices and have a direct sum if . In this case we write .
We note that this definition is equivalent to saying that . We also clarify that when we write , this refers both to the object , and is a statement that . This is similar to the use of when describing a sum of subspaces ; the term refers both to the sum of subspaces, and is a statement that . We will see below that is equivalent to , so we view this notation as a natural analogue of what happens in subspaces.
In Section 3 we define and analyze expansion of graphs coming from Hasse diagrams of dominance orders. These graphs appear in the analysis of the construction in Section 3. Before doing so, let us state some preliminary properties of this partial order, all of which are proven in Appendix C. More specifically, we will show that this is a valid partial order (as already observed in [50]), discuss the properties of pairs of matrices that have a direct sum, and study structures of intervals in this poset (see definition below).
Claim 24.
The pair is a partially ordered set.
We move on to characterize when , that is, when the sum of and is direct. This will be important in the subsequent analyses.
Claim 25.
For any matrices the following are equivalent:
-
1.
, i.e. .
-
2.
The spaces and are trivial.
-
3.
The spaces and .
-
4.
There exists a decomposition and such that the disjoint unions and are independent sets. Indeed, the two sets span and respectively.
We will also use this elementary (but important) observation throughout.
Claim 26 (Direct sum is associative).
Let . If and have a direct sum, and has a direct sum with , then has a direct sum with . Stated differently, if and , then . The same holds for any other permutation of and .
Henceforth, we just write to indicate that for any three distinct .
Finally, we will analyze subposets of that correspond to local components which are analogous to the links in simplicial complexes and Grassmann posets.
Definition 27 (Intervals).
Let be two matrices. The interval between and is the subposet of induced by the set
Similar to the above, we also denote by the matrices in of rank . When we just write .
The main observation we need on these intervals is this.
Proposition 28.
Let be of ranks . The subposets and are isomorphic by . This isomorphism has the property that
Another subposet we will be interested in is the subposet of matrices that are “disjoint” from some . That is,
Definition 29.
Let . The subposet is the subposet of consisting of all .
We note that by Claim 25 .
Claim 30.
Let . Then is an order preserving isomorphism.
2.5 Simplicial complexes and high dimensional expanders
A pure -dimensional simplicial complex is a hypergraph that consists of an arbitrary collection of sets of size together with all their subsets. The -faces are sets of size in , denoted by . We identify the vertices of with its singletons and for good measure always think of . The -skeleton of is . In particular the -skeleton of is a graph. We denote by the diameter of the graph underlying .
2.5.1 Probability over simplicial complexes
Let be a simplicial complex and let be a density function on (that is, ). This density function induces densities on lower level faces by . We omit the level of the faces When it is clear from the context, and just write or for a set .
2.5.2 Links and local spectral expansion
Let be a -dimensional simplicial complex and let be a face. The link of is the -dimensional complex
For a simplicial complex with a measure , the induced measure on is
Definition 31 (Local spectral expander).
Let be a -dimensional simplicial complex and let . We say that is a -local spectral expander if for every , the link of is connected, and for every it holds that .
We stress that this definition includes connectivity of the underlying graph of , because of the face . In addition, in some of the literature the definition of local spectral expanders includes a spectral bound for all and . Even though the definition we use only requires a spectral bound for links of faces , it is well known that when is sufficiently small, this actually implies bounds on for all and (see [87] for the theorem and more discussion).
Cayley Graphs and Cayley Local Spectral Expanders
Definition 32 (Cayley graph over ).
Let . A Cayley graph over with generating set is a graph whose vertices are and whose edges are . We denote such a graph by .
Note that we can label every edge in by its corresponding generator. A Cayley complex is a simplicial complex such that is a Cayley graph (as a set) and such that all edges with the same label have the same weight. We say that is a -two-sided (one-sided) Cayley local spectral expander if it is a Cayley complex and a -two-sided (one-sided) local spectral expander.
3 Subpolynomial degree Cayley local spectral expanders
In this section we construct Cayley local spectral expander with a subpolynomial degree, improving a construction by [50].
Theorem 33.
For every and integer there exists an infinite family of -dimensional -local spectral expanding Cayley complexes with . The degree is upper bounded by .
Golowich proved this theorem for .
As in Golowich’s construction, we proceed as follows. We first construct an expanding family of Grassmann posets over (see Section 2.3), and then we use a proposition by [50] (Proposition 37 below) to construct said Cayley local spectral expanders. The main novelty in this part of the paper is showing that this idea can be iterated, leading to a successive reduction of the degree.
The following notation will be useful later.
Definition 34.
Let be integers and . We say a Grassmann poset is a -poset if is a -dimensional -local spectral expander whose ambient space is , with .
[50] introduces a general approach that turns a Grassmann poset into a simplicial complex called the basification of . The formal definition of this complex is as follows.
Definition 35.
Given a -dimensional Grassmann poset . Its basification is a -dimensional simplicial complex such that for every
In [50] it is observed that the local spectral expansion of is identical to that of . Golowich constructs a Cayley complex whose vertex links are (copies of) the basification. The construction is given below.
Definition 36.
Given the basification of a -dimensional Grassmann complex over the ambient space , define the -dimensional abelian complex such that and for
We observe that the underlying graph is and therefore its degree is .
Proposition 37 ([50]).
Let be a -dimensional Grassmann poset over that is -expanding. Let be the abelian complex given by its basification. Then is a -local spectral expander. In addition, the underlying graph of is a -expander.
Thus our new goal is to prove the following theorem about expanding posets.
Theorem 38.
For every , and there exists infinite family of integers and of -posets .
This is sufficient to prove Theorem 33:
Proof of Theorem 33, assuming Theorem 38.
Let be an infinite family of in Theorem 38 for such that . Let be their basifications. By Proposition 37. The complexes have ambient subspace , degree , and expansion .
3.1 Expanding Grassmann posets from matrices
Let be a -poset. We now describe how to construct from it a -poset where , , and when . In other words, we describe a transformation
After this, we will iterate this construction, this time taking to be the input, producing an even sparser poset etc., as we illustrate further below.
Without loss of generality we identify the ambient space of with and set the ambient space of to be matrices (). The -dimensional subspaces of are
| (3.1) |
In words, these are all matrices whose rank is so that their row and column spaces are in . As we can see, and and therefore . We postpone the construction higher dimensional faces (which determine the dimension ) and the intuition behind the expansion of for later. Let us first show how an iteration of this construction will construct sparser Grassmann posets.
This single step can be iterated any constant number of times, starting from a high enough initial dimension . Let us denote by the operator that takes as input one Grassmann poset and outputs the sparser one as above. Fix and fix a target dimension . Let and let be sufficiently large. We set to be such that (which is a -poset for and that goes to with ) and . The final poset is a
Here , , and when .
The above construction works for any large enough . This gives us an infinite family of Grassmann complexes whose ambient dimension is and whose degree is (where ). This infinite family proves Theorem 38.
3.1.1 The construction of the Grassmann poset
We are ready to give the formal definition of the poset. We construct the top level subspaces, and then take their downward closure to be our Grassmann poset. Every top level face is going to be an image of a “non-standard” Hadamard encoding. The “standard” Hadamard could be described as follows. Let be a vector space, and let be indexed by the vectors in . That is where is the the standard basis vector that is in the -th coordinate and elsewhere. With this notation the “standard” Hadamard encoding maps
where is the standard bilinear form. A “non-standard” Hadamard encoding in this context is the same as above, only replacing the standard vectors with another basis for a subspace, represented by matrices. It is defined by a set satisfying some properties described formally below. The encoding is the linear map ,
similar to the formula above. We continue with a formal definition.
We start with , a -poset (and assume without loss of generality that is a power of ) and let 101010Although we define this poset to the highest dimension possible. Our construction will eventually take a lower dimensional skeleton of it..
Definition 39 (Admissible function).
Consider a -poset with . Let , a (not necessarily linear) function is admissible to if:
-
1.
For every , .
-
2.
The sum matrix is a direct sum of the ’s, that is,
-
3.
The spaces .
We remark that for the construction we only need to consider admissible functions for , that is, functions , where , and . The other admissible functions will be used later in the analysis (see Section 7).
We denote by the set of admissible functions . The Hadamard encoding of a function is the linear function given by
Observe that is an isomorphism so the image of is an -dimensional subspace. This of course means that every subspace is mapped isomorphically to a subspace of the same dimension . Thus, the Grassmann poset is isomorphic to the complete Grassmann .
Definition 40 (Matrix poset).
The poset is a -dimensional poset . We denote by the operator that takes and produces as above.
In other words, is clearly a Grassmann poset and it is a union of for all admissible mappings .
The admissible functions on level give us a natural description for :
Claim 41.
Let be as in Definition 40. Then
We prove this claim in Appendix B.
This poset also comes with a natural distribution over -subspaces is the follows.
-
1.
Sample two -dimensional subspaces independently according to the distribution of .
-
2.
Sample uniformly an admissible function such that the matrix has and .
-
3.
Output .
We remark that we can generalize this construction by changing the definition of “admissible” to other settings. One such generalization that replaces the rank function with the hamming weight results in the Johnson poset which we describe in Section 4. We explore this more generally in Section 7.
We finally reach the main technical theorem of this section, Theorem 42. This theorem proves that if is an expanding poset, then so is a skeleton of . Using this theorem inductively is the key to proving Theorem 38.
Theorem 42.
There exists a constant such that the following holds. Let , and be an integer. Let and let . If is a -poset then the -skeleton of , namely , is a -poset where and .
Proof of Theorem 38, assuming Theorem 42.
Fix and without loss of generality for some integer . Changing variables, it is enough to construct a family of -posets for an infinite sequence of integers , such that the constant in the big only depends on and but not on . Then by setting gives us the result 111111Technically this only gives a family -posets. But can be arbitrarily small. Thus for any , constructing -posets is also a construction of -posets, since eventually for any constant independent of .
We prove this by induction on for all and simultaneously. For we take the complete Grassmanns, namely and the family that are -posets for sufficiently large (the first three parameters are clear. By Claim 20 the links expansion of the complete Grassmann is which goes to with , hence for every and large enough they are -expanders).
Let us assume the induction hypothesis holds for and prove it for . Fix and . By Theorem 42, there exists some and such that if we can find a family of -posets , then the posets are -posets. By the induction hypothesis (applied for and ) such a family indeed exists. The theorem is proven.
3.2 A Proof Roadmap for a single iteration of - Theorem 42
The rest of this section is devoted to proving Theorem 42, and mainly to bounding the expansion of links in . Recall the notation to be the poset of matrices with the domination relation.
We fix the parameters and . Without loss of generality we take to be large enough so that (this requires that for the constant in Theorem 42).
Recall the partial order defined in Section 2.4 on matrices where we write for two matrices if .
Fix , and let . Let be a subspace (where ). In the next two subsections we describe the two steps of the proof: decomposition and upper bounding expansion.
3.2.1 Step I: decomposition
We will show that a link of a subspace decomposes to a tensor product of simpler components.
For this we must define two types of graphs, relying on the domination relation of matrices and the direct sum.
Definition 43 (Subposet graph).
Let and let . The graph has vertices and edges such that there exists such that .
For any two of rank , the graphs so we denote this graph by when we do not care about the specific matrix.
Definition 44 (Disjoint graph).
Let and let . The graph has vertices and edges such that there exists such that we have .
For any and two , the graphs so we denote this graph by when we do not care about the specific matrix.
The first component in the decomposition in the link of is the subposet graph. The second component is the sparsified link graph. This graph depends on , unlike the previous component. In particular, the matrices in this component will have row and column spaces in . For the rest of this section we fix . Let be any matrix whose row span and column span are and . Note that both and have dimension (that is, ). The following definition will only depend on these row and column spaces, but it will be easier in the analysis to give the definition using this matrix .
Definition 45 (Sparsified link graph).
The graph is the graph with vertex set
The edges are all such that there exists a matrix such that , and are an edge in .
Formally, the distribution over edges in the sparsified link graph is the following.
-
1.
Sample and according to their respective distributions.
-
2.
Uniformly sample a matrix such that and .
-
3.
Sample an edge in .
We can now state our decomposition lemma:
Lemma 46.
.
This lemma is proven in Section 3.3.
3.2.2 Step II: upper bounding expansion
It remains to show that and are expander graphs. We prove the following two lemmas.
Lemma 47.
There exists an absolute constant such that for all .
In particular, there is an absolute constant such that the following holds: Let . If and , then
Lemma 48.
There exists a constant such that the following holds. Let be a -poset for , and let where and . Then .
In particular, there is an absolute constant such that the following holds: Let . If , and , then
The constant in Theorem 42 is chosen to be . We now give an high level explanation of the proofs of Lemma 47 and Lemma 48, and afterwards we use them to prove Theorem 42.
The graph does not depend on and the proof of Lemma 47 relies only on the properties of the matrix domination poset. Therefore it is deferred to Appendix D. In a bird’s-eye view, we use Lemma 16, the decomposition lemma, to decompose the graph into smaller subgraphs, and show that every subgraph is close to a uniform subgraph.
We prove Lemma 48 in Section 3.4. Its proof also revolves around Lemma 16, only this time the subgraphs in the decomposition come from (pairs of) subspaces in . Observe that in the first step in sampling an edge in Definition 45, one first samples a pair . The subgraph induced by fixing and in the first step is isomorphic to a graph that contains all rank matrices in for some , that are a direct sum with some matrix (independent of ). Thus every such subgraph is analyzed using the same tools and ideas as in the proof of Lemma 47.
In order to apply Lemma 16, we also need to show that the decomposition graph expands (see its definition in Section 2.1.1). This is the bipartite graph where one side is the vertices in , and the other side are the pairs of subspaces . A matrix is connected to if and .
To analyze this graph, we reduce its expansion to the expansion of containment graphs in . We make the observation that we only care about and , since if and have the same rowspan and colspan, then they also have the same neighbors. To say this in more detail, where is some complete bipartite graph, and replaces the matrices in with (here every matrix is projected to in ). The graph itself is a tensor product of the containment graph of and . Fortunately, as we discussed in Section 2.3, this graph is an excellent expander, which concludes the proof.
Given these components we prove Theorem 42.
Proof of Theorem 42.
Let us verify all parameters . The dimension is clear from the construction.
The size since it is enough to specify vectors to construct a rank matrix (of course we have also double counted since many decompositions correspond to the same matrix). Thus .
Let us verify that the ambient space is dimensional, or in other words that really spans all matrices (recall that we assumed without loss of generality that ’s ambient space is ). For this it is enough to show that there are linearly independent matrices inside . Let be linearly independent vectors. The ambient space of is . Let us show that is spanned by the matrices inside . Indeed, choose some subspaces such that . Then contains all rank matrices in whose row and column spans are inside . These matrices span all matrices whose row and column spans are in and in particularly they span .
Finally let us show that all links are -expanders. Fix . By Lemma 46
so . Both are -expanders by Lemma 47 and Lemma 48 when the conditions of the theorem are met.
To sum up, is a -expanding poset.
Remark 49.
For the readers who are familiar with [50], we remark that contrary to that paper, we do not use the strong trickling down machinery developed in [69]. [69] show that expansion in the top-dimensional links trickles down to the links of lower dimension (with a worse constant, but still sufficient for our theorem). A priori, one may think that using [69] could simplify the proof. However, in our poset all links have the same abstract structure, so we might as well analyze all dimensions at once. Moreover, one observes that in many cases the bound on the expansion of these posets actually improves for lower dimensions.
3.3 Proof of the decomposition lemma - Lemma 46
Claim 50 ([50, Proposition 55]).
Let and let . Then there exists matrices of of rank , whose direct sum is denoted by , such that the link graph
This is not just an abstract isomorphism. The details are as follows. First, [50] observes that given , for some admissible , the set does not depend on , only on . We denote it by .
Intuitively, the following proposition follows from the ’Hadamard-like’ construction of the Grassmann, and the intersection patterns of Hadamard code.
Proposition 51 ([50, Lemmas 59,61,62]).
Let , let , let be as above, with . For every matrix such that there exists unique matrices such that
-
1.
.
-
2.
.
-
3.
For the matrices . That is, .
-
4.
The matrix . That is, (resp. ) intersects trivially with (resp. ).
-
5.
The function is an isomorphism
We restate and reprove this proposition in Section 7. The proof our decomposition lemma is short given the one from [50]. For this (and this only) we need to slightly alter Definition 40 and Definition 45 so that we take into account two posets instead of one. Let be two posets of the same dimension .
Definition 52 (Two-poset admissible function, generalizing Definition 39).
An admissible function with respect to to be a function as in Definition 39 with the distinction that the row and column spaces of the matrix are
Definition 53 (Two-poset matrix poset, generalizing Definition 40).
We denote by the matrix poset defined in Definition 40 such that the admissible functions are with respect to and .
Definition 54 (Two-poset sparsified link graph, generalizing Definition 45).
For we denote by the graph in Definition 45, with the distinction that all sums of row spaces are required to be in and all column spaces are required to be in (instead of them all being in the same poset ).
Proof of Lemma 46.
Fix and its corresponding and . Conditioned on , the first step of the sampling distribution in Definition 40 is the same as sampling and (where ). Fixing the pair and conditioning on all three , sampling an edge in the link is the same as sampling an edge in the link of in the complex . As both and are isomorphic, 121212Recall that is the Grassmann poset containing all subspaces of .. We are back to the complete Grassmann case and are allowed to use Proposition 51. Let be the subgraph obtained when fixing and conditioning on . By Proposition 51, we can decompose this graph to a tensor product
The first components are independent of and ; they are constant among all conditionals (and are all isomorphic to ). Hence this is isomorphic to where is the graph corresponding to a subgraph of obtained by conditioning the edge-sampling process of to sampling and in the first step. Thus the graph and the lemma is proven.
3.4 Expansion of the sparsified link graph
In this section we use the decomposition lemma to reduce the analysis of the sparsified link graph to the case of the complete Grassmann and prove Lemma 48.
We use the following claim on the complete Grassmann.
Claim 55.
Let be the poset of rank matrices for a sufficiently large . Let and let be such that . Then for some universal constant .
We prove this claim in the next section.
Proof of Lemma 48.
Fix the subspace and recall the notation . We intend to use Lemma 15. The local decomposition we use is the following . For every pair we define the graph which is the subgraph obtained by conditioning on being sampled in the first step of Definition 45. The distribution is the distribution that samples independently. By definition of this is indeed a local-decomposition.
We observe that the subgraph of obtained by fixing and in the first step is just and hence by Claim 55 it is a -expander.
Observe that we only care about , and any two with , have the same neighbor set. In other words, this graph is isomorphic to the bipartite tensor product where is the containment graph between and (resp. and ), and is the complete bipartite graph with vertices on one side and a single vertex on the other side. The number is the number of matrices such that , for any pair of fixed subspaces and . By Claim 21 and the fact that is -expanding, the graph is a , where is some constant and the last inequality is because .
By Lemma 15, .
4 Johnson complexes and local spectral expansion
In this section we construct a family of simplicial complexes which we call Johnson complexes whose degree is polynomial in their size. The underlying -skeletons of Johnson complexes are abelian Cayley graphs . We prove in this section that these complexes are local spectral expanders and in particular the links of all faces except for the trivial face have spectral expansion strictly smaller than . We then compare the Johnson complexes with the -dimensional local spectral expanders constructed from random geometric graphs [74] and show that the former complexes can be viewed as a derandomization of the latter random complexes. On the way we also define Johnson Grassmann posets , analogous to the matrix posets given in Section 3.1, and prove in Section 4.4 that Johnson complexes are exactly , which are Cayley complexes whose vertex links are basifications of s (Definition 36).
Remark 56.
Later in Section 7, we shall define the induced Grassmann posets which generalize both the Johnson Grassmann posets and the matrix Grassmann posets, and we shall provide a unified approach to show local spectral expansion for induced Grassmann posets. However in this section, we will present a more direct proof of local expansion that is specific to Johnson complexes.
We name our construction Johnson complexes due to their connection to Johnson graphs. In particular, all the vertex links in a Johnson complex are generalization of Johnson graphs to simplicial complexes. So we start by giving the definition of Johnson graphs and then provide the construction of Johnson complexes.
