Smoothed Analysis of Dynamic Graph Algorithms

Abstract
Recent years have seen significant progress in the study of dynamic graph algorithms, and most notably, the introduction of strong lower bound techniques for them (e.g., Henzinger, Krinninger, Nanongkai and Saranurak, STOC 2015; Larsen and Yu, FOCS 2023). As worst-case analysis (adversarial inputs) may lead to the necessity of high running times, a natural question arises: in which cases are high running times really necessary, and in which cases these inputs merely manifest unique pathological cases?
Early attempts to tackle this question were made by Nikoletseas, Reif, Spirakis and Yung (ICALP 1995) and by Alberts and Henzinger (Algorithmica 1998), who considered models with very little adversarial control over the inputs, and showed fast algorithms exist for them. The question was then overlooked for decades, until Henzinger, Lincoln and Saha (SODA 2022) recently addressed uniformly random inputs, and presented algorithms and impossibility results for several subgraph counting problems.
To tackle the above question more thoroughly, we employ smoothed analysis, a celebrated framework introduced by Spielman and Teng (J. ACM, 2004). An input is proposed by an adversary but then a noisy version of it is processed by the algorithm instead. This model of inputs is parameterized by the amount of adversarial control, and fully interpolates between worst-case inputs and a uniformly random input. Doing so, we extend impossibility results for some problems to the smoothed model with only a minor quantitative loss. That is, we show that partially-adversarial inputs suffice to impose high running times for certain problems. In contrast, we show that other problems become easy even with the slightest amount of noise. In addition, we study the interplay between the adversary and the noise, leading to three natural models of smoothed inputs, for which we show a hierarchy of increasing difficulty stretching between the average-case and the worst-case complexities.
Keywords and phrases:
Dynamic graph algorithms, Smoothed analysis, Shortest pathsFunding:
Ami Paz: Supported by ANR project DIDYA (ANR-25-CE48-0897).Copyright and License:
2012 ACM Subject Classification:
Theory of computation Dynamic graph algorithmsEditor:
Shubhangi SarafSeries and Publisher:
1 Introduction
We study dynamic graph algorithms – data structures for handling graphs that undergo changes. The input is composed of an initial -node graph, followed by a sequence for edge changes (addition or removal) and queries. The goal is to maintain enough information on the graph in order to promptly answer a predetermined query (e.g., is the graph connected, or how many paths of length connect two predefined nodes).
Recent years have seen a large body of work regarding lower bounds for dynamic graph algorithms. One line of work concerns unconditional lower bounds [31, 4, 24, 29]; for example, deciding the connectivity of a dynamic graph (i.e. whether the graph is connected) requires time per update provided the query time is constant [29]. Another celebrated line of work proves polynomial conditional lower bounds [16, 1, 30, 9, 32, 21]; for example, even the seemingly simple problem of counting paths of length 3 between two predefined nodes and (henceforth, - -paths) requires time per update111That is, cannot be solved in time per update, for any constant unless queries take roughly quadratic time [16], assuming the OMv conjecture (see Section 4). Similarly to other algorithmic models, it is natural to ask whether known results in worst-case analysis222In the literature of dynamic graph algorithms, worst-case running time is sometimes contrasted with amortized running time. Here and all throughout, worst-case simply refers to an adversarial input, as opposed to a uniformly random (average-case) input or a smoothed input. encapsulate inherent impossibilities, or just superficially allow for pathological yet unrealistic examples.
Preceding the advances in lower bound techniques, a couple of early works proposed algorithms specialized for distributional inputs of restricted form, with the number of edges (the graph density) playing a crucial role. In [28], the input sequence is assumed to be entirely stochastic (no adversarial choices) and follow simple rules to ensure a predefined density. In [2], an adversary determines ahead of time which steps will add an edge and which will remove one, but the choice of edges to add or remove is made uniformly at random. Consequently, the graph in each round is distributed uniformly over all graphs of a given density, a fact that is crucial in the analysis.
Following advances in lower bound techniques for dynamic graph algorithms (and for fine-grained complexity in general), a recent work [17] revived the average-case analysis of dynamic graph algorithms, offering upper and lower bounds for subgraph counting problems under uniformly random inputs. For example, it shows that - -paths can be counted with update and query times on such inputs, while maintaining the number of such paths of length requires either time per update or roughly quadratic time per query. Note that some classical problems in the field, such as connectivity, are trivial for a uniformly random input: one can blindly answer each query positively, since a random graph is connected w.h.p.
These results point to the fragility of existing lower bounds, but they only apply with very little adversarial control over the input. In our work, we strive to capture input models in which the adversary has more, but not perfect control. In particular, we are led by the following question.
How robust are lower bounds for dynamic graph algorithms?
To address this question, we apply smoothed analysis, a celebrated theoretical framework introduced by Spielman and Teng [35, 36]. In this approach, a smoothed input is created by considering an adversarial input and then perturbing it by adding random noise; the complexity is computed with respect to the smoothed input (e.g., on expectation). Smoothed analysis was applied to different types of inputs; when used on graphs, a random perturbation is applied to an adversarially-chosen graph by independently flipping the (in)existence of each edge with a certain probability [23, 10, 22]. A more recent line of work applied smoothed analysis to a graph-based computational model closer to ours called dynamic networks, where the computation also occurs in rounds (note that this is a model of distributed computation, while ours is centralized). There, each round is executed with an entirely new communication graph, and a smoothed input is simply defined by perturbing each such graph independently as above [8, 26, 7].
We continue the conceptual line of applying random perturbations. In dynamic graph algorithms each round consists of a single edge change, which is too subtle to invoke noise through a global perturbation as in the aforementioned cases. Instead, we apply smoothing per round: with some probability and independently of other rounds, we replace the adversarial edge with a uniformly random edge. Over many changes, this accumulates to a global perturbation, naturally extending previous graph smoothing models. This approach yields diverse input models and results.
In addition to its theoretical merits, smoothed analysis is often argued to be a realistic model of inputs. This applies for dynamic graphs as well as to any computation model, since inputs are prone to minor perturbations before being processed (e.g., due to communication failures or human errors). That is, even if (due to chance or malicious intentions) the intended input should impose high running times, it is well-incentivized to analyze the de facto performance of an algorithm assuming a perturbed version of the input is processed instead (i.e., a smoothed input).
1.1 Smoothed dynamic graphs
We consider fully dynamic graphs with a fixed set of nodes and changing edges. The input consists of the edges of an initial graph, followed by a sequence of edges to be flipped. The complexity of a dynamic graph algorithm is measured by the time it needs for processing the initial graph, the time for processing an edge change, and the time for answering a query.
We next define a -smoothed input, for a parameter , which we name the oblivious flip adversary model of smoothing. First, the adversary fixes an initial graph and a sequence of edge flips. The initial graph is smoothed as follows: each node pair remains consistent with the adversarial choice with probability , and otherwise re-sampled (uniformly from ). Then, each edge flip remains unchanged with probability , and otherwise re-sampled uniformly from . Clearly, when the process coincides with an average-case (uniformly random) input, while for it results in the standard adversarial (worst case) input.
