New Greedy Spanners and Applications

Abstract
We present a simple greedy procedure to compute an -spanner for a graph . We then show that this procedure is useful for building fault-tolerant spanners, as well as spanners for weighted graphs.
Our first main result is an algorithm that, given a multigraph , outputs an edge fault-tolerant -spanner of size which is tight. To our knowledge, this is the first tight result concerning the price of fault tolerance in spanners which are not multiplicative, in any model of faults.
Our second main result is a new construction of a spanner for weighted graphs. We show that any weighted graph has a subgraph with edges such that any path of hop-length in has a replacement path in of weighted length where is the total edge weight of , and denotes the sum of the largest edge weights along . Moreover, we show such approximation is optimal for shortest paths of hop-length . To our knowledge, this is the first construction of a “spanner” for weighted graphs that strictly improves upon the stretch of multiplicative -spanners for all non-adjacent vertex pairs, while maintaining the same size bound.
Our technique is based on using clustering and ball-growing, which are methods commonly used in designing spanner algorithms, to analyze simple greedy algorithms. This allows us to combine the flexibility of clustering approaches with the unique properties of the greedy algorithm to get improved bounds. In particular, our methods give a very short proof that the parallel greedy spanner adds edges, improving upon known bounds.
Keywords and phrases:
Graph Spanners, Greedy AlgorithmsFunding:
Elad Tzalik: Supported by the Adams Fellowship Program of the Israel Academy of Sciences and Humanities.Copyright and License:
2012 ACM Subject Classification:
Mathematics of computing Graph algorithmsAcknowledgements:
We are deeply grateful to Merav Parter for her invaluable guidance, encouraging this collaboration, and suggesting the problem of constructing better FT -spanners. We thank Asaf Petruschka for clarifying the connection between the bounded-degree fault model and the parallel greedy spanner, and we thank Nathan Wallheimer and Ron Safier for useful discussions.Editor:
Shubhangi SarafSeries and Publisher:
1 Introduction
Let be an -vertex weighted graph. A spanner of is a subgraph that approximately preserves distances. Formally, a subgraph is a -spanner of if for all (where denotes the shortest path distance in a graph ). Since their introduction by Peleg and Ullman [41] and Peleg and Schäffer [39], spanners have been found to be extremely useful for a wide variety of applications, including network tasks like routing and synchronization [40, 44, 21, 22, 41], preconditioning linear systems [27], distance estimation [45, 7], and many others. The first tight construction of spanners was given by [5], which proved that any graph admits a -spanner with edges, which is best possible111The upper bound is tight assuming the girth conjecture of Erdős. Nevertheless, the algorithm of [5] is optimal unconditionally..
The foundational work of Althöfer et al. [5], focuses on providing a stretch for adjacent pairs of vertices, and highlights that graphs of girth are a bottleneck for such sparsification. To handle these bottlenecks, much work has focused on -spanners.
Definition 1 (()-spanner).
Let be a graph. A subgraph is called an -spanner of if for all ,
When we call a multiplicative spanner, and when we call it an additive spanner.
Intuitively, -spanners have effectively multiplicative stretch for vertices that are far apart in , while masks the local bottlenecks such a graph may have – in order to achieve an upper bound on the size of the spanner. The first indication that one can provide improved stretch for distant vertices is the seminal work of Elkin and Peleg [30]. In [30] the authors constructed spanners of size edges and for every integer and , as well as a -spanner. This sparked many follow-up works to investigate the tradeoffs of size, distance and stretch achievable in graph sparsification and in particular the spanner of Baswana et al. [6], the spanner of Thorup and Zwick [46], and many additional works e.g. [17, 9, 28].
In real-world scenarios, spanners are frequently employed in systems whose components are susceptible to occasional breakdowns. It is therefore desirable to have spanners possessing resilience to such failures, leading to the notion of fault-tolerant (FT) spanners. Two extensively studied types of faults are edge faults and vertex faults. Spanners in the edge/vertex fault-tolerant (E/VFT) settings are defined as follows:
Definition 2 (E/VFT Spanner).
An -EFT (VFT) -spanner of is a subgraph such that for every set of at most edges (vertices) in , it holds that is an -spanner of .
E/VFT spanners have received major interest in recent years; see, e.g., [18, 23, 10, 14, 24, 11, 12, 36] and references therein. The current state of affairs is that multiplicative FT spanners are well understood; this is reflected by essentially tight bounds on the size of fault tolerant spanners in case of vertex faults [14, 36], edge faults [12], bounded degree faults [13], and color faults [42, 37].
In contrast, the right size bounds required from an -FT spanners is poorly understood, and no tight bounds are known for given that improve the stretch obtained by the multiplicative -FT -spanner in any FT model. The work of [15] studied FT additive and -spanners and constructed -EFT -spanners with many edges. An alternative construction may be given using the method of Dinitz and Krauthgamer [23] to obtain -EFT -spanners with many edges. Finally, one may use an -EFT -spanner which can be done in for multigraphs [18, 14], and for simple graphs. Moreover, each of the aforementioned results, improves upon the others for some range of , which sums up into an unclear picture on the “overhead” one needs to pay for faults in -spanners. Meanwhile, for lower bounds, a folklore lower bound, a multigraph with edges and no proper -EFT -spanner, is known222The lower bound is conditional on the Erdős girth conjecture. The conjecture states that for all integers there exist an node graph with edges and girth . It is common in the area of FT spanners to base lower bounds on the Erdős girth conjecture, see e.g. [10, 13, 42] and reference therein..
Our first main result is clarifying the picture for -EFT, -spanners in multigraphs, by giving a tight upper bound matching the best known lower bound, resolving a long-standing gap, and improving the dependency on by the Dinitz-Krauthgamer approach, to a tight overhead. We prove:
Theorem 3.
Let be a multigraph and let . Then:
-
1.
Existence. There exists an -EFT -spanner of with edges.
-
2.
Construction. There is a polynomial-time algorithm that outputs an -EFT -spanner of with edges.
We highlight that spanners are never used with larger than , since the additional stretch does not bring additional sparsity. On the other hand, the fault parameter can be significantly larger, for example polynomial in . In light of this, the improvement of Theorem 3 on the current known bounds is substantial, and achieves stretch of an -spanner under faults, with the same upper bound formerly known only for the weaker multiplicative fault tolerant spanners, see Table 1.
