Explainable AI for Sequential Decision Making
Abstract
As more and more AI applications have become ubiquitous in our lives, the research area of explainable AI (XAI) has rapidly developed, with goals such as enabling transparency, enhancing collaboration, and increasing trust in AI. However, the focus of XAI to date has largely been on explaining the input-output mappings of “black box” models like neural networks, which have been seen as the central problem for the explainability of AI systems. The challenge of explaining intelligent behavior that extends over time, such as that of robots collaborating with humans or software agents engaged in complex ongoing tasks, has only recently gained attention. We may have AIs that can beat us in Go, but can they teach us how to play?
This Dagstuhl Seminar brought together academic researchers and industry experts from communities such as reinforcement learning, planning, game AI, robotics, and cognitive science to discuss their work on explainability in sequential decision-making contexts. The seminar aimed to move towards a shared understanding of the field and develop a common roadmap for moving it forward. This report documents the program and its results.
Keywords and phrases:
Explainable artificial intelligence, explainable agents, sequential decision making, planning, learningSeminar:
September 8–11, 2024 – https://www.dagstuhl.de/243722012 ACM Subject Classification:
Computing methodologies Artificial intelligence ; Human-centered computingCopyright and License:
1 Executive Summary
Hendrik Baier (Eindhoven University of Technology, NL. h.j.s.baier@tue.nl)
Mark T. Keane (University College Dublin, IE. mark.keane@ucd.ie)
Sarath Sreedharan (Colorado State University – Fort Collins, US.
sarath.sreedharan@colostate.edu)
Silvia Tulli (Sorbonne Université – Paris, FR. silvia.tulli@sorbonne-universite.fr)
Abhinav Verma (Pennsylvania State University – University Park, US. verma@psu.edu)
License: ![]() Creative Commons BY 4.0 International license © Hendrik Baier, Mark T. Keane, Sarath Sreedharan, Silvia Tulli, and Abhinav Verma
Creative Commons BY 4.0 International license © Hendrik Baier, Mark T. Keane, Sarath Sreedharan, Silvia Tulli, and Abhinav Verma
We work with AI and rely on AI for more and more decisions that influence our lives. To serve increasingly urgent goals such as enabling transparency, enhancing collaboration, and increasing trust in AI, the research area of explainable AI (XAI) has rapidly developed in recent years. However, the focus of XAI to date has largely been on explaining the input-output mappings of “black box” models such as neural networks, which have been seen as the central problem for the explainability of AI systems. While these models are certainly important, intelligent behavior often extends over time and needs to be explained and understood as such. The challenge of explaining sequential decision making (SDM), such as that of robots collaborating with humans or software agents engaged in complex ongoing tasks, has only recently gained attention. We may have AIs that can beat us in Go, but can they teach us how to play? We may have search and rescue robots, but can we effectively communicate with them and coordinate missions in the field?
Initial attempts at making the behavior of SDM algorithms more understandable have recently appeared in different fields such as classical AI planning, reinforcement learning, multi-agent systems, or logic-based argumentation – but often focused on ad hoc solutions to specific problems, with an emphasis on area-specific terminology and concepts developed in isolation of other fields. Many of these approaches are also restricted in their scope, for example to explanations of isolated, single actions that do not address the full complexity of SDM; or to summaries of entire agent policies, which are often too high-level to be helpful. To truly trust an AI agent and collaboratively work with it towards human goals, and to increase successful AI adoption and acceptance in many fields from robotics to logistics, and from production planning to smart cities, we need considerable progress in this new field of XAI for SDM (or X-SDM).
Under-researched challenges for X-SDM include for example: XAI for complex decisions, e.g., on plans or policies instead of single output labels; conversational XAI that continuously interacts with users over time, aiming to understand and support them; contestable and collaborative XAI, which can successfully work with users in areas where neither user nor AI is omniscient nor infallible; and flexible decision-making for XAI, able to adapt to users, respect their autonomy, and go beyond one-size-fits-all explanations. This Dagstuhl Seminar aimed to identify and clarify such challenges that are unique to, or of particular relevance to, explainability in sequential decision-making settings. It used complementary perspectives of researchers from different communities such as reinforcement learning, planning, game AI, robotics, and cognitive science, which historically use different theoretical foundations and computational approaches. The aim of the seminar was to move towards a shared understanding of the field, by first building a taxonomy that unifies our perspectives, and then developing a common roadmap for moving X-SDM forward.
This seminar was organized in two parts: in the first part, breakout groups were formed based on the primary research communities of the participants. These groups were encouraged to identify key terminology and definitions in their area, which were later summarized in plenary sessions, and combined into a first sketch of a shared taxonomy. Based on this understanding of the field of explainable sequential decision making, breakout groups in the second part were then formed by participants interested in a particular aspect of future work, and their results were again summarized and combined in later plenary sessions to develop a first sketch of a roadmap for the field. The seminar was accompanied by spotlight talks throughout, giving insight into the work of individual participants. This report gives an overview of the talks, outlines the discussions of all breakout groups, and summarizes sketches of the taxonomy and the roadmap. The interest in the seminar was high and the participants were very enthusiastic to contribute and connect across research fields; the most frequently expressed regret was that the seminar did not last long enough to flesh out more details of the work we started. As the organizers, we therefore consider this seminar a great success and are looking forward to the resulting collaborations and impact to the field.
2 Table of Contents
3 Spotlight Talks
3.1 Guarantees with Decision Trees
Anna Lukina (TU Delft, NL. a.lukina@tudelft.nl)
License: ![]() Creative Commons BY 4.0 International license © Anna Lukina
Creative Commons BY 4.0 International license © Anna Lukina
Decision trees, owing to their interpretability, are attractive as control
policies for (dynamical) systems. Synthesizing such policies is challenging.
Previous approaches do so by imitating a neural network, approximating
a tabular data set, employing reinforcement learning, or modelling the
problem as a mixed-integer linear program. However, these works may
require access to a hard-to-obtain accurate policy or a formal model of
the environment, and may not provide guarantees on the correctness or
size of the final tree policy. In this talk, we exploit important properties of
decision trees to construct and verify them faster than state-of-the-art
approaches.
3.2 Explaining Real-Time Autonomous Driving
Claudia V. Goldman (Hebrew University Business School – Jerusalem, IL.
claudia.goldman@mail.huji.ac.il)
License: ![]() Creative Commons BY 4.0 International license © Claudia V. Goldman
Creative Commons BY 4.0 International license © Claudia V. Goldman
Trust has been studied in the Human Factors research community and found (1) trust is essential when users interact with automation and (2) communicating the automation actions can help in calibrating the trust level of users. We developed explainable AI algorithms that compute automated notifications about the behavior of a system, controlled by an AI decision-making algorithm. We have found, in our previous studies, that providing users with (handcrafted) information about an automated driving maneuver in addition to the information displayed in more familiar graphical Human Machine Interfaces is indeed beneficial. This talk presented our research on explainable AI algorithms, including three types of information, Plan-next, Contrastive, and Value. Also, we implemented three timing schedules to decide when to present that information. These algorithms were evaluated through an online user study of over 800 participants, experiencing simulated automated driving scenarios. Our results showed that automated notifications can increase the understanding and trust levels of users experiencing the AI system. Age, gender, and Advanced Driver Assistance Systems experience can affect these results. A statistically significantly increase was found in both measures for users over 60 years old, with a non-negative prior trust attitude and with prior experience with automated driving features.
3.3 Explainable Search
Hendrik Baier (Eindhoven University of Technology, NL. h.j.s.baier@tue.nl)
License: ![]() Creative Commons BY 4.0 International license © Hendrik Baier
Creative Commons BY 4.0 International license © Hendrik Baier
While search-based AI agents are state-of-the-art in many challenging sequential decision-making domains, contemporary approaches lack the ability to explain, summarize, or visualize their plans and decisions. Users struggle to understand how they are derived from traversing complex spaces of possible futures, contingencies, and eventualities, spanned by the available actions of the agent. This limits human trust in high-stakes scenarios, as well as effective human-AI collaboration. This talk outlines a vision for the research direction of explainable search, and discusses several related challenges. It focuses in particular on online interactions and the resulting understanding of explanations as an ongoing process of mutual collaboration towards human goals.
3.4 Back to the Future of Robotics: Core Principles and Processes
Mohan Sridharan (The University of Edinburgh, UK. m.sridharan@ed.ac.uk)
License: ![]() Creative Commons BY 4.0 International license © Mohan Sridharan
Creative Commons BY 4.0 International license © Mohan Sridharan
Data-driven foundation models and deep learning methods are increasingly being considered state-of-the-art for different problems in robotics and AI. However, these models and methods are resource-hungry, requiring considerable computation, storage, and training examples, which are not available in many practical robotics applications. In addition, it is difficult to incrementally revise the learned models or to understand their internal processing mechanisms. This talk instead advocates a different approach to jointly address the underlying representation, reasoning, control, and learning problems in robotics based on core principles such as iterative refinement, abstraction, interactive learning, and relevance that can be traced back to the early pioneers of AI. It also pushes for embedding decision heuristics in all components to promote simplicity, computational efficiency, and transparency. The benefits of this approach are illustrated using different robotics problems such as visual scene understanding, manipulation, and multiagent collaboration.
3.5 Varieties of Explainable Agency
Pat Langley (Institute for the Study of Learning and Expertise – Palo Alto, US.
patrick.w.langley@gmail.com)
License: ![]() Creative Commons BY 4.0 International license © Pat Langley
Creative Commons BY 4.0 International license © Pat Langley
This talk defined explainable agency as the ability of an intelligent system to provide, on request, the reasons for choices that led to its activities. It also identified three types of self-explanations – structural, preference, and process – that store different forms of content about agent decisions. In addition, it noted two modes for explainable agency – generating summary reports and answering focused questions. Finally, it briefly examined normative agency, which involves attempting to follow society’s maxims, and justified agency, which aims to explain activities in terms of such norms.
3.6 Causal Explanations for Sequential Decision Making Under Uncertainty
Samer Nashed (University of Montreal, CA MILA – Quebec AI Institute, CA.
samer.nashed@mila.quebec)
License: ![]() Creative Commons BY 4.0 International license © Samer Nashed
Creative Commons BY 4.0 International license © Samer Nashed
Stochastic, sequential decision-making systems, such as those modeled by Markov decision processes and their variants, have been increasingly incorporated into many areas of public and private life. However, our ability to explain these systems’ outputs to non-technical end users has not kept pace with this adoption. This talk introduces a novel framework for causal explanations of stochastic, sequential decision-making systems built on the well-studied structural causal model paradigm for causal reasoning. This single framework can identify multiple, semantically distinct explanations for agent actions – something not previously possible. We accompany this framework with an algorithm, MeanRESP, that can operate along a spectrum of approximation. User studies of this system show, among other results, that users prefer certain types of explanans over others, and that they overwhelmingly prefer explanations generated using MeanRESP compared to other state-of-the-art systems. We conclude with a generalized method for explaining partial policies in sequential decision-making systems and discuss several important open questions lying at the boundary of our most common processes and the realities of real-world deployments.