Definition 57 (Johnson graph).
Let be integers. The adjacency matrix Johnson graph is the (uniformly weighted) graph whose vertices are all sets of size inside and two sets are connected if .
Next we define Johnson complexes. We shall use to denote the Hamming weight of a binary string .
Definition 58 (Johnson complex ).
Let and be any integer. Let and let be such that . Let (abbreviate as when is clear from context). The -weight Johnson complex is the -dimensional simplicial complex defined as follows.
For the rest of this work, we fix as above.
It turns out that the weight constraints on -faces in a Johnson complex gives rise to a Hadamard-like intersection pattern for elements in the link faces. Any -face in the link of can be written as . If we identify each with the set of nonzero coordinates in it, these sets always satisfy that any two distinct sets intersect at exactly coordinates, and in general any distinct s intersect at coordinates. We note that this is similar to the intersection pattern of distinct codewords in a Hadamard code.
The main result of this section is proving that all links of this complex are good expanders.
Lemma 59 (Local spectral expansion of Johnson complexes).
For any , the link graph of any -face in the -dimensional Johnson complex is a two-sided -spectral expander. In particular, is a -dimensional two-sided -local spectral expander.
The key observation (Proposition 62) towards showing this lemma is that the link graphs of -faces are the tensor product of Johnson graphs.
Once this decomposition lemma is proven, we can use the second eigenvalue bounds for Johnson graphs to show that the links are -spectral expanders. We note that this construction breaks the link expansion barrier of known elementary constructions of local spectral HDXs (discussed in the introduction). Because our construction breaks this barrier, using the Oppenheim’s trickle down theorem [87], we directly get that the -skeleton of the Johnson complex is also a -spectral expander.
We now outline the rest of this section. First, we prove the link decomposition lemma Proposition 62. Then using this lemma we show that Johnson complexes are basifications of Johnson Grassmann posets. Afterwards, we apply this lemma to prove the main result. Finally, we conclude this section by comparing the density parameters of the Johnson complexes with those of spectrally expanding random geometric complexes.
4.1 Link decomposition
In this part we prove the link decomposition result. Note that by construction the links of all vertices are isomorphic. So it suffices to focus on the link of (denoted by ) to show local spectral expansion for . The link decomposition is a consequence of the Hadmard-like intersection patterns of the faces in as explained earlier.
For the rest of the section, we use to denote the set of nonzero coordinates in a vector and use to denote . We now state the face intersection pattern lemma.
Lemma 60.
Let be an integer. Given a set and a subset , define
Then if and only if for any subset ,
Proof.
We first verify that every set satisfying the cardinality constraints above is in . Recall that by definition if and only if they satisfy the weight equations
Observe that the set of nonzero coordinates in are precisely that are nonzero in odd number of vectors in
and that by definition the set is a partition of . Therefore the weights can be rewritten as
| (4.1) |
Furthermore, for any nonempty subset there are nonempty sets whose intersection with has odd cardinality: let , then the number of ’s subsets of odd cardinality is
So the total number of such is . Therefore if when , then . Thus under this condition .
Next we prove by induction that any satisfies the conditions on . The statement trivially holds when . Suppose the same statement holds for all -faces where .
By (4.1), we can deduce that every satisfies:
| (4.2) |
Then by the induction hypothesis we know that for is the unique solution to the set of constraints above.
Now consider the set of constraints for the -face . There are in total variables and we denote them where and . The new variables are related to variables in via the identity . So (4.2) can be expanded as:
| (4.3) |
Additionally, via (4.1) the weight constraints can be rewritten as:
| (4.4) |
Finally using the constraint , we obtain equations:
| (4.5) |
The constraints in (4.6) are exactly the same as the set of constraints in (4.2) except that the RHS values are instead of . Therefore by the induction hypothesis, the unique solution is . As a result . Finally we also have and . Thus we complete the induction step.
Corollary 61.
Let be an integer and . For any , ’s nonzero coordinate set can be decomposed into the disjoint union of sets each of size as follows,
Applying this coordinate decomposition to vertices and edges in the link graph of any face in , we obtain the following characterization of the graphs.
Proposition 62.
Let be an integer and let . For any -face in , the underlying graph of its link is isomorphic to where .
Proof.
Give an -face in , we note that by construction its link is isomorphic to the link of . So without loss of generality we only consider -faces of the form above and we denote such a face by . The by definition the vertex set in the link of can be written as
By the decomposition lemma Corollary 61, we have the following isomorphism between the link vertices and collections of disjoints sets in . First recall the notation . Then the isomorphism is given by
We use to denote the set .
Similarly, using Corollary 61 we can write the edge set as:
Therefore the adjacency matrix of ’s link graph has entries:
The product structure of gives rise to a natural decomposition into tensor products of matrices where
4.2 Local spectral expansion
We now finish the local spectral expansion proof for Johnson complexes using Proposition 62 together with the following Johnson graph eigenvalue bounds and the trickle-down theorem.
Theorem 63 ([24]).
Let be the unnormalized adjacency matrix of . The eigenvalues of are where
We note that in the theorem above are unnormalized eigenvalues of the Johnson graphs. In the rest of the paper when we talk about spectral expansion, we consider normalized eigenvalues whose values are always in .
We specifically care about the second eigenvalues of the Johnson graphs with . The case of is proved in [70].
Lemma 64 ([70]).
The Johnson graph ’s eigenvalues satisfy .
In other words, the graph is a two-sided -spectral expander.
For the case , we show the following lemma (proof in Appendix E):
Lemma 65.
For any constant , the Johnson graph ’s eigenvalues satisfy that . In other words the graph is a -spectral expander.
The trickle-down theorem states that local spectral expansion implies expansion of all links.
Theorem 66 ([87]).
Let . Let be a -dimensional connected simplicial complex and assume that for any vertex , the link is a two-sided -spectral expander, and that the -skeleton of is connected. Then the -skeleton of is a two-sided -spectral expander. In particular, is a two-sided local spectral expander.
Now we are ready to prove the main result of this section.
Proof of Lemma 59.
Let be any -face in the complex. By Proposition 62, the link graph of is . Since eigenvalues of are , by Equation 2.1 the second largest eigenvalues satisfy . Therefore the link graph of has (via Lemma 64 and Lemma 65). Therefore the -dimensional Johnnson complex is a two-sided -local spectral expander.
Furthermore, applying the trickle-down theorem to the -skeleton we get that the underlying graph of the complex is a two-sided -spectral expander.
4.3 Comparison to local spectral expanders from random geometric complexes
In this part, we compare the structure of the Johnson complexes to that of the random geometric complexes from [74]. We observe that the former can be viewed as a derandomization of the latter.
The random -dimensional geometric complex (RGC) is defined by sampling i.i.d. points from the uniform distribution over the -dimensional unit sphere, adding an edge between if where is picked so that the marginal probability of an edge is , and adding a -face if the three points are pairwise connected. In the following parameter regime the complexes have expanding vertex links.
Theorem 67 (Rephrase of Theorem 1.6 in [74]).
For every , there exists and such that when for , with high probability every vertex link of is a two-sided -local spectral expander whose vertex links are -spectral expanders.
The Johnson complex with can be viewed as an approximate derandomization of the RGCs in over vertices. Note that the points in (which are boolean vectors) embed in the natural way to . Furthermore, these points in all lie on a sphere of radius centered at . Two points are connected in if the distance between their images in is exactly . The distinction from edges in RGCs is that in Johnson complexes points of distance are not connected. Albeit the analysis in [74] shows that most neighbors of a vertex have distance so this is not a significant distinction. Similar to RGCs, three points in form a -face if they are pairwise connected. By Lemma 59 the resulting -dimensional Johnson complex has degree 131313 is the binary entropy function . and its vertex links are -spectral expanders.
Remark 68.
We further observe that while both constructions yield local spectral expanders with arbitrarily small polynomial vertex degree, the link graphs of the Johnson complexes are much denser. Use to denote the number of vertices in the complexes. Then in the Johnson complexes the link graphs have vertex degree while in the RGCs the link graphs have average vertex degree . We remark that one can use a graph sparsification result due to [21] to randomly subsample the -face in while preserving their link expansion. As a result we obtain a family of random subcomplexes of the Johnson complexes that are local spectral expanders with similar vertex degree and link degree as the random geometric complexes. Detailed descriptions and proofs are given in Appendix F.
4.4 Johnson Grassmann posets
In this part, we take a small digression to define the Johnson Grassmann posets and show that their basifications are exactly Johnson complexes .
Definition 69 (Johnson Grassmann posets ).
Let . For every , define the admissible function set as
Define the Hadamard encoding of as
For each admissible function , use to denote the Grassmann poset
Then the Johnson Grassmann poset is .
We first verify that these posets are well-defined.
Claim 70.
For all , .
Proof.
The claim trivially holds for . For , we need to prove that (1) for every , there exist and -dimensional subspace such that and (2) for every , any subspace is in .
We first prove (1). Given any admissible function , for every and , use to denote the vector that is nonzero only at the -th nonzero coordinate of . Here we identify the vector in a natural way with a number in . Use to denote the sum . Set to be the subspace that spans the first coordinates in , and set as follows
Then it is straightforward to verify that and that .
Next we check (2). Note that the codespace is a -dimensional subspace in whose nonzero elements have weight . Furthermore, consider any linear subspace of dimension . Since is an isomorphism, there exists a -dimensional linear subspace such that which is the image of restricted to the domain . Let be a linear map from to , and be such that . Define the function as follows
By construction, is admissible and furthermore for every
We derive that . Thus and so the claim is proven.
Remark 71.
We observe that is a subposet of the complete Grassmann poset , and is obtained by applying the sparsification operator to .
We now prove that is the basification of using the link decomposition result.
Claim 72.
The -dimensional Johnson complex is the -skeleton of the basification of .
Proof.
To prove the claim it suffices to show that any if and only if all non-empty subset has . In this proof we abuse the notation a bit and identify a vector in with the set of its nonzero coordinates.
For the if direction, given , construct such that where is the set of nonzero coordinates of if , and the set of zero coordinates of if . By Lemma 60, all such ’s have weights exactly . By construction their nonzero coordinates are disjoint from each other’s. So is an admissible function. Furthermore, let be elementary vectors in ,
Therefore .
For the only if direction, we can easily check that any contains only vectors of weight . So given any basis of , their nonzero linear combinations all have weight . Now the proof is complete.
5 Coboundary expansion and a van Kampen lemma
In this section we give the necessary preliminaries on coboundary expansion and also introduce a version of the famous van Kampen Lemma [97] that shall be used to prove coboundary expansion in the next section.
5.1 Preliminaries on coboundary expansion
We define coboundary expansion for general groups, closely following the definitions and notation in [28]. For a more thorough discussion on the connection between coboundary expansion and topology, we refer the reader to [28]. In the introduction we defined coboundary expansion as a notion of local testability of a code (which was a subspace of the functions on the edges). Instead of defining coboundary expansion for only -valued functions, we give the most general version of coboundary expansion, which uses arbitrary groups.
Let be a -dimensional simplicial complex for and let be any group. Let be the directed edges in and be the directed -faces. For let . We sometimes identify . For let
and
be the spaces of so-called anti symmetric functions on edges and triangles. For we define operators by
-
1.
is .
-
2.
is .
-
3.
is .
Let be the function that always outputs the identity element. It is easy to check that for all and . Thus we denote by
and have that .
Henceforth, when the dimension of the function is clear from the context we denote by .
Coboundary expansion is a property testing notion so for this we need a notion of distance. Let . Then
| (5.1) |
We also denote the weight of the function .
Definition 73 (-dimensional coboundary expander).
Let be a -dimensional simplicial complex for . Let . We say that is a -dimensional -coboundary expander if for every group , and every there exists some such that
| (5.2) |
In this case we denote .
This definition in particular implies that for any coefficient group.
Coboundary expansion generalizes edge expansion
We note that -dimensional coboundary expanders are generalizations of edge expanders to simplicial complexes of dimension . A graph is a -dimensional simplicial complex. For we can analogously define function spaces , , and operators and over .
Observe that consists of constant functions over the vertices. Using the notations above we can write the definition of a -dimensional coboundary expander as follows.
Definition 74 (-dimensional coboundary expander in ).
A -dimensional simplicial complex is a -dimensional -coboundary expander in if for every there exists some such that
| (5.3) |
Let us check that this is equivalent to the definition of -edge expanders in terms of graph conductance. Viewing every function as a partition of into two sets and and viewing as the indicator function of whether an edge is in the cut between and , we derive that
Then the condition Equation 5.3 is equivalent to the statement that for every vertex partition of the graph ,
This is the standard definition of a -edge expander.
Coboundary Expansion and Local Testability
One should view coboundary expansion as a property testing notion. We call a code (as a subset, no linearity is assumed in the general case). Given a function in the ambient space one cares about its Hamming distance to the code, that is, how many edges of need to be changed in order to get a word in . Denote this quantity . Coboundary expansion relates this quantity to another quantity, the fraction of triangles such that , namely .
We note that if , namely satisfies the property of being in the function space, then one can verify that , or in other words, that . In a -coboundary expander we get a robust inverse of this fact. That is, that if is -far from any function in , then its coboundary is not equal to the identity on at least a -fraction of the triangles.
This suggests the following natural test for this property.
-
1.
Sample a random triangle .
-
2.
Accept if and only if (or equivalently ).
Note that is the probability that fails the test. Saying that a complex is a coboundary expander is saying that this test is sound, namely is a -coboundary expander if and only if for every
| (5.4) |
Over , this view of coboundary expansion was first observed by [61], who used it for testing whether matrices over have low rank. This view also appeared in [41] for a topological property testing notion called cover-stability. In later works, this test was as a component in the analysis of agreement tests [51, 27, 10]. We also refer the reader to [10, 29] for additional connections of coboundary expansion and local testing in the context of unique games problems and to [18] for its connection to group (te)stability.
5.2 Contractions, cycles and cones
One general approach to proving coboundary expansion is the cone method invented by [52] and used in many subsequent works to bound coboundary expansion of various complexes [77, 63, 71, 68, 28]. The following adaptation of the cone method to functions over non-abelian groups is due to [29]. We adopt their definition of cones, and after presenting the definition, we will explain the motivation behind it as well as its connection to isoperimetric inequalities of the complex.
We use ordered sequences of vertices to denote paths in , and to denote the concatenation operator 161616If and then their concatenation is ., and for any path , we use to denote the reverse path. Fixing a simplicial complex , we define two symmetric relations on paths in .
- (BT)
-
We say that if and where .
- (TR)
-
We say that if and for some triangle and .
Let be the smallest equivalence relation that contains the above relations (i.e. the transitive closure of two relations). We comment that these are also the relations defining the fundamental group of the complex (see e.g. [95]).
We also want to keep track of the number of equivalences used to get from one path to another. Towards this we denote by if there is a sequence of paths and such that:
-
1.
and
-
2.
For every , .
I.e. we can get from to by a sequence of equivalences, where exactly one equivalence is by .
Similarly, for we denote by if we get from to using triangles.
A contraction is a sequence of equivalent cycles that ends with a single point. More formally,
Definition 75.
Let be a cycle around . A contraction is a sequence of cycles such that for every . If the contraction contains cycles, we say it uses -triangles, or simply that it is an -contraction.
A -contraction can be viewed as a witness to .
Before giving the definition of cones which are used to prove coboundary expansion, we provide some intuition behind the connection between coboundary expansion and cones. In order to prove Equation 5.4 for a complex , we need to upper bound the distance from any function to the codespace (with being the encoding function). This is done by constructing a message from and a family of paths from one vertex to every other vertex. Note that every edge together with the two paths in from to the edge’s endpoints form a cycle. The ratio between the probability that fails the test and the distance from to the codespac is bounded by these cycles’ length of contraction. The vertex , the family of paths, and the contractions of the induced cycles constitutes a cone. The connection between the cone and coboundary expansion of is captured by Theorem 78 and a detailed proof can be found in [29].
Definition 76 (cone).
A cone is a triple such that
-
1.
.
-
2.
For every , is a walk from to . For , we take to be the cycle with no edges from to itself.
-
3.
For every , is a contraction of .
The sequence depends on the direction of the edge . We take as a convention that just reverses all cycles of (which is also a contraction Of the reverse cycle). Thus for each edge it is enough to define one of .
The maximum length of contraction of among all edges is called the cone area.
Definition 77 (Cone area).
Let be a cone. The area of the cone is
We note that in previous works this was known as the diameter or radius of a cone [68, 29]. We chose the term “area” here since it aligns with the geometric intuition behind triangulation.
Gromov is the first to use the area of the cone to prove coboundary expansion for abelian groups. The following theorem which generalizes Gromov’s approach to general groups is by [29].
Theorem 78 ([29, Lemma 1.6]).
Let be a simplicial complex such that is transitive on -faces. Suppose that there exists a cone with area . Then is a -coboundary expander for any coefficient group .
5.3 Contraction via van Kampen diagrams
In this subsection we prove a version of van Kampen’s lemma for our “robust” context. Previously, we defined the area of a cycle in the cone to be the length of its contraction sequence. The van Kampen lemma reduces the problem of bounding the contraction length of a cycle to counting the number of faces in a planar graph.
The van Kampen diagrams are an essential tool in geometric group theorem [80, Chapter V]. They were introduced by van Kampen in 1933 in the context of the word problem in groups defined by presentations [97], and are a powerful visual tool for exhibiting equivalences of words of some given group presentation. They are also used to bound the number of relations required to prove that a word is equal to identity (such a bound is called the Dehn function of a presentation). The van Kampen diagrams are plane graphs that embed into the presentation complex of a group. The van Kampen lemma states that a word is equivalent to the identity if and only if it forms a cycle in the presentation complex which can be tiled by faces in a van Kampen diagram. Furthermore the number of inner faces of the diagram provides an upper bound on the relations needed to prove that the word equals to identity. The advantage of these diagrams is that they bound the length of a sequential process by the size of static objects.
We need a similar tool in the context of abstract complexes, which is a simple generalization of the above setup. Our main motivation for this statement is give a simple and intuitive way to bound the area of cones. Previous works that use the cones, give sequences of contractions, explaining which triangle goes after another (see e.g. [29]). This is sufficient for the proof. However, in all known examples, the ordering is just a formality, and the proofs were really describing a tiling (i.e. the contraction was really just a set of faces that formed a disk whose boundary is the cycle we needed to contract). So in this section we give justification to just drawing out the tiling via a van Kampen diagram instead of giving the full sequence of contraction.
A plane graph is a planar graph together with an embedding. We will denote by both the abstract graph and the embedding.
The van Kampen lemma has a few components. First we have our simplicial complex and a cycle in . In addition, we have a diagram. This diagram contains:
-
1.
A plane graph that is -vertex connected.
-
2.
A labeling such that for every edge , either , or .
It is easy to see that a walk in is mapped by to a walk in (possibly with repeated vertices).
Let be the set of faces of with being the outer face. For every face let be the cycle bounding , and let . To be completely formal one needs to choose a starting point and an orientation to the cycle, but we ignore this point since the choice is not important to our purposes.
