Improved Approximation Guarantees for Advertisement Placement

Abstract
The advertisement placement problem involves selecting and scheduling ads within a timeline that has capacity constraints to maximize profit. Each task is characterized by its height, width, and profit, and must be fully scheduled across multiple time slots. This problem models practical scenarios such as internet advertising and energy management, and it also generalizes classical combinatorial optimization problems like the knapsack and bin packing problems.
We present a simple -approximation algorithm for any , which improves upon the state-of-the-art factor established by Freund and Naor twenty years ago. Our approach combines rounding techniques with dynamic programming and an efficient extension of list scheduling. Furthermore, we enhance this method with linear programming techniques to provide an almost optimal -approximation algorithm under resource augmentation, which allows for a slight increase in time slot capacities.
Keywords and phrases:
Advertisement Placement, Two-dimensional Packing, Geometric Knapsack, Resource AllocationCategory:
APPROXFunding:
Waldo Gálvez: Supported by ANID through grants SIA85220118 and Fondecyt de Iniciación 11230663.Copyright and License:
2012 ACM Subject Classification:
Theory of computation Design and analysis of algorithmsEditors:
Alina Ene and Eshan ChattopadhyaySeries and Publisher:
1 Introduction
In the advertisement placement problem, the goal is to efficiently select and schedule a set of ads to attract a wider variety of customers, for example, when they visit a specific website or a place. Formally, we are given a set of tasks, each one characterized by a height, a width and a nonnegative profit, and also a timeline of length with a fixed capacity on each time slot. The goal is to select a subset of the tasks with maximum total profit to be scheduled into the timeline while respecting the capacity constraints. Here, scheduling a task means allocating a number of slices or copies of the task equal to its width into different time slots, and the profit of the task is accounted for only if all its copies are correctly allocated.
This problem was first introduced by Adler, Gibbons, and Matias [1], motivated by space-sharing in internet advertising. In this context, a space exists where ads will be displayed that has capacity , and each ad has a size and a display frequency requirement . Consequently, a natural goal is to use the space as effectively as possible, which can be modeled by defining profits as ; indeed, this is the case considered originally by Adler et al. and the main focus of this work. Recently, the advertisement placement problem has found applications in energy management; see, e.g., [2, 28, 30]. In this case, the tasks are electric appliances characterized by their execution time and the energy they use to operate, and the goal is to plan the electric consumption of a given journey while optimizing some associated objective function, assuming that tasks can be interrupted and restarted later. From a theoretical standpoint, advertisement placement can be thought of as a natural and interesting two-dimensional generalization of classical combinatorial optimization problems such as knapsack [25], makespan minimization [26], and bin packing [8], among others.
As observed by Adler et al. [1], the advertisement placement problem is NP-hard even in very restricted settings, including the classical framework of divisible widths introduced by Coffman et al. [22] in the context of bin packing. Later, Freund, and Naor [11] obtained a ()-approximation algorithm for the case with arbitrary widths and arbitrary profits. Upon this work, this result is the best-known so far, even for the problem with profits equal to the task areas.
1.1 Our Results
Our main result is the design of improved approximation algorithms for advertisement placement. More specifically, we achieve a -approximation for the problem (Theorem 1), improving the previously mentioned result due to Freund and Naor [11]. We also complement this result with a -approximation algorithm under resource augmentation, meaning that our algorithm might use a slight extra amount of capacity from each time slot (Theorem 7).
To achieve our -approximation, we classify the tasks according to their heights into tall and short, designing almost optimal algorithms for each case separately. For the case of tall tasks, we show that one can efficiently select a subset of tasks that can be feasibly scheduled and have almost optimal profit via rounding techniques and dynamic programming, which then can be scheduled using known results for the makespan minimization variant of advertisement placement. For the case of short tasks, we show that a simple extension of list scheduling leads to an almost optimal efficient algorithm. Under resource augmentation, we start by scheduling tall tasks precisely as before, but then use a linear programming relaxation to schedule short tasks on top, which can be efficiently rounded to a feasible schedule by adapting the classical scheme due to Lenstra, Shmoys and Tardos [26] while possibly slightly overloading the time slots. This approach requires selecting which short tasks go into the solution, which we do by further distinguishing short tasks into wide and small according to their widths. For the case of wide tasks, we use rounding techniques as in the -approximation for tall tasks, while in the case of small tasks, we run a greedy procedure.
1.2 Related Work
The advertisement placement problem was first introduced by Adler, Gibbons, and Matias [1]. They considered two different variants of the problem: makespan minimization, where the goal is to schedule all the given tasks while minimizing the maximum load, and profit maximization, the variant considered here. Their results concern mainly the special case with divisible widths and profits being equal to the area of the tasks, where they provide a -approximation. For the case of the Makespan Minimization variant, Dean and Goemans developed a -approximation with running time , and an approximation scheme with running time [9].
Other two-dimensional generalizations of knapsack have also been studied in the past. One such example is the two-dimensional geometric knapsack problem, where the input consists of a rectangular knapsack in the two-dimensional plane, and rectangular items, characterized by their height, width and profit; the goal is to select and place a subset of items with maximum total profit in such a way that they are axis-parallel and do not overlap (which corresponds to advertisement placement when slices are restricted to go into contiguous time slots and they all must use the same vertical space). In the case of general profits, the best-known results for this problem are a -approximation, and a -approximation in the case of uniform profits [13]. If the profit of the items is equal to their area, then the problem admits a PTAS [4], and also improved results are known for some special settings, including pseudo-polynomial time algorithms [14], and resource augmentation [21], among others.