3.7 Simulation-Based AI
Simon Lucas (Queen Mary University of London, UK. simon.lucas@qmul.ac.uk)
License: ![]() Creative Commons BY 4.0 International license © Simon Lucas
Creative Commons BY 4.0 International license © Simon Lucas
Search-based AI algorithms such as Monte Carlo Tree Search are well known to provide effective decision-making across a range of problems and work well with RL-learned policy and value functions. They use a simulation model to explore possible futures, and to be effective the model must be fast and copyable. In this talk we made the case for placing more emphasis on the simulation model used by these statistical planning algorithms such as MCTS, and gave an example of a competitive Capture the Flag agent where the quality of the simulation model was instrumental. A significant performance boost was made with techniques including partial model updates, approximate physics, mapping from tick-based to discrete-event simulation, and clean separation between the simulation state and the simulation model. We also demonstrated LLM-based heuristic generation, where the LLM generated a useful state value heuristic function from a text description of the Capture the Flag objectives. While the techniques are not new in themselves, the novel combination provides powerful real-time and rapidly adaptive decision making, and the expected futures provided by the simulation already provide a form of explainability, though much more can be done to provide key information to the user regarding how specific actions are likely to lead to particular outcomes.
3.8 Concept-Level Explainable AI
Wojciech Samek (TU Berlin, DE. wojciech.samek@hhi.fraunhofer.de)
License: ![]() Creative Commons BY 4.0 International license © Wojciech Samek
Creative Commons BY 4.0 International license © Wojciech Samek
The talk introduced Layer-wise Relevance Propagation (LRP), a widely used technique for explaining individual predictions made by deep neural networks. LRP works by tracing the model’s output backward through the network layer by layer. This approach not only allows us to measure how each component of the input (such as individual pixels) contributes to the prediction, but also helps identify important neurons in the model’s hidden layers. Given that individual neurons often encode concepts that are understandable to humans – particularly in image classifiers – this capability enables the explanation to shift from the input space to the concept space. The talk will then cover Concept Relevance Propagation (CRP) and Prototypical Concept Explanation (PCX), two advanced methods that explain individual model predictions using human-understandable concepts and facilitate a systematic examination of global model behaviors. Additionally, the talk will explore how these new methods offer profound insights into the representation and reasoning processes of large language models (LLMs). The discussion will conclude with an overview of the characteristics of next-generation explanation techniques.
4 Breakout Sessions on a Taxonomy of Explainable SDM
4.1 Planning
Rebecca Eifler (LAAS-CNRS – Toulouse, FR. rebecca.eifler@laas.fr)
Sriraam Natarajan (University of Texas at Dallas – Richardson, US.
sriraam.natarajan@utdallas.edu)
Julian Siber (CISPA – Saarbrücken, DE. julian.siber@cispa.de)
Sarath Sreedharan (Colorado State University – Fort Collins, US.
sarath.sreedharan@colostate.edu)
Mohan Sridharan (University of Edinburgh, GB. m.sridharan@ed.ac.uk )
Silvia Tulli (Sorbonne Université – Paris, FR. silvia.tulli@sorbonne-universite.fr)
Stylianos Loukas Vasileiou (Washington University in St. Louis, US.
v.stylianos@wustl.edu)
License: ![]() Creative Commons BY 4.0 International license © Rebecca Eifler, Sriraam Natarajan, Julian Siber, Sarath Sreedharan, Mohan Sridharan, Silvia Tulli, and Stylianos Loukas Vasileiou
Creative Commons BY 4.0 International license © Rebecca Eifler, Sriraam Natarajan, Julian Siber, Sarath Sreedharan, Mohan Sridharan, Silvia Tulli, and Stylianos Loukas Vasileiou
This breakout session focused on creating a taxonomy for explainable planning. In particular, the group structured the challenge of explainable planning around three key aspects: what needs to be explained, how to generate these explanations, and how to evaluate their effectiveness.
What to Explain.
We identified three primary targets requiring explanation in planning systems:
-
First, explanations need to address the planning algorithms themselves. This includes helping users understand the search tree structure, the role and selection of heuristics, and the circumstances that trigger replanning. Users often need clarification about why specific algorithmic choices were made and their implications.
-
Second, the resulting plans themselves require explanation along multiple dimensions. This includes demonstrating plan validity, explaining how the plan satisfies stated preferences, and clarifying aspects of the plan that might be unclear to users.
-
Third, the underlying planning models need explanation. This encompasses proving model correctness, demonstrating that the model is appropriately concise, and explaining the chosen levels of abstraction. Users often need clarification about model components and their interactions.
Importantly, the group also distinguished between global explanations that address system-wide understanding and local explanations that focus on specific decision points or components.
How to Explain.
The group identified two main categories of explanation methods, those that deal with generating the informational content of the explanation, and those that deal with communicating the explanation.
For the former, explanations can leverage several types of information:
-
Contrastive and counterfactual explanations that help users understand why certain choices were made over alternatives.
-
Model information that reveals relevant aspects of the underlying planning model.
-
Abstracts that help to manage complexity and focus on key elements.
For the latter, the group identified several key methods for delivering explanations:
-
Summarization techniques to distill complex planning information.
-
Visualization approaches to make planning concepts more accessible.
-
Various representation schemes, including natural language and formal notations.
-
Both one-shot explanations and interactive dialogues.
Evaluation.
The group outlined four key dimensions for evaluating the quality of explanations.
-
1.
Understanding. This emerged as a complex metric that goes beyond simple comprehension. Our discussions highlighted several crucial aspects:
-
Self-explanation capability: the true test of understanding is whether users can independently work through similar problems or explain the solution to others. This “teach-back” mechanism could serve as a robust indicator of genuine comprehension.
-
Actionability: explanations must bridge the gap between theory and practice. Users should be able to apply the explained concepts to new situations, identify when the explained approach might fail, and make informed modifications to the plan when needed.
-
Uncertainty reduction: effective explanations should progressively reduce uncertainty by clarifying ambiguous aspects of the planning process, addressing common misconceptions, and providing confidence levels for different parts of the explanation.
-
-
2.
Trust. We identified trust as a crucial, yet nuanced metric, consisting of several key components:
-
Transparency: users need to understand not just what the system does, but also its limitations and potential failure modes.
-
Consistency: explanations should maintain internal consistency across different aspects of the system.
-
Calibration: the system should help users develop appropriate levels of trust, avoiding both over-reliance and under-utilization.
-
Verification: users should be able to verify key aspects of the explanation, particularly for critical decisions.
-
-
3.
Satisfaction. User satisfaction, particularly regarding preference alignment, was identified as another important dimension. Specifically:
-
Relevance: explanations should focus on aspects that matter to the specific user and context.
-
Completeness: users should feel their questions and concerns have been adequately addressed.
-
Cognitive load: explanations should be sophisticated enough to be useful but simple enough to be digestible.
-
Customization: the ability to adjust the level of detail and technical depth based on user needs.
-
Interactivity: users should be able to explore aspects they find interesting or unclear.
-
-
4.
Formal Guarantees. The correctness and completeness of explanations require formal consideration:
-
Soundness: ensuring that all provided explanations are logically consistent with the underlying planning system.
-
Completeness: identifying what aspects of the system can and cannot be explained.
-
Verification: developing methods to formally verify the accuracy of explanations.
-
Bounds: establishing theoretical bounds on explanation quality and completeness.
-
Coverage: ensuring that explanations cover all relevant aspects of the decision-making process.
-
These evaluation dimensions are deeply interconnected. For example, formal guarantees can build trust, while satisfaction often depends on understanding. We believe that future work should focus on the following aspects: developing integrated evaluation frameworks that capture these interconnections, creating standardized benchmarks for comparing different explanation approaches, investigating the trade-offs between different evaluation metrics, understanding how evaluation needs vary across different user groups and application domains, and exploring how to adapt explanations based on real-time evaluation feedback.
The challenge ahead lies in developing practical tools and methodologies that can effectively measure and optimize these various dimensions while maintaining the balance between rigor and usability.
4.2 Reinforcement Learning
David Abel (Deepmind – London, UK. dmabel@deepmind.com)
Hendrik Baier (Eindhoven University of Technology, NL. h.j.s.baier@tue.nl)
Tobias Huber (TH Ingolstadt, DE. tobias.huber@thi.de)
Simon Lucas (Queen Mary University of London, UK. simon.lucas@qmul.ac.uk)
Anna Lukina (TU Delft, NL. a.lukina@tudelft.nl)
Ann Nowé (VU Brussels, BE. ann.nowe@vub.be)
Mark Riedl (Georgia Institute of Technology – Atlanta, US. riedl@cc.gatech.edu)
Abhinav Verma (Pennsylvania State University – University Park, US. verma@psu.edu)
License: ![]() Creative Commons BY 4.0 International license © David Abel, Hendrik Baier, Tobias Huber, Simon Lucas, Anna Lukina, Ann Nowé, and Mark Riedl
Creative Commons BY 4.0 International license © David Abel, Hendrik Baier, Tobias Huber, Simon Lucas, Anna Lukina, Ann Nowé, and Mark Riedl
This breakout session spread across two days, focused on the development of a common taxonomy for explainability in sequential decision making. As the members of the group self-identified as having either an interest or expertise in reinforcement learning, the starting point for the taxonomy came from surveys on explainability in reinforcement learning (Milani et al. 2024 [2], Puiutta et al. 2020 [3]). Consequently, our perspectives for the taxonomy were shaped in part by the common principles, definitions, and goals of the field of reinforcement learning.
Our group discussed four questions that we believed a taxonomy for SDM should address: What, Who, How, and Evaluation – In more detail:
-
(Q1: What) What are the primary ingredients of the taxonomy — what is being explained?
-
(Q2: Who) Who are the users and what do they want to get out of the explanation?
-
(Q3: How) How are the explanations generated (algorithmically) and presented (in terms of design)?
-
(Q4: Evaluation) How should we measure the value of explanations?
The group encountered several conceptual difficulties in disentangling the first question (“What?”). We first agreed about the value of the decomposition of what could be explained that is suggested by Milani et al. in their survey: (1) A single decision at a single state, (2) An influential training datum such as a (state, action, reward, next state) tuple, or (3) A longer-term behavior, that include something like a policy, plan, or trajectory. Similarly, the standard distinction of a local as opposed to global explanation was discussed, and used as a starting point for developing our own taxonomy. We noted that in SDM, there are two axes of locality: space (states, observations) and time, visualized as follows:
![[Uncaptioned image]](taxonomy-RL1.png)
That is, along the x-axis, moving to the right increases the number of states (or experiences/observations) involved in the explanation, whereas moving down along the y-axis increases the amount of time involved in the explanation. Thus, an explanation can be local in either space or time, and different points or paths along this plot carve out different kinds of explanations.
This figure framed our initial draft of a three-component taxonomy, visualized as follows:
![[Uncaptioned image]](taxonomy-RL2.png)
Taxonomy of SDM.
We suggested there needs to be at least three distinct components to xSDM:
-
Agent (or decision-maker): a stateful system that produces actions in response to its own state and the last observation.
-
Environment (or domain): a stateful system that produces observations in response to its own state and the last action.