Study cases.
Smoothed analysis can be relevant to any problem presenting a gap between the worst-case and average-case complexities. We consider two classes of such problems: counting small subgraphs, and deciding certain graph properties. Interestingly, the different classes exhibit fundamentally different smoothed complexities as a function of , the fraction of adversarial changes.
| Problem | Average case () | Smoothed case ( const.) | Worst case () | |||
|---|---|---|---|---|---|---|
| - 3-paths | [17] | , | (This work) | , | [16], [14] | |
| Connectivity | (This work) | (This work) | , | [29],[18] | ||
Two examples are depicted in Table 1 for constant values of . The complexity of counting - -paths increases quickly with , e.g., for all values the complexity is asymptotically identical to the worst-case (). In contrast, the complexity of connectivity remains as in the average case () for any constant ; e.g., it is constant for any . This already exemplifies different behaviors in terms of noise robustness: the hardness of counting subgraphs hinges on a small set of adversarial edges and therefore persists even with a lot of randomness, while the decision problems we consider concern with global properties, and even a small amount of noise guarantees that a blind positive answer to all queries is correct w.h.p.
A smooth transition.
A recent work on average-case complexity [17] focuses on counting small subgraphs. Perhaps the strongest message in it is that some problems, such as counting - -paths, are hard not only in the worst-case but also on average. In contrast, counting - -paths is easy even in the worst-case (that is, solvable with constant update and query times). Our focus is the third option presented: for a few problems, including counting - -paths and - -paths, there is a gap: these problems can be solved quickly in the average case, although they admit strong (conditional) lower bounds in the worst-case.
For constant , we show that counting - -paths and - -paths are as hard as the worst case and require linear update time. More interestingly, for sub-constant , we show that both can be solved with update time and constant query time, while time per update is necessary even if we allow almost quadratic query time. That is, the complexity linearly depends on , the fraction of adversarial changes, as stated in Table 2. In particular, the problem is as easy as the average case for very small values of (e.g., ), but becomes asymptotically as hard as the worst case already with , with a gradual transition between the two.
1.2 Models of smoothing
Smoothed analysis was originally introduced for studying the simplex algorithm, where the inputs are continuous and the added noise is Gaussian. The field has greatly evolved since: first, it is now typical to analyze the complexity of a computational problem, rather than that of a specific solution (algorithm), leading to more robust results. Second, the model of random noise was adjusted to discrete inputs, which are common throughout computer science. Lastly, the framework has also been applied to several different computational models, each posing its own unique challenges.
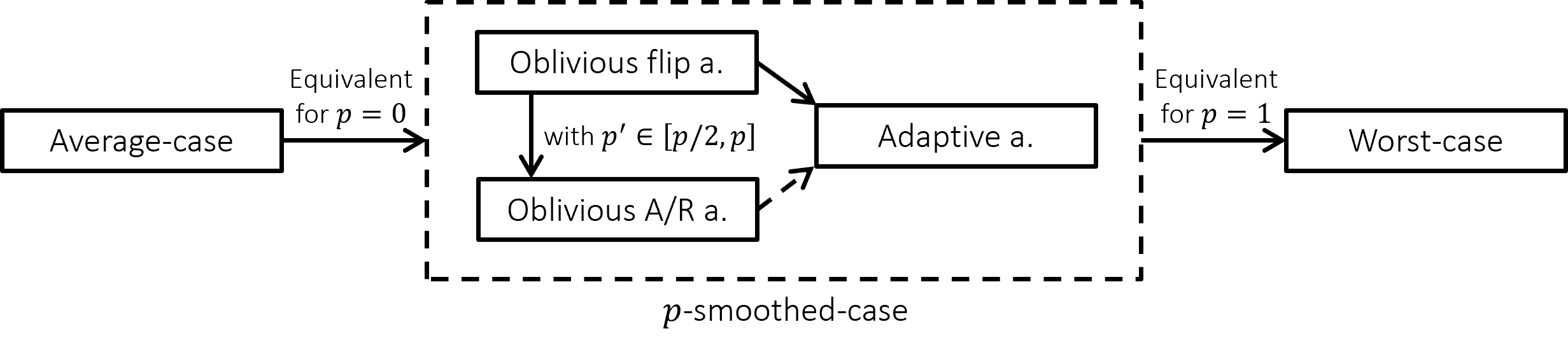
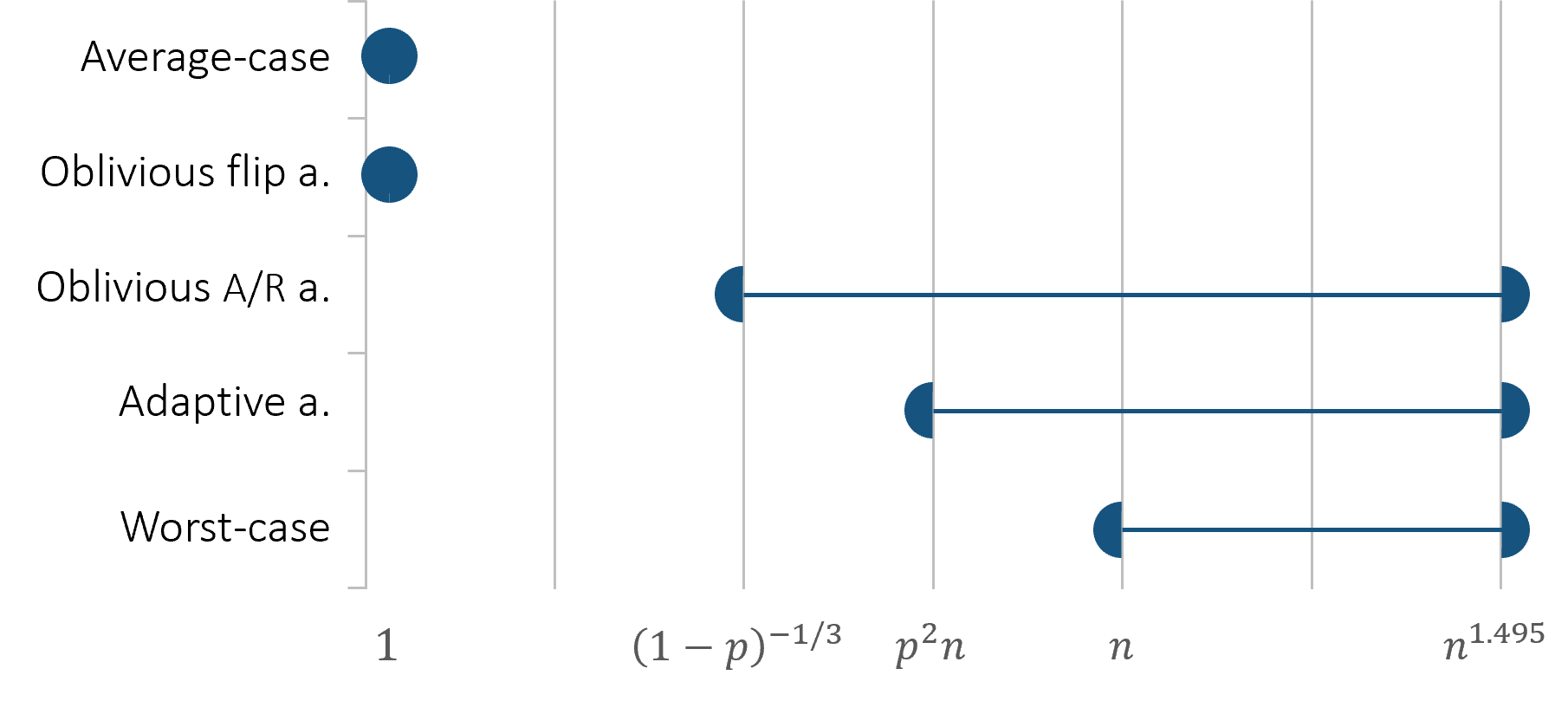
In our case, the inputs are discrete and arrive in an online manner. This gives rise to several natural models of smoothing, differing in the adaptivity of the adversary to the noise and in the way changes are encoded. In the following we present three variants of -smoothed inputs: oblivious flip adversary, oblivious add/remove adversary, and an adaptive adversary. Each model constitutes a different intermediate model between worst-case and average-case, and the relations between them is depicted in Figure 3. In Figure 5 we exemplify how the complexities of concrete problems increase differently as we transition from easier to harder models of input.