Another two-dimensional generalization of knapsack is the unsplittable flow on a path problem, which is similar to advertisement placement with the difference that each task is associated with a set of contiguous time slots where its slices must go in case the task is chosen. After a series of improvements for the problem, Grandoni et al. [17] showed that it admits a PTAS even with non-uniform capacities for the time slots. The setting where, instead of specifying precisely into which time slots a task must go, we specify a longer interval where its slices could go for each task, is known as time windows constrained. For the case of unsplittable flow on a path with time windows constraints (i.e., where slices still must go into contiguous time slots), the best known polynomial time approximation algorithm has an approximation ratio of [16], and it was recently proved that the problem is APX-hard but admits a -approximation in quasi-polynomial time under resource augmentation [3]. For advertisement placement with time windows constraints, Da Silva et al. [7] provide a PTAS when the timeline length is bounded by a constant, and a -approximation for windows of the form [27].
Two-dimensional packing problems where all the given tasks must be placed (similar in spirit to makespan minimization) include well-studied problems such as strip packing [18, 12, 19], demand strip packing [10, 20], two-dimensional variants of bin packing [5, 24], among many others. We refer the reader to the survey by Christensen et al. [6] for further details.
Organization of the paper.
2 Preliminaries
In the advertisement placement problem, we are given a set of tasks, where each task is characterized by its height , its width , and its profit ; we are also given a timeline defined by time slots, and a capacity . The goal is to select a subset of tasks of maximum total profit that can be feasibly scheduled into the timeline. In this context, a feasible schedule for a given set of tasks corresponds to an allocation function that assigns, for each task in the set, different time slots where a slice of the task will be scheduled (i.e., a piece of the task that has height and width ). The allocation function must satisfy that the total load of each time slot , denoted as and corresponding to the sum of the heights of tasks scheduled in the time slot, must be at most (see Fig. 1 for an example). Scheduling two or more slices of a task in the same time slot is not allowed.

Since a feasible schedule requires specifying where each task slice goes, we will assume that is polynomially bounded by to ensure that the output can be returned in polynomial time. Furthermore, unless otherwise stated, it is assumed that , and therefore, the goal is to cover as much area from the region as possible; this objective encodes the original formulation of the problem, as well as other interesting applications (see, e.g., [1]). When referring to the case of general profits, we will denote the problem as weighted advertisement placement.
Areas and Configurations.
For a given task , we define , which naturally extends to a subset of tasks as ; we use an analogous notation for profits. Throughout this work, for a given instance of the problem, will denote a fixed optimal schedule for (dependence on will be dropped if clear from the context), and will denote the total area of the tasks included in OPT; when working with general profits, will denote the total profit of the tasks included in OPT. Given a feasible schedule , we define the load configuration of as a vector of dimension , where each entry stores the total load of a time slot, and is sorted non-increasingly by load; see Fig. 1 for an example.
3 A -approximation for Advertisement Placement
In this section, we prove our first main result.
Theorem 1.
For any , there exists a -approximation for advertisement placement.
To achieve this result, we split our proof into two steps. We start by categorizing the tasks in the input according to their heights into tall and short, proving that an almost optimal solution can be obtained efficiently for each case. In what follows, is a constant, and we say that a task is tall if , and short if . We denote by and the sets of tall and short tasks from the instance, respectively; furthermore, we denote by and the optimal solution restricted to tall and short tasks, respectively.
When focusing on tall tasks, we rely on several rounding procedures. First, by adapting the linear grouping technique from bin packing [8, 23], we reduce the possible number of heights in the instance to a constant number, and then we round down the total width of each group (classified according to the rounded height) to know which tasks will be included in our solution. After this, it is possible to apply the results from Dean and Goemans [9] for makespan minimization in the context of advertisement placement, yielding a PTAS for the tall tasks.
For the case of short tasks, we show that a slight variation of the shortest size least full first (SSLF) algorithm, studied by Freund & Naor [11], yields a PTAS. Since, in any optimal solution, either the tall tasks or the short tasks have total area at least , running both algorithms and returning the best of the computed solutions yields a -approximation.
3.1 Linear Grouping for Tall Tasks
We start by devising the algorithm for tall tasks, where our goal is to compute an almost optimal solution efficiently. Interestingly, the solution we construct will exhibit the extra property of having a load configuration upper bounded by the load configuration of (coordinate-wise), which is a structural property of independent interest. To do so, we first reduce the possible number of heights to a constant number by adapting a linear grouping technique; see, e.g., [8, 23].
Our goal is to select a subset of tasks of total area at least that can be feasibly scheduled. Observe that, if is defined by at most tasks, we can guess precisely such a set in polynomial time and conclude this part. Thus, from now on, we assume that has more than tall tasks. The outline of our procedure is the following:
-
(I)
Suppose that with . We guess a set of at most tall tasks, that we call the guessed tasks; the rest are non-guessed tasks. Out of the guessed tasks, we first guess a subset of at most tasks, that we call the rounding tasks, and a second (disjoint) subset of at most tasks, that we call the shifted tasks. We discard both sets, meaning that they will not be included in our solution.