-
Task (or goal, objective): a characterization of the agent’s goal.
Atomic Elements.
Together, these constituents give rise to the atomic elements of a sequential decision-making problem, such as the actions of the agent, the state of the environment, the goal or reward, and so on. Through combinations of these atomic elements, we arrive at other objects involved in the taxonomy. For example, trajectories of experience arise from the combination of all three components (agent, environment, and task), or we might consider a counterfactual involving how the agent’s action choice changes if the task were to differ. Every explanation in SDM would involve these components.
We further suggested that sequential decision making is a problem involving these three components where the environment state is non-trivial. That is, if the environment did not have a state (or ), then the problem would lose its significance or key structure. As an example, we agreed that planning should fall under the class of sequential decision-making problems, and most simple instances of sequential decision making can be accommodated by our definition. However, if we contrast a k-armed bandit (Lattimore and Szepesvári, 2020 [1]) with a drifting k-armed bandit in which the rewards change over time, we agreed that the latter case is sequential decision making as tracking this successive change is important from the decision maker’s point of view. Naturally, none of these distinctions and categories are likely to be perfect, but we agreed this was a good starting point.
References
- [1] Lattimore, T., and Szepesvári, C. (2020). Bandit algorithms. Cambridge University Press.
- [2] Milani, S., Topin, N., Veloso, M., and Fang, F. (2024). Explainable reinforcement learning: A survey and comparative review. ACM Computing Surveys, 56(7), 1-36.
- [3] Puiutta, E., and Veith, E. M. (2020, August). Explainable reinforcement learning: A survey. In International cross-domain conference for machine learning and knowledge extraction (pp. 77-95). Cham: Springer International Publishing
4.3 Sequential Decision Making – Broad
Ruth Mary Josephine Byrne (Trinity College Dublin, University of Dublin, IE.
rmbyrne@tcd.ie)
Khimya Khetarpal (Deepmind – Seattle, US. khimyakhetarpal@gmail.com)
Bradley Hayes (University of Colorado – Boulder, US. bradley.hayes@colorado@edu)
Pat Langley (Stanford University, US. patrick.w.langley@gmail.com)
Mark T. Keane (University College Dublin, IE. mark.keane@ucd.ie)
Lindsay Sanneman (MIT – Cambridge, US. lindsays@mit.edu)
License: ![]() Creative Commons BY 4.0 International license © Ruth Mary Josephine Byrne, Khimya Khetarpal, Bradley Hayes, Pat Langley, Mark T. Keane, and Lindsay Sanneman
Creative Commons BY 4.0 International license © Ruth Mary Josephine Byrne, Khimya Khetarpal, Bradley Hayes, Pat Langley, Mark T. Keane, and Lindsay Sanneman
This breakout session spread over two days, focused on brainstorming and the development of a taxonomy for explainability in sequential decision making. With experts from a variety of backgrounds, this group chose to discuss the taxonomy covering sequential decision making broadly, hence the name SDM-Broad.
Our discussion revolved around the taxonomy for SDM addressing three key questions: What, How, and Evaluation: where
-
Q1: What? focused on the problems i.e., What is being explained and how is it being studied/formulated?
-
Q2: How? focused on the methods i.e., What are the key components required for the methods chosen and how do these components come together?
-
Q3: Evaluation? focused on metrics i.e., How should we evaluate explanations?
Q1: What? focused on the problems i.e., What is being explained and how is it being studied/formulated?
This question helped everyone in the group shed light on their respective field’s literature. We discussed Daniel Dennet’s [1] distinction between mechanistic and intentional explanation. Next, we discussed how Frank et al. all break down different kinds of explanations, humans to humans, adults to children, experts to novices, etc. More recent work looks at new ideas on humans explaining to devices. One area of interest for psychologists that came up is studying the mismatch between expectation and outcome in explanations. Some of the work can be thought of as an interpretative explanation and not as self-explanation by the machines. An interesting point we touched upon is – one cautionary tale is that when asked people might explain well, justifying why they did something, but their choice might not necessarily match that explanation. Consequently, this leads to an open question of what comes closest to sequential decision making here.
Thinking about what the formulation might be in terms of xSDM, the group found the relevance of human factors literature, as it encompasses what a human needs for their role and task i.e., to perceive all of the relevant information, comprehend that, and project future states of the environment (which could be intentions). The belief-desire intention (BDI) framework was also deemed relevant to this specific question. The group had a consensus that the purpose of explainability in most situations is to meet the informational needs of the user/human.
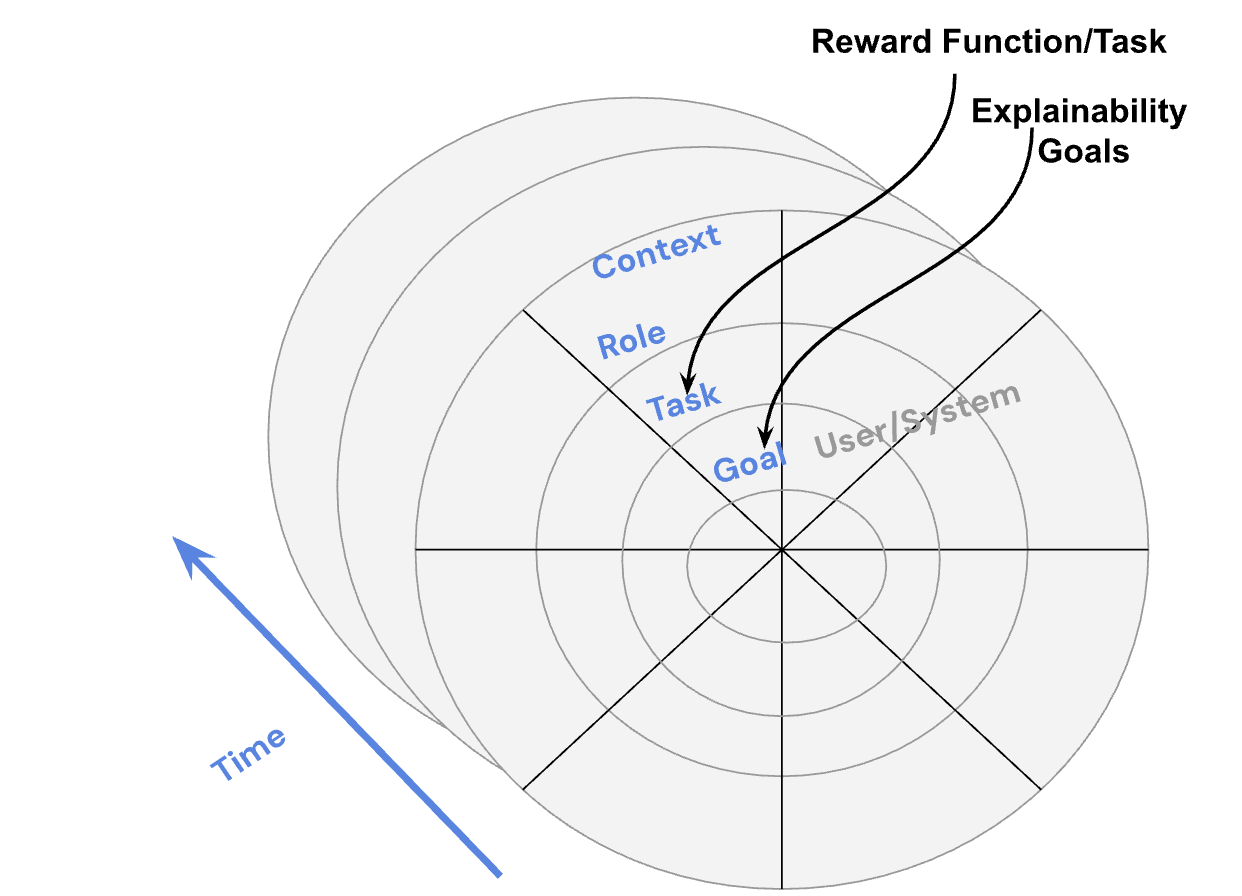
A key reference of the SAFE-AI Framework [3] served as a focal point for the rest of our discussion. Taking inspiration from this framework, we discussed that in any taxonomy, we should have a goal orientation framework consisting of identifying the goal, task, context, role diving into perception, comprehension, and projection. To elaborate, in this taxonomy, one might consider multiple-step trajectories which comprise of 1-step transitions (, , ) with single-step actions or a sequence of actions i.e., operating at another granularity. Here explanations might be about one step or multiple steps, both about the past, present, or future. Using the SAFE-AI framework, the group proposed a multi-component taxonomy, visualized in Figure 1:
-
1.
The primary consideration must be on the initial structure of identifying the context and the role. What does a context look like? For example, in human-agent interaction, the human may be commanding a multi-agent team, obtaining guidance from an expert agent, or even trying to teach the agent new abilities, each of which involves different relations between the human and agents, who take on different roles.
-
2.
Next, consideration must be given to the task at hand, which could potentially be defined by the underlying reward function or some utility that the system/robot is designed to maximize.
-
3.
Upon identifying the context, role, and task, it is crucial to identify the goals. Here, it is important to distinguish between the goals of an AI agent and those of a human/user. This posed an open question on how do we define goals in xSDM?. To this end, the group encountered several conceptual perspectives; the goal of the user could be baked into a reward function, e.g., drive as fast as possible, while at the same time, the goal of the user could also be to increase trust in your decisions if you might be able to have an objective measure. Concurrently, some members believe that goals are usually coded as symbolic descriptions that describe classes of states, not as reward functions.
-
4.
Finally, we suggest that all 1-3 must be considered as a function of time to account for sequential decision making where transitions between states with choices lead to decisions in a sequence. The group noted that there are sequential tasks that might not involve a decision.
Furthermore, in an attempt to answer Q1 (What?), we also focused on characterizing what is unique to sequential decision making about explainability. Key distinctions that we identified include;
-
1.
Looking one step versus sequences of multi-step decision making. A time dependence where each event is time correlated to each other, e.g., forward-looking and backward-looking.
-
2.
Goals would also be trajectory-based, e.g., have long context, and a sequence of outcomes that might occur in the future.
-
3.
SDM explainability can be categorized into: Pre-hoc explanation, post-hoc explanation, online explanation during learning and decision making.
-
4.
Analogy b/w sequence of decision making and the gradient flowing in a NN. While you can study explainability here as well, what is missing is choice.
Q2: How? Focused on methods, that is, what are the key components required for the chosen methods and how do these components come together?
In this part of the discussion, the group focused on methods, trying to characterize what are the key components required for xSDM approaches.
We discussed a primary challenge in developing methods for xSDM is choosing what is relevant to explain, and trying to infer what the goals of the user are. This would require finding the pieces of what is relevant, determining if a user is asking a question or not would also determine the explanations. The group agreed that xSDM would potentially benefit from a time-dependent approach that requires both forward-looking and backward-looking mechanisms depicted in Figure 2. Some of us used these terms from the reinforcement learning literature [4], especially offering an analogy on how explanation in SDM might come across the issue of credit assignment [5] in providing certain explanations, e.g., in a driverless vehicle, when a system needs to explain the cause-and-effect from a history of trajectories. At the same time, we also discussed that symbolic plans can also provide a more interpretable and useful way to assign credit and blame if such a representation is considered.