We emphasize two natural reasons to focus on multigraphs: (1) We believe they are more natural than simple graphs in the presence of faults. This is reflected e.g. in the fact that when adding colors to the edges and allowing color faults, the bounds for FT-spanners in multigraphs do not change. On the other hand, when introducing color faults to a simple graph one gets exactly the same behavior as multigraphs, e.g. the upper/lower bounds for edge-color-fault tolerant spanners in simple graphs jumps to , matching the bound for edge faults/ edge-color faults in multigraphs333See [42] for a more detailed discussion on the best bounds on the various fault models, and the effect of introducing colors.. (2) Even for the well-studied multiplicative EFT spanners, tight lower bounds are known for multigraphs but not for simple graphs, see [12].
| Size bound | Ref. | |
|---|---|---|
| [15] | ||
| [23] | ||
| [18, 14] | ||
| [18, 14] | ||
| new |
Our second main result concerns weighted graphs. Spanners are often used to compress metric spaces that correspond to weighted input graphs, see e.g. [16, 25, 34, 43]. Standard multiplicative spanners can handle weights easily, yet obtaining different better stretches for further pairs is not as obvious. The work of Cohen [20] constructed weighted spanners where the additive term corresponds to a approximation of the distance on top of the multiplicative stretch, where denotes the maximum edge weight over all edges in , which was then improved by [26]. In recent years, there has been a renewed and growing interest in understanding spanners for weighted graphs. The work of [28] achieved constructions of weighted spanners with local stretch, meaning that is replaced by the maximum , which stands for the maximum edge weight along a shortest path between nodes. This was later further studied for additive stretch in a sequence of works obtaining essentially tight results [4, 29, 2, 33].
While for unweighted graphs, an spanner has a better stretch than an spanner with for far enough vertex pairs, this is not necessarily the case in the weighted setting as the term can significantly outweigh the weight of the path. In particular, while the line of works [4, 29, 2, 33] gives tight bounds for additive spanners, such spanners may require edges for any by the seminal work of Abboud and Bodwin [1]. The state of weighted spanners with edges and local stretch guarantee is less understood, with essentially a single construction of Elkin Gitlitz and Neiman [28] of a weighted - spanner with edges. Our second result aims to fill in two gaps that weighted - spanner with have: (1) the bound is ineffective for paths of hop length , in the sense that a multiplicative spanner produces a better stretch, and (2) In case of very irregular weights in , the term may significantly outweigh the constant multiplicative stretch guaranteed. We complement their result by filling these gaps. We show an algorithm that takes a graph and returns a subgraph of size which strictly improves over the stretch of the multiplicative greedy algorithm for all non-adjacent vertices, and obtains optimal approximation for vertices whose shortest path consists of two edges. Given a path of length , let denote the sums of weights along the path, i.e. , and similarly define the sum of the highest weights along the path . We prove:
Theorem 4.
For every weighted graph , there exists a subgraph with edges such that for every pair joined by a path in ,
Moreover, for shortest paths of hop-length this bound is best possible.
To our knowledge, such tight bounds in Theorem 4 were not known, even in the unweighted setting. The work of Baswana et al. [6] achieves an upper bound of for spanners while the work of Parter [35] achieved stretch for vertices at distance (in the unweighted case) and size . Nevertheless in our viewpoint handling weighted graphs is the more interesting part of Theorem 4, whereas the factors is a secondary improvement.
Finally, we show that our technique is robust and useful for analyzing other variants of the greedy spanner. The parallel greedy spanner algorithm, introduced by Haeupler, Hershkovitz and Tan [31], is a variant of the standard greedy algorithm of [5] for computing a spanner, where instead of considering an edge at the step, a set of edges which forms a matching is being considered, and each edge of decides for itself greedily if it could be discarded from , or if it will be added to (the decision is done by checking for if , where is the spanner before was considered). The parallel greedy spanner algorithm appears in relation to later works on length-constrained expanders and routing algorithms, see [19, 32]. The main result of [31] is that the parallel greedy algorithm adds at most edges overall, which was later improved to by Bodwin, Haeupler and Parter [13]. Both papers are technically heavy, with [31] “length-constrained” expander decomposition machinery, and [13] used the counting/dispersion approach of [12] together with a complex choice of paths to count over444The work of [13] does not specifically target parallel greedy spanners but the more challenging bounded-degree FT-spanners, yet their results imply upper bounds on the output size of the parallel greedy spanner.. We show that by applying the tools we develop in this work, one gets an elementary analysis (at most two pages) of the following improved bound:
Proposition 5.
The output of the parallel greedy spanner algorithm with stretch parameter has many edges, and arboricity .
1.1 Technical Overview
The starting point of this work, as well as a central component of the FT-spanner we construct, is a new greedy algorithm we introduce and analyze.
The Greedy Spanner Algorithm
Our goal will be to study the following problem: given a graph and integers , find a sparse subgraph , such that vertices at distance exactly in are at distance in :
Definition 6 ( spanner).
Let be natural numbers. We say that a subgraph of is a spanner of if :
We highlight that this definition is similar to the definition of -spanner appearing in many works and refer the reader to the survey [3] and references therein. Given an spanner of is a subgraph which is a spanner for all , hence the main distinction in our approach is specializing only in fixed . spanners can be thought of as building blocks for spanners in particular we highlight the work of Parter [35] giving an almost tight construction of spanners, and the later work of Parter and Ben-Levy [9] which constructs spanners with edges for . We emphasize that the union of a few spanners usually make an -spanner and in particular it is folklore (and easy to prove) that a union of a and a spanner of a graph , always produces a spanner. We will construct spanners by analyzing the following simple greedy spanner algorithm:
Large Cliques in the Output of the Greedy Algorithm
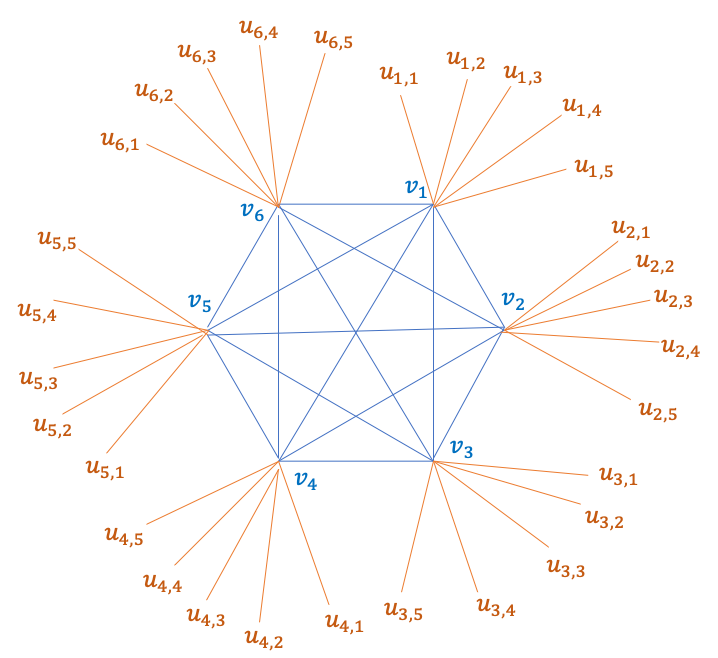
While the high girth of the greedy spanner of [5] is a main feature used in most works, the output of the greedy algorithm for may have very small girth. To demonstrate this, we show that the output of the greedy algorithm does not necessarily have high girth, e.g. it can have a clique of size . Consequently, getting a meaningful size bound for the output of the algorithm requires more than just girth.
Claim 7.
There exists a graph on vertices and an order of the -paths in it such that when the greedy algorithm processes the paths in order, the output has a clique of size .
Proof.
Set , and consider a clique of vertices . Connect each to other vertices , where all are distinct and so each a leaf in the resulting graph, see Figure 1. Consider the following sequence of -paths: in the lexicographical order of , with the indices of considered modulo .
