Recovering Communities in Structured Random Graphs

Abstract
The problem of recovering planted community structure in random graphs has received a lot of attention in the literature on the stochastic block model, where the input is a random graph in which edges crossing between different communities appear with smaller probability than edges induced by communities. The communities themselves form a collection of vertex-disjoint sparse cuts in the expected graph, and can be recovered, often exactly, from a sample as long as a separation condition on the intra- and inter-community edge probabilities is satisfied.
In this paper, we ask whether the presence of a large number of overlapping sparsest cuts in the expected graph still allows recovery. For example, the -dimensional hypercube graph admits distinct (balanced) sparsest cuts, one for every coordinate. Can these cuts be identified given a random sample of the edges of the hypercube where each edge is present independently with some probability ? We show that this is the case, in a very strong sense: the sparsest balanced cut in a sample of the hypercube at rate for a sufficiently large constant is -close to a coordinate cut with high probability. This is asymptotically optimal and allows approximate recovery of all cuts simultaneously. Furthermore, for an appropriate sample of hypercube-like graphs recovery can be made exact. The proof is essentially a strong hypercube cut sparsification bound that combines a theorem of Friedgut, Kalai and Naor on boolean functions whose Fourier transform concentrates on the first level of the Fourier spectrum with Karger’s cut counting argument.
Keywords and phrases:
Hypercube graphs, Community detection, Fourier analysis of Boolean functionsCopyright and License:
2012 ACM Subject Classification:
Theory of computation Graph algorithms analysis ; Mathematics of computing Random graphsEditor:
Shubhangi SarafSeries and Publisher:
1 Introduction
Graph clustering, or community detection, is a fundamental problem in data analysis. The input is a graph , where a subset of vertices is considered a “community” if it is sparsely connected to the rest of the graph and is reasonably well-connected as an induced subgraph. The task is to recover the communities.
Graph clustering with a planted solution has received a lot of attention in the literature. In this setting the vertex set of the graph is assumed to be partitioned into vertex disjoint clusters such that the clusters induce well-connected subgraphs and are sparsely connected to the rest of the graph[24, 15, 13, 23, 16, 29, 31, 32, 3, 10]. For example, in the stochastic block model (SBM; [1]) edges of are generated independently, where an edge is included in the graph with higher probability if and belong to the same cluster, and lower probability otherwise. A large body of work on the stochastic block model shows that, if the edge probabilities satisfy a separation condition, the communities can be recovered from a sample graph with high probability. Determining the exact recovery threshold is a fascinating information theoretic problem for which tight bounds have been obtained over the past two decades [14, 30, 35, 12, 32, 3, 5]. Most of the work on SBM has focused on the case of non-overlapping communities, with only a few works allowing for some overlap. At the same time, in the practice of graph clustering one typically does not expects to have very pronounced cluster. Instead, several clusterings of the vertex set may be consistent with the edge set of the graph. Our central question in this paper is:
Can highly overlapping clusterings be recovered from a sample of the underlying graph?
Perhaps the most basic example of a graph with a large number of overlapping communities is the hypercube graph on vertices, where each of coordinate cuts is a sparsest cut, and defines a partition of the vertex set into two “communities”, namely the two corresponding coordinate halfspaces. This setting is very different from the SBM with two communities, where the expected graph is a union of two cliques on the two clusters and a clique on the entire vertex set, and therefore the two communities are uniquely defined. Formally, the main question we ask in this paper is a structured version of the stochastic block model that allows for many communities with large overlaps:
Can coordinate cuts be recovered from the edge set of a subsampled hypercube?
A priori it would seem plausible that cuts of sparsity comparable to the coordinate cuts may emerge in a subsampled hypercube. Intuitively, this could be a mixture of several coordinate cuts in the original cube (a similar effect is seen in rounding the SDP solution to the sparsest cut problem on the hypercube). However, we show that this is not the case:
Theorem 1.
Let be the -dimensional hypercube, and let be obtained by including each edge with probability , where is a sufficiently large constant. There exists an algorithm with running time that, given , recovers orthogonal balanced cuts, each with Hamming distance to a coordinate cut, with probability at least over the subsampling.
We say that a cut is balanced if . The Hamming distance between two sets is given by , and we say and are orthogonal cuts if . We also remind the reader of the definition of the -dimensional hypercube graph:
Definition 2 (Hypercube).
Define the -dimensional hypercube to be the graph with vertex set , and any two vertices are connected by an edge if their Hamming distance is exactly . We let denote the number of vertices.