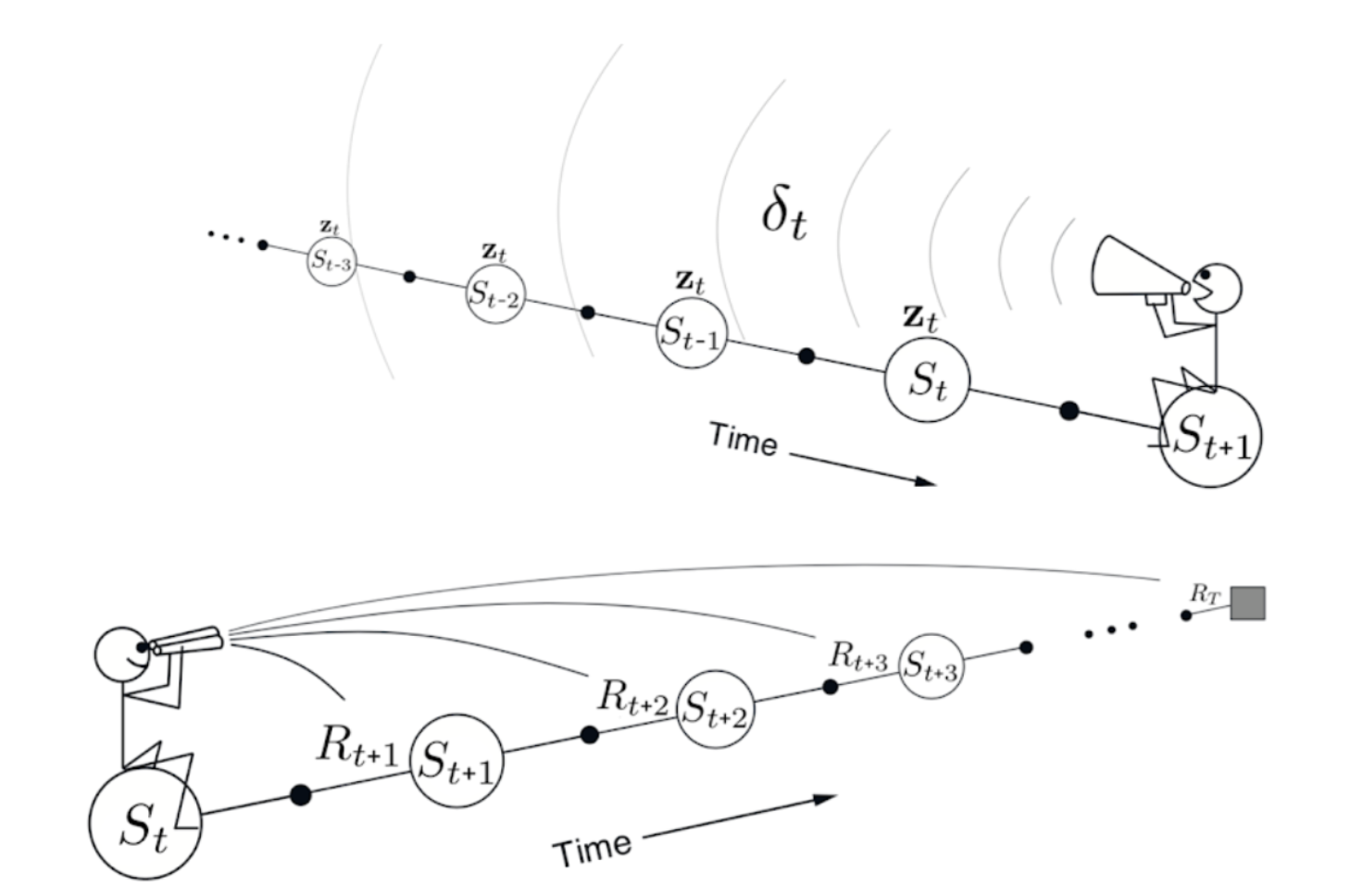
Besides, to develop methods for xSDM, the group delved into what kind of explanations a system would prescribe. The explanations could be:
-
1.
in the form of questions-based post hoc explanations encompassing which action caused which key event, e.g., in chess.
-
2.
in the form of a counterfactual capturing which actions would have caused an outcome, wherein users might have a bias, and machines might match or not match that bias.
-
3.
in the form of explanations that focus on different factors and not just outcome-oriented.
Heuristics like controllability etc. and a more detailed format included in 4) review paper on xRL [2] considering feature importance, counterfactual, and almost all methods in this survey paper could be developed on/built on for sequential explanations as well.
Q3: Evaluation? Focused on metrics, that is, how should we evaluate explanations?
The group noted a good starting point for many measures we believe are important for xSDM evaluation would be the review paper on xRL [2] which offers a variety of metrics over explanations such as 1) user’s feedback, 2) ethical trust improvement of the user, 3) relevance: of the explanation with respect to user goals, 4) completeness of the explanations with respect to user goals, 5) situational awareness global technique including freezing an experimental situation and probing the needs in that situation, 6) complexity where some users might prefer simple explanations while others favor more complex ones, 7) faithful to the underlying model, 8) explanations that are informative, 9) consistency, i.e., if an agent’s reasons for its decisions have changed, then it should explain why it provided different explanations before and after. One example of such an explanation might be achieving meta-level goals. The group noted that it would be useful to define each term in the SAFE-AI framework in the context of these metrics, including discrepancies b/w goal and task, to how to handle context here, which cannot be disjoint, while there can be multiple contexts at the same time, etc. Besides, understanding how failure relates here in these situations is also an open question, e.g., failures in robotics instances.
References
- [1] Dennett, Daniel C. (1971). Intentional systems. The journal of philosophy 68.4 (1971): 87-106.
- [2] Georgeff, Michael, et al. (1998). The belief-desire-intention model of agency. Intelligent Agents V: Agents Theories, Architectures, and Languages: 5th International Workshop.
- [3] Sanneman, Lindsay, and Julie A. Shah. (2022). The situation awareness framework for explainable AI (SAFE-AI) and human factors considerations for XAI systems. International Journal of Human – Computer Interaction 38.18-20: 1772-1788.
- [4] Sutton, Richard S. (2018). Reinforcement learning: An introduction. A Bradford Book.
- [5] Richards, Blake A., and Timothy P. Lillicrap. (2019). Dendritic solutions to the credit assignment problem. Current opinion in neurobiology 54: 28-36.
4.4 A Taxonomy of X-SDM: Summary
Hendrik Baier (Eindhoven University of Technology, NL. h.j.s.baier@tue.nl)
Mark T. Keane (University College Dublin, IE. mark.keane@ucd.ie)
Sarath Sreedharan (Colorado State University – Fort Collins, US.
sarath.sreedharan@colostate.edu)
Silvia Tulli (Sorbonne Université – Paris, FR. silvia.tulli@sorbonne-universite.fr)
Abhinav Verma (Pennsylvania State University – University Park, US. verma@psu.edu)
License: ![]() Creative Commons BY 4.0 International license © Hendrik Baier, Mark T. Keane, Sarath Sreedharan, Silvia Tulli, and Abhinav Verma
Creative Commons BY 4.0 International license © Hendrik Baier, Mark T. Keane, Sarath Sreedharan, Silvia Tulli, and Abhinav Verma
A core aim of the seminar was to develop a framework or taxonomy within which we can understand explanations for sequential decision making (SDM) with a view to structuring and road-mapping future work in the area. Initially, break-out groups were loosely formed into the current research lines covering SDM explanation in (i) AI Planning (Planning), (ii) Reinforcement Learning (RL), (ii) Robotics (Robot), and (iv) Cognitive Science and Neuroscience (CogSci). These groups set about trying to define, from their perspective, the components of a taxonomy for SDM based around five questions:
-
What is SDM? How should we define sequential decision making (SDM) as a topic area in the context of explanation?
-
What needs to be explained in SDM: On what will be the focus of explanation processes? What are the targets for the explanations generated?
-
How might SDM be explained? How will an explanation module compute explanations for SDM? What are the inputs and outputs to this module, what does it need to take into account to produce efficacious explanations that engender understanding, trust in users and ethical-compliance?
-
What metrics might be used? What metrics might be used to assess the efficacy of the explanations generated by any XAI system explaining SDM?
-
What is distinctive/unique about SDM? How is it distinct and its explanation distinct from other AI systems?
Each of the by-group answers to these questions were collated in plenary sessions and, specifically, reflected on, in the final plenary. Here, we attempt to define a generic taxonomy at a level of abstraction that captures SDM in a way that covers the specific perspectives from different research areas. Note, it is recognised that different instantiations of SDM may have component-concepts that are unique to a particular sub-area; for instance, a medical practitioner interacting with a succession of automated MRI diagnoses might require an explanation covering a succession of decisions (e.g., over a series of classifications of different parts of an MRI) without referring to a “policy” or a “reward function”, which would be characteristic of a SDM in reinforcement learning. In the following sections, we consider each of the main questions in turn, and try to develop general statements that capture the content of what was proposed and discussed during the seminar.
4.4.1 What is SDM?
This first question posed to the groups in the opening sessions under the general taxonomy rubric asked them to define, from their perspective of their area, what sequential decision making is about. Not surprisingly, each group produced a somewhat different response to these opening questions, although an overarching summary definition could be:
Definition.
Sequential decision making involves an agent making a series of related decisions over time, where each decision can be influenced by earlier decisions (i.e., a history), current observations and/or projected future states, to optimise some goal, objective or reward.
This overall definition covers the diverse responses given by different groups, which are summarized in their own words in Table 1.
| Field | Definition/Perspective |
|---|---|
| Planning | A problem setting where an agent generates a sequence of decisions, where each decision is selected to optimize an objective given a history. |
| Robots | SDM is series of decisions taken over a time period toward an objective where each decision affects future states and subsequent decisions. |
| RL | SDM is a problem where an agent makes successive decisions in response to successive observations (toward a goal). Components: Agent (decision-maker): a stateful system that produces actions in response to its own state and the last observation Environment (domain): a stateful system that produces observations in response to its own state and the last action Task (goal, objective): a characterization of the agent’s goal. |
| Cog Sci | SDMs involve transitions between states with choices leading to decisions in a sequence. We note there are sequential tasks which might not have a decision involved. |
As unique aspects of sequential decision making, setting it apart from the usual settings considered by XAI, were further mentioned: (a) its temporal setting – as in the dynamics of the environment itself, leading to unique features such as trajectories, key events, and forward and backward looking aspects of decision-making; (b) goals – involving temporally extended intent, temporally extended goals, subgoals, and consistency as the policy unfolds; (c) complexity – SDM has the usual issues of XAI but with the increased complexity of decision sequences; (d) exploration – there are specific issues around credit assignment, and one cannot easily sample anywhere in the state space.