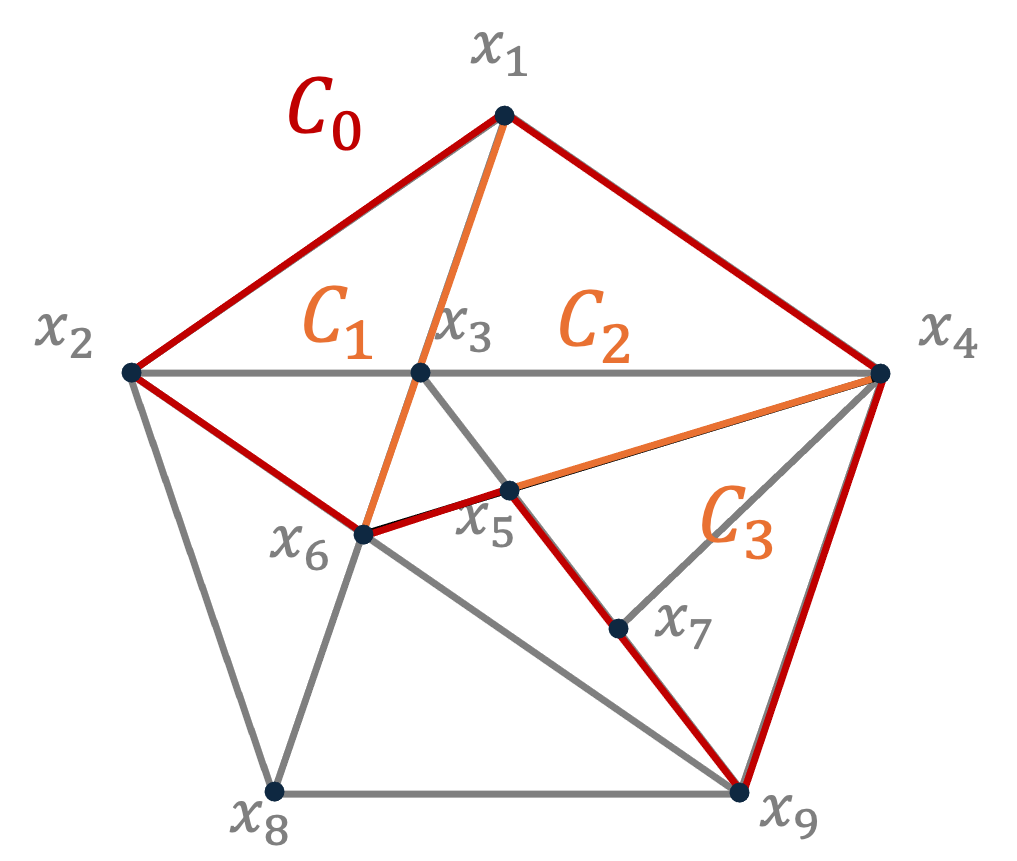
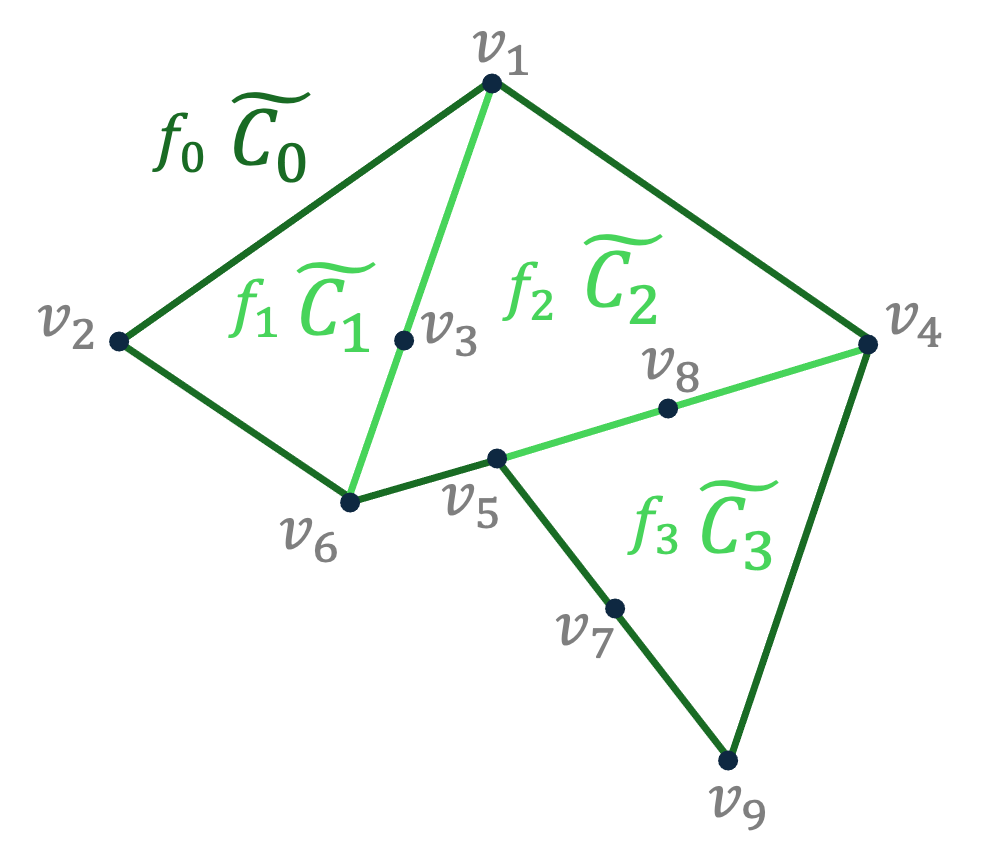
We are now ready to state our van Kampen lemma.
Lemma 79.
Let and be as above. Assume that for every the cycle has an -triangle contraction. Then there exists an -triangle contraction for where .
A proof of the lemma can be found in Appendix G. Here we give a simply example to demonstrate how to use this lemma. Consider the -dimensional complex in Figure 1(a) with vertices and -faces (all triangles in the underlying graph are -faces in ). Let be a cycle in .
A van Kampen diagram for is given in Figure 1(b). has vertices and faces . We can easily check that is -vertex connected and has the natural labeling for and . The labeling satisfies that for .
Furthermore, its clear from the figure that , , and have -triangle, -triangle, and -triangle contractions respectively. So by the van Kampen lemma, has a -triangle contraction.
5.4 Cone areas and isoperimetric inequalities
In this subsection we explain the connection between cone areas and isoperimetric inequality. In a -dimensional simplicial complex, an isoperimetric inequality is an upper bound on the area of a cycle in terms of its length. In our context this is the following.
Definition 80 (Isoperimetric inequality).
Let be a -dimensional simplicial complex and let . We say that admits an -isoperimetric inequality if for every cycle with edges there exists an -triangle contraction
Isoperimetric inequalities are particularly useful in presentation complexes of Cayley graphs in geometric and combinatorial group theory [80]. Cones are closely related to isoperimetric inequalities as was already observed by [52].
We formalize the connection with this proposition.
Proposition 81.
Let be a simplicial complex with diameter and let . Then
-
1.
If admits an -isoperimetric inequality, then has a cone whose area is at most .
-
2.
If has a cone with area then admits an -isoperimetric inequality.
Here the diameter of a complex is the diameter of the underlying graph.
Sketch.
For the first item, we construct a cone as follows. We fix an arbitrary vertex , and as for the paths , we take arbitrary shortest paths from to . Any cycle of the form (where ) has at most edges. We take the smallest contraction of this cycle as . By the isoperimetric inequality, uses at most triangles.
As for the second item, let be a cone with area and let be a cycle with edges . Let be the corresponding paths from to each of the vertices in . By Lemma 79, we can contract via the van Kampen diagram in Figure 2. We note that the boundary cycle of every inner face in the diagram corresponds to (where ) therefore its area is at most . We deduce the isoperimetric inequality .
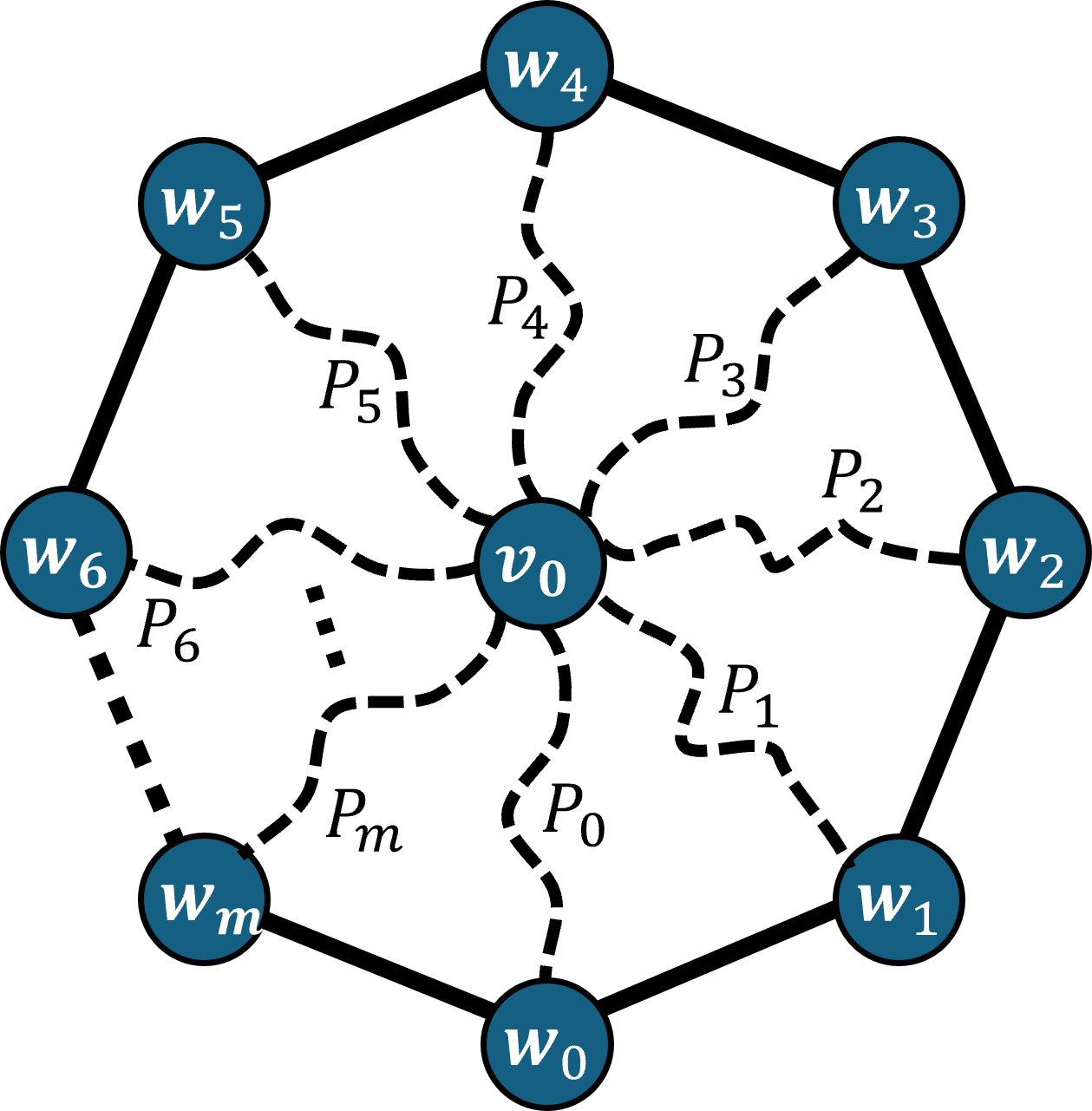
5.5 Substitution and composition
Later in Section 6.1, we will reduce the question of bounding the cone area of some complex to bounding that of which contains as a subcomplex. The relevant definitions and auxiliary proposition for this approach are given below.
Definition 82.
Let be any complex and let be a subcomplex of with . A substitution is a set of paths from to in such that (so it suffices to give one path for each pair of vertices). We say that is an -substitution if all paths have length at most .
We note that the underlying complexes of a substitution are implicit in the notation, but they will always be clear in context. Via the substitution, every path in has a corresponding path in :
Definition 83.
Let be as above and let be a substitution. Let be a path in . The composition is the path
The following proposition captures the key property of this substitution.
Proposition 84.
Let be any complex and let be a subcomplex of containing all vertices of . Let be a substitution. Assume that for every triangle , the composition of the -cycle has an -triangle contraction in . Then for every cycle in that has an -triangle contraction in , the composition cycle in has an -triangle contraction .
To prove this proposition, we need the following claim about the contraction property of two cycles with shared vertices.
Claim 85.
Let and be two cycles in such that is nonempty. If their difference cycle has an -contraction, then there is an -contraction from to .
We delay the proof of this claim and prove the proposition assuming this claim.
Proof of Proposition 84.
Let be the contraction in . Let be their compositions in . If via a TR relation and some BT relations in , by Claim 85 via the -triangle contraction of in . Since there are steps in the contraction of , we have . Lastly, since is a point, by definition of composition so is . So the proposition is proven.
Proof of Claim 85.
We first contract to the intermediate cycle via relations. Then we contract to a point without touching the part . This procedure gives a -contraction from to .
6 Coboundary expansion
Our main result in this section is proving that the Johnson complexes and their vertex links are coboundary expanders via Theorem 78. In addition, in Section 6.3, we also show that the vertex links of the complexes constructed by [50] are coboundary expanders.
Theorem 86.
Let and satisfy that . Then the -dimensional Johnson complex is a -dimensional -coboundary expander.
To show the statement via Theorem 78, it boils down to show that is transitive on -faces and that there exists a cone with area . The first claim is straightforward. The automorphism group contains all permutations of coordinates and all translations by even-weight vectors. In particular, it is transitive on all triangles. So it is enough to bound the cone area of using the following lemma.
Lemma 87.
The Johnson complex has a cone with area .
We note that by Proposition 81, this immediately implies the following corollary.
Corollary 88.
The complex admits an -isoperimetric inequality.
In addition, we also show that every vertex link of is a coboundary expander.
Theorem 89.
Let and satisfies that . In the -dimensional Johnson complex , every vertex link is a -dimensional -coboundary expander.
Remark 90.
Experts may recall the local-to-global theorem in [44] which states that if a complex is both a good local-spectral expander and its vertex links are -dim coboundary expanders then the complex is also a -dim coboundary expander. So one may suspect that the coboundary expansion theorem Theorem 86 can be derived from coboundary expansion of links (Theorem 89) and local-spectral expansion of (Lemma 59). However, this approach fails since the local-spectral expansion of is not good enough for applying the local-to-global theorem. So instead, we prove coboundary expansion of by directly using the cone method.
By link isomorphism, we can focus on the link of without loss of generality. Then the automorphism group contains all permutations of coordinates and so is transitive over (Lemma 60). By Theorem 78 it is enough to show that there exists a cone with area .
Lemma 91.
Let . Any vertex link has a cone with area at most .
As above, by Proposition 81, this implies:
Corollary 92.
A link of a vertex admits an -isoperimetric inequality.
6.1 Constructing a bounded area cone for
In this subsection we give a proof of Lemma 87. We take a two-step approach to showing that has a cone of bounded area. First we define a related complex which contains as a subcomplex, and construct a cone for with bounded area. Next, we replace every edge in with a path in between the same two endpoints. Then effectively the edges forming a triangle in become a cycle in . The second step is then to find a bounded-size tiling for every such cycle inside .
The key proposition used in this approach is as follows.
Proposition 93 (Restatement of Proposition 84 ).
Let be any complex and let be a subcomplex of containing all vertices. Let be a substitution. Assume that for every triangle , the composition of the -cycle has an -triangle contraction in . Then for every cycle in that has an -triangle contraction in , the composition cycle in has an -triangle contraction.
This proposition implies that if for the boundary cycle of every triangle , its composition has a -triangle contraction in , then the cone area of is asymptotically the same as that of . This lemma suggests a two-step strategy towards showing Lemma 87. First we construct a which has a cone of area (Claim 94 is proved in Section 6.1.2), and then we show that the boundary of -faces in has -contraction in (Claim 95 is proved in Section 6.1.3).
Claim 94.
has a cone of area .
Claim 95.
For every triangle whose corresponding boundary cycle is , we can contract the composition in using triangles.
Postponing the proofs of these lemma and claims till later subsections, we are ready to derive Lemma 87.
Proof of Lemma 87.
Claim 94 implies that the complex has cone area , while Claim 95 implies that for every triangle boundary in , its composition has a -triangle contraction in . By Proposition 93 we conclude that he cone area of is .
Before moving on, we consider two “patterns” of contractions shown in Figure 3(a) and Figure 3(b). They are going to be used extensively in the later proofs.
Definition 96 (Middle vertex contraction.).
A cycle has a middle vertex contraction in a simplicial complex if there is a vertex so that for every edge , .
Claim 97 (Middle vertex pattern).
Let be a length cycle in a simplicial complex . If has a middle vertex contraction, then has an -triangle contraction.
Proof.
Given such a cycle and a center vertex , we can construct a van-Kampen diagram for the triangles between and edges in , where is the plane graph given by Figure 3(a) and is the identity map. Note that has inner faces each corresponding to a triangle and an outer face whose boundary is . Then by Lemma 79, has an -triangle contraction.
Definition 98 (Middle path contraction.).
A -cycle has a length middle path contraction in a simplicial complex if there is a length walk so that for every edge , the triangles .
Claim 99 (Middle path pattern).
Let be a -cycle in a simplicial complex . If has a length middle path contraction, then has a -contraction.
Proof.
We again construct a van-Kampen diagram for the set of triangles , where is the plane graph given by Figure 3(b) and is the identity map. Note that has inner faces each corresponding to a triangle and an outer face whose boundary is . Then by Lemma 79, has an -triangle contraction.
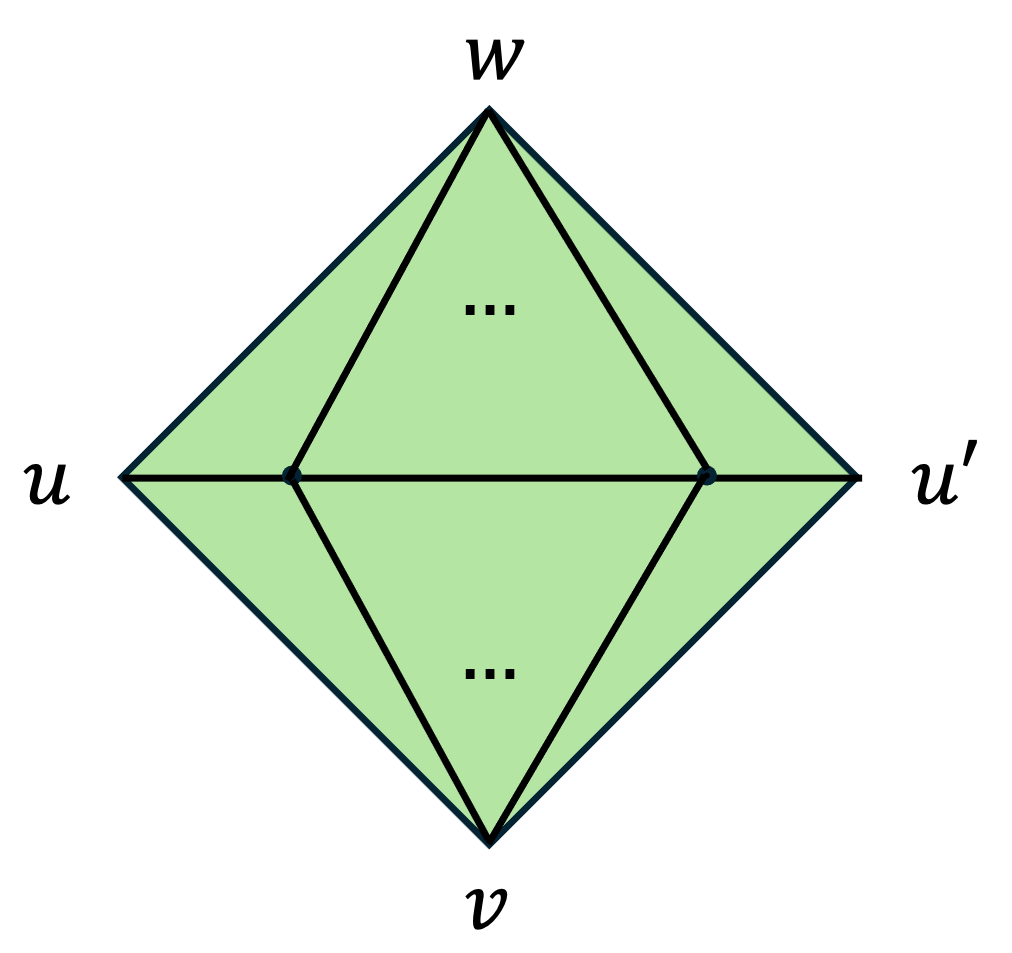
6.1.1 and its cone
In this part, we construct a -dimensional simplicial complex such that has a -substitution in .
Definition 100.
Let . The -dimensional complex is given by
Claim 101.
has a -substitution in .
Proof.