| Problem | Average case | Smoothed case | Worst case | |||
|---|---|---|---|---|---|---|
| - 2-paths | [17] | |||||
| - 3-paths | [17] | , | (This work) | , | [16], [14] | |
| - 4-paths | [17] | , | (This work) | , | [16] | |
| - 5-paths | [17] | |||||
1.2.1 Oblivious adversaries
Operation types in worst and average cases.
A change in a dynamic graph can be seen as choosing a potential edge and flipping it, or as choosing a potential edge and whether to add or to remove it. In the typical worst-case analysis, both views coincide: an algorithm can always check the edge’s status in time and do nothing if it remained unchanged, so an adversary will never choose to leave an edge unchanged. Hence, worst-case complexity does not depend on the operation type. Prior work concerning average-case complexity does not address the relation between flip and add/remove operations. In the full version, we show that up to constant factors the average-case complexity of any problem is also independent of the operations’ encoding.
Operation types in smoothed analysis.
We have already described the oblivious flip adversary, which chooses a sequence of edges to flip, and then some of these edges are re-sampled uniformly. The oblivious add/remove adversary is similarly defined, but instead of edges to flip, it chooses edges to add or remove before some of its operations are replaced by random ones.
A priori, one might suspect that an oblivious add/remove adversary is stronger than an oblivious flip one, as the former can, e.g., fixate on certain edges and persistently remove them. But one might also suspect the opposite, as an oblivious flip adversary is guaranteed to make a change at each round, while an add/remove adversary might “waste” rounds by trying to add an existing edge or remove a missing one. As it turns out, the first intuition is true: if is high enough, an add/remove adversary can simulate a hard case instance on a small subgraph, which we use in order to prove lower bounds for it. Furthermore, using a proxy model with lazy flips we show that the oblivious add/remove adversary is always at least as strong as the flip one: the -smoothed complexity in the oblivious flip model is not higher than the -smoothed complexity in the oblivious add/remove model, for some .
1.2.2 Adaptive adversary
Another issue that emerges when defining smoothing models is adaptivity to the noise. That is, can an adversary disrupt the algorithm even more if it knows the noisy input that was actually fed to the algorithm in previous rounds, rather than only its intended input?333One could consider an even stronger, “fully adaptive” adversary, that also sees the inner state of the algorithm (which includes the noise from previous rounds). Trivially, all our lower bounds apply to such an adversary as well. As all our upper bounds for the adaptive model are deterministic, they also apply against such an adversary. Similar distinctions were recently made in smoothed analysis of dynamic networks [26] and online learning [13].
In our case, at each round the adaptive adversary chooses a new edge to change, with the full knowledge of previous changes made, including the noisy ones, and thus the current state of the graph. We show that this is sometimes enough in order to cause much slower running times, separating the oblivious and the adaptive smoothed models. As in the worst case, an adaptive adversary never asks to add an existing edge or to remove a non-existing one, thus defining it with flip operations or with add/remove ones makes no difference.
Queries.
Queries are part of the input, and are sometimes even crucial for devising worst-case lower bounds, especially for problems where queries are parametrized. This is the case, e.g., in the lower bound for -connectivity [29], where queries are made with parameters and ask whether the nodes and are currently in the same connected component. Hence, parameterized queries could also be studied in a smoothed manner (and in the average-case), yet the problems studied here have no parameterized queries and the issue is left for future work.
1.3 Main results
Table 4 compares our results to known results in average-case and worst-case models, focusing on update times of algorithms with constant query times. We discuss these results below.
1.3.1 Decision problems
We consider several decision problems, such as connectivity and bipartite perfect matching (deciding whether a bipartite graph contains a perfect matching). These are trivial to solve on a random static graph since they hold w.h.p. In the full version we point out that these hold w.h.p. also at each round of an average-case dynamic graph, and are thus also easy to decide in this setting. We extend this argument to -smoothed dynamic graphs with an oblivious flip adversary, show it holds even with very little randomness ( being almost ), and thus reach a trivial constant-time algorithm in this setting as well. Specifically, we show that the random perturbation of the initial graph guarantees the first (polynomially many) graphs in the sequence hold such properties with a polynomially small error, allowing for a trivial “yes” answer. To deal with longer sequences of changes, we argue even more randomness affects the later rounds, and each graph now holds the desired properties with only an exponentially small error. Despite the simple intuition, the formal argument here is not completely straightforward, as the graph at each round is in fact statistically far from a uniformly random graph (e.g., the parity of the number of edges distinguishes the two).
Theorem A (informal).
For any , connectivity and bipartite perfect matching can be decided in constant update and query times under the oblivious flip adversary.
This theorem might raise the question whether the oblivious flip adversary has any power at all, or does it coincide with the average-case complexity. We later separate the models by showing they induce different complexities for subgraph counting problems.
While the trivial “yes” algorithm works well for bipartite perfect matching with an oblivious flip adversary, it fails for the stronger adversaries – oblivious add/remove adversary, and adaptive adversary. To see this, consider an adversary that repeatedly removes all the edges touching a fixed node; if is relatively large, this adversary will manage to isolate the node at least in some of the rounds, rendering the trivial algorithm wrong.
We formalize this intuition and prove lower bounds using a new embedding technique, a type of worst-case to smoothed-case reduction, which might also be applicable in other settings of smoothing of graphs. The adversary focuses on a small set of nodes and controls the induced subgraph on these nodes, as well as its connections with the rest of the graph. It embeds a worst-case lower bound graph on these nodes, such that the decision on the entire graph hinges on the -node subgraph.