-
(II)
The set of non-guessed tasks that have a smaller index than the rounding task with smallest index is discarded.
-
(III)
For any remaining non-guessed task , round up to , with being the closest larger height among the rounding tasks (breaking ties in favor of smaller indices).
See Fig. 2 for a depiction of the procedure. Let be the set of non-guessed tasks whose heights were rounded according to the -th rounding task (sorted non-increasingly by height). As the following lemma shows, there exists a set of guessed tasks with a subset of rounding and shifted tasks that allows to bound the total area of discarded tasks from by , while still having a feasible solution for the rounded tasks from that were not discarded.
Lemma 2.
Let be a set of tall tasks, and be the output of the previous rounding procedure. There exists a set of rounded tall tasks such that:
-
(i)
The number of distinct heights in is constant.
-
(ii)
The total area of is at least .
-
(iii)
There exists a feasible schedule for .
Proof.
Suppose we place all the tasks in one next to the other, sorted non-increasingly by height. Since there is a feasible schedule for them and their height is at least , the total width of tasks in , say , is at most . Starting from the tallest slice in the pile, we partition the slices of the tasks into groups of total width exactly each, except possibly for the last one, which can have a smaller width. We have at most groups.
Our tentative set of rounding tasks from the rounding procedure will initially be defined by taking the task of smallest height from each group , for each (this set may contain less than tasks due to repetitions), and our set of shifted tasks will initially be empty. At this point, the set of rounding tasks and guessed tasks is the same, and tasks with smaller index than the rounding task with smallest index are not part of , so they can be discarded.
Consider the feasible schedule for . Since the first group on the left (i.e., ) is discarded, we will use the empty space due to this removal to place the slices from in the following way: we iteratively place the slices from into the leftmost time slot that had a slice from and does not have any slice from the same corresponding task; if some slice cannot be placed, we skip and continue. We claim that the number of tasks whose slices were not placed entirely by this procedure is at most . Indeed, if there were more, since there must be some time slot that had some slice from that did not get replaced by a slice from , this means that slices that could not get assigned into that space already have another slice from the same job there. However, since all the heights are at least , there can be at most other slices in that time slot, meaning that some task could have used that space in our procedure. This leads to a contradiction.
The set of tasks that could not get assigned by this procedure will be added to the set of shifted tasks. Now that the slices from were either reassigned or removed, we can use that space to place the slices from via the same procedure, and continue until placing the slices from . We obtain a set of at most shifted tasks that were discarded.

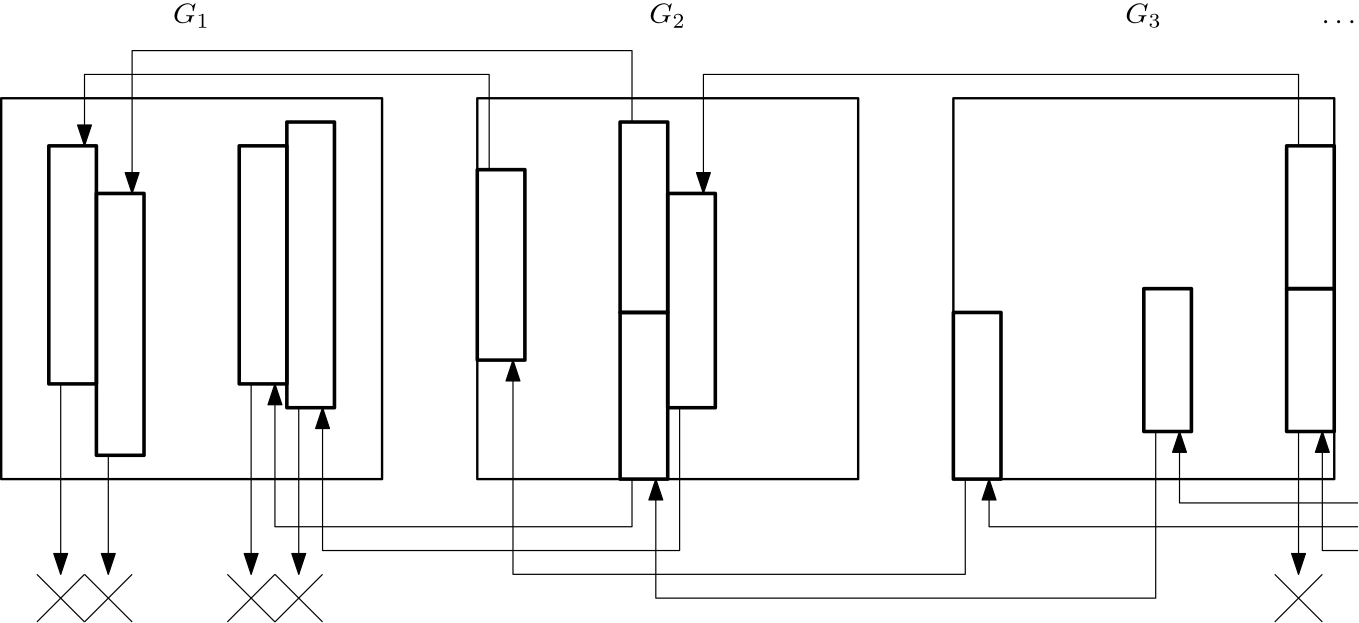
If these sets of rounding and shifted tasks have total area at most , we end here as all the requirements from the lemma would be fulfilled; otherwise, we remove the sets of rounding and shifted tasks from the initial pile (still considering them as guessed tasks, which will later be scheduled just as they originally were), and redo the procedure with the remaining tasks with respect to the width of the surviving tasks, until finding a set of rounding tasks of total area at most . Since the sets of rounding and shifted tasks from each iteration are disjoint, the procedure must end after at most iterations as the total area of the tasks is at most ; consequently, the number of guessed tasks at the end of this procedure is at most .
