Brief Announcement:
Proximal Byzantine Agreement: Improved Accuracy for Fault-Tolerant Replicated Datastreams

Abstract
Approximate Byzantine Agreement (ABA) protocols enable nonfaulty replicas with different initial values to derive a values within a -neighborhood of each other, despite the presence of Byzantine behavior. While they give strong guarantees for this -agreement property, they tend to have weaker guarantees that the derived value is accurate with respect to some ground truth. Worse, they often have impractical requirements such as large replica sets proportional to data dimensionality, or a priori knowledge of the maximum distance between nonfaulty values.
In Stochastic Byzantine Agreement (SBA), the distribution of the nonfaulty values is the result of a stochastic process influenced by sensor measurement error or other sources of noise that affect system outputs. For these scenarios, we present Proximal Byzantine Agreement (), a stochastic Byzantine agreement protocol which infers the most likely output of replicated computation based on the proposed values observed by each replica. Unlike ABA protocols, prioritizes accuracy over agreement. accuracy is relative to the variance of nonfaulty values, yielding comparatively more accurate results for noisy data, particularly when noise is asymmetric. Our evaluations demonstrate this accuracy scales with data dimensionality, outperforming or only mildly underperforming methods that require quorums with up to more replicas and to more computation time per agreement decision, even at relatively low dimensions ( to ).
Keywords and phrases:
Byzantine fault tolerance, distributed control systems, robust statisticsCopyright and License:
2012 ACM Subject Classification:
Computer systems organization Dependable and fault-tolerant systems and networks ; Computer systems organization Sensor networksFunding:
Partial funding provided by 2025 Berkeley RDI AI & Decentralization Innovation Award.Editor:
Dariusz R. KowalskiSeries and Publisher:
1 Introduction
Reliably controlling systems and devices that interact with the physical environment is challenging in any context, but especially in edge networks. Volatile communication, power, and operating conditions demand greater fault tolerance, and edge devices and sensors are often more vulnerable to malicious manipulation than those in secure, monitored facilities. These realities complicate the coherent design of sensor data-processing pipelines, distributed control systems, and multi-agent robotics applications – scenarios that are functionally similar but operationally require ad hoc mitigation techniques to tolerate deployment conditions.
The growing demand for such systems spans consumer-facing devices such as home- automation sensors and controls, personal health monitoring devices and drug-delivery systems, and automotive telemetry and safety systems, as well as industrial and agricultural platforms for monitoring and controlling mechanical, physical, and biological processes. In all of these domains, the quality and reliability of sensor and sensor-derived data is central to effective operation. When that data is delayed, missing, or corrupted – whether from environmental noise, hardware faults, or malicious interference – the consequences can range from suboptimal performance to catastrophic, even unsafe, failures.
Despite shared characteristics, a divergence occurred between communities that prioritize agreement “regardless of what they agree upon” originally proposed by Lamport [9], and communities that also want guarantees on the accuracy of some quantity being approximated. Whereas most agreement protocols give validity [5] specifications on their output in terms of the initial values proposed by nonfaulty replicas, accuracy [12] specifications are with respect to a true quantity approximated by the outputs. Much subsequent work on approximate agreement does not explicitly consider accuracy, with some notable exceptions [1, 3] in the sensor fusion community. In all cases, relatively strong assumptions are made about nonfaulty values such as the maximum pairwise distance [10], maximum width of a containing interval [12], or the true value is contained in the intersection of ranges of nonfaulty replicas [3]. Violating these assumptions affects accuracy and can lead to arbitrary protocol failure.
This paper restores focus on the accuracy of an important subset of approximate Byzantine agreement (ABA) problems under weaker, more realistic assumptions. Since phenomena measured by sensors can often be modeled as stochastic processes [17], we define Stochastic Byzantine Agreement (SBA), a refinement of the ABA problem. In the SBA problem, “true” values are generated by a stochastic process with an unknown output distribution, and the observations of those values proposed by nonfaulty replicas are perturbed by noise drawn from an unknown error distribution. Byzantine replicas act arbitrarily, and thus their proposed values are not generated – or even effectively approximated – by any distribution. Our SBA protocol, Proximal Byzantine Agreement (), uses a novel value selection process, how replicas select outputs based on the messages they receive, that borrows techniques from robust statistics [7]. As long as a majority of these messages are stochastically distributed, the influence of arbitrarily selected values on the inference process is limited to a fixed bound.