An adaptive adversary can embed a worst-case construction for bipartite perfect matching on nodes: between every two designated queries, it changes the internal structure of the subgraph to be as in an -node worst case, and in parallel “fixes” any random edge change that touches these nodes. This results in a polynomial lower bound on the update time of bipartite perfect matching.
Surprisingly, a similar strategy works for the oblivious add/remove adversary, even though it is not aware of the random changes. This requires larger values of and assures a control of a smaller subgraph, but establishes a polynomial lower bound on the update time for this model.
| Problem | Average case | Oblivious flip a. | Oblivious AR a. | Adaptive adv. | Worst case model | |||||
| Small subgraph counting | ||||||||||
|
[17] | , | , | [16], [14] | ||||||
|
[17] | , | , | [16] | ||||||
|
[17] | , | , | [16] | ||||||
|
[17] | , | , | [17] | ||||||
| Other key problems | ||||||||||
|
– | , | [29],[18] | |||||||
|
, | [16], [33] | ||||||||
Theorem B (informal).
For any , there is no algorithm for bipartite perfect matching under an adaptive adversary with and for any , unless the OMv conjecture fails.
If for a constant , then there is no algorithm for bipartite perfect matching under an oblivious add/remove adversary with and for any unless the OMv conjecture fails.
By choosing the best for a given value of , Theorem B implies that there is no algorithm under the oblivious add/remove model with running times and .
1.3.2 Counting small subgraphs
Four subgraph counting problems were shown to have constant average-case update time [17], but worst-case update time. These problems are counting - -paths, - -paths, cycles of length through a fixed node ( triangles), and cycles of length through a fixed node ( -cycles). We establish that their -smoothed update time is essentially identical across all three smoothed models (Figure 5(a)). In the full version we present simple algorithms (a la [17]) that achieve expected update time even with an adaptive adversary (the strongest adversary). Roughly speaking, a change to an edge that touch (or ) is “expensive” – it affect many short paths starting from (or ) and thus results in an update time; other changes take only time to process. Expensive changes occur at random only of the time, but an adversary (of any type) can perform only them, resulting in probability for an -update time change, and an expected update time overall (which translates to the same amortized update time).
Theorem C (informal).
There is an algorithm for counting - -paths, - -paths, triangles and -cycles, with (expected) and under any -smoothing model.
Substituting in the theorem gives a worst-case algorithm with update time. This improves upon the state of the art for - -paths [6] and 4-cycles [14].
In the full version we complement these upper bounds by almost-matching conditional lower bounds on the update time (see Section 4 for an overview). Specifically, we show an lower bound on the update time, for any , that applies even to an oblivious flip adversary (the weakest one). This is achieved by a series of reductions, starting from the OMv conjecture. This part is the most technically involved in this work, and we discuss it further in Section 4.
Theorem D (informal).
Any algorithm for the problems from Theorem C must satisfy
for any , under any -smoothing model, unless the OMv conjecture fails. Specifically, no algorithm can simultaneously have , , and .
This completes the picture for - -paths and the transition between and (see Table 2), showing how the complexity escalates with both the path length and the degree of adversarial control (parameter ).
1.3.3 Hierarchy between smoothing models
While all our models coincide with the worst-case model at and an average-case input at , we show a hierarchy among the smoothing models for different regimes of . The adaptive adversary can be defined with either operation type, and can disregard the additional information it is privy to, making it at least as strong as both its oblivious counterparts. The oblivious add/remove adversary can simulate the oblivious flip adversary (while using ). This induces a (non-strict) hierarchy between the models (Figure 3). We next discuss separation results for these models.
For some problems, such as counting small subgraphs, the three smoothing models coincide with one another (Figure 5(a)): they all admit an algorithm (Theorem C) and a conditional lower bound (Theorem D). These bounds separate the smoothing models from the worst case for and from the average case for , for any constant .
For other problems the three smoothing models demonstrate separations, i.e., different complexities for the same problem. This is the case with perfect bipartite matching (Figure 5(b)): under an oblivious flip adversary with , the problem admits a trivial “yes” algorithm since the graph contains enough random edges at all times (Theorem A). In contrast, an adaptive adversary can embed a worst-case lower bound construction within a small set of nodes, leading to a polynomial lower bound of for the problem (Theorem B). This separates the oblivious flip adversary from the adaptive one for almost any value of , e.g., for .
The more surprising separation is between the oblivious flip adversary and the oblivious add/remove one, as operation types have no effect on the complexity in all other regimes (worst-case, average-case, and adaptive smoothed model). Using our embedding technique, Theorem B gives a super-constant lower bound on the update time of bipartite perfect matching when . This separates the two oblivious models, e.g., when .
Finally, we conjecture that the oblivious add/remove adversary is strictly weaker than the adaptive adversary, but this is left unresolved for the moment.

2 Related work
2.1 Dynamic graph algorithms
Dynamic graph algorithms constitute a deep and well-studied research topic, as was recently presented in the thorough survey of Hanauer, Henzinger and Schulz [15]. The most recent dynamic algorithm for connectivity is by Huang, Huang, Kopelowitz, Pettie and Thorup [18], and has amortized update time and time per query. Small subgraph counting was recently studied by Hanauer, Henzinger and Hua [14], who showed, e.g., that counting - -paths and -triangles (triangles through a given node ) can be done with and constant query time. Kara, Nikolic, Ngo, Olteanu and Zhang [19] studied databases that support enumeration of triangles in trinary relations, and their work implies triangle counting in dynamic graphs with , and .
Pătraşcu and Demaine [29] proved the first unconditional lower bound for dynamic graph algorithms, focusing on connectivity problems in undirected graphs. One of their results asserts that there is no dynamic algorithm for deciding whether the graph is connected with a constant query time and amortized time, a result that remains the best known to date. Some follow-up works [31, 4, 24] considered, e.g., the case of parameterized queries (querying whether two given nodes are in the same connected component) and directed graphs.
Following a line of work on conditional lower bounds in dynamic graphs [1, 30, 9, 32, 21], which used several different conjectures, Henzinger, Krinninger, Nanongkai and Saranurak [16] introduced the OMv conjecture as a unified conjecture. They showed, e.g., that -triangle detection, bipartite matchings and bipartite vertex cover cannot be done with polynomial preprocessing time, and , for any and even amortized and randomized, unless the OMv conjecture is false. The main focus of the works until this point was on worst-case analysis, and average-case analysis was rarely applied, as described next.
2.2 Beyond worst-case analysis of dynamic graph algorithms
The first to study average-case complexity of dynamic graph algorithms were Nikoletseas, Reif, Spirakis and Yung [28]. They consider an initial empty graph, a phase of addition of random edges, and then a phase where random edges are added or remove with equal probabilities. In this setting, they present an algorithm for -connectivity, i.e., where a query includes a pair of nodes and has to determine if they are in the same connected component.