Let be the outcome of the aforementioned procedure. By construction, the number of possible heights in is at most , corresponding to the number of guessed tasks. We can also observe that the total area of is at most ; to see this, observe that, since every height is at least , it holds that for any , and since there are groups with exactly slices each, we can charge the total area of to disjoint sets of groups from . Thus, the total area of discarded tasks, corresponding to tasks in plus the rounding tasks, is at most . In conclusion, the obtained schedule for is feasible and has total area at least .
3.2 Computing a schedule for rounded Tall tasks
Thanks to Lemma 2 applied to , it is possible to reduce ourselves to instances where tall tasks only have a constant number of possible heights, paying a negligible price on the approximation factor. Now, we need to retrieve a schedule for tall tasks. Suppose we had already selected the tasks included in the solution. In that case, this step can be done using a result due to Dean and Goemans in the context of advertisement makespan minimization [9]. In the latter, we are given a set of tasks and a timeline as in our problem, but the goal is to schedule all the given tasks while minimizing the maximum load in the schedule. The authors show that, when tasks have heights at least (where is the optimal makespan) and have constant possible heights, the set of possible schedules can be explored in polynomial time. The following lemma presents guarantees in line with this result but also allows us to check whether a feasible schedule exists respecting the capacity constraints for a given set of tasks, which is required in our context.
Lemma 3.
Let be a set of tasks having a constant number of possible heights that can be scheduled so that each time slot has total load at most and contains a constant number of slices scheduled. Then, there exists a polynomial-time algorithm that computes a polynomial-sized set of solutions containing that solution, even if the values are not given.
Proof.
Let be the number of possible heights in the instance, and be the maximum number of slices scheduled on any time slot. Similar to the classical dynamic program for makespan minimization (see, e.g., [29]), a configuration is a vector in specifying, for each possible height, how many slices of that height are scheduled in a given time slot; in particular, the number of possible configurations is at most .
Consider now any feasible schedule for such that at most slices are scheduled into each time slot. The number of possible load configurations (i.e., vectors specifying in each coordinate how many time slots follow a given configuration) is at most , and therefore, we can efficiently enumerate all possible load configurations. To conclude, we provide a way to verify whether a given load configuration is feasible, i.e., if the tasks in can be scheduled such that the solution follows the given load configuration. To see this, we prove that the following greedy algorithm correctly decides whether a load configuration is feasible:
-
(a)
For each possible height, sort the time slots non-decreasingly according to the total load of slices of that height.
-
(b)
For a fixed height, and considering the time slots from left to right, iteratively assign a slice from a compatible task (i.e., that has not been assigned yet to that time slot) having the largest remaining width.
If a feasible schedule exists for the tasks, we prove that this procedure computes such a schedule via a simple induction on the number of time slots in the load configuration. As a base case, if there is one time slot, since there is a feasible schedule, every task must have width and hence the greedy procedure computes the solution. Consider now an instance with time slots, , where a feasible schedule exists. Consider the set of tasks whose slices are scheduled into the leftmost time slot. If these tasks have the largest widths in the instance (i.e. they are scheduled exactly as in the greedy procedure), then we can simply apply the inductive hypothesis to the remaining time slots and the remaining slices. If it is not the case, then there exists some tasks , with , such that a slice of was scheduled into the leftmost time slot but was not. Since , there must be some time slot where a slice of was scheduled into but was not, and hence we can swap them (see Fig. 3). Consequently, we can again apply the inductive hypothesis, concluding the proof.

To apply Lemma 3, we need to define precisely which tasks we want to include in our solution. The following lemma shows that we can select a set of tasks whose total area is roughly the total area of tall tasks in the optimal solution, and that admits a feasible schedule.
Lemma 4.
For any instance of the problem , and any , there exists a subset of tall tasks that can be selected in polynomial time, such that the following holds:
-
(i)
.
-
(ii)
admits a feasible schedule whose load profile is upper bounded by the load profile of .
Proof.
Let be the set of rounded tall tasks from Lemma 2. Let be the possible heights of tall tasks after rounding, and let be the sets of tasks in of height , for each , respectively. For each , let be the total width of tasks from . We will approximately guess , and then select tasks for our solution according to these widths.
We round according to the following procedure. We guess tasks from , say and consider a value of the form , with . will then be rounded down to the closest value of that form. As this requires guessing a constant number of tasks and a number that ranges from zero to , this can be done in polynomial time.
We now prove that there exists a subset of tasks satisfying the requirements of the lemma such that, for each class , their total width is at most . If , then and the proof follows. If not, consider the widest tasks in (say ), remove from the set (which is the task of smallest width out of them), and then consider the largest possible value of the form that is not larger than . Since is the task of smallest width out of the widest ones, its total area is at most , proving the claim.