By construction, each new path introduces a fresh leaf, ensuring it will be kept by the greedy algorithm, forcing all clique edges into the output (see Figure 1). This shows that the greedy algorithm is forced to include every clique edge. The union of these paths contains the entire graph, and in particular, a -clique.
The Clustered vs. Nearby Process
To bypass the lack of high girth we take a new approach, based on clustering see e.g [30, 6, 8, 17, 9]. A central definition we use is that of a clustered vertex in a graph: a vertex is clustered in a graph with nodes if for all , 555Notice the definition of clusters depend on and , though we omit from the definition for simplicity, as it is fixed throughout the paper.. This definition is inspired by the new “local” viewpoint of the Baswana-Sen algorithm of [37]. We show that adding an edge between relatively far vertices in a graph helps them become more clustered, which is captured by the following key lemma:
Lemma 8 (Neighborhood exchange lemma).
Let be vertices in a graph , and assume that . Let Then for every :
-
(a)
.
-
(b)
.
The merit of the lemma above is that it implies good bounds on the following algorithm we introduce, called the Clustered vs. Nearby Process: For an input graph , initialize an empty graph and iteratively consider an edge , and add to if: (1) The endpoints of are at mutual distance in , and (2) one of ’s endpoints is not clustered in . Using the lemma we show that this process adds only edges where is the parameter of clustering. In particular if one inserts to this process the edges of a graph , one obtains a graph as output, together with the following invariant which is often critical in clustering methods666See e.g. the local analysis of the Baswana-Sen algorithm in [37].: for every either (1) are both clustered or (2) 777One can also extend this process naturally to weighted graphs, which we use in the main result of Section 4. We then apply this lemma to an analogous parallel clustered vs. nearby process – to obtain essentially tight bounds for parallel greedy spanners. The size bound of on the number of edges added by the process has a factor which is present because the analysis of clustering using Lemma 8 goes in rounds. It turns out that sequential algorithms enjoy a better upper bound than the one achieved by this round-by-round clustering. In Section 2 we prove that when edges in the nearby vs clustered process are added sequentially, the number of edges added by this process is . We view the process as a greedy way to achieve clustering, and believe it will find applications in future work.
Obtaining Tight Bounds for the Greedy Spanner
Our approach is based on combining the clustering ideas formerly described with a “path-buying” inspired algorithm, describing how distances shrink throughout the algorithm, together with an extra step we call lateral clustering. We consider the paths , with added by the greedy algorithm, in their order. For each we consider the pair which was at distance before adding to the graph (such a pair must exist by the triangle inequality), we assume without loss of generality this pair is (otherwise reverse the path) and call it the distant pair. Concretely if or is not -clustered, we can “charge” adding as the addition of an edge to the clustered vs nearby process with distance parameter – as the sequential process adds edges, there are only paths with a distant pair with both endpoints not -clustered.888In other words, we use a moderate girth subgraph for the analysis of the clustering that occur during the greedy algorithm. E.g. in Figure 1 the orange edges are distant and contribute to the clustering of their endpoints, while the blue edges of the clique are typically not distant and do not contribute to clustering via the clustered vs nearby process, nevertheless we can still use such paths for clustering in a more intentional way, we describe now.
The rest of the paths have distant pairs which are both already -clustered, let be such path. If was also -clustered we will be done by a “path-buying” like argument (Originally appearing in [6]) – we can show that the pairs of vertices in are at distance before adding but after adding , as this can happens at most once for a pair of vertices, and as there are pairs of vertices this will apply the desired upper bound for such paths. While on a high level, the approach above describes well the main ideas that go into the proof, unfortunately it does not work as stated – there is no guarantee that is or even -clustered! To handle this, the analysis requires an additional technical step which we call “lateral” clustering. In the lateral clustering step we analyze the effect of adding on the size of the -ball around and divide into the following cases: (1) Most vertices of the -ball around were initially (before adding ) at distance from – in this case we still get a significant increase for the size of by adding , hence the number of steps for which such paths can increase the size of a around until it has a ball of size is getting us back to the path-buying type argument, as if is clustered. (2) Most vertices of the -ball around were initially (before adding ) at distance from . In this case we apply a similar “path-buying” type argument for balls around and , which concludes the proof.
In the full version of the paper, we show that the greedy algorithm can also be used for other values of . We reprove a result of Ben-Levy and Parter ([9], Thm 1.2) of the existence of spanners with edges, by showing the greedy algorithm with the same parameters achieves the same size bound.
1.2 Handling Faults
To handle faults, we analyze a FT-greedy algorithm, originally due to [10], adapted to the spanner definition:
Definition 9 (EFT spanners).
Let be a (multi)graph and . A subgraph is an -edge-fault tolerant (-EFT) spanner if for every with and all :
We then study the FT-greedy spanner, which works as follows: For all go over all paths with edges between and , and add to whenever there exist a fault set of edges, disjoint from , such that . We show that the algorithm above achieves the size bounds appearing in Theorem 3.
The Blocking Set Method for Spanners
In [14], Bodwin and Patel studied VFT-spanners, and prove that the -VFT greedy algorithm achieves optimal size bound. To do so, define a blocking set as a collection of edge-vertex pairs, such that each short () cycle in contains one of the pairs. The FT greedy algorithm naturally induces a blocking set of size . They then show that a graph with such blocking set has edges for the vertex fault model. On an intuitive level, a graph that admits a small blocking set is often thought of as being close to having high girth, forcing it to be sparse.
In contrast we view the output of the greedy as producing graphs such that many vertices have cuts of size that substantially separate them. A spark of this viewpoint appears in [38], where a tight analysis for a FT-greedy algorithm was given by applying a “cut-based” view instead of the cycle-based view of [13]. By defining the blocking set for the FT-greedy algorithm, we show that the output size produced isn’t too large when compared to the standard greedy spanner. We show that if is a bound on the maximal number of paths added by the greedy spanner999We actually need a bound for a slightly different algorithm then Algorithm 1, nevertheless this is done for technical reason elaborated in Section 5. on an -vertex graph. Then the -FT greedy spanner adds at most paths. This concludes the proof using the bounds obtained for the spanner described previously.
The proof of the theorem above is short, and has two steps: (1) Showing that it is enough to prove the theorem when the FT algorithm adds edge-disjoint paths at each step, and (2) Showing that if the FT-greedy algorithm adds disjoint paths, then they may be thought of as “long edges” – which reduces the dependence on the fault parameter to be linear similarly to [14, 42].
1.3 Improving Upon Multiplicative Spanners for Weighted Graphs
It is not hard to see that Theorem 4 would follow if we could show that any weighted graph has a subgraph with edges and the following property: any -path in has a replacement path in of weight which is what we achieve in Section 4. We also highlight that the section begins with a simple lower bound, Claim 32, showing that the stretch is the best possible stretch that can be achieved by a subgraph with edges, assuming the girth conjecture.