For any edge (where ), find such that . Such and can be constructed as follows: first split into two vectors of equal weight. Then take any vector of weight with disjoint support from , and set . Now by setting , we obtain a -substitution for in .
To bound the cone area of , we start by constructing a cone for . In the rest of the section we drop the subscript and simply write and . Now we introduce a few definitions in order to describe concisely.
Definition 102 (Monotone path).
A path in is called monotone if , where we identify the string with the set of coordinates that are equal to .
Analogously we can define monotone cycles.
Definition 103 (Monotone cycle).
A cycle is monotone if it can be decomposed to where are monotone paths of equal length.
Definition 104 (Lexicographic path).
Fix an ordering on the coordinates of vectors in . A path in is called lexicographic if the path is monotone and every element in is larger than all elements in under the given ordering.
We also define half-step lexicographic path.
Definition 105 (Half-step lexicographic path).
A path in is called a half-step lexicographic path if it is a lexicographic path from to such that all but the last edge in the path satisfy that , while the last edge satisfies .
Note that if and are connected then there is a unique half-step lexicographic path between them.
Analogously we can define half-step lexicographic cycles.
Definition 106 (Half-step lexicographic cycle).
A cycle in is half-step lexicographic if it can be decomposed to where are half-step lexicographic paths of equal length, and that .
This is saying that in the half-step lexicographic cycle , every edge in and satisfies that , while the endpoints of the two paths satisfy that and .
We consider the following cone :
Definition 107 (Cone of ).
Fix an ordering on the coordinates of vectors in . Set the base vertex . For every we take to be the half-step lexicographic path from to in .
6.1.2 Bounding the area of : proof of Claim 94
We prove that for every , the cycle has a -triangle contraction. The strategy is to decompose into a set of cycles in and compose these cycles’ contractions together to obtain a contraction for . The cycle decomposition is done by a recursive use of Lemma 79.
In the rest of the section, we will use both and set operations (exclusion, union, intersection, and complement) over boolean strings in . are entry-wise XOR for the boolean strings, while set operations are applied to the support of a string (i.e. the set of nonzero entries in the string).
The base case in the recursive argument is a monotone four-cycle, and we first show that all such cycles have -contraction.
Claim 108.
Let be any monotone four-cycle in . Then has a -triangle contraction.
Proof.
By definition of monotone cycles, has size and that . If we can contract since .
Otherwise , we intend to show that has a length middle path contraction. For these vertices we need to find a path between so that for every edge in that path . Let . We split to cases:
-
1.
If then we just take the path to be .
-
2.
Otherwise . Then we split and both into equal-size parts as illustrated in Figure 4. So both and have size at most . We take the path . Since the middle vertex is contained in and has size between that of and , it is connected to and to .
By Claim 99 there is a -triangle contraction of the cycle.

The general statement for all half-step lexicographic cycles is as follows.
Lemma 109.
Let and let be a half-step lexicographic cycle of length . Then has an -contraction.
Proof.
We shall decompose into monotone four-cycle and triangles in as illustrated in Figure 5. Then applying Claim 108, we deduce that has a -contraction. To describe the decomposition, we define auxiliary vertices for and . We next argue that is connected to and in .
First to show that for all is connected to and , note that . Thus if , then and would be connected to both and . To show , we observe that and analogously . Now, assume for contradiction that for some , . Similarly we deduce that . Suppose without loss of generality the largest element in comes from then is a subset of because any element added to after the -th step is larger than all elements in . Thus . We arrive at a contradiction. So indeed , and and are both connected to for .
To show that for all is connected to , note that and . To see that is connected to , note that and so .
Let be the plane graph in Figure 5 whose vertices are . By construction is a van-Kampen diagram for with inner faces.
Furthermore, we note that the cycle boundaries , and for are all monotone four cycles. and are two triangles. Applying Lemma 79 we deduce that has a -triangle contraction. Thus we conclude the proof.
Proof of Claim 94.
Let be an edge in and be the decoding cycle. Since it holds that . Thereby and similarly . Thus the triangle is in . Define the cycle , and the monotone paths and (and ). If both paths have equal length, then we can contract the cycle using -triangles by Lemma 109 as follows. We begin by constructing the following van-Kampen diagram Figure 6(a) to decompose into and : let be the graph with vertices and edges , where denote ’s vertex set and its edge set. By definition, the plane graph given in Figure 6(a) is a van-Kampen diagram with plane graph faces. embeds into as illustrated by Figure 6(a). In particular, the edge boundaries of the faces in are mapped to , and in . Therefore by Lemma 79, has a contraction.
If and are of different length, we do as follows (Figure 6(b)). Assume that is longer. Since , the length of and the length of differ by at most . By construction, the crefix that is obtained by removing the last vertices and ends with a vertex has . Thus . In this case, the triangle can be used to decompose . Denote the monotone cycle . Again by Lemma 109, has a -triangle contraction. Now we add (and also if it is not in ) to the graph . Now the van-Kampen diagram has faces (or if is not in ) whose face boundaries are mapped to (and potentially ). Since the last (or ) cycle has a -triangle contraction, has a -triangle contraction by Lemma 79.
6.1.3 Contracting with : proof of Claim 95
We move back to consider the Johnson complex which is a subcomplex of .
Claim 110.
Let be any four-cycle in . Then has an -triangle contraction.
Note that in contrast to Claim 108 we do not assume monotonicity.
Proof.
Without loss of generality . In this case has for some even . We intend to find a path between and and then apply the middle path contraction from Claim 99. For this we define the following graph .
We note that , and that if there is a length- path from to in this graph, then the four-cycle has a -triangle contraction by Claim 99.
To find such paths, we define two functions mapping tensor products of Johnson graphs to .
where every vertex in the two tensor graphs where and is mapped to . Here we implicitly identify the elements in with the set , and the elements in with . Note that the two tensor product graphs have the same vertex space. Furthermore when is an integer, the two functions are identical.
We first show that the functions give two bijections between the vertex sets: for any distinct vertices in the tensor product graphs, the unions and are also distinct in . Furthermore, for any , and both have weight . This implies that and . Therefore has the preimage under . Vertex bijectivity follows.
We next show that is actually a graph homomorphism. That is to say every edge in is mapped to an edge in . For every edge in , we have and . Subsequently
has weight . Therefore is an edge in . Thus is a vertex bijective graph homomorphism. A similar argument shows that the same is true for .
We next use the following claim to find length- paths between any pair of vertices in and then transfer this property to via .
Claim 111.
Let and be defined as above. For any two vertices and in such that and , there is a length two path in such that and .
The claim immediately implies that for any pair of vertices in the union graph , we can find an intermediate vertex such that the two components in are distinct from the components in and , and then find a length- path of the form in .
We postpone the proof of the claim and conclude that using the vertex bijective graph homomorphisms and , such paths also exist in . Therefore there exists a length- path between any two vertices in . So the four-cycle has an -triangle contraction.
Proof of Claim 111.
When is an integer, . The existence of the intermediate vertex is derived from the fact that there is a length two path between any two vertices in the Johnson graphs and .
Now we focus on the case when is odd. Construct as illustrated in Figure 7(a). Take s.t. , s.t. , s.t. , and s.t. 171717Since , the sizes on the right-hand side of the size constraints are nonnegative. So these size constraints are satisfiable.. Then set . We can verify that , , and .
Similarly, construct as illustrated in Figure 7(b). Take s.t. , s.t. , s.t. , and s.t. . Then set . We can verify that , , and .
Now by construction and , and thus we conclude the proof.
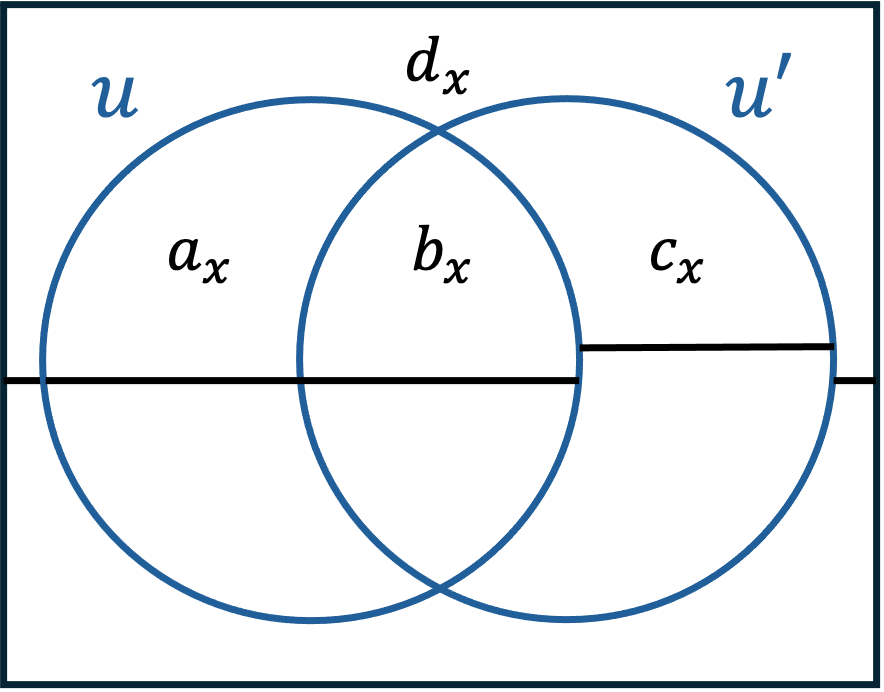
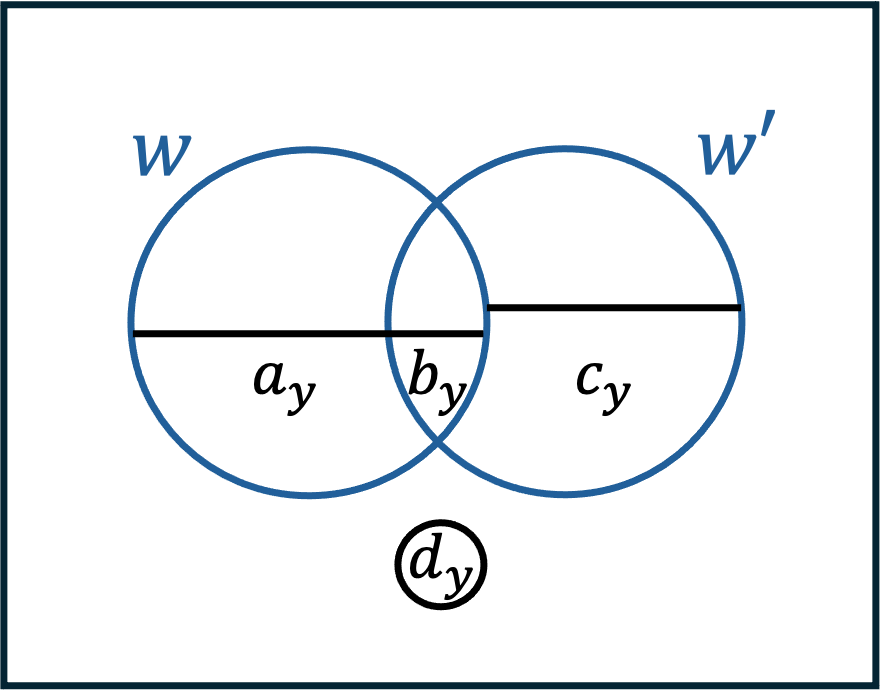
We are ready to prove the main result of this subsection
Proof of Claim 95.
Recall that by Claim 101 for every edge in we can find some such that path . So we focus on six-cycles in of the form such that is a triangle in (i.e. all have weight at most ). Let us further assume without loss of generality that . Thus, where all have weight at most .
Our plan is as follows:
-
1.
We find vertices such that is a cycle in , and such that are neighbors of .
-
2.
We decompose to five four-cycles as illustrated in Figure 8(a). Then by Claim 110 each of the four-cycle has a -triangle contraction. Furthermore, the figure gives a van-Kampen diagram with being the outer face boundary, and the four-cycles being the inner face boundaries. So applying Lemma 79, we can conclude that has a -triangle contraction.
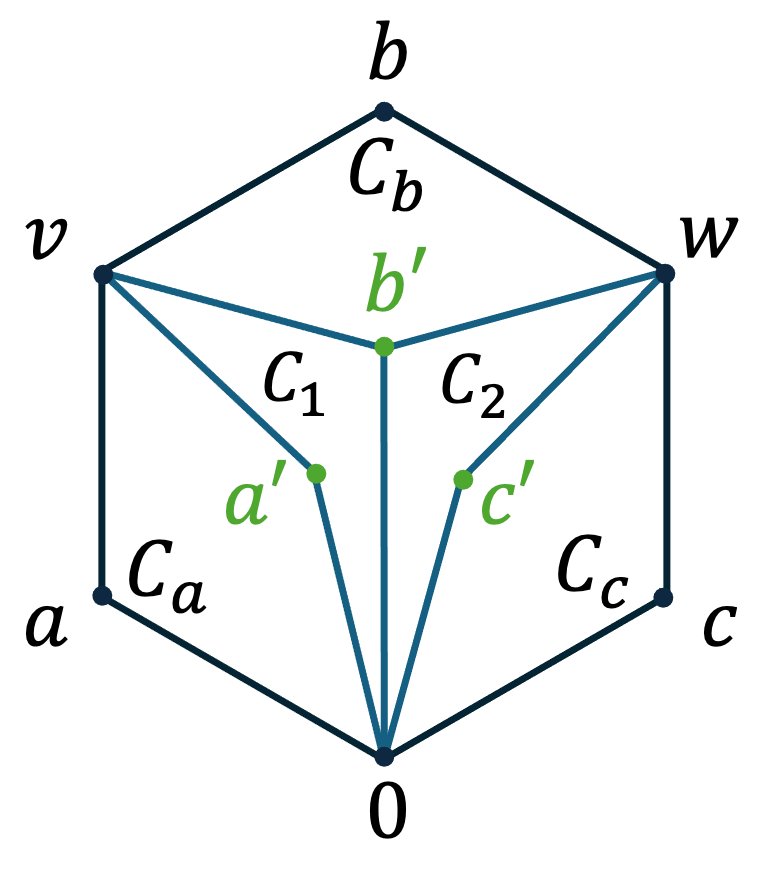
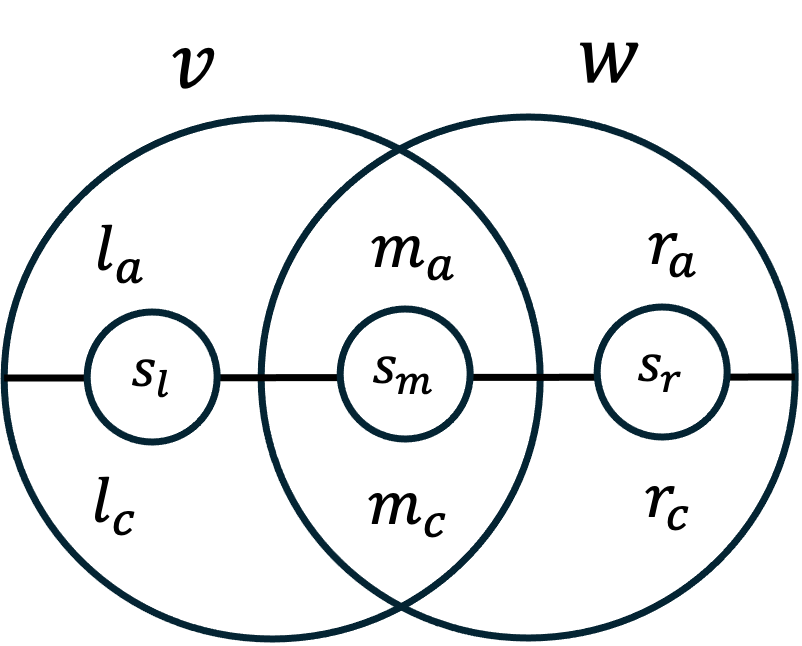
Now we construct . The construction is easy when has even weight. In this case and also have even weight. We construct the auxiliary vertices by first evenly partitioning , and , then finding a set s.t. , and setting , , and . By construction the three vertices are adjacent to and form the cycle in .
The construction becomes complicated when , , and have odd weights. In this case, we partially partition the supports of , and as follows (Figure 8(b)):
where .
Then we pick and where is supported over and . Note that since , the cardinality is well defined. Define . We note that . Similarly , so and have edges to and respectively. Furthermore and . So is connected to and . By construction are all connected to therefore the cycles all exist. Thus we complete the proof.
6.2 Cone diameter of the vertex links: proof of Lemma 91
Recall that the links of every vertex in the complex are isomorphic to one another. Therefore it is enough to prove the lemma for the link of . By Lemma 60, the underlying graph of the link complex is , and the -faces are
Let us begin with the following claim.
Claim 112.
Let be a -cycle in such that , then has a contraction using triangles.
Proof.
We intend to use the middle path pattern from Claim 99. So let us show that there exists a path such that both edges in the path form triangles with and with . To find , we find separately and and set . To find we set and note that both of these have size while has size . We note that and we take by taking coordinates from each of , an additional coordinates from each of . This is possible since:
-
1.
and
-
2.
.
Find analogously in . Then by construction are all in . So Claim 99 implies that has a -triangle contraction.
Proof of Lemma 91.
Without loss of generality consider the link of . Let be the base vertex. Since the diameter of the Johnson graph is , for any we arbitrarily choose a path of length from to as (the existence of triangles ensures that we can do this for neighboring vertices as well). To bound the cone diameter, we consider any edge and its corresponding cone cycle . Let us re-annotate .
Let us begin by reducing to the case where is disjoint from . Observe that and that . Thus and by assumption that there exists a vertex such that is disjoint from .
Since the diameter of the Johnson graph is , we can decompose into five-cycles via the van-Kampen diagram given in Figure 9(a). Then by Lemma 79, if every can be contracted by triangles, the original cycle has a -triangle contraction. So we will show next that every has a contraction of triangles.

Re-annotate such that is disjoint from . We can find some and such that the following holds:
-
1.
is disjoint from .
-
2.
is disjoint from .
-
3.
The path is a closed walk in .
If such vertices exists, then can be decomposed into two four-cycles and a five-cycle via the van-Kampen diagram in Figure 9(b). Furthermore since , each of the four-cycles can by contracted by triangles (Claim 112). Furthermore, we will soon show that has a -triangle contraction using the following claim.
Claim 113.
If a five-cycle in satisfies that every vertex is disjoint from the cycle vertices that are not neighbors of in , then has a -triangle contraction in .
Before proving this claim let us complete the proof of the lemma. Applying Lemma 79 again, we can conclude that has a -triangle contraction.
We now find such and . Partition into of equal size . Then define and . The two sets both have size since . It is straightforward to verify that the three properties above are satisfied. We thus complete the proof.


Proof of Claim 113.
Define sets to be and . By the assumption on the vertices, the sets all have size and satisfy that and . Furthermore, for each we partition it into two disjoint sets of size as illustrated in Figure 10(b).
Now we can decompose into triangles as illustrated in Figure 10(a) by defining and as follows: , , . We can verify that each of the inner face in the figure has its boundary being a triangle in . Thus has a -triangle contraction.
6.3 Coboundary expansion of links in the complexes of [50]
Even though most of this Section 6 is devoted to the Johnson complex, our techniques also extend to the complexes constructed by [50] that were described in Section 3. In this section we prove that the link of every vertex in these complexes are coboundary expanders.
Lemma 114.
Let for . Let be the basification of . Then has a cone with area and is therefore a -dimensional -coboundary expander.
The proof of this lemma is just a more complicated version of the proof of Lemma 91. Before proving the lemma, we give an explicit description of the link structure. The vertices are , i.e. all matrices of a certain rank . The edges are
Finally, the triangles are all such that there exist such that the sum is direct, and
This description is a direct consequence of the definition of admissible functions in Section 3.
We follow the footsteps of the proof of Lemma 91. Towards this we need two claims. The first proves that there exist length paths between any two vertices in , so that we can construct a cone where the cycles have constant length. This was immediate in the Johnson case but needs to be argued here. This claim also constructs length- paths between any two matrices that form a direct sum. we will need this later on.