4.4.2 What Needs to be Explained in SDM?
This second question posed to the groups, under the taxonomy rubric, was to determine the sort of things that are explained in SDM, what tends to be the focus of explanation, what aspects of systems tend to be targeted for explanation. Here, the responses from the groups differed, as groups focused on different explanation targets. Three main aspects were mentioned as to-be-explained items, covering:
-
The decision sequence and the processes/factors leading to this sequence (e.g., history, human inputs, reward function, task, goals etc.)
-
The operation of the decision-making algorithm
-
The environment, aka the current world model (e.g., a Markov Decision Process) or actual world and, in some cases, the relationship between the world model and actual world.
Below, we consider how each group elaborated these different foci in their responses.
4.4.2.1 Explaining the Decision Sequence and Its Influences
All four groups posited that there was a requirement to explain the decision sequence in and of itself, as well as the processes/factors leading to its generation. Overall, the consensus view could be summarised as follows:
Explaining Decisions: Every aspect of the decision sequence (or abstractions of those aspects) can be the focus of an explanation whether it be the decision outcome(s), its state or states, its action or actions, its stated goals, choices or objectives with respect to the past, present or future; or with respect to beliefs about or comparisons to any aspects of other decision sequences (and the status of these states in the World). This explanation of the decision sequence may also address the processes/factors that led to its generation.
This summary is designed to cover the diverse responses given by groups, shown in Table 2.
| Field | Explaining the Decision |
|---|---|
| Planning | Components to be explained: sequence of decision (actions, behaviour, plan or policy) Plan: validity, preference, clarification |
| Robots | Decision, state, belief, action, goal, plan (supported at different levels of abstraction) States: (a) state (may be estimated and not given) (b) in robotics could imply check on perception via state estimation (c) justify a state or belief state Actions: (a) description of plan (b) what happens between contact events (c) full trajectory (from place A to place B) (d) continuous-space signals (velocity, torque) Plans: comparison of plans (w.r.t specific goal) for: (a) outcomes (e.g., Best/Expected/Worst case, distribution, …) (b) state visitation (c) features/criteria (e.g., safety, usability) that may/may not be used in objective function Goals: state vs. outcome description Failures: in the decision sequence |
| RL | Want to explain local decisions: either individual decisions (a given s) or several decisions (trajectories, groups of states, etc). Want to explain the state and time axis of the decision(s) and longer-term behaviour. Also, may want to explain global decisions (policy, global distillation, sub-goals) And influences on the decision: e.g., influential training data: in |
| Cog Sci | Past states, the current state, or future possible states Focus may be on (i) multiple step trajectories comprising 1-step transitions with single step actions wrt. past or future (ii) sequence of actions i.e. operating at another granularity w.r.t. to past or future (iii) current state. Focus may be on goals/choices in the decision sequence, as these may change. Goals as symbolic descriptions of classes of states in a plan. |
4.4.2.2 Explaining the Operation of the Algorithm
All four groups posited that there was a requirement to explain the operation of the algorithm itself being used to make the sequential decisions. This explanation focus could be summarised as follows:
Explaining the Algorithm: The explanation may also focus on the agent or learning method or decision-making algorithm itself, to elucidate its operation to end-users.
This summary description is designed to cover the diverse responses given by groups, shown in Table 3.
| Field | Definition/Perspective |
|---|---|
| Planning | Components to be explained: Algorithm |
| Robots | It may be necessary to explain the agent’s constraints. And to explain failures arising from flaws in the algorithm arising from perception, reasoning, and control. |
| RL | SDM Algorithm: the mechanisms that give rise to behaviour. The learning or execution algorithm. |
| Cog Sci | How the system is working? |
4.4.2.3 Explaining the Environment (World Model or Actual World)
It was also considered that there could be a requirement to explain aspects of the environment involved in a sequence of decisions, where this environment means a world model (e.g. an MDP) or the actual world, with sometimes a concern for the relationship between these two worlds. This explanation focus could be summarised as follows:
Explaining the environment: The explanation may also focus on the environment, as captured in the world model or the agent’s perception/comprehension of the actual world in that model, the process of forming the world model, and discrepancies between both of these worlds.
where this summary description is designed to cover the diverse responses given by groups, shown in Table 4.
| Field | Definition/Perspective |
|---|---|
| Planning | Components to be explained: model (environment, other agents, user) Environment (domain): a stateful system that produces observations in response to its own state and the last action |
| Robots | There may be a need to explain environmental constraints. And to explain failures arising from arising from the robot’s physical constraints and flaws (e.g., in sensors and motors). Environmental/agent constraints such as (computation, memory, power). |
| RL | The MDP (transitions, rewards, discount). Components of an MDP, the objective. |
| Cog Sci | Not addressed, beyond the concern for modelling users. |
4.4.3 How Will SDM Be Explained?
This third question posed to the groups, was to determine how will SDM be explained? How will an explanation module compute explanations for SDM? What are the inputs to this module and outputs from it? What explanation strategy might be used? What does it need to take into account to produce efficacious explanations that elicit the understanding and trust of users, enabling the AI-system to be ethically compliant? The summary statement of the answer to this how question essentially lists what an SDM explanation module needs to do:
What to Compute in Explaining SDM: In computing explanations to SDM there is a need to (i) identify/select the target-item to be being explained in SDM (explanandum), (ii) use the task context (e.g., is the SDM system predicting an outcome, optimising a current plan, presenting alternatives) (iii) represent users’ information-needs, i.e., their current explanation goals, their role in the interacting with the system (e.g., learner, teacher, co-designer), their stakeholder category (i.e., professional role), (iv) determine the goals of the AI system, (v) identify other contextual factors of importance (e.g., user expertise, time of day, organizational context), (vi) identify an effective explanation strategy to deliver the explanation
Here, the responses from the groups differed, as some groups focused on different aspects. In Table 5, we consider how each group elaborated on these different foci in their responses.
| Field | Definition/Perspective |
|---|---|
| Planning | Explanations may be either global or local explanations. The may used contrastive or counterfactual strategies, convey model information and explain abstractions. They may be communicated by summarisation, using natural language or some other representation scheme. |
| Robots | Explanations will need to determine: a. the factors that inform reasons (e.g., states, actions, plans, goals, objective components..) b. whether the required explanation is prompted (reactive) (may need disambiguation due to vague requirement) vs. unprompted (proactive) c. whether the required explanation is prescriptive (outcome of a decision-making process) vs. descriptive (my decision-making rationale is…), d. the superset of reasons that support the explanation (n.b., frame problem arises as embodiment requires consideration of the world which admits needing to consider many levels of abstraction), e. relevant reasons to present to the explainee, considering the explainee’s context and how that context will influence how they receive information), f. other factors/constraints (robot constraints, environmental constraints), g. comparison of different explanations, h. the presentation modality to use for information to the explainee (noting the interface availability conditioned on operating environment) |
| RL | We inherit everything from typical XAI: counterfactuals, counterexamples, causal models, and strategy summaries. Explanations being presented in visual forms, NLP, Proofs/Maths/Logic or interactively. |
| Cog Sci | The explanation methods will need to compute: a. the goal of the user (and how these may change over time) b. the task/context/role of the SAFE-AI Framework, c. the most relevant items to the user that need to be explained, d. forward and backward looking credit assignments. Explanation strategies are all the traditional XAI ones: feature-importance, counterfactuals, and other post-hoc ones. |
4.4.4 What Metrics Should be Used for SDM Explanations
This fourth question posed to the groups, under the general rubric of taxonomy, was to discuss the metrics of SDM explanations that were most crucial to their area. The discussions around this question were seeded by the metrics presented in Table 1 of Milani et al. 2024 [2]. While there was substantial overlap in the type of metrics that were required to judge SDM explanations, the groups were also able to identify many distinct foci that were unique to the challenges that arise in their areas. The SDM explanation metrics could be summarised as follows:
Metrics for Explanations: In developing metrics for SDM explanations there is a need to (i) create metrics for online and offline explanations, (ii) have metrics that are both user dependent and independent, (iii) measure both user-independent and subjective–user specific–criteria, (iv) take user mental models into account, (v) have strong measures for the models inherent properties (like accuracy, performance, uncertainty), (vi) have mechanisms to measure psychological outcomes like trust and understanding.
The groups had varied opinions of the most salient properties that need to be captured by explanation metrics. In Table 6 we have provided a few of the points that each group focused on during the discussion.
| Field | Definition/Perspective |
|---|---|
| Planning | Metrics will need to be evaluated on several user dimensions: a. understanding: self-explanation (can I see if this is the solution?) b. actionability c. uncertainty reduction d. trust e. satisfaction looking at user preferences f. correctness/completeness. |
| Robots | Metrics will need to handle qualitative and quantitative evaluations Metrics will need to assess psychological aspects (user studies assessing usefulness and understanding) Metrics for mechanistic studies (e.g., coherence, coverage, accuracy) and goals (where the desired outcome is achieved v understanding) Online and offline (post-hoc) Should include measures of whether an explanation is needed at a certain time or event. |
| RL | Metrics can be functional or computational: such as correctness, optimality, verification, faithfulness, continuity/stability, robustness; with the issue of them depending on output type. Metrics can be human-grounded: either objective ones (user performance, mental models) or subjective (calibrated trust) |
| Cog Sci | Agreed with the metrics suggested in [2]; Fidelity, Performance, Comprehensibility, Preferability, Actionability, Visualization, and Cognitive load. Raised possibilities of creating more fine-grained evaluations within these categories. |
5 Breakout Sessions on Open Questions and a Roadmap of Explainable SDM
5.1 Simulation Statistics
Hendrik Baier (Eindhoven University of Technology, NL. h.j.s.baier@tue.nl)
Bradley Hayes (University of Colorado – Boulder, US. bradley.hayes@colorado@edu)
Simon Lucas (Queen Mary University of London, UK. simon.lucas@qmul.ac.uk)
Anna Lukina (TU Delft, NL. a.lukina@tudelft.nl)
Ann Nowé (VU Brussels, BE. ann.nowe@vub.be)
License: ![]() Creative Commons BY 4.0 International license © Hendrik Baier, Bradley Hayes, Simon Lucas, Anna Lukina, and Ann Nowé
Creative Commons BY 4.0 International license © Hendrik Baier, Bradley Hayes, Simon Lucas, Anna Lukina, and Ann Nowé
Overview.
Statistical planning algorithms such as Monte Carlo Tree Search (MCTS) use fast and copyable simulation models to provide intelligent decision-making across a range of challenging problem domains. In this working group, we discussed how best to use the simulations to provide explainable decisions. Simulations provide causal models of a domain, and inherently offer a form of explanation: we can simulate a proposed plan and observe the expected outcome, and also observe why rejected plans led to inferior outcomes.
Context.
The nature of the explanations may depend on the explained. An AI developer needs to be able to thoroughly investigate the nature of the planning decisions and what they depend on using a range of tools, some of which may take skill to operate and interpret. An end user is likely to need a high-level view summarizing the key points.
We can also distinguish between online explanations, where the human is in the loop as the decision-making is unfolding, versus post-hoc analysis, or a priori analysis when considering a range of future scenarios.
Uncertainty.
Decision-making and the explanation of decisions are often complicated by the need to deal with two types of uncertainty, environmental and algorithmic:
-
Environmental uncertainty: this arises from stochastic simulation models, from uncertainty due to partial observability, and from not knowing what adversaries and collaborators may do.