Following this, Alberts and Henzinger [2] defined the “restricted randomness” model. To this end, they note that each change consists of a type (add or remove) and a parameter (which edge to add or to remove). In their model, an adversary chooses a sequence of types (add or remove) for the changes, and then the parameter (edge) of each change is chosen uniformly at random from the relevant set (existing edges for a remove operation, node-pairs without edges for an add operation). They show that several problems have better amortized time complexities in the restricted randomness model compared to the best worst-case bounds known at the time (almost no lower bounds where known at the time). The problems considered include connectivity and its variants (edge and node connectivity), maximum cardinality matching, minimum spanning forest, and bipartiteness.
Indeed, one could see this model as an average-case model, but we prefer to use this term only for uniformly random inputs (as in [28, 17]). It can also be seen as a smoothed analysis model, though without the ability to parameterize the amount of randomness.
As this model consists in an adversary and a random process, it should not come as a surprise that both an oblivious adversary and an adaptive one can be considered in this setting. Here, an adversary that chooses the sequence of types in advance is called an oblivious one, and an adversary that can choose each type according to the outcome of the random process so far is an adaptive one. These variants are not equivalent: for example, an adaptive adversary can make sure that all the -edge graphs in the sequence are connected (by adding an -th edge to an -edge graph only if it is connected), while with an oblivious adversary every -edge graph has equal probability, and most of them are not connected. The distinction between adversaries is not made in [2], but the proofs use the fact that each graph has equal probability (conditioned on the number of edges), thus the model there is oblivious.
The average-case complexity of dynamic graph algorithms was disregarded for decades, until recently Henzinger, Lincoln and Saha [17] approached it again with new tools. They studied subgraph counting problems, presented some simple algorithms inspired by [2], and focused mainly on proving conditional lower bounds. Their proofs use ideas from fine-grained complexity [16], and specifically lower bounds for average-case complexity in this setting [5, 3]. For some problems, such as counting - -paths, they show that the average-case complexity cannot be better than the worst-case one (up to an factor), while for others, such as - -paths, they prove a big gap exists. As smoothed analysis lie between the worst case and the average one, we focus the current work only on problems of the last type, where a gap exists. Some of our lower bound proofs use techniques from [17]; for example, while they do not give a lower bound for - -paths (since it is easy in the average case) we give a lower bound for this problem in the smoothed case by extending the technique they used for proving a lower bound for - -paths.
2.3 Smoothed analysis in different models
Smoothed analysis was introduced by Spielman and Teng [35] in relation to using pivoting rules in the simplex algorithm. Since then, it have received much attention in sequential algorithm design. In particular interest to us are smoothed analysis results for static graphs [23, 10, 22] and dynamic networks [8, 26, 11, 7], which we use as inspiration for our model of noise.
In recent years, smoothed analysis was also applied in settings of a repeated game, where inputs are chosen successively. These include dynamic networks, population protocols [34] and online learning [12, 13]. The effect of the adversary’s adaptivity was first studied with regard to information spreading in dynamic networks [26], which is shown to be polynomially slower when the adversary is adaptive compared to an oblivious adversary. The adaptivity question was also studied in the context of online learning [13], and a handful of problems were shown to have the same smoothed complexity whether the adversary is adaptive or oblivious. From these, the dynamic networks works are the most relevant to ours, as they defined similar smoothing models. Their results, however, focus on round complexity and not computation time, and thus are incomparable with ours.
3 Preliminaries
We use for the set , and to denote the symmetric difference between two sets. denotes the number of edge changes in the dynamic graph.
3.1 Defining smoothed dynamic graphs
We extend the definition of a dynamic graph to the case where some updates are chosen at random while others are adversarial. While we explore variants on this model, the basic definition is for the adaptive flip adversary:
Definition 1 (-smoothed dynamic graph, adaptive).
A -smoothed dynamic graph with an adaptive adversary is a dynamic graph created by the following random process.
-
Initially, is proposed by an adversary. For each node-pair , with probability it is included in according to , and with probability it is re-sampled uniformly, i.e., included in as an edge with probability .
-
At step , a node-pair is proposed by the adversary. With probability this remains unchanged, and with probability it is discarded and a new is chosen uniformly at random from . The new graph has edge set .
We also consider oblivious adversaries, that fix all their choices ahead of time, but then in execution each choice is replaced by a random choice with probability . In this model we allow for either a flip adversary or an add/remove adversary:
Definition 2 (-smoothed dynamic graph, oblivious).
A -smoothed dynamic graph with an oblivious adversary is a dynamic graph created by the following random process.
-
An adversary proposes an initial graph and a sequence of changes, where each change consists of a node-pair . An add/remove adversary also chooses an action : add or remove.
-
For each node-pair , with probability it is included in according to , and with probability it is re-sampled uniformly, i.e., included in as an edge with probability .
-
At step , randomly choose and act accordingly:
-
–
if : use the edge . For a flip adversary, flip it, and the new edge set is . For an add/remove adversary use action and accordingly the resulting edge set is either or .
-
–
if : an edge is chosen uniformly at random from , and the new graph has the edge set .
-
–
Note that a graph created by this process can also be thought of as a graph created step by step as in the adaptive adversary case, but by an adversary (flip or add/remove) that does not see any of the random choices in the initial graph and previous steps.
The initial graph.
Smoothing the initial graph is crucial for the model to extrapolate between worst-case and average-case inputs, but it seem to make little difference in all our results. Our algorithms sometime assume an adversarial initial graph (that is, their analysis does not use the smoothing of the initial graph). Our lower bounds rely on a uniformly random initial graph , using the following simple observation:
Observation 3.
The adversarial strategy that proposes an initial graph uniformly at random results in a smoothed initial graph which is uniformly random as well. This strategy can be employed by any type of adversary and any parameter .
Restricted dynamic graphs.
In Section 4, we consider a variant where the graph edges are restricted to a set of potential edges. In this model all changes, both random and adversarial, as well as the initial graph , are on instead of the entire set .
We particularly focus on -partite graphs, defined as follows.
Definition 4 (-partite graph).
Fix a simple graph on node set , and consider a graph on node set . We say that is an -partite graph with a mapping if any edge in is mapped to an edge in , i.e. if then .
If all the graphs of a dynamic graph on are -partite, we say is -partite. In this case we use to denote the set of edges that are allowed in , i.e.
For example, if is composed of two nodes and a single edge and is a -partite graph for some , then is bipartite. In some cases we describe on a node set with parts, calling it -partite (where has nodes). In these cases and are implicit for ease of presentation. For example, in Section 4 we discuss -partite graphs where uses node set . It is then clear from context that is fixed ( as well), and is a -path () graph: .
For a partition of the node set of , we naturally categorize edges and longer paths using the different parts. For example, in a general graph on sets of nodes there could be many edge types, but if the graph is -partite (with the mapping above) then only edges of types exist and -paths from to are all of type .