Since is not known, instead of guessing it exactly we do the following: As before, we guess the widest tasks in , say , discard , and greedily complete the set until reaching total width using tasks whose width is at most that are not part of the guessed tasks. Observe that the total width of selected tasks from the group is at least . The union of the selected tasks will be our set .
For each group, suppose now that the guessed tasks are assigned as in the schedule for , and the remaining tasks are iteratively scheduled into the leftmost time slot where they fit (i.e., where there is no slice from the same task already scheduled), using the time slots where original slices of that group were scheduled. Similarly to the proof of Lemma 2, this procedure schedules all the guessed tasks, and every considered task except for at most many, and hence the total width of scheduled tasks from the group is at least
In conclusion, the total area of scheduled tasks is at least thanks to the guarantees from Lemma 2, the load profile is upper bounded by the load profile of the optimal solution restricted to tall tasks, and the set can be computed in polynomial time as required.
We can now put the pieces together to obtain our algorithm for tall tasks.
Lemma 5.
For every , there exists a polynomial time algorithm that computes a solution for tall tasks with total area at least .
Proof.
3.3 PTAS for Short Tasks
In this section, we show the second component of our approximation algorithm, which is the PTAS for short tasks. We remark that our approximation guarantee for short tasks holds even for the case of general profits, i.e., weighted advertisement placement. We consider two main ideas:
Knapsack relaxation.
We can define a relaxation of the problem through an instance of the classical one-dimensional knapsack problem. We define a knapsack instance with capacity and, for each task , we create an item whose size is and profit is . If we solve this instance, we obtain a set of tasks, say , that maximizes its total profit while maintaining its total area below . The set might not admit a feasible schedule, but it satisfies that . If we run the PTAS for knapsack due to Lawler [25] on this relaxation, we obtain in polynomial time a set of tasks satisfying that .
Least-Full (LF) algorithm.
We consider an adaptation of Graham’s list scheduling algorithm [15] for makespan minimization. The algorithm considers the tasks in any arbitrary but fixed order and iteratively places the slices of the tasks in the time slot with the lowest current load that does not have a copy of that task. The algorithm continues until a task cannot be included, or until scheduling every task in the instance.
Freund and Naor [11] prove that, if tasks obtained from the knapsack relaxation are sorted non-decreasingly by height and then scheduled according to LF, the solution obtained is -approximate even in the presence of general profits. More in detail, the set can be partitioned into three subsets such that each one of them can be feasibly scheduled according to LF; the best of the three corresponds to the desired solution. We prove now that a similar scheme leads to a PTAS for short tasks under general profits. Our procedure works as follows:
-
1.
We compute by approximately solving the knapsack relaxation restricted to short tasks.
-
2.
We sort the tasks in non-increasingly according to .
-
3.
We run the LF algorithm with respect to the previous order, and return the computed solution.
Lemma 6.
For every , the previous procedure computes a feasible schedule with profit at least for the weighted advertisement placement problem.
Proof.
Observe first that, if the algorithm schedules the whole set , we directly obtain the desired guarantee since . On the other hand, if our algorithm did not schedule all the tasks in , we use the following result due to Freund and Naor: Suppose tasks are placed according to the LF algorithm (regardless of the order in which the tasks are considered), let be the maximum height of a task considered so far. At any given moment during the assignment, it holds that for any time slots . This implies that for each pair of time slots , , and therefore the total area of the tasks included in the solution is greater than or equal to , since (otherwise, we would have enough space to include the task that does not fit) and . This already proves the claim for the case of profits being equal to the area (assuming ) because ; we will show that this works even for general profits.
Let ALG be the obtained solution. We use the previous facts to show that . Let be the tasks of sorted non-increasingly according to . Let also be the last task that ALG included. We partition ALG into groups of total area at least and at most by iteratively taking tasks until attaining total area at least . The number of groups that we obtain is at least
where the last inequality holds for every and . Let be the obtained groups, and let be the tasks in . For each , we have that ; indeed, thanks to the order of the tasks, it holds that:
where the third inequality holds since the total area of is at most , and the first and the last inequality follow from the tasks being sorted in non-increasing order according to . We now compare the total profit of and . First, we have that . Since for every , we have that , which implies that , and hence that . In conclusion,
We now have all the ingredients required to prove Theorem 1.
Proof of Theorem 1.
We partition the given instance into short and tall tasks as described in the beginning of Section 3.1, using . We then run the algorithm for tall tasks from Lemma 5 on the tall tasks, and the algorithm for short tasks from Lemma 6 on the short tasks, and return the best of the two solutions. One of them must be a -approximate solution for the problem.
4 A PTAS under Resource Augmentation
The results from Section 3 provide an almost optimal way to schedule tall tasks and also a separate way to schedule short tasks; unfortunately, although the schedule for tall tasks leaves enough space for short tasks on top, our methods do not allow to construct a solution that merges both kinds of tasks. The main obstacle comes from the fact that slices of short tasks may be small in some time slots and large in others, requiring to treat parts of the same task in different ways.