-
Algorithmic uncertainty: statistical planning algorithms usually have a random element such as the random rollouts used in MCTS. This means that given the same inputs, the algorithm may recommend different actions given different random seeds.
Simulator Design.
The type of explanations we can potentially generate also depends on the nature of the simulator, and whether we have access to the code or have ways to tag key events, and generate visualizations. Given a “black-box” simulator that gives access only to the forward model, we can monitor the variation in reward as we play out a trajectory, and how sensitive the expected reward is in relation to variations in action plans and assumptions.
If we can access the simulator state then we can enrich this in a number of useful ways, for example showing heat maps of expected state features, estimating the timing and likelihood of key events, and even generating video clips of interesting vignettes.
In some cases, the nature of the simulation is closely tied to the problem. In games, for example, the starting point for the simulator is a faithful implementation of the game in the case of a board game. In the case of a video game, the simulation essentially is the game, though for statistical planning algorithms we normally run it headless (i.e., with the graphics turned off). But both for complex video games and for real-world problems, we may still need a fast approximate simulator to run enough iterators of the planning algorithm to make good decisions. In these cases, the approximations to enable the decision-making may also feed into the explanations of the decisions.
Related Work.
To date much of the work in the area has focused on explainable search and has focused on MCTS [1]. The existing work concentrates explanations on the search tree [2, 3], which is a key part of MCTS. There is also a clear need for research beyond this, and the following directions seem promising:
-
Using the entire rollouts to aid the explanation. This is essential to algorithms that base their decision on the entire rollout, for example, Rolling Horizon Evolution [4].
-
Monte Carlo Graph Search [5] aims to search more efficiently than MCTS in cases where different action sequences may lead to identical or similar states. The metrics used to define state similarity, by this or other algorithms working with state or action abstractions, may also be instrumental in explaining the decisions made.
Summary.
Statistical planning algorithms are different in nature from classical planning algorithms, requiring different approaches to explain their decisions. There is a small but useful research literature in the area and many promising avenues for future work.
References
- [1] Baier, H., and Kaisers, M. (2021). Towards Explainable MCTS. In 2021 AAAI Workshop on Explainable Agency in AI.
- [2] An, Z., Baier, H., Dubey, A., Mukhopadhyay, A., and Ma, M. (2024). Enabling MCTS Explainability for Sequential Planning Through Computation Tree Logic. In Proceedings of the 27th European Conference on Artificial Intelligence (ECAI 2024), Frontiers in Artificial Intelligence and Applications vol. 392, 4068–4075.
- [3] Bustin, R. and Goldman, C. V. (2024). Structure and Reduction of MCTS for Explainable-AI. In Proceedings of the 27th European Conference on Artificial Intelligence (ECAI 2024), Frontiers in Artificial Intelligence and Applications vol. 392, 1246–1253.
- [4] Gaina, R. D., Devlin, S., Lucas, S. M., and Perez-Liebana, D. (2022). Rolling Horizon Evolutionary Algorithms for General Video Game Playing. IEEE Transactions on Games, 14(2), 232-242. https://doi.org/10.1109/TG.2021.3060282
- [5] Leurent, E., and Maillard, O.-A. (2020). Monte-Carlo Graph Search: the Value of Merging Similar States. In Proceedings of the Asian Conference on Machine Learning (ACML 2020), PMLR, Vol. 129, 577-592.
5.2 Evaluation in explainable sequential decision making
David Abel (Deepmind - London, UK. dmabel@deepmind.com)
Claudia Goldman (Hebrew University Business School – Jerusalem, IL.
claudia.goldman@mail.huji.ac.il)
Tobias Huber (TH Ingolstadt, DE. tobias.huber@thi.de)
Benjamin Krarup (King’s College London – London, UK. benjamin.krarup@kcl.ac.uk)
Mark Riedl (Georgia Institute of Technology – Atlanta, US. riedl@cc.gatech.edu)
Silvia Rossi (University of Naples, IT. silrossi@unina.it)
Silvia Tulli (Sorbonne Université – Paris, FR. silvia.tulli@sorbonne-universite.fr)
License: ![]() Creative Commons BY 4.0 International license © David Abel, Claudia Goldman, Tobias Huber, Benjamin Krarup, Mark Riedl, and Silvia Tulli
Creative Commons BY 4.0 International license © David Abel, Claudia Goldman, Tobias Huber, Benjamin Krarup, Mark Riedl, and Silvia Tulli
This group discussed the unique challenge of evaluating methods for explainability in SDM. We framed our brainstorm by agreeing that the point of evaluation should be to elucidate how, and to what extent, users get value from explanations.
The challenge of evaluation in xSDM.
However, we all agreed that SDM necessitates a great deal of complexity for two key reasons. First, the domains, decision-makers, and objects to be explained are often extremely complex. Second, evaluating a method for explainability often requires a human-in-the-loop, which adds cost and difficulty to evaluation.
Complexity of SDM.
Regarding the complexity of SDM, we noted that SDM problems are often those in which users lack knowledge about the solution space. For example, in AlphaGo [5], the famous move37 was initially declared a mistake by the system. It was only later that this move was identified as a brilliant, insightful move that led to AlphaGo’s victory in that match. Here, we see that even in a closed domain whose rules are known and whose states and actions are finite, it is still possible for those familiar with the domain to not fully understand the solution space. This is far more common in SDM than in other domains such as classification due to the added complexity of decisions over time.
Three kinds of evaluation.
Does evaluation in xSDM strictly need humans in the loop? We agreed that it was valuable to distinguish between three kinds of cases for the purpose of evaluation: (1) humans are strictly in the loop, (2) human data or models are used, or (3) objective properties of the approach are studied. The last case could still be useful for studying, for instance, the speed with which a method can produce its evaluation or other more quantitative properties. The second setting is one where a dedicated group could in principle collect a massive dataset or curate large models for rough evaluation at scale, similar in spirit to ImageNet [2] or the Arcade Learning Environment [1]. On the first style of evaluation, we suggested it could still be valuable for the community to adopt certain guidelines and standards for evaluation. As an example, the psychology community regularly adopts the convention of pre-registering experiments [3](Simmons et al., 2021); the xSDM community could make a push for adopting parallel kinds of experimental methods, or release templates to encourage specific pathways.
Avoiding Scoreboards.
We all agreed that one key trap to avoid is the creation of an evaluation suite that becomes used as a scoreboard; that is, the goal is no longer to gain insight into xSDM methods or problems, but is instead used as a score to be maximized. We agreed that this has taken place in other communities throughout AI history, and suggested it could be difficult to avoid.
The xAI gym.
In light of all of the above, the group proposed the design and development of the xAI gym, a lightweight evaluation suite for xSDM methods. The goal of the xAI gym would be twofold. First, to make it easier for the community to share progress, insights, code, and resources. Second, to make it easier to reach a consensus on rigorous methodology and to do better explainability science. We all agreed that because explainability research is so context-dependent, it becomes very difficult to compare the characteristics of different methods, especially as the field is so fragmented. This could also expedite reproducibility. Our initial mockup of the xAI gym had the following components:
-
Domains: implementations of a few standard environments.
-
Triggers/probes/scenarios: an aperture into the joint SDM system.
-
Explanation goal: what is it we’re after with the explanation?
-
Output forms.
-
Ground truth data-set for evaluation.
-
Agents.
-
xAI algorithm for generating explanations.
-
Evaluation method: questionnaire, methodology, measurements.
For each dimension, our suggestion was that the xAI gym would come with a few of each, but also expose a simple API for others to add their own. Then, the xAI gym’s main operation would be to take as input an instance of each of (or a subset of) the above items, and output a multidimensional visual of characteristics, like the spider-web from the bsuite [4].
We agreed that some subset of the community could benefit from some version of xAI gym.
References
- [1] Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. (2013). The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47, 253-279.
- [2] Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., and Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255).
- [3] P Simmons, J., D Nelson, L., and Simonsohn, U. (2021). Pre-registration: Why and how. Journal of Consumer Psychology, 31(1), 151-162.
- [4] Osband, I., Doron, Y., Hessel, M., Aslanides, J., Sezener, E., Saraiva, A., … and Van Hasselt, H. (2019). Behaviour suite for reinforcement learning. arXiv preprint arXiv:1908.03568.
- [5] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., … and Hassabis, D. (2017). Mastering the game of go without human knowledge. Nature, 550(7676), 354-359.
5.3 Initialization and Invocation of Explanation Generation Processes
Samer B. Nashed (University of Montreal, CA MILA – Quebec AI Institute, CA.
samer.nashed@mila.quebec)
Rebecca Eifler (LAAS-CNRS – Toulouse, FR. rebecca.eifler@laas.fr)
Mark T. Keane (University College Dublin, IE. mark.keane@ucd.ie)
Ruth Mary Josephine Byrne (Trinity College Dublin, University of Dublin, IE.
rmbyrne@tcd.ie)
Julian Siber (CISPA – Saarbrücken, DE. julian.siber@cispa.de)
License: ![]() Creative Commons BY 4.0 International license © Samer B. Nashed, Rebecca Eifler, Mark T. Keane, Ruth Mary Josephine Byrne, and Julian Siber
Creative Commons BY 4.0 International license © Samer B. Nashed, Rebecca Eifler, Mark T. Keane, Ruth Mary Josephine Byrne, and Julian Siber
The majority of work on explainable sequential decision making has focused on developing algorithms and frameworks for identifying the underlying reasons that support a given explanation request, often called explanans [1, 2, 3, 4, 5]. This working group focused on several practical problems that arise when implementing such approaches and integrating them into real-world systems. Principally, we focused on 1) determining when, if at all, systems ought to generate explanations without a request from the user and how they might determine such conditions; 2) how systems may deal with requests for explanation that, from an algorithmic perspective, are not completely specified by the user; and 3) when faced with a large number of equally correct or plausible explanans, how explanation generation systems ought to select which subset of potential reasons to focus computation on or to report. This group focused on minimizing the number of assumptions about the underlying task or application while still relying on the common structure of sequential decision-making tasks and algorithms to discuss problems more specifically when possible.
5.3.1 When to Explain
A central issue for any explanation of a sequential decision-making system is that users have both a desire for information as well as a limit to amount of information they can process. That is, understanding and using an explanation effectively creates cognitive load for the user [6]. Thus, from both the user’s perspective and the system’s perspective there is some cost associated with furnishing an explanation, and so systems ought to produce explanations only when the benefits of doing so are greater than the associated costs. At a high level there are two types of explanation for which we may want to answer this question: what we term anticipatory or proactive explanations, where the system explains an action it is about to take or will take in the future, and reactive or post-hoc explanations, where a system explains why it took an action in the past. From an algorithmic perspective, deriving explanations in these cases is often very similar, but the tools available to actually trigger an explanation computation are quite different.