We note that the subsampling rate in Theorem 1 is such that the expected degree of a vertex is at least , i.e. Theorem 1 allows for an exponential reduction of the average degree after sampling. The guarantee in Theorem 1 is tight up to factors, since the expected number of isolated vertices in is at least . To see this, note that the degree of each vertex in is distributed as . For , the probability that a given vertex is isolated is
So in expectation, at least vertices are isolated, and we cannot hope to classify those vertices.
Exact recovery
Furthermore, we show that, similarly to SBM, exact recovery is possible for a sufficiently high degree sample, specifically, a sample where every vertex has expected degree at least for a sufficiently large constant . The hypercube itself is not a good model to study this setting, as the degree in the hypercube itself is . We therefore study the -distance hypercube, defined below:
Definition 3 (-distance hypercube).
Define the -distance hypercube to be the graph with vertex set , and any two vertices are connected by an edge if their Hamming distance is exactly .
When is odd, the graph is connected. When is even, splits into two connected components, corresponding to the vertices of even and odd Hamming weight, respectively:
where denotes the Hamming weight of .
We show that if the sampling rate is such that a given vertex has at least logarithmic expected degree, exact recovery is possible:
Theorem 4.
Let be a connected component of the -dimensional -distance hypercube . Let be obtained by including each edge with probability , where is a sufficiently large constant. There exists an algorithm with running time that, given , exactly recovers the coordinate cuts, with probability over the subsampling.
Related work on community detection on graphs with overlapping communities
A small number of works allow for overlapping communities. [5] considers SBM with overlapping communities, and observes that this can be reduced to a standard SBM where each “community membership profile” is considered as a separate community. The number of profiles would be too large for our setting, making every vertex in the hypercube have a profile of its own. The work of [37] considers a variant of the SBM with fractional community memberships and proves asymptotic consistency under strong assumptions, such as the existence of “pure” nodes that only belong to one community. Another line of work considers dense graphs [7], but requires much higher densities than in our setting.
Related work on community detection in geometric random graphs
The geometric block model, introduced in [34], generalizes random geometric graphs in the same way that SBMs generalize Erdős–Rényi graphs: In this model, vertices are partitioned into communities, randomly embedded in a metric space, and edges are formed as a function of distances and community memberships. A number of variants and extensions have since been studied [19, 20, 21, 26, 4, 2, 22, 8, 6]. These works, however, focus on detecting (non-overlapping) communities and do not provide guarantees for recovering underlying geometric structure.
Open problem
Our work leaves open a very exciting open problem of recovering coordinate cuts with the same precision as our results, but in polynomial time. The SoS hierarchy seems to be a promising direction.
2 Proof of Theorem 1
In this section we prove Theorem 1. The proof is algorithmic. We state the (simple) algorithm below, and then proceed to analyze it.
The algorithm
Our algorithm finds orthogonal sparse cuts in the subsampled hypercube by solving the optimization problem (solved by direct enumeration in time ):
| (1) | ||||||
Known results from Fourier analysis show that before subsampling, every sparse cut in the hypercube is close (in Hamming distance) to a coordinate cut. Using this, we will prove that after subsampling, all cuts that are far from coordinate cuts remain large, and will therefore not be a part of the optimal solution to (1).
We will need tools from Fourier analysis of boolean functions, and start by setting up the necessary preliminaries.
Preliminaries
Let denote the -dimensional hypercube with vertex set and edges connecting pairs of vertices that differ in exactly one coordinate. We write for the set of edges obtained from after subsampling. For a subset , we sometimes write for its indicator function, and for its edge boundary. We say that a cut is balanced if , and we say that cuts are orthogonal if . For , , we use the notation for the coordinate cut .
For a function , we define its Fourier transform by
where is the the Fourier character . We call the Fourier coefficient of at .
The Fourier characters form an orthogonal basis for functions on , which gives the inverse formula
and Parseval’s identity
Furthermore, for every , the Fourier character is an eigenvector with eigenvalue of the unnormalized Laplacian matrix of the hypercube.
Finally, we need the fact that the singleton cuts are the minimum cuts in a hypercube.
Lemma 5 (Folklore, see e.g., Example 4.1.3 in [36]).
The min cut of the -dimensional hypercube has size , that is
Every sparse cut is close to a coordinate cut
We begin by showing that every cut that is sparse in the original hypercube is indeed close to a coordinate cut. For this, we use the following standard Fourier–analytic identity, which expresses the size of a cut in terms of the Fourier coefficients of its indicator function (see e.g. Theorem 2.38 in [33]). We include a proof for completeness.
Lemma 6.