This brief announcement reports on progress following our initial evaluation [18] of the feasibility of this value selection technique. Previously, only one-dimensional, normally distributed distributions were explored, and probabilistic protocol properties were described informally. Here we give formal, geometric definitions and theorems with rigorous guarantees, including evaluations comparing to multiple ABA protocols on multidimensional data. These evaluations indicate a surprising degree of scalability with respect to dimensionality: only minor losses in accuracy compared to ABA protocols that require more replicas and to more computation time per agreement decision, even at relatively low dimensions ( to ). Since each additional output offers more information from the unknown output distribution, our results indicate can extract more information from observations, reinforcing the tradeoff [12] between high-precision agreement and statistical accuracy.
2 Proximal agreement as a probability maximization
Replicas participating in Approximate Byzantine Agreement (ABA) protocols (e.g.,[5, 14, 19]) start with an arbitrary real value and reach an output solution satisfying two properties:
-
1.
-Agreement: all nonfaulty replicas eventually output values within of each other.
-
2.
Validity: these values are bound (in some sense) by the initial values of nonfaulty replicas.
Mahaney and Schneider [12] distinguish Inexact Agreement (IA) from classical ABA by redefining the validity property in terms of accuracy. Outputs are instead bound by their distance to a true value , which each nonfaulty replica’s initial value approximates.
Our work concerns a new class of protocols that make an additional assumption, often satisfied by the underlying data processed by IA systems. Stochastic Byzantine Agreement (SBA) protocols require that and nonfaulty are – or can be effectively approximated as being – distributed according to probability distributions. No assumptions are made about the nature of Byzantine values. The two distributions are distinct and potentially unknown, but correlated since s approximate . SBA protocols also satisfy -agreement, but in SBA is larger than the values in classical ABA protocols. This difference in -agreement is by design and unavoidable due to tradeoffs between accuracy and high-precision agreement [12]. The goals of these protocols are close enough that we argue ABA is an appropriate umbrella term, with IA and SBA refining properties 1 and 2 as described above.
The key characteristic of our SBA protocol, Proximal Byzantine Agreement (PBA), is that each replica uses the set of received values to find a quorum of values and a candidate such that would be the most likely true value if we knew that the quorum values were nonfaulty. Selecting the highest-probability conditioned on the observations in , ensures that if any (minority of) values in turn out to be faulty, then the quorum (and thus the inferred ) is at least a likely as a quorum containing only nonfaulty values. At a high level, this process is described by the probability maximization in Def. 2.1.
Definition 2.1 (Proximal Byzantine Value Selection).
For received values and quorum size , select a set from the -sized subsets of , and a value that maximizes the likelihood that is the true value given observations in .
Our chosen approximation of Proximal Byzantine Value Selection (PBVS) uses the geometric median of each as a robust estimator for the expected value of the unknown distribution of observations in , thus approximating the candidate . Below we will just use to refer to our approximation of PBVS to avoid additional notation. The geometric median [16] is well-suited for estimating the expected value of a broad class of distributions [15, 16], and remains robust even when of the samples are arbitrarily corrupted. We compare the conditional likelihoods for each and with a similarity-based approximation of conditional probabilities [2]. This is necessary for multidimensional data since the covariance matrix is unknown, but is a reasonable approach since each nonfaulty replica output is an approximation of the same underlying value.
More specifically, for each quorum , we compute its median and evaluate the likelihood using a similarity measure adapted from Blok et al. [2]. approximates the affect of the unknown covariance matrix and joint probability of on the independent probability of with an exponent to score similarity between and quorum values on a scale. We chose this approach after discovering that computing the geometric median and then approximating its likelihood is significantly faster than iteratively evaluating to find maximal values, and had almost no impact on accuracy.