To overcome this difficulty, we describe how to obtain almost optimal solutions under resource augmentation, meaning that our algorithm may overload the time slots up to capacity , while the optimal solution cannot. In this case, as we show, it is possible to schedule short tasks on top of tall tasks via linear programming rounding techniques.
Theorem 7.
For any , there exists a -approximation for advertisement placement under resource augmentation.
Given constants , we classify the tasks as follows (see Fig. 4): A task is tall if ; a task is wide if and ; and a task is small if and .


We denote by , , and the sets of tall, wide, and small tasks in the instance, respectively. Also, we define , and to be the optimal solution restricted to tall, wide, and small tasks, respectively. As mentioned before, we select and schedule tall tasks using Lemma 5; this ensures that the total area of tall tasks in the solution is at least , and also that the load profile of the computed solution is upper bounded by the load profile of (in particular, no time slot is overloaded at the moment).
Let be the solution computed so far. To include wide tasks, we slightly adapt the classical LP rounding procedure developed by Lenstra, Shmoys, and Tardos [26] for makespan minimization on unrelated machines. Given a set of tasks that can be feasibly scheduled, this procedure computes a feasible solution that includes all the given tasks while possibly overloading the time slots by at most . Thus, we first need a way to decide what tasks to include in the solution, which will be done again by rounding the coordinates of the tasks using linear grouping. Here, an instance is horizontally segmented if each task of height and width is replaced by tasks of height and width .
Lemma 8.
For any instance of the problem , there exists a subset of wide tasks that can be selected in polynomial time, such that the following holds:
-
(i)
.
-
(ii)
horizontally segmented admits a feasible schedule whose load profile is upper bounded by the load profile of .
In what follows, we show how to prove Lemma 8. Observe first that, if is defined by at most tasks, we can guess exactly such a set in polynomial time. Thus, from now on, we assume that has more than wide tasks. We will also assume that the tasks are horizontally segmented, meaning that each task of height and width is replaced by tasks of height and width . It is not difficult to see that the optimal profit achieved with the horizontally segmented instance is an upper bound for the original optimal profit. We round up the widths of the wide tasks in the instance as follows:
-
(I)
Suppose that with . We guess a set of at most wide tasks, denoted as guessed tasks (the rest are non-guessed tasks). Out of the guessed tasks, we guess at most tasks, denoted as rounding tasks. We discard the latter.
-
(II)
The set of non-guessed tasks with a smaller index than the rounding task with smallest index is discarded.
-
(III)
For any remaining non-guessed task , round up to , , the closest width among the rounding tasks (breaking ties in favor of smaller indices).
Let be the set of non-guessed tasks whose widths were rounded according to the -th rounding task (sorted non-increasingly by width). As the following proposition shows, there exists a set of guessed tasks with a subset of rounding tasks that allow to bound the total area of discarded tasks by , while still having a feasible solution for the rounded tasks that were not discarded.
Proposition 9.
Let be a set of wide tasks, and be the output of the previous rounding procedure. There exists a set of rounded wide tasks such that::
-
(i)
The number of distinct widths in is constant.
-
(ii)
The total area of is at least .
-
(iii)
There exists a feasible schedule for horizontally segmented.
Proof.
Suppose we place all the tasks in one on top of the other, sorted non-increasingly by width. Since there is a feasible schedule for them and their width is at least , the total height of tasks in , say , is at most . From now on, we work with horizontally segmented. Starting from the widest horizontal segment in the pile, we partition them into groups of total height exactly each, except possibly for the last one, which can have a smaller height. Observe that we have at most groups. Our tentative set of rounding tall tasks from the rounding procedure will initially be defined by taking the task of smallest width from each group , with (this set may contain less than tasks due to repetitions). Observe that, at this point, the set of rounding tasks and guessed tasks is the same, and tasks with smaller index than the rounding task with smallest index are not part of , so they can be safely discarded.
We now prove that there is a feasible schedule for these (horizontally segmented) rounded tasks. Consider a feasible schedule for . Since the first group, , is discarded, we use the space due to this removal to place the horizontal segments from by simply replacing them one by one. Since the original schedule was feasible for , it must be as well for the horizontal segments in . Now that the slices from were reassigned, we can use that space to place the slices from in the same way, and continue until placing the slices from . If this set of rounding tasks has total area at most , we end the argument here as all the requirements from the lemma would be fulfilled; otherwise, we remove the set of rounding tasks from the initial pile (still considering these tasks as guessed tasks, which will later be scheduled just as they originally were), and redo the procedure with the remaining tasks with respect to the width of the surviving tasks, until finding a set of rounding tasks of total area at most . Since the sets of rounding tasks from each iteration are disjoint, the procedure must end after at most iterations as the total area of the tasks is at most ; consequently, the number of guessed tasks at the end of this procedure is at most .
Let be the outcome of the previous procedure. By construction, the number of possible heights in is at most , corresponding to the number of guessed tasks. We can also observe that the total area of is at most ; to see this, observe that, since every width is at least , it holds that for any , and since there are groups with exactly slices each, we can charge the total area of to disjoint sets of groups from . Thus, the total area of discarded tasks, corresponding to tasks in plus the rounding tasks, is at most . As argued before, the obtained schedule for horizontally segmented is feasible and has total area at least , which concludes the proof.
We now have the ingredients to prove Lemma 8.
Proof of Lemma 8.