Let be the -dimensional hypercube, and let . Let denote the indicator function on . Then
Proof.
Let be the unnormalized Laplacian of . The cut size of is given by
| (2) |
Expanding in the Fourier basis, we have Since the Fourier characters are eigenvectors of with eigenvalues , we obtain
| (3) |
Combining Equations (2) and (3) gives the lemma. From the above lemma, we will show that every sparse cut must place most of its Fourier mass on the first two levels. This is because the contribution of each Fourier coefficient to the cut size is weighted by , so the mass on higher levels contributes to the cut size proportionally.
This will allow us to apply the Friedgut–Kalai–Naor (FKN) theorem, which states that any boolean function with nearly all of its Fourier mass on the first two levels, has to be close to the indicator function of a coordinate cut.
Theorem 7 (FKN Theorem, Theorem 1.1 in [18]).
If is a boolean function, and if then either or or for some or for some . Here, and are absolute constants.
We remark that the conclusion of the FKN theorem is far from obvious. In particular, the assumption that is a boolean function is essential. For example, consider a convex combination of coordinate cuts . This places all of its Fourier mass on the first two levels, but is in general not close to any coordinate cut.
A corollary of the FKN Theorem (Theorem 7) is that every sparse cut in the hypercube must be close to a coordinate cut. For completeness, we include a proof of this known fact.
Lemma 8 (Sparse cuts are close to coordinate cuts, Corollary 1.2 in [18]).
Suppose with . If , then there exists a coordinate cut such that
Here is an absolute constant.
Proof.
We start by bounding the Fourier mass above the first two levels in order to apply the FKN theorem (Theorem 7). Suppose . From Lemma 6, we have
| (4) |
On the other hand, we have
| (5) |
and, since , we have
| (6) |
Combining Equations (4), (5) and (6) gives
| by (4) and (5) | ||||
The second summand is non-negative by the assumption that , which gives . Therefore, by Theorem 7 we have or . Finally, to rule out the second possibility, note that the above equation gives , which rearranges to .
Cut counting on the difference from a coordinate cut
Next, we want to show that a cut that is far (in Hamming distance) from every coordinate cut, cannot become the sparsest cut after subsampling. Let be a cut with and . Then for some coordinate cut . We want to show that with a high probability, , i.e. that the coordinate cut is still sparser than after subsamling. To show this, we want to apply the Chernoff bound to show concentration for each cut, and Karger’s cut-counting theorem to union bound over all possible choices of the cut .
Theorem 9 (Karger’s cut counting theorem [25]).
Let . Then for all graphs , the number of -approximate minimum cuts in is at most .
We start by noting that a direct cut counting plus Chernoff bound argument does not work. Indeed, a direct Chernoff bound applied to and would require concentration within a factor for all simultaneously, which is too strong. Instead, we use the fact that is close to , and show that the differences and concentrate well. In essence, we apply a Karger-style cut counting argument on the difference between , thereby only requiring the Chernoff bound to handle a constant factor deviation.
Applying a Chernoff bound, using the trivial upper-bound
we can show that and concentrate within a -factor with probability at least
To union bound, we must enumerate over all cuts with . A naive application of Karger’s theorem (using , by Lemma 5) shows that there are at most such cuts, which is too weak of a bound.
Instead, we observe that for a fixed coordinate cut , the set is uniquely determined by , so it suffices to enumerate the possible choices for . Applying Karger’s cut-counting theorem with the trivial bound gives that there are at most possible choices for the set . However, this bound is still too weak. We will therefore derive a stronger bound on and .
Lemma 10.
Let be a set with and and let be the coordinate cut such that (exists by Lemma 8). Then there exists a universal constant such that
Proof.
It is straightforward to verify that for every pair of sets , it holds that , which gives the first inequality. We now prove the second inequality.
Let and . Furthermore, write . Then is partitioned into the four sets , , and (see Figure 1).
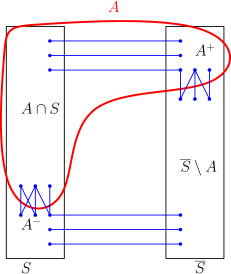
The high-level idea is that the edge boundaries of and consist of and , which cross the cut , and and , which cross the cut . Since the former two sets cross the coordinate cut, they have size at most . Since the latter two sets contribute to the cut , they cannot be too large, as otherwise the edge-boundary of would have size significantly larger than We now prove this more formally.
Claim 11.
Proof.
Since is partitioned into and , and is partitioned into and , we have
Similarly, since is partitioned into and , and is partitioned into and , we have
Combining, we get
On the other hand, we have
Combining the above two equations yields the claim.