2.1 Geometric properties
Approximation of a true value introduces a degree of uncertainty for systems that use those approximations to make decisions. We are unaware of any ABA protocols that estimates the uncertainty of its outputs.111In a sense, the strong assumptions of existing IA protocols [12, 4, 3] act as inputs about uncertainty. In many scenarios, it may be better to perform no action at all than to act on very uncertain data. Therefore, calculating a concrete guarantee on each output is an important feature of protocols.
A well-known result [11] is that the displacement of the geometric median of a set of nonfaulty values is bounded when up to faulty values are added to the set.
Lemma 2.2 (Theoretical maximum displacement [6, 11]).
Let , and such that with geometric medians and . Let and . Then the maximum displacement is
However, the contents of is unknown, so the bound implied by Lemma 2.2 cannot be directly calculated from the information available. Instead, Lemma 2.3 presents a computable bound guaranteed to contain the geometric median of the nonfaulty values, but is based only on the received values and the system parameters (i.e., , , and ).
Lemma 2.3 (Computable maximum displacement).
Let , and such that with and , and . Then
The computable displacement is used to compute the region guarantee for a given result. The fact that only produces outputs with region guarantees containing the true output is our instantiation of an accuracy [12] property.
Definition 2.4 (Region Guarantee).
For any set , where , define by removing the elements of furthest from . Let . The region guarantee is a -dimensional ball centered at with radius .
Lemma 2.5 (Accuracy).
For any ) containing nonfaulty and at most faulty values, let . Then and
2.2 OneShot Agreement and Termination
For this brief announcement, we describe OneShot , a protocol that prioritizes accuracy. It infers the potential distances between the true value, its output, and other replica outputs using only the messages it receives, without additional coordination. Clients can receive proposed values directly from replicas and execute our PBVS algorithm locally to select values. Like most IA protocols [3, 4, 13], but unlike other ABA protocols [5, 12, 14, 19], OneShot does not iterate to converge on a single answer. Doing so would obscure the initial values, sacrifice accuracy, and undermine the fidelity of the region guarantees.
The termination conditions are thus straightforward: OneShot requires values where , so termination for the asynchronous case requires at least replicas. Otherwise, faulty replicas could withhold values without being distinguished from nonfaulty replicas experiencing a network partition, and halt progress.
OneShot’s requirements on replica set size compare favorably to other ABA protocols (Table 1), particularly when considering its lack of dependency on data dimensionality and weak assumptions regarding the range of correct values. Unlike prior work that tend to improve accuracy with more replicas, a distinguishing characteristic of value selection is that more replicas are not required to ensure the safety or liveness properties of the system, yet still benefits from the increase in accuracy.
| Algorithm | |
|---|---|
| OneShot | |
| ABA [5] | |
| IA [12] | |
| BI [3, 4] | |
| BVC [14, 19] |
Despite the absence of inter-replica coordination or iteration, the values derived by consumers from different subsets are bounded with respect to their distance to the true expected value. This bound is in terms of the displacement properties of the geometric median discussed in §2.1, and contingent on quorum sizes representing a sufficiently large fraction of the nonfaulty replicas, in this case .
It is taken for granted in other protocols that quorums must contain at least half of all nonfaulty replicas since these protocols ensure all quorums intersect. We only make this size requirement explicit for agreement because not all instances of necessarily involve multiple consumers. For example, there is no need for agreement if a system controller is the only consumer of replica outputs, as is often the case in industrial control systems. For contrast, note that accuracy (Lemma 2.5) only requires quorum membership to be more than twice the number of faulty replicas.
Lemma 2.6 (Agreement).
For any , let , , , and . If and , then for any other subset where and , .