Claim 115.
-
1.
For any two matrices there is a path of length between and .
-
2.
If then there is a path . Moreover, there exists such a path where the middle vertex such that the components of this sum have equal rank and satisfy and 181818Not all paths from to have this property. For instance, let be four independent vectors. Let , and . One can verify that because then is indeed a path. However, we can directly check that there are no such that ..
The second claim is a a variant of Claim 112. Claim 112 bounds -cycles in the Johnson complex provided that two non-neighbor vertices in the cycle are disjoint. This claim is the analog for :
Claim 116.
Let be a -cycle with the following properties.
-
1.
The matrices are a direct sum.
-
2.
We can decompose and such that and .191919We note that there is no analogue to second property of the cycle in the statement 112. The analogue is that (and similarly for ). This follows from the first property in the Johnson case but we require it explicitly in this case.
Then the cycle has a tiling with -triangles.
Both of these claims are proven after the lemma itself.
Proof of Lemma 114.
It is easy to see that the complex has a transitive action on the triangles. Therefore by Theorem 78, it suffices to find a cone whose area is to prove coboundary expansion.
Let be an arbitrary matrix we take as the root of our cone. We take arbitrary length paths from to every matrix . This is possible by Claim 115.
For every edge , we need to find a contraction for the cycle . We note that this cycle has length . Therefore it suffices to show that every cycle has a tiling with triangles. We begin by reducing the problem into tilings of cycles instead. Indeed, observe that for every edge in the cycle, . Therefore there exists some such that and are a direct sum with and respectively (In fact, a random matrix will satisfy this with high probability for all edges in the cycle because ).

By Claim 115 there exists a length two path from to every vertex in the cycle as in Figure 11(a). Therefore, by drawing these paths we can decompose our cycle into cycles of length of the form such that the row/column spaces of are a direct sum with and . This is a similar step as the one we do in Figure 9(a) in the Johnson case.
Fix a cycle as above let us denote by the matrix such that . Let be of equal rank such that . Denote by . We observe that and are all edges and therefore we can decompose this cycle into a -cycle and two -cycles that we need to tile (see Figure 11(b)).
The tiling of is simple. We decompose and into a direct sum of matrices of equal rank and . Then the matrix is connected in a triangle with all three edges. so we can triangulate this three cycle using three triangles.
As for the cycles , we tile them with the claim Claim 116 using -triangles. Thus we can triangulate every -cycle using of triangles. As every -cycle is decomposed into such -cycles we get a total of triangles, so the cone area is .
Proof of Claim 115.
First note that the first statement follows from the second, because for any there exists some such that and (this is because of the assumption that ). Thus we can take a -path from to and then another -path from to .
Let us thus show that assuming that there is a -path from to . Decompose of equal rank, and similarly for . Let and take the path . The claim follows.
Up until now, this was largely similar to Lemma 91. Surprisingly, the proof of Claim 116 is more complicated then its Johnson analogue Claim 112. This stems from the fact the matrix domination poset is different from the matrix Johnson Grassmann poset, and in particular there isn’t a perfect analogue to set intersection in the matrix poset (this is called a meet in poset theory).
Proof of Claim 116.
We will use the middle path pattern Claim 99. We observe that and , and we can view them as vertices in and respectively. We will use a similar strategy as in Claim 112, and use the fact that the graph has short paths between every two matrices. That is,
Claim 117.
For every and two matrices there is a path of length between and .
This claim is proven in the end of Section D.4.
Using this claim, we find a pair of -paths from to in and respectively: and . Then we observe that the matrices form a path from to in . Moreover, every edge in this path is in a triangle with and with . The claim is proven.
6.3.1 Coboundary expansion in the links and cosystolic expansion
In [50] it is proven that the Cayley complex whose link is is not a coboundary expander for any constant . It is done by proving that .
However, we can still prove that these complexes are cosystolic expanders. This notion is a weakening of coboundary expansion that allows the existence of cohomology, i.e. for :
Definition 118 (-dimensional cosystolic expander).
Let be a -dimensional simplicial complex for . Let . We say that is a -dimensional -cosystolic expander if for every group , and every there exists some such that
| (6.1) |
The difference between this definition and the definition of coboundary expansion, is that in the definition of coboundary expansion we require , or equivalently whereas here we only require which is less restrictive.
We note that cosystolic expansion is still an important property and can sometimes be used in applications such as topological overlapping property [43] or to get some form of agreement testing guarantee [27].
Kaufman, Kazhdan and Lubotzky were the first to prove that in local spectral expanders, cosystolic expansion follows from coboundary expansion of the links [60] (together with local spectral expansion). Later on their seminal result was extended to all groups and higher dimensions [44, 63, 64, 65, 28]. In particular, we can use the quantitatively stronger theorem in [28, Theorem 1.2], to get cosystolic expansion from Lemma 114 and the local spectral expansion.
Corollary 119.
Let for . Let be the basification of . Let be the complexes whose links are isomorphic to , as constructed in Section 3. Assume that is sufficiently large such that is a -local spectral expander. Then is also a -dimensional -cosystolic expander.
We omit the details.
7 Induced Grassmann posets
In this subsection we will present a generalization of our Johnson and Matrix Grassmann posets. After a few preliminaries, we will present a way to construct Grassmann posets based on the Hadamard encoding. We will see that such complexes have a simple description of their links. Afterwards, we will show that on some of these complexes we can decompose the links into a tensor product of simple graphs, generalizing some of the previous results in this paper. We start with some classical facts about quotient spaces and bilinear forms.
7.1 Preliminaries on quotient spaces and bilinear forms
Quotient spaces
Let be a subspace. The quotient space is a vector space whose vectors are the sets for every vector . It is standard that addition (and scalar multiplication) is well defined on these sets. Addition is defined as and the sum of the two sets does not depend on the representatives and .
Bilinear forms
Let be two vector spaces. A bilinear form is a function such that
for every and . A bilinear form is non-degenerate if for every there exists such that , and for every there exists such that .
When possible, we will work with the standard bilinear form given by instead of arbitrary bilinear forms. The next claim allows us to move to this standard bilinear form.
Claim 120.
Let be a non-degenerate bilinear form. Then and there exists isomorphisms such that .
From now on, we write instead of when it is clear from context; Claim 120 justifies the abuse of notation.
Proof sketch of Claim 120.
To see that , note that from non-degeneracy the function that sends is an injective linear function. Swapping and shows that the dimensions are equal.
We observe that for every basis of there exists a dual basis of such that . As for the isomorphisms, we fix some basis of and its dual basis . Let be the standard basis. It is easy to verify that the pair of isomorphisms that sends to , and that sends to satisfy .
For a fixed bilinear form and a subspace the orthogonal subspace is the subspace
and for a subspace , one can analogously define .
Definition 121 (Derived bilinear form).
Let be a non-degenerate bilinear form and let be a subspace. The derived bilinear form is a bilinear form given by
for any and .
It is easy to verify that is well defined. That is, it does not depend on the representative . It is also straightforward to verify that this derived bilinear form is non-degenerate.
Most of the time we will abuse notation and write instead of when is clear from the context.
7.2 The induced Grassmann poset - definition and running examples
In this subsection we construct a type of Grassmann posets called induced Grassmann posets. This construction generalizes the matrix Grassmann poset [50], its sparsified version in Definition 40 and the Johnson Grassmann poset in Definition 58.
Let be a function, not necessarily linear. The induced Hadamard encoding of is the linear map where
We note that the inner product between any and the vector is always . Thus we just need to define these functions over .
We call the induced Hadamard encoding, because if , we index the coordinates of by the non-zero vectors of , and set to be the function that sends to the standard basis vector that is on the -th coordinate and zero elsewhere. Then is the (usual) Hadamard encoding and its image is the Hadamard code.
Definition 122 (Induced Grassmann poset).
Let be two integers such that . Let be a set of (non-linear) functions such that every is injective and the set is independent. The -induced Grassmann poset is the -dimensional Grassmann poset such that .
To be explicit, for , an -dimensional subspace is in if there exists some containing . Equivalently, this is if and only if there exist a and a subspace such that . For this says that if and only if for some and non-zero .
We note that if the vectors in the image of are independent, then . We also note that different may still result in the same spaces .
Although this definition seems abstract, hopefully, the following examples, which were already introduced in the previous sections, will convince the reader that this definition is natural.
Example 123 (The complete Grassmann).
Let and be positive integers. Let be all injective functions whose image is independent. Then is the -skeleton of the complete Grassmann of . To see this let us show that every -dimensional subspace has some such that . Let be an arbitrary function and let . Find some that maps to and set . It is easy to verify that indeed and that .
Example 124 (Johnson Grassmann poset).
Let and be positive integers. Let be the standard basis for . Let be the set of injective functions from to . For this , the poset is the Johnson Grassmann poset.
First note that a vector from is in if and only if its Hamming weight is : every such vector is equal to for some and . The ’s are distinct standard basis vectors, and there are exactly non-zero in the sum. Therefore the weight of is .
The -dimensional subspaces are the Hadamard encoding on coordinates inside . Let us be more precise. Fix a map and for simplicity assume that . Let . By indexing with the coordinates of , then , which is the Hadamard encoding of .
The basification of this poset is an alternative description of the links of Johnson complexes.
Example 125 (Matrix poset [50]).
Let and . Recall that is the set of all rank one matrices over . Let be the set of functions such that the matrix is a direct sum, or in other words . One can see directly that such ’s are the admissible functions of Definition 39 for the special case where the ambient poset is complete Grassmann . In this case, .202020There is a slight technical difference between this complex and the one in [50], that follows from Golowich’s use of larger fields. See [50] for more details.
To draw the analogy to the Johnson, let us illustrate that indeed a matrix is a -dimensional subspace in the -induced Grassmann poset if and only if . This follows the same logic as in the Johnson case. If then for some and . This means that is the sum of distinct ’s. As the matrix is a direct sum, the sum of the ’s is also a direct sum. This implies that . On the other hand, suppose has rank and decomposition . Take an arbitrary and let . As also has size , we can find some that maps the elements in to the in the decomposition of . For such an , we have , thus concluding .
The construction in [50] used matrices over a larger field of characteristic instead of itself. See [50] for the details.
The next example is the one given in Definition 40.
Example 126 (Sparsified matrix poset).
Let and let be any -dimensional Grassmann poset over . We define a sparsification .
where . The one dimensional spaces are -rank matrices such that . The top-level spaces are , such that the sum of row spaces (resp. column spaces) is in .
Finally, we end this subsection with the comment that if one has a distribution over , this also defines a distribution over in a natural way. That is, sampling and then outputting . Unless otherwise stated, we will always take the uniform distribution over .
7.2.1 Subspaces of an induced Grassmann poset
Fix . The subspaces are defined by downward closure, but we can give an alternative description of via an induced Grassmann poset with some that is derived from . We begin by looking at our examples for intuition and then generalize.
In the examples above, the lower dimensional subspaces have some structure to them. For instance, one can verify that the -dimensional subspaces in the Johnson Grassmann poset could be described as images of Hadamard encodings where the image of consists of vectors of Hamming weight such that the supports of every pair and are disjoint. This generalizes the case where , and the image of are distinct vectors of weight .
In a similar manner, we saw in Claim 41 that -dimensional subspaces of the Matrix Grassmann poset are images of induced Hadamard encodings
where every has rank and has rank . Again, this is a natural generalization of the case where .
Back to the more general setup. Recall that every is the image of for some . The map is always injective, therefore every -dimensional subspace is also the image of some -dimensional subspace .
Let be the -dimensional space such that , that is, . Let be . We use the bilinear form to define the function as the induced Hadamard encoding, i.e.
Here we recall that for (and we recall that this is independent of the choice of representative ).
Let
We will show that for every , and hence induces .
Claim 127.
For every subspace , , function , and , . As a result, .
Here there is some abuse of notation since the domain of is not , but some arbitrary -dimensional space . However, this does not matter since we are taking the image space of .
Before proving this claim, let us review our previous examples in light of this.
Example 128 (Johnson Grassmann poset).
For the Johnson Grassmann poset, fix a -dimensional subspace . Then a function if and only if every value has Hamming weight and for every the supports of and are mutually disjoint.
By Claim 120 we replace the functions in , with similar functions whose domain is , without changing the resulting poset. Thus another set of functions such that the induced Grassmann on is also equal to is the set of all functions such that the Hamming weight of every is , and such that if then the supports of and are disjoint. These are exactly the admissible functions in Definition 69.
Example 129 (Matrix poset and sparsified matrix poset).
For the matrix example above let us fix some and -dimensional subspace . The matrix is a direct sum of rank matrices. Thus . The matrices have the property that their sum is a direct sum, or equivalently that .222222Note that this is not the matrix in Example 125, since the matrices do not participate in this sum when .
We remark that the sparsified matrix induced Grassmann poset also admit a similar description of the -spaces which was explained in Section 3.
Proof of Claim 127.
Fix and an dimensional subspace . Let be some -dimensional subspace in . Let . Note that while , we can remove all elements from the sum since is orthogonal to them. We also recall that for every , so
Thus in particular for every , . As is injective, every subspace is the image of some -dimensional subspace . The claim follows.
7.3 A decomposition for the links
Our goal is to prove that links of some induced Grassmann posets decompose into tensor products of simple graphs, reproving and extending both Proposition 51 for the matrix Grassmann poset, Lemma 46 for the sparsified matrix poset, and Proposition 62 for the Johnson Grassmann poset.
For this we need to zoom in to a less general class of induced Grassmann posets, which we call rank-based induced Grassmann posets with the direct-meet property. Let us define these.
7.3.1 Rank-based posets
Let be a spanning set that does not contain . The rank of a vector with respect to , , is the minimum number of elements in necessary to write as their sum.
Definition 130 (-admissible spanning set).
We say is -admissible if for every with there exists some such that .
Example 131.
-
1.
For example in Johnson Grassmann posets, take to be the standard basis. Then is just its Hamming weight. This set is -admissible.
-
2.
For matrix Grassmann posets, taking to be the set of rank one matrices inside , then is its usual matrix rank. This set is also -admissible. This second example can be extended to being the rank one -tensors for in as well.
The following notation of a direct sum generalizes the matrix poset direct sum.
Definition 132 (Abstract direct sum).
We say that is a direct sum and write , if . We also write if .
For we have if and only if they are disjoint (as sets) and if and only if . For the definitions of and coincide with the direct sum and matrix domination order defined in Section 2.4. It is easy to show that for any the relation is always a partial order.
Definition 133 (Rank -admissible functions).
Let be an integer. Let be a -admissible set. A rank admissible function is such that every has , and such that is a direct sum. The rank admissible set of functions is the set containing all rank admissible functions.
We comment that this set indeed gives rise to an induced Grassmann poset, because if the sum of the vectors in is a direct sum, then this set is independent. The reason is that if there is a nonempty subset such that , then
which shows that in such a case the sum was not a direct sum in the first place.
For the rest of this section we will always assume there is some ambient -admissible set , and that with respect to this set.
Definition 134 (Rank-based induced Grassmann poset).
If is the rank admissible set with respect to some , then is called a rank-based induced Grassmann poset.
Example 135.
Both the Johnson Grassmann poset and the matrix Grassmann posets are rank-based induced Grassmann posets for and respectively.
Example 136 (Non example).
The -skeleton of the complete Grassmann is not a rank-based induced Grassmann for any . To see this we observe that in a rank-based induced Grassmann poset , every has . This is because is always a direct sum of vectors of rank . However, in the complete Grassmann contains all non-zero vectors, including the vectors in which have rank one.
7.3.2 The direct-meet property
Unfortunately, this is still too general for a meaningful decomposition lemma. For this we also need to define another property of which we will call the direct-meet property.
Definition 137 (Meet).
The Meet of a set of elements is an element such that
-
1.
For every , (in the abstract direct sum sense).
-
2.
For every , if for every , then .
This is a standard definition in poset theory. We note that does not necessarily exist, but if it exists it is always unique.
Definition 138 (Direct-meet property).
We say that has the direct-meet property if for every three elements, such that , the meet of exists and is equal to .
We say has the direct-meet property if it is a rank-based induced complex, where the generating set has the direct-meet property.
We note that this definition is not satisfied by all spanning sets .
Example 139 (Non example).
Let where are the standard basis. Then does not have the direct-meet property. To see this let . The triple is a direct sum. However, and , but . Hence is not the meet of and .
However, both the Johnson and the matrix sets have this property.
Example 140.
For the set which defines , the direct-meet property holds. Indeed, the meet of any set is the intersection , where we treat the vectors as sets. In particular, the meet of and is .
Example 141.
A more interesting example is the low-rank decomposition case. Let be the set of rank matrices which defines . Contrary to the Johnson case, there exists a set with no meet. For example let be independent, let and let . Both and are under and in the matrix domination order. However, and and therefore there is no meet for . Nevertheless, the rank matrices have the direct-meet property.
Claim 142.
The set has the direct-meet property.
This claim essentially abstracts the observation in [50, Lemma 57]. We prove it in Section C.3.
Finally we state an elementary claim about the meet which we will use later on, extending the property from three elements to any finite number of elements.
Claim 143.
Let be a set with the direct-meet property. Let be such that (with respect to ). Let be linear combinations of , i.e. for some subsets . Then
The proof is just an induction on the size of . We omit it.
7.3.3 The general decomposition lemma
We move towards our decomposition lemma for links of a rank-based with the direct-meet property. Our components for the decomposition lemma are the following.
Definition 144 (-domination graph).
Let be of rank . The graph has vertices
To sample an edge we sample a uniformly random decomposition , such that and output such that . The set of edges is the support of the the above distribution.
For , this graph coincides with the subposet graphs introduced in Definition 43. For the Johnson Grassmann poset, this graph turns out to be the Johnson graph . This is because every vector in the graph has weight and is contained in a of weight . Having and in this definition is equivalent to and intersecting on half their coordinates.
We continue with our second component.
Definition 145 (-link graph).
Let be a vector whose rank is and let . The graph has vertices
We define the (weighted) edges according to the following sampling process. To sample an edge we sample a random such that . Then we uniformly sample such that and output a random edge in .
For , this graph coincides with the disjoint graph introduced in Definition 44. For the Johnson Grassmann poset, this graph is also a Johnson graph, . This is because every vector in the graph has weight whose support is disjoint from . The sampling process in this graph amounts to uniformly sampling a -weighted set that is disjoint from , and then taking a step inside its . This is the same as sampling (uniformly) two subsets disjoint from that intersect on half their coordinates.
The final component we need to state the decomposition lemma is this following claim.
Claim 146.
Let be a rank-based induced poset with the direct-meet property. Then for every , and such that , it holds that .
We will hence denote by the image set of a given . We also denote by the direct sum.
This claim is a consequence of the direct-meet property. We prove it later and for now, let us proceed to the decomposition lemma.
Lemma 147 (The decomposition lemma).
Let with and as above. Then .
We observe that this lemma applied to implies Proposition 62. Applied to this lemma proves Proposition 51. We can even generalize this lemma slightly more to capture the sparsified matrix case in Lemma 46. See Section 7.4 for details.
In order to prove Lemma 147, we need to define the isomorphism. To do so, we give a combinatorial criterion for a vector being in in terms of its meets with the elements in .
Claim 148.
Let with as above. Let . Then is in the link of if and only if there exists unique with the following properties:
-
1.
(that is, is equal to the sum of all ’s and this sum is direct).
-
2.
All ’s have equal rank.
-
3.
.
In this case the subspace , has .
Note that items and imply that the rank of is half the rank of .
Given Claim 148, we can define the isomorphism by
| (7.1) |
where the image consists of the unique ’s promised by the claim. This function is also a bijection by Claim 148.
To conclude the proof, we need to argue that an edge is sampled by sampling the different components independently from one another. For this part, we basically need the following independence claim for the distribution we used when sampling . Let be the random variable obtained by sampling a function from . For a set , let be the random variable obtained by restricting the function only to the vectors of . Let . Then and are independent, if we condition on the event .
Claim 149.
Let be a rank-based poset. Let be a partition. Let be such that and .
Consider the joint random variables . Then conditioned on the event that for every
these random variables are independent.