To continue, note that the edges in and in are crossing the coordinate cut . Since is a coordinate cut, every vertex can have at most one edge crossing incident on it. This gives
| (7) |
where the last inequality follows by the lemma assumption. Combining with Claim 11, and recalling from the lemma assumption that , we obtain
| by Claim (11) | ||||
| by Equation (7) | ||||
| by the lemma assumption | ||||
| for | ||||
which completes the proof. With this stronger bound on , we can now bound the number of cuts of size .
Lemma 12.
Let be a coordinate cut. The number of sets of size such that and is at most .
Proof.
Let be of size such that and . Given , the set is uniquely determined by the choice of , so we just need to count the number of possible choices for . Letting denote the universal constant in Lemma 10, we have
On the other hand, by Lemma 5, the minimum cut has size , so is an -approximate minimum cut with Therefore, by Karger’s cut counting theorem (Theorem 9), the number of choices for is at most
Here denotes the binary entropy function
To bound the deviation of the cut sizes after subsampling, we use the additive Chernoff bound (see e.g., Theorems 1.10.10 and 1.10.11 in [17]).
Theorem 13.
Let be independent random variables taking values in . Let . Let . Then
Applying the Chernoff bound, we show that with high probability, every cut remains larger than its closest coordinate cut after subsampling.
Lemma 14.
Let and let be a set of size such that Let be the coordinate cut such that (exists by Lemma 8). Then
Proof.
Let and let . We have
So we need to bound the probability of the event From the lemma assumption, we have
| (8) |
By Lemma 10, we have
Let Then , so applying the Chernoff bound (Lemma 13), we get
and
By a union bound, with probability at least , it holds that
where the second inequality follows from Equation (8). We can now show that every sufficiently large cut remains larger than a coordinate cut after subsampling.
Lemma 15.
Let for a sufficiently large constant , and let . Then with probability at least , the following holds: For every and every balanced cut of size , it holds that
where is the coordinate cut such that (exists by Lemma 8).
Proof.
Suppose , where denotes the hidden constant in the -notation in Lemma 12 and denotes the hidden constant in the -notation in Lemma 14. Let for . For every coordinate cut with and , and for every , let be the event that there exists a cut of size with such that
We now show that For every cut of size with , by Lemma 14, we have
By Lemma 12, the number of such cuts is at most . Therefore, by a union bound, we have
since and
since
since
for sufficiently large.
Finally, taking a union bound over the possible choices of and the possible choices for , gives the lemma. Lemma 15 implies that the sparsest cut after sampling is close in Hamming distance to a coordinate cut. However, since the objective value of (1) is a sum , we need to exclude the possibility that the optimal solution includes a large cut due to the other cuts being surprisingly sparse. Corollary 16 handles this.
Corollary 16.
Conditioned on the success of the event in Lemma 15, for every balanced cut , it holds that
where is the coordinate with the smallest hamming distance to , is a universal constant, and .
Proof.
Let be he universal constant from Lemma 10. Let be a cut of size and let be the coordinate cut with the smallest Hamming distance to . By Lemma 8, we have . Consider two cases depending on .
Suppose . Then by Lemma 15, we have , so we are done.
Proof.
Fix a coordinate cut . Then , so applying the Chernoff bound (Lemma 13) with , we obtain
By a union bound over the coordinate cuts, the above equation holds simultaneously for all with probability at least If this holds, then, since is a feasible solution to (1), the optimal value of (1) is at most
Finally, we put everything together to prove Theorem 1.
Proof of Theorem 1.
Running time.
We can solve this program by enumerating all feasible families of cuts, of which there are at most and computing the corresponding edge counts, so the running time is .
Correctness.
Condition on the success of the events in Lemma 15 and Lemma 17. By a union bound, this occurs with probability at least
Let be the optimal solution to (1). For every , let denote the coordinate cut with the smallest Hamming distance to . We start by proving that this is a matching, i.e., that the set consists of different coordinate cuts. Suppose not. Then or for some . If , then by triangle inequality,
so either or If instead , then again by triangle inequality,
so again either or .
Let be the index such that . Applying Lemma 8 with gives , where is the universal constant from Lemma 8. Therefore, by Lemma 15 and Lemma 17, we have
| by Lemma 15 | ||||
| by Lemma 17 | ||||
Furthermore, letting be the universal constant from Corollary 16, for every , we have
| by Corollary 16 | ||||
| by Lemma 17 | ||||
| since . |
But then summing over all gives
which is a contradiction, since objective value of (1) is at most , by Lemma 17. Thus, the set must contain distinct coordinate cuts.