Following the theme presented in the paper, one may guess the following generalization of the greedy algorithm in the spirit of [5] – go over the paths in order of weight and add each path which does not have good approximation in the current subgraph. The main difficulty in this approach stems from the following question: According to which order should be processed? The multiplicative greedy spanner scans edges, and in such case there is a natural order – order of weight. On the other hand the greedy spanner for scans paths of length – if those were composed of weighted edges it is unclear which order to choose: maybe order the paths by maximum edge weight on the path? another natural options are the total edge weight/ a linear combination of the weights along the path. We didn’t find a single order for which the analysis goes through.
A different attempt is to use what is called -light initialization, appearing in [4, 2, 29] in the context of weighted additive spanners. -light initialization describes an initialization phase prior to running an algorithm, in which every vertex adds its lightest adjacent edges – in our case edges. This approach is effective in handling but doesn’t seem to generalize to higher – the main reason is that it allows to compare weights in a very local way (around a vertex), which does not propagate to something meaningful for long enough paths. Even if one replaces the initialization phase by a clustering phase, it seems that additional structure is needed to design the algorithm.
In light of the above, we took a different approach – instead of running a greedy algorithm in some unique order, such that an analysis similar to Theorem 19 follows, we break the algorithm according to the steps in the analysis of Theorem 19, by introducing weighted notions of clustering, lateral clustering, a greedy phase, and a new “distance-reduction” phase, each with it’s own novel order. We believe that this approach can be fruitful for other constructions of spanners for weighted graphs.
We now briefly describe the phases of the algorithm, their corresponding order, and what they informally try to achieve. The spanner will be the union of all edges added in the various phases. Assume for now is even, and . The other parity of is handled similarly in Section 4.
Phase 1: Adding a Multiplicative Spanner
We begin by adding to the spanner a multiplicative spanner with edges. The main reason for this phase is the following observation: every -path (in ) with an edge in the final spanner (the second edge may not be present in the final spanner) has the right stretch in the final spanner. Hence it’s enough to obtain a good stretch for -paths in with both edges not in the final spanner.
Phase 2: Greedy Clustering
We go over all edges by increasing order of weight and will run the clustered vs nearby process on all edges by order of weight and add those added by the process, which is edges. By the end of this phase we ensure that any edge not in the final spanner has either (1) , or (2) that are clustered at the time of considering – which implies that , and are of size , for 101010 is the underlying of all edges of weight at most .. In case an edge wasn’t added due to condition (2) we call this edge saturated.
It now follows that paths with two edges that weren’t included because have good stretch already by the end of this phase. For the rest of the paths which do not meet the desired stretch by the end of phase we have (w.l.o.g) that both were clustered at the time (aka weight) for which the edge was considered in phase . This allows to add edges that improve distances between vertices, while still adding only edges.
Phase 3: Lateral Clustering
The lateral clustering phase is an algorithm where each vertex (independently) adds edges. For every vertex denote by to be the smallest weight of a saturated edge (see description of phase 2) incident to . Each vertex goes over it’s neighbors by order of weight and checks wether adding the edge substantially increases the size of the ball of radius around . The reason for choosing this particular order is that this way we order ’s neighbors in a monotone way according to the implied distance (to ) guarantee we can get on the vertices from ’s ball, after the edge addition.
After phase 3 the neighbors of that were not added divide into two: (type 1 neighbors) neighbors of such that at time of considering the -ball around was already of size , and (type 2 neighbors) neighbors such that when considering , the ball of radius in the spanner, shares many neighbors with the ball of radius around .
Phase 4: Global Distance Reduction by Edges
In this phase we go over all saturated edges , that is edges that weren’t added by phase due to both endpoints being clustered (according to the corresponding weight) and reconsider adding them to the spanner – as they may create useful shortcuts for vertex pairs between their clusters. More concretely, we go over by order of weight and for each we check how many pairs of will be of distance due to adding – if this quantity is we will add to the spanner. Again this phase adds the right number of edges. The key property of this phase (together with phase 4) is that by the end of it, we have successfully handled all paths such that: (1) was saturated in phase 2, and wasn’t added during phase 4 (2) when considered in phase 3, was a type 2 neighbor when considered by .
Phase 5: Greedy Phase
The fifth and last phase is greedy, we will go over all paths that do not have the right stretch in the spanner, and if a path doesn’t satisfy the right stretch we add it. It is not hard to check that the only path that may have a bad stretch have: (1) is saturated and wasn’t added in phase 4, and (2) was a type 2 neighbor of (meaning that already has a sufficiently large ball around it). In such case, we show that many distances ( in the set must improve by adding the path. Still we need to make sure that every pair of vertices improve at most once. For this we choose the last order to be – which correspond to the distance bound of the short paths created by the greedy fixes.
1.4 Organization of the Paper
In Section 2 we set the stage and develop the key definitions and tools we need through the paper, and warm up by showing how to apply these tools to analyze the parallel greedy spanner. In Section 3 we analyze the greedy algorithm. In Section 4 we describe and analyze the weighted spanner in Theorem 4. Section 5 concludes the construction of the -FT -spanner with size .
1.5 Notations
For an unweighted graph we denote for the length of their shortest to path by . For a path we use to denote the first vertex of the path and similarly denotes the last vertex on the path, and is the length of the path. We denote by the set of vertices that has a path of length to .
A weighted graph is a triple with . For a path in a weighted graph we denote by the sum of weights of , by (resp. ) the maximum (resp. minimum) edge weight along . For a weighted graph , denotes the minimum of over all to paths in . For a weighted graph we write for the underlying unweighted graph of . For a threshold , let be the subgraph of induced by edges of weight at most , and let be its underlying unweighted graph. For two sets we denote and the corresponding difference set. For a set and graph we denote the graph .
2 Clustering in Changing Graphs
We now introduce tools that would be useful throughout the paper, and in particular, describe the clustered vs distant process, and prove Proposition 16.
We begin with a definition of a clustered vertex. The definition above depends on , and throughout the paper all clusters will appear with the same which will be clear from context.
Definition 10 (Clusters).
A vertex has an -cluster in a graph if for all we have If is maximal with this property, we say is -clustered.
Intuitively, being -clustered means that the neighborhood of a vertex grows at least polynomially fast in radius, with growth per step.
Notice that any vertex is -clustered in every graph. We also have the following observation.
Observation 11.
If a vertex is -clustered in a graph , then .
Proof.
By definition a -clustered vertex has . Hence and the claim follows.
We next restate and prove the neighborhood exchange lemma. This lemma is crucial as it shows how clustering properties propagate when adding a new edge between distant vertices.
Lemma 12 (Neighborhood exchange lemma).
Let be vertices in a graph , and assume that . Let Then for every :
-
(a)
and .
-
(b)
, and .
Proof.
For (a), suppose . Then and , so by the triangle inequality, contradicting that . For (b), since , for every we have
which implies the claim.
2.1 The Clustered vs. Nearby Process
For a fixed integer (that is different in different contexts) and a subgraph of we shall call a vertex which has an -cluster in fully clustered in and call a pair of vertices distant if . When is clear from context we simply say a vertex is fully-clustered, and that a pair of vertices is distant, according to the above.