Let be the set of rounded wide tasks from Proposition 9. Let be the possible widths of wide tasks after rounding. Let be the sets of tasks in of width , for each respectively. For each , let be the total height of tasks from . We will approximately guess , and then select tasks to include in the desired solution according to these rounded total widths.
We round according to the following procedure. We guess tasks from , say and consider a value of the form , with . will then be rounded down to the closest value of that form. As this requires guessing a constant number of tasks and a number that ranges from zero to , this can be done in polynomial time. We now prove that there exists a subset of tasks satisfying the requirements of the lemma such that, for each class , their total height is at most , by simply running the known PTAS for the one-dimensional knapsack problem [25]. For each task, we define an item of size and profit equal to , and consider a knapsack of capacity . Since has total height at most , the PTAS on the created knapsack instance will find a set of tasks with total height at least , which can be feasibly scheduled (horizontally segmented) where originally was, defining our set . Now that we have our set of wide tasks, we show how to efficiently schedule them, but possibly overloading the time slots by at most .
Lemma 10.
Let be a set of horizontally segmented tasks that can be feasibly scheduled so that each time slot has total load . There exists a polynomial time algorithm that computes a schedule for without horizontally segmenting such that, for each time slot , the total load of tasks scheduled in it is at most .
Proof.
We consider the following feasibility program for scheduling :
Here, is a binary variable encoding whether a slice of task is scheduled into time slot or not. Since horizontally segmented can be scheduled in such a way that each time slot has total load , the linear relaxation of this program is feasible.
Let be a feasible solution for the LP formulation. We can now round this solution by adapting the classical rounding scheme by Lenstra, Shmoys, and Tardos [26] (see also [9]). We construct a bipartite graph with nodes representing tasks on one side, and time slots on the other, and we have an edge from a task to a time slot if . We can assume that these edges form a forest; if there were alternating cycles, we can augment the flow in the cycle appropriately, preserving the amount assigned to any time slot, maintaining feasibility, until one of the values becomes either zero or one, breaking the cycle. The outdegree of each task must be at least since the widths are integral, implying that we can always find an alternating path with endpoints at two different time slots and , such that both of them have indegree . We can again augment the flow along this path until every pair involved becomes integral, which only increases the flow entering the endpoints of the path, by at most . In conclusion, this rounding procedure returns a feasible integral schedule that increases the load of each time slot by at most .
We now have all the ingredients required to prove Theorem 7.
Proof of Theorem 7.
Consider . By applying Lemmas 8 and 10, we can schedule wide tasks on top of in a way that the load of each time slot is at most . Let be the solution constructed so far. Consider the small tasks in any arbitrary but fixed order, which will be scheduled according to the LF algorithm, i.e., scheduling each slice into the least loaded time slot that does not contain slices of the same task, until the first time the load of a time slot becomes larger than (or until scheduling all the small tasks). If all the small tasks are scheduled, the proof is finished; if not, this means that at least time slots have total load at least , and thus the total area of tasks scheduled so far would be at least , concluding the proof of Theorem 7.
References
- [1] Micah Adler, Phillip B. Gibbons, and Yossi Matias. Scheduling space-sharing for internet advertising. Journal of Scheduling, 5(2):103–119, 2002. doi:10.1002/jos.74.
- [2] Soroush Alamdari, Therese Biedl, Timothy M. Chan, Elyot Grant, Krishnam Raju Jampani, Srinivasan Keshav, Anna Lubiw, and Vinayak Pathak. Smart-grid electricity allocation via strip packing with slicing. In WADS, volume 8037, pages 25–36, 2013. doi:10.1007/978-3-642-40104-6_3.
- [3] Alexander Armbruster, Fabrizio Grandoni, Edin Husic, Antoine Tinguely, and Andreas Wiese. On the approximability of unsplittable flow on a path with time windows. In IPCO, volume 15620, pages 29–42, 2025. doi:10.1007/978-3-031-93112-3_3.
- [4] Nikhil Bansal, Alberto Caprara, Klaus Jansen, Lars Prädel, and Maxim Sviridenko. A structural lemma in 2-dimensional packing, and its implications on approximability. In ISAAC, volume 5878, pages 77–86, 2009. doi:10.1007/978-3-642-10631-6_10.
- [5] Nikhil Bansal and Arindam Khan. Improved approximation algorithm for two-dimensional bin packing. In SODA, pages 13–25, 2014. doi:10.1137/1.9781611973402.2.
- [6] Henrik I. Christensen, Arindam Khan, Sebastian Pokutta, and Prasad Tetali. Approximation and online algorithms for multidimensional bin packing: A survey. Computer Science Review, 24:63–79, 2017. doi:10.1016/J.COSREV.2016.12.001.
- [7] Mauro R. C. da Silva, Rafael C. S. Schouery, and Lehilton L. C. Pedrosa. A polynomial-time approximation scheme for the MAXSPACE advertisement problem. In LAGOS, volume 346, pages 699–710, 2019. doi:10.1016/J.ENTCS.2019.08.061.
- [8] Wenceslas Fernandez de la Vega and George S. Lueker. Bin packing can be solved within 1+epsilon in linear time. Combinatorica, 1(4):349–355, 1981. doi:10.1007/BF02579456.