So now suppose that we have a matching, i.e. that the set contains distinct coordinate cuts. Then is a feasible solution to (1). Recall that is the universal constant from Lemma 8 and is the universal constant from Corollary 16. Let , and suppose for contradiction that
for some . Applying Lemma 8 with , gives
where the last inequality follows by choice of . So by Lemma 15, we have
But then, by Corollary 16, we have
which contradicts the optimality of , since is a feasible solution. Therefore, we conclude that with probability at least , it holds that for all .
3 Proof of Theorem 4
The proof follows the same overall strategy as Theorem 1. The algorithm solves to following optimization problem and outputs the optimal solution.
| (9) | ||||||
We want to use the FKN Theorem (Theorem 7) to show that every sparse cut is close to a coordinate cut, and then use Karger’s cut-counting theorem (Theorem 9) to union bound over all cuts. In the -distance cube, every vertex has degree , and for every coordinate cut and every vertex , exactly of the edges incident on cross the cut . These higher degrees allow for better concentration bounds, which is why we can achieve exact recovery. It is important to note that when is even, the -distance cube has at least two components, corresponding to the vertices with odd Hamming weight, and the vertices with even Hamming weight.
Definition 18 (Component of ).
Let , be the subgraphs induced by
respectively. We say that is an component of if
-
and is odd, or
-
and is even.
We say that a cut is a coordinate cut in if for some coordinate cut
Later, in Remark 23, we will see that when is sufficiently large, the components of are exactly the connected components.
We start by analyzing the spectrum of the -distance cube . Known results for the Hamming association scheme (see e.g. Theorem 5, Chapter 21 in [28]) show that the eigenvalues of the adjacency matrix of are given by binary Krawtchouk polynomials
Therefore, the eigenvalues of the Laplacian satisfy
We include a direct calculation of the eigenvalues in the full version for completeness.
Lemma 19 (Eigenvalues of ).
Let be an integer, and let be the unnormalized Laplacian of . Then the Fourier characters form an eigenbasis of , with corresponding eigenvalues
| (10) |
Using the above lemma, we can write the size of any cut in in terms of the Fourier coefficients of its indicator function.
Lemma 20.
Let be the -dimensional -distance hypercube, and let be component of (as per Definition 18). Let , and let denote the indicator function on . Then
Proof.
Since there are no edges between and , we can use the unnormalized Lapacian of the entire graph to express the cut size of as
| (11) |
On the other hand, expanding in the Fourier basis, we have By Lemma 19, every Fourier character is an eigenvector of with eigenvalue , which gives
| (12) |
To argue that every sparse cut places most of its Fourier mass on the first two levels, we first need to argue that the eigenvalues with are large compared to those with .
Lemma 21.
Let be a positive integer, and let be sufficiently large. Denote by the eigenvalue corresponding to sets of size . Then:
-
If is odd, then for every with , it holds that
-
If is even, then for every with , it holds that , and for every with , it holds that .
The proof of Lemma 21 is included in the full version. Using the spectral gap established in Lemma 21, we will show that every sparse cut places most of its Fourier mass on the first two levels. As a first step, we derive a lower bound on the expansion of a cut in terms of the higher-level Fourier coefficients.
Lemma 22.
Let be an integer, let be sufficiently large, and let be a component of (as per Definition 18). Let with , and let be the indicator function on .
-
If is odd, then
-
If is even, then
Remark 23 (Coordinate cuts are sparsest cuts).
Proof.
We prove the lemma for the case when is odd. The case when is even is similar and is included in the full version. We have
| (13) |
and, since , we have
| (14) |
Denote by the eigenvalue corresponding to sets of size . Also note from (10), that .
Combining Lemma 20, together with Equations (13) and (14) gives
by Lemma 20
by Lemma 21
by (13) and (14)
Here the last inequality uses that , by the assumption.
As a corollary of Lemma 22, we get that sparse cuts place almost all of their Fourier mass on the first two levels (and, in the even- case, also on the top two levels).
Corollary 24.
Let be an integer, let be sufficiently large and let be a component of (as per Definition 18). Let be a subset with and suppose that . Let denote the indicator function of . Then
-
If is odd, then
-
If is even, then
Proof.
We prove the lemma for the case when is odd. The case when is even is similar and is included in the full version. By Lemma 22, we have
which gives
We now wish to apply the FKN theorem (Theorem 7) to argue that every sparse cut must be close to a coordinate cut. We can do that in the case when is odd. However, when is even, we are in a slightly different setting: First, the function is only supported on one of the connected components, and second, puts most of its Fourier mass on both the bottom two and the top two levels. Therefore, we need to extend the FKN theorem to the case of even .