3.2 Properties of the Poisson distribution
Our proofs use probabilistic tools extensively. For the distance between two distribution over the same domain we use the well-known statistical distance (sometimes called total-variation distance). We make an extensive use of the Poisson distribution and more importantly the Poissonization technique (see, e.g., [27, Section 8.4]). We use for the Poisson distribution with parameter and sometimes for a random variable drawn from this distribution. Some helpful properties of the Poisson distribution are summarized in the following fact.
Fact 5.
-
1.
Additivity of Poisson: for two parameters , it holds that:
-
2.
Parity of Poisson: for any parameter , and random variable , we have
-
3.
“Poissonization”: consider a set of samples from a distribution with support , and denote by the number of times element was sampled. Then distributes according to , and are independent from one another.
-
4.
Concentration: let . For any and , we have:
-
5.
Efficient sampling (e.g., [20]): a value from can be generated with running time where is the eventual output value (recall ).
4 A technical overview of the subgraph counting lower bounds
The most technically involved proofs are those of our tight lower bounds for counting small subgraphs. These apply in the weakest model (oblivious flip adversary) while the matching upper bounds are in the strongest model (adaptive adversary), thus resolving the smoothed complexity of these problems for all three smoothed input models.
As discussed before, we achieve some lower bounds using an embedding technique. However, for counting small subgraphs, these bounds are far from being tight, and a stronger technique is necessary. To obtain tight lower bounds, we instead employ a sequence of reductions, expanding on previous techniques used to show lower bounds for average-case complexities [17, 5, 3].
In a nutshell, [17] presents a sequence of reductions which solves the OMv problem (discussed below) by aggregating solutions from several executions of a dynamic counting algorithm, run on several different (well-correlated) uniformly random dynamic graphs. These instances are randomly generated from a single OMv input in a way that: (i) the noise is correlated and cancels out, allowing to solve the OMv problem; and (ii) each instance marginally resembles (in statistical distance) to a uniformly random input.
The outline of our lower bounds is similar, but condition (ii) above crucially changes: the instances produced by the reduction should marginally resemble -smoothed inputs, rather than uniformly random (average-case) inputs. In contrast to the average case, proving a lower bound for the smoothed case requires a choice of a specific adversarial strategy that “imposes hardness”.444Indeed, not all adversarial strategies would produce a nontrivial lower bound. For example, if the adversary chooses a uniformly random input, then after -smoothing the input remains uniformly random – for which there are efficient algorithms for the problems we consider. Applying -smoothing to this strategy yields a certain distribution over dynamic graphs that replaces the uniformly random input in condition (ii) above.
In addition to the above, the sequence of fine-grained reductions must be (iii) highly efficient. While this was a non-issue in the average case, it requires a careful treatment in our setting, where we apply conditional sampling from non-uniform distributions. In our argument we repeatedly use the Poissonization technique, described below, to control the dependencies between different instances, obtaining (i), (ii) and (iii). This technique is well-suited for our smoothed models, and we believe it should prove useful for other smoothed models of computation as well.
Poisson distribution.
We recall the Poisson distribution is supported on and parameterized by its mean value (see [27, Section 8.4]). In a nutshell, is the number of successful coin tosses when tossing infinitely many times a coin with infinitesimally small success probability, such that the expected number of successful attempts is . Formally, this is the limit for of the binomial distribution . Useful properties of this distribution are summarized in Section 3.2.
The Poissonization technique.
A particularly useful property of the Poisson distribution is known as Poissonization (Item 3 of Fact 5), and we next describe it in our setting. Consider a distribution over a set of edges. A multi-set of edges sampled from can be described by its histogram , where represents the number of times the edge is sampled. When drawing such samples, the histogram values exhibit a slight dependency among them, merely due to the fact that their sum is fixed to . This dependency poses complications in probabilistic and information-theoretic analysis, especially if additional constraints on the histogram values exist. To address this, we independently sample the value for each edge from , where represents the probability of in . This yields a total of samples, which might not be precisely samples, but remains well-concentrated around and even allows sampling conditioned on individual histogram values having e.g., a desired parity.
We apply Poissonization in several ways in our proofs, most prominently in Step below. This helps to simplify and clear up some hardness results of [17] and correct inaccuracies. More crucially, Poissonization helps us overcome the additional challenges that arise due to the adversarial presence.
Sections 4.1, 4.2 and 4.3 together prove a lower bound for counting - -paths, which is extended to other problems in the full version of the paper. The bounds are conditioned on the OMv conjecture [16], which formalizes the common belief that a truly sub-cubic combinatorial algorithm for matrix multiplication does not exist.
4.1 Step 1: Massaging the OMv conjecture
The first step reduces between online algebraic matrix-vector multiplication problems. It consists of an algebraic reduction that was presented in [16] and is standard by now, and two reductions that were presented in [17].
Definition 6 (OMv problem).
The OMv problem is the following online problem. Fix an integer . The initial inputs are a Boolean -vector and a Boolean matrix . Then, Boolean vectors of dimension arrive online, for . An algorithm solves the OMv problem correctly if it outputs the Boolean vector before the arrival of , for , and outputs .
Conjecture 7 (OMv conjecture [16, Conjecture 1.1]).
For any constant , there is no -time algorithm that solves OMv with error probability at most in the word-RAM model with -bit words.
After a standard reduction from the OMv problem to the OuMv problem, two other reductions are made. The first reduces to OuMv with operations modulo (that is, over instead of ), as defined below. The second reduction is a typical worst-case to average-case reduction over , showing the problem is as hard on random inputs. We define the OuMv problem and state the reduction to conclude this step.
Definition 8 (parity OuMv problem).
The parity OuMv problem is the following online problem. Fix an integer . The initial inputs are two Boolean -vectors , and a Boolean matrix . Then, pairs of Boolean vectors of dimension arrive online, for . An algorithm solves the parity OuMv problem correctly if it outputs the Boolean value (over ) before the arrival of , for , and outputs .
An algorithm solves the average-case parity OuMv problem if it answers correctly, with error probability at most , over inputs that are chosen independent and uniformly at random (that is, all entries of the matrix and the vectors are i.i.d. random bits).
The sequence of reductions concludes in the following lemma.
Lemma 9 ([17, Section 2]).
For any constant , there is no -time algorithm that solves the average-case parity OuMv problem, unless the OMv conjecture fails.
Remark 10.
At this point, [17, Section 2.1] reduces the former problem to a newly defined algebraic online problem, the biased average-case OuMv problem. Unfortunately, this leads to some inconsistencies in their proof (e.g., the statements regarding this online problem use the notions of update and query times, which are irrelevant to online problems). To circumvent this, our argument diverges from theirs, directly reducing the parity OuMv problem to a dynamic graph problem.
4.2 Step 2: From OuMv to counting - -paths in restricted graphs
We next show that average-case parity OuMv can be solved using an algorithm that counts - -paths in -partite -smoothed dynamic graphs with an oblivious flip adversary.