Consider the following algorithm:
We call an edge boosting if is a distant pair and either or is not fully clustered at the time of consideration. Algorithm 2 appears throughout this paper both explicitly as a step of an algorithm (also for weighted graphs, as it appears in Section 4) and implicitly as a subsequence of actions performed by the greedy algorithm that can be coupled with execution of Algorithm 2. We now state and prove an upper bound on the number of edges that can be actually added by Algorithm 2.
Proposition 13.
The number of edges added by Algorithm 2 is for any .
For the proof we will need the following:
Lemma 14.
Let be a graph with vertices, and with . Let be the graph . Assume moreover the following holds:
-
1.
has girth .
-
2.
For every , either or does not have -cluster in .
Then .
Proof.
Let be the average degree of . Recall that we can always find an induced subgraph of of minimum degree with , by iteratively removing low degree vertices. We claim . Assume towards contradiction that . Let be the last edge from appearing in , and , and observe that clearly we have that the minimum degree of is at least . Since has girth the same holds for the subgraph . Moreover since has girth , the BFS tree around every vertex has no collisions up to radius . We obtain that for any vertex we have
In particular this means every vertex in is -clustered including the endpoints of – contradiction to assumption 2 of the lemma. Hence we conclude that . As we obtain .
Proof of Proposition 13.
Consider the graph on vertex set induced by all the edges added by Algorithm 2. We claim that this graph has girth .
Assume the contrary: there is a cycle of length . Consider the edge , the last edge added by the algorithm along the cycle. All other edges of the cycle were present in at the moment when the algorithm considered and they formed a path between and , hence , which contradicts condition (1) of adding .
Now we see that the sequence of edges added by Algorithm 2 satisfies the conditions of Lemma 14: the high girth condition is just shown and the non-clustered condition is implied by condition (2) of adding an edge. So the desired bound follows.
Now we will state and prove a result for the parallel greedy spanner. The parallel greedy spanner is defined algorithmically as follows.
Definition 15 (Parallel greedy spanner).
In a graph on vertices fix some (ordered) sequence of matchings . We call the output of the Algorithm 3 on input a parallel greedy spanner of .
We shall prove the following:
Proposition 16.
Any parallel greedy spanner of an -vertex graph has at most edges.
Proof.
We first note that by Observation 11, Algorithm 3 never adds an edge that contains a -clustered vertex. This shows that the parallel spanner is the same as the result of the following procedure. Take Algorithm 2 with and modify it as follows: instead of a sequence of edges use a sequence of matchings in and on each step add all the edges from the current matching that are boosting. Since now we add many edges simultaneously, the previous girth argument doesn’t work and we use the neighborhood exchange lemma.
Suppose on the step we add an edge , where is -clustered and is -clustered and , in such case say a boost occur at the vertex . By definition of being -clustered, , where is the current before the -th step. On the other hand, recall that by Claim 11, , and so by Lemma 12 with , , hence , where the last inequality follows from being -clustered.
Such a thing can clearly occur to each vertex for fixed on at most many iterations of Algorithm 3 until gets -clustered, so there are iterations for which is boosted in total (a vertex can’t be clustered). Since the edges added on each iteration are vertex disjoint, the number of boosts on each step is at least the number of added edges, and so the number of added edges is bounded by as required.
Remark 17.
We note that the proof above also shows that the arboricity111111The arboricity of a graph is the minimum integer , such that is a union of forests. It is well known to be equivalent (up to a constant factor), to the minimum such that the edges of can be oriented s.t. every vertex has ingoing edges. of the output of the parallel greedy spanner is . This follows from the previous proof, by orienting the edge from the non-boosted vertex to the boosted one (ties broken arbitrarily).
A Limitation for Removing the Factor Above
We note that in general the factor can’t be removed (in contrast to the standard greedy algorithm). Consider , and the vertex graph of the -hypercube and to be the edges parallel to . Then the endpoints of each edge in the new matching are disconnected in the current spanner, and so the algorithm adds all edges.
Spanner for Path Collections
Let be a collection of paths of length on the vertex set . For a sub-collection denote by . A subcollection is -spanner for if : . The size of the spanner is just .
We now describe the corresponding greedy construction of spanners for path collections.
Observation 18.
If an algorithm returns for any path collection on vertices a spanner of size , then there is an algorithm that given a graph outputs a spanner with many edges.
Proof.
Given a graph apply the let be all length paths in . Let be a spanner of , then is a spanner of of the required size. In light of this, it is enough to obtain bounds for spanner for path collections. The main distinction is that paths in do not have to be shortest in any form in the definition above.
3 Analysis of the Greedy algorithm
The main goal of this section is to prove the following:
Theorem 19.
The greedy algorithm for path collections, Algorithm 4, Outputs a spanner with -paths, and runs in polynomial time.
By Observation 18 this would also prove that any graph with vertices has a spanner of size .
On a high level, the proof is based on showing that whenever a -path is added, distances in the current shrink in a structured way. Initially a path addition affects local geometry, but over time each addition produces a larger global effect.
Let denote the -th -path added by the algorithm, and let
be the subgraph consisting of all edges that were added before adding the current path .
Claim 20.
If is added, then either or .
Proof.
Since was added, . By the triangle inequality,
so at least one of the two summands exceeds .
We call an -distant pair if . Thus every added path yields at least one distant pair. We assume wlog is the distant pair, otherwise – reverse the order of the path. For the analysis, set
Think of as the radius up to which we bound the local effect of path additions. When -balls become sufficiently large, we switch to a different, global counting argument. The notation of is mostly to unify the analysis of both even and odd – the main property we will use about is that always.
Clusters
We use the definition of clusters from Section 2, see Definition 10, and we need the following addition to it to simplify the terminology.
Definition 21 (Fully clustered vertices).
If has an -cluster, we say is fully clustered.
This coincides with the definition given in Section 2 with .
Boosting Steps
An -distant pair is boosting if at least one of is not fully clustered in . We call the step of the algorithm boosting if at least one -distant pair is boosting. This coincides with the definition of boosting from Section 2 with .
Lemma 22.
The total number of boosting steps over all vertices is .
Proof.
In full version.
Remark 23.
Cluster sizes are (weakly) monotone: since , we have for all . Thus once has an -cluster, it keeps it thereafter.
3.1 Lateral Clustering
The discussion above accounts for boosting steps, which imply that the distant edge of each remaining path has clustered endpoints. In particular, for the argument to go through we would like to show that even the vertex on which doesn’t participate in the distant pair will have a big ball around it. To handle this we introduce:
-
Lateral clusters: formed around the not-necessarily-distant endpoint of the newly added -path.
-
A global counting argument, once clusters are full which resembles the path-buying technique.
Definition 24 (Lateral clusters).
A vertex has an lateral cluster in if .
From now on, when is not boosting and is the -distant pair, we examine lateral clusters around .
Definition 25 (Lateral boosting).
We say a lateral boost occurs at step (for the non-distant endpoint ) if:
-
(i)
is not -laterally clustered in ; and
-
(ii)
.
In this case, we say is laterally boosted.
Claim 26.
If is laterally boosted at step , then
Proof.
All vertices in lie outside but lie inside after adding , by concatenating and a shortest path in from to .
Therefore we have:
Claim 27.
Every vertex can be laterally boosted at most times.
Proof.