Lemma 25 (FKN theorem for even ).
Let denote the indicator function of the even component . Suppose that is a boolean function supported on such that and . Then there exists an index such that or . Here is an absolute constant.
The proof is included in the full version. We can now argue that sparse cuts are close to coordinate cuts.
Proof.
If is even, then we can without loss of generality assume that is supported on the even component, and the lemma follows from Corollary 24 and Lemma 25.
Next, we want to apply Karger’s cut-counting theorem (Theorem 9) and a Chernoff bound (Lemma 13). Similarly to the proof of Theorem 1, we need to establish a strong bound on the size of and .
Lemma 27.
The proof is almost identical to the proof of Lemma 10, and is included in the full version. In order to apply Karger’s cut-counting theorem, we also need to establish the size of the minimum cuts.
Lemma 28 (The singleton cuts are min-cuts).
Let be an integer, and let be sufficiently large. Let be a component of (as per Definition 18). Then
Proof.
If , then For the rest of the proof, we consider and split into two cases according to .
Case 1: .
By Lemma 22, we have
Case 2: .
Every vertex in has degree . A vertex in can have at most neighbors in , so it must have at least edges to . Summing over all vertices in , we obtain
where the last inequality follows from . We can now apply Karger’s cut-counting theorem to count the number of cuts of size .
Lemma 29.
Let be a component of (as per Definition 18), and let be a coordinate in . The number of sets of size such that and is at most .
Proof.
Given , the set is uniquely determined by the choice of , so we just need to count the number of possible choices for . Let denote the hidden constant in the big -notation in Lemma 27. By Lemma 27, we have
By Lemma 28, the minimum cut has size , so is an -approximate minimum cut with . Therefore, by Karger’s cut counting theorem (Theorem 9), the number of choices for is at most
Here denotes the binary entropy function
Lemma 30.
The proof is similar to Lemma 14, and is included in the full version.
Lemma 31.
Let be a component of (as per Definition 18). Suppose for a sufficiently large constant , and let , where is the universal constant from Lemma 26. Then with probability at least , the following holds: For every , and every balanced cut of size , it holds that
where is the coordinate cut in such that (exists by Lemma 26).
Proof.
Let be the hidden constant in the -notation in Lemma 29 and let be the hidden constant in the -notation in Lemma 30. Suppose that is a sufficiently large constant. Let for . For every coordinate cut with and , and for every , let be the event that there exists a balanced cut of size with such that
We now show that For every balanced cut of size with , by Lemma 30, we have
By Lemma 29, the number of such cuts is at most . Therefore, by a union bound, we have
Taking a union bound over the possible choices of and the possible choices for , we get the claim for .
Corollary 32.
Conditioned on the success of the event in Lemma 31, for every balanced cut it holds that
Proof.
Let be a balanced cut of size . If , then we are done by Lemma 31. If instead , then , so by Lemma 26, there exists a coordinate cut such that
where the last inequality follows by the setting . But then is equal to , so we are done.
Lemma 33.
Proof of Theorem 4.
Running time.
We can solve (9) by enumerating over all feasible families of cuts, of which there are at most and computing the corresponding edge counts, so the running time is .
Correctness.
Condition on the success of the events in Lemma 31 and Lemma 33. By a union bound, this occurs with probability at least Let be the optimal solution to (9). For every , let denote the coordinate cut in with the smallest Hamming distance to .
We start by proving that this is a matching, i.e., that the set consists of different coordinate cuts. Suppose not. Then or for some . If , then by triangle inequality,
so either or If instead , then by triangle inequality,
so again either or .
Let be the index such that . Applying Lemma 26 with gives . From Lemma 31 and Lemma 33, we have
| by Lemma 31 | ||||
| by Lemma 33 | ||||
Furthermore, from Lemma 31 and Lemma 33, we have that for every ,
But then summing over all gives
| (15) |
which is a contradiction, since objective value of (9) is at most , by Lemma 33. Thus, the set must contain distinct coordinate cuts.
So now suppose that we have a matching, i.e. that the set contains distinct coordinate cuts. Then is a feasible solution to (9). Suppose for contradiction that for some . Then by Lemma 31 applied to , we have
and for every , by Lemma 32 applied to , we have
But this gives , contradicting the optimality of .
References
- [1] Emmanuel Abbe. Community detection and stochastic block models: recent developments. J. Mach. Learn. Res., 18(1):6446–6531, January 2017.