A -partite graph is composed of nodes partitioned as , where , and can only have edges of types (that is, ). To represent the OuMv problem using this graph, consider and as the indicators of the and edges, respectively (e.g., ). It is not hard to see that the product is exactly the number of - -paths.
Assume we have a -partite graph that represents and as above, and we get the next pair and want to update the graph accordingly. In worst-case analysis, such reduction can use adversarial choices: flip the and edges to represent , leave the edges intact, and then query the number of - -paths to retrieve . When random changes are involved in the process, however, undesired changes to edges are bound to occur. Moreover, such changes are more likely than others, as there are potential edges of types and only potential edges of the other types ( and ). Next, we describe how to overcome this challenge.
For the mere problem of having any changes in edges, a standard solution used in [17] serves here as well: the reduction creates copies of the graph, such that whenever a query is made, each has different edges but they have exactly the same and edges. To be precise, the edges in the 3 graphs will represent 3 matrices such that , while the and edges in all the graphs represent and . This assures that the sum modulo 2 of the number of - -paths in the three graphs gives with the original matrix :
| (1) |
The harder challenge is to synthesize such correlated change sequences that resemble authentic -smoothed change sequences. To this end, consider an oblivious adversary whose strategy is not deterministic, but instead chooses an or edge u.a.r. That is, each change is distributed on the graph edges by
After applying -smoothing, each change has the following distribution over the graph edges
This guarantees the highest chances for a change of type and after smoothing, which is crucial for avoiding redundancies in the reduction and obtaining a tight lower bound. Moreover, since all edge changes are drawn from , we can simulate a sequence by generating a multi-set of edges and later randomize the order in which they are changed. We create a sequence of roughly changes using Poissonization. This breaks dependencies and allows us to construct a multi-set of samples by drawing the number of appearances of each edge independently.
Edges of types and .
Recall that changes to and are shared by all copies; hence, we create one multi-set of such changes, . Let and be the difference vectors, and denote by the number of times the edge is added to . Our goal is to ensure that for each such edge, (and similarly for edges and ). Naively using rejection sampling (resampling the multi-set until all conditions are met) would take attempts. Instead, we use Poissonization: for each edge , draw a Poisson number of samples independently, conditioned on the desired parity, i.e., . Rejection sampling of each value separately only requires attempts overall.
Edges of type .
Drawing for each edge in a similar way would require time, which is too costly for this fine-grained reduction. However, only changes of type are expected, so we instead draw the total number of changes from a Poisson distribution with parameter , and then assign an edge u.a.r. for each of these changes. In actuality, we wish to create correlated copies, where edges cancel out. To this end, we draw three multi-sets , each composed of edges of type , where each edge is chosen u.a.r. Each copy uses exactly two of the sets , such that each set is used twice. This ensures that (1) holds.
Adding to the multi-set of each copy and shuffling each of them separately produces sequences of edge changes that are statistically close to a sequence of edge changes drawn from . Bounding the statistical distance limits the additional error from the imperfect simulation, guaranteeing the error probability on the output is only slightly higher than the error probability of executions of the - -paths counting algorithm on genuine -smoothed inputs.
Remark 11.
The simulation above is perhaps the crux of the reduction, generating inputs for the dynamic graph algorithm from inputs to the OuMv problem. We note that the simulation used in [17] was much simpler and easily shown to be efficient, but its proof of correctness was incomplete. One place that is lacking is a false proof for Claim C.2. While this is fixable for their specific case, it stems in an inescapable subtlety of handling dependencies. Our use of Poissonization in both the simulation and the analysis tackles these subtleties and formally proves our claims, as well as theirs.
4.3 Step 3: From restricted graphs to general graphs
Finally, we show how to count - -paths in the restricted class of -partite graphs using an algorithm that counts such paths in general graphs. This reduction uses inclusion-edgeclusion: it takes a -partite graph , and constructs (general) graphs by adding edges that were previously not allowed (exterior edges). The same approach was taken in the average-case analysis, but smoothed inputs require more attention due to the adversarial presence.
To account for the adversarial presence, the transition from a -smoothed -partite graph to -smoothed graphs must use that sufficiently weakens the adversary. Still, this can be done using , which is crucial for a lossless reduction leading to (nearly) tight lower bounds.
The new dynamic graphs all use the original node set , and initially all have the same interior edges as the -partite graph. Their initial exterior edges are correlated in the following sense: they properly partition the four exterior edge sets . That is, there exists four partitions, one for each edge set, such that the exterior edges of each of the initial graphs constitute a unique combination of the parts, one from each edge set.
We next describe how to construct a single change, using a parameter . We flip a coin ; if we make an interior change, the next change in the -smoothed sequence of , while if we change a random exterior edge. Choosing carefully and guarantees that a sequence of such changes is -smoothed on a general graph, for an appropriate adversarial strategy. We apply this sequence of changes to each of the graphs.
Since the graphs undergo the exact same changes, they properly partition the four exterior edge sets at all times. This invariant ensures that the total number of exterior - -paths (i.e., not of type ) in all graphs is always easy to compute. After querying all graphs for their - -paths count, we sum the answers, subtract the exterior paths, and divide by . This gives the number of paths in , since each interior path appears in all graph and was counted times.
To summarize, steps 1-3 dictate a chain of fine-grained reductions as follows. An algorithm for counting - -paths in general graphs can be used to count them in a -partite graph, which in turn can be used to solve the average-case parity OuMv problem. A solution for the average-case parity OuMv problem implies a solution to the OMv problem, contradicting the OMv conjecture.
References
- [1] Amir Abboud and Virginia Vassilevska Williams. Popular conjectures imply strong lower bounds for dynamic problems. In FOCS, pages 434–443. IEEE Computer Society, 2014. doi:10.1109/FOCS.2014.53.
- [2] David Alberts and Monika Rauch Henzinger. Average-case analysis of dynamic graph algorithms. Algorithmica, 20(1):31–60, 1998. doi:10.1007/PL00009186.
- [3] Enric Boix-Adserà, Matthew S. Brennan, and Guy Bresler. The average-case complexity of counting cliques in erdős-rényi hypergraphs. In FOCS, pages 1256–1280. IEEE Computer Society, 2019. doi:10.1109/FOCS.2019.00078.
- [4] Raphaël Clifford, Allan Grønlund, and Kasper Green Larsen. New unconditional hardness results for dynamic and online problems. In FOCS, pages 1089–1107. IEEE Computer Society, 2015. doi:10.1109/FOCS.2015.71.
- [5] Mina Dalirrooyfard, Andrea Lincoln, and Virginia Vassilevska Williams. New techniques for proving fine-grained average-case hardness. In FOCS, pages 774–785. IEEE, 2020. doi:10.1109/FOCS46700.2020.00077.
- [6] Camil Demetrescu and Giuseppe F Italiano. A new approach to dynamic all pairs shortest paths. Journal of the ACM (JACM), 51(6):968–992, 2004. doi:10.1145/1039488.1039492.