5.3.1.1 Anticipatory and Proactive Explanations
We discussed several potential ethos for determining when to instantiate or trigger an explanation computation. The first is based on so-called ‘critical decision points’. These are points or states along a trajectory or plan where the difference between potential successor states, according to some metric, is large. For example, there may in some cases be an action taken that is not reversible or has the potential to result multiple outcomes of vastly different utility. Such critical points may be identified in several ways, and we highlight two possibilities. First, if an action may affect the reachability or state ergodicity for the agent, then there may be value in explaining the rationale behind these potentially irreversible actions. Second, if the planning model indicates a distribution over successor state utilities that has a high variance, then it may be seen as necessary to explain the agent’s behavior as the user may perceive such a situation as posing significant risk, even if the plan or policy is optimal in the sense that expected utility is maximized.
Beyond critical decision points, there may be value in proactively furnishing explanations in order to address or reduce ambiguity. For example, if there are a large number of roughly equivalent actions, explaining an agent’s reasoning may help the agent seem less arbitrary. This is somewhat complicated by the fact that many ties in planning algorithms are in fact broken arbitrarily, so producing explanans that are acceptable to users in such a scenario is likely to be challenging in its own right. Similarly, if there is ambiguity with respect to the current state of the agent rather than the resultant state, explanations may have value in making users aware of what the artificial agent believes is true. This is most commonly an issue in systems with partial observability [7, 8, 9], where the agent only maintains a belief about what is true rather than know with certainty. In these scenarios, proactive explanations might potentially feature “close” counterfactual scenarios that provide explanans based on how the agent would reason about situations that are similar but not identical to its current one. For example, if there was a bicyclist approaching on the agent’s left (though it does not believe there to be one), it would alter its behavior; however, because it believes there to be no cyclist, it will proceed with action .
The last category of triggers of proactive explanations we considered was those learned from data. In practice, as people interact with systems, it is possible to collect very large datasets, including items like the states in which explanations are requested or the moments when other actions are taken that indicate a deviation of user mental models from agent behavior, such as when a human driver takes over control from an autonomous vehicle. Generally, it is difficult to map such moments to specific metrics, but the strong performance of large machine learning models to represent similarity between high-dimensional data [10] makes us optimistic that data-driven approaches for instantiating proactive explanations are also viable.
5.3.1.2 Reactive and Post-hoc Explanations
The most common prevailing assumption in the explainable sequential decision-making literature is that explanations are served in a post-hoc manner upon request. While certainly a point of oversight broadly speaking, this is a reasonable assumption for many cases where proactive explanations are too frequent or expensive, or require too much cognitive load, and instead system designers opt for post-hoc explanations. In general, we identified two types of events beyond explicit explanation requests that may provide good triggers for generating explanations of past action selection: unexpected behavior and unexpected outcomes.
Unexpected behavior occurs when the agent takes an action or a sequence of actions that do not align with the expectations of observers or users. This working group considers identifying such behaviors extremely challenging, possibly to the point of rendering approaches based on unexpected behavior infeasible. This is due to several reasons. First, determining what the user expected the agent to do without relying on explicit communication from the user is very challenging, and would almost certainly require an explicit model of the user. Basic models of the user may be practical, such as gaze tracking or other bio-markers of surprise or intent, but beyond such simple models, understanding a user’s state of mind with enough fidelity to infer which agent actions they predict seems impractical. Such reasoning processes may also reduce to reasoning about theory of mind, an area which has been shown to be computationally intractable in most cases.
Without modeling users either implicitly or explicitly, it may still be possible to identify unexpected behavior statistically, by comparing current agent behavior to past agent behavior. Indeed, for many sequential decision-making systems a change in behavior without a change in the environment or objective function would likely be unexpected as this would represent a seeming deviation from optimal behavior. While we do not identify any particular theoretical shortcomings of this approach, it is important to note that the scenarios in which such a method might be applicable seem limited. In order to generate reliable triggers, behavior of an agent given the same or very similar scenarios would need to change frequently without violating optimality, and the agent would need to frequently visit similar states in order to generate enough data to identify deviations. These two conditions are not typically not satisfied simultaneously, as if the problem is small enough to generate sufficient data for each state then the agent has likely converged to a fixed optimal policy, while if the environment is large then it is difficult to gather enough behavior data in order to identify reliable triggers.
In contrast to explanations triggered by unexpected behaviors, explanation triggers based on unexpected outcomes do not seek to reconcile a fundamental difference in reasoning or world models between agent and user. Instead, such explanations are mostly focused on trust building and reassurance. For example, humans often employ such explanations after accidentally causing damage or offense. In deterministic sequential decision-making tasks there is no notion of unexpected outcome. However, for many decision-making models, such as Markov decision processes, it is relatively easy to identify when a low-probability transition has occurred. It is also possible to identify when such events have a large impact on the agent’s expected utility. For example, we could simply monitor the difference in value function between state and successor state , and when there is a large difference, this indicates a low-probability event has occurred and thus an explanation is warranted. The main downside of such approaches is that it is difficult to use them to understand the underlying reasoning of the sequential decision-making agent since they are primarily invoked in response to stochasticity in the environment rather than the agent’s reasoning.
5.3.2 Resolving Multiple Explanation Requests
We have seen above that automatic post-hoc explanation triggers are not straightforward to design. In many systems, this problem is avoided entirely by simply relying on humans to request explanations. While appealing, this creates several other challenges due to humans’ frequent underspecification of counterfactual scenarios within the explanation request. For example, the request for explanation “Why did you open the door?” is an underspecified counterfactual. It is missing a “foil”, typically provided in the form of a “rather than” or “instead of” clause. Many algorithms for explanation generation require both the action taken or proposed by the agent (action ) as well as one or more hypothetical alternative actions (e.g. action ). Humans communicating in natural language often leave the foil implicit, relying on the explainer to determine which counterfactual assignment is most relevant. Such problems os disambiguation are notoriously difficult for computers, no less so when related to explanations.
Here we have outlined several potential approaches for dealing with this issue. First, it may be possible to use the heuristic that foils are often minimal (or small) deviations from the fact. For example, they are often the negation or a semantically similar alternative of the fact in the request: “Why did you open the door instead of [leaving it closed]/[opening the window]?”. This is a very appealing solution if such negations or similar alternatives can be easily identified. However, this may be challenging in practice.
In settings where the agent is engaged in a well-defined task (e.g. autonomous driving) rather than a more open-ended deployment (e.g. domestic home robot), then it may be possible to cover most of the frequently referenced foils through a list of pre-set options derived from user studies or from domain experts. User studies in this case seem particularly compelling for their ability to include users who will be genuinely curious and confused about the agent, prompting a more natural distribution of explanation requests. Results from such studies could also be integrated into explanation systems via iterative, interactive processes that lead to users confirming counterfactual variable values directly. Similar dialogue systems have been proposed for other systems, including program synthesis [12], question answering [13], and human-robot interaction [14], and thus we consider this a relatively promising approach.
Another possible approach is to cluster similar potential foils together. This could be done semantically via large language models, or by analyzing forward models used for planning to find symmetries or similarities with respect to action effects (e.g. a reasonable implied foil for the fact (action) of changing lanes to the right would be the symmetric action of changing lanes to the left). Given a fact belonging to a particular cluster, potential foils could then be drawn from that cluster to complete counterfactual explanation request. A primary challenge for such an approach is of course finding and curating appropriate clusters of state and action variables. This problem is exacerbated by the fact that variables in decision-making problems typically do not represent the agent or the world at a single level of abstraction in space, time, or concept. Thus, making comparisons between variables in order to form clusters could be potentially very challenging.
Last, we discussed the possibility of learning to fill in missing foils directly from data gathered from previous requests for explanations. This may work well for problems where the number of variables is small or where certain foils are only of interest in particular scenarios within the decision-making problem. However, as problems scale to larger state spaces and tasks and agents become more complex, it seems likely that data sets size will increasingly become a limiting factor. Thus, developing data-efficient methods for learning to do foil assignment will likely be important.
5.3.3 Choosing between Plausible Explanans
The meta-choice between different potential explanans generally occurs twice in an explanation generation pipeline. First, in some systems it may be possible to restrict analysis or computation to a subset of possible explanans. This general concept has many operationalizations, but a common example is Aristotle’s classification of the different types of explanations (material, formal, efficient (mechanistic), final) [11]. Once a particular type of explanation is chosen, this effectively creates a subset of all possible explanans from which the eventual explanation presented to the user will draw from.
Second, once an algorithm has been run to identify all valid explanans, a subset of these variables must be selected to present to the user. In general, there may be many variables in the planning process that meet the given definition or heuristic that highlight them as relevant to the counterfactual analysis taking place. If the number is too high, presenting all such variables will unnecessarily increase cognitive load, create explanations which are convoluted and hard to follow, and possibly confuse the user rather than clarify. Thus, reducing the overall number while still maintaining the most important components is an important open problem. In both cases, this working group identified user studies as the far-and-away most promising method to determine both generalizable rules as well as context-dependent preferences.
References
- [1] Nashed, S. B., Mahmud, S., Goldman, C. V., and Zilberstein, S. (2022). Causal explanations for sequential decision making under uncertainty. arXiv preprint arXiv:2205.15462.
- [2] Milani, S., Topin, N., Veloso, M., and Fang, F. (2024). Explainable reinforcement learning: A survey and comparative review. ACM Computing Surveys 56.7: pp. 1–36.
- [3] Tsirtsis, S., De, A., and Rodriguez, M. (2021). Counterfactual explanations in sequential decision making under uncertainty. Advances in Neural Information Processing Systems 34: pp. 30127–30139.
- [4] Bica, I., Jarrett, D., Hüyük, A., and van der Schaar, M. (2020). Learning “what-if” explanations for sequential decision making. arXiv preprint arXiv:2007.13531.
- [5] Gyevnar, B., Wang, C., Lucas, C. G., Cohen, S. B., and Albrecht, S. V. (2023). Causal Explanations for Stochastic Sequential Multi-Agent Decision-Making. AAMAS Workshop on Explainable and Transparent AI and Multi-Agent Systems.
- [6] Sweller, J. (1994). Cognitive load theory, learning difficulty, and instructional design. Learning and Instruction 4.4: pp. 295–312.
- [7] Coruhlu, G., Erdem, E., and Patoglu, V. (2021). Explainable robotic plan execution monitoring under partial observability. IEEE Transactions on Robotics 38.4: pp. 2495–2515.
- [8] Lauri, M., Hsu, D., and Pajarinen, J. (2022). Partially observable Markov decision processes in robotics: A survey. IEEE Transactions on Robotics 39.1: pp. 21–40.
- [9] Kurniawati, H. (2022). Partially observable Markov decision processes and robotics. Annual Review of Control, Robotics, and Autonomous Systems 5.1: pp. 253–277.
- [10] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. (2021). Learning transferable visual models from natural language supervision. International Conference on Machine Learning: pp. 8748–8763.
- [11] Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence 267: pp. 1–38.
- [12] Mayer, M., Soares, G., Grechkin, M., Le, V., Marron, M., Polozov, O., Singh, R., Zorn, B., and Gulwani, S. (2015). User interaction models for disambiguation in programming by example. Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology, pp. 291–301.
- [13] Sun, W., Cai, H., Chen, H., Ren, P., Chen, Z., de Rijke, M., and Ren, Z. (2023). Answering ambiguous questions via iterative prompting. arXiv preprint arXiv:2307.03897.