- [9] Brian C. Dean and Michel X. Goemans. Improved approximation algorithms for minimum-space advertisement scheduling. In ICALP, volume 2719, pages 1138–1152, 2003. doi:10.1007/3-540-45061-0_87.
- [10] Franziska Eberle, Felix Hommelsheim, Malin Rau, and Stefan Walzer. A tight (3/2+)-approximation algorithm for demand strip packing. In SODA, pages 641–699, 2025. doi:10.1137/1.9781611978322.20.
- [11] Ari Freund and Joseph Naor. Approximating the advertisement placement problem. Journal of Scheduling, 7(5):365–374, 2004. doi:10.1023/B:JOSH.0000036860.90818.5F.
- [12] Waldo Gálvez, Fabrizio Grandoni, Afrouz Jabal Ameli, Klaus Jansen, Arindam Khan, and Malin Rau. A tight (3/2+)-approximation for skewed strip packing. Algorithmica, 85(10):3088–3109, 2023. doi:10.1007/S00453-023-01130-2.
- [13] Waldo Gálvez, Fabrizio Grandoni, Salvatore Ingala, Sandy Heydrich, Arindam Khan, and Andreas Wiese. Approximating geometric knapsack via L-packings. ACM Transactions on Algorithms, 17(4):33:1–33:67, 2021. doi:10.1145/3473713.
- [14] Waldo Gálvez, Fabrizio Grandoni, Arindam Khan, Diego Ramírez-Romero, and Andreas Wiese. Improved approximation algorithms for 2-dimensional knapsack: Packing into multiple l-shapes, spirals, and more. In SOCG, volume 189, pages 39:1–39:17, 2021. doi:10.4230/LIPICS.SOCG.2021.39.
- [15] Ronald L. Graham. Bounds on multiprocessing timing anomalies. SIAM Journal of Applied Mathematics, 17(2):416–429, 1969.
- [16] Fabrizio Grandoni, Salvatore Ingala, and Sumedha Uniyal. Improved approximation algorithms for unsplittable flow on a path with time windows. In WAOA, volume 9499, pages 13–24, 2015. doi:10.1007/978-3-319-28684-6_2.
- [17] Fabrizio Grandoni, Tobias Mömke, and Andreas Wiese. A PTAS for unsplittable flow on a path. In STOC, pages 289–302, 2022. doi:10.1145/3519935.3519959.
- [18] Rolf Harren, Klaus Jansen, Lars Prädel, and Rob van Stee. A (5/3 + )-approximation for strip packing. Computational Geometry, 47(2):248–267, 2014. doi:10.1016/J.COMGEO.2013.08.008.
- [19] Klaus Jansen and Malin Rau. Closing the gap for pseudo-polynomial strip packing. In ESA, volume 144, pages 62:1–62:14, 2019. doi:10.4230/LIPICS.ESA.2019.62.
- [20] Klaus Jansen, Malin Rau, and Malte Tutas. Hardness and tight approximations of demand strip packing. In SPAA, pages 479–489, 2024. doi:10.1145/3626183.3659971.
- [21] Klaus Jansen and Roberto Solis-Oba. Rectangle packing with one-dimensional resource augmentation. Discrete Optimization, 6(3):310–323, 2009. doi:10.1016/J.DISOPT.2009.04.001.
- [22] Edward G. Coffman Jr., M. R. Garey, and David S. Johnson. Bin packing with divisible item sizes. Journal of Complexity, 3(4):406–428, 1987. doi:10.1016/0885-064X(87)90009-4.
- [23] Claire Kenyon and Eric Rémila. A near-optimal solution to a two-dimensional cutting stock problem. Mathematics of Operations Research, 25(4):645–656, 2000. doi:10.1287/MOOR.25.4.645.12118.
- [24] Ariel Kulik, Matthias Mnich, and Hadas Shachnai. Improved approximations for vector bin packing via iterative randomized rounding. In FOCS, pages 1366–1376, 2023. doi:10.1109/FOCS57990.2023.00084.
- [25] Eugene L. Lawler. Fast approximation algorithms for knapsack problems. Mathematics of Operations Research, 4(4):339–356, 1979. doi:10.1287/MOOR.4.4.339.
- [26] Jan Karel Lenstra, David B. Shmoys, and Éva Tardos. Approximation algorithms for scheduling unrelated parallel machines. Mathematical Programming, 46:259–271, 1990. doi:10.1007/BF01585745.
- [27] Lehilton L. C. Pedrosa, Mauro R. C. da Silva, and Rafael C. S. Schouery. Approximation algorithms for the MAXSPACE advertisement problem. Theory of Computing Systems, 68(3):571–590, 2024. doi:10.1007/S00224-024-10170-2.
- [28] Shaojie Tang, Qiuyuan Huang, Xiang-Yang Li, and Dapeng Wu. Smoothing the energy consumption: Peak demand reduction in smart grid. In INFOCOM, pages 1133–1141, 2013. doi:10.1109/INFCOM.2013.6566904.
- [29] Vijay V. Vazirani. Approximation algorithms. Springer, 2001.
- [30] Sean Yaw, Brendan Mumey, Erin McDonald, and Jennifer Lemke. Peak demand scheduling in the smart grid. In IEEE SmartGridComm, pages 770–775, 2014. doi:10.1109/SMARTGRIDCOMM.2014.7007741.