If is laterally boosted then
hence any vertex has an -ball of size after lateral boosts.
Corollary 28 (Non-boosting steps that are laterally boosted).
The number of indices for which the -distant pair is not boosting and a lateral boost occurs is .
We now bound all remaining non-boosting steps (steps that do not have a boosting distant pair, and do not trigger a lateral boost).
Lemma 29.
Let be a step whose -distant pair is not boosting, and assume no lateral boost occurs because condition (i) fails (i.e., already has an -lateral cluster in ). Then the number of such steps is .
Proof.
In full version.
Lemma 30.
Let be a step whose -distant pair is not boosting, and assume no lateral boost occurs because condition (ii) fails, i.e.,
Then the number of such steps is .
Proof.
In full version.
Proof of Theorem 19.
In full version.
We need the following formulation of Theorem 19 for the construction of FT-spanners.
Theorem 31 (Equivalent combinatorial formulation).
Let be an unweighted graph and let be 2-paths with such that for all . Then .
Proof.
Processing the paths in order, each is added by the greedy rule by assumption, so the number of additions equals . Apply Theorem 19.
4 Improved Stretch for Weighted Graphs
We refer the reader to Section 1.5 to recall notations used for weighted graphs. We remind the reader the objective of this section.
Goal.
Construct, in polynomial time, a weighted subgraph of size such that for every -edge path in there is an path in of weight at most
We note that the stretch bound above is optimal assuming the Erdős girth conjecture as we now elaborate.
Claim 32.
Assuming the Erdős girth conjecture holds, for each there is a weighed graph on vertices with edges such that for all proper subgraphs there is a -path in such that .
Proof.
Take a graph on vertices with edges and of girth , promised by the Erdős girth conjecture. We can assume that is connected (otherwise connect components by a tree). Let all weights of the edges of be . Then for each vertex add a new vertex and an edge of weight . Let be the resulting graph. Let be a proper subgraph of . Suppose that for some we have . Then take a neighbor of in (such exists because is connected.) Then , but , since is a leaf in . Thus we can assume that all leaf edges are in , and since is proper, there is some . Take , then , where the second inequality follows from the high girth assumption.
We keep the same notation for as appears in Section 3. Also for the unweighted graphs that appear in this section we us the same terminology related to distances, balls and being (laterally) clustered as in the previous sections.
The algorithm
We now proceed with describing an algorithm that produces a spanner as promised in Theorem 41. We now define each of the five phases of the algorithm formally, and refer the reader to the technical overview a description on a higher level.
Phase 1: Initialization
Initialize to contain any -spanner of with edges (e.g., by the standard greedy construction). This guarantees that any -path having at least one edge already in attains the target stretch.
Observation 33.
For any -path , if either or , then .
Phase 2: Clustering
Process edges in nondecreasing order of weight . Let be the underlying unweighted graph of the current restricted to edges of weight at most . If
-
(i)
, and
-
(ii)
at least one of is not fully clustered in ,
add to . An edge that met (i) but was not added (because both endpoints were already fully clustered) is called saturated. We call edges added in this phase clustering edges.
Lemma 34 (Phase-2 size).
The number of clustering edges is .
Proof.
In full version.
Claim 35 (Saturated edges).
If an edge is saturated at threshold , then both and are fully clustered already in the (unweighted) graph formed by edges added before reached weight . Consequently, if (resp. ) denotes the minimum threshold at which (resp. ) becomes fully clustered, then and .
Phase 3: Lateral Clustering
For each , process its neighbors with fully clustered, in increasing order of the key
where is the threshold at which first became fully clustered. If , skip . In this case we say the candidate is saturated when cosidered by ; Otherwise let
and test if ; if so, add the edge to . Such an added edge is called a lateral clustering edge. If the test fails because , we say the cluster of is roughly contained in the lateral cluster of .
Claim 36 (Phase-3 size).
Each vertex adds lateral clustering edges; hence Phase 3 contributes edges overall.
Proof.
In full version.
Phase 4: Global Distance Reduction by Edges
Process edges of in nondecreasing order of weight . If , define
If , add to (and test symmetrically with swapped). Edges added here are distance-reduction edges. An edge that met but was not added has roughly close clusters.
Claim 37 (Phase-4 size).
Phase 4 adds edges.
Proof.
In full version.
A Key Combinatorial Lemma
We now capture a type of -paths that achieve the desired stretch of the spanner due to the application of phases 3 and 4. Such a -path, say has one edge with fully clustered ends which wasn’t added in phase 4, and one edge which wasn’t added in phase as ’s cluster was already roughly contained in ’s lateral cluster. We will show that in such a case the path has the desired stretch.
Lemma 38.
Let be a -path in . Assume that:
-
(a)
has roughly close clusters (so both and are fully clustered and Phase 4 did not add ), and
-
(b)
the cluster of is roughly contained in the lateral cluster of (so Phase 3, when considered from , did not add for failing the -test).
Let be the subgraph consisting of all edges added prior to the (latest) consideration of either in Phase 4 or in Phase 3. Then
Proof.
In full version.
Phase 5: Greedy Path Additions (Final Repairs)
Let be the set of -paths that still lack a replacement path in of weight at most .
Lemma 39.
Every contains a saturated edge.
Proof.
In full version.
By the above lemma, for each we can choose: (1) one saturated edge , and (2) the other edge (“lat” for lateral). For the greedy phase process the paths of in increasing order of the key: When a path is encountered, if the desired replacement path is still absent, insert both edges of into .
Claim 40 (Phase-5 size).
Phase 5 adds paths (hence edges).
Proof.
In full version.
Correctness and Size
Recall that for a path , denotes the sum of the highest weights along .
Theorem 41.
Given a graph the algorithm above outputs a subgraph s.t.:
-
1.
For any two vertices and a path between them we have ;
-
2.
.
Proof.
In full version.
5 Fault Tolerant Spanners
Definition 42 (EFT spanner).
Let be a (multi)graph and . A subgraph is an -edge-fault tolerant (-EFT) spanner if for every with and all ,
We next describe the greedy construction used throughout this section.
By construction, the output of Algorithm 5 is an -EFT spanner. To bound the size, we formalize the obstruction to adding a path via blocking sets.
Definition 43 ( blocking set).
Let be paths of length on a common vertex set . We say they admit an edge-blocking set if for every there exists a set with and such that
Every ordered pair with is called a block.
Claim 44.
Let be the -paths added by Algorithm 5. Then they admit an edge-blocking set.
Proof.
For each let be the set required by Algorithm 5 to add to the current spanner . It means that , and . This shows that the sets satisfy Definition 43.
In light of the above, it’s enough to obtain combinatorial bounds on the size of path collections with an blocking set, to conclude size bounds on the output of the FT greedy algorithm. We first observe that one can reduce the size of FT greedy spanners and the corresponding standard greedy spanners by sub-sampling, as appears in [14]. Let denote the maximum number of length- paths that can be added by the non-FT greedy process for path collections Algorithm 4 on an -vertex input (i.e., the standard greedy that adds a path whenever the current distance between its endpoints exceeds ).
Theorem 45.
Suppose admit an edge-blocking set. Then
Proof.
In full version.