- [14] Doğan, F. I., Torre, I., and Leite, I. (2022). Asking follow-up clarifications to resolve ambiguities in human-robot conversation. 2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 461–469.
5.4 A Roadmap for X-SDM: Summary
Hendrik Baier (Eindhoven University of Technology, NL. h.j.s.baier@tue.nl)
Mark T. Keane (University College Dublin, IE. mark.keane@ucd.ie)
Sarath Sreedharan (Colorado State University – Fort Collins, US.
sarath.sreedharan@colostate.edu)
Silvia Tulli (Sorbonne Université – Paris, FR. silvia.tulli@sorbonne-universite.fr)
Abhinav Verma (Pennsylvania State University – University Park, US. verma@psu.edu)
License: ![]() Creative Commons BY 4.0 International license © Hendrik Baier, Mark T. Keane, Sarath Sreedharan, Silvia Tulli, and Abhinav Verma
Creative Commons BY 4.0 International license © Hendrik Baier, Mark T. Keane, Sarath Sreedharan, Silvia Tulli, and Abhinav Verma
In the following, we summarize the results of the breakout groups and plenary meetings on the topic of open questions and a potential roadmap for explainable sequential decision making.
5.4.1 Open Questions
While each question has aspects that are relevant to the more general problem of explainable AI, we try our best to highlight aspects more specific to sequential decision making.
-
1.
How much do we have to study human behavior before we make more progress in generating explanations for sequential decision making problems?
With respect to the question, we do not mean that the replication of human explanation should necessarily be the goal, but it may be worthwhile to understand how humans explain. However, a full understanding of human behavior is not a prerequisite for building XAI systems. It is also important to understand how people intake information. At the level of community, one of the challenges is how we can retain contact with nearby communities, such as cognitive science, psychology, human factors, and so on. This would allow us to leverage the latest results from these disciplines to inform how we design explanations. Another point that was brought up was how we find actual end users of AI systems where our method can be tested. Along these lines, there was a question of whether we can make better connections with industry. -
2.
What are the goals of an explanation?
There was general agreement that there is no one-size-fits-all solution. A more overarching objective could be to identify explanations that could help support the overall human goal or human-AI/robot team goal. This could also inform what component to explain and what level of abstraction to provide the explanation at. For more specific goals, one should look to use cases, industry, and end-users. There is also a need to look at the existing works to identify potential implicit goals that may have been incorporated into the methods. -
3.
How do we explain modeled and unmodeled side effects?
A large part of the problem of explaining side effects was the problem of having a clear definition of what we mean by a side effect. As part of the effort, one will need to identify what parts of the problem are modeled vs. unmodeled. Additionally, there was a general agreement that side effects were aspects that were not known or unanticipated at the decision time. There was a general interest in the idea of using LLMs as a tool one could leverage to explain side effects. There is also a dimension of how user modeling would come into play during the explanation of side effects. Finally, there is a question of when to provide explanations for side effects. One of the notions that was discussed was providing explanations when the system transitions to a critical state, where the critical state was defined to be one from where the outcomes of the current plan may be significantly altered from what was expected. We also propose treating explaining failures as a special case of explaining side effects. -
4.
How do we support explanations in the context of large solution spaces?
There was a general consensus that more interesting aspects of generating explanations in the presence of large solution spaces weren’t merely a result of the presence of a large solution space, but other factors that may occur with it. For example, there could be cases where selected solutions are very far from what the user expected. In large solution spaces, there is also a possibility that the solver hasn’t explored the entire solution space. Finally, the presence of a large solution space is also closely related to the dimension of the degree of uncertainty the user might have. Here, the uncertainty might not just be related to the solution space but also to the environment and the decision-maker. -
5.
How do we effectively learn user models?
Some of the potential components one could learn include epistemic, inferential, and vocabulary capabilities of the user. A related challenge that we need to address here is identifying what part of the user model is relevant to the given problem or explanatory query and how we model it. In general, information like their knowledge or expertise might be important. A potential possibility here could include starting with a model of an archetypical user and then personalizing it based on interaction. There is also a question of learning such models in an ethical way. -
6.
When is it okay (for an AI) to tell a (white) lie?
Our initial discussion started with a focus on white lies, i.e., a lie you tell someone that is harmless and could have legitimate arguments for using it, including simplifying the overall explanations. However, soon enough, the group decided to focus on the question of when any form of lying might be considered acceptable. Since there is more established work in this direction for the overall XAI problem, the group decided to focus just on problems specific to SDM. One of the reasons lying might find more utility in the context of SDM could be because the explanations, in general, are more complex and may take longer to communicate. There could also be more opportunities to lie. Also, if we look at problems that involve real-time explanations, there may be scenarios where lying could allow the agent to perform more actions, or avoid explanation bottlenecks. Also, the group highlighted the fact that omission can also be considered a form of lying. -
7.
How do we explain changing policies/plans in a trajectory?
Next, we discussed the problem of explaining when the agent may choose to change its decisions during execution, including cases like replanning. This is closely related to the problem of life-long learning. While there might be differences in the specifics of explanations as one moves from one decision-making paradigm to another, there is a need to establish a more general framework that captures the commonalities. -
8.
How do we generate explanations for mismatches in vocabulary between user and AI?
The problem here is that the user and the AI system may represent the task or the problem in different terms and as such, may need to bridge this difference for effective explanations. One of the closely related questions that came up was how do we even identify when such a difference exists? -
9.
How do you use explanation to potentially engage the user to obtain better solutions?
This is particularly important given that, for sequential decision making, many of the decision-making systems may be incomplete or suboptimal. There is a possibility here that the user might in fact be able to come up with better decisions. As such, an explanation in such a context should support the user in potentially identifying better solutions.Two more problems were also raised at different points during this seminar, relating to the more general problem of XAI. Specifically, the need to develop a more general theory of explanations, and the need to identify effective ways to evaluate explanations.
5.4.2 Next Steps
Apart from addressing these specific open questions, we also identified potential next steps we should take as a community. One particular one that came up often was the need for standardized ways to evaluate explanations. The proposed “xAI Gym” could provide consistent testing across different approaches, balancing automated testing with human evaluation. However, getting meaningful user feedback is expensive and time-consuming, and there is a risk of gaming evaluation metrics rather than improving the actual quality of the explanation. One suggestion that came up during the discussion was to investigate the potential of using Large Language Models as a potential proxy to evaluate the effectiveness of explanation. Interestingly, since the seminar, some preliminary work has been done in this direction (cf. [1]). Another suggestion that was made was to identify more real-world use cases and involve industry partners. Testing proposed methods on such scenarios could be crucial in identifying if there are any gaps that we may be overlooking. Efforts like the recent Airbus Competition on Scalable and Explainable AI Decision-Making [2] may represent useful steps in this direction.
We also need to make sure that we are building and maintaining connections with related fields like cognitive science and psychology, and ensuring that the latest results from these fields are being leveraged in our own efforts. Finally, more effort needs to be made in sharing and synthesizing results and insights from different subgroups of explainable sequential decision-making, such as those present at this seminar – which is not to say that there exist no unique challenges each group may face. Table 7 provides a further summary of the main challenges identified across breakout groups.
References
- [1] Bona, F.B., Dominici, G., Miller, T., Langheinrich, M., & Gjoreski, M. (2024). Evaluating Explanations Through LLMs: Beyond Traditional User Studies.
- [2] Beluga AI Challenge, https://tuples.ai/competition-challenge/
| Group | Key Challenges |
|---|---|
| RL Group | Explaining three key aspects: – Decisions (individual and trajectories) – Learning/execution algorithms – MDP components (transitions, rewards, discount) Handling temporal coupling of states Developing metrics for both functional/computational and human-grounded evaluation Addressing unique SDM aspects (dynamics, temporally extended goals) Tailoring explanations for different users (developers, domain experts, non-experts) |
| AI Planning | Explaining algorithm components (search tree, heuristics, replanning) Explaining plan validity and preferences Developing methods for model correctness and abstraction Balancing global vs local explanations Evaluating understanding, trust, satisfaction, and correctness Creating effective communication (visualization, natural language, dialogue) |
| SDM/Broad Group | Managing time dependence in explanations Handling changing goals in sequential processes Integrating SAFE-AI Framework (task/context/role) Balancing mechanistic vs intentional explanations Developing both forward and backward looking explanations Addressing mismatches between expectations and outcomes |
| Robotics | Explaining state estimation and belief states Supporting multiple description levels: – Contact events – Full trajectories – Continuous-space signals Managing environmental/agent constraints Balancing online vs post-hoc explanations Personalizing explanations based on expertise and context Handling physical constraints and failures |
| SimStats | Using rollouts to estimate state distributions Balancing simulation design with explanation needs Quantifying and presenting uncertainty Determining appropriate abstraction levels Implementing meaningful ’what-if’ scenarios |
| Explanation-Request Initialization | Determining when to provide proactive explanations Handling underdetermined requests Understanding explanation value to users Balancing compute cost vs cognitive load Determining appropriate types of explanations for different contexts |
| Evaluations | Creating standardized evaluation methods (xAI Gym proposal) Handling context-dependent nature of explanations Managing the expense of user feedback Avoiding gamification of evaluation metrics Balancing human-in-the-loop vs automated evaluation |
6 Participants
-
David Abel – Google DeepMind – London, GB
-
Hendrik Baier – TU Eindhoven, NL
-
Ruth Mary Josephine Byrne – Trinity College Dublin, University of Dublin, IE
-
Rebecca Eifler – LAAS – Toulouse, FR
-
Claudia Goldman – The Hebrew University of Jerusalem, IL
-
Bradley Hayes – University of Colorado – Boulder, US
-
Tobias Huber – TH Ingolstadt, DE
-
Mark T. Keane – University College Dublin, IE
-
Khimya Khetarpal – Google DeepMind – Seattle, US
-
Benjamin Krarup – King’s College London, GB
-
Pat Langley – ISLE – Palo Alto, US
-
Simon M. Lucas – Queen Mary University of London, GB
-
Anna Lukina – TU Delft, NL
-
Samer Nashed – University of Montreal, CA & MILA – Quebec AI Institute, CA
-
Sriraam Natarajan – University of Texas at Dallas – Richardson, US
-
Ann Nowé – Free University of Brussels, BE
-
Ron Petrick – Heriot-Watt University – Edinburgh, GB
-
Mark Riedl – Georgia Institute of Technology – Atlanta, US
-
Silvia Rossi – University of Naples, IT
-
Wojciech Samek – Fraunhofer HHI – Berlin, DE
-
Lindsay Sanneman – MIT – Cambridge, US
-
Julian Siber – CISPA – Saarbrücken, DE
-
Sarath Sreedharan – Colorado State University – Fort Collins, US
-
Mohan Sridharan – University of Edinburgh, GB
-
Silvia Tulli – Sorbonne Université – Paris, FR
-
Stylianos Loukas Vasileiou – Washington University – St. Louis, US
-
Abhinav Verma – Pennsylvania State University – University Park, US
![[Uncaptioned image]](x3.jpg)