- [7] Michael Dinitz, Jeremy Fineman, Seth Gilbert, and Calvin Newport. Smoothed analysis of information spreading in dynamic networks. In 36th International Symposium on Distributed Computing, page 1, 2022.
- [8] Michael Dinitz, Jeremy T Fineman, Seth Gilbert, and Calvin Newport. Smoothed analysis of dynamic networks. Distributed Computing, 31(4):273–287, 2018. doi:10.1007/S00446-017-0300-8.
- [9] Dorit Dor, Shay Halperin, and Uri Zwick. All-pairs almost shortest paths. SIAM J. Comput., 29(5):1740–1759, 2000. doi:10.1137/S0097539797327908.
- [10] Tobias Friedrich, Thomas Sauerwald, and Dan Vilenchik. Smoothed analysis of balancing networks. Random Structures & Algorithms, 39(1):115–138, 2011. doi:10.1002/RSA.20341.
- [11] Seth Gilbert, Uri Meir, Ami Paz, and Gregory Schwartzman. On the complexity of load balancing in dynamic networks. In Proceedings of the 33rd ACM Symposium on Parallelism in Algorithms and Architectures, pages 254–264, 2021. doi:10.1145/3409964.3461808.
- [12] Nika Haghtalab, Tim Roughgarden, and Abhishek Shetty. Smoothed analysis of online and differentially private learning. Advances in Neural Information Processing Systems, 33:9203–9215, 2020.
- [13] Nika Haghtalab, Tim Roughgarden, and Abhishek Shetty. Smoothed analysis with adaptive adversaries. In FOCS, pages 942–953. IEEE, 2021. doi:10.1109/FOCS52979.2021.00095.
- [14] Kathrin Hanauer, Monika Henzinger, and Qi Cheng Hua. Fully dynamic four-vertex subgraph counting. In SAND, volume 221 of LIPIcs, pages 18:1–18:17. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2022. doi:10.4230/LIPIcs.SAND.2022.18.
- [15] Kathrin Hanauer, Monika Henzinger, and Christian Schulz. Recent advances in fully dynamic graph algorithms - A quick reference guide. ACM J. Exp. Algorithmics, 27:1.11:1–1.11:45, 2022. doi:10.1145/3555806.
- [16] Monika Henzinger, Sebastian Krinninger, Danupon Nanongkai, and Thatchaphol Saranurak. Unifying and strengthening hardness for dynamic problems via the online matrix-vector multiplication conjecture. In STOC, pages 21–30. ACM, 2015. doi:10.1145/2746539.2746609.
- [17] Monika Henzinger, Andrea Lincoln, and Barna Saha. The complexity of average-case dynamic subgraph counting. In SODA, pages 459–498. SIAM, 2022. doi:10.1137/1.9781611977073.23.
- [18] Shang-En Huang, Dawei Huang, Tsvi Kopelowitz, Seth Pettie, and Mikkel Thorup. Fully dynamic connectivity in amortized expected time. TheoretiCS, 2, 2023. doi:10.46298/THEORETICS.23.6.
- [19] Ahmet Kara, Hung Q. Ngo, Milos Nikolic, Dan Olteanu, and Haozhe Zhang. Maintaining triangle queries under updates. ACM Trans. Database Syst., 45(3):11:1–11:46, 2020. doi:10.1145/3396375.
- [20] Donald Ervin Knuth. The art of computer programming, volume 3. Pearson Education, 1997.
- [21] Tsvi Kopelowitz, Seth Pettie, and Ely Porat. Higher lower bounds from the 3sum conjecture. In SODA, pages 1272–1287. SIAM, 2016. doi:10.1137/1.9781611974331.CH89.
- [22] Michael Krivelevich, Daniel Reichman, and Wojciech Samotij. Smoothed analysis on connected graphs. SIAM Journal on Discrete Mathematics, 29(3):1654–1669, 2015. doi:10.1137/151002496.
- [23] Michael Krivelevich, Benny Sudakov, and Prasad Tetali. On smoothed analysis in dense graphs and formulas. Random Structures & Algorithms, 29(2):180–193, 2006. doi:10.1002/RSA.20097.
- [24] Kasper Green Larsen and Huacheng Yu. Super-logarithmic lower bounds for dynamic graph problems. In FOCS, pages 1589–1604. IEEE, 2023. doi:10.1109/FOCS57990.2023.00096.
- [25] Uri Meir and Ami Paz. Smoothed analysis of dynamic graph algorithms, 2025. doi:10.48550/arXiv.2502.13007.
- [26] Uri Meir, Ami Paz, and Gregory Schwartzman. Models of smoothing in dynamic networks. In DISC, volume 179 of LIPIcs, pages 36:1–36:16. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2020. doi:10.4230/LIPIcs.DISC.2020.36.
- [27] Michael Mitzenmacher and Eli Upfal. Probability and computing: Randomization and probabilistic techniques in algorithms and data analysis. Cambridge university press, 2017.
- [28] Sotiris E. Nikoletseas, John H. Reif, Paul G. Spirakis, and Moti Yung. Stochastic graphs have short memory: Fully dynamic connectivity in poly-log expected time. In ICALP, volume 944 of Lecture Notes in Computer Science, pages 159–170. Springer, 1995. doi:10.1007/3-540-60084-1_71.
- [29] Mihai Pătraşcu and Erik D. Demaine. Logarithmic lower bounds in the cell-probe model. SIAM J. Comput., 35(4):932–963, 2006. doi:10.1137/S0097539705447256.
- [30] Mihai Puatracscu. Towards polynomial lower bounds for dynamic problems. In STOC, pages 603–610. ACM, 2010. doi:10.1145/1806689.1806772.
- [31] Mihai Puatracscu and Mikkel Thorup. Don’t rush into a union: take time to find your roots. In STOC, pages 559–568. ACM, 2011. doi:10.1145/1993636.1993711.
- [32] Liam Roditty and Uri Zwick. On dynamic shortest paths problems. Algorithmica, 61(2):389–401, 2011. doi:10.1007/S00453-010-9401-5.
- [33] Piotr Sankowski. Faster dynamic matchings and vertex connectivity. In SODA, pages 118–126. SIAM, 2007. URL: http://dl.acm.org/citation.cfm?id=1283383.1283397.
- [34] Gregory Schwartzman and Yuichi Sudo. Smoothed Analysis of Population Protocols. In 35th International Symposium on Distributed Computing (DISC 2021), volume 209 of Leibniz International Proceedings in Informatics (LIPIcs), pages 34:1–34:19. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2021. doi:10.4230/LIPIcs.DISC.2021.34.
- [35] Daniel A. Spielman and Shang-Hua Teng. Smoothed analysis of algorithms: Why the simplex algorithm usually takes polynomial time. J. ACM, 51(3):385–463, 2004. doi:10.1145/990308.990310.
- [36] Daniel A. Spielman and Shang-Hua Teng. Smoothed analysis: an attempt to explain the behavior of algorithms in practice. Commun. ACM, 52(10):76–84, 2009. doi:10.1145/1562764.1562785.