We prove the lemma first, then go back to show the sub-claims.
Proof of Lemma 147.
Let us denote by . We define a map mapping as in (7.1). That is, the ’s are as in Claim 148. By Claim 148, this map is well defined for every and sends link vertices into the vertices of . Moreover, by Claim 148 this is also a bijection, since the map
is indeed onto according to the claim.
Next we prove that a pair is an edge in if and only if is an edge in (ignoring any edge weights for now). Recall that is an edge in if and only if where . By Claim 148, . Let us re-index ’s with
for . Moreover, by applying Claim 148 to we have that if and only if:
-
1.
We can decompose such that the rank of every summand is equal.
-
2.
For every , .
-
3.
The final is a direct sum with (the sum of all elements in ).
So on the one hand, if are neighbors in the tensor product , we can take and which will satisfy the above property (and is well defined by the properties of and the direct-meet property). This shows that being an edge in implies being an edge in .
For the reverse direction, suppose there exists such a decomposition of . Then for every the vectors and have that and . In addition they have equal rank and their direct sum is equal to . Thus is an edge in . For the final component, a similar argument applies: We decompose , and . All three vectors have rank and have a direct sum. Furthermore, and . As a result is an edge in . Thus is an edge in .
Finally, we note that we can sample by sampling every pair independently. Indeed, when sampling an edge in the link of , we are conditioning on sampling some so that for a fixed -dimensional subspace , the image of is fixed. For every , there exists some such that depend only on the values of (this is the such that ). For the final component , this edge only depends on restricted to . By Claim 149, the values of on the respective parts in each coset are independent once all values of have been fixed. We conclude that indeed is an isomorphism.
Proof of Claim 146.
We will prove something even stronger. With the notation in the claim, we show that there exists some such that 232323Note that a priori and could have different domains, so technically is an isomorphism between the domain of and that of .. Let be such that and such that without loss of generality the domain of and is . Observe that by Claim 143, , since the subset on the left consists of direct sums of a bunch of , and is the only common component in these sums of .
Now assume that . This implies that there is an isomorphism such that . On the other hand, by the above
Set and we got . We note that the above proof used the intersection patterns of the Hadamard code.
Proof of Claim 148.
Let and be such that and let be such that . Write such that and . We recall that every can be partitioned into two cosets of , and therefore . By the fact that this sum is also direct.
We first prove the only if direction. Let be such that . By Claim 127, it also holds that . By the fact that , the inner product and therefore, . This implies that for every , exactly one of satisfies . Indeed:
Assume that and thus (the other case is similar). In this case, because this whole sum is a direct sum every non-zero component in the sum is dominated by . In particular . Moreover, any component that does not appear in this sum is a direct sum with , and in particular .
Thus we re-index (arbitrarily) and set to be the component where and . We also set and note that also participates in the linear combination of because . All ’s have rank and by the discussion above, we have that . Moreover, for every and is a direct sum with the sum of ’s. Thus, by construction. Finally, we note that the when the admissible functions come from a rank-based construction that has the direct-meet property, then for some . Thus, the ’s are unique.
Conversely, let us assume that the three items hold and prove that . Let be such that . Recall that consists of all functions whose image contains vectors of rank whose sum is a direct sum. Therefore, let us construct such a function satisfying . First, we re-index the elements as ’s for every (but keep the notation as before) so that . For an input ,
It is easy to see that the image of is , and these vectors form a direct sum and they all have rank . Thus we successfully construct a . Moreover, one readily verifies that and that for we have that . Thus .
Proof of Claim 149.
It suffices to prove that is independent of where denotes the rest of the random variables. For any , the distribution for is uniform over all partial functions satisfying (1) , and (2) . This follows from the fact that for any fixed conditioning of the form where the image of sum up to for all , all such functions have equal probability density.
For , a similar argument applies. Conditioned on (where the sum of each ’s values equals ), the last partial function is sampled by picking a uniformly random (ordered) set of rank elements satisfying that . It is obvious that the distribution of is independent of the specific functions assigned to .
7.4 The distribution over admissible functions
We can extend the decomposition lemma above to a slightly more general setup. In this setup we sample according to a specified distribution instead of sampling it uniformly. Let be a set of admissible functions. Let be a probability density function of . We say that is permutation invariant if for every and every permutation of , . Such a induces the following measure over the -dimensional subspaces in the rank-based induced poset: first sample , and then outputs . We call posets obtained by this process measured rank-based posets.
The sparsified matrix poset is an example of a measured rank-based posets, where the distribution of admissible functions is given by the following:
-
1.
Sample independently.
-
2.
Sample uniformly at random such that and .
For general , this distribution is nonuniform, and the resulting poset is a measured rank-based poset. Hence this more generalized definition captures the sparsified matrix poset in Definition 40.
For such posets we can prove a version of the decomposition lemma using the following variants of the graphs from Definition 145.
Definition 150 (-link graph).
Let be of rank and let . The graph has vertices
The edge distribution is given by: first sample a random vector conditioned on . Then uniformly sample a of rank and finally output an edge in according to the distribution in that graph.
Lemma 151.
Let be a measured rank-based poset with the direct-meet property. Then for every with and defined as before,
The proof of this lemma follows the exact same argument in the proof of the decomposition lemma Lemma 147. Therefore we omit the proof for brevity.
References
- [1] Vedat Alev, Fernando Jeronimo, and Madhur Tulsiani. Approximating constraint satisfaction problems on high-dimensional expanders. In Proc. 59th IEEE Symp. on Foundations of Computer Science, pages 180–201, November 2019. doi:10.1109/FOCS.2019.00021.
- [2] Noga Alon, Oded Goldreich, Johan Håstad, and René Peralta. Simple constructions of almost k-wise independent random variables. Random Structures & Algorithms, 3(3):289–304, 1992. doi:10.1002/RSA.3240030308.
- [3] Noga Alon and Yuval Roichman. Random cayley graphs and expanders. Random Structures & Algorithms, 5(2):271–284, 1994. doi:10.1002/RSA.3240050203.
- [4] Nima Anari, Vishesh Jain, Frederic Koehler, Huy Tuan Pham, and Thuy-Duong Vuong. Entropic independence i: Modified log-sobolev inequalities for fractionally log-concave distributions and high-temperature ising models. arXiv preprint, 2021. arXiv:2106.04105.
- [5] Nima Anari, Kuikui Liu, Shayan Oveis Gharan, and Cynthia Vinzant. Log-concave polynomials ii: high-dimensional walks and an fpras for counting bases of a matroid. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pages 1–12, 2019. doi:10.1145/3313276.3316385.
- [6] Anurag Anshu, Nikolas P Breuckmann, and Chinmay Nirkhe. Nlts hamiltonians from good quantum codes. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, pages 1090–1096, 2023. doi:10.1145/3564246.3585114.
- [7] Sanjeev Arora and Madhu Sudan. Improved low degree testing and its applications. In Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing, pages 485–495, El Paso, Texas, 1997. doi:10.1145/258533.258642.
- [8] Mitali Bafna, Max Hopkins, Tali Kaufman, and Shachar Lovett. Hypercontractivity on high dimensional expanders. In Proceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing, pages 185–194, 2022. doi:10.1145/3519935.3520040.
- [9] Mitali Bafna, Noam Lifshitz, and Dor Minzer. Constant degree direct product testers with small soundness, 2024. arXiv:2402.00850.
- [10] Mitali Bafna and Dor Minzer. Characterizing direct product testing via coboundary expansion. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 1978–1989, 2024. doi:10.1145/3618260.3649714.
- [11] Mitali Bafna, Dor Minzer, and Nikhil Vyas. Quasi-linear size pcps with small soundness from hdx. arXiv preprint, 2024. doi:10.48550/arXiv.2407.12762.
- [12] Cristina M Ballantine. Ramanujan type buildings. Canadian Journal of Mathematics, 52(6):1121–1148, 2000.
- [13] Imre Bárány. A generalization of carathéodory’s theorem. Discrete Mathematics, 40(2-3):141–152, 1982. doi:10.1016/0012-365X(82)90115-7.
- [14] Yonatan Bilu and Nathan Linial. Constructing expander graphs by 2-lifts and discrepancy vs. spectral gap. In 45th Annual IEEE Symposium on Foundations of Computer Science, pages 404–412. IEEE, 2004. doi:10.1109/FOCS.2004.19.
- [15] Endre Boros and Zoltán Füredi. The number of triangles covering the center of an n-set. Geometriae Dedicata, 17:69–77, 1984.
- [16] Donald I Cartwright, Patrick Solé, and Andrzej Żuk. Ramanujan geometries of type an. Discrete mathematics, 269(1-3):35–43, 2003.
- [17] Michael Chapman, Nathan Linial, and Peled Yuval. Expander graphs — both local and global. Combinatorica, 40:473–509, 2020. doi:10.1007/s00493-019-4127-8.
- [18] Michael Chapman and Alexander Lubotzky. Stability of homomorphisms, coverings and cocycles i: Equivalence, 2023. arXiv:2310.17474.
- [19] Michael Chapman and Alexander Lubotzky. Stability of homomorphisms, coverings and cocycles ii: Examples, applications and open problems, 2023. arXiv:2311.06706.
- [20] Zongchen Chen, Andreas Galanis, Daniel Štefankovič, and Eric Vigoda. Rapid mixing for colorings via spectral independence. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1548–1557. SIAM, 2021.
- [21] Fan Chung and Paul Horn. The spectral gap of a random subgraph of a graph. Internet Mathematics, 4(2-3):225–244, 2007. doi:10.1080/15427951.2007.10129296.
- [22] David Conlon. Hypergraph expanders from cayley graphs. Israel Journal of Mathematics, 233(1):49–65, 2019.
- [23] David Conlon, Jonathan Tidor, and Yufei Zhao. Hypergraph expanders of all uniformities from cayley graphs. Proceedings of the London Mathematical Society, 121(5):1311–1336, 2020.
- [24] Philippe Delsarte and Vladimir I. Levenshtein. Association schemes and coding theory. IEEE Transactions on Information Theory, 44(6):2477–2504, 1998. doi:10.1109/18.720545.
- [25] Yotam Dikstein. New high dimensional expanders from covers. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, pages 826–838, 2023. doi:10.1145/3564246.3585183.
- [26] Yotam Dikstein and Irit Dinur. Agreement testing theorems on layered set systems. In Proceedings of the 60th Annual IEEE Symposium on Foundations of Computer Science, 2019.
- [27] Yotam Dikstein and Irit Dinur. Agreement theorems for high dimensional expanders in the small soundness regime: the role of covers. CoRR, abs/2308.09582, 2023. doi:10.48550/arXiv.2308.09582.
- [28] Yotam Dikstein and Irit Dinur. Coboundary and cosystolic expansion without dependence on dimension or degree. CoRR, abs/2304.01608, 2023. doi:10.48550/arXiv.2304.01608.
- [29] Yotam Dikstein and Irit Dinur. Swap cosystolic expansion. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 1956–1966, 2024. doi:10.1145/3618260.3649780.
- [30] Yotam Dikstein, Irit Dinur, Yuval Filmus, and Prahladh Harsha. Boolean functions on high-dimensional expanders. arXiv preprint arXiv:1804.08155, 2018. arXiv:1804.08155.
- [31] Yotam Dikstein, Irit Dinur, and Alexander Lubotzky. Low acceptance agreement tests via bounded-degree symplectic hdxs, 2024. URL: https://eccc.weizmann.ac.il/report/2024/019/.
- [32] Yotam Dikstein and Max Hopkins. Chernoff bounds and reverse hypercontractivity on hdx. arXiv preprint arXiv:2404.10961, 2024. doi:10.48550/arXiv.2404.10961.
- [33] Irit Dinur. The pcp theorem by gap amplification. Journal of the ACM (JACM), 54(3):12–es, 2007.
- [34] Irit Dinur, Shai Evra, Ron Livne, Alexander Lubotzky, and Shahar Mozes. Good locally testable codes. arXiv preprint arXiv:2207.11929, 2022. doi:10.48550/arXiv.2207.11929.
- [35] Irit Dinur, Yuval Filmus, Prahladh Harsha, and Madhur Tulsiani. Explicit sos lower bounds from high-dimensional expanders. In 12th Innovations in Theoretical Computer Science (ITCS 2021), 2021. arXiv:2009.05218.
- [36] Irit Dinur and Elazar Goldenberg. Locally testing direct products in the low error range. In Proc. 49th IEEE Symp. on Foundations of Computer Science, 2008.
- [37] Irit Dinur, Prahladh Harsha, Tali Kaufman, Inbal Livni Navon, and Amnon Ta-Shma. List-decoding with double samplers. SIAM journal on computing, 50(2):301–349, 2021. doi:10.1137/19M1276650.
- [38] Irit Dinur and Tali Kaufman. High dimensional expanders imply agreement expanders. In 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS), pages 974–985. IEEE, 2017. doi:10.1109/FOCS.2017.94.
- [39] Irit Dinur, Siqi Liu, and Rachel Yun Zhang. New codes on high dimensional expanders. arXiv preprint arXiv:2308.15563, 2023. doi:10.48550/arXiv.2308.15563.
- [40] Irit Dinur and Inbal Livni Navon. Exponentially small soundness for the direct product z-test. In 32nd Computational Complexity Conference, CCC 2017, July 6-9, 2017, Riga, Latvia, pages 29:1–29:50, 2017. doi:10.4230/LIPICS.CCC.2017.29.
- [41] Irit Dinur and Roy Meshulam. Near coverings and cosystolic expansion. Archiv der Mathematik, 118(5):549–561, May 2022. doi:10.1007/s00013-022-01720-6.
- [42] Dominic Dotterrer and Matthew Kahle. Coboundary expanders. Journal of Topology and Analysis, 4(04):499–514, 2012.
- [43] Dominic Dotterrer, Tali Kaufman, and Uli Wagner. On expansion and topological overlap. Geometriae Dedicata, 195:307–317, 2018.
- [44] Shai Evra and Tali Kaufman. Bounded degree cosystolic expanders of every dimension. In Proceedings of the forty-eighth annual ACM symposium on Theory of Computing, pages 36–48, 2016. doi:10.1145/2897518.2897543.
- [45] Ofer Gabber and Zvi Galil. Explicit constructions of linear-sized superconcentrators. Journal of Computer and System Sciences, 22(3):407–420, 1981. doi:10.1016/0022-0000(81)90040-4.
- [46] Jason Gaitonde, Max Hopkins, Tali Kaufman, Shachar Lovett, and Ruizhe Zhang. Eigenstripping, spectral decay, and edge-expansion on posets. arXiv preprint arXiv:2205.00644, 2022. doi:10.48550/arXiv.2205.00644.
- [47] Howard Garland. -adic curvature and the cohomology of discrete subgroups of -adic groups. Ann. of Math., 97(3):375–423, 1973. doi:10.2307/1970829.
- [48] Oded Goldreich and Shmuel Safra. A combinatorial consistency lemma with application to proving the PCP theorem. In RANDOM: International Workshop on Randomization and Approximation Techniques in Computer Science. LNCS, 1997.
- [49] Louis Golowich. Improved Product-Based High-Dimensional Expanders. In Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM 2021), volume 207, 2021. doi:10.4230/LIPIcs.APPROX/RANDOM.2021.38.
- [50] Louis Golowich. From grassmannian to simplicial high-dimensional expanders. arXiv preprint arXiv:2305.02512, 2023. doi:10.48550/arXiv.2305.02512.
- [51] Roy Gotlib and Tali Kaufman. List agreement expansion from coboundary expansion, 2022. arXiv:2210.15714.
- [52] M. Gromov. Singularities, expanders and topology of maps. part 2: from combinatorics to topology via algebraic isoperimetry. Geom. Funct. Anal., 20:416–526, 2010. doi:10.1007/s00039-010-0073-8.
- [53] Anna Gundert and Uli Wagner. On eigenvalues of random complexes. Israel Journal of Mathematics, 216:545–582, 2016.
- [54] Tom Gur, Noam Lifshitz, and Siqi Liu. Hypercontractivity on high dimensional expanders. In Proceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing, pages 176–184, 2022. doi:10.1145/3519935.3520004.
- [55] Christopher Hoffman, Matthew Kahle, and Elliot Paquette. The threshold for integer homology in random d-complexes. Discrete & Computational Geometry, 57:810–823, 2017. doi:10.1007/S00454-017-9863-1.
- [56] Shlomo Hoory, Nathan Linial, and Avi Wigderson. Expander graphs and their applications. Bulletin of the American Mathematical Society, 43(4):439–561, 2006.
- [57] Max Hopkins and Ting-Chun Lin. Explicit lower bounds against -rounds of sum-of-squares. arXiv preprint arXiv:2204.11469, 2022. doi:10.48550/arXiv.2204.11469.
- [58] Russell Impagliazzo, Valentine Kabanets, and Avi Wigderson. New direct-product testers and 2-query PCPs. SIAM J. Comput., 41(6):1722–1768, 2012. doi:10.1137/09077299X.
- [59] Fernando Granha Jeronimo, Shashank Srivastava, and Madhur Tulsiani. Near-linear time decoding of ta-shma’s codes via splittable regularity. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 1527–1536, 2021. doi:10.1145/3406325.3451126.
- [60] Tali Kaufman, David Kazhdan, and Alexander Lubotzky. Isoperimetric inequalities for ramanujan complexes and topological expanders. Geometric and Functional Analysis, 26(1):250–287, 2016.
- [61] Tali Kaufman and Alexander Lubotzky. High dimensional expanders and property testing. In Innovations in Theoretical Computer Science, ITCS’14, Princeton, NJ, USA, January 12-14, 2014, pages 501–506, 2014. doi:10.1145/2554797.2554842.
- [62] Tali Kaufman and David Mass. High dimensional random walks and colorful expansion. In 8th Innovations in Theoretical Computer Science Conference (ITCS 2017). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2017.
- [63] Tali Kaufman and David Mass. Good distance lattices from high dimensional expanders. (manuscript), 2018. arXiv:1803.02849.
- [64] Tali Kaufman and David Mass. Unique-neighbor-like expansion and group-independent cosystolic expansion. In 32nd International Symposium on Algorithms and Computation (ISAAC 2021). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2021.
- [65] Tali Kaufman and David Mass. Double balanced sets in high dimensional expanders. arXiv preprint arXiv:2211.09485, 2022. doi:10.48550/arXiv.2211.09485.
- [66] Tali Kaufman and Izhar Oppenheim. Construction of new local spectral high dimensional expanders. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, pages 773–786, 2018. doi:10.1145/3188745.3188782.
- [67] Tali Kaufman and Izhar Oppenheim. High order random walks: Beyond spectral gap. Combinatorica, 40:245–281, 2020. doi:10.1007/S00493-019-3847-0.
- [68] Tali Kaufman and Izhar Oppenheim. Coboundary and cosystolic expansion from strong symmetry. In 48th International Colloquium on Automata, Languages, and Programming, ICALP 2021, July 12-16, 2021, Glasgow, Scotland (Virtual Conference), volume 198 of LIPIcs, pages 84:1–84:16. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2021. doi:10.4230/LIPIcs.ICALP.2021.84.
- [69] Tali Kaufman and Ran J Tessler. Garland’s technique for posets and high dimensional grassmannian expanders. arXiv preprint, 2021. arXiv:2101.12621.
- [70] Mikhail Koshelev. Spectrum of johnson graphs. Discrete Mathematics, 346(3):113262, 2023. doi:10.1016/J.DISC.2022.113262.
- [71] Dmitry N Kozlov and Roy Meshulam. Quantitative aspects of acyclicity. Research in the Mathematical Sciences, 6(4):1–32, 2019.
- [72] Wen-Ching Winnie Li. Ramanujan hypergraphs. Geometric & Functional Analysis GAFA, 14:380–399, 2004.
- [73] Nathan Linial and Roy Meshulam. Homological connectivity of random 2-complexes. Combinatorica, 26(4):475–487, 2006. doi:10.1007/S00493-006-0027-9.
- [74] Siqi Liu, Sidhanth Mohanty, Tselil Schramm, and Elizabeth Yang. Local and global expansion in random geometric graphs. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, STOC 2023, pages 817–825, New York, NY, USA, 2023. Association for Computing Machinery. doi:10.1145/3564246.3585106.