3 Evaluation



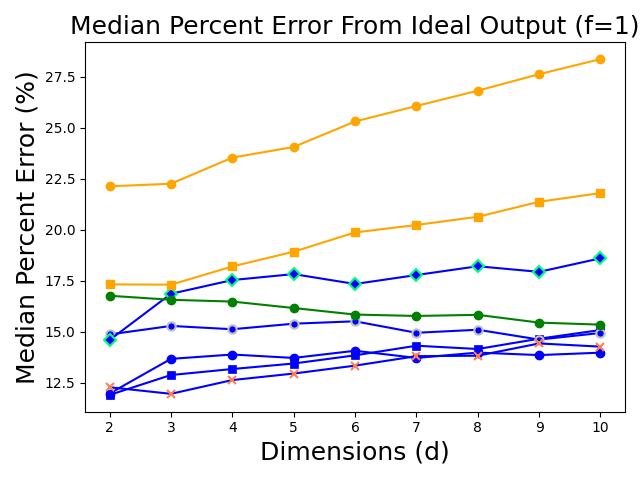
accuracy compared to baseline.
We perform repeated simulations on Chameleon Cloud [8], comparing under several quorum sizes against approximate Byzantine Vector Consensus (BVC) [19] and Brooks-Iyengar (BI) [4]. Here we present only the Byzantine attack scenario. Each trial samples -dimensional replica outputs from a random Gaussian or Exponential distribution (with a fixed, low variance) and multiplies each element-wise by a noise vector independently sampled from an error distribution with and (uniformly-sampled) standard deviation from to . We compute the agreement vector of each protocol and report the median percent error with respect to across 1000 trials.
Figure 1(a) compares results when outputs are sampled from a Gaussian distribution under an optimal Byzantine attack with . While BVC remains highly robust, achieves comparable accuracy with just (small ) outputs, versus BVC’s (large ) outputs. This indicates that at least some of BVC’s accuracy may result from its reliance on more samples, but any ABA protocol will improve in accuracy with more samples: aggregating values concentrates outputs around the true value. approaches the true value with fewer samples (i.e., replicas) and performance overhead.
In the Exponential and large setting (), Figure 1(b) shows outperforms all other protocols. In the small setting, demonstrates superior accuracy to all baselines – even in the -unknown case, where the prior distribution is estimated as Gaussian. This accuracy advantage likely stems from ’s quorum selection strategy and agreement inference method. In contrast, the benefit other protocols received from additional samples in the Gaussian case, a symmetric distribution, are tempered in the exponential case, an asymmetric distribution. The gap in accuracy suggests the averaging effect occurring in other protocols generalizes poorly to other distributions, whereas ’s more statistically-informed approach adapts more easily.
Runtime performance.
Figure 2 presents runtime benchmarks for and on a node hosted on a single Raspberry Pi Zero 2W. These results are based on repeated simulations of the , BVC, and BI protocols operating on sets of -dimensional vectors. where , and quorum sizes set to . is faster than BVC for , (with similar performance at lower ), and more than faster at , . In all , scenarios, significantly outperforms BVC ().

While BI also exhibits scalable runtime in high-dimensional settings, each replica must produce outputs with a known error range that contains the true value, and that must also intersect the ranges of all other nonfaulty nodes. If these invariants are violated by any nonfaulty replica, the system may not withstand Byzantine attack. Even without an attack, the protocol could fail to terminate.
Our empirical results against BVC reinforces that offers a compelling trade-off: it maintains competitive accuracy while substantially reducing computational cost. Beyond performance, also provides robust fault tolerance and accurate agreement with significantly fewer replica outputs. Notably, ’s minimum required number of replicas and quorum size are independent of ; in contrast to BVC, whose replica requirements scale significantly with . Under-provisioned systems instead have more uncertainty, but the amount is characterized by region guarantees. This scalable perfomance and graceful, principled degradation indicate promise for both large-scale and resource-constrained sensor-based control systems and datastream processing applications.
References
- [1] Buke Ao, Yongcai Wang, Lu Yu, Richard R. Brooks, and S. S. Iyengar. On Precision Bound of Distributed Fault-Tolerant Sensor Fusion Algorithms. ACM Computing Surveys (CSUR), May 2016. doi:10.1145/2898984.