- [2] Emmanuel Abbe, François Baccelli, and Abishek Sankararaman. Community detection on euclidean random graphs. Information and Inference: A Journal of the IMA, 10(1):109–160, May 2020.
- [3] Emmanuel Abbe, Afonso S. Bandeira, and Georgina Hall. Exact recovery in the stochastic block model. IEEE Transactions on Information Theory, 62(1):471–487, 2016. doi:10.1109/TIT.2015.2490670.
- [4] Emmanuel Abbe, Enric Boix-Adserà, Peter Ralli, and Colin Sandon. Graph powering and spectral robustness. SIAM Journal on Mathematics of Data Science, 2(1):132–157, 2020. doi:10.1137/19M1257135.
- [5] Emmanuel Abbe and Colin Sandon. Community detection in general stochastic block models: Fundamental limits and efficient algorithms for recovery. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science (FOCS), FOCS ’15, pages 670–688, USA, 2015. IEEE Computer Society. doi:10.1109/FOCS.2015.47.
- [6] Luiz Emilio Allem, K. Avrachenkov, Carlos Hoppen, Hariprasad Manjunath, and Lucas Sibemberg. Multi-community spectral clustering for geometric graphs, 2025. doi:10.48550/arXiv.2508.00893.
- [7] Sanjeev Arora, Rong Ge, Sushant Sachdeva, and Grant Schoenebeck. Finding overlapping communities in social networks: toward a rigorous approach. In Proceedings of the 13th ACM Conference on Electronic Commerce, EC ’12, pages 37–54, New York, NY, USA, 2012. Association for Computing Machinery. doi:10.1145/2229012.2229020.
- [8] Konstantin Avrachenkov, Andrei Bobu, and Maximilien Dreveton. Higher-order spectral clustering for geometric graphs. Journal of Fourier Analysis and Applications, 27(2):22, 2021.
- [9] Kiril Bangachev and Guy Bresler. Sandwiching random geometric graphs and erdos-renyi with applications: Sharp thresholds, robust testing, and enumeration. In Proceedings of the 57th Annual ACM Symposium on Theory of Computing, pages 310–321, June 2025. doi:10.1145/3717823.3718125.
- [10] Charles Bordenave, Marc Lelarge, and Laurent Massoulié. Non-backtracking spectrum of random graphs: Community detection and non-regular ramanujan graphs. In Venkatesan Guruswami, editor, IEEE 56th Annual Symposium on Foundations of Computer Science, FOCS 2015, Berkeley, CA, USA, 17-20 October, 2015, pages 1347–1357. IEEE Computer Society, 2015. doi:10.1109/FOCS.2015.86.
- [11] Sébastien Bubeck, Jian Ding, Ronen Eldan, and Miklós Z. Rácz. Testing for high-dimensional geometry in random graphs. Random Structures & Algorithms, 49, 2014. URL: https://api.semanticscholar.org/CorpusID:15367951.
- [12] Yudong Chen and Jiaming Xu. Statistical-computational tradeoffs in planted problems and submatrix localization with a growing number of clusters and submatrices. J. Mach. Learn. Res., 17(1):882–938, January 2016.
- [13] Ashish Chiplunkar, Michael Kapralov, Sanjeev Khanna, Aida Mousavifar, and Yuval Peres. Testing graph clusterability: Algorithms and lower bounds. In 2018 IEEE 59th Annual Symposium on Foundations of Computer Science (FOCS), pages 497–508. IEEE, 2018. doi:10.1109/FOCS.2018.00054.
- [14] Anne Condon and Richard M. Karp. Algorithms for graph partitioning on the planted partition model. Random Structures & Algorithms, 18(2):116–140, 2001. doi:10.1002/1098-2418(200103)18:2<116::AID-RSA1001>3.0.CO;2-2.
- [15] Artur Czumaj, Pan Peng, and Christian Sohler. Testing cluster structure of graphs. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, STOC ’15, pages 723–732, New York, NY, USA, 2015. Association for Computing Machinery. doi:10.1145/2746539.2746618.
- [16] Aurelien Decelle, Florent Krzakala, Cristopher Moore, and Lenka Zdeborová. Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications. Phys. Rev. E, 84:066106, December 2011. doi:10.1103/PhysRevE.84.066106.
- [17] Benjamin Doerr. Probabilistic Tools for the Analysis of Randomized Optimization Heuristics, pages 1–87. Springer International Publishing, January 2020. doi:10.1007/978-3-030-29414-4_1.