- [75] Siqi Liu, Sidhanth Mohanty, and Elizabeth Yang. High-dimensional expanders from expanders. In 11th Innovations in Theoretical Computer Science Conference (ITCS 2020), volume 151, page 12. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2020.
- [76] Alexander Lubotzky. Expander graphs in pure and applied mathematics. Bulletin of the American Mathematical Society, 49(1):113–162, 2012.
- [77] Alexander Lubotzky, Roy Meshulam, and Shahar Mozes. Expansion of building-like complexes. Groups, Geometry, and Dynamics, 10(1):155–175, 2016.
- [78] Alexander Lubotzky, Ralph Phillips, and Peter Sarnak. Ramanujan graphs. Combinatorica, 8(3):261–277, 1988. doi:10.1007/BF02126799.
- [79] Alexander Lubotzky, Beth Samuels, and Uzi Vishne. Explicit constructions of ramanujan complexes of type ad. European Journal of Combinatorics, 26(6):965–993, 2005. doi:10.1016/J.EJC.2004.06.007.
- [80] Roger C Lyndon, Paul E Schupp, RC Lyndon, and PE Schupp. Combinatorial group theory, volume 89. Springer, 1977.
- [81] Neal Madras and Dana Randall. Markov chain decomposition for convergence rate analysis. Annals of Applied Probability, pages 581–606, 2002.
- [82] Adam W. Marcus, Daniel A. Spielman, and Nikhil Srivastava. Interlacing families i: Bipartite ramanujan graphs of all degrees. Annals of Mathematics, 182:307–325, 2015. doi:10.4007/annals.2015.182.1.7.
- [83] Adam W Marcus, Daniel A Spielman, and Nikhil Srivastava. Interlacing families ii: Mixed characteristic polynomials and the Kadison-Singer problem. Annals of Mathematics, pages 327–350, 2015.
- [84] Grigorii Aleksandrovich Margulis. Explicit constructions of concentrators. Problemy Peredachi Informatsii, 9(4):71–80, 1973.
- [85] Roy Meshulam and Nathan Wallach. Homological connectivity of random k-dimensional complexes. Random Structures & Algorithms, 34(3):408–417, 2009. doi:10.1002/RSA.20238.
- [86] Ryan O’Donnell and Kevin Pratt. High-dimensional expanders from chevalley groups. In Shachar Lovett, editor, 37th Computational Complexity Conference, CCC 2022, July 20-23, 2022, Philadelphia, PA, USA, volume 234 of LIPIcs, pages 18:1–18:26. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2022. doi:10.4230/LIPIcs.CCC.2022.18.
- [87] Izhar Oppenheim. Local spectral expansion approach to high dimensional expanders part i: Descent of spectral gaps. Discrete & Computational Geometry, 59(2):293–330, 2018. doi:10.1007/S00454-017-9948-X.
- [88] Pavel Panteleev and Gleb Kalachev. Asymptotically good quantum and locally testable classical LDPC codes. In Stefano Leonardi and Anupam Gupta, editors, STOC ’22: 54th Annual ACM SIGACT Symposium on Theory of Computing, Rome, Italy, June 20 - 24, 2022, pages 375–388. ACM, 2022. doi:10.1145/3519935.3520017.
- [89] Mark S Pinsker. On the complexity of a concentrator. In 7th International Telegraffic Conference, volume 4, pages 1–318, 1973.
- [90] Ran Raz. A parallel repetition theorem. SIAM Journal on Computing, 27(3):763–803, June 1998. doi:10.1137/S0097539795280895.
- [91] Ran Raz and Shmuel Safra. A sub-constant error-probability low-degree test, and a sub-constant error-probability pcp characterization of np. In Proceedings of the Twenty-ninth Annual ACM Symposium on Theory of Computing, STOC ’97, pages 475–484, New York, NY, USA, 1997. ACM. doi:10.1145/258533.258641.
- [92] Omer Reingold. Undirected connectivity in log-space. J. ACM, 55(4), 2008. doi:10.1145/1391289.1391291.
- [93] Omer Reingold, Salil Vadhan, and Avi Wigderson. Entropy waves, the zig-zag graph product, and new constant-degree expanders and extractors. In Proceedings 41st Annual Symposium on Foundations of Computer Science, pages 3–13. IEEE, 2000. doi:10.1109/SFCS.2000.892006.
- [94] Ronitt Rubinfeld and Madhu Sudan. Robust characterizations of polynomials with applications to program testing. SIAM J. Comput., 25(2):252–271, 1996. doi:10.1137/S0097539793255151.
- [95] David Surowski. Covers of simplicial complexes and applications to geometry. Geometriae Dedicata, 16:35–62, April 1984. doi:10.1007/BF00147420.
- [96] Amnon Ta-Shma. Explicit, almost optimal, epsilon-balanced codes. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, pages 238–251, 2017. doi:10.1145/3055399.3055408.
- [97] Egbert R Van Kampen. On some lemmas in the theory of groups. American Journal of Mathematics, 55(1):268–273, 1933.
Appendix A The decomposition lemma
Proof of Lemma 15.
Let us denote by the adjacency operators of respectively. We also denote by the bipartite adjacency operator of . That is, for a function , is the function . We note that by assumption, for every such that , .
Let be an eigenvector of of norm and denote its eigenvalue by . Then
where is the restriction of to the vertices of . Let us denote such that is a constant and . Then by expansion,
Here first equality is algebra, the second is because and the last equality is due to the fact that has norm . Finally, we note that the constant . That is
Appendix B Intermediate subspaces of the expanding matrix Grassmann poset
In this appendix we prove that the intermediate subspaces in the Grassmann matrix poset come from level -admissible functions.
Claim (Restatement of Claim 41).
Let be as in Definition 40. Then
For this proof we recall the preliminaries in Section 7 on quotient spaces and bilinear forms.
Proof of Claim 41.
Fix and . It is enough to prove that if and only if there exists such that (i.e. if and only if ). We start with some and prove that . Let be such that . Let be such that . The matrices in the image of are linearly independent 242424Here we say matrices are linearly independent if they are linear indpendent as vectors in . since their sum has maximal rank. Hence is an isomorphism. From this there exists some -dimensional subspace so that . We write for some -dimensional subspace (with respect to the standard bilinear form). Let us define as
It is direct to check that is admissible, since every is a disjoint sum of rank one matrices, and the sum is also equal to
which has rank and whose row and column spaces are in and respectively, since it is contained in the row and column space of . We can also define as
Here the inner product is the derived inner product as in Section 2.2. We note that because
where is because the derived inner product is equal to (the standard) inner product for every . Even though the function is defined over which is not equal to , and is defined through the derived bilinear form (not the standard one), by Claim 120 we can find an admissible so that . This proves that .
As for the converse direction, “reverse engineer” the proof above. Let , and we show that . Let be such that . Let and let . These spaces exist from the purity of and . We define as follows. For every we (arbitrarily) find a decomposition of into rank one matrices, and index them by . That is, . We set . For we define using and . We find space and such that and ordered bases to and to . We (arbitrarily) re-index these bases as and and set . It is a direct definition chase to verify that is admissible, i.e. that has rank and its row and column spaces are equal to and respectively. Finally, the image of restricted to is since
Thus and it contains , so .
Appendix C Elementary properties of matrix poset
C.1 Domination is a partial order
Let us begin by showing that this relation is a partial order. We do so using this claim.
Proof of Claim 25.
The implications of and are a direct consequence of the definitions. Let us see that .
This shows that if then (and similarly for the column space).
Finally, let us see that . Assume that are trivial. Let us write . Then we can write and and because the row and column spaces intersect trivially, we have that and are sized sets that are independent, thus proving (which implies ). This also shows that , thus proving .
Proof of Claim 26.
Proof of Claim 24.
We need to verify reflexivity, anti-symmetry and transitivity. Let be matrices.
-
1.
Reflexivity is clear.
-
2.
Anti-symmetry: assume that and this implies that so .
- 3.
Remark 152.
Recall the following definition from partially ordered set theory.
Definition 153 (Rank function).
Let be a poset. A rank function is a function with the following properties.
-
1.
If then .
-
2.
For every there exists so that .
A poset is called a graded poset if there exists a rank function for that poset.
The order of matrices is also a graded poset, where the matrix is the rank function. To see this, we note that if , then so in particular and if , . Moreover, if then by the fourth item of Claim 25, we can write for some . Taking concludes that the function (of matrices) is a rank function (of the graded poset).
C.2 Isomorphism of intervals
We begin with this claim.
Claim 154.
-
1.
Let . Then if and only if .
-
2.
Let be such that and . Then if and only if .
Proof.
For the first item,
For the second item,
Proof of Proposition 28.
By Claim 154 the bijection maps such that to such that . Therefore is well defined as a function from to . Obviously is injective (since it is injective over the set of all matrices). Moreover, if then by Claim 154 the order is maintained, i.e. . The fact that follows from . Thus to conclude we need to show that is surjective, or in other words, if then . Let . Then by Claim 25 and in particular and similarly . By , we have that and by Claim 25 this implies that and similarly for the columns spaces. We conclude that and are trivial. By using Claim 25 we have that for ,
or equivalently that . Finally, we also have that by Claim 154 (as and ). Thus is surjective since is a preimage of inside .
Proof of Claim 30.
Fix and note that if and only if . Thus is a bijection. The order preservation follows from the second item of Claim 154.
C.3 The matrices have the direct-meet property
In this subsection we prove Claim 142.
Proof of Claim 142.
The technical statement we shall use in the proof is the following: For any matrices such that and , it holds that .
Let us first show that this statement implies the direct meet property. Let be three matrices whose sum is direct. We observe that 252525It is clear that . The other direction follows from a dimension count. and similarly . Consider any such that and . Observe that . Thus . The same argument applies to the respective column spaces, and so by the technical statement above . This implies that the set has the direct meet property.
Now we prove the statement itself. Observe that and . Moreover, which means that (respectively ) intersects trivially with (respectively ). Thus . So we get
On the other hand, because , the equality above can be rewritten as
or equivalently i.e. .
Appendix D Properties of the graphs induced by the matrix poset
In this appendix we prove Lemma 47 and Claim 55 necessary to prove the expansion of the complexes constructed in Section 3. We also prove Claim 117 necessary for the coboundary expansion proven in Section 6. To do so, we need to take a technical detour and provide some further definitions that generalize the graphs in said statements. In Section 3 we defined some graphs that naturally arise from the relations and . To analyze them, we need to generalize these definitions.
Definition 155 (Relation graph).
Let . The relation graph is the bipartite graph whose vertices are and if .
This is the analogous graph to the “down-up” graph in simplicial complexes, i.e. the graph whose vertices are and (for some simplicial complex ) and whose edges are all pairs such that (see e.g. [38]).
Another important graph is the following “sum graph”.
Definition 156 (Sum graph).
Let be integers such that and . The Sum graph is the bipartite graph whose vertices are and if there exists such that are a direct sum.
When we denote this graph by . In this case its definition simplifies: if and only if .
All the aforementioned graphs turn up when one analyzes the Grassmann graph defined in Section 3. However, the bulk of the analysis in Section 3 is on links of the Grassmann complex. There the graphs that appear are actually subgraphs of these graphs. Hence, we also make the following definitions of the graphs where we take or as our underlying posets instead of all .
Definition 157 (Upper bounded relation graph).
Let . Let . The graph is the bipartite graph whose vertices are and if .
Note that for every , the graphs are isomorphic. So when we do not care about the matrix we write instead of .
The graphs and are defined analogously as the subgraphs of matrices in :
Definition 158 (Upper bounded sum graph).
Let be integers such that and . Let . The Sum graph is the bipartite graph whose vertices are and if there exists such that .
In these cases we also write when we do not care about .
The second type of localization is with respect to subspaces.
Definition 159 (Lower bounded local relation graph).
Let be integers such that . Let . The graph is the subgraph of whose vertices are in .
Definition 160 (Lower bounded sum graph).
Let be integers such that and . Let . The Sum graph is the bipartite graph whose vertices are and if there exists such that (is a direct sum).
In the next section we prove upper bounds on the expansion of some of these graphs. In all the following claims stands for universal constants which we don’t calculate (and may change between claims). The main lemmas we need are these.
Lemma 161.
.
Lemma 162.
Let be such that and . Let . Then .
In order to prove these lemmas we need to analyze the other graphs as well. More specifically, we will use Lemma 15 to reduce the analysis of the graphs to the expansion of the and graphs. The bounds we need for Lemma 161 are these.
Claim 163.
Let . Then .
Claim 164.
Let . The graph is isomorphic to . Consequently by Claim 163 .
For Lemma 162 we will also need this claim.
Claim 165.
Let be such that and . Let . Then .
The proofs of all these claims are all quite technical, and while most of the proof ideas repeat themselves among claims, we did not find one proof from which to deduce all claims. More details are given in the next subsections. We conclude this sub section with the short proofs of Lemma 47 and Claim 55, that were necessary to prove the main theorem in Section 3. They follow directly from Lemma 161 and Lemma 162.
Proof of Lemma 47.
The double cover of is . Thus by Lemma 161 and Observation 14 .
Proof of Claim 55.
Careful definition chasing reveals that the double cover of is (isomorphic to) . Indeed, assume for simplicity that . Thus the vertices in the double cover of are two copies of . This is because by Claim 25, if and only if are a direct sum. Hence by Observation 14 it is enough to argue about the bipartite expansion of .
We observe that in if and only if in . Matrices and are connected in when there exists such that . This is equivalent to existence of such that with and (the sum of ’s is ). Observe that is redundant in this definition, that is, it is enough to require that there exists such that with and . This is because if we are given these as so, we can always find a suitable . By writing and , we get that are connected in , if and only if . This is exactly the definition of the edges in .
Thus by Lemma 162 .
D.1 Expansion of the upper bound local graphs
Proof of Lemma 161.
Fix and . We intend to use Lemma 16. We index our components by , where every component will be the graph containing edges such that . We claim that , by the map . Indeed, by Proposition 28 the vertices in , which are map isomorphically to the vertices of . Moreover, by Claim 154 if and only if .
Thus and by Claim 163 we conclude that .
Proof of Lemma 162.
We use Lemma 16. Our components will be for all . We observe that sampling an edge by sampling and then sampling an edge in , results in a uniform distribution over the edges of . By Lemma 161 every such component has .
We note that the (say) left side of the bipartite decomposition graph is the bipartite graph with:
-
1.
.
-
2.
.
-
3.
.
This is precisely . By Claim 165, so by Lemma 16,
Let us also give a short proof for Claim 164.
Proof of Claim 164.
Fix and . For notational convenience let and . We define to be
Let us first show that indeed bijectively maps the vertices to respectively. For this is clear. Moreover, if and only if , and in this case if and only if . Thus is a bijection of the vertex sets in every side.
Next we verify that if and only if . Indeed, if and only if . By definition of , this is if and only if and , or more compactly, . On the other hand, if and only if , and thus if and only if . The isomorphism is proven.
D.2 Bounding the expansion of the direct sum graphs
The proof of Claim 163 is by induction on the sum of matrix ranks, . We begin with the base case.
Claim 166.
.
The base case follows from the fact that the walk in is close to the uniform random walk as in Corollary 11.
Proof of Claim 166.
Without loss of generality let us assume that , the identity matrix whose rank is . For vectors the standard bilinear form over , which we sometimes abuse notation and call an “inner product”. Golowich observes the following
Claim 167 ([50, Lemma 66]).
Let the identity matrix of rank . A matrix if and only if for some and such that
Thus is (isomorphic to) the bipartite graph where , is a disjoint copy of , and we connect if and only if (i.e. we move from to ). We will use Corollary 11 and show that the two step walk in this graph is -close to the uniform graph, thus proving that . For concreteness we will use the two step walk from to .
Let us fix an initial vertex and let be the distribution over vertices in the two step walk. Let be the uniform distribution over vertices. We want to show that .
The basic idea is this: we prove below that the probability that we traverse from to essentially only depends on whether , and whether (and not on or themselves). While this is not true per se, it is true up to some negligible probability. Then we use the large regularity to bound the probability that has or by . This asserts that is (almost) uniform on a set that contains all but a negligible fraction of the vertices, which is enough to show closeness to . Details follow.
We record for later the following observations.
Observation 168.
-
1.
If then .
-
2.
.
-
3.
The graph is -regular.
The first two observations are immediate, but we explain the third: fixing , we count its neighbors . There are choices for since it is perpendicular to and non-zero. Given , the vector satisfies
Note that are linearly independent since both are non-zero and . There are solutions to these linear equations hence the graph is -regular.
Let be any vertex. The first crude bound we give on the is just by regularity. For any , . This bound is tight when . Similarly, if either or then we also just bound ; there are at most such pairs.
Now let us assume and calculate more accurate upper and lower bounds on by counting how many two paths there are from to , or equivalently, how many are common neighbors of .
Given , the vector needs to satisfy . The two vectors are linearly independent by assumption that they are both distinct and non-zero. Thus there are non-zero -s that satisfy .
Fixing the vector needs to satisfy and . If are linearly independent then there are exactly solutions to these equations, all of them are non-zero, and every such solution corresponds to a common neighbor . If they are not linearly independent we claim that there is no solution. We note that every pair must be linearly independent: All three are non-zero vectors. Moreover, are distinct vectors by assumption, and similarly (resp. ) because (resp. ). Every pair of distinct non-zero vectors are independent. Thus, if there is a dependency then , and so the first two equations imply that , so there is no solution.
We conclude that the number of paths from to is one of the following.
-
1.
- if is not a valid solution in the first step, i.e. either or .
-
2.
otherwise.
We have that for every such pair,
for . This implies that for
and
Thus in particular,
The claim now follows from Corollary 11.
Now we prove Claim 163. As mentioned before, the proof is by induction on . A similar induction was done in [26] when analyzing the so-called swap walk, a generalization of the Kneser graph to high dimensional expanders. In the inductive step, one uses Lemma 16 to reduce the analysis of to that of (which holds true by the inductive assignment). Details follow.
Proof of Claim 163.
We show that if then
| (D.1) |
By using this inequality we eventually get that
where the final equality holds by Claim 166.
To prove (D.1) we use Lemma 16. In this case our local decomposition is . The graph is the induced bipartite subgraph where and . We claim that : the isomorphism maps
For the right sides, we note that if and only if so this isomorphism maps the right side of to that of . For the left sides, Proposition 28 gives us that if and only if . Thus maps matrices isomorphically to matrices on the left side of . Checking that in if and only if in is direct. Therefore for every , the second largest eigenvalue .
D.3 Bounding the expansion of the relation graphs
We start by proving the claim in the following special case.
Claim 169.
Let and let be such that , then
Proof of Claim 169.
Fix . For this case we intend to use Corollary 11 on the two step walk on . We prove that
| (D.2) |
where is the distribution of the two step walk starting from , and the distribution is the uniform distribution over . Fix and from now on we just write instead of for short.
We will show that there exists a set such that both for a sufficiently small . Then we will also prove that the distribution conditioned on this event is uniform, and this will give us (D.2). Here
A quick calculation will show that in this case for some .
First we show that : Let us show that the probability of choosing a uniform such that is at most (the same also holds for the column spaces). The row span of is sampled uniformly as an dimensional subspace inside a dimensional space, conditioned on . So this probability is
The ratio is bounded by via standard calculations. The same probability holds for the columns spaces, therefore . The last equality is by .
Next we claim that . Indeed, the two step walk from traverses to some (whose row space intersects trivially with ), and from we independently choose a matrix . As , it follows that if and only if . For any fixed , the probability that is at most (repeating the calculation above).
Now let us show that conditioned on , for any two neighbors of in the two step walk, the probability of sampling is the same as sampling . To show this it is enough to show that there exists a graph isomorphism of the original “one-step graph”, that fixes and sends to . Let us denote by the general linear group, or equivalently the group of invertible matrices. We will find such that:
-
1.
.
-
2.
.
-
3.
.