For paths of length 2 we can improve and get:
Theorem 46.
Let be the collection of paths that has a edge blocking set. Then .
Proof.
In full version.
Observation 47.
The union of an -EFT spanner and an -EFT spanner is a -EFT spanner. In particular, if we take the spanner constructed above and an optimal spanner, we get a -EFT spanner of size .
Proof.
In full version.
A Matching Lower Bound
The size of the -EFT spanner we obtained here is the best possible assuming the girth conjecture of Erdős. Take an Erdős graph on vertices with edges and girth strictly greater than , replace each edge by parallel edges and then attach a leaf to each vertex. Such a graph has no proper -EFT spanner. For -EFT -spanner the same construction without adding leaves has no proper -EFT -spanner.
6 Conclusions
In this work we suggested a simple greedy procedure to obtain a spanner, and gave tight constructions of -EFT for multigraphs, as well as a construction that takes a graph as input, and outputs a subgraph approximating weighted paths of hop-length in , with optimal size/stretch tradeoff.
In follow-up work together with Parter, we give an bound for spanners supporting vertex faults, nearly matching the lower bound of [10]. We also prove that the greedy spanner has similar size guarantees to the spanners of Ben-Levy and Parter [9], and analyze the corresponding FT-greedy spanner to obtain truly polynomial (in ) constructions achieving the stretch of the constructions of [9], for every fixed .
References
- [1] Amir Abboud and Greg Bodwin. The 4/3 additive spanner exponent is tight. J. ACM, 64(4):28:1–28:20, 2017. doi:10.1145/3088511.
- [2] Abu Reyan Ahmed, Greg Bodwin, Keaton Hamm, Stephen G. Kobourov, and Richard Spence. On additive spanners in weighted graphs with local error. In Lukasz Kowalik, Michal Pilipczuk, and Pawel Rzazewski, editors, Graph-Theoretic Concepts in Computer Science - 47th International Workshop, WG 2021, Warsaw, Poland, June 23-25, 2021, Revised Selected Papers, volume 12911 of Lecture Notes in Computer Science, pages 361–373. Springer, 2021. doi:10.1007/978-3-030-86838-3_28.
- [3] Abu Reyan Ahmed, Greg Bodwin, Faryad Darabi Sahneh, Keaton Hamm, Mohammad Javad Latifi Jebelli, Stephen G. Kobourov, and Richard Spence. Graph spanners: A tutorial review. Comput. Sci. Rev., 37:100253, 2020. doi:10.1016/J.COSREV.2020.100253.
- [4] Abu Reyan Ahmed, Greg Bodwin, Faryad Darabi Sahneh, Stephen G. Kobourov, and Richard Spence. Weighted additive spanners. In Isolde Adler and Haiko Müller, editors, Graph-Theoretic Concepts in Computer Science - 46th International Workshop, WG 2020, Leeds, UK, June 24-26, 2020, Revised Selected Papers, volume 12301 of Lecture Notes in Computer Science, pages 401–413. Springer, 2020. doi:10.1007/978-3-030-60440-0_32.
- [5] Ingo Althöfer, Gautam Das, David P. Dobkin, Deborah Joseph, and José Soares. On sparse spanners of weighted graphs. Discret. Comput. Geom., 9:81–100, 1993. doi:10.1007/BF02189308.
- [6] Surender Baswana, Telikepalli Kavitha, Kurt Mehlhorn, and Seth Pettie. Additive spanners and (alpha, beta)-spanners. ACM Trans. Algorithms, 7(1):5:1–5:26, 2010. doi:10.1145/1868237.1868242.
- [7] Surender Baswana and Sandeep Sen. Approximate distance oracles for unweighted graphs in time. In Proceedings of the Fifteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 271–280, 2004. URL: http://dl.acm.org/citation.cfm?id=982792.982830.
- [8] Surender Baswana and Sandeep Sen. A simple and linear time randomized algorithm for computing sparse spanners in weighted graphs. Random Struct. Algorithms, 30(4):532–563, 2007. doi:10.1002/rsa.20130.
- [9] Uri Ben-Levy and Merav Parter. New (, ) spanners and hopsets. In Shuchi Chawla, editor, Proceedings of the 2020 ACM-SIAM Symposium on Discrete Algorithms, SODA 2020, Salt Lake City, UT, USA, January 5-8, 2020, pages 1695–1714. SIAM, 2020. doi:10.1137/1.9781611975994.104.
- [10] Greg Bodwin, Michael Dinitz, Merav Parter, and Virginia Vassilevska Williams. Optimal vertex fault tolerant spanners (for fixed stretch). In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 1884–1900, 2018. doi:10.1137/1.9781611975031.123.
- [11] Greg Bodwin, Michael Dinitz, and Caleb Robelle. Optimal vertex fault-tolerant spanners in polynomial time. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 2924–2938, 2021. doi:10.1137/1.9781611976465.174.
- [12] Greg Bodwin, Michael Dinitz, and Caleb Robelle. Partially optimal edge fault-tolerant spanners. In Proceedings of the 2022 ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 3272–3286, 2022. doi:10.1137/1.9781611977073.129.
- [13] Greg Bodwin, Bernhard Haeupler, and Merav Parter. Fault-tolerant spanners against bounded-degree edge failures: Linearly more faults, almost for free. In David P. Woodruff, editor, Proceedings of the 2024 ACM-SIAM Symposium on Discrete Algorithms, SODA 2024, Alexandria, VA, USA, January 7-10, 2024, pages 2609–2642. SIAM, 2024. doi:10.1137/1.9781611977912.93.
- [14] Greg Bodwin and Shyamal Patel. A trivial yet optimal solution to vertex fault tolerant spanners. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, PODC, pages 541–543, 2019. doi:10.1145/3293611.3331588.
- [15] Gilad Braunschvig, Shiri Chechik, David Peleg, and Adam Sealfon. Fault tolerant additive and (, )-spanners. Theor. Comput. Sci., 580:94–100, 2015. doi:10.1016/J.TCS.2015.02.036.
- [16] Leizhen Cai and J. Mark Keil. Computing visibility information in an inaccurate simple polygon. Int. J. Comput. Geom. Appl., 7(6):515–538, 1997. doi:10.1142/S0218195997000326.
- [17] Shiri Chechik. New additive spanners. In Sanjeev Khanna, editor, Proceedings of the Twenty-Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2013, New Orleans, Louisiana, USA, January 6-8, 2013, pages 498–512. SIAM, 2013. doi:10.1137/1.9781611973105.36.
- [18] Shiri Chechik, Michael Langberg, David Peleg, and Liam Roditty. Fault tolerant spanners for general graphs. SIAM J. Comput., 39(7):3403–3423, 2010. doi:10.1137/090758039.
- [19] Julia Chuzhoy and Merav Parter. Fully dynamic algorithms for graph spanners via low-diameter router decomposition. In Yossi Azar and Debmalya Panigrahi, editors, Proceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2025, New Orleans, LA, USA, January 12-15, 2025, pages 785–823. SIAM, 2025. doi:10.1137/1.9781611978322.23.