- [2] Sergey Blok, Douglas Medin, and Daniel Osherson. Probability from similarity. In AAAI Spring Symposium on Logical Formalization of Commonsense Reasoning, pages 36–42, 2003.
- [3] Richard Ree Brooks and S. Sitharama Iyengar. Optimal matching algorithm for multidimensional sensor readings. In Sensor Fusion and Networked Robotics VIII, volume 2589. SPIE, September 1995. doi:10.1117/12.220948.
- [4] R.R. Brooks and S.S. Iyengar. Robust distributed computing and sensing algorithm. Computer, 29(6), June 1996. doi:10.1109/2.507632.
- [5] Danny Dolev, Nancy A. Lynch, Shlomit S. Pinter, Eugene W. Stark, and William E. Weihl. Reaching approximate agreement in the presence of faults. Journal of The Acm, 33(3), May 1986. doi:10.1145/5925.5931.
- [6] El-Mahdi El-Mhamdi, Sadegh Farhadkhani, Rachid Guerraoui, and Lê-Nguyên Hoang. On the Strategyproofness of the Geometric Median. In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics. PMLR, April 2023. URL: https://proceedings.mlr.press/v206/el-mhamdi23a.html.
- [7] Peter J. Huber and Elvezio M. Ronchetti. Robust Statistics. Wiley, 2011.
- [8] Kate Keahey, Jason Anderson, Zhuo Zhen, Pierre Riteau, Paul Ruth, Dan Stanzione, Mert Cevik, Jacob Colleran, Haryadi S. Gunawi, Cody Hammock, Joe Mambretti, Alexander Barnes, François Halbach, Alex Rocha, and Joe Stubbs. Lessons learned from the chameleon testbed. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC ’20). USENIX Association, July 2020. URL: https://www.usenix.org/conference/atc20/presentation/keahey.
- [9] Leslie Lamport. The weak Byzantine generals problem. Journal of the ACM, 30(3), 1983. doi:10.1145/2402.322398.
- [10] Leslie Lamport and P. M. Melliar-Smith. Byzantine clock synchronization. In Principles of Distributed Computing (PODC), 1984. doi:10.1145/800222.806737.
- [11] Hendrik P. Lopuhaa and Peter J. Rousseeuw. Breakdown Points of Affine Equivariant Estimators of Multivariate Location and Covariance Matrices. The Annals of Statistics, 19(1), March 1991. doi:10.1214/aos/1176347978.
- [12] Stephen R. Mahaney and Fred B. Schneider. Inexact agreement: Accuracy, precision, and graceful degradation. In Principles of Distributed Computing (PODC). ACM Press, 1985. doi:10.1145/323596.323618.
- [13] Keith Marzullo. Tolerating failures of continuous-valued sensors. ACM Transactions on Computer Systems, 8(4), November 1990. doi:10.1145/128733.128735.
- [14] Hammurabi Mendes and Maurice Herlihy. Multidimensional approximate agreement in Byzantine asynchronous systems. In Proceedings of the Forty-Fifth Annual ACM Symposium on Theory of Computing. ACM, June 2013. doi:10.1145/2488608.2488657.
- [15] Stanislav Minsker. Geometric median and robust estimation in Banach spaces. Bernoulli, 21(4), November 2015. doi:10.3150/14-BEJ645.
- [16] Stanislav Minsker and Nate Strawn. The Geometric Median and Applications to Robust Mean Estimation. SIAM Journal on Mathematics of Data Science, 6(2), June 2024. doi:10.1137/23M1592420.
- [17] Emanuel Parzen. Stochastic Processes. Dover Books on Mathematics. Dover Publications Inc., 2015.
- [18] Roy Shadmon and Owen Arden. Enhancing accuracy in approximate byzantine agreement with bayesian inference. In 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks - Supplemental Volume (DSN-S), 2025. doi:10.1109/DSN-S65789.2025.00064.
- [19] Nitin H Vaidya and Vijay K Garg. Byzantine vector consensus in complete graphs. In Proc. of the 2013 ACM Symposium on Principles of Distributed Computing, 2013.