- [18] Ehud Friedgut, Gil Kalai, and Assaf Naor. Boolean functions whose fourier transform is concentrated on the first two levels. Advances in Applied Mathematics, 29(3):427–437, 2002. doi:10.1016/S0196-8858(02)00024-6.
- [19] Sainyam Galhotra, Arya Mazumdar, Soumyabrata Pal, and Barna Saha. The geometric block model. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), April 2018. doi:10.1609/aaai.v32i1.11905.
- [20] Sainyam Galhotra, Arya Mazumdar, Soumyabrata Pal, and Barna Saha. Connectivity of Random Annulus Graphs and the Geometric Block Model. In Dimitris Achlioptas and László A. Végh, editors, Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM 2019), volume 145 of Leibniz International Proceedings in Informatics (LIPIcs), pages 53:1–53:23, Dagstuhl, Germany, 2019. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. doi:10.4230/LIPIcs.APPROX-RANDOM.2019.53.
- [21] Sainyam Galhotra, Arya Mazumdar, Soumyabrata Pal, and Barna Saha. Community recovery in the geometric block model. J. Mach. Learn. Res., 24(1), January 2023. URL: http://jmlr.org/papers/v24/22-0572.html.
- [22] Julia Gaudio, Xiaochun Niu, and Ermin Wei. Exact community recovery in the geometric sbm. In Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2158–2184, 2024. doi:10.1137/1.9781611977912.78.
- [23] Grzegorz Gluch, Michael Kapralov, Silvio Lattanzi, Aida Mousavifar, and Christian Sohler. Spectral clustering oracles in sublinear time. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms, SODA 2021, Virtual Conference, January 10 - 13, 2021, pages 1598–1617. SIAM, 2021. doi:10.1137/1.9781611976465.97.
- [24] Paul Holland, Kathryn B. Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps. Social Networks, 5:109–137, 1983. URL: https://api.semanticscholar.org/CorpusID:34098453.
- [25] David R Karger. Global min-cuts in RNC, and other ramifications of a simple min-cut algorithm. In ACM-SIAM Symposium on Discrete Algorithms, 1993. URL: https://api.semanticscholar.org/CorpusID:10445344.
- [26] Shuangping Li and Tselil Schramm. Spectral clustering in the gaussian mixture block model, 2023. doi:10.48550/arXiv.2305.00979.
- [27] Siqi Liu, Sidhanth Mohanty, Tselil Schramm, and Elizabeth Yang. Testing thresholds for high-dimensional sparse random geometric graphs. In Proceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing, STOC 2022, pages 672–677, New York, NY, USA, 2022. Association for Computing Machinery. doi:10.1145/3519935.3519989.
- [28] Florence Jessie MacWilliams and Neil James Alexander Sloane. The theory of error-correcting codes, volume 16. Elsevier, 1977.
- [29] Laurent Massoulié. Community detection thresholds and the weak ramanujan property. In Proceedings of the Forty-Sixth Annual ACM Symposium on Theory of Computing, STOC ’14, pages 694–703, New York, NY, USA, 2014. Association for Computing Machinery. doi:10.1145/2591796.2591857.
- [30] F. McSherry. Spectral partitioning of random graphs. In Proceedings 42nd IEEE Symposium on Foundations of Computer Science, pages 529–537, 2001. doi:10.1109/SFCS.2001.959929.
- [31] Elchanan Mossel, Joe Neeman, and Allan Sly. Reconstruction and estimation in the planted partition model. Probability Theory and Related Fields, 162, July 2014. doi:10.1007/s00440-014-0576-6.
- [32] Elchanan Mossel, Joe Neeman, and Allan Sly. Consistency thresholds for the planted bisection model. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, STOC ’15, pages 69–75, New York, NY, USA, 2015. Association for Computing Machinery. doi:10.1145/2746539.2746603.
- [33] Ryan O’Donnell. Analysis of Boolean Functions. Cambridge University Press, 2014.
- [34] Abishek Sankararaman and François Baccelli. Community detection on euclidean random graphs. In Proceedings of the 2018 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), 2018. arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9781611975031.142.
- [35] van Vu. A simple svd algorithm for finding hidden partitions. Combinatorics, Probability and Computing, 27:124–140, 2014. URL: https://api.semanticscholar.org/CorpusID:8561244.
- [36] Douglas Brent West et al. Introduction to graph theory, volume 2. Prentice hall Upper Saddle River, 2001.
- [37] Yuan Zhang, Elizaveta Levina, and Ji Zhu. Detecting overlapping communities in networks using spectral methods. SIAM Journal on Mathematics of Data Science, 2(2):265–283, 2020. doi:10.1137/19M1272238.