- [20] Edith Cohen. Polylog-time and near-linear work approximation scheme for undirected shortest paths. J. ACM, 47(1):132–166, 2000. doi:10.1145/331605.331610.
- [21] Lenore Cowen. Compact routing with minimum stretch. J. Algorithms, 38(1):170–183, 2001. doi:10.1006/jagm.2000.1134.
- [22] Lenore Cowen and Christopher G. Wagner. Compact roundtrip routing in directed networks. J. Algorithms, 50(1):79–95, 2004. doi:10.1016/j.jalgor.2003.08.001.
- [23] Michael Dinitz and Robert Krauthgamer. Fault-tolerant spanners: better and simpler. In Proceedings of the 30th Annual ACM Symposium on Principles of Distributed Computing, PODC, pages 169–178, 2011. doi:10.1145/1993806.1993830.
- [24] Michael Dinitz and Caleb Robelle. Efficient and simple algorithms for fault-tolerant spanners. In PODC ’20: ACM Symposium on Principles of Distributed Computing, pages 493–500, 2020. doi:10.1145/3382734.3405735.
- [25] Andrew Dobson and Kostas E. Bekris. Sparse roadmap spanners for asymptotically near-optimal motion planning. Int. J. Robotics Res., 33(1):18–47, 2014. doi:10.1177/0278364913498292.
- [26] Michael Elkin. Computing almost shortest paths. In Ajay D. Kshemkalyani and Nir Shavit, editors, Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing, PODC 2001, Newport, Rhode Island, USA, August 26-29, 2001, pages 53–62. ACM, 2001. doi:10.1145/383962.383983.
- [27] Michael Elkin, Yuval Emek, Daniel A. Spielman, and Shang-Hua Teng. Lower-stretch spanning trees. SIAM J. Comput., 38(2):608–628, 2008. doi:10.1137/050641661.
- [28] Michael Elkin, Yuval Gitlitz, and Ofer Neiman. Almost shortest paths with near-additive error in weighted graphs. In Artur Czumaj and Qin Xin, editors, 18th Scandinavian Symposium and Workshops on Algorithm Theory, SWAT 2022, June 27-29, 2022, Tórshavn, Faroe Islands, volume 227 of LIPIcs, pages 23:1–23:22. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2022. doi:10.4230/LIPIcs.SWAT.2022.23.
- [29] Michael Elkin, Yuval Gitlitz, and Ofer Neiman. Improved weighted additive spanners. Distributed Comput., 36(3):385–394, 2023. doi:10.1007/S00446-022-00433-X.
- [30] Michael Elkin and David Peleg. (1+epsilon, beta)-spanner constructions for general graphs. SIAM J. Comput., 33(3):608–631, 2004. doi:10.1137/S0097539701393384.
- [31] Bernhard Haeupler, D. Ellis Hershkowitz, and Zihan Tan. Parallel greedy spanners. CoRR, abs/2304.08892, 2023. doi:10.48550/arXiv.2304.08892.
- [32] Bernhard Haeupler, Jonas Hübotter, and Mohsen Ghaffari. A cut-matching game for constant-hop expanders. In Yossi Azar and Debmalya Panigrahi, editors, Proceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2025, New Orleans, LA, USA, January 12-15, 2025, pages 1651–1678. SIAM, 2025. doi:10.1137/1.9781611978322.51.
- [33] An La and Hung Le. New weighted additive spanners. CoRR, abs/2408.14638, 2024. doi:10.48550/arXiv.2408.14638.
- [34] James D. Marble and Kostas E. Bekris. Asymptotically near-optimal planning with probabilistic roadmap spanners. IEEE Trans. Robotics, 29(2):432–444, 2013. doi:10.1109/TRO.2012.2234312.
- [35] Merav Parter. Bypassing erdős’ girth conjecture: Hybrid stretch and sourcewise spanners. In Javier Esparza, Pierre Fraigniaud, Thore Husfeldt, and Elias Koutsoupias, editors, Automata, Languages, and Programming - 41st International Colloquium, ICALP 2014, Copenhagen, Denmark, July 8-11, 2014, Proceedings, Part II, volume 8573 of Lecture Notes in Computer Science, pages 608–619. Springer, 2014. doi:10.1007/978-3-662-43951-7_49.
- [36] Merav Parter. Nearly optimal vertex fault-tolerant spanners in optimal time: sequential, distributed, and parallel. In STOC ’22: 54th Annual ACM SIGACT Symposium on Theory of Computing, pages 1080–1092, 2022. doi:10.1145/3519935.3520047.
- [37] Merav Parter, Asaf Petruschka, Shay Sapir, and Elad Tzalik. Parks and recreation: Color fault-tolerant spanners made local. In Yossi Azar and Debmalya Panigrahi, editors, Proceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2025, New Orleans, LA, USA, January 12-15, 2025, pages 4061–4094. SIAM, 2025. doi:10.1137/1.9781611978322.139.
- [38] Merav Parter and Elad Tzalik. Connectivity certificate against bounded-degree faults: Simpler, better and supporting vertex faults. In Ioana Oriana Bercea and Rasmus Pagh, editors, 2025 Symposium on Simplicity in Algorithms, SOSA 2025, New Orleans, LA, USA, January 13-15, 2025, pages 369–377. SIAM, 2025. doi:10.1137/1.9781611978315.28.
- [39] David Peleg and Alejandro A. Schäffer. Graph spanners. J. Graph Theory, 13(1):99–116, 1989. doi:10.1002/jgt.3190130114.
- [40] David Peleg and Jeffrey D. Ullman. An optimal synchronizer for the hypercube. SIAM J. Comput., 18(4):740–747, 1989. doi:10.1137/0218050.
- [41] David Peleg and Eli Upfal. A tradeoff between space and efficiency for routing tables. In Proceedings of the 20th Annual ACM Symposium on Theory of Computing, STOC, pages 43–52, 1988. doi:10.1145/62212.62217.
- [42] Asaf Petruschka, Shay Sapir, and Elad Tzalik. Color fault-tolerant spanners. In 15th Innovations in Theoretical Computer Science Conference, ITCS, volume 287 of LIPIcs, pages 88:1–88:17. Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2024. doi:10.4230/LIPIcs.ITCS.2024.88.
- [43] Oren Salzman, Doron Shaharabani, Pankaj K. Agarwal, and Dan Halperin. Sparsification of motion-planning roadmaps by edge contraction. Int. J. Robotics Res., 33(14):1711–1725, 2014. doi:10.1177/0278364914556517.
- [44] Mikkel Thorup and Uri Zwick. Compact routing schemes. In Proceedings of the Thirteenth Annual ACM Symposium on Parallel Algorithms and Architectures, SPAA, pages 1–10, 2001. doi:10.1145/378580.378581.
- [45] Mikkel Thorup and Uri Zwick. Approximate distance oracles. J. ACM, 52(1):1–24, 2005. doi:10.1145/1044731.1044732.
- [46] Mikkel Thorup and Uri Zwick. Spanners and emulators with sublinear distance errors. In Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2006, Miami, Florida, USA, January 22-26, 2006, pages 802–809. ACM Press, 2006. URL: http://dl.acm.org/citation.cfm?id=1109557.1109645.