Assume we found such . We claim that is an isomorphism of the one-step graph. Indeed, note that if then as multiplying by an invertible matrix maintains rank, it follows that . Therefore, is a bijection on the vertices of the graph. It is easy to check that this multiplication also maintains the relation so this is indeed an isomorphism. Finally, it is also easy to see that is mapped to a path , so in particular such an isomorphism implies that the probability of sampling is the same.
To find such recall that . Thus we can decompose , , and . By assumption on the intersections of the row (and column) spaces, the sets and are independent and have the same size. The same holds for the corresponding sets of column vectors (replacing with ). Thus we just find any such that
These will have the desired properties. By the arguments above, the claim is proven. We comment that the above proof is one place where an analogous argument fails to hold for higher dimensional tensors. We heavily relied on the fact that for any fixed matrix , the row span and column span of an rank matrix is uniformly distributed over dimensional subspaces inside and , even if these marginals are not independent.
We move on to the general case.
Proof of Claim 165.
Fix and . The case where is by Claim 169 so assume that . Towards using Lemma 16, we decompose to components where is the graph induced by all edges such that . We claim that is isomorphic to . The isomorphism is . Let us start by showing that this maps vertices to vertices.
Indeed, fix any and let . Explicitly,
Note that every is a direct sum , and as this implies that . As we saw before, this implies that , therefore . Conversely, if then has . Moreover, as then , i.e. . It is also clear that hence . Of course, a similar argument holds for the right side , then is a bijection of the vertex set. Finally, by Claim 154, if and only if , so this is indeed an isomorphism of graphs.
We note that if then and therefore we can use Claim 169 and deduce that for every , . Moreover, we observe that the bipartite local to global graph for the left side, is , thus by Claim 169 this also has and so by Lemma 16 the lemma is proven. We comment that the requirement that is just for convenience. Multiple uses of the same decomposition with Lemma 16, would yield a similar bound whenever for any fixed constant . As we only need the claim for , we merely mention this without proof.
D.4 Short paths in
This subsection of the appendix is devoted to the proof of Claim 117 which is necessary to analyze the coboundary expansion of the complexes in [50].
We begin with the following auxiliary claim proven in the end of the subsection.
Claim 170.
Let be a rank matrix and let be a rank matrix.
-
1.
Let be such that . Then there exists a matrix with such that .
-
2.
Let be such that then there exists such that
Phrasing this claim differently, the first item claims that any two matrices in one side of have a length path between them. The first item claims that any two matrices in one side of have a length path between them.
Proof of Claim 117.
We proceed as follows. We first decompose into ranked matrices such that and . Then we find some of rank such that . This is possible due to the first item in Claim 170.
Then we will prove that there exists a -path composed of three paths of length : one from to , one from to and one from to .
Let us show how to construct the first path, the other two are constructed similarly. Note that and that they are both . Thus if we find such that
Then by Proposition 28, adding to all three will give us the desired path in :
But observe that has rank , and thus existence of such matrices is promised by Claim 170 so we can conclude.
Proof of Claim 170.
Without loss of generality let us assume that is the identity matrix of rank and that is the identity matrix of rank . We wish to use the criterion for given in Claim 167.
For this proof we also require the following observation which follows from elementary linear algebra. We leave its proof to the reader.
Observation 171.
Let be a subspace of dimension . Let be independent vectors. Assume that . Then for every there exists a solution to the set of linear equations:
-
1.
For every , , and
-
2.
For every , .
Let us begin with the first item. Given of rank we need to find some of tank such that . Equivalently, we will find such that and satisfies the criterion in Claim 167.
Let us write where these decompositions satisfy the property in Claim 167. Let . As is a solution space of linear equations over , it is a subspace of dimension . We will select the rows of from .
However, it is not enough to just select arbitrary rows from , since we need to satisfy the condition that if participates in the decomposition of then if and only if . In addition, we will also require that will be perpendicular to all the ’s. This will define a set of linear equations which we will solve using Observation 171. To do this we will find an -dimensional subspace in that intersects trivially with the span of the ’s (the sum of row spaces of and ).
We note that . Let us show this for : any non-zero vector is a sum of where at least on of the ’s are not zero. On the other hand, , so there is at least one , implying that . Thus we conclude that , and in particular there exists some dimensional subspace such that intersects trivially with . Let be a basis of .
Thus by Observation 171, for every there exists some such that
-
1.
For every , for all , and
-
2.
In addition
By taking we observe that both and satisfy Claim 167, and therefore .
Let us turn to the second item. We continue with the notation . The strategy here will be similar. Let . We observe that this is the solution set of linear equations and therefore its dimension is . Let be independent vectors, and set . We observe that as before so by Observation 171, for every there exists some such that
-
1.
For every , .
-
2.
For every ,
We note that the linear equations for ’s do not consider the ’s.
Similarly, we find ignoring the ’s. That is, for every we find such that
-
1.
For every , .
-
2.
For every ,
Then we set and . It is easy to verify that as before .
Now we find such that . The upshot of the previous step is that now and have the same row space . Thus we find as follows. Let . This subspace also has dimension so let be a set of independent vectors from .
As before, we observe that but this time . Thus by Observation 171 for every , we can find such that
-
1.
For every , , and
-
2.
In addition,
Then we set . It is direct to verify that by Claim 167.
Appendix E Second largest eigenvalue of
Proof of Lemma 65.
Let . For the Johnson graph , its largest unnormalized eigenvalue Therefore by Theorem 63 the absolute values of the normalized eigenvalues are
Here the convention is that when we write for or , then the term is equal to . Thus, the terms corresponding to or vanish since the product of the three binomial coefficients is for these choices of . We first show the statement for odd . In this case, we group terms and together to get
To simplify the products we first observe that for any , and .
| (E.1) |
Furthermore we use the following claim to bound the term in absolute value:
Claim 172.
For any constant and any integers and ,
A proof is given later in the appendix. By the claim the expression in Equation E.1 can be bounded by a binomial sum:
Next consider the case of even . First use the binomial identity to obtain the following bound
First note that the second term and the fourth term always evaluate to . Thus we can simplify the expression as
These two terms resembles the expression of and can be bounded by grouping terms and .
Proof of Claim 172.
We prove the statement by induction on . The case of holds trivially. Suppose the statement holds for all , then we are going to show that the inequality also holds for . Note that by the induction hypothesis
| (E.2) |
To simplify the expressions we define
and also
Using this notation, (E.2) can be rewritten as
Rearranging the inequality we get that
| (E.3) |
Now we bound this difference
| (E.4) |
We note that for fixed constants , and , the function is decreasing when . If we set , and , then
Therefore
and together with the fact that we can deduce that (E.4). Equivalently,
where the second inequality holds by (E.3). Note that this inequality is exactly the claim statement for . Thus we finish the induction step and conclude the proof.
Appendix F Sparsifying the Johnson complexes
While both the Johnson complexes and the RGCs over vertices have vertex degree , the Johnson complexes have much denser vertex links, or equivalently more -faces. The degree of the Johnson complex ’s vertex links is
while that of the RGCs is . In fact we can sparsify the links and reduce the number of -faces in Johnson complexes by keeping each -face with probability , and set so that the link degree becomes . Then we shall use the following theorem to show that the link expansion is preserved after subsampling.
Theorem 173 (Theorem 1.1 [21]).
Suppose is a graph on vertices with second largest eigenvalue in absolute value and minimum degree . A random subgraph of with edge-selection probability has a second eigenvalue satisfying
with probability where tends to faster than any polynomial in .
From this eigenvalue preservation result we can get the following sparsification.
Corollary 174.
Consider a random subcomplex of a -dimensional Johnson complex constructed by selecting each -face i.i.d. with probability where , and is the degree of ’s vertex links. Then with high probability every vertex link of is a -spectral expander.
Here we recall that is the binary entropy function.
Proof.
We first argue that almost surely so that for every the vertex link has the same vertex set as . From the subsampling process we know that for any edge , the degree of in the link of follows a binomial distribution with
By the Chernoff bound for binomial distributions we know that
So by a simply union bound over all pairs of we get that with probability every link in has the same vertex set as .
Next, recall by Lemma 59 ’s vertex links have second eigenvalue . Since the choice of ensures that , each link of is a expander. Finally, applying an union bound over all links of completes the proofs.
Appendix G Proof of the van Kampen lemma
To prove this lemma, we would like to contract using the contractions of so the proof should give us an order in which -s are contracted. This order is given by the order in which the set are contracted to reduce to a point. Therefore, for every such diagram, it suffices to find a single face such that we can contract to obtain a diagram of a cycle with one less interior face. The property we need from is that the shared boundary of and is a contiguous path. This requirement is captured in the following definition.
Definition 175 (valid face and path).
Let be a van Kampen diagram. We say that an interior face is valid if we can write its boundary cycle such that the exterior cycle can be written as where contains at least one edge and the vertices of are disjoint (except for the endpoints). In this case we call a valid path.
Lemma 79 will easily follow from the following three claims.
Claim 176.
Every -connected plane graph has at least one valid face.
Claim 177.
Let be a valid path in . Then for every , .
Claim 178.
Let be a van Kampen diagram, let and let be the induced subgraph on . Then is -vertex connected.
Given the three claims, we can prove the van Kampen lemma as follows.
Proof of Lemma 79.
Fix be as defined in Section 5.3. We prove this lemma by induction on the number of inner faces of . If has exactly one inner face , then its boundary is also the boundary of the outer face . Then we can deduce that . So indeed there is a contraction of using -triangles.
Assuming the lemma is true for all van Kampen diagrams with at most inner faces, we shall prove it for van Kampen diagrams with inner faces. By Claim 176, we can always find a valid face in such that and where is the corresponding valid path. The decompositions are illustrated in Figure 12.
Using Claim 85, we can contract (the image of the outer boundary of under ) to using triangles. Correspondingly, we can construct an induced subgraph of by removing all edges and intermediate vertices in .
Note that the the outer boundary of is . Furthermore, since the intermediate vertices in all have degree in (by Claim 177), removing these vertices only removes the inner face . Therefore, has inner faces. Finally by Claim 178, is still a -connected plane graph.
Thereby is a van Kampen diagram of the cycle in with inner faces, and so the induction hypothesis applies. Thus we complete the inductive step and the lemma is proven.
Next we shall prove the three supporting claims. Before doing so, we define the cyclic ordering of vertices in a cycle which will later be used in the proofs.
Definition 179 (Cyclic ordering).
Let be a graph. For a given cycle in , a cyclic ordering of the vertices in is such that two consecutive vertices in the ordering share an edge in .
Proof of Claim 176.
We will show that either there exists a valid face, or that there exists two inner faces and four vertices in the cycle such that , (that is, on the boundaries of the respective faces), and such that in the cyclic ordering of , . Then we will show that the latter case implies there is an embedding of a -clique on the plane, reaching a contradiction. We mention that these points do not need to be vertices in , only points on the plane.
Indeed, take a face that shares an edge with . If it is not valid, it partitions into disconnected segments (and this partition is not empty since otherwise was valid). If there exists some that touches two distinct segments, we can take and as above. Otherwise, we take some , that contains an edge. We now search for a valid face whose path is contained in , and continue as before. That is, take some that shares an edge in with the outer face. If it is valid we take and if not we consider the partition of as before. We note that this process stops because the number of edges in the segment in every step strictly decreases - and when we stop we either find a valid face or four points as above.
Now let us embed the -clique. Indeed, we fix a point on the outer face in the interior of , and take to be the vertices of the clique. The edges are drawn as follows.
-
1.
From to every other vertex we can find four non intersecting curves that only go through .272727For this one can use the Riemann mapping theorem to isomorphically map the outer face to the unit disc and to its boundary. Without loss of generality we can choose so that it is mapped to the center. Then we draw straight lines from the image of to the rest of the points in the boundary (and use the inverse to map this diagram back to our graph).
-
2.
The edges are the curves induced by the cycle . These curves do not intersect the previous ones (other than in ) since the curves in the first item lie in the interior of .
-
3.
By assumption, the pairs and so we can connect these pairs by curves that lie in the interiors of and respectively, and in particular they do not intersect any of the other curves.
Proof of Claim 177.
Let be the valid face. Let us denote by the edges adjacent to in which is not an endpoint. Assume towards contradiction that there is another edge adjacent to . Thus either lies in the interior or the exterior of .
If it lies in the interior, then by -vertex connectivity there exists a path starting at connecting to another point in the boundary of , and other than and the end point, the path lies in the interior of . This is a contradiction, since any such path disconnects to two faces. Otherwise it lies in the exterior, but the argument is the same only with instead of .
Proof of Claim 178.
Let the end points in , and notice that participate in a cycle in - the cycle bounding the outer face. In particular is connected. Remove any vertex from . Let be a path that connects two vertices in (that may contain some vertices in ). Let us show that we can modify to some in . By Claim 177 every vertex in which we removed had degree . Therefore any path containing a vertex in , contains all of (or its reverse). Thus to mend we just need to show that and are in a simple cycle in . Indeed, this is true from the definition of a valid path: and such that all vertices in are disjoint besides the end points. The paths participate in simple cycles therefore is a simple cycle and we conclude.
Appendix H Expansion of containment walks in the Grassmann poset
Proof of Claim 21.
Although all the claims below apply for for any , for a simple presentation let us assume that (the same idea works for arbitrary ). Let us denote by the bipartite graph operator from to . We note that , and therefore it is sufficient to prove that . We do so by induction on .
In fact, we prove a slightly stronger statement, that . This suffices because . Let be the adjoint operator to , and denote by be the second largest eigenvalue of the two step walk from to . To show that it suffices to prove that .
The base case for the induction is for . In this case
where is the non-lazy version of the walk (namely, where we traverse from to if ). The adjacency operator is the link of , and thus by -expansion we have that .
Assume that and consider the two step walk on . As above, we note that
where is the non-lazy version of the walk. We note that the laziness probability is because every subspace has exactly subspaces of codimension (so this is the regularity of the vertex). Thus we will prove below that and this will complete the induction.
Let us decompose the non-lazy walk via Lemma 15. Our components are . To be more explicit, note that in the two step walk if and only if . We can choose such a pair by first choosing and then choosing an in the link . The distribution of the link if the conditional distribution, hence taking to be the -marginal of the distribution over flags in , we have that is a local-to-global decomposition. The local-to-global graph connects to - so this is just the containment graph which by induction is a -expander. By Lemma 15, and we can conclude.
Appendix I A degree lower bound
A classical result in graph theory says that a connected Cayley graph over has degree at least . Moreover, if the Cayley graph is a -expander then it has degree at least [2]. Are there sharper lower bounds on the degree if the Cayley graph is also a Cayley local spectral expander?
In this section we consider the “inverse” point of view on this question. Given a graph with vertices, what is the maximal such that there exists a connected Cayley complex over whose link is isomorphic to . Using this point of view, we prove new lower bounds for Cayley local spectral expanders, that depend on properties of . Specifically, we prove that if has no isolated vertices then ; if is connected we prove that . Finally, if the link is a -regular edge expander, we prove a bound of . For all these bounds, we use the code theoretic interpretation of the links given in [50].
We begin by describing the link of a Cayley complex, and using this description we give a lower bound on the degree of the Cayley complex in terms of the rank of some matrix. This linear algebraic characterization of a degree lower bound is already implicit in [50, Section 6].
After that, we will lower bound the rank of the matrix, and through this we will get lower bounds on the degree of such Cayley complexes.
A link in a Cayley complex naturally comes with labels on the edges which are induced by the generating set (i.e. an edge between and in the link of will be labeled which by assumption is a generator in the generating set). Note that if is labeled then there is a -cycle in the link between and where every edge whose endpoints correspond to two generators is labeled by the third generator.
Let be a graph with vertex set and a labeling . The graph is nice if for every that is labeled there is a three cycle in the graph where is labeled and is labeled . We would like to understand for which does there exist a Cayley complex over so that the vertex links of are isomorphic to . That is, for which can we find generators such that the map is a graph isomorphism between the vertex link and . Observe that for this to hold, whenever there is an edge labeled by , we require that . Thus we can define the matrix to have in every row the indicator vector of for every labeled by . Let us show that this is a sufficient condition.
Claim 180.
Let be a nice graph with vertices. Let and let be the matrix whose rows are the ’s. Then the following is equivalent.
-
1.
The columns of are in the kernel of .
-
2.
There exists a Cayley complex over and whose link is isomorphic to whose underlying graph is .
In particular, if is connected then .
This equivalence is essentially what was proven in [50, Lemma 77]. The degree bound is a direct consequence of it. Nevertheless, we prove it in our language for clarity.
Proof.
If the first item occurs, this means that for every labeled by , and therefore the -cycles are in so add into the triangle set of . Then it is straightforward to verify that the link of is isomorphic to .
On the other hand, from the discussion above, the isomorphism to implies that for every edge in with label, their corresponding generators satisfy . Hence the columns of are in .
In particular, this implies that . On the other hand, if the complex is connected then . Combining the two we get that the degree of is lower bounded by .
Corollary 181.
Let be a connected Cayley complex over with degree such that the link of contains no isolated vertices. Then . Moreover, if the link is connected then .
Proof.
The corollary follows from the inequality , together with the observation that which we now explain. We can greedily select independent rows from such that whenever a generator has not appeared in any selected rows, we take an row where appears. As every newly selected row contains at most new generators, we can find at least such equations. Thus, and the bound follows.
If the link is connected, we can improve on this argument. At every step when we select a row, we denote by the set of vertices that have appeared in the selected rows. Since the link is connected, therefore while we can always choose a new row containing vertices from both and its complement, in which case the new row (besides the first one) introduces at most new vertices. Thus . The bound follows.
I.1 Improved bound from expansion
If the graph is an (edge) expander, we can improve the naive bounds above. Let be the degree of the Cayley complex and be the degree of a vertex in the link. We get a degree bound of . In particular, if the degree goes to infinity (which is also a necessary condition to get better and better spectral expansion), this lower bound tends to infinity as well.
Lemma 182.
Let be a simple Cayley HDX over with generators.282828Simple, means that there are no loops or multi-edges. This also implies that every two labels of edges that share a vertex are distinct. Assume that the link is -regular and denote it by . Let be such that for every subset of vertices in the link ,
where the probability is over sampling an edge (oriented) in the link. Then
A few remarks are in order.
Remark 183.
-
1.
We note that the edge expansion condition in the lemma is equivalent to one-sided -spectral expansion for some by Cheeger’s inequality. Thus whenever is bounded away from we can treat as some constant absorbed in the notation, and write .
-
2.
Moreover, the well-known Alon-Boppana bound implies that -regular -one sided spectral expanders have . Therefore, this bound also implies
However, this is not as sharp as the bound given in [2].
-
3.
We prove this lemma for regular graphs for simplicity. The argument could be extended for more general edge expanders.
Proof of Lemma 182.
We will assume without loss of generality that since otherwise the claim is trivial from the bound . By Claim 180, therefore it suffices to prove that
| (I.1) |
to prove the lemma.
This lower bound follows from the same greedy row selection process we conducted above. We start by greedily selecting rows from such that the selected rows are independent. We keep track of the vertices/variables that appear in the selected rows, and select new rows such that every new row introduces the least number of new vertices possible. We will prove that there is a way to select rows so that only fraction of the rows selected will introduce more than one new vertex (and the number of newly introduced vertices in one step is always ). Since the process terminates after steps, the argument above implies that which in turn implies (I.1).
For we denote by the set of variables that are contained in one of the first rows selected. By assumption, . Equivalently,
In particular, for every there exists a vertex such that at least of its outgoing edges go into . In particular, once every has at least edges into .
Hence, we select rows as follows. If we select new rows arbitrarily that introduce as few new vertices as possible. After , if in the -th step every new row introduces at least two new vertices, we select a row that contains (as defined above) and a vertex in (such a row exists by our choice of ). We observe that if every new row introduces at least two new vertices, this implies that the edges connecting to are labeled by distinct generators in . In particular, after selecting which adds and another new vertex to , there are at least edges from to that are labeled by distinct vertices in (since these edge labels were not in when we inserted ). So the next steps of the process add at most new vertex per step. In particular, for every such step where vertices are inserted to to get , there is a sequence of steps each of which adds new vertex. In conclusion, there are at most steps that introduce more than one new vertex to (out of at least steps) and the lemma follows.